36k字从Attention讲解Transformer及其在Vision中的应用(pytorch版)
文章目录
- 0.卷积操作
- 1.注意力
- 1.1 注意力概述(Attention)
- 1.1.1 Encoder-Decoder
- 1.1.2 查询、键和值
- 1.1.3 注意力汇聚: Nadaraya-Watson 核回归
- 1.2 注意力评分函数
- 1.2.1 加性注意力
- 1.2.2 缩放点积注意力
- 1.3 自注意力(Self-Attention)
- 1.3.1 自注意力的定义和计算
- 1.3.2 自注意力的应用
- 1.3.3 Self-Attention 与 CNN 与 RNN
- 1.4 多头自注意力 (Multihead Attention)
- 2. Transformer
- 2.1 Transformer的整体结构
- 2.2 Transformer的输入
- 2.2.1 单词Embedding
- 2.2.2 位置Encoding
- 2.3 Transformer的Encoder-Decoder
- 2.3.1 Encoder block
- 2.3.2 Decoder block
- 2.4 Transformer的输出
- 2.5 Transformer的训练过程和损失函数
- 2.5.1 训练过程
- 2.5.2 损失函数
- 2.6 Transformer的代码实现
- 2.6.1 基于位置的前馈神经网络
- 2.6.2 残差连接和层规范化
- 2.6.3 编码器
- 2.6.4 解码器
- 2.6.5 训练
- 3. pytorch中的注意力机制类
- 3.1 torch.nn.MultiheadAttention
- 4. Transformer 在计算机视觉领域的应用
- 4.1 Vision Transformer
- 4.1.1 ViT的总体结构
- 4.1.2 Embedding层结构详解
- 4.1.3 Transformer Encoder详解
- 4.1.4 MLP Head详解
- 4.2 Swin Transformer
- 4.2.1 网络的整体框架
- 4.2.2 Patch Mering
- 4.2.3 W-MSA
- 4.2.4 SW-MSA
- 参考文献
0.卷积操作
深度学习中的卷积操作:https://blog.csdn.net/zyw2002/article/details/128306697
1.注意力
1.1 注意力概述(Attention)
1.1.1 Encoder-Decoder
Encoder-Decoder框架顾名思义也就是编码-解码框架,在NLP中Encoder-Decoder框架主要被用来处理序列-序列问题。也就是输入一个序列,生成一个序列的问题。这两个序列可以分别是任意长度。
具体到NLP中的任务比如:
- 文本摘要,输入一篇文章(序列数据),生成文章的摘要(序列数据)
- 文本翻译,输入一句或一篇英文(序列数据),生成翻译后的中文(序列数据)
- 问答系统,输入一个question(序列数据),生成一个answer(序列数据)
基于Encoder-Decoder框架具体使用什么模型实现,用的较多的应该就是seq2seq模型和Transformer了。
Encoder-Decoder中的输入和输出
输入
1)输入是一个向量
2)输入是一组向量
输出
1)每一个向量对应一个输出
2)整个序列只输出一个标签
3)模型自己决定输出序列的长度
Encoder-Decoder中的结构原理
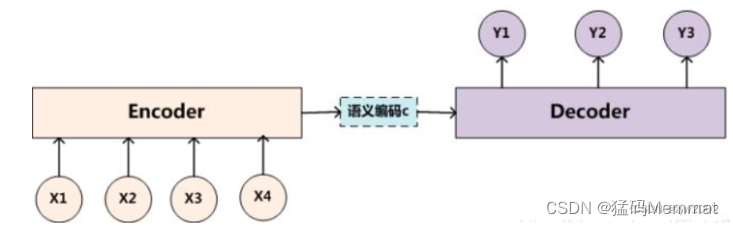
Encoder:编码器,对于输入的序列<x1,x2,x3…xn>进行编码,使其转化为一个语义编码C,这个C中就储存了序列<x1,x2,x3…xn>的信息。
Encoder 是怎么编码的呢?
编码方式有很多种,在文本处理领域主要有RNN/LSTM/GRU/BiRNN/BiLSTM/BiGRU,可以依照自己的喜好来选择编码方式
以RNN为例来具体说明一下:
以上图为例,输入<x1,x2,x3,x4>,通过RNN生成隐藏层的状态值<h1,h2,h3,h4>,如何确定语义编码C呢?最简单的办法直接用最后时刻输出的ht作为C的状态值,这里也就是可以用h4直接作为语义编码C的值,也可以将所有时刻的隐藏层的值进行汇总,然后生成语义编码C的值,这里就是C=q(h1,h2,h3,h4),q是非线性激活函数。
得到了语义编码C之后,接下来就是要在Decoder中对语义编码C进行解码了。
Decoder:解码器,根据输入的语义编码C,然后将其解码成序列数据,解码方式也可以采用RNN/LSTM/GRU/BiRNN/BiLSTM/BiGRU。
Decoder和Encoder的编码解码方式可以任意组合。
Decoder 是怎么解码的呢?
基于
seq2seq模型有两种解码方式:
解码方法1:《Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation》
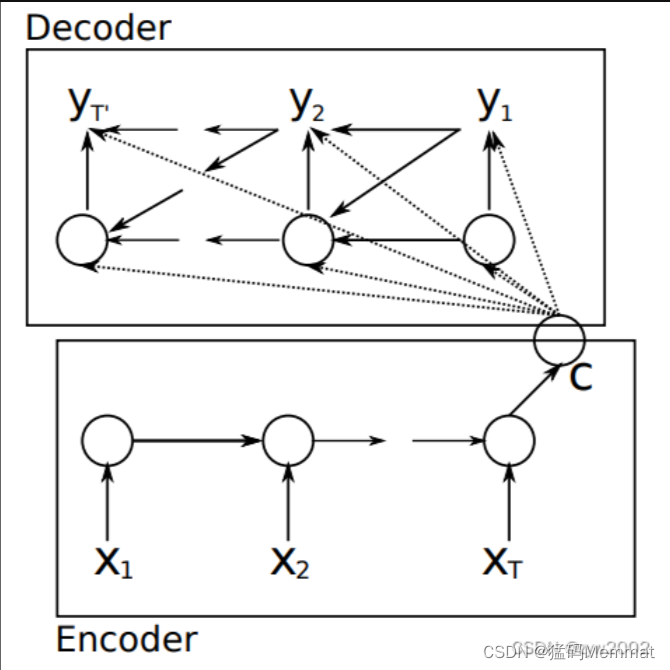
该方法指出,因为语义编码C包含了整个输入序列的信息,所以在解码的每一步都引入C。文中Ecoder-Decoder均是使用RNN,在计算每一时刻的输出yt时,都应该输入语义编码C,即
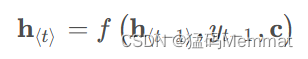
类似的,下一个符号的条件分布是:
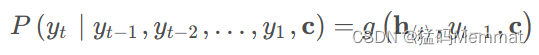
其中 h t h_t ht为当前t时刻的隐藏层的值, y t − 1 y_{t-1} yt−1为上一时刻的预测输出,作为t时刻的输入,每一时刻的语义编码C是相同地。
解码方法2:《Sequence to Sequence Learning with Neural Networks》
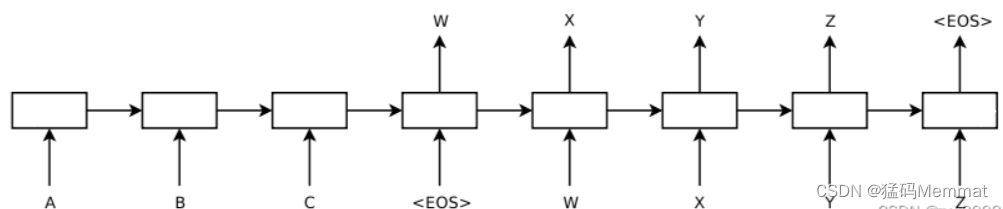
这个编码方式相对简单,只在Decoder的初始输入引入语义编码C,将语义编码C作为隐藏层状态值 h 0 h_0 h0的初始值,
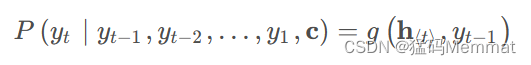
如上图,该模型读取一个输入句子“ABC”,并产生“WXYZ”作为输出句子。模型在输出句尾标记后停止进行预测。注意,LSTM读取反向输入句子,因为这样做会在数据中引入许多短期依赖关系
基于
seq2seq模型有两种解码方式都不太好(两种解码方式都只采用了一个语义编码C),而基于attention模型的编码方式中采用了多个C
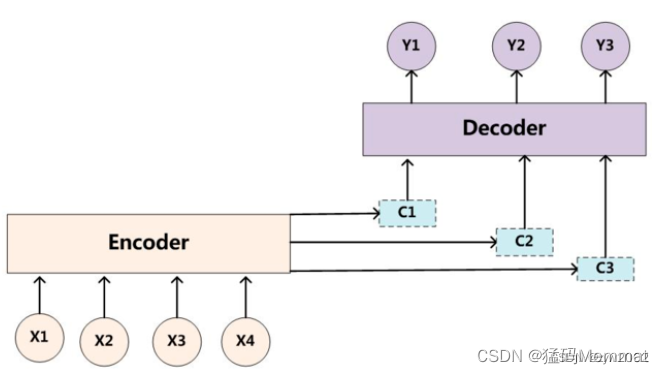
上图就是引入了Attention 机制的Encoder-Decoder框架。咱们一眼就能看出上图不再只有一个单一的语义编码C,而是有多个C1,C2,C3这样的编码。当我们在预测Y1时,可能Y1的注意力是放在C1上,那咱们就用C1作为语义编码,当预测Y2时,Y2的注意力集中在C2上,那咱们就用C2作为语义编码,以此类推,就模拟了人类的注意力机制。
以机器翻译例子"Tom chase Jerry" - "汤姆追逐杰瑞"来说明注意力机制:
当我们在翻译"杰瑞"的时候,为了体现出输入序列中英文单词对于翻译当前中文单词不同的影响程度,比如给出类似下面一个概率分布值:
(Tom,0.3)(Chase,0.2)(Jerry,0.5)
每个英文单词的概率代表了翻译当前单词“杰瑞”时,注意力分配模型分配给不同英文单词的注意力大小。这对于正确翻译目标语单词肯定是有帮助的,因为引入了新的信息。同理,目标句子中的每个单词都应该学会其对应的源语句子中单词的注意力分配概率信息。这意味着在生成每个单词Yi的时候,原先都是相同的中间语义表示C会替换成根据当前生成单词而不断变化的Ci。理解AM模型的关键就是这里,即由固定的中间语义表示C换成了根据当前输出单词来调整成加入注意力模型的变化的Ci。
每个Ci 对应这不同源语句子单词的注意力分配概率,比如对于上面的英汉翻译来说,对应的信息可能如下:
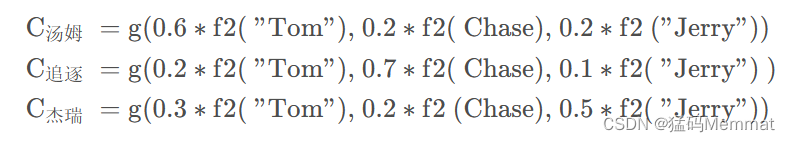
f2(“Tom”),f2(“Chase”),f2(“Jerry”)就是对应的隐藏层的值h(“Tom”),h(“Chase”),h(“Jerry”)。g函数就是加权求和。αi表示权值分布。因此Ci的公式就可以写成:
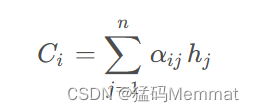
怎么知道attention模型所需要的输入句子单词注意力分配概率分布值 a i j a_{ij} aij呢? 我们可以通过下文介绍的注意力评分函数求得
1.1.2 查询、键和值
下面来看看如何通过自主性的与非自主性的注意力提示, 用神经网络来设计注意力机制的框架。
首先,考虑一个相对简单的状况, 即只使用非自主性提示。 要想将选择偏向于感官输入, 则可以简单地使用参数化的全连接层, 甚至是非参数化的最大汇聚层或平均汇聚层。
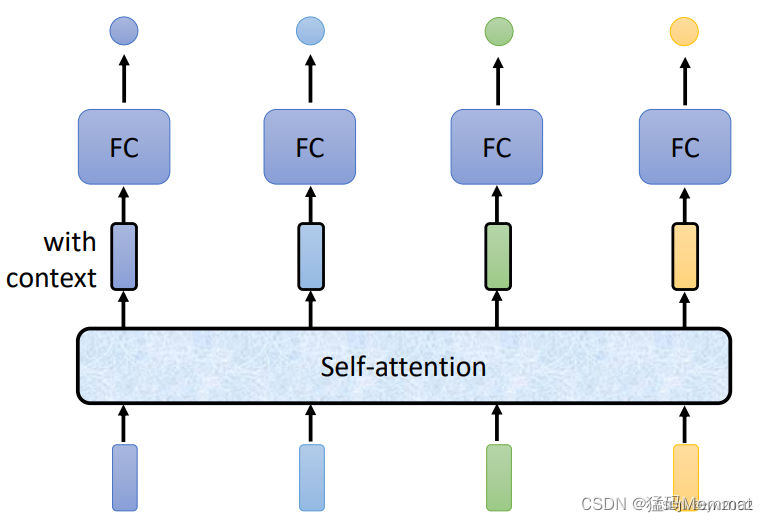
在注意力机制的背景下,自主性提示被称为查询(query)。 给定任何查询,注意力机制通过注意力汇聚(attention pooling)将选择引导至感官输入(sensory inputs,例如中间特征表示)。在注意力机制中,这些感官输入被称为值(value)。 更通俗的解释,每个值都与一个键(key)配对, 这可以想象为感官输入的非自主提示。
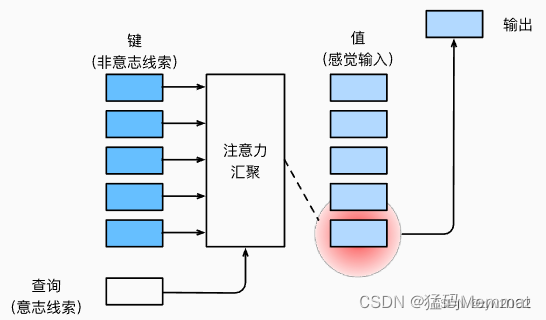
如上图: 注意力机制通过注意力汇聚(注意力的分配方法)将查询(自主性提示)和键(非自主性提示)结合在一起,实现对值(感官输入)的选择倾向。
1.1.3 注意力汇聚: Nadaraya-Watson 核回归
上图中的注意力汇聚是怎么实现的呢?
可通过Nadaraya-Watson核回归模型来了解常见的注意力汇聚模型(平均汇聚、非参数注意力汇聚、带参数注意力汇聚)。
为什么要在机器学习中引入注意力机制呢?
在全连接层,FC只能考虑相邻的几个数据,但是无法考虑到整个序列。
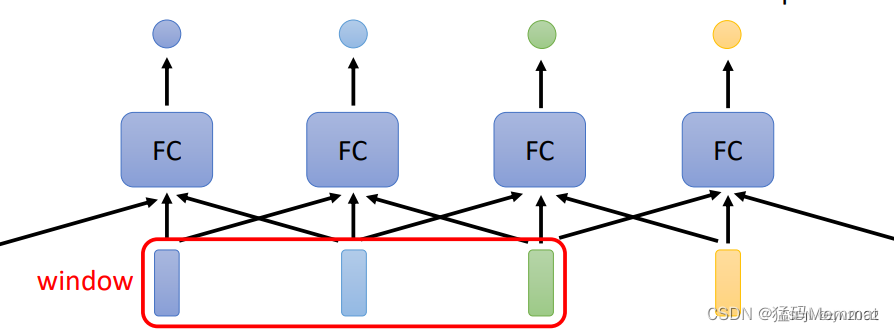
注意力机制(self-attention)可以考虑到整个序列的信息。因此,输出的向量带有全局的上下文信息。
1.2 注意力评分函数
接下来,我们讲解如何通过注意力评分函数来分配注意力。
我们使用高斯核来对查询(query)和键(key)之间的关系建模。 我们可以将高斯核指数部分视为注意力评分函数(attention scoring function), 简称评分函数(scoring function),然后把这个函数的输出结果输入到softmax函数中进行运算。 通过上述步骤,我们将得到与键对应的值的概率分布(即注意力权重)。最后,注意力汇聚的输出就是基于这些注意力权重的值的加权和。
下图说明了如何将注意力汇聚的输出计算成为值的加权和, 其中a表示注意力评分函数。 由于注意力权重是概率分布, 因此加权和其本质上是加权平均值。
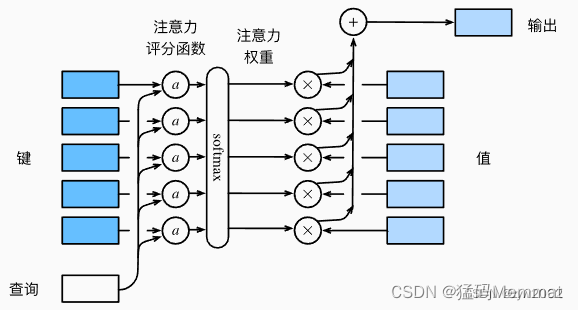

正如我们所看到的,选择不同的注意力评分函数a会导致不同的注意力汇聚操作。 在本节中,我们将介绍两个流行的评分函数(加性注意力、缩放点积注意力),稍后将用他们来实现更复杂的注意力机制。
掩蔽softmax操作
掩蔽softmax操作, 是为实现下文的评分函数做铺垫。
正如上面提到的,softmax操作用于输出一个概率分布作为注意力权重。 在某些情况下,并非所有的值都应该被纳入到注意力汇聚中。 例如,为了高效处理小批量数据集, 某些文本序列被填充了没有意义的特殊词元。 为了仅将有意义的词元作为值来获取注意力汇聚, 我们可以指定一个有效序列长度(即词元的个数), 以便在计算softmax时过滤掉超出指定范围的位置。 通过这种方式,我们可以在下面的masked_softmax函数中 实现这样的掩蔽softmax操作(masked softmax operation), 其中任何超出有效长度的位置都被掩蔽并置为0。
#@save
def masked_softmax(X, valid_lens):"""通过在最后一个轴上掩蔽元素来执行softmax操作"""# X:3D张量,valid_lens:1D或2D张量if valid_lens is None:return nn.functional.softmax(X, dim=-1)else:shape = X.shapeif valid_lens.dim() == 1:valid_lens = torch.repeat_interleave(valid_lens, shape[1])else:valid_lens = valid_lens.reshape(-1)# 最后一轴上被掩蔽的元素使用一个非常大的负值替换,从而其softmax输出为0X = d2l.sequence_mask(X.reshape(-1, shape[-1]), valid_lens,value=-1e6)return nn.functional.softmax(X.reshape(shape), dim=-1)
为了演示此函数是如何工作的, 考虑由两个2×4矩阵表示的样本, 这两个样本的有效长度分别为2和3。 经过掩蔽softmax操作,超出有效长度的值都被掩蔽为0。
masked_softmax(torch.rand(2, 2, 4), torch.tensor([2, 3]))
tensor([[[0.5423, 0.4577, 0.0000, 0.0000],[0.6133, 0.3867, 0.0000, 0.0000]],[[0.3324, 0.2348, 0.4329, 0.0000],[0.2444, 0.3943, 0.3613, 0.0000]]])
同样,我们也可以使用二维张量,为矩阵样本中的每一行指定有效长度。
masked_softmax(torch.rand(2, 2, 4), torch.tensor([[1, 3], [2, 4]]))
tensor([[[1.0000, 0.0000, 0.0000, 0.0000],[0.4142, 0.3582, 0.2275, 0.0000]],[[0.5565, 0.4435, 0.0000, 0.0000],[0.3305, 0.2070, 0.2827, 0.1798]]])
1.2.1 加性注意力
#@save
class AdditiveAttention(nn.Module):"""加性注意力"""def __init__(self, key_size, query_size, num_hiddens, dropout, **kwargs):super(AdditiveAttention, self).__init__(**kwargs)self.W_k = nn.Linear(key_size, num_hiddens, bias=False)self.W_q = nn.Linear(query_size, num_hiddens, bias=False)self.w_v = nn.Linear(num_hiddens, 1, bias=False)self.dropout = nn.Dropout(dropout)def forward(self, queries, keys, values, valid_lens):queries, keys = self.W_q(queries), self.W_k(keys)# 在维度扩展后,# queries的形状:(batch_size,查询的个数,1,num_hidden)# key的形状:(batch_size,1,“键-值”对的个数,num_hiddens)# 使用广播方式进行求和features = queries.unsqueeze(2) + keys.unsqueeze(1)features = torch.tanh(features)# self.w_v仅有一个输出,因此从形状中移除最后那个维度。# scores的形状:(batch_size,查询的个数,“键-值”对的个数)scores = self.w_v(features).squeeze(-1)self.attention_weights = masked_softmax(scores, valid_lens)# values的形状:(batch_size,“键-值”对的个数,值的维度)return torch.bmm(self.dropout(self.attention_weights), values)我们用一个小例子来演示上面的AdditiveAttention类, 其中查询、键和值的形状为(批量大小,步数或词元序列长度,特征大小), 实际输出为(2,1,20)、(2,10,2)和(2,10,4)。 注意力汇聚输出的形状为(批量大小,查询的步数,值的维度)。
queries, keys = torch.normal(0, 1, (2, 1, 20)), torch.ones((2, 10, 2))
# values的小批量,两个值矩阵是相同的
values = torch.相关文章:
36k字从Attention讲解Transformer及其在Vision中的应用(pytorch版)
文章目录 0.卷积操作1.注意力1.1 注意力概述(Attention)1.1.1 Encoder-Decoder1.1.2 查询、键和值1.1.3 注意力汇聚: Nadaraya-Watson 核回归1.2 注意力评分函数1.2.1 加性注意力1.2.2 缩放点积注意力1.3 自注意力(Self-Attention)1.3.1 自注意力的定义和计算1.3.2 自注意…...

网站怎么选择适合的服务器
IDC数据中心大致分为T1、T2、T3、T4 T1:基本机房基础设施(可用性99.671%、年平均故障时间28.8小时) 1) T1 基本数据中心拥有非冗余容量组件,以及一个单一的非冗余分配路径来为关键环境提供服务。T1 基础设施包括:IT …...

http协议和HTTP编程流程
目录 1、http协议 (1)概念 (2)使用的端口 (3)长连接和短连接 (4)常见web服务器 2、https(443) 3、浏览器连接服务器编程 1、http协议 (超文…...

【NPM】包的指令
npm 安装的包可以根据其用途和作用进行分类,一般可以分为以下几种类型: 普通依赖(Regular Dependencies): 这些是你项目中的实际依赖项,用于构建、运行或扩展你的应用程序。这些依赖会被包含在你的应用程序…...

音频4A算法导论
+我V hezkz17进数字音频系统研究开发交流答疑群(课题组) 一 音频4A算法是? 音频4A算法是指自动增益控制(Automatic Gain Control, AGC)、自动噪声抑制(Automatic Noise Suppression, ANS)和自动回声消除(Automatic Echo Cancellation, AEC),主动降噪ANC(Active Noi…...
SecureBridge安全文件下载的组件Crack
SecureBridge安全文件下载的组件Crack SecureBridge包括SSH、SSL和SFTP客户端和服务器组件。它使用SSH或SSL安全传输层协议和加密消息语法来保护任何TCP流量,这些协议为客户端和服务器提供身份验证、强数据加密和数据完整性验证。SecureBridge组件可以与数据访问组件…...

进程同步
目录 临界区(Critical Section): 互斥量(Mutex): 信号量(Semaphore): 事件(Event): 进程同步的四种方法 临界区(Critical Section): 通过对多线程的串行…...
Prometheus+Grafana+AlertManager监控Linux主机状态
文章目录 PrometheusGrafanaAlertManager监控平台搭建开始监控Grafana连接Prometheus数据源导入Grafana模板监控Linux主机状态 同系列文章 PrometheusGrafanaAlertManager监控平台搭建 Docker搭建并配置Prometheus Docker拉取并配置Grafana Docker安装并配置Node-Exporter …...
UI设计第一步,在MasterGo上开展一个新项目
我们都知道,一个完整的项目,要经历创建团队、搭建组件库、应用规范以及管理设计资产,那么今天小编就在MasterGo中带你从0到1开展一个全新的项目。 你一定遇到过这种情况,同团队的设计师,由于使用不同版本或不同软件&a…...

【校招VIP】TCP/IP模型之常用协议和端口
考点介绍: 大厂测试校招面试里经常会出现TCP/IP模型的考察,TCP/IP协议是网络基础知识,是互联网的基石,不管你是做开发、运维还是信息安全的,TCP/IP 协议都是你绕不过去的一环,程序员需要像学会看书写字一样…...
Spring统一功能处理
1. AOP存在的问题 获取参数复杂AOP的规则相对简单 2. 拦截器 2.1. 应用(以登录为例) 2.1.1. 自定义拦截器 新建interceptor文件夹 import org.springframework.web.servlet.HandlerInterceptor;import javax.servlet.http.HttpServletRequest; import javax.servlet.http…...

搭建CFimagehost私人图床,实现公网远程访问的详细指南
文章目录 1.前言2. CFImagehost网站搭建2.1 CFImagehost下载和安装2.2 CFImagehost网页测试2.3 cpolar的安装和注册 3.本地网页发布3.1 Cpolar临时数据隧道3.2 Cpolar稳定隧道(云端设置)3.3.Cpolar稳定隧道(本地设置) 4.公网访问测…...

Python的logging.config模块
要使用Python的logging.config模块记录一个月的日志数据,你可以按照以下步骤进行操作: 首先,导入必要的模块: import logging import logging.config import datetime创建一个配置文件,例如logging.ini,用…...

【2023】LeetCode HOT 100——滑动窗口子串
目录 1. 无重复字符的最长子串1.1 C++实现1.2 Python实现1.3 时空分析2. 找到字符串中所有字母异位词2.1 C++实现2.2 Python实现2.3 时空分析3. 和为 K 的子数组3.1 C++实现3.2 Python实现3.3 时空分析4. 滑动窗口最大值4.1 C++实现4.2 Python实现4.3 时空分析5. 最小覆盖子串5…...
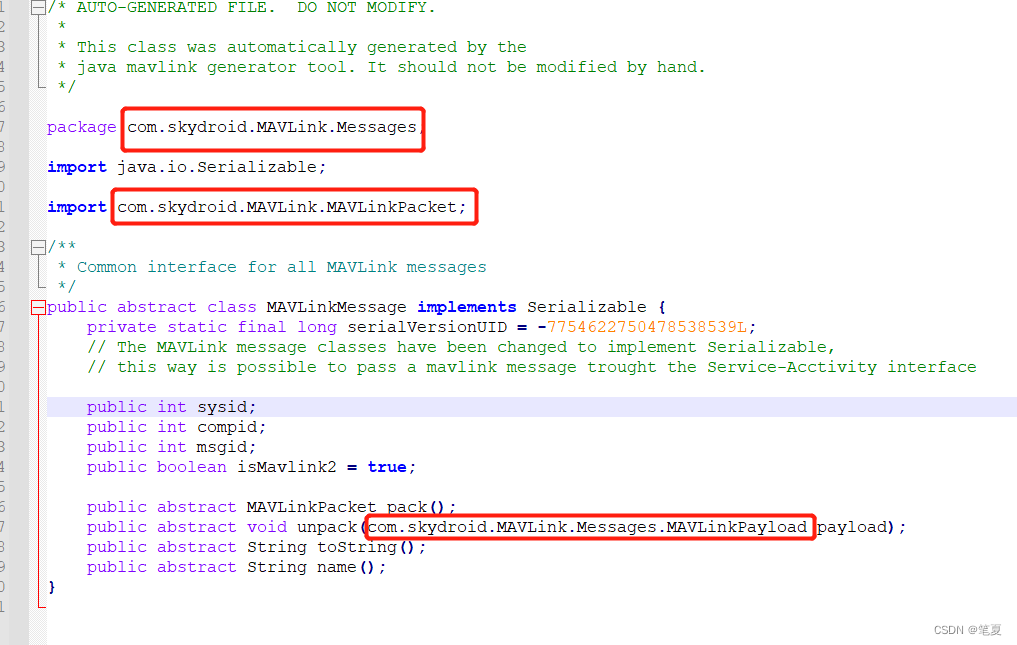
【云卓笔记】mavlink java文件
根据飞控提供的xml文件来生成的 生成的就是这样的java文件 准备工作: Mavlink协议生成 参考 1.安装mavlink : 使用MAVLink工具的要求是 Python 3.3 (recommended) or Python 2.7 Python future模块 (可选) PythonTklnter模块(如果需要使用图形用户界面)。 环境变量PYTHO…...

电机控制软件框架
应用层包括main 主函数模块,ISR 中断处理函数模块、时基Systick 模块和BLDC 应用接口模块;算法层包括BLDC Algorithm 模块和PID control 模块;驱动层(Driver layer):包括GD32Fxx_Standard_peripheral libra…...
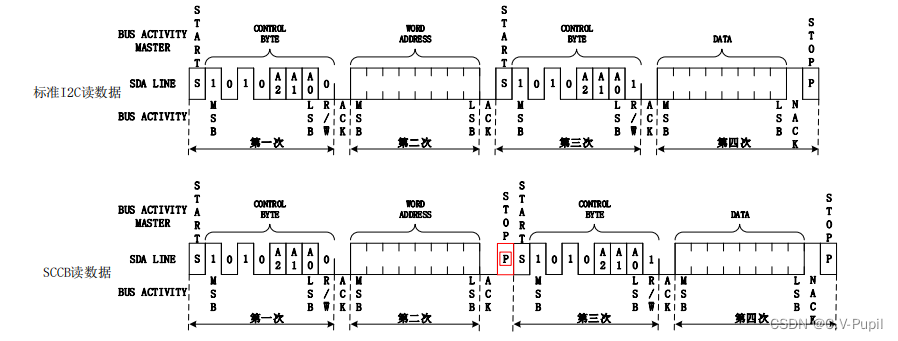
SCCB与IIC的异同及FPGA实现的注意事项
文章目录 前言一、信号线二、SCCB数据传输格式三、SCCB写(与IIC完全一致)四、SCCB读五、SCCB和IIC的区别 前言 IIC接口有比较广泛的应用,而SCCB(Serial Camera Control Bus,串行摄像头控制总线)是由OV&…...
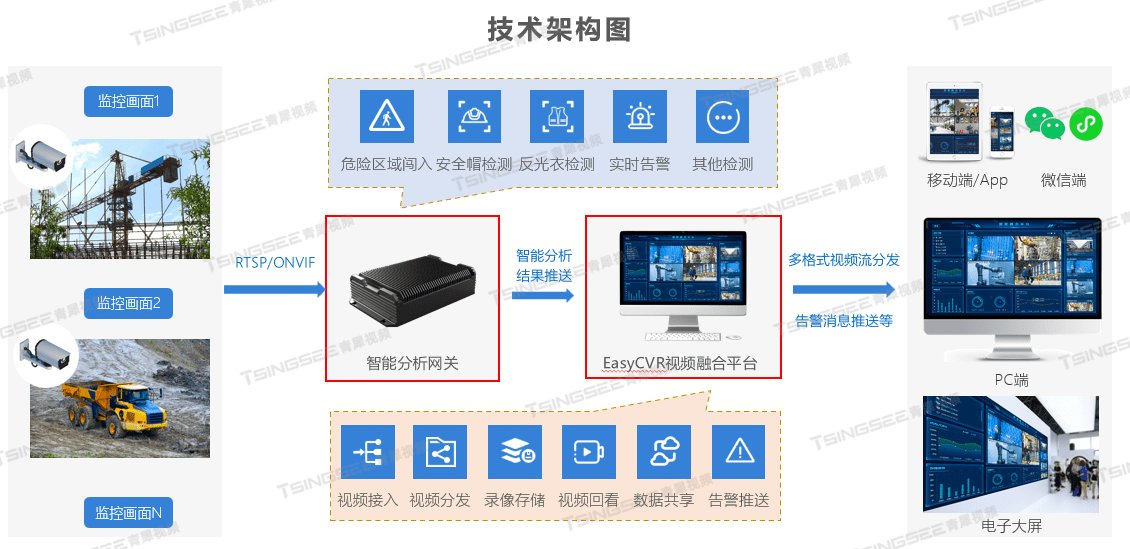
【开发】安防监控视频智能分析平台新功能:安全帽/反光衣/安全带AI识别详解
人工智能技术已经越来越多地融入到视频监控领域中,近期我们也发布了基于AI智能视频云存储/安防监控视频AI智能分析平台的众多新功能,该平台内置多种AI算法,可对实时视频中的人脸、人体、物体等进行检测、跟踪与抓拍,支持口罩佩戴检…...

数据结构 - 线性表的顺序存储
一、顺序存储定义: 把逻辑上相邻的数据元素存储在物理上相邻的存储单元中。简言之,逻辑上相邻,物理上也相邻顺序表中,任一元素可以随机存取(优点) 二、顺序表中元素存储位置的计算 三、顺序表在算法中的实…...

栈和队列在数据结构中的应用
文章目录 理解栈和队列的概念及其特点栈的应用和操作队列的应用和操作结论 🎉欢迎来到数据结构学习专栏~探索栈和队列在数据结构中的应用 ☆* o(≧▽≦)o *☆嗨~我是IT陈寒🍹✨博客主页:IT陈寒的博客🎈该系列文章专栏:…...
)
从STM32迁移到普冉PY32F003:UART代码移植保姆级教程(附HAL库对比)
从STM32到普冉PY32F003的UART代码迁移实战指南 1. 国产MCU替代浪潮下的技术选择 近年来,半导体行业的供应链波动促使更多工程师将目光投向国产MCU解决方案。普冉PY32F003系列作为Cortex-M0内核的代表产品,以48MHz主频、64KB Flash和8KB RAM的配置&#x…...

告别FTP龟速:用NTFS-3G在CentOS7上直连移动硬盘拷贝200G大文件
告别FTP龟速:用NTFS-3G在CentOS7上直连移动硬盘拷贝200G大文件当面对数百GB的设计素材、日志文件或数据库备份需要迁移时,传统的FTP传输往往会成为效率瓶颈。我曾在一个视频处理项目中,需要将230GB的4K原始素材从移动硬盘导入服务器ÿ…...
--脚本介绍)
二十六.签名与脚本(1)--脚本介绍
1.区块链脚本介绍在之前的章节中,我们了解了签名与验证相关,但是btc的交易数据,签名和验证,不是单纯的,还有脚本深度参与其中。我们从开始来:bool SendMoney(CScript scriptPubKey, int64 nValue, CWalletT…...
用Azure Kinect DK和Body Tracking SDK,5分钟实现一个实时人体骨骼点检测Demo(C++版)
5分钟实战:用Azure Kinect DK实现实时人体骨骼点追踪(C版) 当你第一次拿到Azure Kinect DK时,最令人兴奋的莫过于它强大的人体追踪能力。这款深度相机不仅能捕捉高清彩色图像,更能通过AI算法实时重建人体骨骼关节点。本…...

百度深度学习研究院的“叛将“,带着一颗芯片改变了中国智能驾驶——地平线余凯,从ImageNet冠军到征程出货1000万
大家好,我是写代码的篮球球痴。这篇文章跟我自己有点关系——我开的是理想汽车。理想的智驾系统 AD Pro,搭载的就是地平线征程 5 芯片。2026 年 1 月理想 AD Pro 4.0 推送,基于单颗征程 6M 实现了城市 NOA——这是行业里第一个用单颗 128TOPS…...

深度解析:UI-TARS视觉语言模型驱动的自动化操作框架核心技术架构
深度解析:UI-TARS视觉语言模型驱动的自动化操作框架核心技术架构 【免费下载链接】UI-TARS-desktop The Open-Source Multimodal AI Agent Stack: Connecting Cutting-Edge AI Models and Agent Infra 项目地址: https://gitcode.com/GitHub_Trending/ui/UI-TARS-…...
)
从数据到模型:手把手教你预处理MPIIFaceGaze和EyeDiap数据集(Python实战)
从数据到模型:手把手教你预处理MPIIFaceGaze和EyeDiap数据集(Python实战)当你第一次打开MPIIFaceGaze或EyeDiap数据集的压缩包时,那种面对杂乱文件夹和神秘.mat文件的迷茫感,我太熟悉了。作为计算机视觉工程师…...

AI 应用原型开发阶段利用 Taotoken 快速进行多模型效果对比
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 AI 应用原型开发阶段利用 Taotoken 快速进行多模型效果对比 在构建一个 AI 应用的原型时,开发者常常面临一个核心问题&…...

Playwright文件上传避坑指南:遇到动态生成的文件选择框怎么办?
Playwright文件上传避坑指南:动态生成文件选择框的实战解决方案最近在为一个电商平台做自动化测试时,遇到了一个棘手的问题——商品图片上传功能总是失败。页面上的"上传图片"按钮明明可以点击,但传统的set_input_files()方法却毫无…...

具身智能的发展对人类社会的影响有哪些?
具身智能对人类社会影响一、经济产业层面产业重构:催生机器人、智能制造、自动驾驶新产业,重塑生产链条效率跃升:替代重复繁重劳作,工厂、农业、物流产能大幅提升就业结构变化:低端体力岗位缩减,运维、研发…...