Kafka优化篇-压测和性能调优
简介
Kafka的配置详尽、复杂,想要进行全面的性能调优需要掌握大量信息,这里只记录一下我在日常工作使用中走过的坑和经验来对kafka集群进行优化常用的几点。
Kafka性能调优和参数调优
性能调优
JVM的优化
java相关系统自然离不开JVM的优化。首先想到的肯定是Heap Size的调整。
vim bin/kafka-server-start.sh
调整KAFKA_HEAP_OPTS="-Xmx16G -Xms16G”的值推荐配置:一般HEAP SIZE的大小不超过主机内存的50%。
网络和ios操作线程配置优化:
# broker处理消息的最大线程数,默认是3
num.network.threads=9
# broker处理磁盘IO的线程数,默认是8
num.io.threads=16推荐配置:
num.network.threads主要处理网络io,读写缓冲区数据,基本没有io等待,配置线程数量为cpu核数加1。
num.io.threads主要进行磁盘io操作,高峰期可能有些io等待,因此配置需要大些。配置线程数量为cpu核数2倍,最大不超过3倍。
socket server可接受数据大小(防止OOM异常):
#默认是100M,这里设置成200M
socket.request.max.bytes=2147483600推荐配置:
根据自己业务数据包的大小适当调大。这里取值是int类型的,而受限于java int类型的取值范围又不能太大:
java int的取值范围为(-2147483648~2147483647),占用4个字节(-2的31次方到2的31次方-1,不能超出,超出之后报错:org.apache.kafka.common.config.ConfigException: Invalid value 8589934592 for configuration socket.request.max.bytes: Not a number of type INT。
接收消息配置
#默认值是1M-1048576 (1 mebibyte),设置成2M
message.max.bytes=2097153
#分区副本同步最大的消息默认1M-1048576 (1 mebibyte),设置成2M
replica.fetch.max.bytes=2097153The number of bytes of messages to attempt to fetch for each partition. This is not an absolute maximum, if the first record batch in the first non-empty partition of the fetch is larger than this value, the record batch will still be returned to ensure that progress can be made. The maximum record batch size accepted by the broker is defined via
message.max.bytes(broker config) ormax.message.bytes(topic config).
log数据文件刷盘策略
# 每当producer写入10000条消息时,刷数据到磁盘
log.flush.interval.messages=10000
# 每间隔1秒钟时间,刷数据到磁盘
log.flush.interval.ms=1000推荐配置:
为了大幅度提高producer写入吞吐量,需要定期批量写文件。一般无需改动,如果topic的数据量较小可以考虑减少log.flush.interval.ms和log.flush.interval.messages来强制刷写数据,减少可能由于缓存数据未写盘带来的不一致。推荐配置分别message 10000,间隔1s。
日志保留策略配置
# 日志保留时长
log.retention.hours=72
# 段文件配置
log.segment.bytes=1073741824推荐配置:
日志建议保留三天,也可以更短;段文件配置1GB,有利于快速回收磁盘空间,重启kafka加载也会加快(kafka启动时是单线程扫描目录(log.dir)下所有数据文件)。如果文件过小,则文件数量比较多。
replica复制配置
num.replica.fetchers=3
replica.fetch.min.bytes=1
replica.fetch.max.bytes=5242880推荐配置:
每个follow从leader拉取消息进行同步数据,follow同步性能由这几个参数决定,分别为:
拉取线程数(num.replica.fetchers):fetcher配置多可以提高follower的I/O并发度,单位时间内leader持有更多请求,相应负载会增大,需要根据机器硬件资源做权衡,建议适当调大;
最小字节数(replica.fetch.min.bytes):一般无需更改,默认值即可;
最大字节数(replica.fetch.max.bytes):默认为1MB,这个值太小,推荐5M,根据业务情况调整
最大等待时间(replica.fetch.wait.max.ms):follow拉取频率,频率过高,leader会积压大量无效请求情况,无法进行数据同步,导致cpu飙升。配置时谨慎使用,建议默认值,无需配置。
分区数量配置
num.partitions=5推荐配置:
默认partition数量1,如果topic在创建时没有指定partition数量,默认使用此值。Partition的数量选取也会直接影响到Kafka集群的吞吐性能,配置过小会影响消费性能,建议改为5。
参数调优
一段Kafka生产端的示例代码
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("buffer.memory", 67108864);
props.put("batch.size", 131072);
props.put("linger.ms", 100);
props.put("max.request.size", 10485760);
props.put("acks", "1");
props.put("retries", 10);
props.put("retry.backoff.ms", 500);KafkaProducer<String, String> producer = new KafkaProducer<String, String>(props);内存缓冲的大小
首先我们看看“buffer.memory”这个参数是什么意思?
Kafka的客户端发送数据到服务器,一般都是要经过缓冲的,也就是说,你通过KafkaProducer发送出去的消息都是先进入到客户端本地的内存缓冲里,然后把很多消息收集成一个一个的Batch,再发送到Broker上去的。

所以这个“buffer.memory”的本质就是用来约束KafkaProducer能够使用的内存缓冲的大小的,他的默认值是32MB。
那么既然了解了这个含义,大家想一下,在生产项目里,这个参数应该怎么来设置呢?
你可以先想一下,如果这个内存缓冲设置的过小的话,可能会导致一个什么问题?
首先要明确一点,那就是在内存缓冲里大量的消息会缓冲在里面,形成一个一个的Batch,每个Batch里包含多条消息。
然后KafkaProducer有一个Sender线程会把多个Batch打包成一个Request发送到Kafka服务器上去。
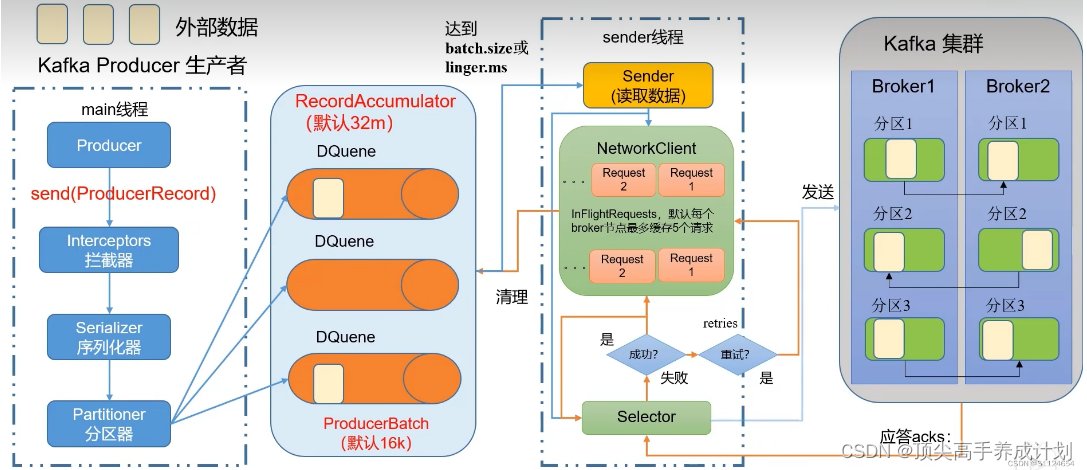
那么如果要是内存设置的太小,可能导致一个问题:消息快速的写入内存缓冲里面,但是Sender线程来不及把Request发送到Kafka服务器。
这样是不是会造成内存缓冲很快就被写满?一旦被写满,就会阻塞用户线程,不让继续往Kafka写消息了。
所以对于“buffer.memory”这个参数应该结合自己的实际情况来进行压测,你需要测算一下在生产环境,你的用户线程会以每秒多少消息的频率来写入内存缓冲。
比如说每秒300条消息,那么你就需要压测一下,假设内存缓冲就32MB,每秒写300条消息到内存缓冲,是否会经常把内存缓冲写满?经过这样的压测,你可以调试出来一个合理的内存大小。
多少数据打包为一个Batch合适?
接着你需要思考第二个问题,就是你的“batch.size”应该如何设置?这个东西是决定了你的每个Batch要存放多少数据就可以发送出去了。
比如说你要是给一个Batch设置成是16KB的大小,那么里面凑够16KB的数据就可以发送了。
这个参数的默认值是16KB,一般可以尝试把这个参数调节大一些,然后利用自己的生产环境发消息的负载来测试一下。
比如说发送消息的频率就是每秒300条,那么如果比如“batch.size”调节到了32KB,或者64KB,是否可以提升发送消息的整体吞吐量。
因为理论上来说,提升batch的大小,可以允许更多的数据缓冲在里面,那么一次Request发送出去的数据量就更多了,这样吞吐量可能会有所提升。
但是这个东西也不能无限的大,过于大了之后,要是数据老是缓冲在Batch里迟迟不发送出去,那么岂不是你发送消息的延迟就会很高。
比如说,一条消息进入了Batch,但是要等待5秒钟Batch才凑满了64KB,才能发送出去。那这条消息的延迟就是5秒钟。
所以需要在这里按照生产环境的发消息的速率,调节不同的Batch大小自己测试一下最终出去的吞吐量以及消息的 延迟,设置一个最合理的参数。
要是一个Batch迟迟无法凑满怎么办?
要是一个Batch迟迟无法凑满,此时就需要引入另外一个参数了,“linger.ms”
他的含义就是说一个Batch被创建之后,最多过多久,不管这个Batch有没有写满,都必须发送出去了。
给大家举个例子,比如说batch.size是16kb,但是现在某个低峰时间段,发送消息很慢。
这就导致可能Batch被创建之后,陆陆续续有消息进来,但是迟迟无法凑够16KB,难道此时就一直等着吗?
当然不是,假设你现在设置“linger.ms”是50ms,那么只要这个Batch从创建开始到现在已经过了50ms了,哪怕他还没满16KB,也要发送他出去了。
所以“linger.ms”决定了你的消息一旦写入一个Batch,最多等待这么多时间,他一定会跟着Batch一起发送出去。
避免一个Batch迟迟凑不满,导致消息一直积压在内存里发送不出去的情况。这是一个很关键的参数。
这个参数一般要非常慎重的来设置,要配合batch.size一起来设置。
举个例子,首先假设你的Batch是32KB,那么你得估算一下,正常情况下,一般多久会凑够一个Batch,比如正常来说可能20ms就会凑够一个Batch。
那么你的linger.ms就可以设置为25ms,也就是说,正常来说,大部分的Batch在20ms内都会凑满,但是你的linger.ms可以保证,哪怕遇到低峰时期,20ms凑不满一个Batch,还是会在25ms之后强制Batch发送出去。
如果要是你把linger.ms设置的太小了,比如说默认就是0ms,或者你设置个5ms,那可能导致你的Batch虽然设置了32KB,但是经常是还没凑够32KB的数据,5ms之后就直接强制Batch发送出去,这样也不太好其实,会导致你的Batch形同虚设,一直凑不满数据。
最大请求大小
“max.request.size”这个参数决定了每次发送给Kafka服务器请求的最大大小,同时也会限制你一条消息的最大大小也不能超过这个参数设置的值,这个其实可以根据你自己的消息的大小来灵活的调整。
给大家举个例子,你们公司发送的消息都是那种大的报文消息,每条消息都是很多的数据,一条消息可能都要20KB。
此时你的batch.size是不是就需要调节大一些?比如设置个512KB?然后你的buffer.memory是不是要给的大一些?比如设置个128MB?
只有这样,才能让你在大消息的场景下,还能使用Batch打包多条消息的机制。但是此时“max.request.size”是不是也得同步增加?
因为可能你的一个请求是很大的,默认他是1MB,你是不是可以适当调大一些,比如调节到5MB?
重试机制
“retries”和“retries.backoff.ms”决定了重试机制,也就是如果一个请求失败了可以重试几次,每次重试的间隔是多少毫秒。
这个大家适当设置几次重试的机会,给一定的重试间隔即可,比如给100ms的重试间隔。
持久化机制
“acks”参数决定了发送出去的消息要采用什么样的持久化策略,这个涉及到了很多其他的概念。
Kafka压测
用Kafka官方自带的脚本,对Kafka进行压测。Kafka压测时,可以查看到哪个地方出现了瓶颈==(CPU,内存,网络IO)。一般都是网络IO达到瓶颈。 ==
使用下面两个kafka自带的脚本
kafka-consumer-perf-test.shkafka-producer-perf-test.sh
Kafka Producer(生产)压力测试
进入kafka的安装目录,执行下面的命令
bin/kafka-producer-perf-test.sh --topic test --record-size 100 --num-records 100000 --throughput -1 --producer-props bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092说明:
record-size是一条信息有多大,单位是字节。num-records是总共发送多少条信息。throughput是每秒多少条信息,设成-1,表示不限流,可测出生产者最大吞吐量。
输出:
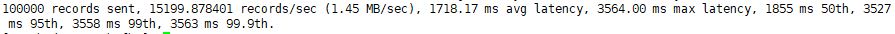
参数解析:本例中一共写入10w条消息,吞吐量为1.45 MB/sec,每次写入的平均延迟为1718.17毫秒,最大的延迟为3564.00毫秒。
Kafka Consumer(消费)压力测试
Consumer的测试,如果这四个指标(IO,CPU,内存,网络)都不能改变,考虑增加分区数来提升性能。
进入kafka的安装目录,执行下面的命令
bin/kafka-consumer-perf-test.sh --broker-list hadoop102:9092,hadoop103:9092,hadoop104:9092 --topic test --fetch-size 10000 --messages 10000000 --threads 1参数说明:
--zookeeper 指定zookeeper的链接信息。
--topic 指定topic的名称。
--fetch-size 指定每次fetch的数据的大小。
--messages 总共要消费的消息个数。
输出:

start.time开始时间:2021-01-27 13:55:20:963。end.time结束时间:2021-01-27 13:55:36:555。data.consumed.in.MB共消费数据:22.1497MB。MB.sec吞吐量:1.4206MB/sec。data.consumed.in.nMsg共消费消息条数:232256条。nMsg.sec平均每秒消费条数:14895.8440条。
计算Kafka分区数
- 创建一个只有1个分区的topic。
- 测试这个topic的producer吞吐量(1.45m/s)和consumer吞吐量(1.42m/s)。数据来自上面的压测。
- 假设他们的值分别是Tp和Tc,单位可以是MB/s。 4)然后假设你期望的目标吞吐量是Tt(10m/s),那么分区数=Tt /min(Tp,Tc) ,这里取最小值是因为使最低的吞吐量都能达到期望的吞吐量。
- 例如:producer吞吐量=20m/s;consumer吞吐量=50m/s,期望吞吐量100m/s。
- 分区数=100 / 20 =5分区 5)分区数一般设置为:3-10个。
Kafka机器数量计算
- Kafka机器数量(经验公式)= 2 *(峰值生产速度 * 副本数 / 100)+ 1。
-
比如我们的峰值生产速度是50M/s。副本数为2。
Kafka机器数量 = 2 *(50 * 2 / 100)+ 1 = 3台
- 先拿到峰值生产速度,再根据设定的副本数,就能预估出需要部署Kafka的数量。 副本数默认是1个
- 在企业里面2-3个都有,2个居多。
- 比如我们的峰值生产速度是50M/s(一般不超过50M/s)。生产环境可以设置为2。 Kafka机器数量=2(50*2/100)+1=3台
- 副本多可以提高可靠性,但是会降低网络传输效率。
相关文章:
Kafka优化篇-压测和性能调优
简介 Kafka的配置详尽、复杂,想要进行全面的性能调优需要掌握大量信息,这里只记录一下我在日常工作使用中走过的坑和经验来对kafka集群进行优化常用的几点。 Kafka性能调优和参数调优 性能调优 JVM的优化 java相关系统自然离不开JVM的优化。首先想到…...
MinIo-SDK
3.2.5 SDK 3.2.5.1上传文件 MinIO提供多个语言版本SDK的支持,下边找到java版本的文档: 地址:https://docs.min.io/docs/java-client-quickstart-guide.html 最低需求Java 1.8或更高版本: maven依赖如下: XML<dependency&g…...

系统分析师真题2018试卷相关概念一
面向对象的基本概念: 对象的三要素为:属性(数据)、方法(操作)、对象ID(标识)UML2.0包括14种图: 类图(class diagram):类图描述一组类、接口、协作和他们之间的关系。在OO系统的建模中,最常见的图就是类图。类图给出了系统的静态设计图,活动类的类图给出了系统的静…...
身为大学生,你不会还不知道有这些学生福利吧!!!!
本文介绍的是利用学生身份可以享受到的相关学生优惠权益,但也希望各位享受权利的同时不要忘记自己的义务,不要售卖、转手自己的学生优惠资格,使得其他同学无法受益。 前言 高考已经过去,我们也将迎来不同于以往的大学生活&#x…...

试题 算法训练 藏匿的刺客
问题描述 强大的kAc建立了强大的帝国,但人民深受其学霸及23文化的压迫,于是勇敢的鹏决心反抗。 kAc帝国防守森严,鹏带领着小伙伴们躲在城外的草堆叶子中,称为叶子鹏。 kAc帝国的派出的n个看守员都发现了这一问题ÿ…...

JavaWab开发的总括以及HTML知识
一、Web开发的总括在这里我来给大家介绍一下Wab开发需要配合哪些前后端的对应语言:首先是Java(Java通常的工作):Wab开发android开发大数据开发另外,Wab开发想要学好就需要配合之前博客中的内容,如:多线程/IO/网络/数据结构/数据库......这里建议学懂前面的内容再往下走.JavaWab…...
迁移【图文教程】)
Oracle数据库文件(*.dbf)迁移【图文教程】
目录 背景 解决 第1步:sqlplus登录 第2步:查看Oracle数据文件所在目录 第3步:修改表空间为离线状态 第4步: 移动数据库文件到新目录 第5步:修改表空间数据文件位置 第6步:修改表空间为online状态 第7步:临时表空间处理 第8步:验证修改是否成功 参考...
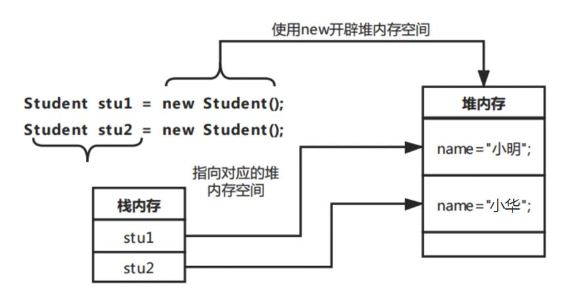
Java中如何创建和使用对象?
要想使用一个类则必须要有对象。在Java程序中可以使用new关键字创建对象,具体格式如下:类名对象名称null; 对象名称new 类名();上述格式中,创建对象分为声明对象和实例化对象两步,也可以直接通过下面的方式创建对象,具…...
Spring Cloud Alibaba--ActiveMQ微服务详解之消息队列(四)
上篇讲述高并发情况下的数据库处理方式:分布式事务管理机制。即使我们做到这一步并发情况只能稍微得到缓解,当然千万级别的问题不大,但在面对双十一淘宝这类的达上亿的并发的时候仅仅靠分布式事务管理还是远远不够,即使数据库可以…...
32岁,薪水被应届生倒挂,裸辞了
今年 32 岁,我从公司离职了,是裸辞。 前段时间,我有一件事情一直憋在心里很难受,想了很久也没找到合适的人倾诉,就借着今天写出来。 我一个十几年开发经验,八年 软件测试 经验的职场老人,我慢…...
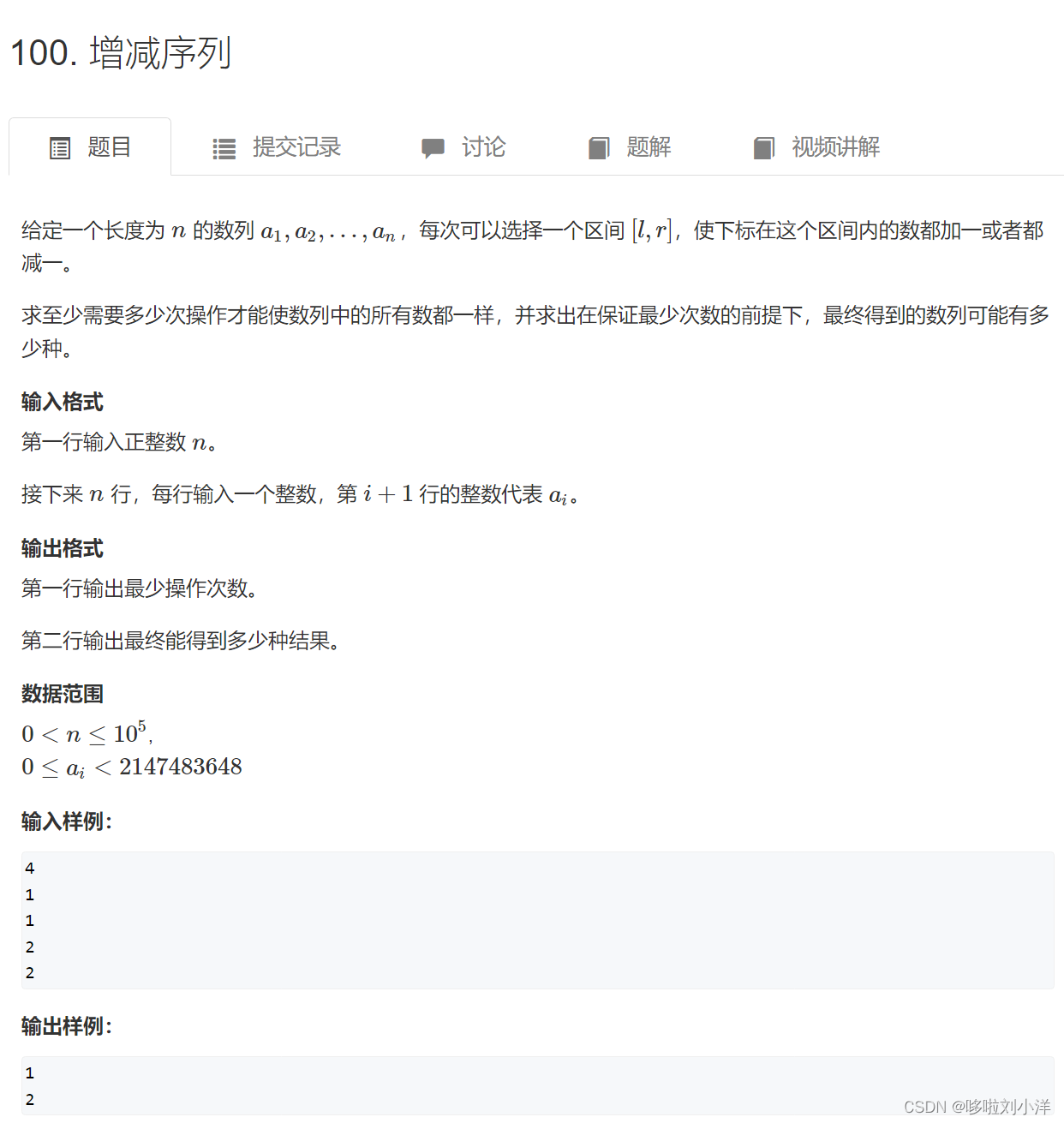
蓝桥杯训练day1
前缀和差分1.前缀和(1)3956. 截断数组(2)795. 前缀和(3)796. 子矩阵的和(4)1230. K倍区间(5)99. 激光炸弹2.差分(1)797. 差分(2)差分矩阵(3)3729. 改变数组元素(4)100. 增减序列1.前缀和 (1)3956. 截断数组 方法1:暴力 先用两个数组分别保存前缀和,后缀…...

Unity毛发系统TressFX Exporter
Unity 数字人交流群:296041238 一:在Maya下的TressFX Exporter 插件安装步骤: 1. 下载Maya的TressFX Exporter插件 下载地址:TressFX Exporter 链接:https://github.com/Unity-China/cn.unity.hairfx.core/tree/m…...

《爆肝整理》保姆级系列教程python接口自动化(十九)--Json 数据处理---实战(详解)
简介 上一篇说了关于json数据处理,是为了断言方便,这篇就带各位小伙伴实战一下。首先捋一下思路,然后根据思路一步一步的去实现和实战,不要一开始就盲目的动手和无头苍蝇一样到处乱撞,撞得头破血流后而放弃了。不仅什么…...

Golang:reflect反射的使用例子
1.reflect包作用 reflect包定义了“反射”相关能力,“反射”在计算机学中是指计算机程序在运行时(runtime)可以访问、检测和修改它本身状态或行为的一种能力。基于反射特性可以通用化地解决一些需要频繁修改代码及硬编码问题,但是…...

markdown常用语法--花括号(超详细)
💌 所属专栏:【Markdown常用语法】 😀 作 者:我是夜阑的狗🐶 🚀 个人简介:一个正在努力学技术的CV工程师,专注基础和实战分享 ,欢迎咨询! …...
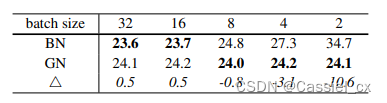
BN、SyncBN、IN、LN、GN学习记录
1 BatchNormBN的原理BN是计算机视觉最常用的标准化方法,它沿着N、H、W维度对输入特征图求均值和方差,随后再利用均值和方差来归一化特征图。计算过程如下图所示,1)沿着通道维度计算其他维度的均值;2)沿着通…...

使用 Auto-scheduling 优化算子
本篇回答来源于 TVM 官方英文文档 Lianmin Zheng,Chengfan Jia。更多 TVM 中文文档可访问→https://tvm.hyper.ai/ 本教程将展示 TVM 的 Auto Scheduling 功能,如何在不编写自定义模板的情况下,找到最佳 schedule。 与基于模板的 AutoTVM 依…...
智能运维应用之道,告别企业数字化转型危机
面临的问题及挑战 数据中心发展历程 2000 年中国数据中心始建,至今已经历以下 3 大阶段。早期:离散型数据中心 IT 因以项目建设为导向,故缺乏规划且无专门运维管理体系,此外,开发建设完的项目均是独立运维维护&#…...

第七章 SQL错误信息 - SQL错误代码 -400 到 -500
文章目录第七章 SQL错误信息 - SQL错误代码 -400 到 -500SQL错误代码和消息表WinSock错误代码-10050到-11002第七章 SQL错误信息 - SQL错误代码 -400 到 -500 SQL错误代码和消息表 错误代码描述-400发生严重错误-401严重连接错误-402用户名/密码无效-405无法从通信设备读取-4…...

DDFN: Decoupled Dynamic Filter Networks解耦的动态卷积
一、论文信息 论文名称:Decoupled Dynamic Filter Networks 论文:https://thefoxofsky.github.io/files/ddf.pdf 代码:https://github.com/theFoxofSky/ddfnet 主页:https://thefoxofsky.github.io/project_pages/ddf 作者团…...

WAN2.2文生视频镜像部署案例:私有云K8s集群中弹性扩缩容视频生成服务
WAN2.2文生视频镜像部署案例:私有云K8s集群中弹性扩缩容视频生成服务 1. 引言:当视频创作遇上弹性算力 想象一下,你的团队需要为新产品发布制作一批宣传视频。传统的流程是:策划写脚本、设计师画分镜、剪辑师合成渲染࿰…...

OpenClaw智能搜索:Qwen3.5-9B支持的知识检索与摘要
OpenClaw智能搜索:Qwen3.5-9B支持的知识检索与摘要 1. 为什么需要智能搜索助手 作为一个经常需要查阅技术文档的研究者,我每天要花大量时间在不同平台间切换——打开浏览器搜索、翻阅PDF论文、在GitHub仓库里找示例代码。最头疼的是,当需要…...
秒杀大数据题)
蓝桥杯二分算法通关指南:模板+真题+避坑,O(logn)秒杀大数据题
蓝桥杯二分算法通关指南:模板真题避坑,O(logn)秒杀大数据题 文章目录蓝桥杯二分算法通关指南:模板真题避坑,O(logn)秒杀大数据题一、蓝桥杯二分核心题型(精简必背)1. 二分查找(基础必考…...

零代码实战:用OpenClaw和Qwen3.5-9B-AWQ-4bit制作表情包生成器
零代码实战:用OpenClaw和Qwen3.5-9B-AWQ-4bit制作表情包生成器 1. 为什么需要本地化表情包生成工具 作为一个长期混迹技术社区的老鸟,我经常需要在群聊中快速制作贴合讨论主题的表情包。传统方式要么依赖在线生成器(存在隐私风险࿰…...

2025_NIPS_JavisGPT: A Unified Multi-modal LLM for Sounding-Video Comprehension and Generation
JavisGPT 论文核心总结与翻译 一、主要内容总结 JavisGPT 是首个面向同步音视频(sounding video)理解与生成的统一多模态大语言模型(MLLM),核心解决现有模型将音视频视为独立模态、缺乏时空同步建模的问题。 模型采用编码器-LLM-解码器架构,以 Qwen2.5-VL-7B-Instruct…...

姜翰奇补题
3.23-3.29一、PTA天梯赛5:第5,7,8,10,11,12二、牛客:136周赛三、马蹄集:DFS和BFS搜索题目四、牛客:蓝桥杯模拟赛3.30-4.5一、PTA天梯赛6:第8、9、10二、牛客:137周赛三、…...

新手避坑指南:用Boson NetSim 11模拟多子网互联,从连线到ping通的全流程复盘
新手避坑指南:用Boson NetSim 11模拟多子网互联,从连线到ping通的全流程复盘 第一次打开Boson NetSim 11时,那种兴奋和忐忑交织的感觉至今难忘。作为网络工程初学者,我们往往怀揣着教科书上的理论知识,却在第一次实操时…...

嵌入式环形缓冲区:统一队列/栈/数组的零分配实现
1. 项目概述SSVQueueStackArray 是一个面向嵌入式系统的轻量级、零分配(zero-allocation)、编译期类型安全的环形缓冲区(Ring Buffer)实现库,专为资源受限的 MCU 环境设计。其核心目标并非提供通用容器抽象,…...

智慧校园软件怎么选?看懂这 5 个核心功能再决定不迟
✅作者简介:合肥自友科技 📌核心产品:智慧校园软件(包括教工管理、学工管理、教务管理、考务管理、后勤管理、德育管理、资产管理、公寓管理、实习管理、就业管理、离校管理、科研平台、档案管理、学生平台等26个子平台) 。公司所有人员均有多…...

数据治理与数据质量:从策略到实践
数据治理与数据质量:从策略到实践 前言 作为一个在数据深渊里捞了十几年 Bug 的女码农,我深知数据治理和数据质量在企业数据管理中的重要性。随着数据量的爆炸式增长和数据类型的多样化,数据治理和数据质量已经成为企业数据管理的核心挑战。今…...