数据结构——布隆计算器
文章目录
- 1.什么是布隆过滤器?
- 2.布隆过滤器的原理介绍
- 3.布隆过滤器使用场景
- 4.通过 Java 编程手动实现布隆过滤器
- 5.利用Google开源的 Guava中自带的布隆过滤器
- 6.Redis 中的布隆过滤器
- 6.1介绍
- 6.2使用Docker安装
- 6.3常用命令一览
- 6.4实际使用
1.什么是布隆过滤器?
布隆过滤器(Bloom Filter)是一个叫做 Bloom 的老哥于1970年提出的。我们可以把它看作由二进制向量(或者说位数组)和一系列随机映射函数(哈希函数)两部分组成的数据结构。相比于我们平时常用的的 List、Map 、Set 等数据结构,它占用空间更少并且效率更高,但是缺点是其返回的结果是概率性的,而不是非常准确的。理论情况下添加到集合中的元素越多,误报的可能性就越大。并且,存放在布隆过滤器的数据不容易删除。

位数组中的每个元素都只占用 1 bit ,并且每个元素只能是 0 或者 1。这样申请一个 100w 个元素的位数组只占用 1000000Bit / 8 = 125000 Byte = 125000/1024 kb ≈ 122kb 的空间。
总结:一个名叫 Bloom 的人提出了一种来检索元素是否在给定大集合中的数据结构,这种数据结构是高效且性能很好的,但缺点是具有一定的错误识别率和删除难度。并且,理论情况下,添加到集合中的元素越多,误报的可能性就越大。
2.布隆过滤器的原理介绍
当一个元素加入布隆过滤器中的时候,会进行如下操作:
- 使用布隆过滤器中的哈希函数对元素值进行计算,得到哈希值(有几个哈希函数得到几个哈希值)。
- 根据得到的哈希值,在位数组中把对应下标的值置为 1。
当我们需要判断一个元素是否存在于布隆过滤器的时候,会进行如下操作:
- 对给定元素再次进行相同的哈希计算;
- 得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1,说明该元素不在布隆过滤器中。
举个简单的例子:
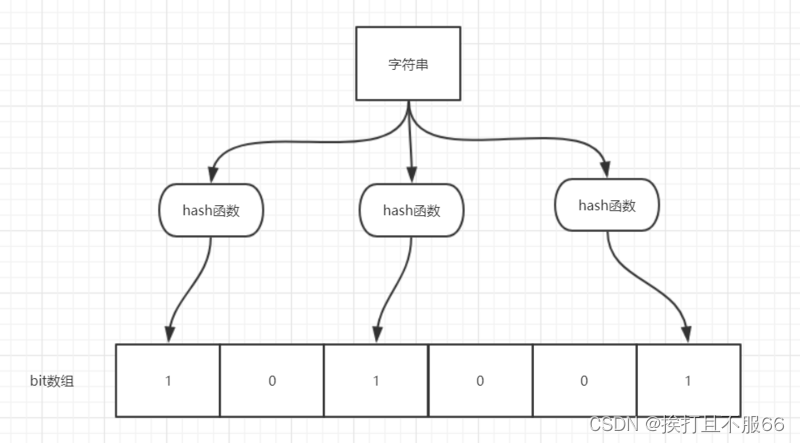
如图所示,当字符串存储要加入到布隆过滤器中时,该字符串首先由多个哈希函数生成不同的哈希值,然后在对应的位数组的下表的元素设置为 1(当位数组初始化时 ,所有位置均为0)。当第二次存储相同字符串时,因为先前的对应位置已设置为 1,所以很容易知道此值已经存在(去重非常方便)。
如果我们需要判断某个字符串是否在布隆过滤器中时,只需要对给定字符串再次进行相同的哈希计算,得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1,说明该元素不在布隆过滤器中。
不同的字符串可能哈希出来的位置相同,这种情况我们可以适当增加位数组大小或者调整我们的哈希函数。
综上,我们可以得出:布隆过滤器说某个元素存在,小概率会误判。布隆过滤器说某个元素不在,那么这个元素一定不在。
3.布隆过滤器使用场景
- 判断给定数据是否存在:比如判断一个数字是否存在于包含大量数字的数字集中(数字集很大,5亿以上!)、 防止缓存穿透(判断请求的数据是否有效避免直接绕过缓存请求数据库)等等、邮箱的垃圾邮件过滤、黑名单功能等等。
- 去重:比如爬给定网址的时候对已经爬取过的 URL 去重。
4.通过 Java 编程手动实现布隆过滤器
我们上面已经说了布隆过滤器的原理,知道了布隆过滤器的原理之后就可以自己手动实现一个了。
如果你想要手动实现一个的话,你需要:
- 一个合适大小的位数组保存数据
- 几个不同的哈希函数
- 添加元素到位数组(布隆过滤器)的方法实现
- 判断给定元素是否存在于位数组(布隆过滤器)的方法实现。
下面给出一个我觉得写的还算不错的代码(参考网上已有代码改进得到,对于所有类型对象皆适用):
import java.util.BitSet;public class MyBloomFilter {/*** 位数组的大小*/private static final int DEFAULT_SIZE = 2 << 24;/*** 通过这个数组可以创建 6 个不同的哈希函数*/private static final int[] SEEDS = new int[]{3, 13, 46, 71, 91, 134};/*** 位数组。数组中的元素只能是 0 或者 1*/private BitSet bits = new BitSet(DEFAULT_SIZE);/*** 存放包含 hash 函数的类的数组*/private SimpleHash[] func = new SimpleHash[SEEDS.length];/*** 初始化多个包含 hash 函数的类的数组,每个类中的 hash 函数都不一样*/public MyBloomFilter() {// 初始化多个不同的 Hash 函数for (int i = 0; i < SEEDS.length; i++) {func[i] = new SimpleHash(DEFAULT_SIZE, SEEDS[i]);}}/*** 添加元素到位数组*/public void add(Object value) {for (SimpleHash f : func) {bits.set(f.hash(value), true);}}/*** 判断指定元素是否存在于位数组*/public boolean contains(Object value) {boolean ret = true;for (SimpleHash f : func) {ret = ret && bits.get(f.hash(value));}return ret;}/*** 静态内部类。用于 hash 操作!*/public static class SimpleHash {private int cap;private int seed;public SimpleHash(int cap, int seed) {this.cap = cap;this.seed = seed;}/*** 计算 hash 值*/public int hash(Object value) {int h;return (value == null) ? 0 : Math.abs(seed * (cap - 1) & ((h = value.hashCode()) ^ (h >>> 16)));}}
}
测试:
String value1 = "https://javaguide.cn/";String value2 = "https://github.com/Snailclimb";MyBloomFilter filter = new MyBloomFilter();System.out.println(filter.contains(value1));System.out.println(filter.contains(value2));filter.add(value1);filter.add(value2);System.out.println(filter.contains(value1));System.out.println(filter.contains(value2));
Output:
false
false
true
true
测试:
Integer value1 = 13423;Integer value2 = 22131;MyBloomFilter filter = new MyBloomFilter();System.out.println(filter.contains(value1));System.out.println(filter.contains(value2));filter.add(value1);filter.add(value2);System.out.println(filter.contains(value1));System.out.println(filter.contains(value2));
Output:
false
false
true
true
5.利用Google开源的 Guava中自带的布隆过滤器
自己实现的目的主要是为了让自己搞懂布隆过滤器的原理,Guava 中布隆过滤器的实现算是比较权威的,所以实际项目中我们不需要手动实现一个布隆过滤器。
首先我们需要在项目中引入 Guava 的依赖:
<dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><version>28.0-jre</version></dependency>
实际使用如下:
我们创建了一个最多存放 最多 1500个整数的布隆过滤器,并且我们可以容忍误判的概率为百分之(0.01)
// 创建布隆过滤器对象BloomFilter<Integer> filter = BloomFilter.create(Funnels.integerFunnel(),1500,0.01);// 判断指定元素是否存在System.out.println(filter.mightContain(1));System.out.println(filter.mightContain(2));// 将元素添加进布隆过滤器filter.put(1);filter.put(2);System.out.println(filter.mightContain(1));System.out.println(filter.mightContain(2));
在我们的示例中,当mightContain() 方法返回true时,我们可以99%确定该元素在过滤器中,当过滤器返回false时,我们可以100%确定该元素不存在于过滤器中。
Guava 提供的布隆过滤器的实现还是很不错的(想要详细了解的可以看一下它的源码实现),但是它有一个重大的缺陷就是只能单机使用(另外,容量扩展也不容易),而现在互联网一般都是分布式的场景。为了解决这个问题,我们就需要用到 Redis 中的布隆过滤器了。
6.Redis 中的布隆过滤器
6.1介绍
Redis v4.0 之后有了 Module(模块/插件) 功能,Redis Modules 让 Redis 可以使用外部模块扩展其功能 。布隆过滤器就是其中的 Module。详情可以查看 Redis 官方对 Redis Modules 的介绍 :https://redis.io/modules
另外,官网推荐了一个 RedisBloom 作为 Redis 布隆过滤器的 Module,地址:https://github.com/RedisBloom/RedisBloom. 其他还有:
- redis-lua-scaling-bloom-filter (lua 脚本实现):https://github.com/erikdubbelboer/redis-lua-scaling-bloom-filter
- pyreBloom(Python中的快速Redis 布隆过滤器) :https://github.com/seomoz/pyreBloom
- …
RedisBloom 提供了多种语言的客户端支持,包括:Python、Java、JavaScript 和 PHP。
6.2使用Docker安装
如果我们需要体验 Redis 中的布隆过滤器非常简单,通过 Docker 就可以了!我们直接在 Google 搜索docker redis bloomfilter 然后在排除广告的第一条搜素结果就找到了我们想要的答案(这是我平常解决问题的一种方式,分享一下),具体地址:https://hub.docker.com/r/redislabs/rebloom/ (介绍的很详细 )。
具体操作如下:
➜ ~ docker run -p 6379:6379 --name redis-redisbloom redislabs/rebloom:latest
➜ ~ docker exec -it redis-redisbloom bash
root@21396d02c252:/data# redis-cli
127.0.0.1:6379>
6.3常用命令一览
注意: key:布隆过滤器的名称,item : 添加的元素。
BF.ADD:将元素添加到布隆过滤器中,如果该过滤器尚不存在,则创建该过滤器。格式:BF.ADD {key} {item}。BF.MADD: 将一个或多个元素添加到“布隆过滤器”中,并创建一个尚不存在的过滤器。该命令的操作方式BF.ADD与之相同,只不过它允许多个输入并返回多个值。格式:BF.MADD {key} {item} [item ...]。- **
BF.EXISTS** : 确定元素是否在布隆过滤器中存在。格式:BF.EXISTS {key} {item}。 BF.MEXISTS: 确定一个或者多个元素是否在布隆过滤器中存在格式:BF.MEXISTS {key} {item} [item ...]。
另外,BF.RESERVE 命令需要单独介绍一下:
这个命令的格式如下:
BF.RESERVE {key} {error_rate} {capacity} [EXPANSION expansion] 。
下面简单介绍一下每个参数的具体含义:
- key:布隆过滤器的名称
- error_rate :误报的期望概率。这应该是介于0到1之间的十进制值。例如,对于期望的误报率0.1%(1000中为1),error_rate应该设置为0.001。该数字越接近零,则每个项目的内存消耗越大,并且每个操作的CPU使用率越高。
- capacity: 过滤器的容量。当实际存储的元素个数超过这个值之后,性能将开始下降。实际的降级将取决于超出限制的程度。随着过滤器元素数量呈指数增长,性能将线性下降。
可选参数:
- expansion:如果创建了一个新的子过滤器,则其大小将是当前过滤器的大小乘以
expansion。默认扩展值为2。这意味着每个后续子过滤器将是前一个子过滤器的两倍。
6.4实际使用
127.0.0.1:6379> BF.ADD myFilter java
(integer) 1
127.0.0.1:6379> BF.ADD myFilter javaguide
(integer) 1
127.0.0.1:6379> BF.EXISTS myFilter java
(integer) 1
127.0.0.1:6379> BF.EXISTS myFilter javaguide
(integer) 1
127.0.0.1:6379> BF.EXISTS myFilter github
(integer) 0
相关文章:
数据结构——布隆计算器
文章目录 1.什么是布隆过滤器?2.布隆过滤器的原理介绍3.布隆过滤器使用场景4.通过 Java 编程手动实现布隆过滤器5.利用Google开源的 Guava中自带的布隆过滤器6.Redis 中的布隆过滤器6.1介绍6.2使用Docker安装6.3常用命令一览6.4实际使用 1.什么是布隆过滤器…...

金融学复习博迪(第6-9章)
第6章 投资项目分析 学习目的:解释资本预算;资本预算基本法则 资本预算过程包含三个基本要素: 一提出针对投资项目的建议 一对这些建议进行评价 一决定接受和拒绝哪些建议 6.1项目分析的特性 资本预算的过程中的基本单位是单个的投资项目。投…...
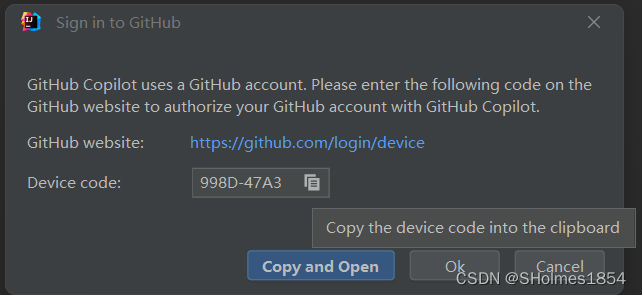
解决idea登录github copilot报错问题
试了好多方案都没用,但是这个有用, 打开idea-help-edit custonm vm options 然后在这个文件里面输入 -Dcopilot.agent.disabledtrue再打开 https://github.com/settings/copilot 把这个设置成allow,然后重新尝试登录copilot就行就行 解决方…...

什么是Flex布局?请列举一些Flex布局的常用属性。
聚沙成塔每天进步一点点 ⭐ 专栏简介⭐ Flex布局(Flexible Box Layout)⭐ Flex布局的常用属性⭐ 写在最后 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 记得点击上方或者右侧链接订阅本专栏哦 几何带你启航前端之旅 欢迎来到前端入门之…...

React + TypeScript + antd 常见开发场景
时间戳转格式 // 获取当前时间戳(示例) const timestamp Date.now(); // 或者使用特定的时间戳值// 创建一个新的Date对象,并传入时间戳 const date new Date(timestamp);// 获取年、月、日的值 const year date.getFullYear(); const mon…...
前端基础踩坑记录
前言:在做vue项目时,有时代码没有报错,但运行时却各种问题,没有报错排查起来就很费劲,本人感悟:写前端,需要好的眼神!!!谨以此博客记录下自己的踩坑点。 一、…...

k8s删除pod镜像没响应marking for deletion pod TaintManagerEviction
使用命令强制删除 Pod的状态为"Marking for deletion"表示该Pod正在被标记为待删除状态,但实际上并没有被删除。这可能是因为以下原因之一: 删除操作被阻塞:可能是由于某些资源或容器正在使用该Pod,导致删除操作被阻塞…...

Nginx 使用 lua-nginx-module 来获取post请求中的request和response信息
如果想要在nginx中打印出 http request 的所有 header,需要在编译nginx时开启 1、安装编译所需的依赖 apt-get install build-essential libpcre3 libpcre3-dev zlib1g zlib1g-dev libssl-dev2、创建下载路径 mkdir -p /opt/download3、下载所需的文件 # 不要下载…...
函数(1))
【Opencv】三维重建之cv::recoverPose()函数(1)
官网链接 从估计的本质矩阵和两幅图像中的对应点恢复相机之间的旋转和平移,使用光束法则进行检验。返回通过检验的内点数目。 #include <opencv2/calib3d.hpp>int cv::recoverPose ( InputArray E, InputArray points1, InputArray points2, InputArray …...

Perl兼容正则表达式函数-PHP8知识详解
在php8中有两类正则表达式函数,一类是perl兼容正则表达式函数,另一类是posix扩展正则表达式函数。二者区别不大,我们推荐使用Perl兼容正则表达式函数。 1、使用正则表达式对字符串进行匹配 用正则表达式对目标字符串进行匹配是正则表达式的主…...

Python处理空值NaN
fork_address_tempread_excel_column_to_list(./eqp_info.xls,Sheet1,车辆地址)for i in fork_address_temp:print(type(i))fork_address[0 if address nan else address for address in fork_address_temp]fork_address结果 <class float><class float><class…...

软件机器人助力交通运输局数据录入,实现高效管理
随着科技的迅速发展,许多传统的行业正在寻求通过科技创新优化工作流程、提升效率。在这样的大背景下,交通运输部门也开始注重引入科技手段改善工作流程。博为小帮软件机器人正逐步改变着交通运输局的工作方式。 软件机器人:交通管理的利器 博…...
时序分解 | MATLAB实现基于SGMD辛几何模态分解的信号分解分量可视化
时序分解 | MATLAB实现基于SGMD辛几何模态分解的信号分解分量可视化 目录 时序分解 | MATLAB实现基于SGMD辛几何模态分解的信号分解分量可视化效果一览基本介绍程序设计参考资料 效果一览 基本介绍 SGMD分解算法(辛几何模态分解),分解结果可视…...

FinalShell报错:Swap file “.docker-compose.yml.swp“ already exists
FinalShell中编辑docker-compose.yml文件,保存时报错:Swap file ".docker-compose.yml.swp" already exists;报错信息截图如下: 问题原因:有人正在编辑docker-compose.yml文件或者上次编辑没有保存ÿ…...
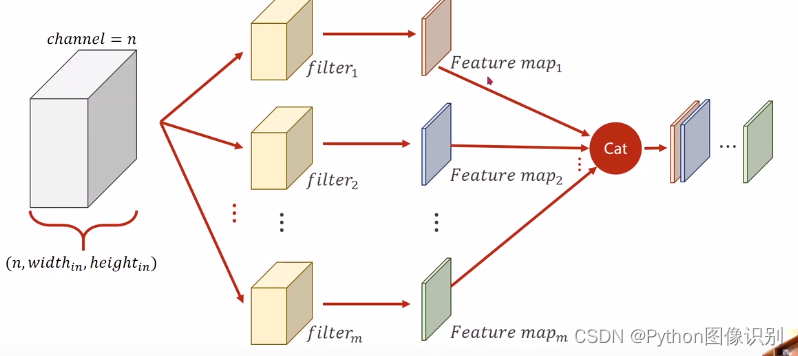
卷积过程详细讲解
1:单通道卷积 以单通道卷积为例,输入为(1,5,5),分别表示1个通道,宽为5,高为5。假设卷积核大小为3x3,padding0,stride1。 卷积过程如下: 相应的卷积核不断…...

代码随想录第五十六天
代码随想录第五十六天 Leetcode 583. 两个字符串的删除操作Leetcode 72. 编辑距离 Leetcode 583. 两个字符串的删除操作 题目链接: 两个字符串的删除操作 自己的思路:想到了,但是初始化初始错了!!!! 思路1:直接动规五…...

.NET 最便捷的Log4Net日志记录器
最便捷的Log4Net使用方法 LOG4NET 配置日志记录器开始引用nuget LOG4NET 配置日志记录器 Apache log4net 库是一个帮助程序员将日志语句输出到各种的工具 的输出目标。log4net是优秀的Apachelog4j™框架的移植 Microsoft.NET 运行时。我们保持了与原始log4j相似的框架 同时利…...

深入探讨软件逆向工程:解密黑盒的奥秘
引言 逆向工程作为计算机科学领域中的一项关键技术,扮演着解密、漏洞分析、反病毒等诸多领域的重要角色。本文将深入探讨逆向工程的概念、应用领域以及一些常用的逆向工程技术。 什么是逆向工程? 逆向工程是指通过分析已有的程序或设备,推…...
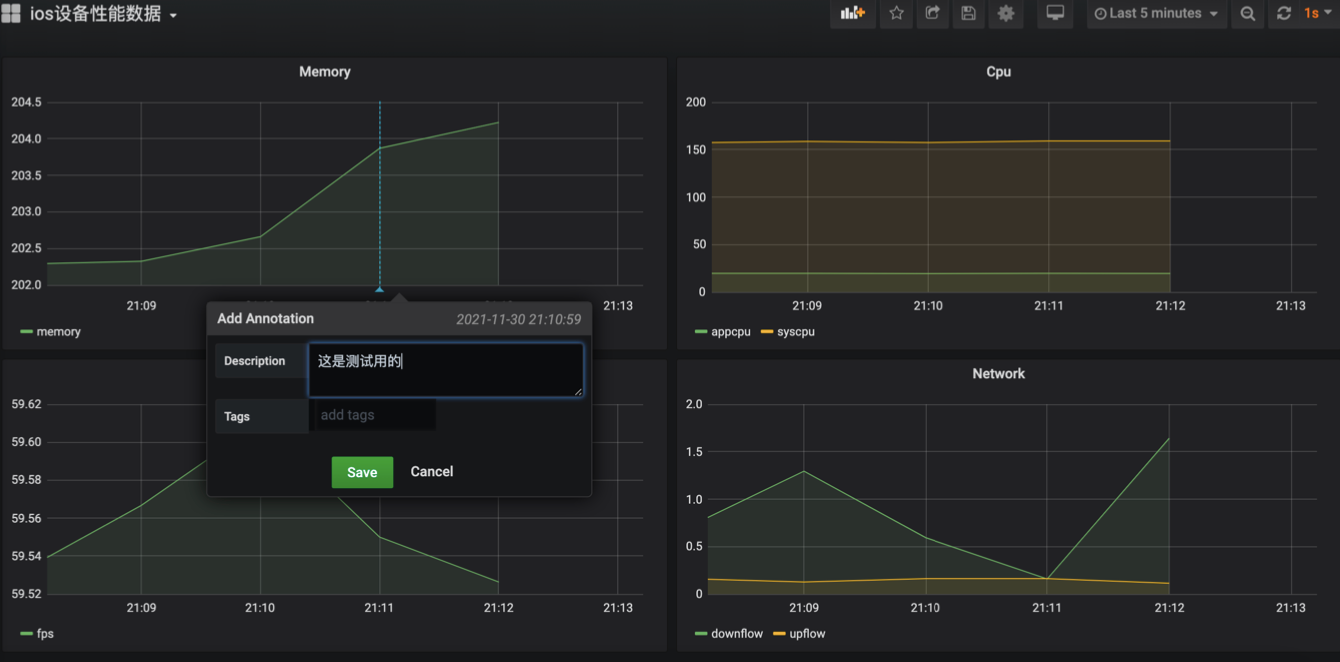
利用tidevice+mysql+grafana实现ios性能测试
利用tidevicemysqlgrafana实现ios性能测试 1.什么是tidevice? tidevice是一个可以和ios设备进行通信的工具,提供以下功能: 截图获取手机信息ipa包的安装和卸载根据bundleID 启动和停止应用列出安装应用信息模拟Xcode运行XCTest,…...
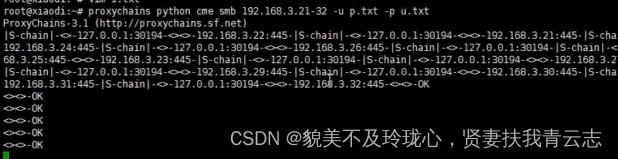
内网安全:WMI协议与SMB协议横向移动
目录 网络拓扑图 网络环境说明 WMI协议 SMB协议 域内信息收集 WMI协议 - 横向移动 利用方式一:wmic命令 利用方式一:cscript 利用方式一:impacket SMB协议 - 横向移动 利用方式一:psexec 利用方式二:psexe…...

Seraphine:英雄联盟玩家的智能BP助手与战绩查询工具完全指南
Seraphine:英雄联盟玩家的智能BP助手与战绩查询工具完全指南 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine 你是否曾经在英雄联盟的BP阶段感到迷茫,不知道应该禁用哪个英雄࿱…...

从滑动变阻器到真实传感器:STM32CubeMX ADC单通道采集电压的校准与数据处理实战
从滑动变阻器到真实传感器:STM32CubeMX ADC单通道采集电压的校准与数据处理实战 在嵌入式开发中,ADC(模数转换器)是将模拟信号转换为数字信号的关键外设。许多开发者能够通过STM32CubeMX快速配置ADC并获取原始值,但当…...

探索Harepacker复活版:打造你的MapleStory创意工坊
探索Harepacker复活版:打造你的MapleStory创意工坊 【免费下载链接】Harepacker-resurrected All in one .wz file/map editor for MapleStory game files 项目地址: https://gitcode.com/gh_mirrors/ha/Harepacker-resurrected 你是否曾经梦想过亲手改造Map…...

Qt QSettings管理Windows环境变量:原理、实现与实战优化
1. 项目概述最近在做一个Qt开发的桌面工具,里面有个功能点需要动态修改用户的系统环境变量,比如把一些我们自己打包的工具路径加到用户的PATH里,这样用户在其他地方打开命令行也能直接调用。一开始想着用系统API或者直接写注册表,…...

告别Unity WebGL的模糊UI:用Vue3重构前端界面,手把手教你实现双向通信
Unity WebGL与Vue3的完美联姻:打造高清交互界面的实战指南 1. 为什么需要重构Unity WebGL的UI系统? 许多Unity开发者都曾经历过这样的困境:当我们将精心制作的3D项目发布为WebGL版本时,原生UGUI在浏览器中的表现往往不尽如人意。模…...

ARM PMU性能监控机制与微架构事件解析
1. ARM PMU性能监控体系深度解析性能监控单元(PMU)是现代处理器中用于统计硬件事件的关键模块,它如同处理器的"听诊器",能够精确捕捉微架构层面的各类行为。在ARMv8/v9架构中,PMU通过事件计数器机制实现对指令流水线、缓存子系统、…...

Python之vyvert包语法、参数和实际应用案例
一、vyvert 包概述(Python) vyvert(0.1.0)是一个轻量级依赖注入(DI)库,灵感来自 pytest 与 FastAPI,主打简洁注解式注入、自动依赖解析、异步兼容。 定位:非侵入式 DI&am…...

数据库安全与权限管理
数据库安全与权限管理 1. 技术分析 1.1 数据库安全概述 数据库安全是保护数据资产的关键: 安全威胁未授权访问: 密码泄露SQL注入: 恶意SQL数据泄露: 敏感信息暴露数据篡改: 非法修改安全措施:访问控制加密存储审计日志1.2 权限管理 权限级别全局权限: ALL PRIVILEGE…...

PotPlayer百度翻译插件终极指南:免费实现20+语言实时字幕翻译
PotPlayer百度翻译插件终极指南:免费实现20语言实时字幕翻译 【免费下载链接】PotPlayer_Subtitle_Translate_Baidu PotPlayer 字幕在线翻译插件 - 百度平台 项目地址: https://gitcode.com/gh_mirrors/po/PotPlayer_Subtitle_Translate_Baidu PotPlayer字幕…...

正交张量、正定张量与材料稳定性:在有限元分析ABAQUS中的实际应用与参数设置
正交张量、正定张量与材料稳定性:在有限元分析ABAQUS中的实际应用与参数设置 当工程师在ABAQUS中遇到材料刚度矩阵非正定警告时,往往意味着仿真结果可能失去物理意义。这种警告背后隐藏着深刻的张量数学原理——正定张量的性质直接决定了材料本构模型的稳…...