实训笔记8.24
实训笔记8.24
- 8.24笔记
- 一、Sqoop数据迁移工具
- 1.1 Sqoop的基本概念
- 1.2 Sqoop的基本操作
- 1.2.1 命令语法
- 1.2.2 list-databases
- 1.2.3 list-tables
- 1.2.3 eval
- 1.2.4 import
- 1.2.5 export
- 1.2.6 导入
- 二、Flume日志采集工具
- 2.1 数据采集的问题
- 2.2 数据采集一般使用的技术
- 2.3 扩展:通过爬虫技术采集第三方网站数据
- 2.3.1 爬虫目前主要有两种类型的爬虫
- 2.4 Flume日志采集工具概述
- 2.4.1 Flume的组成架构
- 2.4.2 Flume的采集数据的工作流程
- 2.4.3 Flume安装部署:三部曲
8.24笔记
一、Sqoop数据迁移工具
1.1 Sqoop的基本概念
Sqoop数据迁移工具主要作用就是实现将数据在RDBMS(MySQL、SQL Server、Oracle)和Hadoop平台(HDFS、Hive、HBase)之间进行来回的迁移。
Sqoop中,将RDBMS的数据迁移到Hadoop平台我们称为数据导入import,将Hadoop平台的数据迁移到RDBMS中称之为数据导出export。
Sqoop在进行数据的导入和导出时,会使用sqoop提供的命令来进行操作,但是sqoop底层会把命令转换称为MapRecude程序在YARN上运行(sqoop的运行需要Hadoop平台环境,Sqoop也是基于Hadoop平台的软件)
【注意】和sqoop技术一样的还有一个技术叫做DataX,DataX是阿里云提供的一个数据迁移工具,除了可以实现和sqoop一样的功能,同时还提供了一些sqoop无法完成一些数据迁移操作。Datax底层不是基于MapReduce
1.2 Sqoop的基本操作
1.2.1 命令语法
sqoop command params
command:help 、eval、import、export、list-databases、list-tables、version
1.2.2 list-databases
查看RDBMS中有哪些数据库的 sqoop list-databases 参数
| 参数 | 说明 |
|---|---|
| –driver | JDBC的驱动类 |
| –connect | JDBCUrl |
| –username | 数据库的用户名 |
| –password | 数据库的密码 |
1.2.3 list-tables
查询某一个RDBMS数据库下有哪些数据表的 sqoop list-tables 参数
| 参数 | 说明 |
|---|---|
| –driver | JDBC的驱动类 |
| –connect | JDBCUrl |
| –username | 数据库的用户名 |
| –password | 数据库的密码 |
1.2.3 eval
通过sqoop连接RDBMS执行SQL语句 sqoop eval 参数
| 参数 | 说明 |
|---|---|
| –driver | JDBC的驱动类 |
| –connect | JDBCUrl |
| –username | 数据库的用户名 |
| –password | 数据库的密码 |
| –query |-e | sql语句即可 |
1.2.4 import
实现数据导入的,将RDBMS的数据导入到HDFS、Hive、HBase中
-
导入数据到HDFS
参数 说明 –driver JDBC的驱动类 –connect JDBCUrl –username 数据库的用户名 –password 数据库的密码 –table 指定导入RDBMS中哪个数据表的数据 –columns 可以不写,RDBMS数据表的列名的列表,将数据表的指定列导入,如果不写,代表导入table指定的数据表的所有列的数据 –where ‘条件’ 可以不写,根据筛选条件导入RDBMS的–table指定数据表的指定数据,如果不加,那么默认代表导入–table指定的数据表的所有数据 –query ‘dql语句’ 根据查询语句的结果导入指定的数据,–query不能和–table、–columns、–where一起使用,如果–query的DQL语句中出现了where子语句,必须在where子语句中添加一个 and $CONDITIONS–target-dir 导入到HDFS上的目录路径 –delete-target-dir 导入数据到HDFS上时,路径如果提前存在会报错,命令代表删除存在的–target-dir目录 –as-textfile|–as-sequencefile… 导入数据在HDFS上存储的文件格式 –num-mappers | -m 导入程序在底层转换称为多个map task任务执行 –fields-terminated-by 指定将数据导入到HDFS的文件中时,列和列的分隔符,默认一种特殊字符 –lines-terminated-by 指定将数据导入到HDFS的文件中时,行和行的分隔符,默认就是换行符 –null-string 如果导入的MySQL数据表的某一个字符串类型的列的值为null,那么我们在HDFS的文件中使用什么字符替换null值 –null-non-string 如果导入的MySQL数据表的某一个非字符串类型的列的值为null,那么我们在HDFS的文件中使用什么字符替换null值 -
导入数据到Hive
-
先把数据导入到HDFS
-
再把导入到HDFS上的数据装载到Hive数据表中
-
参数列表
参数 说明 –driver JDBC的驱动类 –connect JDBCUrl –username 数据库的用户名 –password 数据库的密码 –table 指定导入RDBMS中哪个数据表的数据 –columns 可以不写,RDBMS数据表的列名的列表,将数据表的指定列导入,如果不写,代表导入 --table指定的数据表的所有列的数据 –where ‘条件’ 可以不写,根据筛选条件导入RDBMS的–table指定数据表的指定数据,如果不加,那么默认代表导入–table指定的数据表的所有数据 –query ‘dql语句’ 根据查询语句的结果导入指定的数据,–query不能和–table、–columns、–where一起使用,如果–query的DQL语句中出现了where子语句,必须在where子语句中添加一个 and $CONDITIONS–hive-import 执行Hive的导入操作 –hive-database 指定导入到Hive的哪个数据库 –hive-table 指定导入到Hive的哪个数据表,数据表可以不用提前存在 –create-hive-table 如果指定的hive数据表不存在,通过该选项自动创建表,但是如果Hive数据表存在的,那么该参数不需要添加 –num-mappers | -m 导入程序在底层转换称为多个map task任务执行 –fields-terminated-by 指定将数据导入到HDFS的文件中时,列和列的分隔符,默认一种特殊字符,同时自动创建Hive数据表时,表的列的分隔符 –lines-terminated-by 指定将数据导入到HDFS的文件中时,行和行的分隔符,默认就是换行符 一般是不使用这个参数的,就算我们设置了也不生效,除非我们加上一些特殊参数 –null-string 如果导入的MySQL数据表的某一个字符串类型的列的值为null,那么我们在HDFS的文件中使用什么字符替换null值 –null-non-string 如果导入的MySQL数据表的某一个非字符串类型的列的值为null,那么我们在HDFS的文件中使用什么字符替换null值 -
注意事项
- 将RDBMS的数据导入到Hive时,因为先把数据导入到HDFS,再把数据load装载到Hive中,因此我们要求导入到HDFS上的文件中列的分隔符必须和Hive数据表的列的分隔符保持一致,如果不一致数据无法导入成功。
- 如果Hive数据表不存在,那么再导入的时候可以指定-
--create-hive-table创建数据表,创建的数据表的列的分隔符和–fields-terminated-by设置的HDFS上文件的列的分隔符保持一致的
-
-
全量导入和增量导入
把RDBMS的数据导入到HDFS或者Hive都是有两种方式:全量导入、增量导入 全量导入指的是将RDBMS表的所有数据导入到HDFS或者Hive 增量导入指的是只将新增的RDBMS表的所有数据导入到HDFS或者Hive中默认情况下,HDFS导入数据时会覆盖原有的数据,hive导入数据时,会把数据重复性的在表中添加一份。
必须考虑全量导入和增量导入问题。只学习Hive的
-
Hive的全量导入
--hive-overwrite参数,将RDBMS表中的所有数据(–table 如果加了–query --columns,就不是全量的问题)添加到Hive对应的数据表,而且覆盖添加。一般使用在第一次将RDBMS的数据导入到Hive中,如果第一次导入不需要–hive-overwrite选项 如果不是第一次导入,还想全量导入,那么必须加–hive-overwrite选项
-
Hive的增量导入
sqoop的增量导入有两种方式:
append lastmodified,其中Hive的增量导入只支持append方式,HDFS增量导入支持lastmodified方式append增量导入需要指定RDBMS中一个可以自增或者是数字依次变大的一个列,同时还需要指定上一次导入的时候值的大小
--check-column RDBMS对应的列--incremental append--last-value num
-
-
【导入数据时间字段的问题】
数据导入之后,RDBMS中的时间和Hive中时间不一致,主要由于时区的问题导致的,RDBMS使用的时区和导入数据时指定的时区参数不是同一个时区导致的问题。
只需要保证RDBMS的时区和导入参数设置的时区serverTimezone保持一致即可。
RDBMS的时区:
select @@global.time_zone默认情况下,只要我们在中国,没有改过数据库和系统的时区,数据库和系统时区默认是+0800,因此
serverTimezone=Asia/Shanghai
1.2.5 export
将Hadoop平台的数据导出到RDBMS中,导出比导入简单。导出数据时,因为Hive、HBase存储的数据都在HDFS上,因此导出只需要学习如何将HDFS上的数据导出到RDBMS即可。
【导出的注意事项】:RDBMS中的数据表必须提前存在,如果不存在,会报错
导出参数
| 类型 | 参数 | 说明 |
|---|---|---|
| 导出时和RDBMS相关的参数 | –driver | JDBC的驱动类 |
| –connect | JDBCUrl | |
| –username | 数据库的用户名 | |
| –password | 数据库的密码 | |
| –table | 指定导入RDBMS中哪个数据表的数据 | |
| –columns <col,col,col…> | 代表的rdbms的列名,列名必须和文件中列的顺序保持一致,防止数据串列 | |
| 导出HDFS的参数 | –export-dir | 导出的HDFS哪个目录下的文件数据 |
| –num-mappers | -m | 将导出命令翻译称为n个map task任务 | |
| –input-fields-terminated-by | 很重要,指定HDFS上文件中列和列的分隔符的 | |
| –input-lines-terminated-by | 指定HDFS上文件行和行的分割符 行的分隔符\n | |
| –update-mode | 取值allowinsert和updateonly,导出数据的两种模式 allowinsert 更新已经导出的数据,同时追加新的数据 对mysql数据库目前不支持的 updateonly 只更新以前导出的数据,新的数据不会导出 | |
| –update-key | –update-mode如果想实现它的功能,必须和–update-key结合使用,而且–update-day最好指定一个RDBMS的主键字段,否则update-mode的效果会出现混乱 |
【注意】如果没有指定update-mode 那么默认是追加的形式导出(会出数据重复)
如果我们想要导出数据到MySQL,而且还不想让数据重复,可以先使用sqoop eval 操作执行清空目标表数据的命令,清空成功以后再导出数据。
1.2.6 导入
导入一般是我们需要对RDBMS的数据进行大数据处理分析时,我们把RDBMS的数据通过import导入到HDFS或者Hive,导出之后我们处理完成,得到结果数据表,然后把结果数据表通过export导出到RDBMS中,用于后期的数据可视化展示。
二、Flume日志采集工具
2.1 数据采集的问题
数据采集一般指的是将数据采集到大数据环境下进行持久化、海量化的保存,目的主要是为了我们后期的大数据处理(数据统计分析、数据挖掘等等)沉底数据基础。
不同的来源的数据我们一般有不同的数据采集方式
- 数据来源于我们的RDBMS关系型数据库:Sqoop数据迁移工具实现数据的采集
- 数据来源于我们系统运行产生的日志文件:日志文件记录的数据量特别庞大,但是日志文件不属于大数据存储系统中东西,因此日志文件记录不了海量的数据,日志文件都会有一个定期清理规则。采集日志文件数据到大数据环境中。 一般采集日志文件数据到大数据环境使用的就是Flume技术
- 数据来源于其他网站:开发一个电影网站,电影网站应该具备哪些功能,哪些类型的电影能受用户的欢迎。分析竞品数据,这种情况竟品数据都是人家别人家网站的数据,但是我们需要分析,但是人家不给你数据,通过爬虫获取数据(一不留神就犯法)。
- 数据来源于各种传感器设备:不需要我们管
- 第三方提供、购买的第三方数据、开源数据集平台提供的(阿里云的天池数据集、kaggle数据集平台、飞浆数据集平台、各个地区的政府公开数据集平台)
2.2 数据采集一般使用的技术
sqoop技术:采集RDBMS的数据到大数据环境中
Flume技术:采集系统/网站产生的日志文件数据、端口数据等等到大数据环境中
爬虫技术:采集第三方的数据,爬虫一般是把采集的数据放到一个文件或者RDBMS数据库当中
2.3 扩展:通过爬虫技术采集第三方网站数据
爬虫技术就是通过读取网页/网站的界面结构,获取网页中嵌套的数据
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9oPvCpo4-1692874175452)(./8.24/96623B46-FF42-4d5d-8F37-80A1CD28B94A.png)]](https://img-blog.csdnimg.cn/aa399c4137a7466b9fb26f749fd7f21d.png)
2.3.1 爬虫目前主要有两种类型的爬虫
- 通过代码进行爬虫 python写的
- 优点:在于可以定制化爬虫内容
- 缺点:
- 编写代码,代码是非常复杂
- 很多网站做了反爬虫校验,可能写了代码也无法爬取数据
- 通过可视化爬虫工具爬虫
- 优点:不需要写一行代码,只需要点点点就可以定制化数据爬虫,反爬虫问题不用担心
- 缺点:
- 无法随心所欲爬取数据
- 可能会收费
- 八爪鱼爬虫工具、集搜客爬虫工具…
2.4 Flume日志采集工具概述
Flume也是Apache开源的顶尖项目,专门用来采集海量的日志数据到指定的目的地。
Flume采集数据采用一种流式架构思想,只要数据源有数据,就可以源源不断的采集数据源的数据到目的地
2.4.1 Flume的组成架构
Flume之所以可以实现采集不同数据源(不仅仅只包含日志文件数据)到指定的目的地,源于Flume的设计机构。
- Agent:一个Flume采集数据的进程,一个Flume软件可以启动多个Flume采集进程Agent
- Source:Flume的一个数据源组件,是Flume专门用来连接数据源的组件,一个Flume采集进程Agent中,Source组件可以有一个也可以有多个
- Channel:Flume中一个类似于缓存池的组件,缓存池的主要作用就是用来临时保存source数据源采集的数据,目的地需要数据,从缓冲池中获取,防止数据源数据产生过快,而目的地消费数据过慢,导致程序崩溃的问题。一个Agent中,可以存在多个Channel组件
- Sink:Flume中一个目的地(下沉地)组件,是Flume专门用来连接目的地的组件,一个Flume进程中,sink组件也可以有多个,但是一个sink只能从一个channel中获取数据。不能一个sink从不同channel拉取数据
- event:Flume中数据传输单位。Flume采集数据源的数据时,会把数据源的数据封装为一个个的event。
脚本文件xxx.conf:需要用户自己编写的,Flume采集数据时,数据源和目的地有很多种,因此如果我们采集数据时,我们必须自定义一个脚本文件,在脚本文件中需要定义采集的数据源的类型、channel管道的类型、sink的目的地的类型、以及source channel sink三者之间的关系。脚本文件定义成功之后,我们才能去根据脚本文件启动Flume采集进程Agent
【注意】一个source只能连接一个数据源,一个sink只能连接一个目的地
2.4.2 Flume的采集数据的工作流程
首先我们先编写xx.conf脚本文件定义我们的采集的数据源、目的地、管道的类型,定义成功之后我们根据脚本启动Flume采集进程Agent。一旦当Flume采集进程启动成功,source就会去监听数据源的数据,一旦当数据源有数据产生,那么source组件会把数据源的数据封装为一个个的event,然后source把event数据单位传输到channel管道中缓存,然后sink组件会从channel中拉取指定个数的event,将event中数据发送给sink连接的目的地。
2.4.3 Flume安装部署:三部曲
- 上传解压
- 配置环境变量
- 修改配置文件
- conf/flume-env.sh
- bin/flume-ng flume运行需要Java环境,文件中需要指定Flume运行需要的内存容量
相关文章:
实训笔记8.24
实训笔记8.24 8.24笔记一、Sqoop数据迁移工具1.1 Sqoop的基本概念1.2 Sqoop的基本操作1.2.1 命令语法1.2.2 list-databases1.2.3 list-tables1.2.3 eval1.2.4 import1.2.5 export1.2.6 导入 二、Flume日志采集工具2.1 数据采集的问题2.2 数据采集一般使用的技术2.3 扩展&#x…...
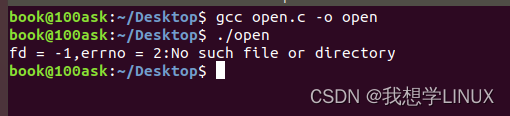
Linux下的系统编程——系统调用(五)
前言: 由操作系统实现并提供给外部应用程序的编程接口。(Application Programming Interface,API)。系统调用就是应用程序同系统之间数据交互的桥梁。 open/close函数 1.open函数: (1)int open(char *pathname, int flags) …...

动物体外受精手术VR模拟仿真培训系统保证学生及标本的安全
奶牛是养殖业主要的资源,因此保证奶牛的健康对养殖业的成功和可持续发展具有重要已用,奶牛有一些常见易发病,一旦处理不当,对奶牛业都会造成较大的经济损失,传统的奶牛手术培训实操难度大、风险高且花费大,…...
微信小程序|步骤条
步骤条是现代用户界面设计中常见的元素之一,它能够引导用户按照预定顺序完成一系列任务或步骤。在小程序中,实现步骤条可以为用户提供更好的导航和引导,使用户体验更加流畅和直观。本文将介绍如何在小程序中实现步骤条,并逐步展示实现的过程和关键技巧 目录 步骤条的作用及…...

如何才能设计出“好的”测试用例?
软件测试用例的设计质量直接影响到测试的完整性、有效性以及自动化测试的实施效果,是软件测试成功的重要保证,良好的软件测试用例对于提高测试的有效性和效率至关重要。那大家知道好的测试用例该怎么写吗?应该从哪几个方面来撰写呢࿱…...
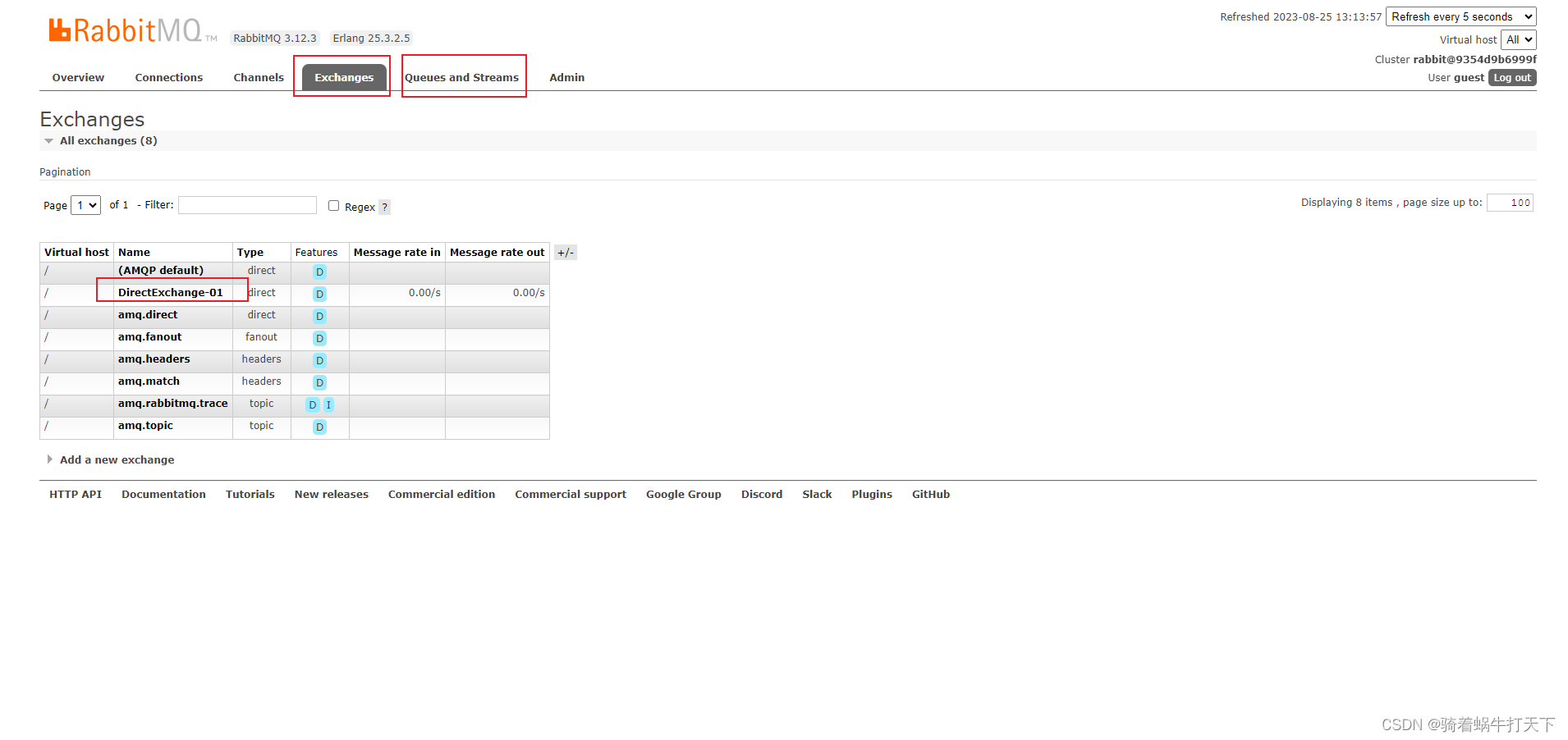
DirectExchange直连交换机
目录 一、简介 二、使用步骤 三、demo 父pom文件 pom文件 配置文件 config 消费者 生产者 测试 一、简介 直连型交换机,根据消息携带的路由键将消息投递给对应队列。 大致流程,有一个队列绑定到一个直连交换机上,同时赋予一个路由…...

Shell 编程:探索 Shell 的基本概念与用法
目录 Shell 简介 Shell 脚本 Shell 脚本运行 Shell 变量 1、创建变量和赋值 2、引用变量 3、修改变量的值 4、只读变量 5、删除变量 6、环境变量 Shell 字符串操作 1、拼接字符串 2、字符串长度 3、字符串截取 Shell 数组 1、创建数组 2、访问数组元素 shell …...
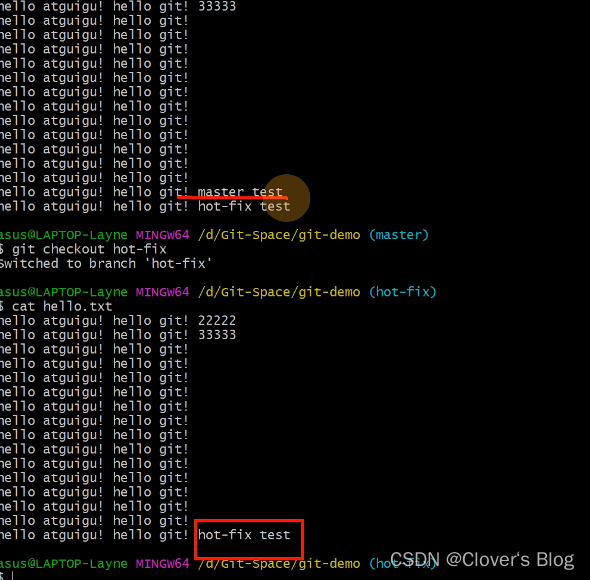
【Git分支操作---讲解二】
Git分支操作---讲解二 查看分支创建分支切换分支修改分支切换分支合并分支合并分支【冲突】(只会修改主分支不会修改其他分支)什么时候会有冲突? 查看分支 创建分支 切换分支 修改分支 切换分支 合并分支 合并分支【冲突】(只会修改主分支不会修改其他分支) 什么时…...

vue2+qrcodejs2+clipboard——实现二维码展示+下载+复制到剪切板——基础积累
最近在写后台管理系统时,遇到一个需求就是要实现二维码的展示下载复制到剪切板。 效果图如下: 1.二维码展示下载功能——qrcodejs20.0.2 我是安装的qrcodejs20.0.2,指定了具体的版本号,也可以安装默认的当前稳定版本࿰…...

【PHP】echo 输出数组报Array to string conversion解决办法
代码: <?PHP echo "Hello World!";$demoName array("kexuexiong","xiong");echo "<pre>";var_dump($demoName);echo $demoName; print_r($demoName);echo "</pre>"; ?>输出结果࿱…...
)
Arduino驱动MiCS-4514气体传感器(气体传感器篇)
目录 1、传感器特性 2、控制器和传感器连线图 3、驱动程序...

marked在vue项目中改变超链接跳转方式和图片放大预览
marked在vue项目中改变超链接跳转方式和图片放大预览 这里我是另起一个js文件对marked的配置做了修改,参考如下 import marked from marked let renderer new marked.Renderer() const linkRenderer renderer.link const imgRenderer renderer.image // 超链接…...
leetcode485. 最大连续 1 的个数
思路:【双指针】 left左边界,right往右跑遇到0,则计算该长度。并更新cnt(最大连续1个数)。 class Solution { public:int findMaxConsecutiveOnes(vector<int>& nums) {int left 0, right 0;int cnt 0;…...

linux 源代码编译
源代码编译 有时候会在linux上下载源码包,然后进行编译成可执行的文件,这个过程需要经过configure、make、make install、make clean四个步骤 configure 为这个程序在当前的操作系统环境下选择合适的编译器和环境参数来编译该代码 make 对程序代码进行编…...

C语言日常刷题 1
文章目录 题目答案与解析1234.5.6. 题目 1、执行下面程序,正确的输出是( ) int x5,y7; void swap() { int z; zx; xy; yz; } int main() { int x3,y8; swap(); printf(“%d,%d\n”,x, y); return 0; } A: 5,7 B: 7,5 C: 3,8 D: 8…...
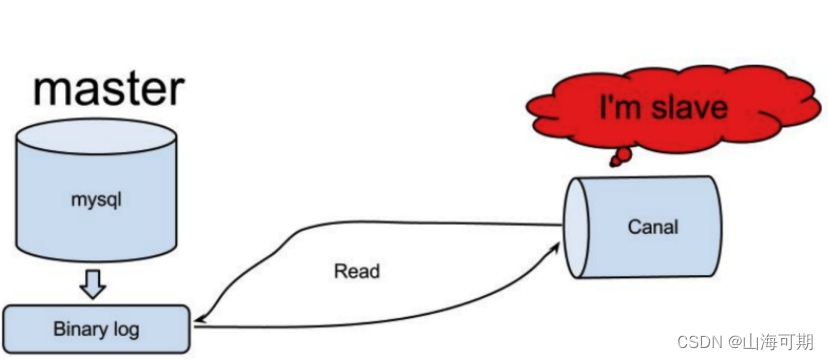
es和数据库同步方案
5.5 课程信息索引同步 5.5.1 技术方案 通过向索引中添加课程信息最终实现了课程的搜索,我们发现课程信息是先保存在关系数据库中,而后再写入索引,这个过程是将关系数据中的数据同步到elasticsearch索引中的过程,可以简单成为索引…...

手机NFC功能是什么?
手机NFC功能是什么? 随着智能手机的不断发展和普及,NFC(近场通讯)功能已经成为了我们生活中不可或缺的一部分。NFC是一种无线通信技术,可以让手机和其他设备之间进行快速的数据交换和支付操作。那么,手机NFC功能是什么࿱…...
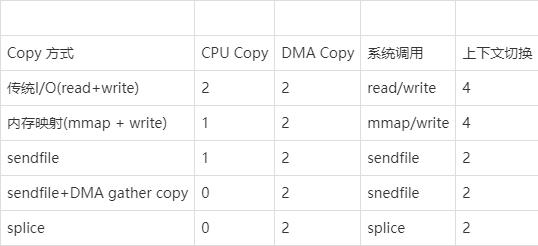
零拷贝技术详解
当涉及到网络编程和IO操作时,数据拷贝是一个常见的性能瓶颈。传统的数据拷贝过程中,数据需要从内核缓冲区复制到用户空间缓冲区,然后再从用户空间缓冲区复制到内核缓冲区,这个过程会耗费大量的CPU时间和内存带宽,降低系…...

【VS Code插件开发】消息通信(四)
🐱 个人主页:不叫猫先生,公众号:前端舵手 🙋♂️ 作者简介:前端领域优质作者、阿里云专家博主,共同学习共同进步,一起加油呀! 📢 资料领取:前端…...

开源硬件:下一个技术革命?
🌷🍁 博主猫头虎 带您 Go to New World.✨🍁 🦄 博客首页——猫头虎的博客🎐 🐳《面试题大全专栏》 文章图文并茂🦕生动形象🦖简单易学!欢迎大家来踩踩~🌺 &a…...

CircuitJS1:如何在浏览器中免费创建电子电路仿真
CircuitJS1:如何在浏览器中免费创建电子电路仿真 【免费下载链接】circuitjs1 Electronic Circuit Simulator in the Browser 项目地址: https://gitcode.com/gh_mirrors/ci/circuitjs1 CircuitJS1是一款强大的开源电子电路仿真工具,让你直接在浏…...

现代工业的命脉——稀土
你可能从未见过稀土,但它们藏在你每天离不开的手机、电脑、汽车甚至节能灯泡里。没有稀土,科技产品的性能会瞬间退回几十年前。有人把它们比作“工业维生素”——用量极少,作用却无可替代。稀土不是土,是一组金属元素先说清楚一个…...

避开HAL库:STM32F103寄存器级PWM移相全桥配置避坑指南
STM32F103寄存器级PWM移相全桥实战:从原理到避坑指南 在嵌入式开发领域,许多工程师习惯使用HAL库或标准库进行STM32开发,这确实能提高开发效率。但当项目对时序精度、资源占用或性能有极致要求时,直接操作寄存器往往能带来更优的效…...

Windows 11系统优化神器:Win11Debloat一站式去广告与性能提升指南
Windows 11系统优化神器:Win11Debloat一站式去广告与性能提升指南 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declu…...

【免费下载】 Maven 3.8.5 压缩包下载【maven下载安装与配置】
Maven 3.8.5 压缩包下载 简介 本仓库提供 Maven 3.8.5 版本的压缩包下载。Maven 是一个强大的项目管理和构建自动化工具,广泛应用于 Java 项目的开发中。 资源文件 文件名: maven3.8.5压缩包描述: Maven 3.8.5 版本的压缩包 下载链接 请点击以下链接下载 Mave…...

【Android】CloneTTS最强朗读听书引擎-可克隆一切音色
【Android】CloneTTS最强朗读听书引擎-可克隆一切音色 链接:https://pan.xunlei.com/s/VOsu4mh3O_d7zjeERkKPfcG4A1?pwddi3y# CloneTTS 是一款运行在安卓系统本地的文字转语音(TTS)原生引擎,允许用户离线克隆所需的声音并直接使用该声音来朗读书籍或长…...

保姆级教程:在华大HC32L136上驱动SPI屏,用DMA发送提升刷屏效率
华大HC32L136单片机SPI屏DMA驱动实战指南 在物联网设备和智能硬件开发中,流畅的图形界面往往能大幅提升用户体验。而实现这一目标的关键,在于高效稳定的显示驱动设计。本文将深入探讨如何利用华大半导体HC32L136单片机的SPI接口与DMA控制器,构…...

Hitboxer:免费解决游戏按键冲突的专业SOCD重映射工具
Hitboxer:免费解决游戏按键冲突的专业SOCD重映射工具 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 你是否曾在激烈的格斗游戏中,因为同时按下左右方向键而无法准确释放必杀技ÿ…...

终极解决方案:NoSleep防休眠工具让你的Windows永不休眠
终极解决方案:NoSleep防休眠工具让你的Windows永不休眠 【免费下载链接】NoSleep Lightweight Windows utility to prevent screen locking 项目地址: https://gitcode.com/gh_mirrors/nos/NoSleep 你是否曾经遇到过这样的困扰?深夜下载大型文件到…...

SteamVR Unity插件实战:解决VR开发中的三大核心挑战
SteamVR Unity插件实战:解决VR开发中的三大核心挑战 【免费下载链接】steamvr_unity_plugin SteamVR Unity Plugin - Documentation at: https://valvesoftware.github.io/steamvr_unity_plugin/ 项目地址: https://gitcode.com/gh_mirrors/st/steamvr_unity_plug…...