组合实现多类别分割(含实战代码)
来源:投稿 作者:AI浩
编辑:学姐
摘要
segmentation_models_pytorch是一款非常优秀的图像分割库,albumentations是一款非常优秀的图像增强库,这篇文章将这两款优秀结合起来实现多类别的图像分割算法。数据集选用CamVid数据集,类别有:sky,building,pole,road,pavement,tree,signsymbol,fence,car,pedestrian,bicyclist,unlabelled等12个类别。数据量不大,下载地址:mirrors/alexgkendall/segnet-tutorial·GitCode。
通过这篇文章,你可以学习到:
1、如何在图像分割使用albumentations增强算法?
2、如何使用dice_loss和cross_entropy_loss?
3、如何segmentation_models_pytorch构架UNET++模型?
4、如何对分割数据做one-hot编码?
项目结构
项目的结构如下:
训练
新建train.py,插入一下代码:
import os
import numpy as np
import cv2
import albumentations as albu
import torch
import segmentation_models_pytorch as smp
from torch.utils.data import DataLoader
from torch.utils.data import Dataset as BaseDataset
导入需要的安装包,接下来编写数据载入部分。
# ---------------------------------------------------------------
### 加载数据
# CamVid数据集中用于图像分割的所有标签类别
CLASSES = ['sky', 'building', 'pole', 'road', 'pavement','tree', 'signsymbol', 'fence', 'car','pedestrian', 'bicyclist', 'unlabelled']
class Dataset(BaseDataset):"""CamVid数据集。进行图像读取,图像增强增强和图像预处理.Args:images_dir (str): 图像文件夹所在路径masks_dir (str): 图像分割的标签图像所在路径class_values (list): 用于图像分割的所有类别数augmentation (albumentations.Compose): 数据传输管道preprocessing (albumentations.Compose): 数据预处理"""def __init__(self,images_dir,masks_dir,augmentation=None,preprocessing=None,):self.ids = os.listdir(images_dir)self.images_fps = [os.path.join(images_dir, image_id) for image_id in self.ids]self.masks_fps = [os.path.join(masks_dir, image_id) for image_id in self.ids]# convert str names to class values on masksself.class_values = list(range(len(CLASSES)))self.augmentation = augmentationself.preprocessing = preprocessingdef __getitem__(self, i):# read dataimage = cv2.imread(self.images_fps[i])image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)mask = cv2.imread(self.masks_fps[i], 0)# 从标签中提取特定的类别 (e.g. cars)masks = [(mask == v) for v in self.class_values]mask = np.stack(masks, axis=-1).astype('float')# 图像增强应用if self.augmentation:sample = self.augmentation(image=image, mask=mask)image, mask = sample['image'], sample['mask']# 图像预处理应用if self.preprocessing:sample = self.preprocessing(image=image, mask=mask)image, mask = sample['image'], sample['mask']print(mask.shape)return image, maskdef __len__(self):return len(self.ids)
定义类别。类别的顺序对应mask的类别。
self.images_fps和self.masks_fps是图片的list和对应的mask图片的list。
self.class_values,类别对应的index,index的值对应mask上的类别值。
self.augmentation数据增强,使用albumentations增强。self.preprocessing数据的预处理,包含归一化和标准化,预处理的方法来自smp.encoders.get_preprocessing_fn(ENCODER, ENCODER_WEIGHTS)。
接下来,解释__getitem__函数的内容:读取图片。
将图片转为RGB,cv2读取图片,默认是BGR,所以需要做转化。
接下来两行代码,实现将mask转为one-hot编码。输入的shape是(360,480)输出是(360,480,12)
图像增强。
图像预处理。
然后返回预处理后的图片和mask。
接下来是图片增强的代码:
def get_training_augmentation():train_transform = [albu.HorizontalFlip(p=0.5),albu.ShiftScaleRotate(scale_limit=0.5, rotate_limit=0, shift_limit=0.1, p=1, border_mode=0),albu.PadIfNeeded(min_height=384, min_width=480, always_apply=True, border_mode=0),albu.IAAAdditiveGaussianNoise(p=0.2),albu.IAAPerspective(p=0.5),albu.OneOf([albu.CLAHE(p=1),albu.RandomBrightness(p=1),albu.RandomGamma(p=1),],p=0.9,),albu.OneOf([albu.IAASharpen(p=1),albu.Blur(blur_limit=3, p=1),albu.MotionBlur(blur_limit=3, p=1),],p=0.9,),albu.OneOf([albu.RandomContrast(p=1),albu.HueSaturationValue(p=1),],p=0.9,),]return albu.Compose(train_transform)def get_validation_augmentation():"""调整图像使得图片的分辨率长宽能被32整除"""test_transform = [albu.PadIfNeeded(384, 480)]return albu.Compose(test_transform)def to_tensor(x, **kwargs):return x.transpose(2, 0, 1).astype('float32')def get_preprocessing(preprocessing_fn):"""进行图像预处理操作Args:preprocessing_fn (callbale): 数据规范化的函数(针对每种预训练的神经网络)Return:transform: albumentations.Compose"""_transform = [albu.Lambda(image=preprocessing_fn),albu.Lambda(image=to_tensor, mask=to_tensor),]return albu.Compose(_transform)
首先,我们一起查看get_training_augmentation里面的代码。这里比较复杂。这些需要注意的是PadIfNeeded方法。
由于UNet系列的文章经历了5次缩放,所以图片必须被32整除。所以通过填充的方式将图片的尺寸改为(384,480)。
同样,在验证集也要做这样的操作。 to_tensor函数是将图片的值转为tensor,并将维度做交换。由于cv2读取的图片和mask的onehot的维度都是(W,H,C),需要高改为(C,W,H)。
get_preprocessing是对数据做预处理,有归一化和标准化,然后,将图片和mask转为to_tensor。
接下来,将最重要的训练部分:
# $# 创建模型并训练
# ---------------------------------------------------------------
if __name__ == '__main__':ENCODER = 'efficientnet-b1'ENCODER_WEIGHTS = 'imagenet'ACTIVATION = 'softmax' # could be None for logits or 'softmax2d' for multiclass segmentationDEVICE = 'cuda'# 使用unet++模型model = smp.UnetPlusPlus(encoder_name=ENCODER,encoder_weights=ENCODER_WEIGHTS,classes=len(CLASSES),activation=ACTIVATION,)preprocessing_fn = smp.encoders.get_preprocessing_fn(ENCODER, ENCODER_WEIGHTS)
这部分的代码主要是定义模型。
模型选用unet++,解码器是efficientnet-b1,预训练权重为:imagenet。 定义类别。
preprocessing_fn获取 smp.encoders的预处理方法。
# 数据集所在的目录DATA_DIR = './data/CamVid/'# 如果目录下不存在CamVid数据集,则克隆下载if not os.path.exists(DATA_DIR):print('Loading data...')os.system('git clone https://github.com/alexgkendall/SegNet-Tutorial ./data')print('Done!')# 训练集x_train_dir = os.path.join(DATA_DIR, 'train')y_train_dir = os.path.join(DATA_DIR, 'trainannot')# 验证集x_valid_dir = os.path.join(DATA_DIR, 'val')y_valid_dir = os.path.join(DATA_DIR, 'valannot')# 加载训练数据集train_dataset = Dataset(x_train_dir,y_train_dir,augmentation=get_training_augmentation(),preprocessing=get_preprocessing(preprocessing_fn))# 加载验证数据集valid_dataset = Dataset(x_valid_dir,y_valid_dir,augmentation=get_validation_augmentation(),preprocessing=get_preprocessing(preprocessing_fn))# 需根据显卡的性能进行设置,batch_size为每次迭代中一次训练的图片数,num_workers为训练时的工作进程数,如果显卡不太行或者显存空间不够,将batch_size调低并将num_workers调为0train_loader = DataLoader(train_dataset, batch_size=2, shuffle=True, num_workers=0)valid_loader = DataLoader(valid_dataset, batch_size=1, shuffle=False, num_workers=0)
这部分的代码主要是数据集加载。
定义数据集所在路径。
获取训练集和验证集的路径。
加载训练集和验证集。
将训练集和测试集放入DataLoader中,根据显卡的大小定义batch_size,训练集需要shuffle,验证集不需要。
然后,定义loss
loss = smp.utils.losses.DiceLoss() + smp.utils.losses.CrossEntropyLoss()metrics = [smp.utils.metrics.IoU(threshold=0.5),smp.utils.metrics.Recall()]optimizer = torch.optim.Adam([dict(params=model.parameters(), lr=0.0001),])
loss是DiceLoss和CrossEntropyLoss组合。
评分标准为IoU和Recall。
优化器选用Adam。
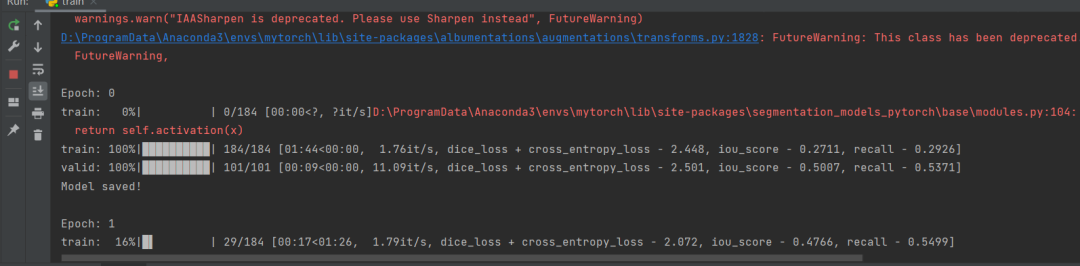
# 创建一个简单的循环,用于迭代数据样本train_epoch = smp.utils.train.TrainEpoch(model,loss=loss,metrics=metrics,optimizer=optimizer,device=DEVICE,verbose=True,)valid_epoch = smp.utils.train.ValidEpoch(model,loss=loss,metrics=metrics,device=DEVICE,verbose=True,)# 进行40轮次迭代的模型训练max_score = 0for i in range(0, 40):print('\nEpoch: {}'.format(i))train_logs = train_epoch.run(train_loader)valid_logs = valid_epoch.run(valid_loader)# 每次迭代保存下训练最好的模型if max_score < valid_logs['iou_score']:max_score = valid_logs['iou_score']torch.save(model, './best_model.pth')print('Model saved!')if i == 25:optimizer.param_groups[0]['lr'] = 1e-5print('Decrease decoder learning rate to 1e-5!')
创建TrainEpoch和ValidEpoch循环用来迭代数据集。
按照迭代次数循环,保存最好的模型。
完成上面的工作后就可以开始训练了。
测试
完成训练后就开始测试部分。
import osimport albumentations as albu
import cv2
import matplotlib.pyplot as plt
import numpy as np
import segmentation_models_pytorch as smp
import torch
from torch.utils.data import Dataset as BaseDatasetos.environ['CUDA_VISIBLE_DEVICES'] = '0'
导入所需要的包
# ---------------------------------------------------------------
### 加载数据
# CamVid数据集中用于图像分割的所有标签类别
CLASSES = ['sky', 'building', 'pole', 'road', 'pavement','tree', 'signsymbol', 'fence', 'car','pedestrian', 'bicyclist', 'unlabelled']
class Dataset(BaseDataset):"""CamVid数据集。进行图像读取,图像增强增强和图像预处理.Args:images_dir (str): 图像文件夹所在路径masks_dir (str): 图像分割的标签图像所在路径class_values (list): 用于图像分割的所有类别数augmentation (albumentations.Compose): 数据传输管道preprocessing (albumentations.Compose): 数据预处理"""def __init__(self,images_dir,masks_dir,augmentation=None,preprocessing=None,):self.ids = os.listdir(images_dir)self.images_fps = [os.path.join(images_dir, image_id) for image_id in self.ids]self.masks_fps = [os.path.join(masks_dir, image_id) for image_id in self.ids]# convert str names to class values on masksself.class_values = list(range(len(CLASSES)))self.augmentation = augmentationself.preprocessing = preprocessingdef __getitem__(self, i):# read dataimage = cv2.imread(self.images_fps[i])image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)mask = cv2.imread(self.masks_fps[i], 0)# 从标签中提取特定的类别 (e.g. cars)masks = [(mask == v) for v in self.class_values]mask = np.stack(masks, axis=-1).astype('float')# 图像增强应用if self.augmentation:sample = self.augmentation(image=image, mask=mask)image, mask = sample['image'], sample['mask']# 图像预处理应用if self.preprocessing:sample = self.preprocessing(image=image, mask=mask)image, mask = sample['image'], sample['mask']return image, maskdef __len__(self):return len(self.ids)# ---------------------------------------------------------------
### 图像增强def get_validation_augmentation():"""调整图像使得图片的分辨率长宽能被32整除"""test_transform = [albu.PadIfNeeded(384, 480)]return albu.Compose(test_transform)def to_tensor(x, **kwargs):return x.transpose(2, 0, 1).astype('float32')def get_preprocessing(preprocessing_fn):"""进行图像预处理操作Args:preprocessing_fn (callbale): 数据规范化的函数(针对每种预训练的神经网络)Return:transform: albumentations.Compose"""_transform = [albu.Lambda(image=preprocessing_fn),albu.Lambda(image=to_tensor, mask=to_tensor),]return albu.Compose(_transform)
上面的代码是数据加载和数据增强,和训练集的代码一样。
# 图像分割结果的可视化展示
def visualize(**images):"""PLot images in one row."""n = len(images)plt.figure(figsize=(16, 5))for i, (name, image) in enumerate(images.items()):plt.subplot(1, n, i + 1)plt.xticks([])plt.yticks([])plt.title(' '.join(name.split('_')).title())plt.imshow(image)plt.show()
可视化测试结果,展示原图,真实的mask,预测的mask。
# ---------------------------------------------------------------
if __name__ == '__main__':DATA_DIR = './data/CamVid/'# 测试集x_test_dir = os.path.join(DATA_DIR, 'test')y_test_dir = os.path.join(DATA_DIR, 'testannot')ENCODER = 'efficientnet-b1'ENCODER_WEIGHTS = 'imagenet'ACTIVATION = 'softmax' # could be None for logits or 'softmax2d' for multiclass segmentationDEVICE = 'cuda'preprocessing_fn = smp.encoders.get_preprocessing_fn(ENCODER, ENCODER_WEIGHTS)# ---------------------------------------------------------------# $# 测试训练出来的最佳模型# 加载最佳模型best_model = torch.load('./best_model.pth')# 创建测试数据集test_dataset = Dataset(x_test_dir,y_test_dir,augmentation=get_validation_augmentation(),preprocessing=get_preprocessing(preprocessing_fn),)# ---------------------------------------------------------------# $# 图像分割结果可视化展示# 对没有进行图像处理转化的测试集进行图像可视化展示test_dataset_vis = Dataset(x_test_dir, y_test_dir)# 从测试集中随机挑选3张图片进行测试for i in range(3):n = np.random.choice(len(test_dataset))image_vis = test_dataset_vis[n][0].astype('uint8')image, gt_mask = test_dataset[n]gt_mask = (np.argmax(gt_mask, axis=0) * 255 / (gt_mask.shape[0])).astype(np.uint8)x_tensor = torch.from_numpy(image).to(DEVICE).unsqueeze(0)pr_mask = best_model.predict(x_tensor)pr_mask = (pr_mask.squeeze().cpu().numpy())pr_mask = (np.argmax(pr_mask, axis=0) * 255 / (pr_mask.shape[0])).astype(np.uint8)# 恢复图片原来的分辨率gt_mask = cv2.resize(gt_mask, (480, 360))pr_mask = cv2.resize(pr_mask, (480, 360))visualize(image=image_vis,ground_truth_mask=gt_mask,predicted_mask=pr_mask)
获取测试集的路径。
定义ENCODER 为 efficientnet-b1,ENCODER_WEIGHTS为imagenet,ACTIVATION为softmax。
获取预训练参数。
加载模型。
加载数据集。
加载没有做处理的图片。
随机选择3张图片从test_dataset_vis获取图片。
从test_dataset获取对应的图片和mask。
将mask放大255的范围。
预测图片,生成预测的mask。
将预测的mask也对应的放到255的范围。
然后重新resize到原来的尺寸。
可视化结果。
运行结果:



CVPR图像分割必读论文🚀🚀🚀
关注下方卡片《学姐带你玩AI》
回复“CVPR”免费领取
码字不易,欢迎大家点赞评论收藏!
引用 https://blog.csdn.net/hhhhhhhhhhwwwwwwwwww/article/details/124086830
相关文章:
组合实现多类别分割(含实战代码)
来源:投稿 作者:AI浩 编辑:学姐 摘要 segmentation_models_pytorch是一款非常优秀的图像分割库,albumentations是一款非常优秀的图像增强库,这篇文章将这两款优秀结合起来实现多类别的图像分割算法。数据集选用CamVid…...

从红队视角看AWD攻击
AWD的权限维持 攻防兼备AWD模式是一种综合考核参赛团队攻击、防御技术能力、即时策略的比赛模式。在攻防模式中,参赛队伍分别防守同样配置的虚拟靶机,并在有限的博弈时间内,找到其他战队的薄弱环节进行攻击,同时要对自己的靶机环…...

龙腾万里,福至万家——“北京龙文化促进协会第九届龙抬头传承会”在京举办
2023年2月21日(农历2月初二)上午9:00点至下午13:00,由北京龙文化促进协会主办、传世经典(北京)文化发展有限公司承办、北京华夏龙文旅联盟协办的“北京龙文化促进协会第九届二月二龙抬头传承会”在北京市丰台区顺和国际大厦A口6层会议厅隆重召开。 传承会活动内容主…...
)
《软件方法》强化自测题-业务建模(4)
按照业务建模、需求、分析、设计工作流考察,答案不直接给出,可访问自测链接或扫二维码自测,做到全对才能知道答案。 知识点见《软件方法》(http://www.umlchina.com/book/softmeth.html)、 “软件需求设计方法学全程…...
Prometheus之pushgateway
Pushgateway简介 Pushgateway是Prometheus监控系统中的一个重要组件,它采用被动push的方式获取数据,由应用主动将数据推送到pushgateway,然后Prometheus再从Pushgateway抓取数据。使用Pushgateway的主要原因是: Prometheus和targ…...
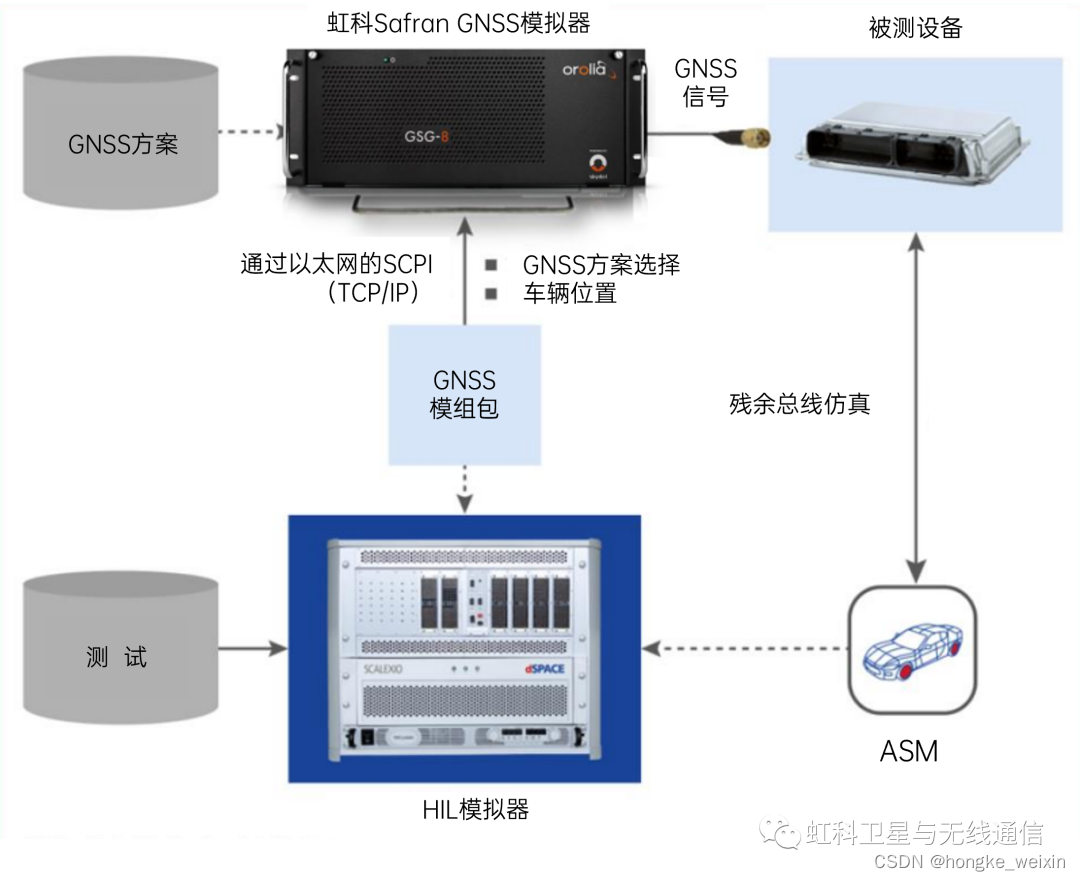
3分钟带您快速了解HIL测试及其架构
什么是HIL测试硬件在环(HIL)仿真是一种用于测试导航系统的技术,其中测试前并不知道车辆轨迹。在这种情况下,车辆轨迹被实时馈送到GNSS模拟器。HIL可用于复杂实时系统的开发和测试,如卫星控制系统、军事战术导弹、飞机飞…...

华为认证含金量如何?
一本证书是否有用,还要看它是否被市场所认可。 我们说华为认证HCIP有用,很大一部分还取决于它极高的适用性和权威性。华为是国内最大的生产销售通信设备的民营通信科技公司。 自2013年起,国家对网络安全极度重视,相继把国外的网…...

刷题记录:牛客NC54586小翔和泰拉瑞亚
传送门:牛客 题目描述: 小翔爱玩泰拉瑞亚 。 一天,他碰到了一幅地图。这幅地图可以分为n列,第i列的高度为Hi,他认为这个地图不好看,决定对它进行改造。 小翔又学会了m个魔法,实施第i个魔法可以使地图的第Li列到第Ri列…...
面试个3年自动化测试,测试水平一言难尽。。。。
公司前段缺人,也面了不少测试,结果竟然没有一个合适的。 一开始瞄准的就是中级的水准,也没指望来大牛,提供的薪资在10-20k,面试的人很多,但平均水平很让人失望。 看简历很多都是3年工作经验,但…...
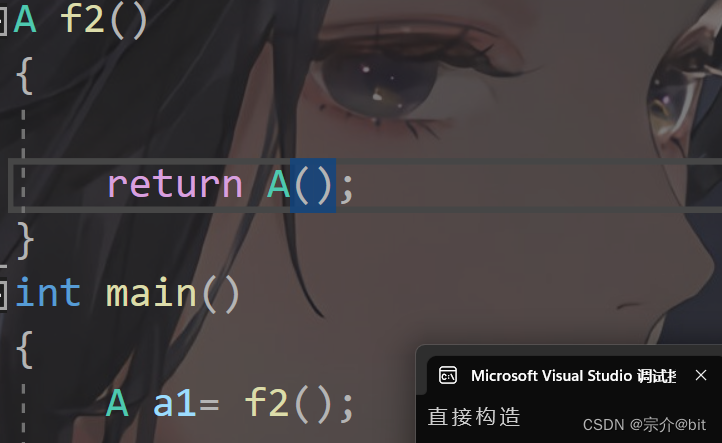
C++面向对象(下)
文章目录前言1.再谈构造函数1.初始化列表2.explicit关键字2. static成员1.概念3.友元1.概念2.友元函数3.友元类4. 内部类5.匿名对象6.编译器优化7.总结前言 本文是主要是将之前关于C面向对象中的一些没有归纳到的零星知识点进行补充,同时对C中的面向对象简单收个尾…...
面试一位软件测试6年工作者:一年经验掰成六年来用....
在众多面试中,对于那个工作了6年的面试者,我印象很深刻,因为最开始拿到简历的时候,我一摸:"这简历,好厚啊!"再一看,工作6年。 于是我去找了我的领导,我说:“这人我应该没…...

Java8 新特性--Optional
Optional是什么 java.util.Optional Jdk8提供Optional,一个可以包含null值的容器对象,可以用来代替xx ! null的判断。 Optional常用方法 of public static <T> Optional<T> of(T value) {return new Optional<>(value); }为value…...

Pytorch GPU版本简明下载安装教程
1.根据自己的显卡型号下载显卡驱动并安装。这一步会更新你的显卡驱动,也可忽略第1步,如果第2步出现问题,返回执行第1步。 点击这里下载英伟达显卡驱动 2.安装完成后,wincmd打开命令行,输入nvidia-smi,查看…...
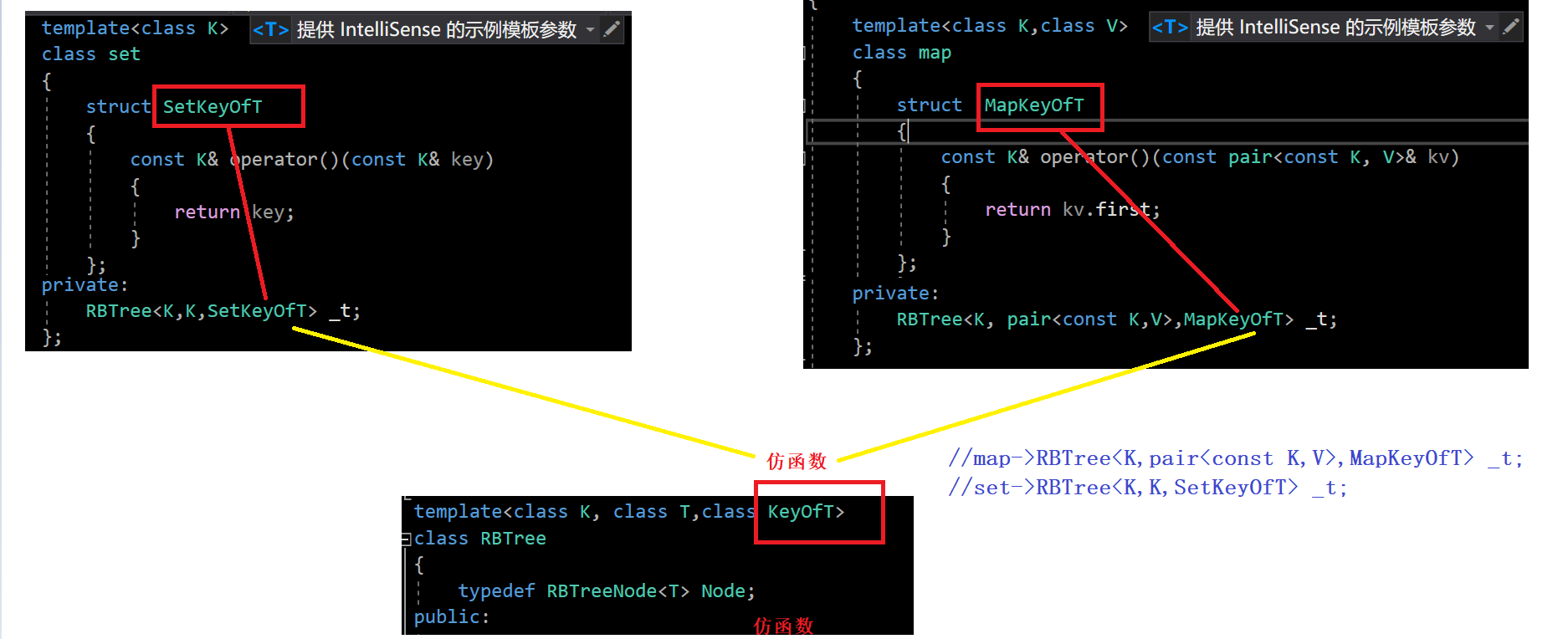
【C++】map和set的封装
文章目录一、前情回顾二、简化源码三、仿函数四、迭代器五、set的实现六、map的实现七、红黑树代码一、前情回顾 set 参数只有 key,但是map除了key还有value。我们还是需要KV模型的红黑树的: #pragma once #include <iostream> #include <ass…...

互融云金融控股集团管理平台系统搭建
金融控股公司是指对两个或两个以上不同类型金融机构拥有实质控制权,自身仅开展股权投资管理、不直接从事商业性经营活动的有限责任公司或者股份有限公司。 金融控股公司是金融业实现综合经营的一种组织形式,也是一种追求资本投资最优化、资本利润最大化…...
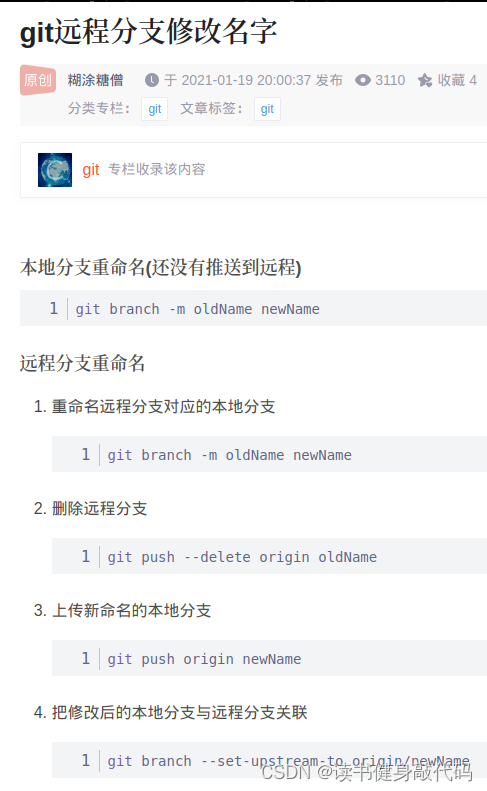
Git复习
1. 引言 现在要用到Git,复习一下关于Git的指令,知识摘自《Pro Git》 2. 起步 git和其他版本控制软件最大的差别在于git是直接记录某个版本的快照,而不是逐渐地比较差异。 安装: sudo apt install git-all设置用户信息: git c…...
---使用VertexBuffer(顶点缓冲区))
WebGPU学习(2)---使用VertexBuffer(顶点缓冲区)
在本文中,我们使用 VertexBuffer 绘制一个矩形。示例地址 1.准备顶点数据 首先,我们准备好顶点数据。定义顶点数据有多种方法,这次我们将在 TypeScript 代码中将其定义为 Float32Array 类型的数据。 const quadVertexSize 4 * 8; // 一个顶…...

【C++之容器篇】AVL树的底层原理和使用
目录前言一、AVL树二、AVL树的底层实现1. 结点类型的定义2. AVL树的定义3. 查找函数4. 插入函数(重难点)三、判断平衡树的方法前言 AVL树其实是在搜索树的基础上加上一些限制因素,从而使搜索树的结构保持相对平衡,通过前面我们对二叉搜索树的学习&#x…...
从交换机安全配置看常见局域网攻击
前言 构建零信任网络,自然离不开网络准入(NAC),这就涉及到交换机的一些安全测试,于是有了此文《从交换机安全配置看常见局域网攻击》。 交换机安全配置 如本文标题所说从交换机安全配置看常见的局域网攻击,那么下面提到的各种攻…...
工具篇3.5世界热力图
一、定义 世界热力图是一种地图形式,它使用颜色的变化来显示世界各个地区的某种指标(如 GDP、人口、气候等)的分布和密度。通常,世界热力图会使用不同的颜色来表示数据的变化,例如使用蓝色表示低值,红色表…...

文脉定序完整指南:从模型下载、镜像构建、服务启动到监控告警全流程
文脉定序完整指南:从模型下载、镜像构建、服务启动到监控告警全流程 如果你正在构建一个智能问答系统或知识库,一定遇到过这样的烦恼:系统能搜出一堆看似相关的文档,但最精准、最贴切的答案往往不在最前面。用户需要手动翻找&…...

Asian Beauty Z-Image Turbo隐私安全实践:纯本地生成如何保护商业图片数据
Asian Beauty Z-Image Turbo隐私安全实践:纯本地生成如何保护商业图片数据 1. 商业图片数据的安全挑战 在数字内容创作领域,商业图片数据的安全问题日益突出。想象一下,一家电商公司需要为新品生成模特展示图,或者一家广告公司要…...

Guohua Diffusion国风绘画工具:5分钟快速部署,小白也能画水墨神兽
Guohua Diffusion国风绘画工具:5分钟快速部署,小白也能画水墨神兽 1. 工具简介:专为国风绘画而生的AI神器 Guohua Diffusion是一款专注于国风水墨画生成的本地AI绘画工具,基于原生Guohua-Diffusion模型开发。它最大的特点就是&q…...

Kandinsky-5.0-I2V-Lite-5s多风格测试:卡通、写实、水墨画生成效果对比
Kandinsky-5.0-I2V-Lite-5s多风格测试:卡通、写实、水墨画生成效果对比 1. 开场:当静态艺术遇见动态魔法 想象一下,你珍藏的卡通插画突然活了过来,水墨画中的山水开始流动,写实照片里的场景有了生命。这正是Kandinsk…...

复古游戏新玩法:OpenClaw+Qwen3-14B实现经典游戏自动化
复古游戏新玩法:OpenClawQwen3-14B实现经典游戏自动化 1. 当AI遇见复古游戏:一场技术人的浪漫实验 去年整理旧物时,我在抽屉深处翻出一张《金庸群侠传》的光盘。这款1996年发布的经典游戏,承载着无数80后的青春记忆。当我试图在…...
)
【面板数据】A股上市公司研发投入数据(2000-2024年)
数据简介:作为评估企业创新能力与可持续发展潜力的关键维度,上市公司研发投入呈现显著的行业差异化特征,但总体保持稳健增长态势。随着信息披露监管要求的持续强化,研发投入透明度已成为提升企业市场信誉的重要抓手。值得注意的是…...

保姆级教程:用Keil5将你的STM32F103工程无缝迁移到国民技术N32G45X
从STM32F103到N32G45X:嵌入式工程师的国产MCU迁移实战指南 在嵌入式开发领域,芯片选型往往决定着项目的成败。随着国产微控制器的崛起,越来越多的工程师开始考虑将原有基于STM32的项目迁移到国产平台。国民技术的N32G45X系列以其出色的性价比…...
(Matlab代码实现))
风光负荷不同鲁棒性对系统总成本的影响研究(考虑上下备用容量)(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

号令天下:守财数字能量号组413与313能守财吗
在数字能量学的体系中,延年磁场是主导守财的核心能量,天医磁场主打招财纳福,生气磁场侧重拓展人脉,二者并不具备直接的守财属性。像 413、313 这类组合,核心作用集中在招财聚财方面,守财能力相对薄弱&#…...

OpenClaw性能调优:Qwen3-14B镜像响应速度提升3倍实操
OpenClaw性能调优:Qwen3-14B镜像响应速度提升3倍实操 1. 为什么需要性能调优? 上周我在用OpenClaw自动处理100份PDF文档时,发现一个奇怪现象:同样的任务,晚上执行比白天快得多。经过排查才发现,白天我的本…...