2023年国赛 高教社杯数学建模思路 - 案例:随机森林
文章目录
- 1 什么是随机森林?
- 2 随机深林构造流程
- 3 随机森林的优缺点
- 3.1 优点
- 3.2 缺点
- 4 随机深林算法实现
- 建模资料
## 0 赛题思路
(赛题出来以后第一时间在CSDN分享)
https://blog.csdn.net/dc_sinor?type=blog
1 什么是随机森林?
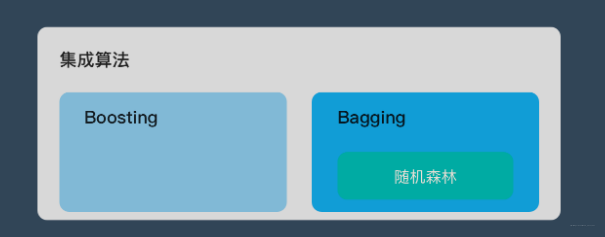
随机森林属于 集成学习 中的 Bagging(Bootstrap AGgregation 的简称) 方法。如果用图来表示他们之间的关系如下:
决策树 – Decision Tree
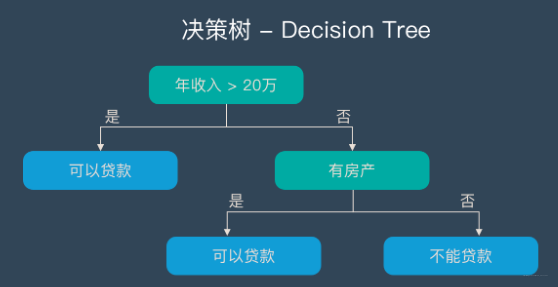
在解释随机森林前,需要先提一下决策树。决策树是一种很简单的算法,他的解释性强,也符合人类的直观思维。这是一种基于if-then-else规则的有监督学习算法,上面的图片可以直观的表达决策树的逻辑。
随机森林 – Random Forest | RF
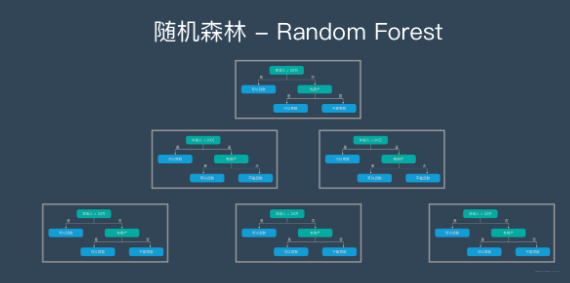
随机森林是由很多决策树构成的,不同决策树之间没有关联。
当我们进行分类任务时,新的输入样本进入,就让森林中的每一棵决策树分别进行判断和分类,每个决策树会得到一个自己的分类结果,决策树的分类结果中哪一个分类最多,那么随机森林就会把这个结果当做最终的结果。
2 随机深林构造流程

-
- 一个样本容量为N的样本,有放回的抽取N次,每次抽取1个,最终形成了N个样本。这选择好了的N个样本用来训练一个决策树,作为决策树根节点处的样本。
-
- 当每个样本有M个属性时,在决策树的每个节点需要分裂时,随机从这M个属性中选取出m个属性,满足条件m << M。然后从这m个属性中采用某种策略(比如说信息增益)来选择1个属性作为该节点的分裂属性。
-
- 决策树形成过程中每个节点都要按照步骤2来分裂(很容易理解,如果下一次该节点选出来的那一个属性是刚刚其父节点分裂时用过的属性,则该节点已经达到了叶子节点,无须继续分裂了)。一直到不能够再分裂为止。注意整个决策树形成过程中没有进行剪枝。
-
- 按照步骤1~3建立大量的决策树,这样就构成了随机森林了。
3 随机森林的优缺点
3.1 优点
- 它可以出来很高维度(特征很多)的数据,并且不用降维,无需做特征选择
- 它可以判断特征的重要程度
- 可以判断出不同特征之间的相互影响
- 不容易过拟合
- 训练速度比较快,容易做成并行方法
- 实现起来比较简单
- 对于不平衡的数据集来说,它可以平衡误差。
- 如果有很大一部分的特征遗失,仍可以维持准确度。
3.2 缺点
- 随机森林已经被证明在某些噪音较大的分类或回归问题上会过拟合。
- 对于有不同取值的属性的数据,取值划分较多的属性会对随机森林产生更大的影响,所以随机森林在这种数据上产出的属性权值是不可信的
4 随机深林算法实现
数据集:https://archive.ics.uci.edu/ml/machine-learning-databases/undocumented/connectionist-bench/sonar/
import csv
from random import seed
from random import randrange
from math import sqrtdef loadCSV(filename):#加载数据,一行行的存入列表dataSet = []with open(filename, 'r') as file:csvReader = csv.reader(file)for line in csvReader:dataSet.append(line)return dataSet# 除了标签列,其他列都转换为float类型
def column_to_float(dataSet):featLen = len(dataSet[0]) - 1for data in dataSet:for column in range(featLen):data[column] = float(data[column].strip())# 将数据集随机分成N块,方便交叉验证,其中一块是测试集,其他四块是训练集
def spiltDataSet(dataSet, n_folds):fold_size = int(len(dataSet) / n_folds)dataSet_copy = list(dataSet)dataSet_spilt = []for i in range(n_folds):fold = []while len(fold) < fold_size: # 这里不能用if,if只是在第一次判断时起作用,while执行循环,直到条件不成立index = randrange(len(dataSet_copy))fold.append(dataSet_copy.pop(index)) # pop() 函数用于移除列表中的一个元素(默认最后一个元素),并且返回该元素的值。dataSet_spilt.append(fold)return dataSet_spilt# 构造数据子集
def get_subsample(dataSet, ratio):subdataSet = []lenSubdata = round(len(dataSet) * ratio)#返回浮点数while len(subdataSet) < lenSubdata:index = randrange(len(dataSet) - 1)subdataSet.append(dataSet[index])# print len(subdataSet)return subdataSet# 分割数据集
def data_spilt(dataSet, index, value):left = []right = []for row in dataSet:if row[index] < value:left.append(row)else:right.append(row)return left, right# 计算分割代价
def spilt_loss(left, right, class_values):loss = 0.0for class_value in class_values:left_size = len(left)if left_size != 0: # 防止除数为零prop = [row[-1] for row in left].count(class_value) / float(left_size)loss += (prop * (1.0 - prop))right_size = len(right)if right_size != 0:prop = [row[-1] for row in right].count(class_value) / float(right_size)loss += (prop * (1.0 - prop))return loss# 选取任意的n个特征,在这n个特征中,选取分割时的最优特征
def get_best_spilt(dataSet, n_features):features = []class_values = list(set(row[-1] for row in dataSet))b_index, b_value, b_loss, b_left, b_right = 999, 999, 999, None, Nonewhile len(features) < n_features:index = randrange(len(dataSet[0]) - 1)if index not in features:features.append(index)# print 'features:',featuresfor index in features:#找到列的最适合做节点的索引,(损失最小)for row in dataSet:left, right = data_spilt(dataSet, index, row[index])#以它为节点的,左右分支loss = spilt_loss(left, right, class_values)if loss < b_loss:#寻找最小分割代价b_index, b_value, b_loss, b_left, b_right = index, row[index], loss, left, right# print b_loss# print type(b_index)return {'index': b_index, 'value': b_value, 'left': b_left, 'right': b_right}# 决定输出标签
def decide_label(data):output = [row[-1] for row in data]return max(set(output), key=output.count)# 子分割,不断地构建叶节点的过程对对对
def sub_spilt(root, n_features, max_depth, min_size, depth):left = root['left']# print leftright = root['right']del (root['left'])del (root['right'])# print depthif not left or not right:root['left'] = root['right'] = decide_label(left + right)# print 'testing'returnif depth > max_depth:root['left'] = decide_label(left)root['right'] = decide_label(right)returnif len(left) < min_size:root['left'] = decide_label(left)else:root['left'] = get_best_spilt(left, n_features)# print 'testing_left'sub_spilt(root['left'], n_features, max_depth, min_size, depth + 1)if len(right) < min_size:root['right'] = decide_label(right)else:root['right'] = get_best_spilt(right, n_features)# print 'testing_right'sub_spilt(root['right'], n_features, max_depth, min_size, depth + 1)# 构造决策树
def build_tree(dataSet, n_features, max_depth, min_size):root = get_best_spilt(dataSet, n_features)sub_spilt(root, n_features, max_depth, min_size, 1)return root
# 预测测试集结果
def predict(tree, row):predictions = []if row[tree['index']] < tree['value']:if isinstance(tree['left'], dict):return predict(tree['left'], row)else:return tree['left']else:if isinstance(tree['right'], dict):return predict(tree['right'], row)else:return tree['right']# predictions=set(predictions)
def bagging_predict(trees, row):predictions = [predict(tree, row) for tree in trees]return max(set(predictions), key=predictions.count)
# 创建随机森林
def random_forest(train, test, ratio, n_feature, max_depth, min_size, n_trees):trees = []for i in range(n_trees):train = get_subsample(train, ratio)#从切割的数据集中选取子集tree = build_tree(train, n_features, max_depth, min_size)# print 'tree %d: '%i,treetrees.append(tree)# predict_values = [predict(trees,row) for row in test]predict_values = [bagging_predict(trees, row) for row in test]return predict_values
# 计算准确率
def accuracy(predict_values, actual):correct = 0for i in range(len(actual)):if actual[i] == predict_values[i]:correct += 1return correct / float(len(actual))if __name__ == '__main__':seed(1) dataSet = loadCSV('sonar-all-data.csv')column_to_float(dataSet)#dataSetn_folds = 5max_depth = 15min_size = 1ratio = 1.0# n_features=sqrt(len(dataSet)-1)n_features = 15n_trees = 10folds = spiltDataSet(dataSet, n_folds)#先是切割数据集scores = []for fold in folds:train_set = folds[:] # 此处不能简单地用train_set=folds,这样用属于引用,那么当train_set的值改变的时候,folds的值也会改变,所以要用复制的形式。(L[:])能够复制序列,D.copy() 能够复制字典,list能够生成拷贝 list(L)train_set.remove(fold)#选好训练集# print len(folds)train_set = sum(train_set, []) # 将多个fold列表组合成一个train_set列表# print len(train_set)test_set = []for row in fold:row_copy = list(row)row_copy[-1] = Nonetest_set.append(row_copy)# for row in test_set:# print row[-1]actual = [row[-1] for row in fold]predict_values = random_forest(train_set, test_set, ratio, n_features, max_depth, min_size, n_trees)accur = accuracy(predict_values, actual)scores.append(accur)print ('Trees is %d' % n_trees)print ('scores:%s' % scores)print ('mean score:%s' % (sum(scores) / float(len(scores))))
建模资料
资料分享: 最强建模资料


相关文章:
2023年国赛 高教社杯数学建模思路 - 案例:随机森林
文章目录 1 什么是随机森林?2 随机深林构造流程3 随机森林的优缺点3.1 优点3.2 缺点 4 随机深林算法实现 建模资料 ## 0 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 1 什么是随机森林ÿ…...

element Collapse 折叠面板 绑定事件
1. 点击面板触发事件 change <el-collapse accordion v-model"activeNames" change"handleChange"><el-collapse-item title"一致性 Consistency"><div>与现实生活一致:与现实生活的流程、逻辑保持一致,…...

CSS :mix-blend-mode、aspect-ratio
mix-blend-mode 元素的内容应该与元素的直系父元素的内容和元素的背景如何混合。 mix-blend-mode: normal; // 正常mix-blend-mode: multiply; // 正片叠底mix-blend-mode: screen; // 滤色mix-blend-mode: overlay; // 叠加mix-blend-mode: darken; // 变暗mix-blend-mode: …...
Module not found: Error: Can‘t resolve ‘less-loader‘解决办法
前言: 主要是在自我提升方面,感觉自己做后端还是需要继续努力,争取炮筒前后端,作为一个全栈软阿金开发人员,所以还是需要努力下,找个方面,目前是计划学会Vue,这样后端有java和pytho…...

量化QAT QLoRA GPTQ
模型量化的思路可以分为PTQ(Post-Training Quantization,训练后量化)和QAT(Quantization Aware Training,在量化过程中进行梯度反传更新权重,例如QLoRA),GPTQ是一种PTQ的思路。 QAT…...

CentOS下查看 ssd 寿命
SSD写入量达到设计极限,颗粒擦写寿命耗尽后会导致磁盘写入速度非常缓慢,读取正常。 使用smartctl及raid卡管理软件查看硬盘smart信息可以发现Media_Wearout_Indicator值降为1,表明寿命完全耗尽。 涉及范围 所有SSD处理方案 查看SSD smart信…...

Node基础--npm相关内容
下面,我们一起来看看Node中的至关重要的一个知识点-----npm 1.npm概述 npm(Node Package Manager),CommonJS包规范是理论,npm是其中一种实践。 对于Node而言,NPM帮助其完成了第三方模块的发布、安装和依赖等。借助npm,Node与第三方模块之间形成了很好的一个 生态系统。(类…...

Python图片爬虫工具
不废话了,直接上代码: import re import os import requests import tqdmheader{User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36}def getImg(url,idx,path):imgre…...

制造执行系统(MES)在汽车行业中的应用
汽车行业在不断发展中仍然面临一些挑战和痛点。以下是一些当前汽车行业可能面临的问题: 1.电动化和可持续性转型:汽车行业正逐渐向电动化和可持续性转型,但这需要投入大量资金和资源,包括电池技术、充电基础设施等,同时…...

Spring与Mybatis集成且Aop整合
目录 一、集成 1.1 集成的概述 1.2 集成的优点 1.3 代码示例 二、整合 2.1 整合概述 2.2 整合进行分页 一、集成 1.1 集成的概述 集成是指将不同的组件、部分或系统组合在一起,以形成一个整体功能完整的解决方案。它是通过连接、交互和协调组件之间的关系来实…...

【nonebot-plugin-mystool】快速安装使用nonebot-plugin-mystool
快速安装使用nonebot-plugin-mystool,以qq为主 前期准备:注册一个QQ号,python3.9以上的版本安装,go-cqhttp下载 用管理员模式打开powershell,并输入以下命令 #先排查是否有安装过的nonebot,若有则删除 pip uninstal…...
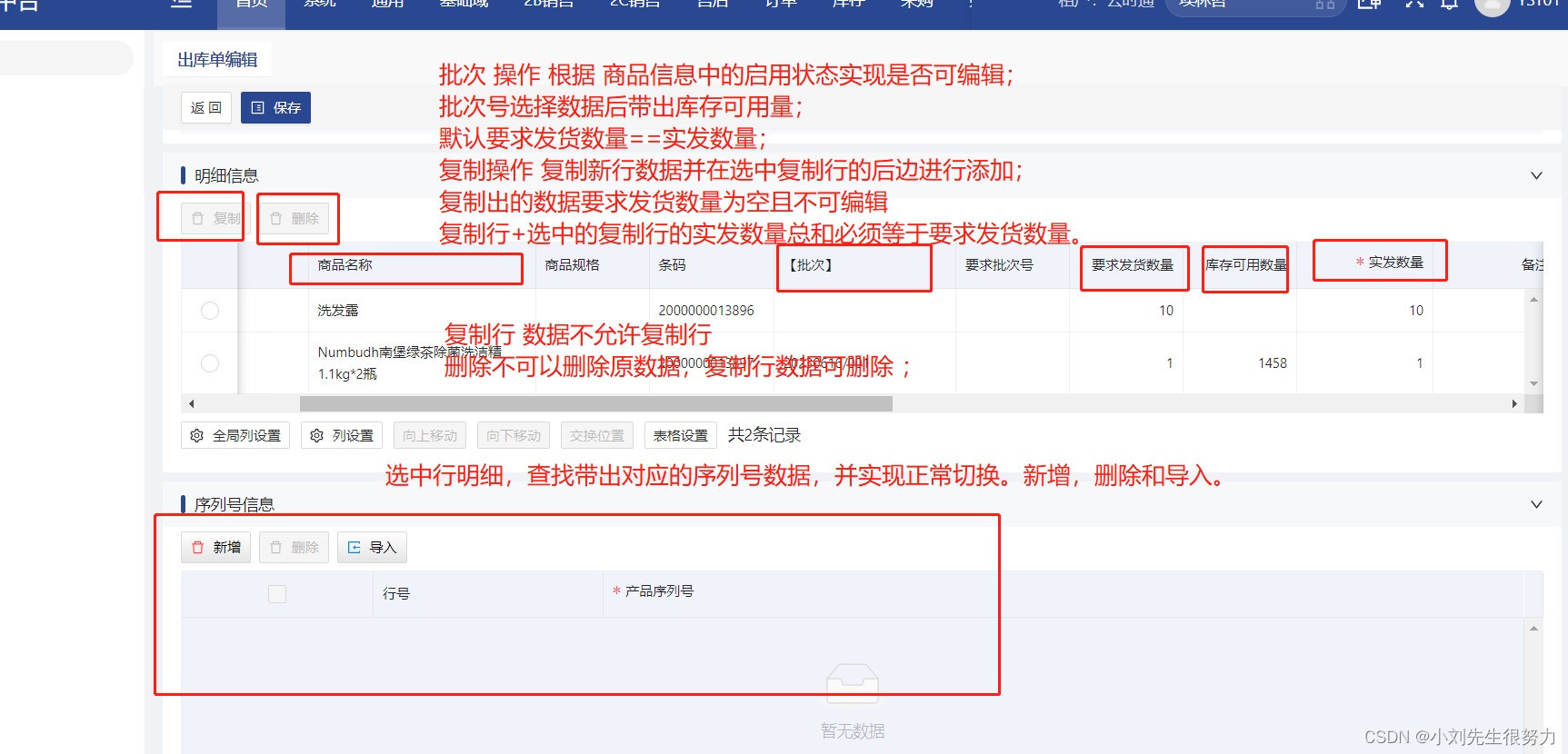
js实现数据关联查找更新。数据求和验证
为了实现这个功能我们和后端定义了数据结构 data:{id:‘’,formInfo:,formInfo2:,formInfo3:,formInfo4:, ......deailData:[ // 明细数据 // saleData 查询带出的对应明细序列号数据{ id:, ocopyId:, copyId:, odoId:, ......, saleData:[ { id:, oc…...

区块链上地址与银行账户有什么区别?
在区块链世界中,除了交易还有另一个基础要素:地址。在日前推出的Onchain AML合规技术方案,也有一个与区块链地址密切相关的概念:KYA(Know Your Address,了解你的地址)。 那问题来了,区块链地址究竟有什么用…...
)
CF 148 D Bag of mice(概率dp求概率)
CF 148 D. Bag of mice(概率dp求概率) Problem - 148D - Codeforces 大意:袋子里有 w 只白鼠和 b 只黑鼠 ,A和B轮流从袋子里抓,谁先抓到白色谁就赢。A每次随机抓一只,B每次随机抓完一只之后会有另一只随机老鼠跑出来。如果两个人…...

引入本地 jar 包教程
将本地 jar 包,放到 resource 目录下,在 pom.xml 文件中加入如下依赖: <dependency><groupId>com.hk</groupId><artifactId>examples</artifactId><version>1.0</version><scope>system<…...
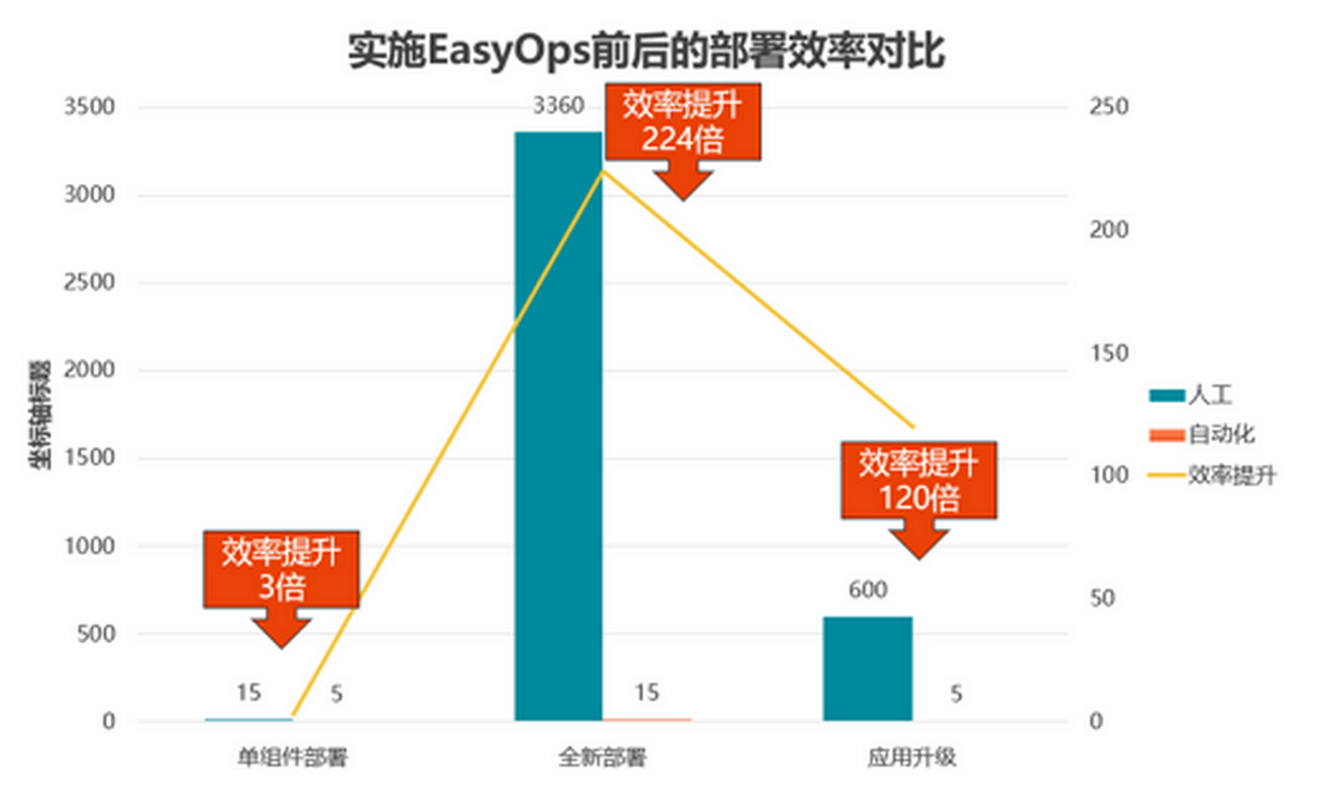
优维产品最佳实践第5期:什么是持续集成?
谈到到DevOps,持续交付流水线是绕不开的一个话题,相对于其他实践,通过流水线来实现快速高质量的交付价值是相对能快速见效的,特别对于开发测试人员,能够获得实实在在的收益。 本期EasyOps产品使用最佳实践,…...
空时自适应处理用于机载雷达——元素空间空时自适应处理(Matla代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

聚观早报 | 青瓷游戏上半年营收3.34亿元;如祺出行冲击IPO
【聚观365】8月26日消息 青瓷游戏上半年营收3.34亿元 如祺出行冲击IPO 索尼互动娱乐将收购Audeze 昆仑万维上半年净利润3.6亿元 T-Mobile计划在未来五周内裁员5000人 青瓷游戏上半年营收3.34亿元 青瓷游戏发布截至2023年6月30日止的中期业绩,财报显示…...

硅谷的魔法:如何塑造了全球技术的未来
硅谷的创新文化简介 硅谷,位于美国加利福尼亚州的圣克拉拉谷,已经从一个半导体产业的中心发展成为全球技术创新的代名词。这里集结了全球最顶尖的技术公司、创业者和投资者,共同创造了一个技术创新的奇迹。 起源与发展 硅谷的起源与斯坦福大…...
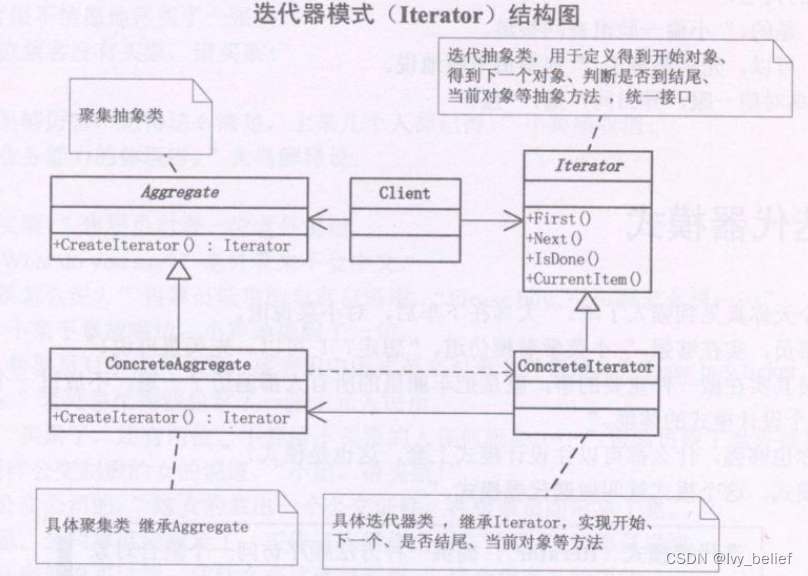
(三)行为模式:4、迭代器模式(Iterator Pattern)(C++示例)
目录 1、迭代器模式(Iterator Pattern)含义 2、迭代器模式的UML图学习 3、迭代器模式的应用场景 4、迭代器模式的优缺点 (1)优点 (2)缺点 5、C实现迭代器模式的实例 1、迭代器模式(Itera…...

Win11Debloat:一键清理Windows 11,让你的电脑重回清爽状态
Win11Debloat:一键清理Windows 11,让你的电脑重回清爽状态 【免费下载链接】Win11Debloat 一个简单的PowerShell脚本,用于从Windows中移除预装的无用软件,禁用遥测,从Windows搜索中移除Bing,以及执行各种其…...
)
【国家级等保2.0合规必读】:Python扩展模块安全开发规范(含12项强制检查项+自动化检测脚本)
第一章:Python扩展模块安全开发概述Python 扩展模块(C/C 编写的 .so/.dll 文件)是提升性能、复用底层库或与系统交互的关键手段,但其直接操作内存、绕过 Python 运行时保护机制的特性,也使其成为安全风险的高发区。开发…...

Android架构组件
Android架构组件:构建现代化应用的利器 在移动应用开发中,良好的架构设计是保证应用稳定性和可维护性的关键。Google推出的Android架构组件(Android Architecture Components)为开发者提供了一套标准化工具,帮助简化开…...
)
STM32CubeMX实战:5分钟搞定RTC定时唤醒低功耗设计(附LED状态检测技巧)
STM32CubeMX实战:RTC定时唤醒与低功耗设计的5个关键技巧 嵌入式开发者经常面临一个挑战:如何在保证设备功能完整的同时,最大限度地延长电池寿命。RTC(实时时钟)定时唤醒技术正是解决这一问题的利器,它能让…...

终极LxgwWenKai字体配置指南:如何为VSCode和IDEA打造完美中文编程体验
终极LxgwWenKai字体配置指南:如何为VSCode和IDEA打造完美中文编程体验 【免费下载链接】LxgwWenKai LxgwWenKai: 这是一个开源的中文字体项目,提供了多种版本的字体文件,适用于不同的使用场景,包括屏幕阅读、轻便版、GB规范字形和…...

效率提升秘籍:用快马AI自动生成六花直装更新页面,节省开发时间
作为一名经常需要维护应用更新页面的开发者,我深刻体会到手动编写更新日志的繁琐。每次版本迭代,从整理更新内容到排版发布,往往要耗费大量时间。最近尝试用InsCode(快马)平台的AI功能自动生成更新页面,效率提升非常明显。 传统更…...

突破传统:用Arduino SI4735库打造全频段数字收音机方案
突破传统:用Arduino SI4735库打造全频段数字收音机方案 【免费下载链接】SI4735 SI473X Library for Arduino 项目地址: https://gitcode.com/gh_mirrors/si/SI4735 你是否曾梦想过亲手打造一台能接收全球广播的专业收音机?面对传统模拟电路的复杂…...

VAP:腾讯开源的高性能动画播放引擎,如何让你的应用动起来更流畅?
VAP:腾讯开源的高性能动画播放引擎,如何让你的应用动起来更流畅? 【免费下载链接】vap VAP是企鹅电竞开发,用于播放特效动画的实现方案。具有高压缩率、硬件解码等优点。同时支持 iOS,Android,Web 平台。 项目地址: https://git…...

2026必看:八款热门AI编程工具横评
一、AI编程工具榜单综述当下AI技术全面渗透软件开发领域,各类AI编程工具大幅降低了开发门槛、提升了编码效率,成为开发者必备的效率神器。本次横评精选海内外8款主流产品,覆盖AI原生IDE、插件式编程助手等不同形态,全方位盘点各工…...

手把手教你用R玩转MSigDB:从数据库下载、基因集构建到GSEA/GSVA完整流程
手把手教你用R玩转MSigDB:从数据库下载、基因集构建到GSEA/GSVA完整流程 如果你正在寻找一个权威的基因集数据库来支持你的转录组功能分析,MSigDB(Molecular Signatures Database)无疑是首选。作为Broad研究所维护的核心资源&…...