2023年国赛 高教社杯数学建模思路 - 案例:感知机原理剖析及实现
文章目录
- 1 感知机的直观理解
- 2 感知机的数学角度
- 3 代码实现
- 4 建模资料
# 0 赛题思路
(赛题出来以后第一时间在CSDN分享)
https://blog.csdn.net/dc_sinor?type=blog
1 感知机的直观理解
感知机应该属于机器学习算法中最简单的一种算法,其原理可以看下图:
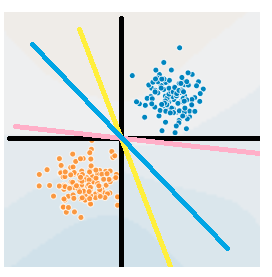
比如说我们有一个坐标轴(图中的黑色线),横的为x1轴,竖的x2轴。图中的每一个点都是由(x1,x2)决定的。如果我们将这张图应用在判断零件是否合格上,x1表示零件长度,x2表示零件质量,坐标轴表示零件的均值长度和均值重量,并且蓝色的为合格产品,黄色为劣质产品,需要剔除。那么很显然如果零件的长度和重量都大于均值,说明这个零件是合格的。也就是在第一象限的所有蓝色点。反之如果两项都小于均值,就是劣质的,比如在第三象限的黄色点。
在预测上很简单,拿到一个新的零件,我们测出它的长度x1,质量x2,如果两项都大于均值,说明零件合格。这就是我们人的人工智能。
那么程序怎么知道长度重量都大于均值的零件就是合格的呢?
或者说
它是怎么学会这个规则的呢?
程序拿到手的是当前图里所有点的信息以及标签,也就是说它知道所有样本x的坐标为(x1, x2),同时它属于蓝色或黄色。对于目前手里的这些点,要是能找到一条直线把它们分开就好了,这样我拿到一个新的零件,知道了它的质量和重量,我就可以判断它在线的哪一侧,就可以知道它可能属于好的或坏的零件了。例如图里的黄、蓝、粉三条线,都可以完美地把当前的两种情况划分开。甚至x1坐标轴或x2坐标轴都能成为一个划分直线(这两个直线均能把所有点正确地分开)。
读者也看到了,对于图中的两堆点,我们有无数条直线可以将其划分开,事实上我们不光要能划分当前的点,当新来的点进来是,也要能很好地将其划分,所以哪条线最好呢?
怎样一条直线属于最佳的划分直线?实际上感知机无法找到一条最佳的直线,它找到的可能是图中所有画出来的线,只要能把所有的点都分开就好了。
得出结论:
如果一条直线能够不分错一个点,那就是一条好的直线
进一步来说:
如果我们把所有分错的点和直线的距离求和,让这段求和的举例最小(最好是0,这样就表示没有分错的点了),这条直线就是我们要找的。
2 感知机的数学角度
首先我们确定一下终极目标:甭管找最佳划分直线啥中间乱七八糟的步骤,反正最后生成一个函数f(x),当我们把新的一个数据x扔进函数以后,它会预测告诉我这是蓝的还是黄的,多简单啊。所以我们不要去考虑中间过程,先把结果定了。
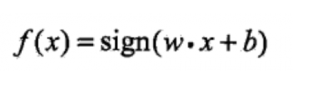
瞧,f(x)不是出来了嘛,sign是啥?wx+b是啥?别着急,我们再看一下sigin函数是什么。
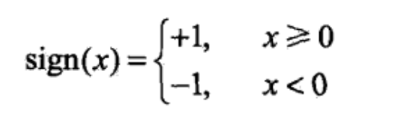
sign好像很简单,当x大于等于0,sign输出1,否则输出-1。那么往前递归一下,wx+b如果大于等于0,f(x)就等于1,反之f(x)等于-1。
那么wx+b是啥?
它就是那条最优的直线。我们把这个公式放在二维情况下看,二维中的直线是这样定义的:y=ax+b。在二维中,w就是a,b还是b。所以wx+b是一条直线(比如说本文最开始那张图中的蓝线)。如果新的点x在蓝线左侧,那么wx+b<0,再经过sign,最后f输出-1,如果在右侧,输出1。等等,好像有点说不通,把情况等价到二维平面中,y=ax+b,只要点在x轴上方,甭管点在线的左侧右侧,最后结果都是大于0啊,这个值得正负跟线有啥关系?emmm….其实wx+b和ax+b表现直线的形式一样,但是又稍有差别。我们把最前头的图逆时针旋转45度,蓝线是不是变成x轴了?哈哈这样是不是原先蓝线的右侧变成了x轴的上方了?其实感知机在计算wx+b这条线的时候,已经在暗地里进行了转换,使得用于划分的直线变成x轴,左右侧分别为x轴的上方和下方,也就成了正和负。
那么,为啥是wx+b,而不叫ax+b?
在本文中使用零件作为例子,上文使用了长度和重量(x1,x2)来表示一个零件的属性,所以一个二维平面就足够,那么如果零件的品质和色泽也有关系呢?那就得加一个x3表示色泽,样本的属性就变成了(x1,x2,x3),变成三维了。wx+b并不是只用于二维情况,在三维这种情况下,仍然可以使用这个公式。所以wx+b与ax+b只是在二维上近似一致,实际上是不同的东西。在三维中wx+b是啥?我们想象屋子里一个角落有蓝点,一个角落有黄点,还用一条直线的话,显然是不够的,需要一个平面!所以在三维中,wx+b是一个平面!至于为什么,后文会详细说明。四维呢?emmm…好像没法描述是个什么东西可以把四维空间分开,但是对于四维来说,应该会存在一个东西像一把刀一样把四维空间切成两半。能切成两半,应该是一个对于四维来说是个平面的东西,就像对于三维来说切割它的是一个二维的平面,二维来说是一个一维的平面。总之四维中wx+b可以表示为一个相对于四维来说是个平面的东西,然后把四维空间一切为二,我们给它取名叫超平面。由此引申,在高维空间中,wx+b是一个划分超平面,这也就是它正式的名字。
正式来说:
wx+b是一个n维空间中的超平面S,其中w是超平面的法向量,b是超平面的截距,这个超平面将特征空间划分成两部分,位于两部分的点分别被分为正负两类,所以,超平面S称为分离超平面。
细节:
w是超平面的法向量:对于一个平面来说w就是这么定义的,是数学知识,可以谷歌补习一下
b是超平面的截距:可以按照二维中的ax+b理解
特征空间:也就是整个n维空间,样本的每个属性都叫一个特征,特征空间的意思是在这个空间中可以找到样本所有的属性组合

我们从最初的要求有个f(x),引申到能只输出1和-1的sign(x),再到现在的wx+b,看起来越来越简单了,只要能找到最合适的wx+b,就能完成感知机的搭建了。前文说过,让误分类的点距离和最大化来找这个超平面,首先我们要放出单独计算一个点与超平面之间距离的公式,这样才能将所有的点的距离公式求出来对不?

先看wx+b,在二维空间中,我们可以认为它是一条直线,同时因为做过转换,整张图旋转后wx+b是x轴,那么所有点到x轴的距离其实就是wx+b的值对不?当然了,考虑到x轴下方的点,得加上绝对值->|wx+b|,求所有误分类点的距离和,也就是求|wx+b|的总和,让它最小化。很简单啊,把w和b等比例缩小就好啦,比如说w改为0.5w,b改为0.5b,线还是那条线,但是值缩小两倍啦!你还不满意?我可以接着缩!缩到0去!所以啊,我们要加点约束,让整个式子除以w的模长。啥意思?就是w不管怎么样,要除以它的单位长度。如果我w和b等比例缩小,那||w||也会等比例缩小,值一动不动,很稳。没有除以模长之前,|wx+b|叫函数间隔,除模长之后叫几何间隔,几何间隔可以认为是物理意义上的实际长度,管你怎么放大缩小,你物理距离就那样,不可能改个数就变。在机器学习中求距离时,通常是使用几何间隔的,否则无法求出解。

对于误分类的数据,例如实际应该属于蓝色的点(线的右侧,y>0),但实际上预测出来是在左侧(wx+b<0),那就是分错了,结果是负,这时候再加个符号,结果就是正了,再除以w的模长,就是单个误分类的点到超平面的举例。举例总和就是所有误分类的点相加。
上图最后说不考虑除以模长,就变成了函数间隔,为什么可以这么做呢?不考虑wb等比例缩小这件事了吗?上文说的是错的吗?
有一种解释是这样说的:感知机是误分类驱动的算法,它的终极目标是没有误分类的点,如果没有误分类的点,总和距离就变成了0,w和b值怎样都没用。所以几何间隔和函数间隔在感知机的应用上没有差别,为了计算简单,使用函数间隔。

以上是损失函数的正式定义,在求得划分超平面的终极目标就是让损失函数最小化,如果是0的话就相当完美了。

感知机使用梯度下降方法求得w和b的最优解,从而得到划分超平面wx+b,关于梯度下降及其中的步长受篇幅所限可以自行谷歌。
3 代码实现
#coding=utf-8
#Author:Dodo
#Date:2018-11-15
#Email:lvtengchao@pku.edu.cn
'''
数据集:Mnist
训练集数量:60000
测试集数量:10000
------------------------------
运行结果:
正确率:81.72%(二分类)
运行时长:78.6s
'''
import numpy as np
import time
def loadData(fileName):'''加载Mnist数据集:param fileName:要加载的数据集路径:return: list形式的数据集及标记'''print('start to read data')# 存放数据及标记的listdataArr = []; labelArr = []# 打开文件fr = open(fileName, 'r')# 将文件按行读取for line in fr.readlines():# 对每一行数据按切割福','进行切割,返回字段列表curLine = line.strip().split(',')# Mnsit有0-9是个标记,由于是二分类任务,所以将>=5的作为1,<5为-1if int(curLine[0]) >= 5:labelArr.append(1)else:labelArr.append(-1)#存放标记#[int(num) for num in curLine[1:]] -> 遍历每一行中除了以第一哥元素(标记)外将所有元素转换成int类型#[int(num)/255 for num in curLine[1:]] -> 将所有数据除255归一化(非必须步骤,可以不归一化)dataArr.append([int(num)/255 for num in curLine[1:]])#返回data和labelreturn dataArr, labelArr
def perceptron(dataArr, labelArr, iter=50):'''感知器训练过程:param dataArr:训练集的数据 (list):param labelArr: 训练集的标签(list):param iter: 迭代次数,默认50:return: 训练好的w和b'''print('start to trans')#将数据转换成矩阵形式(在机器学习中因为通常都是向量的运算,转换称矩阵形式方便运算)#转换后的数据中每一个样本的向量都是横向的dataMat = np.mat(dataArr)#将标签转换成矩阵,之后转置(.T为转置)。#转置是因为在运算中需要单独取label中的某一个元素,如果是1xN的矩阵的话,无法用label[i]的方式读取#对于只有1xN的label可以不转换成矩阵,直接label[i]即可,这里转换是为了格式上的统一labelMat = np.mat(labelArr).T#获取数据矩阵的大小,为m*nm, n = np.shape(dataMat)#创建初始权重w,初始值全为0。#np.shape(dataMat)的返回值为m,n -> np.shape(dataMat)[1])的值即为n,与#样本长度保持一致w = np.zeros((1, np.shape(dataMat)[1]))#初始化偏置b为0b = 0#初始化步长,也就是梯度下降过程中的n,控制梯度下降速率h = 0.0001#进行iter次迭代计算for k in range(iter):#对于每一个样本进行梯度下降#李航书中在2.3.1开头部分使用的梯度下降,是全部样本都算一遍以后,统一#进行一次梯度下降#在2.3.1的后半部分可以看到(例如公式2.6 2.7),求和符号没有了,此时用#的是随机梯度下降,即计算一个样本就针对该样本进行一次梯度下降。#两者的差异各有千秋,但较为常用的是随机梯度下降。for i in range(m):#获取当前样本的向量xi = dataMat[i]#获取当前样本所对应的标签yi = labelMat[i]#判断是否是误分类样本#误分类样本特诊为: -yi(w*xi+b)>=0,详细可参考书中2.2.2小节#在书的公式中写的是>0,实际上如果=0,说明改点在超平面上,也是不正确的if -1 * yi * (w * xi.T + b) >= 0:#对于误分类样本,进行梯度下降,更新w和bw = w + h * yi * xib = b + h * yi#打印训练进度print('Round %d:%d training' % (k, iter))#返回训练完的w、breturn w, b
def test(dataArr, labelArr, w, b):'''测试准确率:param dataArr:测试集:param labelArr: 测试集标签:param w: 训练获得的权重w:param b: 训练获得的偏置b:return: 正确率'''print('start to test')#将数据集转换为矩阵形式方便运算dataMat = np.mat(dataArr)#将label转换为矩阵并转置,详细信息参考上文perceptron中#对于这部分的解说labelMat = np.mat(labelArr).T#获取测试数据集矩阵的大小m, n = np.shape(dataMat)#错误样本数计数errorCnt = 0#遍历所有测试样本for i in range(m):#获得单个样本向量xi = dataMat[i]#获得该样本标记yi = labelMat[i]#获得运算结果result = -1 * yi * (w * xi.T + b)#如果-yi(w*xi+b)>=0,说明该样本被误分类,错误样本数加一if result >= 0: errorCnt += 1#正确率 = 1 - (样本分类错误数 / 样本总数)accruRate = 1 - (errorCnt / m)#返回正确率return accruRate
if __name__ == '__main__':#获取当前时间#在文末同样获取当前时间,两时间差即为程序运行时间start = time.time()#获取训练集及标签trainData, trainLabel = loadData('../Mnist/mnist_train.csv')#获取测试集及标签testData, testLabel = loadData('../Mnist/mnist_test.csv')#训练获得权重w, b = perceptron(trainData, trainLabel, iter = 30)#进行测试,获得正确率accruRate = test(testData, testLabel, w, b)#获取当前时间,作为结束时间end = time.time()#显示正确率print('accuracy rate is:', accruRate)#显示用时时长print('time span:', end - start)
4 建模资料
资料分享: 最强建模资料


相关文章:
2023年国赛 高教社杯数学建模思路 - 案例:感知机原理剖析及实现
文章目录 1 感知机的直观理解2 感知机的数学角度3 代码实现 4 建模资料 # 0 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 1 感知机的直观理解 感知机应该属于机器学习算法中最简单的一种算法,其…...

java-红黑树
节点内部存储 红黑树规则 或者: 红黑树添加节点规则: 添加节点默认是红色的(效率高) 红黑树示例 注:红黑树增删改查性能都很好...
vue2 vue中的常用指令
一、为什么要学习Vue 1.前端必备技能 2.岗位多,绝大互联网公司都在使用Vue 3.提高开发效率 4.高薪必备技能(Vue2Vue3) 二、什么是Vue 概念:Vue (读音 /vjuː/,类似于 view) 是一套 **构建用户界面 ** 的 渐进式 …...

AI驱动下的智能制造:工业自动化的新纪元
随着人工智能(AI)技术的持续进步,其在工业自动化领域的影响日益显著。作为现代科技的代表,AI不仅为各行业带来了前所未有的商机和技术思路,更在工业自动化领域中引发了一场深刻的变革。本文将深入探讨AI对智能制造的影…...

docker 命令
一、docker命令 1、镜像保存 docker save imageid -o modelzoozl.tar #把镜像保存到本地 docker load -i dockername #把tar包load下来,load成镜像 docker export CONTAINERID/CONTAINERNAME -o modelzoozl.tar #把启动着的镜像导出 docker import modelzo…...
2023年高教社杯数学建模思路 - 复盘:光照强度计算的优化模型
文章目录 0 赛题思路1 问题要求2 假设约定3 符号约定4 建立模型5 模型求解6 实现代码 建模资料 0 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 1 问题要求 现在已知一个教室长为15米,宽为12米&…...

生成式人工智能的潜在有害影响与未来之路(二)
利润高于隐私:不透明数据收集增加 背景和风险 生成型人工智能工具建立在各种大型、复杂的机器学习模型之上,这些模型需要大量的训练数据才能发挥作用。对于像ChatGPT这样的工具,数据包括从互联网上抓取的文本。对于像Lensa或Stable Diffusi…...
如何自己实现一个丝滑的流程图绘制工具(三)自定义挂载vue组件
背景 bpmn-js是个流程图绘制的工具,但是现在我希望实现的是,绘制的不是节点而是一个vue组件。 保留线的拖拽和连接。 方案 那就说明不是依赖于节点的样式,找到了他有个属性,就是类似覆盖节点的操作。 思路就是用vue组件做遮罩&…...

UNIAPP调用API接口
API:开发者可以通过这些接口与其它程序进行交互,获取所需数据或者执行指定操作。 网络请求 API: UniApp 中内置了网络请求 API,方便调用 uni.request uni.uploadFile uni.request 接口主要用于实现网络请求。GET 和 POST 是使用最普遍的两种…...
 - 认识类的继承)
理解 Delphi 的类(五) - 认识类的继承
先新建一个 VCL Forms Application 工程, 代码中就已经出现了两个类: 一个是 TForm 类; 一个是 TForm1 类; TForm1 继承于 TForm. TForm 是 TForm1 的父类; TForm1 是 TForm 的子类. unit Unit1;interfaceusesWindows, Messages, SysUtils, Variants, Classes, Graphics, Contr…...

mybatis概述及搭建
目录 1.概述 2.mybatis搭建 1.创建一个maven项目,添加mybatis、mysql所依赖的jar 2.创建一个数据库表,及对应的java类 3.创建一个mybatis的核心配置文件,配置数据库连接信息,配置sql映射文件 4.创建sql映射文件,…...

DNDC模型---土壤碳储量、温室气体排放、农田减排、土地变化、气候变化中的应用
由于全球变暖、大气中温室气体浓度逐年增加等问题的出现,“双碳”行动特别是碳中和已经在世界范围形成广泛影响。国家领导人在多次重要会议上讲到,要把“双碳”纳入经济社会发展和生态文明建设整体布局。同时,提到要把减污降碳协同增效作为促…...
Android studio 2022.3.1 鼠标移动时不显示快速文档
在使用技术工具的过程中,我们时常会遇到各种各样的问题和挑战。最近,我升级了我的Android Studio到2022.3.1版本,但是在使用过程中,我碰到了一个让我颇为困扰的问题:在鼠标移动到类名或字段上时,原本应该显…...
五度易链最新“产业大数据服务解决方案”亮相,打造数据引擎,构建智慧产业!
快来五度易链官网 点击网址【http://www.wdsk.net/】 看看我们都发布了哪些新功能!!! 自2015年布局产业大数据服务行业以来,“五度易链”作为全国产业大数据服务行业先锋企业,以“让数据引领决策,以智慧驾驭未来”为愿景,肩负“打…...

简述hive环境搭建
文章目录 部署参数配置hive简单命令 部署 Hive的三种部署模式,主要按Metastore 的运行模式进行区分。 在安装Hive之前,要求先预装JDK 8、Hadoop、MySQL ; 1.下载hive,并解压缩到用户主目录下 tar -xzvf apache-hive-2.3.6-bin.t…...
小米AI音箱联网升级折腾记录(解决配网失败+升级失败等问题)
小米AI音箱(一代)联网升级折腾记录 我折腾了半天终于勉强能进入下载升级包这步,算是成功一半吧… 总结就是,网络信号一定要好,需要不停换网找到兼容的网,还需要仔细配置DNS让音响连的上api.mina.mi.com 推荐…...
tensorRT安装
官方指导文档:Installation Guide :: NVIDIA Deep Learning TensorRT Documentation 适配很重要!!!! 需要cuda, cuDNN, tensorRT三者匹配。我的cuda11.3 所以对应的cuDNN和tensorRT下载的是如下版本: cud…...
电脑重装+提升网速
https://www.douyin.com/user/self?modal_id7147216653720341767&showTabfavorite_collectionhttps://www.douyin.com/user/self?modal_id7147216653720341767&showTabfavorite_collection 零封有哈数的主页 - 抖音 (douyin.com)https://www.douyin.com/user/self?…...
Modelica由入门到精通—为什么要学习Modelica语言
1.为什么要学习Modelica语言 本人正在研究Modelica 多领域统一建模仿真语言,特此做学习入门介绍,希望可以帮助需要的小伙伴。 文章目录 1.为什么要学习Modelica语言一、背景二、系统建模与仿真2.1 系统仿真与系统模型2.2 仿真价值与可靠性 三、物理建模…...

opencv 进阶20-随机森林示例
OpenCV中的随机森林是一种强大的机器学习算法,旨在解决分类和回归问题。随机森林使用多个决策树来进行预测,每个决策树都是由随机选择的样本和特征组成的。在分类问题中,随机森林通过投票来确定最终的类别;在回归问题中࿰…...

为什么92%的开发者查不到真正“实时”新闻?Perplexity底层时间戳校验机制首度公开
更多请点击: https://intelliparadigm.com 第一章:为什么92%的开发者查不到真正“实时”新闻?Perplexity底层时间戳校验机制首度公开 当开发者在凌晨三点搜索“React 19 正式发布”,返回结果却显示“发布时间:2024-03…...
详解)
Redis Sorted Set(有序集合)详解
Redis 里面有一种非常强大的数据结构: Sorted Set(有序集合)简称: ZSet这是 Redis 面试和项目里非常高频的东西。一、什么是 Sorted Set 先记住一句话: Sorted Set 自动排序的 Set它具备: Set 的去重自动排…...

Docker 网络模式详解:bridge、host、overlay 和 macvlan
Docker 网络模式详解:bridge、host、overlay 和 macvlan Docker 提供了多种网络模式,让容器既能灵活通信,又能实现安全隔离。无论是单机多容器应用,还是跨主机的 Swarm 集群,亦或需要直接接入物理网络的 IoT 设备&…...

GPT-4V食物识别实测:准确率真能到87.5%?我们复现了那篇论文的实验
GPT-4V食物识别技术深度测评:从实验室数据到真实场景的挑战 当一张摆盘精致的牛排照片被上传到GPT-4V界面,三秒后系统不仅识别出"肋眼牛排",还精确标注出"约350克"和"780千卡"时,这种看似科幻的场景…...

Fluent模拟火箭发动机喷管?试试用分子动理论定义气体属性,避开数据缺失的坑
火箭发动机喷管仿真中的分子动理论实战:突破高温燃气物性数据困境 当你在Fluent中打开火箭发动机喷管的仿真项目时,面对H2/CO/H2O混合燃气在3000K温度梯度下的物性参数定义,是否曾为找不到可靠数据而抓狂?传统方法需要逐个温度点…...

拆解新客裂变与裂变率:诺云用户可直接套用的获客增长指南
在流量红利消退、公域获客成本高企的当下,“新客裂变”早已成为企业降低获客成本、实现指数级增长的核心抓手,而“裂变率”作为衡量裂变效果的核心指标,直接决定了这场获客动作的成败。今天,我们就聚焦“新客裂变”与“裂变率”这…...
)
「国内直连」Claude Code安装与API配置保姆级教程:从Node.js到调用,小白少踩坑(亲测跑通)
前言 国内用户最头疼的就是海外账号和网络问题,其实找对中转接口就能省不少事。 这篇文章把从Node.js安装到Claude Code启动的全流程整理清楚,用88api做接口中转(国内直连,不用翻墙),尽量让每个步骤都能照…...

终极免费Redis可视化工具:Windows版RedisDesktopManager完全指南
终极免费Redis可视化工具:Windows版RedisDesktopManager完全指南 【免费下载链接】RedisDesktopManager-Windows RedisDesktopManager Windows版本 项目地址: https://gitcode.com/gh_mirrors/re/RedisDesktopManager-Windows 你是否厌倦了在命令行中操作Red…...

告别黑盒调试:手把手教你用ControlDesk的Bus Navigator虚拟通道抓取CAN信号
告别黑盒调试:手把手教你用ControlDesk的Bus Navigator虚拟通道抓取CAN信号 在汽车电子开发中,硬件在环(HIL)测试往往面临一个典型困境:当物理ECU或CAN卡尚未就绪时,如何提前开展总线信号验证?传…...

2025届必备的五大AI辅助论文助手推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 在当下人工智能范畴里身为重要参与者的DeepSeek,它所产出的论文常常展现出严谨的…...