【C++心愿便利店】No.3---内联函数、auto、范围for、nullptr
文章目录
- 前言
- 🌟一、内联函数
- 🌏1.1.面试题
- 🌏1.2.内联函数概念
- 🌏1.3.内联函数特性
- 🌟二、auto关键字
- 🌏2.1.类型别名思考
- 🌏2.2.auto简介
- 🌏2.3.auto的使用细节
- 🌏2.4.auto不能推导的场景
- 🌏2.5.小场景补充
- 🌟三、基于范围的for循环
- 🌏3.1.范围for的语法
- 🌏3.2.范围for的使用条件
- 🌟四、指针空值nullptr
前言

👧个人主页:@小沈YO.
😚小编介绍:欢迎来到我的乱七八糟小星球🌝
📋专栏:C++ 心愿便利店
🔑本章内容:内联函数、auto、范围for、nullptr
记得 评论📝 +点赞👍 +收藏😽 +关注💞哦~
提示:以下是本篇文章正文内容,下面案例可供参考
🌟一、内联函数
🌏1.1.面试题
通过对C语言的学习,对于宏有了一定的了解,当定义一个宏常量是是非常方便的直接替换这在数据结构链表处有明显的体现,但是对于宏函数的写法就比较容易出错有以下几种形式的错误需要提醒:
#define N 10//宏常量
//宏函数
#define ADD(int x , int y) {return x+y;}//宏的调用不需要return
#define ADD(x , y) (return x+y;)
#define ADD(x , y) return x+y;#define ADD(x , y) x+y;//宏后面不需要分号
//加分号是可以的但对于有些语法是不通过的
int main()
{ADD(1, 2);//这种是不会报错的printf("%d\n", ADD(1, 2));//这种会报错因为宏替换后,会多出一个分号return 0;
}#define ADD(x , y) x+y//可能出现优先级错误
int main()
{ADD(1, 2);printf("%d\n", ADD(1, 2));printf("%d\n", ADD(1, 2) * 3);//这里替换后变成了1+2*3=7显然不是想要得到的9return 0;
}#define ADD(x , y) (x+y)//可能出现优先级错误
int main()
{ADD(1, 2);printf("%d\n", ADD(1, 2));printf("%d\n", ADD(1, 2) * 3);int a = 1, b = 2;ADD(a | b, a & b);//替换后变成(a|b+a&b) +号的优先级高于| &所以会先算+return 0;
}#define ADD(x , y) ((x)+(y)) 这是正确的
宏的优缺点?
优点:
1.增强代码的复用性。
2.提高性能。
缺点:
1.不方便调试宏。(因为预编译阶段进行了替换)
2.导致代码可读性差,可维护性差,容易误用,语法很坑。
3.没有类型安全的检查 。
宏函数的优点:
1.没有类型的严格限制
2.针对频繁调用小函数,不需要再建立栈帧,提高了效率
int Add(int left, int right)
//这种函数调用是需要建立栈帧的但是宏函数不需要直接替换了
{return left + right;
}
C++有哪些技术替代宏?
- 常量定义 换用const enum
- 短小函数定义 换用内联函数
🌏1.2.内联函数概念
以inline修饰的函数叫做内联函数,编译时C++编译器会在调用内联函数的地方展开,没有函数调用建立栈帧的开销,内联函数提升程序运行的效率。
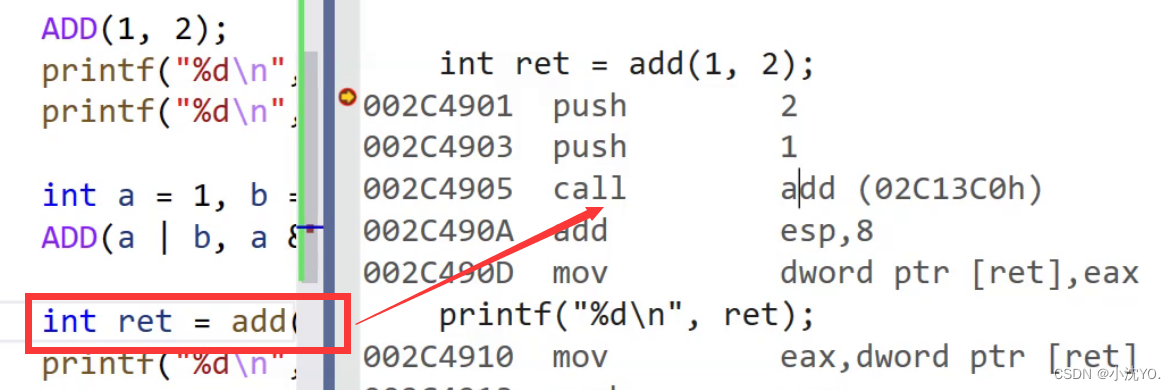
如果在上述函数前增加inline关键字将其改成内联函数,在编译期间编译器会用函数体替换函数的调用。
- 在release模式下,查看编译器生成的汇编代码中是否存在call Add
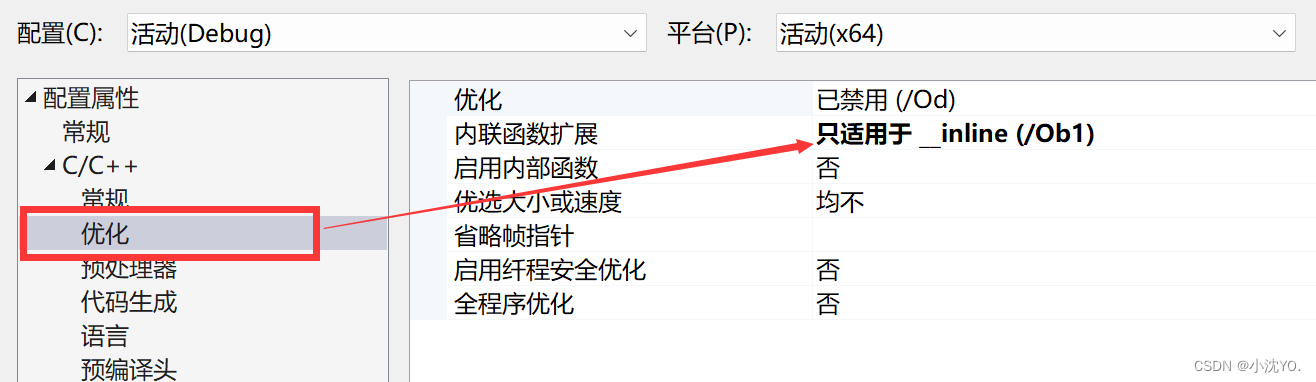
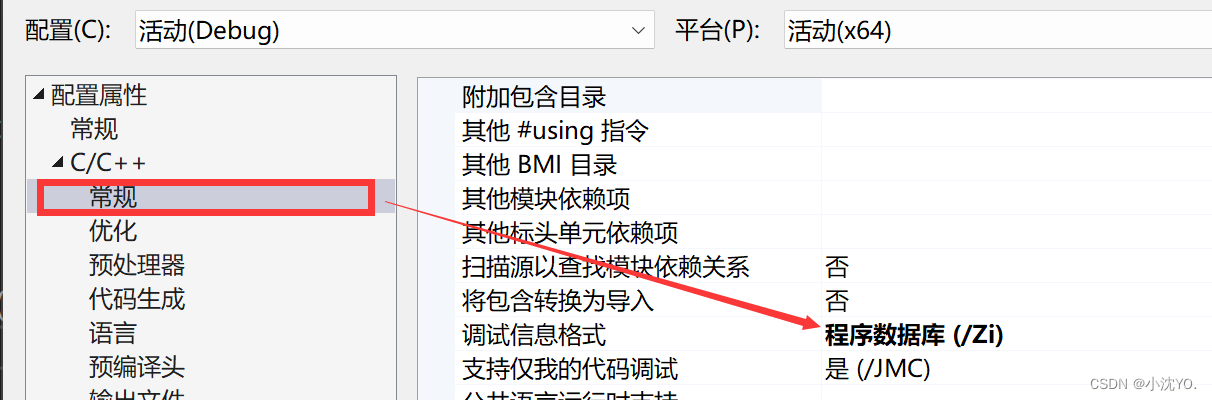
- 在debug模式下,需要对编译器进行设置,否则不会展开(因为debug模式下,编译器默认不会对代码进行优化,以下给出vs2013的设置方式)

inline int add(int x, int y)
{return x + y;
}
int main()
{int a = 1, b = 2;int ret = add(1, 2);//int ret = add(a | b , a & b);//这样写也不会像宏函数一样出错了printf("%d\n", ret);return 0;
}
🌏1.3.内联函数特性
inline是一种以空间换时间的做法,如果编译器将函数当成内联函数处理,在编译阶段,会用函数体替换函数调用,缺陷:可能会使目标文件变大(代码膨胀),优势:少了调用开销,提高程序运行效率。(不能任何情况下都用内联)
inline对于编译器而言只是一个建议,不同编译器关于inline实现机制可能不同,一般建议:将函数规模较小(即函数不是很长,具体没有准确的说法,取决于编译器内部实现)、不是递归、且频繁调用的函数采用inline修饰,否则编译器会忽略inline特性。下图为《C++prime》第五版关于inline的建议:
一般来说,内联机制用于优化规模较小、流程直接、频繁调用的函数。很多编译器都不支持内联递归函数,而且一个75行的函数也不大可能在调用点内联地展开。
inline int add(int x, int y)
{return x + y;
}
inline int func()
{int x1= 0;int x2 = 0;int x3 = 0;int x4 = 0;int ret = 0;ret += x1;ret *= x2;ret /= x3;ret /= x3;ret /= x3;ret += x1;ret += x1;return ret;
}
int main()
{int a = 1, b = 2;//int ret = add(1, 2);int ret = add(a | b , a & b);printf("%d\n", ret);ret = func();return 0;
}
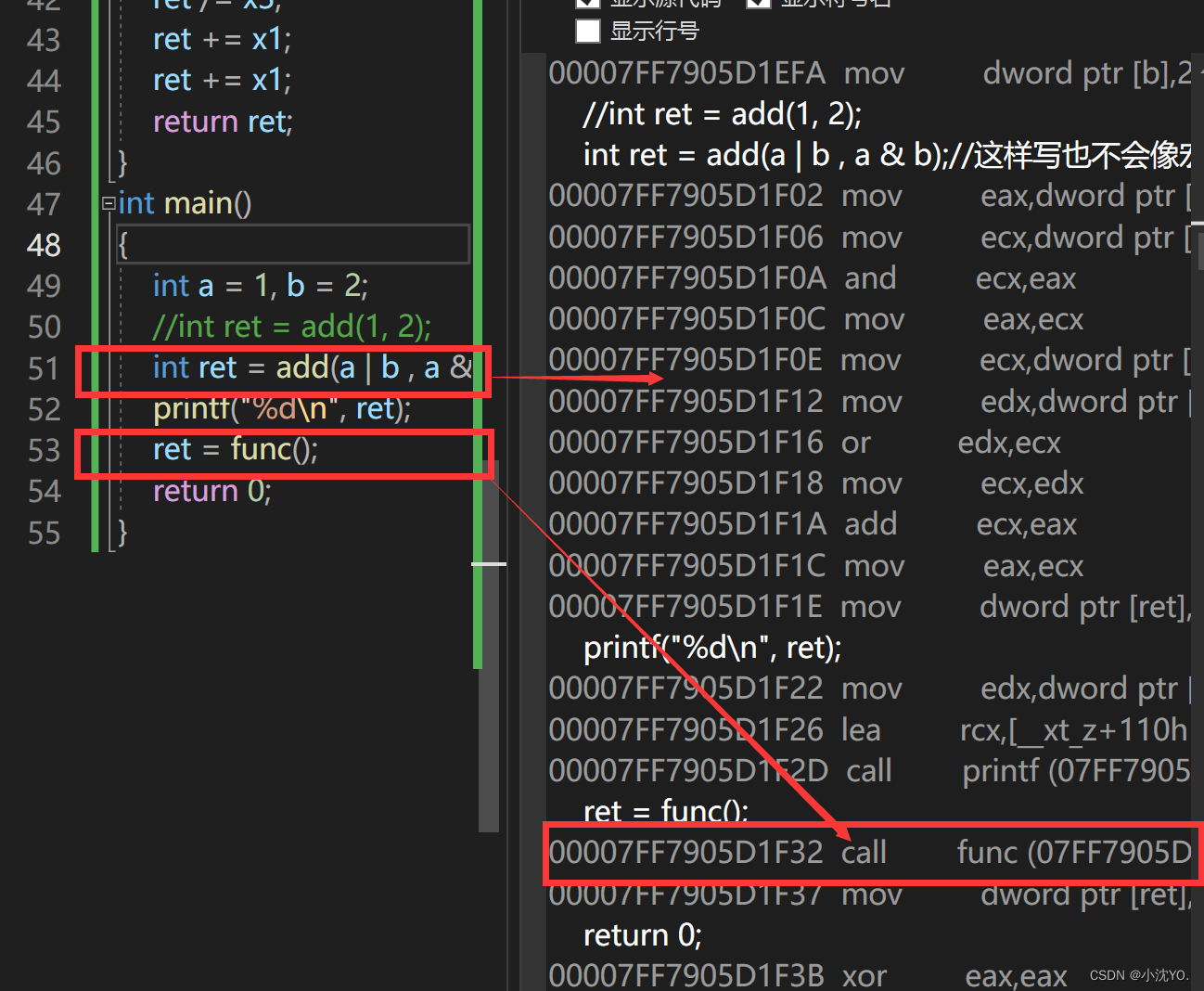
inline int add(int x, int y)
{return x + y;
}
inline int func()
{int x1= 0;int x2 = 0;int x3 = 0;int x4 = 0;int ret = 0;ret += x1;return ret;
}
int main()
{int a = 1, b = 2;//int ret = add(1, 2);int ret = add(a | b , a & b);//这样写也不会像宏函数一样出错了printf("%d\n", ret);ret = func();return 0;
}
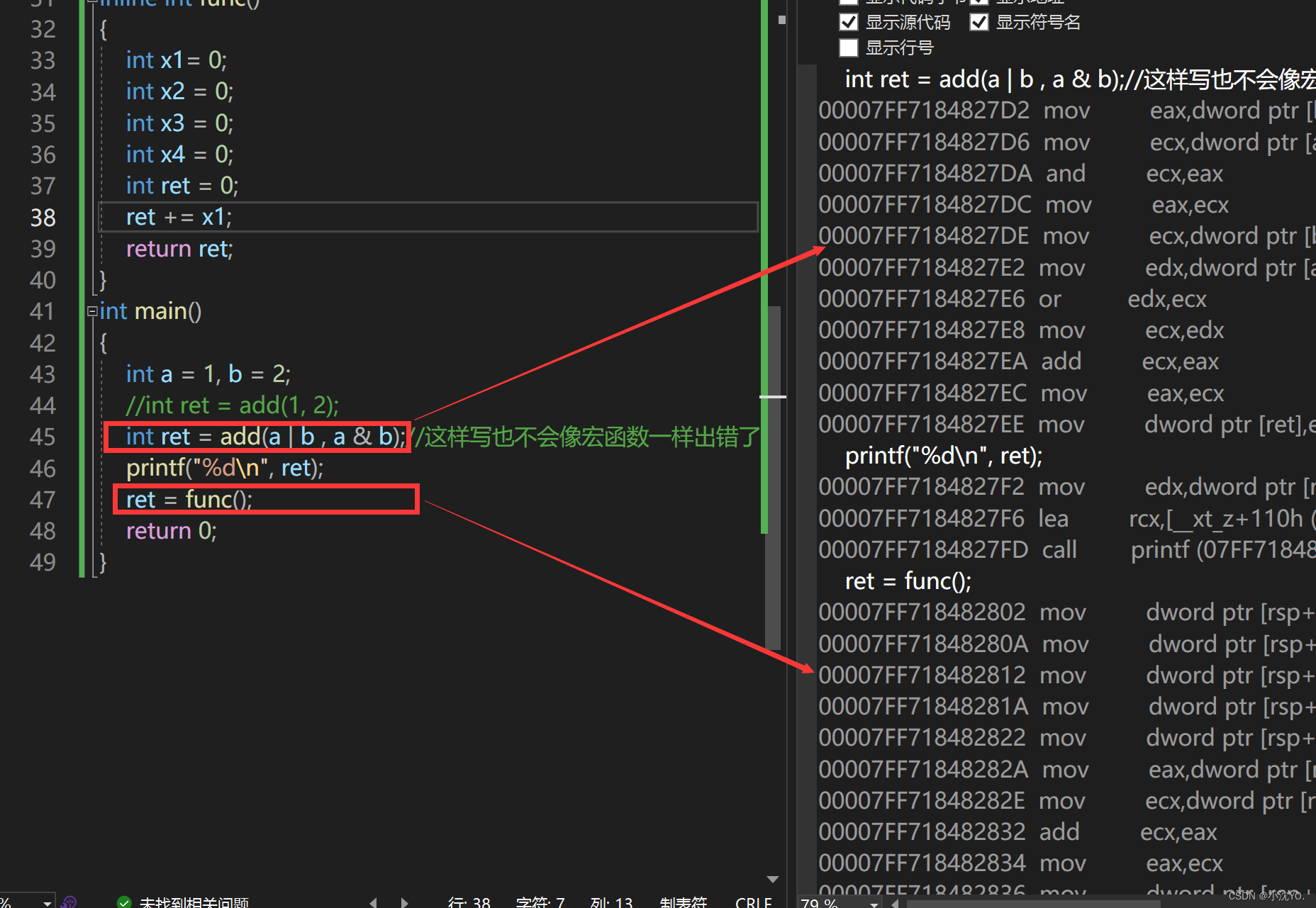
inline不建议声明和定义分离,分离会导致链接错误。因为inline被展开,就没有函数地址了,链接就会找不到
//Func.h
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>using namespace std;inline void f(int i);//Func.cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include "Func.h"
void f(int i)
{cout << "f(int i)" << i << endl;
}//Test.cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
#include"Func.h"
using namespace std;
int main()
{f(1);//只有声明需要地址(但内联不会进入符号表)return 0;
}
Test.cpp调用f(1)函数,f()只有声明没有定义,调用实际链接的时候编译语法都过了,允许在链接的时候再去找地址,定义可能在其他地方,就去其他地方找地址(用函数名修饰规则去找)找不到就会出现链接错误
当Func.h中inline void f(int i);变成void f(int i)就不会出现问题(去掉内联)

//Func.h
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>using namespace std;inline void f(int i);void fx();//Func.cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include "Func.h"
void f(int i)
{cout << "f(int i)" << i << endl;
}
void fx()
{f(1);//既有声明也有定义这里直接展开不需要地址
}//Test.cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
#include"Func.h"
using namespace std;
int main()
{f(1);fx();return 0;
}
f()这个函数肯定是在的,不然fx()就不会调到它,但是Test.cpp中的 f() 不可调用Func.cpp中的 f() 可以调用,一般只有声明没有定义调不到,但是在Func.cpp中定义了 f()也调不到,原因就是f()函数定义成了内联,在用的地方就展开了就不需要生成指令建立栈帧把地址放进符号表

//Func.h
//声明和定义不分离
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>using namespace std;inline void f(int i);
{cout << "f(int i)" << i << endl;
}//Test.cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
#include"Func.h"
using namespace std;
int main()
{f(1);return 0;
}
🌟二、auto关键字
🌏2.1.类型别名思考
随着程序越来越复杂,程序中用到的类型也越来越复杂,经常体现在:
- 类型难于拼写
- 含义不明确导致容易出错
#include<iostream>
#include<vector>
#include<string>
using namespace std;
int TestAuto()
{return 10;
}
int main()
{std::vector<std::string>v;//std::vector<std::string>::iterator it = v.begin();《==》auto it = v.begin();auto it = v.begin();cout << typeid(it).name() << endl;//auto e; 无法通过编译,使用auto定义变量时必须对其进行初始化return 0;
}
在编程时,常常需要把表达式的值赋值给变量,这就要求在声明变量的时候清楚地知道表达式的类型。然而有时候要做到这点并非那么容易,因此C++11给auto赋予了新的含义
🌏2.2.auto简介
在早期C/C++中auto的含义是:使用auto修饰的变量,是具有自动存储器的局部变量,但遗憾的是一直没有人去使用它,大家可思考下为什么?
C++11中,标准委员会赋予了auto全新的含义即:auto不再是一个存储类型指示符,而是作为一个新的类型指示符来指示编译器,auto声明的变量必须由编译器在编译时期推导而得(根据右边的值自动推导左边的类型)
int TestAuto()
{return 10;
}
int main()
{int a = 10;auto b = a;auto c = 'a';auto d = TestAuto();cout << typeid(b).name() << endl;cout << typeid(c).name() << endl;cout << typeid(d).name() << endl;//auto e; 无法通过编译,使用auto定义变量时必须对其进行初始化return 0;
}
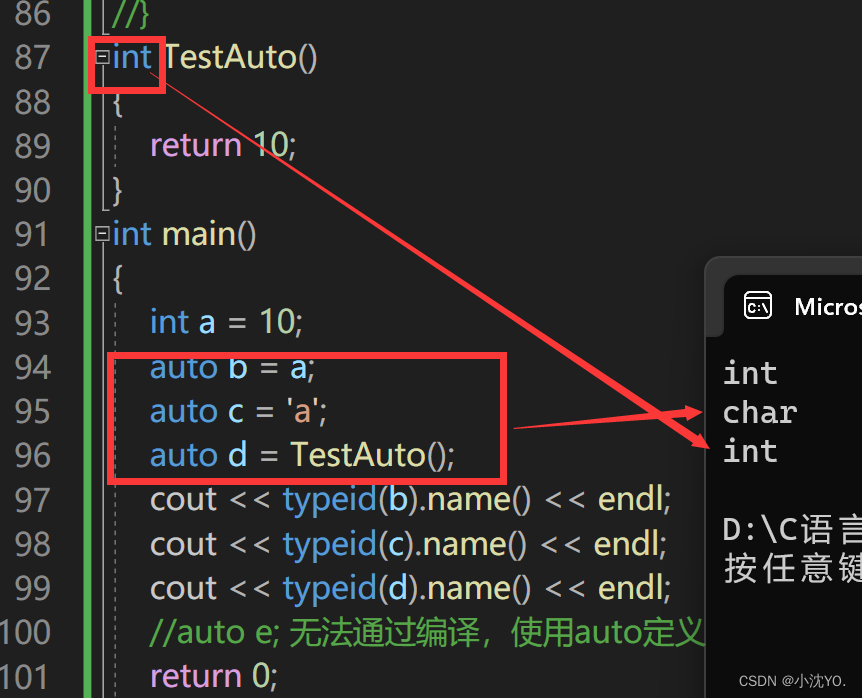
使用auto定义变量时必须对其进行初始化,在编译阶段编译器需要根据初始化表达式来推导auto的实际类型。因此auto并非是一种“类型”的声明,而是一个类型声明时的“占位符”,编译器在编译期会将auto替换为变量实际的类型。
🌏2.3.auto的使用细节
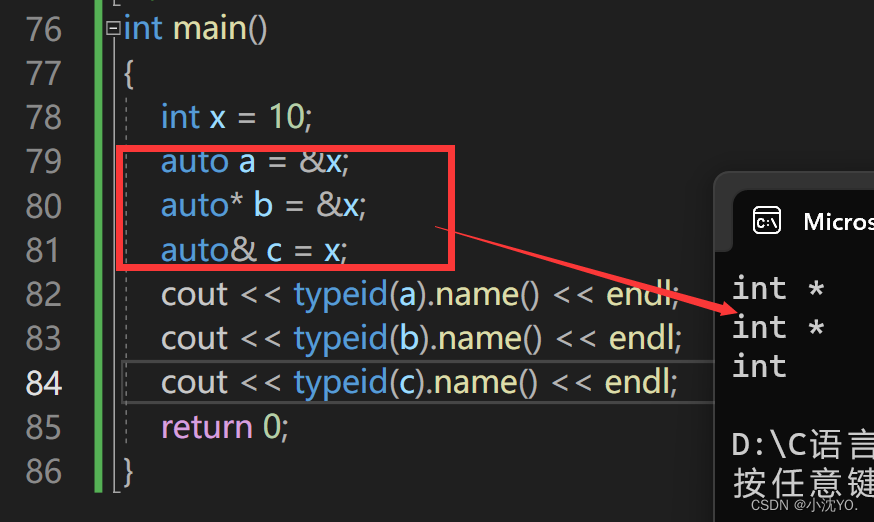
int main()
{int x = 10;auto a = &x;auto* b = &x;auto& c = x;cout << typeid(a).name() << endl;cout << typeid(b).name() << endl;cout << typeid(c).name() << endl;return 0;
}
void TestAuto()
{auto a = 1, b = 2; auto c = 3, d = 4.0; // 该行代码会编译失败,因为c和d的初始化表达式类型不同
}
🌏2.4.auto不能推导的场景
- auto不能作为函数的参数
// 此处代码编译失败,auto不能作为形参类型,因为编译器无法对a的实际类型进行推导
void TestAuto(auto a)
{}
- auto不能直接用来声明数组
void TestAuto()
{int a[] = {1,2,3};auto b[] = {4,5,6};
}
- 为了避免与C++98中的auto发生混淆,C++11只保留了auto作为类型指示符的用法
- auto在实际中最常见的优势用法就是跟以后会讲到的C++11提供的新式for循环,还有lambda表达式等进行配合使用。
🌏2.5.小场景补充
TypeId 返回一个变量或数据类型的“类型”。
🌟三、基于范围的for循环
🌏3.1.范围for的语法
在C++98中如果要遍历一个数组,可以按照以下方式进行:
#include<iostream>
using namespace std;
void TestFor()
{int array[] = { 1, 2, 3, 4, 5 };for (int i = 0; i < sizeof(array) / sizeof(array[0]); ++i)array[i] *= 2;for (int* p = array; p < array + sizeof(array) / sizeof(array[0]); ++p)cout << *p<<" ";
}
int main()
{TestFor();return 0;
}
对于一个有范围的集合而言,由程序员来说明循环的范围是多余的,有时候还会容易犯错误。因此C++11中引入了基于范围的for循环。for循环后的括号由冒号“ :”分为两部分:第一部分是范围内用于迭代的变量,第二部分则表示被迭代的范围
#include<iostream>
using namespace std;
void TestFor()
{int array[] = { 1, 2, 3, 4, 5 };for (int i = 0; i < sizeof(array) / sizeof(array[0]); ++i)array[i] *= 2;for (int* p = array; p < array + sizeof(array) / sizeof(array[0]); ++p)cout << *p<<" ";cout << endl;for (auto& n : array)//至于这里为什么采用引用//是因为不采用引用只是从array中取数赋值给n,n*=2发生变化对数组没影响所以要引用才能改变数组{n *= 2;}for (auto m : array)//当然也不是必须写成auto m,可以int m ,double m,只是auto会根据右边值的类型推导出左边类型{cout << m << " ";}cout << endl;
}
int main()
{TestFor();return 0;
}
🌏3.2.范围for的使用条件
对于数组而言,就是数组中第一个元素和最后一个元素的范围;对于类而言,应该提供
begin和end的方法,begin和end就是for循环迭代的范围。
注意:以下代码就有问题,因为for的范围不确定
void TestFor(int array[])
{for(auto& e : array)cout<< e <<endl;
}
🌟四、指针空值nullptr
在良好的C/C++编程习惯中,声明一个变量时最好给该变量一个合适的初始值,否则可能会出现不可预料的错误,比如未初始化的指针。如果一个指针没有合法的指向,我们基本都是按照如下方式对其进行初始化:
void TestPtr()
{
int* p1 = NULL;
int* p2 = 0;
// ……
}
NULL实际是一个宏,在传统的C头文件(stddef.h)中,可以看到如下代码:
#ifndef NULL
#ifdef __cplusplus
#define NULL 0
#else
#define NULL ((void *)0)
#endif
#endif
可以看到,NULL可能被定义为字面常量0,或者被定义为无类型指针(void*)的常量。不论采取何种定义,在使用空值的指针时,都不可避免的会遇到一些麻烦,比如:
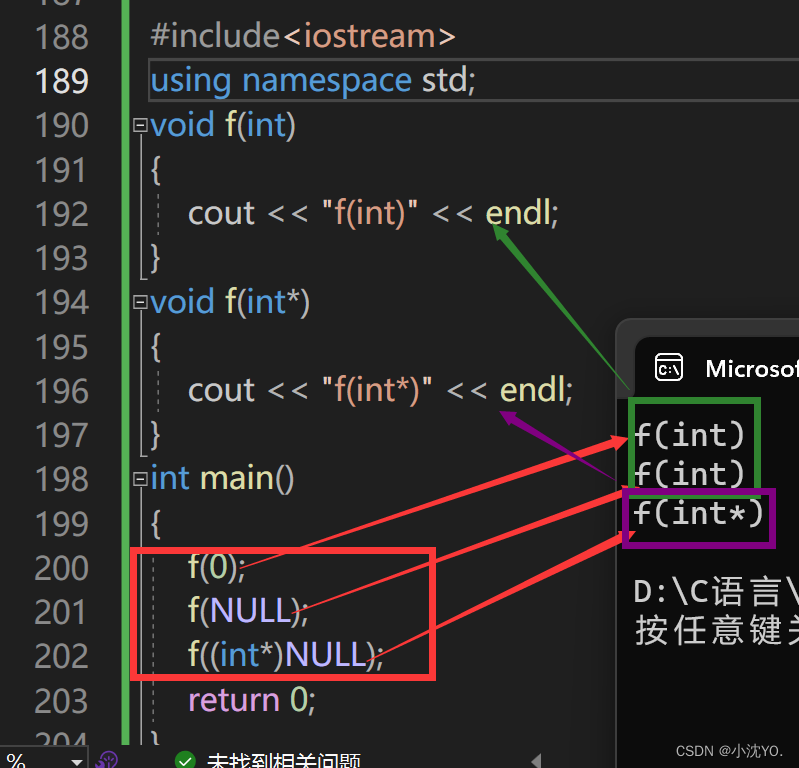
#include<iostream>
using namespace std;
void f(int)
{cout << "f(int)" << endl;
}
void f(int*)
{cout << "f(int*)" << endl;
}
int main()
{f(0);f(NULL);f((int*)NULL);return 0;
}
程序本意是想通过f(NULL)调用指针版本的f(int*)函数,但是由于NULL被定义成0,因此与程序的初衷相悖。
在C++98中,字面常量0既可以是一个整形数字,也可以是无类型的指针(void*)常量,但是编译器默认情况下将其看成是一个整形常量,如果要将其按照指针方式来使用,必须对其进行强转(void *)0。
-
在使用nullptr表示指针空值时,不需要包含头文件,因为nullptr是C++11作为新关键字引入的。
-
在C++11中,sizeof(nullptr) 与 sizeof((void*)0)所占的字节数相同。
-
为了提高代码的健壮性,在后续表示指针空值时建议最好使用nullptr
相关文章:
【C++心愿便利店】No.3---内联函数、auto、范围for、nullptr
文章目录 前言🌟一、内联函数🌏1.1.面试题🌏1.2.内联函数概念🌏1.3.内联函数特性 🌟二、auto关键字🌏2.1.类型别名思考🌏2.2.auto简介🌏2.3.auto的使用细节🌏2.4.auto不能…...

CV:边缘检测的算法包含 Prewitt、Sobel、Laplacian 和 Canny。
目录 1. 边缘检测(Prewitt) 2. 边缘检测(Sobel) 3. 边缘检测(Laplacian) 3. 边缘检测(Canny) 边缘检测的算法包含 Prewitt、Sobel、Laplacian 和 Canny。 人在图像识别上具有难…...
【算法系列篇】前缀和
文章目录 前言什么是前缀和算法1.【模板】前缀和1.1 题目要求1.2 做题思路1.3 Java代码实现 2. 【模板】二维前缀和2.1 题目要求2.2 做题思路2.3 Java代码实现 3. 寻找数组的中心下标3.1 题目要求3.2 做题思路3.3 Java代码实现 4. 除自身以外的数组的乘积4.1 题目要求4.2 做题思…...
若依移动端Ruoyi-App 项目的后端项目入门
后端项目运行 运行报错 Error creating bean with name sysConfigServiceImpl: Invocation of init method failed 数据库创建了。 代码连接数据库地方了也匹配上了。但是还是报错。 分析 : 想起来我电脑从来没有安装过redis 下载安装redis到windows 链接&…...

(学习笔记-调度算法)内存页面置换算法
在了解内存页面置换算法前,我们得先了解 缺页异常(缺页中断)。 当 CPU 访问的页面不在物理内存中时,便会产生一个缺页中断,请求操作系统将缺页调入到物理内存。那它与一般的中断主要区别在于: 缺页中断在指令执行 [期…...

行为型模式-观察者模式
1.观察者设计模式* 定义:当对象间存在一对多关系时,则使用观察者模式(Observer Pattern)。比如,当一个对象被修改时,则会自动通知依赖它的对象。观察者模式属于行为型模式。 意图:定义对象间的…...

前端面试:【新技术与趋势】WebAssembly、Serverless、GraphQL
在不断演进的技术领域中,WebAssembly、Serverless和GraphQL都是备受关注的新技术和趋势。它们改变了软件开发、部署和数据传输的方式,为开发者提供了更多的选择和灵活性。 1. WebAssembly(Wasm): 简介: Web…...
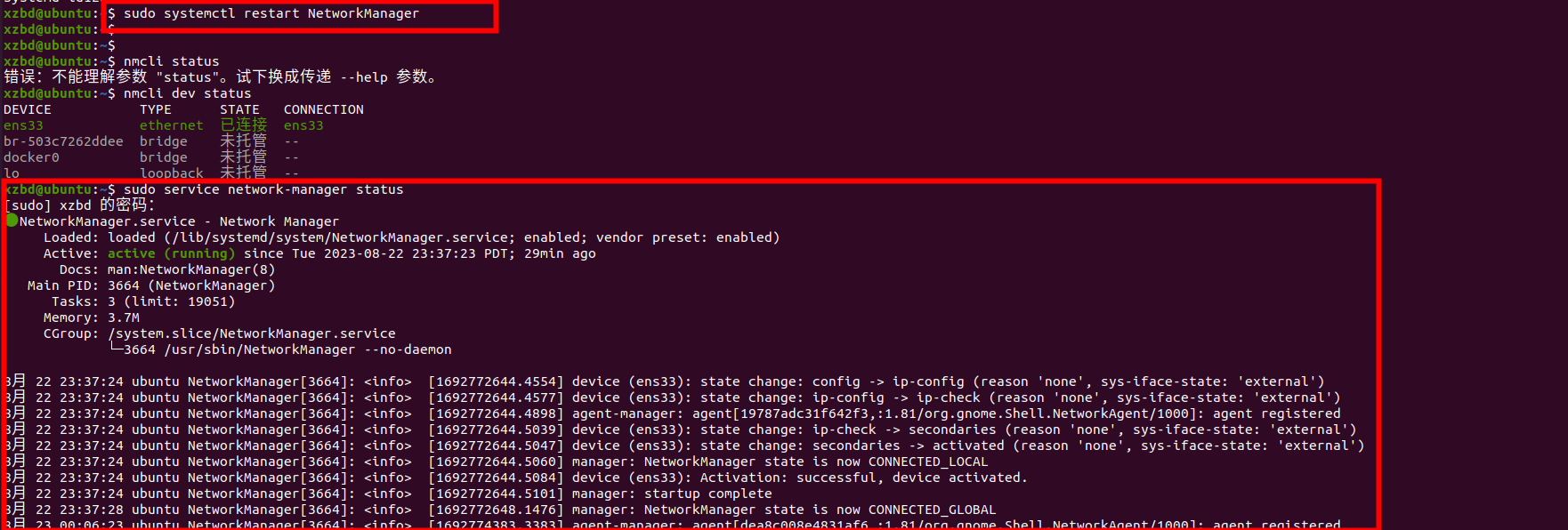
【ubuntu】 20.04 网络连接器图标不显示、有线未托管、设置界面中没有“网络”选项等问题解决方案
问题 在工作中 Ubuntu 20.04 桌面版因挂机或不当操作,意外导致如下问题 1、 Ubuntu 网络连接图标消失 2、 有线未托管 上图中展示的是 有线 已连接 ,故障的显示 有限 未托管 或其他字符 3、 ”设置“ 中缺少”网络“选项 上图是设置界面,…...
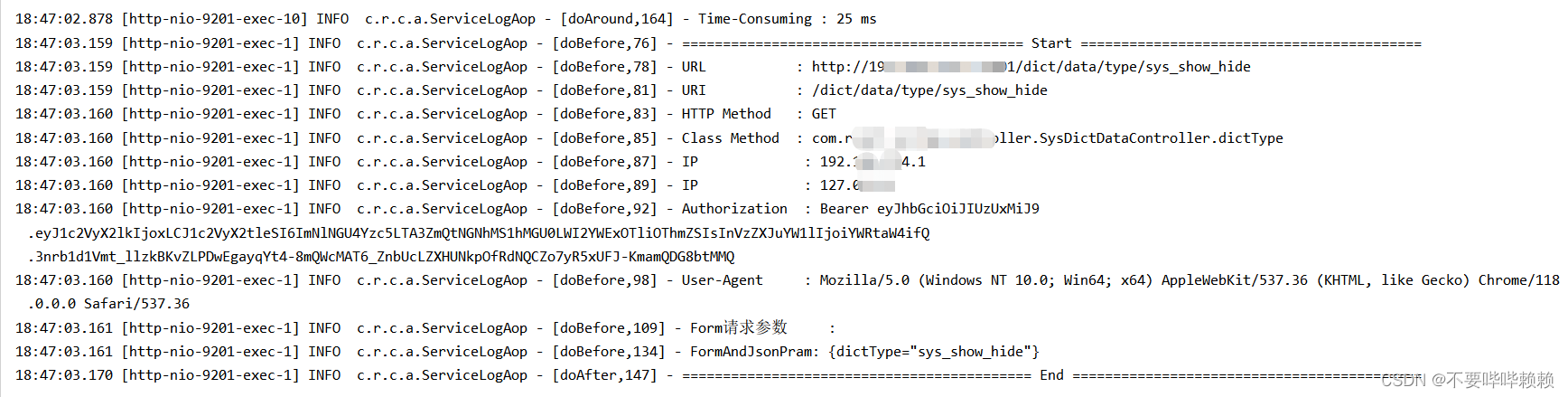
SpringCloud/SpringBoot多模块项目中配置公共AOP模块实现打印子模块Controller所有请求参数与日志
项目中遇到多个模块需要打印Controller请求日志,在每个模块里面加AOP并且配置单独的切面笔者认为代码冗余,于是乎就打算把AOP日志打印抽离成一个公共模块,谁想用就引入Maven坐标就行。 定义公共AOP模块 并编写AOP工具 AOP模块pom.xml如下 &…...

【GeoDa实用技巧100例】022:geoda生成空间权重矩阵(邻接矩阵、距离矩阵)
geoda生成空间权重矩阵(邻接矩阵、距离矩阵),车式矩阵、后式矩阵、K邻接矩阵。 文章目录 一、概述二、“车式”邻接的gal文档生成三、“后式”邻接gal文档生成四、k最近邻居gat文档生成五、查看gal和gat文档一、概述 空间权重矩阵(或相应的表格形式)一般需要用计算机软件生…...
基于web的鲜花商城系统java jsp网上购物超市mysql源代码
本项目为前几天收费帮学妹做的一个项目,Java EE JSP项目,在工作环境中基本使用不到,但是很多学校把这个当作编程入门的项目来做,故分享出本项目供初学者参考。 一、项目描述 基于web的鲜花商城系统 系统有2权限:前台…...
意外发现Cortex-M内核带的64bit时间戳,比32bit的DWT时钟周期计数器更方便,再也不用担心溢出问题了
视频: https://www.bilibili.com/video/BV1Bw411D7F5 意外发现Cortex-M内核带的64bit时间戳,比32bit的DWT时钟周期计数器更方便,再也不用担心溢出问题了 介绍: 看参数手册的Debug章节,System ROM Table里面带Timestam…...
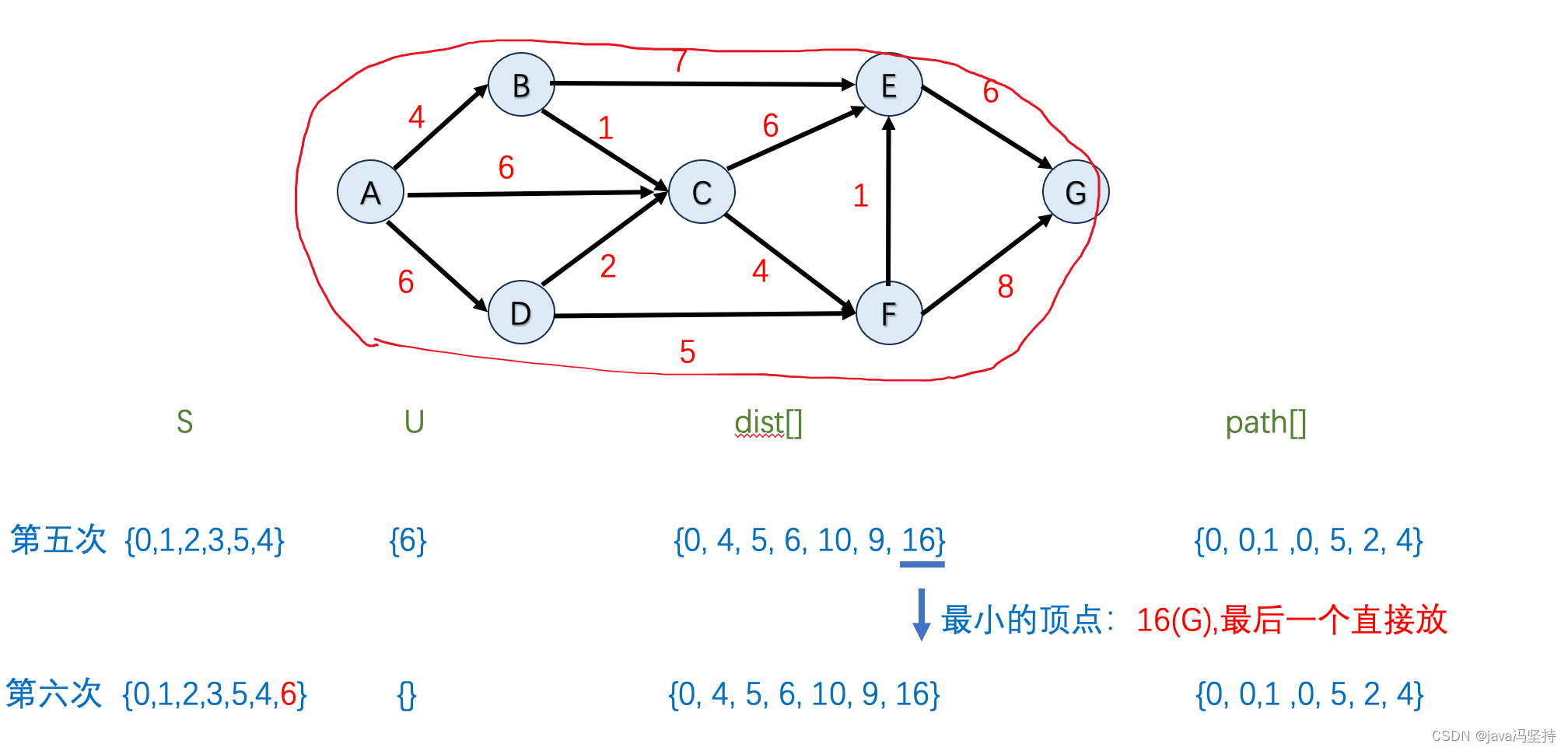
数据结构与算法细节篇之最短路径问题:Dijkstra和Floyd算法详细描述,java语言实现。
文章目录 前言一、单源最短路径1、单源最短路径问题2、Dijkstra 初始化a、参数b、初始化参数c、算法步骤 3、Dijkstra 算法详细步骤a、第一轮算法执行b、第二轮算法执行c、第三轮算法执行d、第四轮算法执行e、第五轮算法执行f、第六轮算法执行 4、java算法实现 二、多源最短路径…...
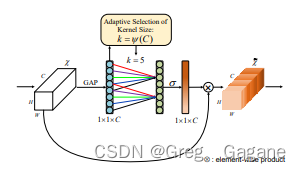
改进YOLO系列:6.添加ECA注意力机制
添加ECA注意力机制 1. ECA注意力机制论文2. ECA注意力机制原理3. ECA注意力机制的配置3.1common.py配置3.2yolo.py配置3.3yaml文件配置1. ECA注意力机制论文 论文题目:ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks 论文链接:ECA-N…...
软件测试知识点总结(一)
文章目录 前言一. 什么是软件测试二. 软件测试和软件调试的区别三. 软件测试和研发的区别四. 优秀的测试人员所应该具备的素质总结 前言 在现实生活中的很多场景下,我们都会进行测试。 比如买件衣服,我们需要看衣服是不是穿着好看,衣服材质如…...

持续集成与持续交付:现代软件测试的变革之路
引言 在数字化时代,软件开发的速度和复杂性都在不断增加。为了满足市场的需求,企业需要更快、更高效地交付高质量的软件产品。在这样的背景下,持续集成与持续交付(CI/CD)成为了软件开发和测试的核心实践。 软件开发的…...
深度学习基本理论下篇:(梯度下降/卷积/池化/归一化/AlexNet/归一化/Dropout/卷积核)、深度学习面试
深度学习基本理论上篇:(MLP/激活函数/softmax/损失函数/梯度/梯度下降/学习率/反向传播) 深度学习基本理论上篇:(MLP/激活函数/softmax/损失函数/梯度/梯度下降/学习率/反向传播)、深度学习面试_会害羞的杨…...
)
[Ubuntu 20.04] 通过udev规则修改网卡名称(例如eth0)
在 Ubuntu 20.04 操作系统中,默认情况下,网卡接口名称采用了一种较为复杂的命名方式(如 enp0s3、eth0 等)。然而,有时候我们可能更希望使用更简洁和易于识别的名称来标识不同的网络接口。那么如何在 Ubuntu 20.04 中修改网卡接口的名称,以满足个性化需求。 步骤一:查看当…...

Java“牵手”根据关键词搜索(分类搜索)lazada商品列表页面数据获取方法,lazadaAPI实现批量商品数据抓取示例
lazada商城是一个网上购物平台,售卖各类商品,包括服装、鞋类、家居用品、美妆产品、电子产品等。要获取lazada商品列表和商品详情页面数据,您可以通过开放平台的接口或者直接访问lazada商城的网页来获取商品详情信息。以下是两种常用方法的介…...
Java—实现多线程程序 | 入门
目录 一、前言 二、基本概念 进程 线程 三、Java多线程实现 java.lang.Thread类 获取线程名字及对象 获取main进程名 Thread currentThread() 四、线程优先级 设置优先级 一、前言 前期入门学习的代码中,全部都是单线的程序,也就是从头到尾…...

如何高效为离线音乐库批量下载同步歌词:LRCGET工具全解析
如何高效为离线音乐库批量下载同步歌词:LRCGET工具全解析 【免费下载链接】lrcget Utility for mass-downloading LRC synced lyrics for your offline music library. 项目地址: https://gitcode.com/gh_mirrors/lr/lrcget 你是否拥有大量本地音乐文件却苦于…...

5分钟快速上手:FigmaCN免费中文界面插件终极指南
5分钟快速上手:FigmaCN免费中文界面插件终极指南 【免费下载链接】figmaCN 中文 Figma 插件,设计师人工翻译校验 项目地址: https://gitcode.com/gh_mirrors/fi/figmaCN 还在为Figma的英文界面而烦恼吗?想要专注于设计创意却被语言障碍…...

SpringBoot+Vue的牙科诊所预约平台毕业设计源码
博主介绍:✌ 专注于Java,python,✌关注✌私信我✌具体的问题,我会尽力帮助你。一、研究目的本研究旨在构建一个基于Spring Boot与Vue框架的牙科诊所预约平台以解决传统医疗预约模式中存在的信息不对称问题和资源分配效率低下问题。随着数字化医疗技术的快…...

终极矢量图标库完全指南:Remix Icon 3200+免费图标深度解析
终极矢量图标库完全指南:Remix Icon 3200免费图标深度解析 【免费下载链接】RemixIcon Open source neutral style icon system 项目地址: https://gitcode.com/gh_mirrors/re/RemixIcon Remix Icon 是一套开源的矢量图标库,包含超过3200个精心设…...

实战指南:VRM-Addon-for-Blender 终极VRM格式导入导出解决方案
实战指南:VRM-Addon-for-Blender 终极VRM格式导入导出解决方案 【免费下载链接】VRM-Addon-for-Blender VRM Importer, Exporter and Utilities for Blender 2.93 to 5.1 项目地址: https://gitcode.com/gh_mirrors/vr/VRM-Addon-for-Blender VRM(…...

5个高效方法:如何用AKShare处理金融数据去重,避免重复数据干扰分析
5个高效方法:如何用AKShare处理金融数据去重,避免重复数据干扰分析 【免费下载链接】akshare AKShare is an elegant and simple financial data interface library for Python, built for human beings! 开源财经数据接口库 项目地址: https://gitcod…...

3个步骤搭建Sunshine游戏串流服务器:从零到一的完整指南
3个步骤搭建Sunshine游戏串流服务器:从零到一的完整指南 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 你是否曾经梦想过在客厅的电视上玩书房电脑里的3A大作…...

STM32H7网络通信避坑指南:CubeMX配置LWIP 2.1.2时,这几个DCache和ETH的坑你别踩
STM32H7网络通信深度优化:LWIP 2.1.2配置与Cache一致性实战解析 当你在CubeMX中勾选了ETH和LWIP组件,生成代码后却发现设备无法稳定响应ping请求,或者传输大文件时出现数据错乱——这很可能与STM32H7独特的Cache架构有关。本文将带你深入理解…...

图解UART串口通信:从电平标准到数据帧的完整解析
1. UART串口通信基础:从物理层到协议层 第一次接触嵌入式开发时,我被UART这个名字唬住了——Universal Asynchronous Receiver/Transmitter(通用异步收发器),听起来像是某种高端设备。直到用USB转TTL模块点亮了第一个L…...

任务历史面板:浏览 Claude Code 的完整任务对话、复制提示词、一键切换继续工作
在技术领域,我们常常被那些闪耀的、可见的成果所吸引。今天,这个焦点无疑是大语言模型技术。它们的流畅对话、惊人的创造力,让我们得以一窥未来的轮廓。然而,作为在企业一线构建、部署和维护复杂系统的实践者,我们深知…...