arxiv2017 | 用于分子神经网络建模的数据增强 SMILES Enumeration

论文标题:SMILES Enumeration as Data Augmentation for Neural Network Modeling of Molecules
论文地址:https://arxiv.org/abs/1703.07076
代码地址:https://github.com/Ebjerrum/SMILES-enumeration
一、摘要

摘要中明显提出:先指出多个SMILES对应一个分子,标准SMILES对应一个分子。采用数据增强,使得数据集扩大130倍,然后指出改进效果。
二、Introduction
第一段:描述数据集大小限制了OSAR领域的应用。小数据集需要更多正则化或者小网络。在CV中可以通过多种手段进行数据增强,以扩大数据集,使得模型更具鲁棒性。
第二段:分子表征有三种(分子描述符、SMILES、Graph),SMILES的变化有很多种,如CCC→C(C)C,分子越复杂,其变化越多,对应的SMILES也越多。如下:
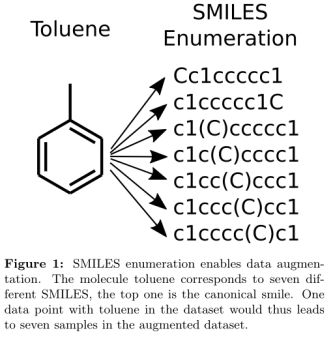
第三段:描述应用方法。SMILES enumeration for QSAR using LSTM
三、Methods
SMILES enumeration:一个python脚本(函数)。将SMILES转化为molfile→打乱原子顺序→转换为mol→RDKit生成SMILES→存入set中(保证不重)。简洁代码:
def randomize_smile(sml):"""Function that randomizes a SMILES sequnce. This was adapted from theimplemetation of E. Bjerrum 2017, SMILES Enumeration as Data Augmentationfor Neural Network Modeling of Molecules.Args:sml: SMILES sequnce to randomize.Return:randomized SMILES sequnce ornan if SMILES is not interpretable."""try:m = Chem.MolFromSmiles(sml)ans = list(range(m.GetNumAtoms()))np.random.shuffle(ans)nm = Chem.RenumberAtoms(m, ans)return Chem.MolToSmiles(nm, canonical=False)except:return float('nan')
Molecular dataset:756 dihydrofolate inhibitors with P. carinii DHFR inhibition data
J. J. Sutherland, L. A. O’Brien, D. F. Weaver, Spline-fitting with a genetic algorithm: a method for developing classification structure-activity relationships., Journal of chemical information and computer sciences 43 (2003) 1906–1915. doi: 10.1021/ci034143r.
训练:测试=9:1,并没有在验证集上取best。embedding_dim = 74,one-hot编码。
LSTM neural network:LSTM+全连接层。两个模型,一个是标准模型,一个是枚举模型。实行超参数搜索。标准模型应该LSTM layers更小会更好一点(因为数据集小),应该是陷入模型局部最优值。但是L1、L2的正则化有一点的作用。
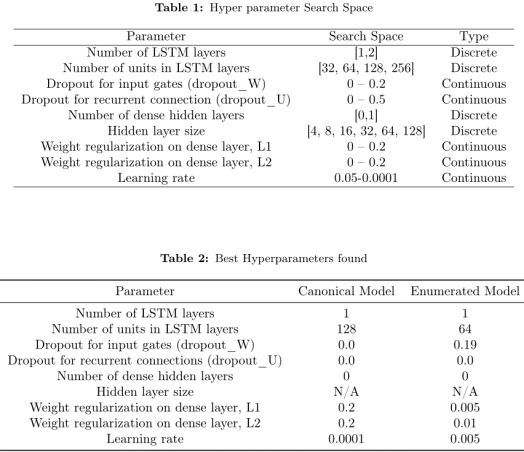
损失下降:蓝线是没有正则化惩罚的均方误差,绿线是包含正则化惩罚的损失,红线是测试集中的均方误差。标准模型在标准数据上要迭代更多epoch,因为数据集要远小于枚举数据集,需要更多梯度更新。但是运行时间大致相同。
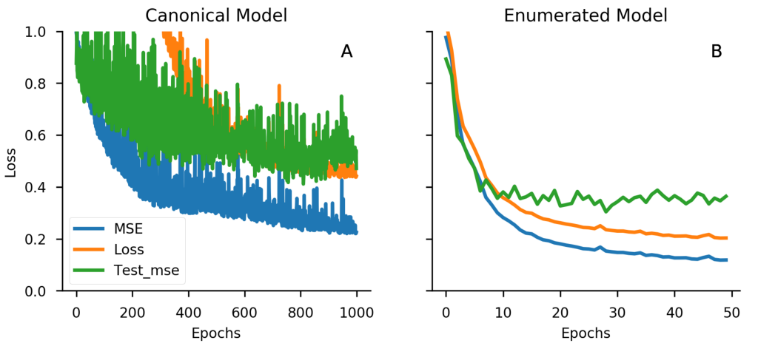
散点图:左列为标准模型在标准数据集、枚举数据集上的表现。右列为枚举模型在标准数据集、枚举数据集上的表现。
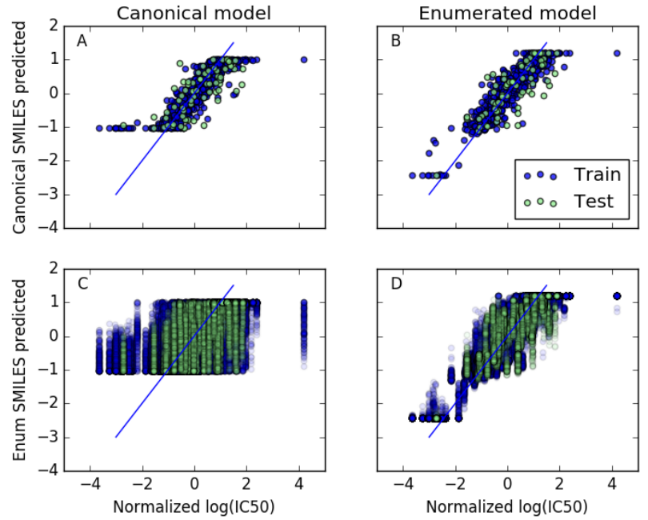
下表列出具体数值:
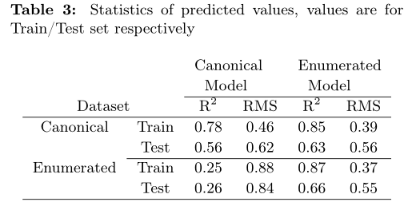
该研究缺乏对训练集、测试集和验证集的划分,其中超参数在测试集上进行调优,但最终性能在验证集上进行评估。因此,LSTM-QSAR模型观测到的预测性能可能在一定程度上被高估。
然而,本研究的重点是使用SMILES枚举的增益,而不是生成最优的DHFR QSAR模型。正则模型在训练和测试集上的性能都较低。如果性能上的差异是由于过度拟合造成的,那么较小的数据集可能会有优势。
四、Conclusion
This short investigation has shown promise in using SMILES enumeration as a data augmentation technique for neural network QSAR models based on SMILES data.
相关文章:
arxiv2017 | 用于分子神经网络建模的数据增强 SMILES Enumeration
论文标题:SMILES Enumeration as Data Augmentation for Neural Network Modeling of Molecules论文地址:https://arxiv.org/abs/1703.07076代码地址:https://github.com/Ebjerrum/SMILES-enumeration一、摘要摘要中明显提出:先指…...
)
倒计时2天!TO B人的传统节日,2023年22客户节(22DAY)
去年,2022.02.22,正月二十二星期二,在这个最多2的一天,成功举办了“首届22客户节(22DAY)”,一群To B互联网人相约杭州见证; 癸卯兔年,2023.02.22,让我们再度…...

java版工程管理系统Spring Cloud+Spring Boot+Mybatis实现工程管理系统源码
java版工程管理系统Spring CloudSpring BootMybatis实现工程管理系统 工程项目各模块及其功能点清单 一、系统管理 1、数据字典:实现对数据字典标签的增删改查操作 2、编码管理:实现对系统编码的增删改查操作 3、用户管理:管理和…...
:142环形链表II、242有效的字母异位词、383赎金信、349两个数组的交集)
数据结构刷题(六):142环形链表II、242有效的字母异位词、383赎金信、349两个数组的交集
1.环形链表II题目链接思路:设置快慢双指针注意:(1)是否有环(快慢双指针是否能碰面也就是相等)(2)环形入口的判断。从头结点出发一个指针,从相遇节点 也出发一个指针&…...
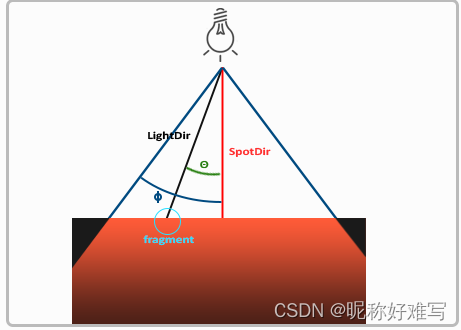
OpenGL学习日记之光照计算
引言 现实生活中的光照极其复杂,而且会收到很多因素的影响,是我们当前计算机的算力无法模拟的。因此我们会根据一些简化的模型来模拟现实光照,这样在可以模拟出近似的光照感受,但是又没有那么复杂的计算。 常用的光照模型有&…...
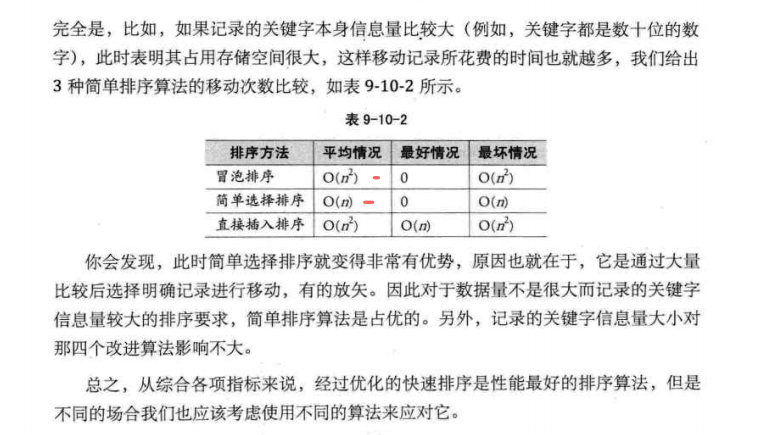
七大排序经典排序算法
吾日三省吾身:高否?富否?帅否?答曰:否。滚去学习!!!(看完这篇文章先)目前只有C和C的功底,暂时还未开启新语言的学习,但是大同小异,语法都差不多。目录:一.排序定义二.排序…...

设计模式—“对象性能”
面向对象很好地解决了“抽象”的问题,但是必不可免地要付出一定的代价。对于通常情况来讲,面向对象的成本大都可以忽略不计。但是某些情况,面向对象所带来的成本必须谨慎处理。 典型模式有:Singleton、Flyweight 一、Flyweight 运用共享技术将大量细粒度的对象进项复用,…...
基于Spring Boot的零食商店
文章目录项目介绍主要功能截图:登录后台首页个人信息管理用户管理前台首页购物车部分代码展示设计总结项目获取方式🍅 作者主页:Java韩立 🍅 简介:Java领域优质创作者🏆、 简历模板、学习资料、面试题库【关…...

Python语言的优缺点
为初学者而著!适合准备入行开发的零基础员学习python。python也是爬虫、大数据、人工智能等知识的基础。感兴趣的小伙伴可以评论区留言,领取视频教程资料和小编一起学习,共同进步!https://www.bilibili.com/video/BV13D4y1G7pt/?…...

3款强大到离谱的电脑软件,个个提效神器,从此远离加班
推荐3款让你偷懒,让你上头的提效电脑软件,个个功能强大,让你远离加班! 很多几个小时才能做好的事情,用上它们,只需要5分钟就行!! 1、JNPF —— 个人最喜欢的低代码软件 它为开发者…...

vue3 使用typescript小结
最近学习vue3 typescript,网上看了很多文章,汇总一下,分享给大家,希望会对大家有帮助。 一. 为props标注类型 defineProps()宏函数支持从它的参数中推导类型: <script setup langts>import { defineProps } fro…...
PYTHON爬虫基础
一、安装package 在使用爬虫前,需要先安装三个包,requests、BeautifulSoup、selenium。 输入如下代码,若无报错,则说明安装成功。 import requests from bs4 import BeautifulSoup import selenium二、Requests应用 了解了原理…...

JavaScript刷LeetCode模板技巧篇(一)
虽然很多人都觉得前端算法弱,但其实 JavaScript 也可以刷题啊!最近两个月断断续续刷完了 leetcode 前 200 的 middle hard ,总结了一些刷题常用的模板代码。 常用函数 包括打印函数和一些数学函数。 const _max Math.max.bind(Math); co…...
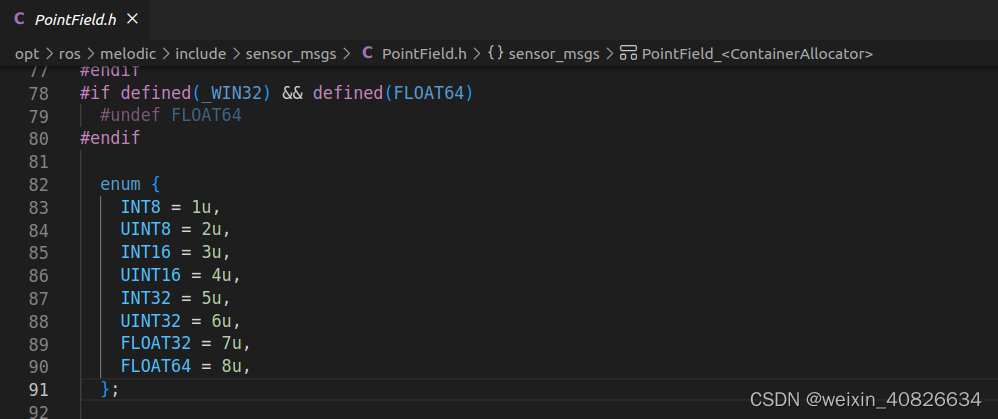
ros-sensor_msgs/PointCloud2消息内容解释
1.字段解释 header-----头文件,包含消息的序列号,时间戳(系统时间)和坐标系id,其中secs为秒,nsecs为去除秒数后剩余的纳秒数 height-----点云的高度,如果是无序点云,则为1,例子中的点云为有序点…...
LeetCode 每日一题2347. 最好的扑克手牌
Halo,这里是Ppeua。平时主要更新C语言,C,数据结构算法......感兴趣就关注我吧!你定不会失望。 🌈个人主页:主页链接 🌈算法专栏:专栏链接 我会一直往里填充内容哒! &…...
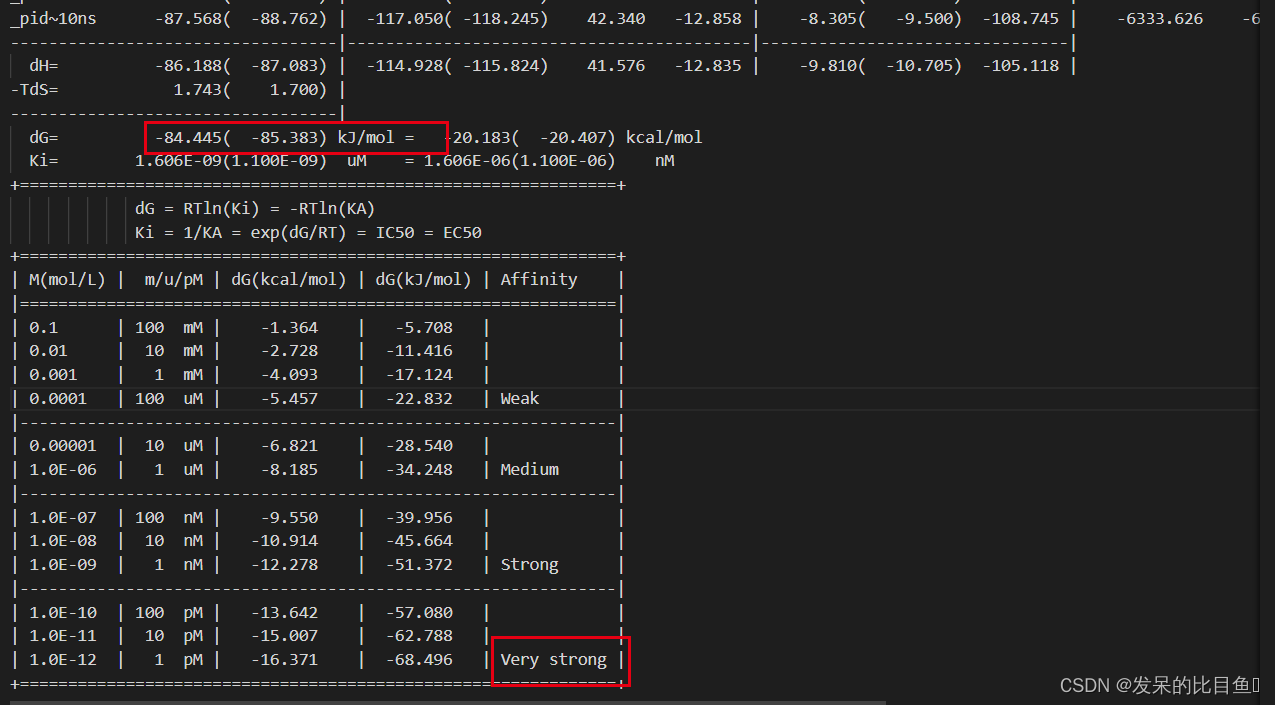
MMPBSA计算--基于李继存老师gmx_mmpbsa脚本
MMPBSA计算–基于李继存老师gmx_mmpbsa脚本 前期准备 软件安装 安装gromacs, 可以查阅 我的blogGromacs-2022 GPU-CUDA加速版 unbantu 安装 apbs, sudo apt install apbs 安装 gawk, sudo apt install gawk MD模拟好的文件 我们以研究蛋白小分子动态相互作用-III(蛋白配体…...

Kafka优化篇-压测和性能调优
简介 Kafka的配置详尽、复杂,想要进行全面的性能调优需要掌握大量信息,这里只记录一下我在日常工作使用中走过的坑和经验来对kafka集群进行优化常用的几点。 Kafka性能调优和参数调优 性能调优 JVM的优化 java相关系统自然离不开JVM的优化。首先想到…...
MinIo-SDK
3.2.5 SDK 3.2.5.1上传文件 MinIO提供多个语言版本SDK的支持,下边找到java版本的文档: 地址:https://docs.min.io/docs/java-client-quickstart-guide.html 最低需求Java 1.8或更高版本: maven依赖如下: XML<dependency&g…...

系统分析师真题2018试卷相关概念一
面向对象的基本概念: 对象的三要素为:属性(数据)、方法(操作)、对象ID(标识)UML2.0包括14种图: 类图(class diagram):类图描述一组类、接口、协作和他们之间的关系。在OO系统的建模中,最常见的图就是类图。类图给出了系统的静态设计图,活动类的类图给出了系统的静…...
身为大学生,你不会还不知道有这些学生福利吧!!!!
本文介绍的是利用学生身份可以享受到的相关学生优惠权益,但也希望各位享受权利的同时不要忘记自己的义务,不要售卖、转手自己的学生优惠资格,使得其他同学无法受益。 前言 高考已经过去,我们也将迎来不同于以往的大学生活&#x…...

Pop 核心架构解析:深入理解 Bubble Tea 框架与邮件发送原理
Pop 核心架构解析:深入理解 Bubble Tea 框架与邮件发送原理 【免费下载链接】pop Send emails from your terminal 📬 项目地址: https://gitcode.com/gh_mirrors/pop2/pop 想要在终端中优雅地发送邮件吗?Pop 是一个基于 Go 语言开发的…...

全网炸了!5亿人用的Axios竟被投毒,你的密钥还保得住吗?
早些时候,聊过 Python 领域那场惊心动魄的供应链攻击。当时我就感叹,虽然我们 JavaScript 开发者对这类套路烂熟于心,但亲眼目睹这种规模的“投毒”还是头一次。然而,属于我们 JS 圈的至暗时刻,终究还是卷土重来了。而…...

Spring-AI 第 13 章 - 多模态消息处理详解
📚 理论基础 什么是多模态 AI? 多模态 AI(Multimodal AI) 是能够同时处理和生成多种类型数据(文本、图像、音频等)的人工智能系统。 多模态模型架构 ┌──────────────┐ ┌──────────────┐ │ 图像输入 │ │ 文本输入 …...

雷达目标分类及宽带测角方案设计实现
本文参考,仅供学习使用基于飞腾M6678的雷达目标 分类和宽带测角研究与实现硬件计算平台介绍1. 飞腾M6678芯片核心参数与优势飞腾M6678是国防科技大学自主研发的国产多核DSP,专为数字信号处理设计,核心特性为:硬件资源:…...

如何通过arknights-ui实现明日方舟界面定制?解锁个性化游戏体验新方式
如何通过arknights-ui实现明日方舟界面定制?解锁个性化游戏体验新方式 【免费下载链接】arknights-ui H5 复刻版明日方舟游戏主界面 项目地址: https://gitcode.com/gh_mirrors/ar/arknights-ui arknights-ui是一个基于H5CSS技术的开源项目,它提供…...

Nine PRO 邮箱 APP专业高级版 邮箱合集整理 一个就够了
软件简介: Nine 是一款面向 Android 的专业级电子邮件客户端,主打 Exchange 生态深度适配、本地数据存储与全链路安全,集邮件、日历、联系人、任务与笔记于一体,是商务办公与多账户管理的高效工具。 核心定位: 专为 …...

告别subfloat!LaTeX中minipage+subfigure排版多图的最佳实践
LaTeX多图排版进阶指南:minipage与subfigure的黄金组合 在学术论文和技术文档写作中,图片排版往往是让人头疼的问题。特别是当需要处理多张图片并为其添加子标题时,传统的subfloat方法常常会遇到标题溢出、无法自动换行等令人沮丧的情况。本文…...

解决Windows 11 LTSC应用商店缺失难题:从根源修复到生态重建的完整方案
解决Windows 11 LTSC应用商店缺失难题:从根源修复到生态重建的完整方案 【免费下载链接】LTSC-Add-MicrosoftStore Add Windows Store to Windows 11 24H2 LTSC 项目地址: https://gitcode.com/gh_mirrors/ltscad/LTSC-Add-MicrosoftStore 在企业环境和专业工…...

完美架构的设计哲学与实践方法论
“完美架构不是设计出来的,是演化出来的。核心是高内聚低耦合 开闭原则 依赖倒置。抓住三个关键点:边界清晰、变化隔离、可测试。沟通上用架构图 契约测试对齐认知,代码组织遵循六边形架构,调试建立可观测性体系。”一、完美架…...
)
信号处理实战:如何用Python快速实现FFT频域分析(附完整代码)
信号处理实战:如何用Python快速实现FFT频域分析(附完整代码) 在数字信号处理领域,频域分析是揭示信号隐藏特征的关键技术。想象一下,你面对一组看似杂乱无章的传感器数据,或是音频工程师需要分析一段复杂的…...