Flink流批一体计算(18):PyFlink DataStream API之计算和Sink
目录
1. 在上节数据流上执行转换操作,或者使用 sink 将数据写入外部系统。
2. File Sink
File Sink
Format Types
Row-encoded Formats
Bulk-encoded Formats
桶分配
滚动策略
3. 如何输出结果
集合数据到客户端,execute_and_collect方法将收集数据到客户端内存
将结果发送到DataStream sink connector
将结果发送到Table & SQL sink connector
4. 执行 PyFlink DataStream API 作业。
1. 在上节数据流上执行转换操作,或者使用 sink 将数据写入外部系统。
本教程使用 FileSink 将结果数据写入文件中。
def split(line):yield from line.split()# compute word count
ds = ds.flat_map(split) \.map(lambda i: (i, 1), output_type=Types.TUPLE([Types.STRING(), Types.INT()])) \.key_by(lambda i: i[0]) \.reduce(lambda i, j: (i[0], i[1] + j[1]))ds.sink_to(sink=FileSink.for_row_format(base_path=output_path,encoder=Encoder.simple_string_encoder()).with_output_file_config(OutputFileConfig.builder().with_part_prefix("prefix").with_part_suffix(".ext").build()).with_rolling_policy(RollingPolicy.default_rolling_policy()).build()
)sink_to函数,将DataStream数据发送到自定义sink connector,仅支持FileSink,可用于batch和streaming执行模式。
2. File Sink
Streaming File Sink是Flink1.7中推出的新特性,是为了解决如下的问题:
大数据业务场景中,经常有一种场景:外部数据发送到kafka中,flink作为中间件消费kafka数据并进行业务处理;处理完成之后的数据可能还需要写入到数据库或者文件系统中,比如写入hdfs中。
Streaming File Sink就可以用来将分区文件写入到支持 Flink FileSystem 接口的文件系统中,支持Exactly-Once语义。这种sink实现的Exactly-Once都是基于Flink checkpoint来实现的两阶段提交模式来保证的,主要应用在实时数仓、topic拆分、基于小时分析处理等场景下。
Streaming File Sink 是社区优化后添加的connector,推荐使用。
Streaming File Sink更灵活,功能更强大,可以自己实现序列化方法
Streaming File Sink有两个方法可以输出到文件:行编码格式forRowFormat 和 块编码格式forBulkFormat。
forRowFormat 比较简单,只提供了SimpleStringEncoder写文本文件,可以指定编码。
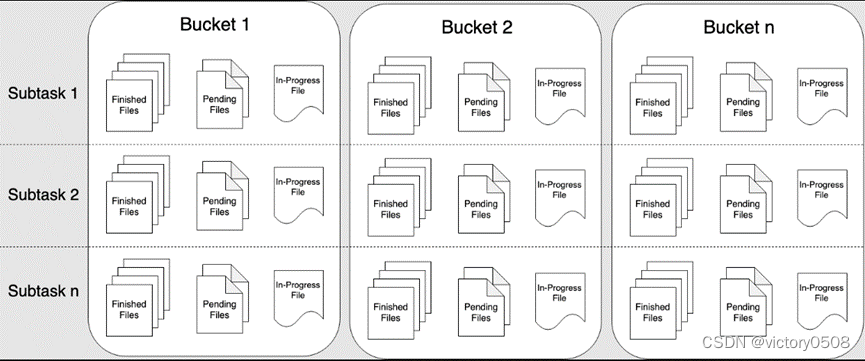
由于流数据本身是无界的,所以,流数据将数据写入到分桶(bucket)中。默认使用基于系统时间(yyyy-MM-dd--HH)的分桶策略。在分桶中,又根据滚动策略,将输出拆分为 part 文件。
Flink 提供了两个分桶策略,分桶策略实现了
org.apache.flink.streaming.api.functions.sink.filesystem.BucketAssigner 接口:
BasePathBucketAssigner,不分桶,所有文件写到根目录;
DateTimeBucketAssigner,基于系统时间(yyyy-MM-dd--HH)分桶。
除此之外,还可以实现BucketAssigner接口,自定义分桶策略。
Flink 提供了两个滚动策略,滚动策略实现了
org.apache.flink.streaming.api.functions.sink.filesystem.RollingPolicy 接口:
DefaultRollingPolicy 当超过最大桶大小(默认为 128 MB),或超过了滚动周期(默认为 60 秒),或未写入数据处于不活跃状态超时(默认为 60 秒)的时候,滚动文件;
OnCheckpointRollingPolicy 当 checkpoint 的时候,滚动文件。
File Sink
File Sink 将传入的数据写入存储桶中。考虑到输入流可以是无界的,每个桶中的数据被组织成有限大小的 Part 文件。 完全可以配置为基于时间的方式往桶中写入数据,比如可以设置每个小时的数据写入一个新桶中。这意味着桶中将包含一个小时间隔内接收到的记录。
桶目录中的数据被拆分成多个 Part 文件。对于相应的接收数据的桶的 Sink 的每个 Subtask,每个桶将至少包含一个 Part 文件。将根据配置的滚动策略来创建其他 Part 文件。 对于 Row-encoded Formats默认的策略是根据 Part 文件大小进行滚动,需要指定文件打开状态最长时间的超时以及文件关闭后的非活动状态的超时时间。 对于 Bulk-encoded Formats 在每次创建 Checkpoint 时进行滚动,并且用户也可以添加基于大小或者时间等的其他条件。
重要: 在 STREAMING 模式下使用 FileSink 需要开启 Checkpoint 功能。 文件只在 Checkpoint 成功时生成。如果没有开启 Checkpoint 功能,文件将永远停留在 in-progress 或者 pending 的状态,并且下游系统将不能安全读取该文件数据。
Format Types
FileSink 不仅支持 Row-encoded 也支持 Bulk-encoded,例如 Apache Parquet。 这两种格式可以通过如下的静态方法进行构造:
- Row-encoded sink:
FileSink.forRowFormat(basePath, rowEncoder) - Bulk-encoded sink:
FileSink.forBulkFormat(basePath, bulkWriterFactory)
不论创建 Row-encoded Format 或者 Bulk-encoded Format 的 Sink 时,都必须指定桶的路径以及对数据进行编码的逻辑。
Row-encoded Formats
Row-encoded Format 需要指定一个 Encoder,在输出数据到文件过程中被用来将单个行数据序列化为 Outputstream。
除了 bucket assigner,RowFormatBuilder 还允许用户指定以下属性:
- Custom RollingPolicy :自定义滚动策略覆盖 DefaultRollingPolicy
- bucketCheckInterval (默认值 = 1 min) :基于滚动策略设置的检查时间间隔
data_stream = ...
sink = FileSink \.for_row_format(OUTPUT_PATH, Encoder.simple_string_encoder("UTF-8")) \.with_rolling_policy(RollingPolicy.default_rolling_policy(part_size=1024 ** 3, rollover_interval=15 * 60 * 1000, inactivity_interval=5 * 60 * 1000)) \.build()
data_stream.sink_to(sink)这个例子中创建了一个简单的 Sink,默认的将记录分配给小时桶。 例子中还指定了滚动策略,当满足以下三个条件的任何一个时都会将 In-progress 状态文件进行滚动:
- 包含了至少15分钟的数据量
- 从没接收延时5分钟之外的新纪录
- 文件大小已经达到 1GB(写入最后一条记录之后)
Bulk-encoded Formats
Bulk-encoded 的 Sink 的创建和 Row-encoded 的相似,但不需要指定 Encoder,而是需要指定 BulkWriter.Factory。 BulkWriter 定义了如何添加和刷新新数据以及如何最终确定一批记录使用哪种编码字符集的逻辑。
Flink 内置了5种 BulkWriter 工厂类:
- ParquetWriterFactory
- AvroWriterFactory
- SequenceFileWriterFactory
- CompressWriterFactory
- OrcBulkWriterFactory
重要 Bulk-encoded Format 仅支持一种继承了 CheckpointRollingPolicy 类的滚动策略。 在每个 Checkpoint 都会滚动。另外也可以根据大小或处理时间进行滚动。
桶分配
桶的逻辑定义了如何将数据分配到基本输出目录内的子目录中。
Row-encoded Format 和 Bulk-encoded Format使用了 DateTimeBucketAssigner 作为默认的分配器。 默认的分配器 DateTimeBucketAssigner 会基于使用了格式为 yyyy-MM-dd--HH 的系统默认时区来创建小时桶。日期格式( 即 桶大小)和时区都可以手动配置。
还可以在格式化构造器中通过调用 .withBucketAssigner(assigner) 方法指定自定义的 BucketAssigner。
Flink 内置了两种 BucketAssigners:
DateTimeBucketAssigner:默认的基于时间的分配器BasePathBucketAssigner:分配所有文件存储在基础路径上(单个全局桶)
PyFlink 只支持 DateTimeBucketAssigner 和 BasePathBucketAssigner 。
滚动策略
RollingPolicy 定义了何时关闭给定的 In-progress Part 文件,并将其转换为 Pending 状态,然后在转换为 Finished 状态。 Finished 状态的文件,可供查看并且可以保证数据的有效性,在出现故障时不会恢复。 在 STREAMING 模式下,滚动策略结合 Checkpoint 间隔(到下一个 Checkpoint 成功时,文件的 Pending 状态才转换为 Finished 状态)共同控制 Part 文件对下游 readers 是否可见以及这些文件的大小和数量。在 BATCH 模式下,Part 文件在 Job 最后对下游才变得可见,滚动策略只控制最大的 Part 文件大小。
Flink 内置了两种 RollingPolicies:
DefaultRollingPolicyOnCheckpointRollingPolicy
PyFlink 只支持 DefaultRollingPolicy 和 OnCheckpointRollingPolicy 。
3. 如何输出结果
ds.print()
Collect results to client
集合数据到客户端,execute_and_collect方法将收集数据到客户端内存
with ds.execute_and_collect() as results:
for result in results:
print(result)
将结果发送到DataStream sink connector
add_sink函数,将DataStream数据发送到sink connector,此函数仅支持FlinkKafkaProducer, JdbcSink和StreamingFileSink,仅在streaming执行模式下使用
from pyflink.common.typeinfo import Types
from pyflink.datastream.connectors import FlinkKafkaProducer
from pyflink.common.serialization import JsonRowSerializationSchemaserialization_schema = JsonRowSerializationSchema.builder().with_type_info(type_info=Types.ROW([Types.INT(), Types.STRING()])).build()kafka_producer = FlinkKafkaProducer(topic='test_sink_topic',serialization_schema=serialization_schema,producer_config={'bootstrap.servers': 'localhost:9092', 'group.id': 'test_group'})ds.add_sink(kafka_producer)sink_to函数,将DataStream数据发送到自定义sink connector,仅支持FileSink,可用于batch和streaming执行模式
from pyflink.datastream.connectors import FileSink, OutputFileConfig
from pyflink.common.serialization import Encoderoutput_path = '/opt/output/'
file_sink = FileSink \.for_row_format(output_path, Encoder.simple_string_encoder()) \ .with_output_file_config(OutputFileConfig.builder().with_part_prefix('pre').with_part_suffix('suf').build()) \.build()
ds.sink_to(file_sink)将结果发送到Table & SQL sink connector
Table & SQL connectors也被用于写入DataStream. 首先将DataStream转为Table,然后写入到 Table & SQL sink connector.
from pyflink.common import Row
from pyflink.common.typeinfo import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.table import StreamTableEnvironmentenv = StreamExecutionEnvironment.get_execution_environment()
t_env = StreamTableEnvironment.create(stream_execution_environment=env)
# option 1:the result type of ds is Types.ROW
def split(s):splits = s[1].split("|")for sp in splits:yield Row(s[0], sp)ds = ds.map(lambda i: (i[0] + 1, i[1])) \.flat_map(split, Types.ROW([Types.INT(), Types.STRING()])) \.key_by(lambda i: i[1]) \.reduce(lambda i, j: Row(i[0] + j[0], i[1]))# option 1:the result type of ds is Types.TUPLE
def split(s):splits = s[1].split("|")for sp in splits:yield s[0], spds = ds.map(lambda i: (i[0] + 1, i[1])) \.flat_map(split, Types.TUPLE([Types.INT(), Types.STRING()])) \.key_by(lambda i: i[1]) \.reduce(lambda i, j: (i[0] + j[0], i[1]))# emit ds to print sink
t_env.execute_sql("""CREATE TABLE my_sink (a INT,b VARCHAR) WITH ('connector' = 'print')""")table = t_env.from_data_stream(ds)
table_result = table.execute_insert("my_sink")4. 执行 PyFlink DataStream API 作业。
PyFlink applications 是懒加载的,并且只有在完全构建之后才会提交给集群上执行。
要执行一个应用程序,你只需简单地调用 env.execute()。
env.execute()
相关文章:
Flink流批一体计算(18):PyFlink DataStream API之计算和Sink
目录 1. 在上节数据流上执行转换操作,或者使用 sink 将数据写入外部系统。 2. File Sink File Sink Format Types Row-encoded Formats Bulk-encoded Formats 桶分配 滚动策略 3. 如何输出结果 Print 集合数据到客户端,execute_and_collect…...

03.sqlite3学习——数据类型
目录 sqlite3学习——数据类型 SQL语句的功能 SQL语法 SQL命令 SQL数据类型 数字类型 整型 浮点型 定点型decimal 浮点型 VS decimal 日期类型 字符串类型 CHAR和VARCHAR BLOB和TEXT SQLite 数据类型 SQLite 存储类 SQLite 亲和类型(Affinity)及类型名称 Boo…...
LLM-chatgpt训练过程
流程简介 主要包含模型预训练和指令微调两个阶段 模型预训练:搜集海量的文本数据,无监督的训练自回归decoder; O T P ( O t < T ) O_TP(O_{t<T}) OTP(Ot<T),损失函数CE loss指令微调:在输入文本中加入…...

【学习笔记】[ABC274Ex] XOR Sum of Arrays
有点难😅 真的是 A B C ABC ABC的难度吗😅 非常精妙的哈希题目。 定义矩阵乘法: c i , j ⊕ ( a i , k & b k , j ) c_{i,j}\oplus (a_{i,k}\& b_{k,j}) ci,j⊕(ai,k&bk,j) 之所以可以矩阵乘法是因为满足 ( a ⊕ b )…...
抖音web频道爬虫
抖音web频道爬虫代码: <?php header(Content-Type:application/json; charsetutf-8);//抖音频道爬虫class DouyinChannel{private $app_id 1;private $spider_code 1;private $channels [["channel_name" > "热点","url"…...
总结)
sql中的替换函数replace()总结
1,表达式 --replace()--语法: REPLACE ( string_expression , string_pattern , string_replacement )--参数:string_expression:字符串表达式string_pattern:想要查找的子字符串string_replacement&#…...
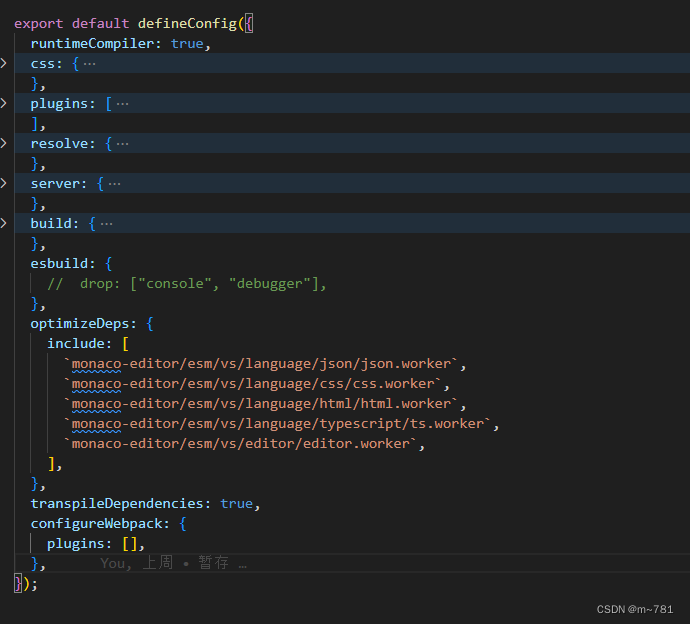
vue3 vite使用 monaco-editor 报错
报错:Unexpected usage at EditorSimpleWorker.loadForeignModule 修改配置: "monaco-editor-webpack-plugin": "^4.2.0",删除不用 版本: "monaco-editor": "^0.28.1", 修改如下: opti…...

微信小程序获取蓝牙权限
要获取微信小程序中的蓝牙权限,您可以按照以下步骤进行操作: 1. 在 app.json 文件中添加以下代码: "permissions": { "scope.userLocation": { "desc": "需要获取您的地理位置授权以搜索…...

GE 8920-PS-DC安全模块
安全控制: 这个安全模块通常用于实现工业自动化系统中的安全控制功能。它可以监测各种安全参数,如机器运动、温度、压力等,以确保系统在安全范围内运行。 PLC兼容性: 通常,这种安全模块可以与可编程逻辑控制器&#x…...
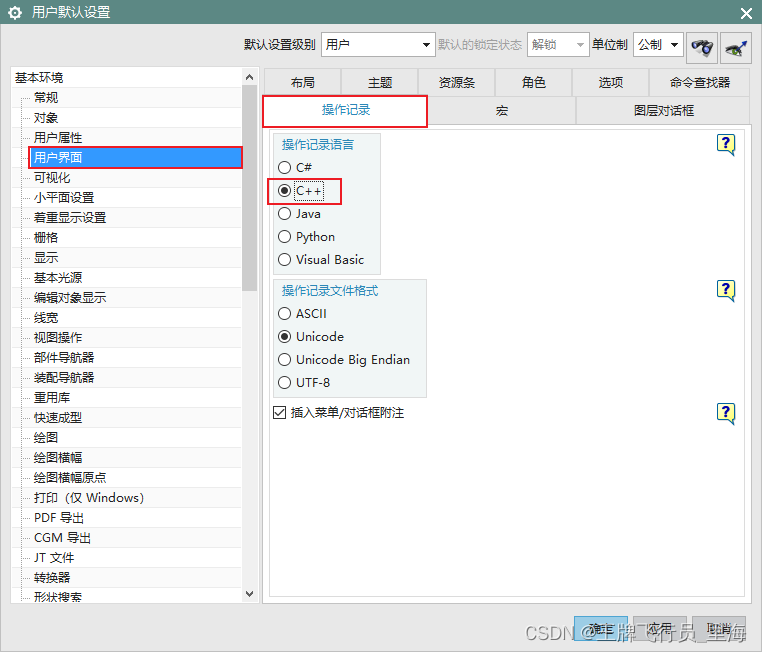
UG\NX二次开发 使用BlockUI设计对话框时,如何设置默认的开发语言?
文章作者:里海 来源网站:王牌飞行员_里海_里海NX二次开发3000例,C\C++,Qt-CSDN博客 简介: NX二次开发使用BlockUI设计对话框时,如何设置默认的代码语言? 效果: 方法: 依次打开“文件”->“实用工具”->“用户默认设置”->“用户界面”->“操作记录”->“…...
W5500-EVB-PICO进行UDP组播数据回环测试(九)
前言 上一章我们用我们的开发板作为UDP客户端连接服务器进行数据回环测试,那么本章我们进行UDP组播数据回环测试。 什么是UDP组播? 组播是主机间一对多的通讯模式, 组播是一种允许一个或多个组播源发送同一报文到多个接收者的技术。组播源将…...
24 WEB漏洞-文件上传之WAF绕过及安全修复
目录 WAF绕过上传参数名解析:明确哪些东西能修改?常见绕过方法:符号变异-防匹配( " ;)数据截断-防匹配(%00 ; 换行)重复数据-防匹配(参数多次)搜索引擎搜索fuzz web字典文件上传安全修复方案 WAF绕过 safedog BT(宝塔) XXX云盾 宝塔过滤的比安全狗厉害一些&a…...
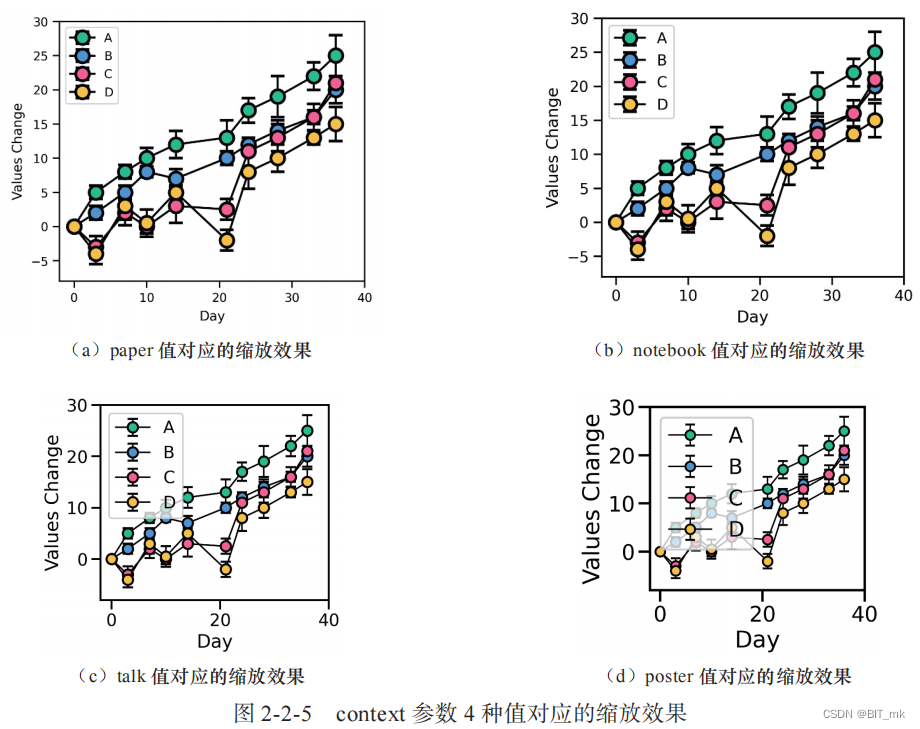
Python科研绘图--Task03
目录 图类型 关系类型图 散点图的例子 数据分布型图 rugplot例子 分类数据型图 编辑回归模型分析型图 多子图网格型图 FacetGrid() 函数 PairGrid() 函数 绘图风格、颜色主题和绘图元素缩放比例 绘图风格 颜色主题 绘图元素缩放比列 图类型 关系类型图 数据集变量…...
ssm端游游戏账号销售管理系统源码和论文
ssm端游游戏账号销售管理系统源码和论文069 开发工具:idea 数据库mysql5.7 数据库链接工具:navcat,小海豚等 技术:ssm 摘 要 互联网发展至今,无论是其理论还是技术都已经成熟,而且它广泛参与在社会中的方方面面…...
ssm+vue农家乐信息平台源码和论文
ssmvue农家乐信息平台源码和论文066 开发工具:idea 数据库mysql5.7 数据库链接工具:navcat,小海豚等 技术:ssm 1、研究现状 国外,农家乐都被作为潜在的发展农村经济,增加农民收入的重要手段,让农户广…...

安装启动yolo5教程
目录 一、下载yolo5项目 二、安装miniconda(建议不要安装在C盘) 三、安装CUDA 四、安装pytorch 五、修改配置参数 六、修改电脑参数 七、启动项目 博主硬件: Windows 10 家庭中文版 一、下载yolo5项目 GitHub - ultralytics/yolov5:…...

封装redis 分布式锁 RedisCallback
RedisCallback 是redis 一个回调接口,在 Redis 连接后执行单个命令,返回执行命令后的结果。 如果在使用 RedisCallback 时,需要自动获取 Redis 连接资源,使用完毕后并释放连接资源。 RedisTemplate 类提供了一个 execute 方法&am…...

代码随想录算法训练营第17期第32天 | 122. 买卖股票的最佳时机 II、455.分发饼干、376. 摆动序列、53. 最大子序和
122. 买卖股票的最佳时机 II 我好像记得这道题是怎么写的,也不知道是福是祸 1. 收集每天的正利润就可以,收集正利润的区间,就是股票买卖的区间,而我们只需要关注最终利润,不需要记录区间 2.局部最优:收集…...
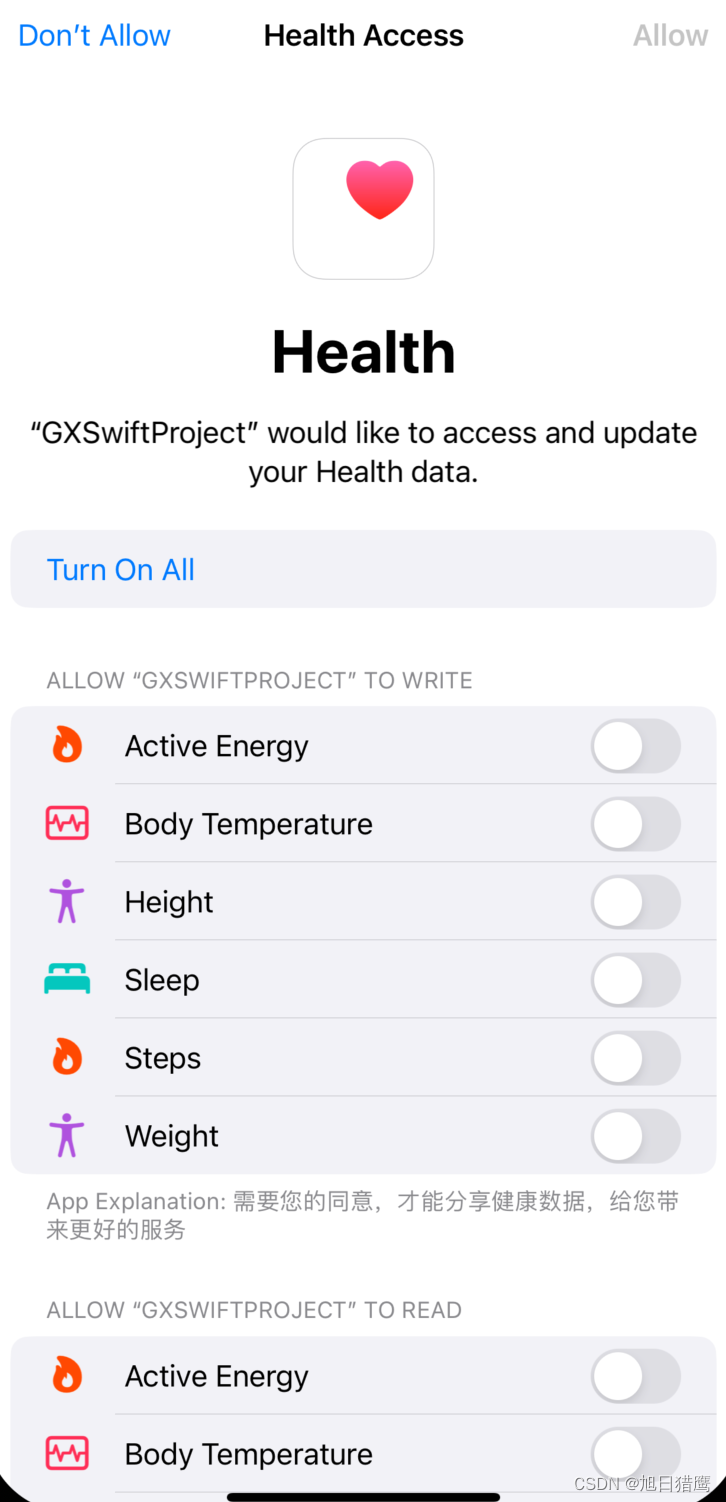
iOS HealthKit 介绍
文章目录 一、简介二、权限配置1. 在开发者账号中勾选HealthKit2. 在targets的capabilities中添加HealthKit。3. infoPlist需要配置权限 三、创建健康数据管理类1. 引入头文件2. 健康数据读写权限3. 检查权限4. 读取步数数据5. 写入健康数据 四、运行获取权限页面 一、简介 He…...
Windows平台Unity下播放RTSP或RTMP如何开启硬解码?
我们在做Windows平台Unity播放RTMP或RTSP的时候,遇到这样的问题,比如展会、安防监控等场景下,需要同时播放多路RTMP或RTSP流,这样对设备性能,提出来更高的要求。 虽然我们软解码,已经做的资源占有非常低了…...

std::accumulate算法深度解析:从求和到通用折叠,解锁STL隐藏的瑞士军刀
1. 重新认识std::accumulate:不只是求和工具 第一次接触std::accumulate时,大多数人都是从求和开始的。确实,这个算法默认行为就是对范围内的元素进行累加。但如果你只把它当作一个高级计算器,那就太小看这个STL中的"瑞士军刀…...

BiliBiliToolPro:解放双手的B站自动化神器,让你的账号管理从未如此轻松
BiliBiliToolPro:解放双手的B站自动化神器,让你的账号管理从未如此轻松 【免费下载链接】BiliBiliToolPro B 站(bilibili)自动任务工具,支持docker、青龙、k8s等多种部署方式。全面拥抱AI。敏感肌也能用。 项目地址:…...

告别日志脱敏烦恼:手把手教你用sensitive注解优雅保护用户隐私数据
优雅实现日志脱敏:基于注解的隐私数据保护实战指南 在金融、电商等强合规领域,用户隐私数据保护早已从"可选"变为"必选"。每次看到同事在代码中手动拼接"手机号:"user.getPhone().substring(0,3)"****&qu…...

别只盯着TPS!用JMeter汇总报告做一次完整的性能瓶颈分析实战
别只盯着TPS!用JMeter汇总报告做一次完整的性能瓶颈分析实战 在性能测试领域,JMeter的汇总报告(Summary Report)是最常用的监听器之一,但很多测试工程师往往只关注其中的TPS(每秒事务数)指标&am…...

现代化管理平台架构优化:FastAPI+Vue3+RBAC权限模型的技术实现与性能提升
现代化管理平台架构优化:FastAPIVue3RBAC权限模型的技术实现与性能提升 【免费下载链接】vue-fastapi-admin ⭐️ 基于 FastAPIVue3Naive UI 的现代化轻量管理平台 A modern and lightweight management platform based on FastAPI, Vue3, and Naive UI. 项目地址…...

手把手教你用85033E校准套件搞定E5071C网分的TDR和S参数测量
手把手教你用85033E校准套件搞定E5071C网分的TDR和S参数测量 在射频和微波测试领域,网络分析仪是工程师不可或缺的工具,而E5071C作为一款经典的中端矢量网络分析仪,广泛应用于通信、雷达、天线等领域的研发和测试。对于刚接触这款设备的新手工…...

B站视频下载神器:如何优雅地将Bilibili内容保存到本地
B站视频下载神器:如何优雅地将Bilibili内容保存到本地 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirrors/b…...

合成孔径雷达干涉测量InSAR数据处理、地形三维重建、形变信息提取、监测等技术应用
合成孔径雷达干涉测量(Interferometric Synthetic Aperture Radar, InSAR)技术作为一种新兴的主动式微波遥感技术,凭借其可以穿过大气层,全天时、全天候获取监测目标的形变信息等特性,已在地表形变监测、DEM生成、滑坡…...

Crontab实战指南:从基础配置到高级调试技巧
1. Crontab入门:从零开始掌握定时任务 第一次接触Crontab时,我被这个看似简单却功能强大的工具深深吸引。作为Linux系统中最经典的定时任务工具,它就像一位不知疲倦的助手,能够精确地在指定时间执行你交代的任何任务。记得刚开始使…...

MASA模组中文汉化包:让技术模组真正为你所用
MASA模组中文汉化包:让技术模组真正为你所用 【免费下载链接】masa-mods-chinese 一个masa mods的汉化资源包 项目地址: https://gitcode.com/gh_mirrors/ma/masa-mods-chinese 还在为Minecraft技术模组的英文界面而头疼吗?当你在使用Litematica进…...