使用 Auto-scheduling 优化算子
本篇回答来源于 TVM 官方英文文档 Lianmin Zheng,Chengfan Jia。更多 TVM 中文文档可访问→https://tvm.hyper.ai/
本教程将展示 TVM 的 Auto Scheduling 功能,如何在不编写自定义模板的情况下,找到最佳 schedule。
与基于模板的 AutoTVM 依赖手工模板来定义搜索空间不同,auto-scheduler 不需要任何模板。用户只需编写计算声明,无需任何 schedule 命令或模板。auto-scheduler 可以自动生成一个大的搜索空间,并在空间中找到最优 schedule。
本教程中使用矩阵乘法作为示例。
注意,本教程不会在 Windows 或最新版本的 macOS 上运行。如需运行,请将本教程的主体放在 if name == “main”: 代码块中。
import osimport numpy as np
import tvm
from tvm import te, auto_scheduler
定义矩阵乘法
首先,定义一个带有偏置加法的矩阵乘法。注意,这里使用了 TVM 张量表达式语言中的标准操作。主要区别在于函数定义上方使用了 register_workload 装饰器。该函数应返回输入/输出张量列表。通过这些张量,auto-scheduler 可以得到整个计算图。
@auto_scheduler.register_workload # Note the auto_scheduler decorator
def matmul_add(N, L, M, dtype):A = te.placeholder((N, L), name="A", dtype=dtype)B = te.placeholder((L, M), name="B", dtype=dtype)C = te.placeholder((N, M), name="C", dtype=dtype)k = te.reduce_axis((0, L), name="k")matmul = te.compute((N, M),lambda i, j: te.sum(A[i, k] * B[k, j], axis=k),name="matmul",attrs={"layout_free_placeholders": [B]}, # enable automatic layout transform for tensor B)out = te.compute((N, M), lambda i, j: matmul[i, j] + C[i, j], name="out")return [A, B, C, out]
创建搜索任务
定义函数后,可以为 auto_scheduler 创建要搜索的任务。我们为这个矩阵乘法指定了特定的参数,如这里是两个大小为 1024x1024 的矩阵乘法。然后我们创建一个 N=L=M=1024 和 dtype=“float32” 的搜索任务
使用自定义 TARGET 提高性能
为让 TVM 充分利用特定的硬件平台,需要手动指定 CPU 功能。例如:
启用 AVX2:将下面的 llvm 替换为 llvm -mcpu=core-avx2
启用 AVX-512:将下面的 llvm 替换为 llvm -mcpu=skylake-avx512
target = tvm.target.Target("llvm")
N = L = M = 1024
task = tvm.auto_scheduler.SearchTask(func=matmul_add, args=(N, L, M, "float32"), target=target)# 检查计算图
print("Computational DAG:")
print(task.compute_dag)
输出结果:
Computational DAG:
A = PLACEHOLDER [1024, 1024]
B = PLACEHOLDER [1024, 1024]
matmul(i, j) += (A[i, k]*B[k, j])
C = PLACEHOLDER [1024, 1024]
out(i, j) = (matmul[i, j] + C[i, j])
设置 auto-scheduler 的参数
接下来,为 auto-scheduler 设置参数。
num_measure_trials 表示搜索过程中可用的测试试验次数。本教程为了快速演示只进行了 10 次试验。实际上,1000 是搜索收敛的最佳数量。可以根据自己的时间预算进行更多试验。
此外,我们用 RecordToFile 将测试记录记录到文件 matmul.json 中。测试记录可用于查询历史最佳、恢复搜索以及以后进行更多分析。
有关更多参数,参见 TuningOptions
log_file = "matmul.json"
tune_option = auto_scheduler.TuningOptions(num_measure_trials=10,measure_callbacks=[auto_scheduler.RecordToFile(log_file)],verbose=2,
)
开始搜索
准备好所有输入就可以开始搜索,让 auto-scheduler 发挥它的作用。经过一些测试试验后,可从日志文件中加载最佳 schedule 并应用。
# 运行 auto-tuning(搜索)
task.tune(tune_option)
# 应用最佳 schedule
sch, args = task.apply_best(log_file)
检查优化的 schedule
auto-scheduling 完成后,可将 schedule 降级来查看 IR。auto-scheduler 执行合适的优化,包括多级循环切分、布局转换、并行化、向量化、循环展开和算子融合。
print("Lowered TIR:")
print(tvm.lower(sch, args, simple_mode=True))
输出结果:
Lowered TIR:
@main = primfn(A_1: handle, B_1: handle, C_1: handle, out_1: handle) -> ()attr = {"from_legacy_te_schedule": True, "global_symbol": "main", "tir.noalias": True}buffers = {A: Buffer(A_2: Pointer(float32), float32, [1048576], []),B: Buffer(B_2: Pointer(float32), float32, [1048576], []),C: Buffer(C_2: Pointer(float32), float32, [1048576], []),out: Buffer(out_2: Pointer(float32), float32, [1048576], [])}buffer_map = {A_1: A, B_1: B, C_1: C, out_1: out}preflattened_buffer_map = {A_1: A_3: Buffer(A_2, float32, [1024, 1024], []), B_1: B_3: Buffer(B_2, float32, [1024, 1024], []), C_1: C_3: Buffer(C_2, float32, [1024, 1024], []), out_1: out_3: Buffer(out_2, float32, [1024, 1024], [])} {allocate(auto_scheduler_layout_transform: Pointer(global float32), float32, [1048576]), storage_scope = global {for (ax0.ax1.fused.ax2.fused: int32, 0, 128) "parallel" {for (ax4: int32, 0, 256) {for (ax6: int32, 0, 4) {for (ax7: int32, 0, 8) {auto_scheduler_layout_transform_1: Buffer(auto_scheduler_layout_transform, float32, [1048576], [])[((((ax0.ax1.fused.ax2.fused*8192) + (ax4*32)) + (ax6*8)) + ax7)] = B[((((ax4*4096) + (ax6*1024)) + (ax0.ax1.fused.ax2.fused*8)) + ax7)]}}}}for (i.outer.outer.j.outer.outer.fused: int32, 0, 16384) "parallel" {allocate(matmul: Pointer(global float32x8), float32x8, [4]), storage_scope = global;for (i.outer.inner: int32, 0, 2) {matmul_1: Buffer(matmul, float32x8, [4], [])[0] = broadcast(0f32, 8)matmul_1[1] = broadcast(0f32, 8)matmul_1[2] = broadcast(0f32, 8)matmul_1[3] = broadcast(0f32, 8)for (k.outer: int32, 0, 256) {for (k.inner: int32, 0, 4) {let cse_var_2: int32 = (((floormod(i.outer.outer.j.outer.outer.fused, 128)*8192) + (k.outer*32)) + (k.inner*8))let cse_var_1: int32 = ((((floordiv(i.outer.outer.j.outer.outer.fused, 128)*8192) + (i.outer.inner*4096)) + (k.outer*4)) + k.inner){matmul_1[0] = (matmul_1[0] + (broadcast(A[cse_var_1], 8)*auto_scheduler_layout_transform_1[ramp(cse_var_2, 1, 8)]))matmul_1[1] = (matmul_1[1] + (broadcast(A[(cse_var_1 + 1024)], 8)*auto_scheduler_layout_transform_1[ramp(cse_var_2, 1, 8)]))matmul_1[2] = (matmul_1[2] + (broadcast(A[(cse_var_1 + 2048)], 8)*auto_scheduler_layout_transform_1[ramp(cse_var_2, 1, 8)]))matmul_1[3] = (matmul_1[3] + (broadcast(A[(cse_var_1 + 3072)], 8)*auto_scheduler_layout_transform_1[ramp(cse_var_2, 1, 8)]))}}}for (i.inner: int32, 0, 4) {let cse_var_3: int32 = ((((floordiv(i.outer.outer.j.outer.outer.fused, 128)*8192) + (i.outer.inner*4096)) + (i.inner*1024)) + (floormod(i.outer.outer.j.outer.outer.fused, 128)*8))out[ramp(cse_var_3, 1, 8)] = (matmul_1[i.inner] + C[ramp(cse_var_3, 1, 8)])}}}}
}
检查正确性并评估性能
构建二进制文件并检查其正确性和性能。
func = tvm.build(sch, args, target)
a_np = np.random.uniform(size=(N, L)).astype(np.float32)
b_np = np.random.uniform(size=(L, M)).astype(np.float32)
c_np = np.random.uniform(size=(N, M)).astype(np.float32)
out_np = a_np.dot(b_np) + c_npdev = tvm.cpu()
a_tvm = tvm.nd.array(a_np, device=dev)
b_tvm = tvm.nd.array(b_np, device=dev)
c_tvm = tvm.nd.array(c_np, device=dev)
out_tvm = tvm.nd.empty(out_np.shape, device=dev)
func(a_tvm, b_tvm, c_tvm, out_tvm)# Check results
np.testing.assert_allclose(out_np, out_tvm.numpy(), rtol=1e-3)# Evaluate execution time.
evaluator = func.time_evaluator(func.entry_name, dev, min_repeat_ms=500)
print("Execution time of this operator: %.3f ms"% (np.median(evaluator(a_tvm, b_tvm, c_tvm, out_tvm).results) * 1000)
)
输出结果:
Execution time of this operator: 93.286 ms
使用记录文件
在搜索过程中,所有测试记录都保存到记录文件 matmul.json 中。测试记录可用于重新应用搜索结果、恢复搜索和执行其他分析。
下面是从文件中加载最佳 schedule,并打印等效的 Python schedule API 的例子。可用于调试和学习 auto-scheduler 的行为。
print("Equivalent python schedule:")
print(task.print_best(log_file))
输出结果:
Equivalent python schedule:
matmul_i, matmul_j, matmul_k = tuple(matmul.op.axis) + tuple(matmul.op.reduce_axis)
out_i, out_j = tuple(out.op.axis) + tuple(out.op.reduce_axis)
matmul_i_o_i, matmul_i_i = s[matmul].split(matmul_i, factor=4)
matmul_i_o_o_i, matmul_i_o_i = s[matmul].split(matmul_i_o_i, factor=1)
matmul_i_o_o_o, matmul_i_o_o_i = s[matmul].split(matmul_i_o_o_i, factor=2)
matmul_j_o_i, matmul_j_i = s[matmul].split(matmul_j, factor=8)
matmul_j_o_o_i, matmul_j_o_i = s[matmul].split(matmul_j_o_i, factor=1)
matmul_j_o_o_o, matmul_j_o_o_i = s[matmul].split(matmul_j_o_o_i, factor=1)
matmul_k_o, matmul_k_i = s[matmul].split(matmul_k, factor=4)
s[matmul].reorder(matmul_i_o_o_o, matmul_j_o_o_o, matmul_i_o_o_i, matmul_j_o_o_i, matmul_k_o, matmul_i_o_i, matmul_j_o_i, matmul_k_i, matmul_i_i, matmul_j_i)
out_i_o_i, out_i_i = s[out].split(out_i, factor=4)
out_i_o_o, out_i_o_i = s[out].split(out_i_o_i, factor=2)
out_j_o_i, out_j_i = s[out].split(out_j, factor=8)
out_j_o_o, out_j_o_i = s[out].split(out_j_o_i, factor=1)
s[out].reorder(out_i_o_o, out_j_o_o, out_i_o_i, out_j_o_i, out_i_i, out_j_i)
s[matmul].compute_at(s[out], out_j_o_i)
out_i_o_o_j_o_o_fused = s[out].fuse(out_i_o_o, out_j_o_o)
s[out].parallel(out_i_o_o_j_o_o_fused)
s[matmul].pragma(matmul_i_o_o_o, "auto_unroll_max_step", 8)
s[matmul].pragma(matmul_i_o_o_o, "unroll_explicit", True)
s[matmul].vectorize(matmul_j_i)
s[out].vectorize(out_j_i)
恢复搜索则更为复杂,需要自己创建搜索策略和 cost model,并通过日志文件恢复搜索策略和 cost model 的状态。下面的示例进行了 5 次试验来恢复它们的状态:
def resume_search(task, log_file):print("Resume search:")cost_model = auto_scheduler.XGBModel()cost_model.update_from_file(log_file)search_policy = auto_scheduler.SketchPolicy(task, cost_model, init_search_callbacks=[auto_scheduler.PreloadMeasuredStates(log_file)])tune_option = auto_scheduler.TuningOptions(num_measure_trials=5, measure_callbacks=[auto_scheduler.RecordToFile(log_file)])task.tune(tune_option, search_policy=search_policy)resume_search(task, log_file)
输出结果:
Resume search:
/usr/local/lib/python3.7/dist-packages/xgboost/training.py:17: UserWarning: Old style callback is deprecated. See: https://xgboost.readthedocs.io/en/latest/python/callbacks.htmlwarnings.warn(f'Old style callback is deprecated. See: {link}', UserWarning)
最后的说明和总结
本教程展示了如何在不指定搜索模板的情况下,使用 TVM Auto-Scheduler 自动优化矩阵乘法。从张量表达式(TE)语言开始,演示了一系列关于 TVM 如何优化计算操作的示例。
下载 Python 源代码:auto_scheduler_matmul_x86.py
下载 Jupyter Notebook:auto_scheduler_matmul_x86.ipynb
以上就是该文档的全部内容,查看更多 TVM 中文文档,请访问→https://tvm.hyper.ai/
相关文章:

使用 Auto-scheduling 优化算子
本篇回答来源于 TVM 官方英文文档 Lianmin Zheng,Chengfan Jia。更多 TVM 中文文档可访问→https://tvm.hyper.ai/ 本教程将展示 TVM 的 Auto Scheduling 功能,如何在不编写自定义模板的情况下,找到最佳 schedule。 与基于模板的 AutoTVM 依…...
智能运维应用之道,告别企业数字化转型危机
面临的问题及挑战 数据中心发展历程 2000 年中国数据中心始建,至今已经历以下 3 大阶段。早期:离散型数据中心 IT 因以项目建设为导向,故缺乏规划且无专门运维管理体系,此外,开发建设完的项目均是独立运维维护&#…...

第七章 SQL错误信息 - SQL错误代码 -400 到 -500
文章目录第七章 SQL错误信息 - SQL错误代码 -400 到 -500SQL错误代码和消息表WinSock错误代码-10050到-11002第七章 SQL错误信息 - SQL错误代码 -400 到 -500 SQL错误代码和消息表 错误代码描述-400发生严重错误-401严重连接错误-402用户名/密码无效-405无法从通信设备读取-4…...

DDFN: Decoupled Dynamic Filter Networks解耦的动态卷积
一、论文信息 论文名称:Decoupled Dynamic Filter Networks 论文:https://thefoxofsky.github.io/files/ddf.pdf 代码:https://github.com/theFoxofSky/ddfnet 主页:https://thefoxofsky.github.io/project_pages/ddf 作者团…...

NISP认证报名条件是什么?考试内容是什么?
科学技术是社会发展的第一生产力,每个国家为了能够获得更高的国际地位,不断提升自己的科学技术,现代最为先进的技术就是信息通信,在军事、民生、医疗、教育、制造等等领域都起着重要的作用,我们的生活也因为信息技术而…...

利用redis实现缓存、发布订阅、分布式锁功能
Redis是一个内存键值存储数据库,通常用于缓存、会话管理、消息队列等场景。以下是一些常见的Redis使用场景:1.缓存:将常用的数据缓存在Redis中,以减少对数据库的访问次数,提高应用程序的性能。2.会话管理:使…...
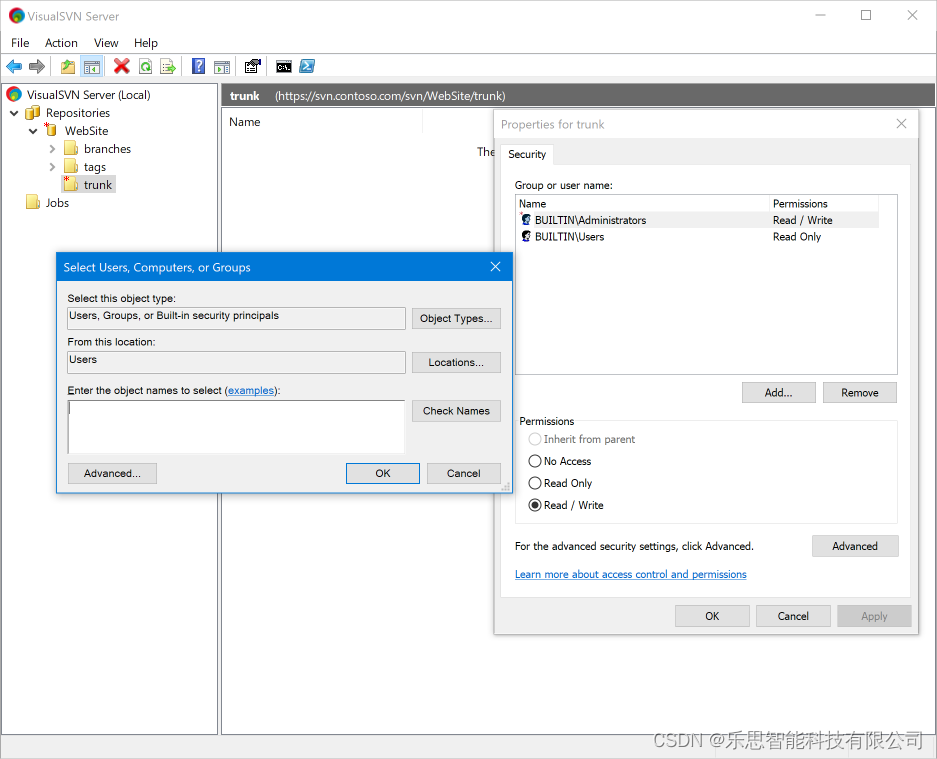
SVN无法连接到服务器的各种问题原因及解决办法
SVN专业使用教程详解 第一节 安装VisualSVN Server服务器 第一步 下载SVN服务器,需要链接的请私信。 点击下载的执行文档进行安装 选择组件 选择在部署 VisualSVN Server 时安装VisualSVN Server 和 Administration Tools 组件。 调整初始服务器配置 或者&…...

React 基本使用
目录 React 安装 React基本使用 React脚手架 脚手架使用React JSX基本使用 JSX列表渲染 JSX条件渲染 JSX模板精简 JSX样式控制 JSX综合案例 React 安装 npm i react react-domnpm init -y(生成基础目录文件) <!-- 引入js文件 --><sc…...
单例模式设计(面试题)
1、static修饰变量规则static修饰的静态成员属于 类而不是对象,所有的对象共享一份静态成员数据,所以不占用类的空间static修饰的成员,定义类的时候,必须分配空间static修饰的静态成员数据 必须类中定义 类外初始化静态成员变量可…...
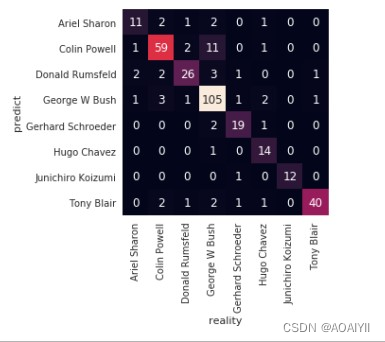
机器学习:基于支持向量机(SVM)进行人脸识别预测
机器学习:基于支持向量机(SVM)进行人脸识别预测 文章目录机器学习:基于支持向量机(SVM)进行人脸识别预测一、实验目的二、实验原理三、实验环境四、实验内容五、实验步骤1.准备数据2.业务理解3.数据理解4.数…...

【服务器数据恢复】多块磁盘离线导致RAIDZ崩溃的数据恢复案例
服务器数据恢复环境: SUN ZFS系列某型号存储阵列; 40块磁盘组建的存储池(其中4块磁盘用作全局热备盘),池内划分出若干空间映射到服务器使用; 服务器使用Windows操作系统。 服务器故障: 服务器在…...

iconfont 图标如何在uniapp中的tabBar使用
注意: 小程序并不支持tabBar中 设置 iconfont 1. 材料准备 首先进入字体图标网址:iconfont-阿里巴巴矢量图标库;(如果你没有登入,记得登入一下) 把图标添加入购物车 添加到购物车之后-(右上角…...
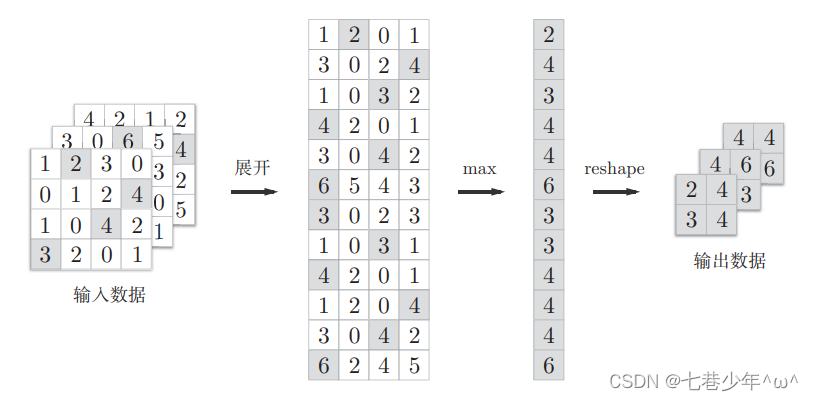
第六章.卷积神经网络(CNN)—卷积层(Convolution)池化层(Pooling)
第六章.卷积神经网络(CNN) 6.1 卷积层(Convolution)&池化层(Pooling) 1.整体结构 以5层神经网络的实现为例: 1).基于全连接层(Affine)的网络 全连接层:相邻层的所有神经元之间都有连接 2).常见的CNN的网络 3).全连接层存在的问题 数据的形状容易被…...
c/c++开发,无可避免的模板编程实践(篇六)
一、泛型算法 1.1 泛型算法概述 c标准库不仅包含数据结构(容器、容器适配器等),还有很多算法。数据结构可以帮助存放特定情况下需要保存的数据,而算法则会将数据结构中存储的数据进行变换。标准库没有给容器添加大量的功能函数&am…...
【Java】Spring核心与设计思想
文章目录Spring核心与设计思想1. Spring是什么1.1 什么是容器1.2 什么是IOC1.2.1 传统程序开发1.2.2 控制反转式程序开发1.2.3 对比总结规律1.3 理解Spring IOC1.4 DI概念说明Spring核心与设计思想 1. Spring是什么 我们通常所说的Spring指的是Spring Framework(S…...

组合实现多类别分割(含实战代码)
来源:投稿 作者:AI浩 编辑:学姐 摘要 segmentation_models_pytorch是一款非常优秀的图像分割库,albumentations是一款非常优秀的图像增强库,这篇文章将这两款优秀结合起来实现多类别的图像分割算法。数据集选用CamVid…...

从红队视角看AWD攻击
AWD的权限维持 攻防兼备AWD模式是一种综合考核参赛团队攻击、防御技术能力、即时策略的比赛模式。在攻防模式中,参赛队伍分别防守同样配置的虚拟靶机,并在有限的博弈时间内,找到其他战队的薄弱环节进行攻击,同时要对自己的靶机环…...

龙腾万里,福至万家——“北京龙文化促进协会第九届龙抬头传承会”在京举办
2023年2月21日(农历2月初二)上午9:00点至下午13:00,由北京龙文化促进协会主办、传世经典(北京)文化发展有限公司承办、北京华夏龙文旅联盟协办的“北京龙文化促进协会第九届二月二龙抬头传承会”在北京市丰台区顺和国际大厦A口6层会议厅隆重召开。 传承会活动内容主…...
)
《软件方法》强化自测题-业务建模(4)
按照业务建模、需求、分析、设计工作流考察,答案不直接给出,可访问自测链接或扫二维码自测,做到全对才能知道答案。 知识点见《软件方法》(http://www.umlchina.com/book/softmeth.html)、 “软件需求设计方法学全程…...
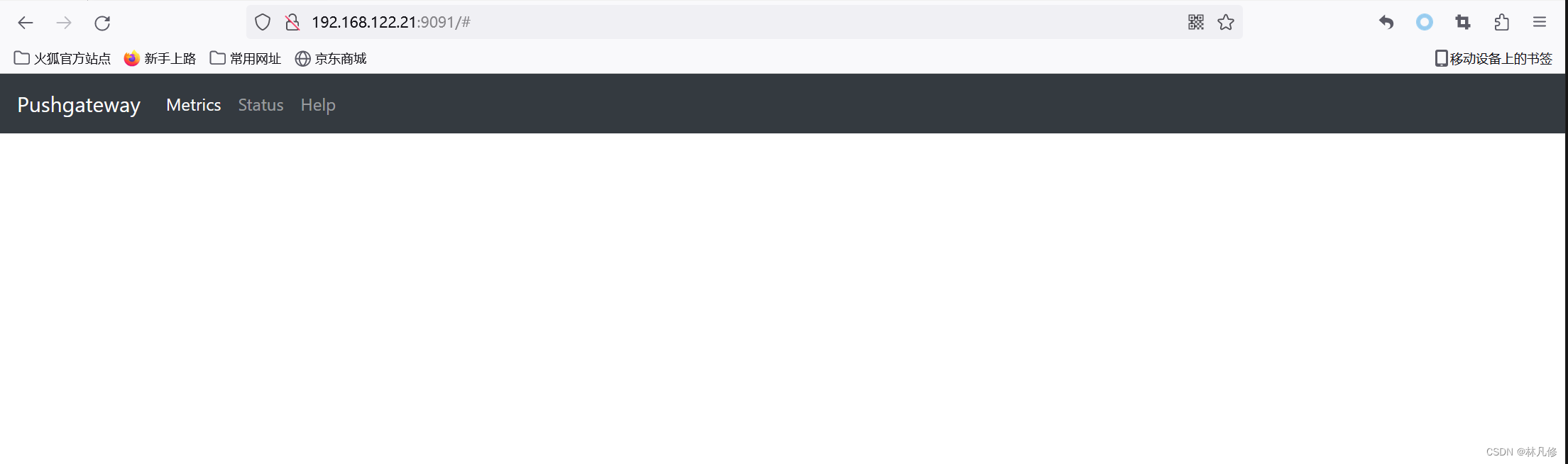
Prometheus之pushgateway
Pushgateway简介 Pushgateway是Prometheus监控系统中的一个重要组件,它采用被动push的方式获取数据,由应用主动将数据推送到pushgateway,然后Prometheus再从Pushgateway抓取数据。使用Pushgateway的主要原因是: Prometheus和targ…...

DeepSeek linux-6.19/kernel/events/ring_buffer.c 源码分析
我来分析 Linux 6.19 内核中 kernel/events/ring_buffer.c 的源码。这个文件实现了 perf events 子系统的环形缓冲区管理,用于在内核和用户空间之间高效传递性能事件数据。 文件概述 ring_buffer.c 是 perf events 系统的核心组件,负责管理用于存储性能事…...

Qwen3-TTS在VSCode中的开发调试技巧:从语音克隆到音色设计
Qwen3-TTS在VSCode中的开发调试技巧:从语音克隆到音色设计 1. 开发环境搭建 1.1 Python虚拟环境配置 在VSCode中开发Qwen3-TTS项目,首先需要配置合适的Python环境。推荐使用conda或venv创建独立的虚拟环境,避免依赖冲突。 # 使用conda创建…...
)
【学习笔记】C++(2)
C++学习笔记 三、进阶 —— 类和对象 1、概述 2、基础 —— 公有、私有、保护、构造、析构 3、拷贝构造、临时对象不能绑定到非const引用问题 4、浅拷贝、深拷贝、移动拷贝 5、静态 6、内联和外联 7、链表 8、函数模板和类模板 9、友元 10、继承-派生(1) —— 基础 11、继承-…...

OpenClaw硬件优化:Qwen2.5-VL-7B在低配设备上的运行技巧
OpenClaw硬件优化:Qwen2.5-VL-7B在低配设备上的运行技巧 1. 为什么要在低配设备上运行OpenClaw? 去年夏天,我在一台2018款MacBook Air(8GB内存)上第一次尝试部署OpenClaw时,系统几乎瞬间卡死。这让我意识…...

【逆向实战】Unity3D+il2cpp手游反编译与逻辑修改全流程解析【IDA Pro+il2CppDumper】
1. 从零开始理解Unity3Dil2cpp逆向 第一次接触手游逆向的朋友可能会被"il2cpp"这个术语吓到。其实简单来说,il2cpp就是Unity3D用来提升游戏性能的编译方案——它把C#代码先转成C,再编译成原生机器码。这种架构虽然让游戏跑得更快,但…...

STM32驱动X-NUCLEO-IHM02A1实现工业级步进电机控制
1. X-NUCLEO-IHM02A1 驱动开发深度解析:面向工业级步进电机控制的 STM32 底层实现 X-NUCLEO-IHM02A1 是意法半导体(STMicroelectronics)推出的高性能双通道步进电机驱动扩展板,专为 STM32 Nucleo 开发平台设计。该板基于 STSPIN22…...

3种方案玩转赛博朋克2077存档修改:从入门到精通的技术指南
3种方案玩转赛博朋克2077存档修改:从入门到精通的技术指南 【免费下载链接】CyberpunkSaveEditor A tool to edit Cyberpunk 2077 sav.dat files 项目地址: https://gitcode.com/gh_mirrors/cy/CyberpunkSaveEditor 赛博朋克2077存档编辑器是一款专业级游戏数…...

场效应管MOS
场效应管 场效应管又称场效应晶体管(Field Effect Transistor,缩写为FET),它与三极管一样,具有放大能力。场效应管有漏极(D极)、栅极(G极)和源极(S极…...

雷达目标分类及宽带测角方案设计实现
本文参考,仅供学习使用基于飞腾M6678的雷达目标 分类和宽带测角研究与实现硬件计算平台介绍1. 飞腾M6678芯片核心参数与优势飞腾M6678是国防科技大学自主研发的国产多核DSP,专为数字信号处理设计,核心特性为:硬件资源:…...

d3d8to9:Direct3D 8到9的API转换解决方案及技术实现
d3d8to9:Direct3D 8到9的API转换解决方案及技术实现 【免费下载链接】d3d8to9 A D3D8 pseudo-driver which converts API calls and bytecode shaders to equivalent D3D9 ones. 项目地址: https://gitcode.com/gh_mirrors/d3/d3d8to9 诊断D3D8游戏兼容性问题…...