实战:大数据Spark简介与docker-compose搭建独立集群
文章目录
- 前言
- 技术积累
- Spark简介
- Spark核心功能及优势
- Spark运行架构
- Spark独立集群搭建
- 安装docker和docker-compose
- docker-compose编排
- docker-compose编排并运行容器
- Spark集群官方案例测试
- 写在最后
前言
很多同学都使用过经典的大数据分布式计算框架hadoop,其分布式文件系统HDFS对数据管理很友好,但是计算能力较Spark还是不足。俗话说工欲善其事必先利其器,今天就介绍docker容器化部署Spark集群。
技术积累
Spark简介
Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。对于分布式计算方面Spark基于内存进行分布式计算,大大提升性能。

Spark核心功能及优势
更快的速度
内存计算下,Spark 比 Hadoop 快100倍。
易用性
Spark 提供了80多个高级运算符。
通用性
Spark 提供了大量的库,包括Spark Core、Spark SQL、Spark Streaming、MLlib、GraphX。 开发者可以在同一个应用程序中无缝组合使用这些库。
支持多种资源管理器
Spark 支持 Hadoop YARN,Apache Mesos,及其自带的独立集群管理器
Spark运行架构
Spark框架的核心是一个计算引擎,整体来说,它采用了标准的master-slave的结构
图所示:展示了一个Spark执行时的基本架构,图中的Driver表示master,负责管理整个集群中的作业任务调度。图中的Executor则是slave,负责实际执行任务。
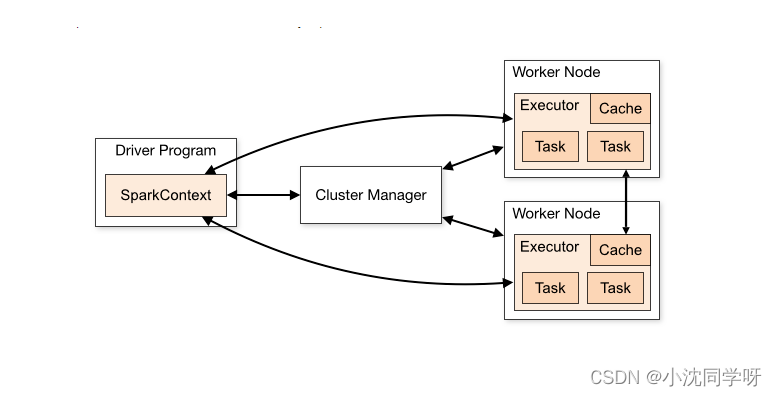
用户程序创建 SparkContext 后,它会连接到集群资源管理器,集群资源管理器会为用户程序分配计算资源,并启动 Executor;
Driver 将计算程序划分为不同的执行阶段和多个 Task,之后将 Task 发送给 Executor;
Executor 负责执行 Task,并将执行状态汇报给 Driver,同时也会将当前节点资源的使用情况汇报给集群资源管理器。
Spark独立集群搭建
安装docker和docker-compose
docker与docker-compose安装
#安装docker社区版
yum install docker-ce
#版本查看
docker version
#docker-compose插件安装
curl -L https://github.com/docker/compose/releases/download/1.21.2/docker-compose-`uname -s`-`uname -m` -o /usr/local/bin/docker-compose
#可执行权限
chmod +x /usr/local/bin/docker-compose
#版本查看
docker-compose version
docker-compose编排
docker-compose-spark.yaml
version: "3.3"
services:master:image: registry.cn-hangzhou.aliyuncs.com/senfel/spark:3.2.1container_name: masteruser: rootcommand: " /opt/bitnami/java/bin/java -cp /opt/bitnami/spark/conf/:/opt/bitnami/spark/jars/* -Xmx1g org.apache.spark.deploy.master.Master --host master --port 7077 --webui-port 8080 "environment:- SPARK_MODE=master- SPARK_RPC_AUTHENTICATION_ENABLED=no- SPARK_RPC_ENCRYPTION_ENABLED=no- SPARK_LOCAL_STORAGE_ENCRYPTION_ENABLED=no- SPARK_SSL_ENABLED=novolumes:- ./python:/pythonnetwork_mode: hostextra_hosts:- "master:10.10.22.91"- "localhost.localdomain:127.0.0.1"worker1:image: registry.cn-hangzhou.aliyuncs.com/senfel/spark:3.2.1container_name: worker1user: rootenvironment:- SPARK_MODE=worker- SPARK_MASTER_URL=spark://master:7077- SPARK_WORKER_MEMORY=1G- SPARK_WORKER_CORES=1- SPARK_RPC_AUTHENTICATION_ENABLED=no- SPARK_RPC_ENCRYPTION_ENABLED=no- SPARK_LOCAL_STORAGE_ENCRYPTION_ENABLED=no- SPARK_SSL_ENABLED=nonetwork_mode: hostextra_hosts:- "master:10.10.22.91"- "localhost.localdomain:127.0.0.1"worker2:image: registry.cn-hangzhou.aliyuncs.com/senfel/spark:3.2.1container_name: worker2user: rootenvironment:- SPARK_MODE=worker- SPARK_MASTER_URL=spark://master:7077- SPARK_WORKER_MEMORY=1G- SPARK_WORKER_CORES=1- SPARK_RPC_AUTHENTICATION_ENABLED=no- SPARK_RPC_ENCRYPTION_ENABLED=no- SPARK_LOCAL_STORAGE_ENCRYPTION_ENABLED=no- SPARK_SSL_ENABLED=nonetwork_mode: hostextra_hosts:- "master:10.10.22.91"- "localhost.localdomain:127.0.0.1"
docker-compose编排并运行容器
docker-compose -f docker-compose-spark.yaml up -d

浏览器访问
http://10.10.22.91:8080/

至此Spark独立集群搭建完成。
当然如果需要整合HDFS可以直接搭建一个Hadoop集群。这里不再累述,请参照之前的博文。
Spark集群官方案例测试
1、任意选择一个节点执行圆周率计算,这里选择master
#查看spark master容器信息
docker ps | grep master
#进入容器 默认就会进入/opt/bitnami/spark
docker exec -it master bash
#执行官方计算圆周率的案例
./bin/spark-submit --master spark://master:7077 --class org.apache.spark.examples.SparkPi ./examples/jars/spark-examples_2.12-3.2.1.jar 1000
参数:
–master 提交集群
–class 运行主类路径
1000 运行1000次
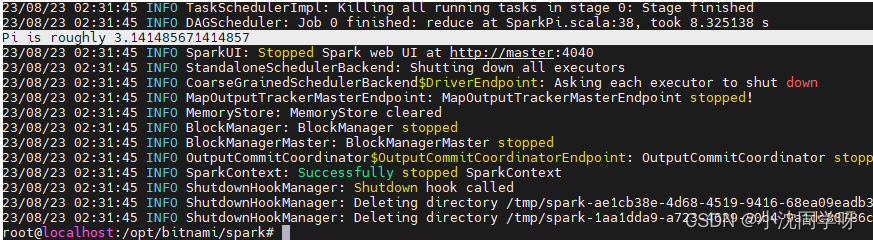
2、查看执行结果
Pi is roughly 3.141485671414857
计算次数越多这个圆周率精度越准确
写在最后
Spark是采用分布式数据集RDD对数据进行管理,用内存进行分布式计算,它的性能叫hadoop有显著的提升。对于Spark独立集群的搭建我们用docker容器也是比较的简单,当然,我们也可以集成在springboot开发出适应业务的功能安装需求进行远程提交任务。
相关文章:
实战:大数据Spark简介与docker-compose搭建独立集群
文章目录 前言技术积累Spark简介Spark核心功能及优势Spark运行架构 Spark独立集群搭建安装docker和docker-composedocker-compose编排docker-compose编排并运行容器 Spark集群官方案例测试写在最后 前言 很多同学都使用过经典的大数据分布式计算框架hadoop,其分布式…...

嵌入性视角下的企业集成创新网络演化过程
从嵌入性角度来看,集成创新网络以社会关系嵌入或结构嵌入的联结方式,实 现创新资源共享。由于规模经济和能力的差异,较高的信息复杂程度往往更强调网 络化和外部组织之间的联合而不是一体化。企业集成创新网络依靠创新网络结点上 企业的合…...

回归预测 | MATLAB实现FA-ELM萤火虫算法优化极限学习机多输入单输出回归预测(多指标,多图)
回归预测 | MATLAB实现FA-ELM萤火虫算法优化极限学习机多输入单输出回归预测(多指标,多图) 目录 回归预测 | MATLAB实现FA-ELM萤火虫算法优化极限学习机多输入单输出回归预测(多指标,多图)效果一览基本介绍…...
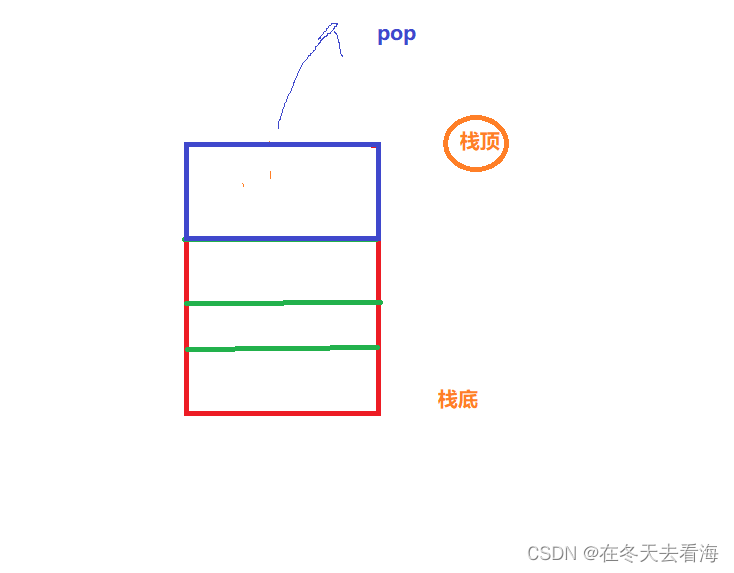
数据结构数组栈的实现
Hello,今天我们来实现一下数组栈,学完这个我们又更进一步了。 一、栈 栈的概念 栈是一种特殊的线性表,它只允许在固定的一端进行插入和删除元素的操作。 进行数据的插入和删除只在栈顶实现,另一端就是栈底。 栈的元素是后进先出。…...

成集云 | 抖店连接器客户静默下单催付数据同步钉钉 | 解决方案
源系统成集云目标系统 方案介绍 随着各品牌全渠道铺货,主播在平台上直播时客户下了订单后不能及时付款,第一时间客户收不到提醒,不仅造成了客户付款率下降,更大量消耗了企业的人力成本和经济。而成集云与钉钉深度合作࿰…...

【算法专题突破】双指针 - 复写零(2)
目录 1. 题目解析 2. 算法原理 3. 代码编写 写在最后: 1. 题目解析 题目链接:1089. 复写零 - 力扣(Leetcode) 我先来读题, 题目的意思非常的简单,其实就是, 遇到 0 就复制一个写进数组&a…...
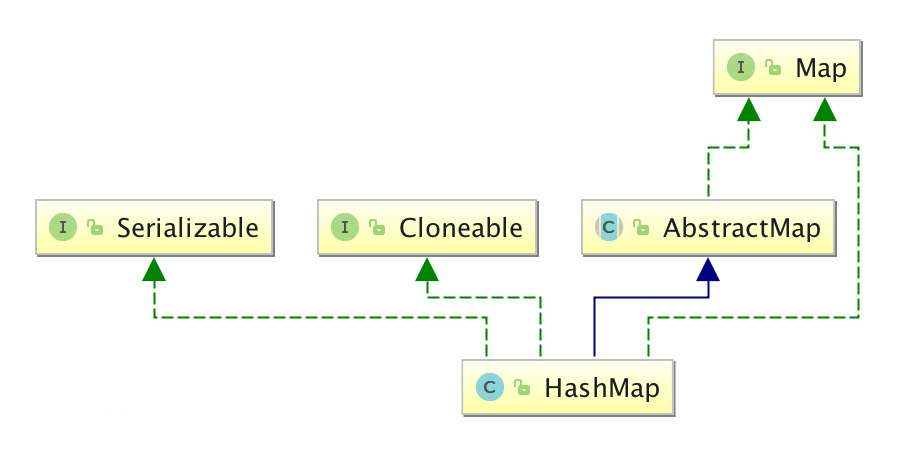
【Java从0到1学习】11 Java集合框架
1. Collection 1.1 Java类中集合的关系图 1.2 集合类概述 在程序中可以通过数组来保存多个对象,但在某些情况下开发人员无法预先确定需要保存对象的个数,此时数组将不再适用,因为数组的长度不可变。例如,要保存一个学校的学生信…...
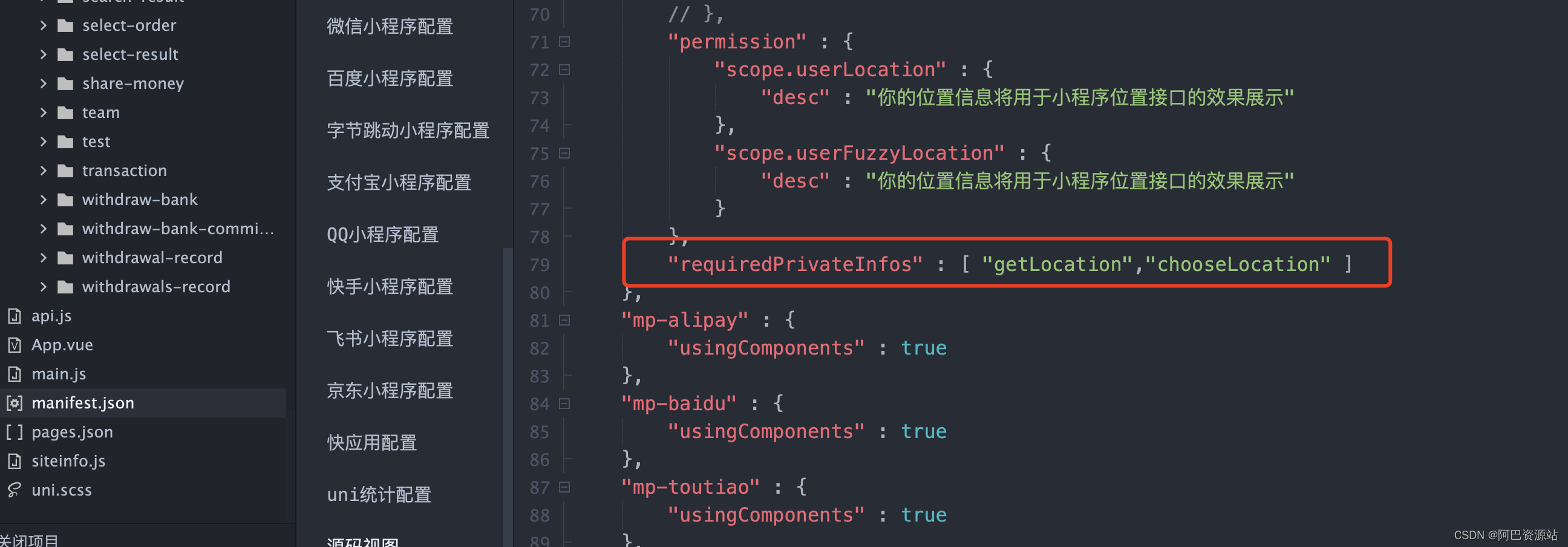
uniapp使用uni.chooseLocation()打开地图选择位置
使用uni.chooseLocation()打开地址选择位置: 在Uniapp源码视图进行设置 添加这个属性:"requiredPrivateInfos":["chooseLocation"] </template><view class"location_box"><view class"locatio…...

学习笔记|课后练习解答|电磁炉LED实战|逻辑运算|STC32G单片机视频开发教程(冲哥)|第八集(下):课后练习分析与解答
文章目录 课后练习解答需求分解增加KEY3控制代码如下: 第一版代码问题分析Tips:STC-ISP的设置 Tips:定时器实现完整电磁炉显示功能的代码测试流程 总结 课后练习解答 增加按键3,按下后表示启动,选择的对应的功能的LED…...
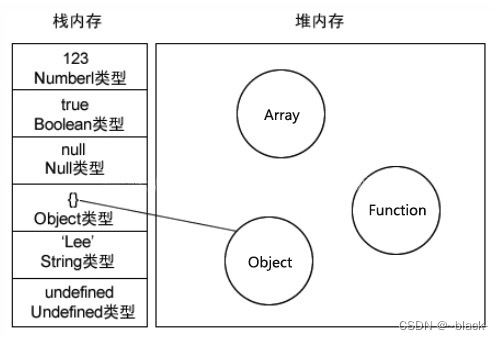
前端高频面试题 js中堆和栈的区别和浏览器的垃圾回收机制
一、 栈(stack)和 堆(heap) 栈(stack):是栈内存的简称,栈是自动分配相对固定大小的内存空间,并由系统自动释放,栈数据结构遵循FILO(first in last out)先进后出的原则,较为经典的就是乒乓球盒结…...

自然语言处理:大语言模型入门介绍
自然语言处理:大语言模型入门介绍 语言模型的历史演进大语言模型基础知识预训练Pre-traning微调Fine-Tuning指令微调Instruction Tuning对齐微调Alignment Tuning 提示Prompt上下文学习In-context Learning思维链Chain-of-thought提示开发(调用ChatGPT的…...

使用秘籍|如何实现图数据库 NebulaGraph 的高效建模、快速导入、性能优化
本文整理自 NebulaGraph PD 方扬在「NebulaGraph x KubeBlocks」meetup 上的演讲,主要包括以下内容: NebulaGraph 3.x 发展历程NebulaGraph 最佳实践 建模篇导入篇查询篇 NebulaGraph 3.x 的发展历程 NebulaGraph 自 2019 年 5 月开源发布第一个 alp…...
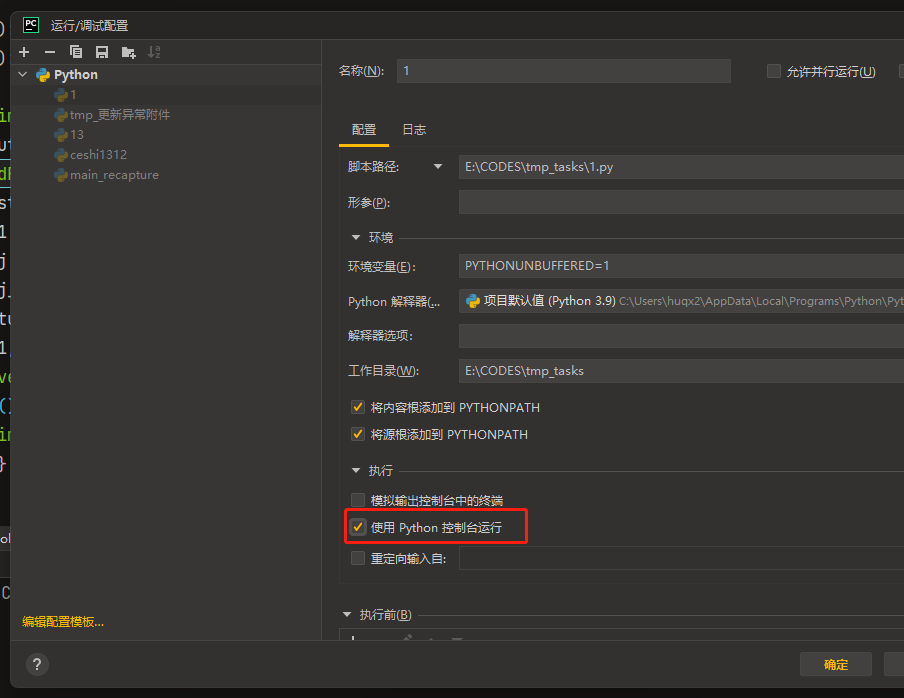
对于pycharm 运行的时候不在cmd中运行,而是在python控制台运行的情况,如何处理?
对于pycharm 运行的时候不在cmd中运行,而是在python控制台运行的情况,如何处理? 比如,你在运行你的代码的时候 它总在python控制台运行,十分难受 解决方法 在pycharm中设置下即可,很简单 选择运行点击…...

Spring MVC 二 :基于xml配置
创建一个基于xml配置的Spring MVC项目。 Idea创建新项目,pom文件引入依赖: <dependency><groupId>org.springframework</groupId><artifactId>spring-context</artifactId><version>5.2.12.RELEASE</version>…...

springboot aop方式实现接口入参校验
一、前言 在实际开发项目中,我们常常需要对接口入参进行校验,如果直接在业务代码中进行校验,则会显得代码非常冗余,也不够优雅,那么我们可以使用aop的方式校验,这样则会显得更优雅。 二、如何实现…...
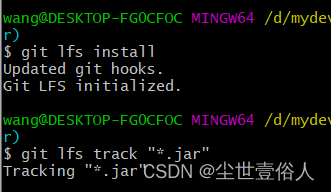
解决git上传远程仓库时的大文件提交
在git中超过100M的文件会上传失败,而当一个文件超过50M时会给你警告,如下 warning: File XXXXXX is 51.42 MB; this is larger than GitHubs recommended maximum file size of 50.00 MB 解决这种问题,首先在项目的.git文件夹中找到.gitigno…...
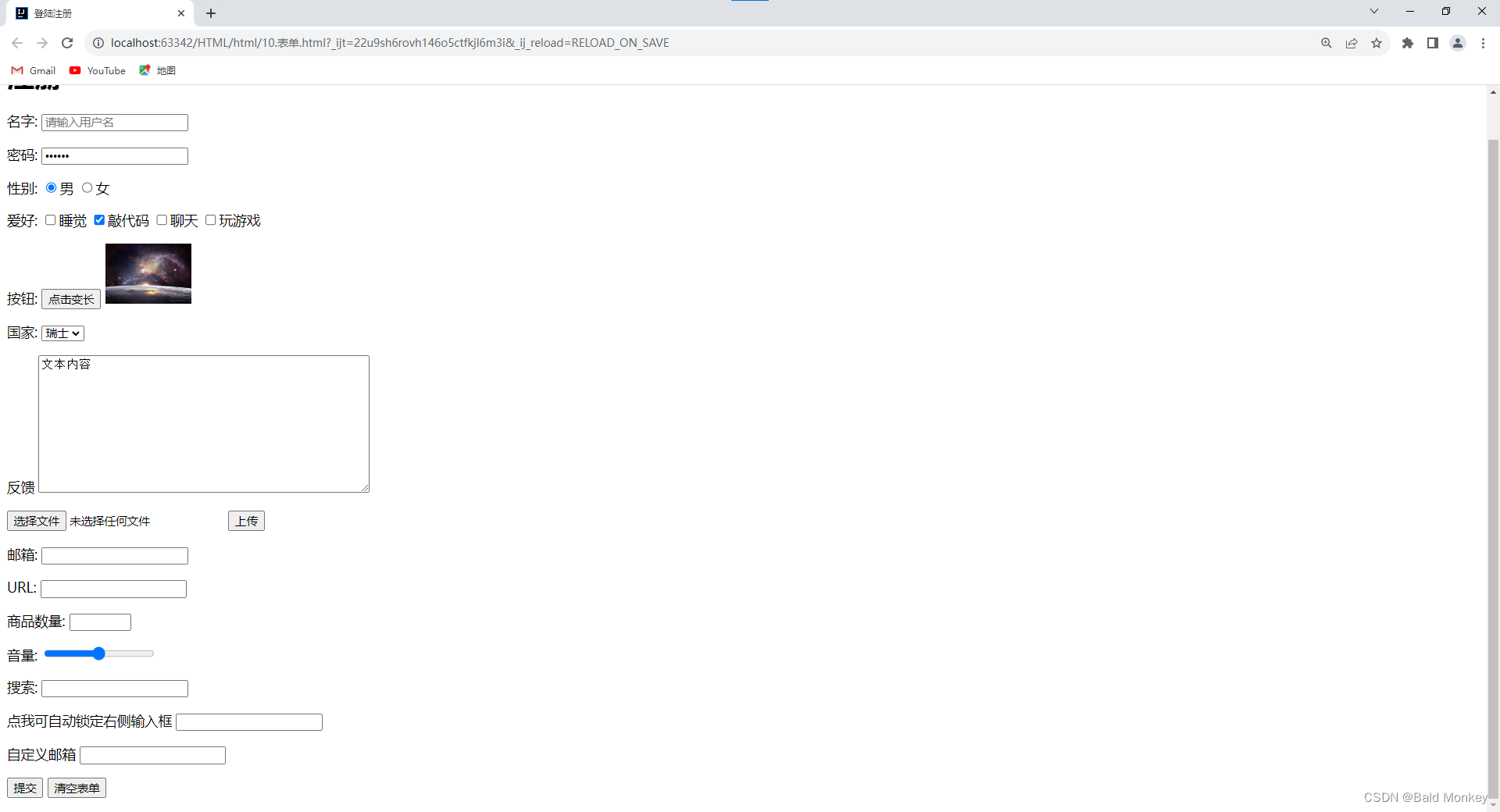
HTML学习笔记02
HTML笔记02 页面结构分析 元素名描述header标题头部区域的内容(用于页面或页面中的一块区域)footer标记脚部区域的内容(用于整个页面或页面的一块区域)sectionWeb页面中的一块独立区域article独立的文章内容aside相关内容或应用…...
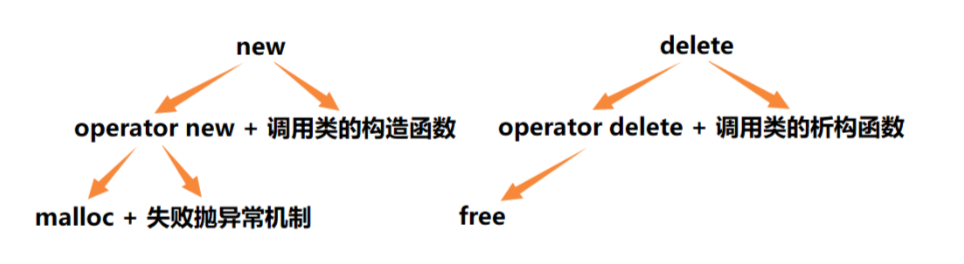
<C++> 内存管理
1.C/C内存分布 让我们先来看看下面这段代码 int globalVar 1; static int staticGlobalVar 1; void Test() {static int staticVar 1;int localVar 1;int num1[10] {1, 2, 3, 4};char char2[] "abcd";char *pChar3 "abcd";int *ptr1 (int *) mal…...

【Java】ByteBuffer类的arrayOffset方法详解+示例
arrayOffset功能详解;arrayOffset在position等于0和非0两种场景下的demo。使用类java.nio.ByteBuffer中的arrayOffset()方法可以获得这个缓冲区的第一个元素在底层支持(backing)数组中的偏移量。 如果这个buffer底层是由数组支持的,那么buffer的postion p对应于数组的index…...
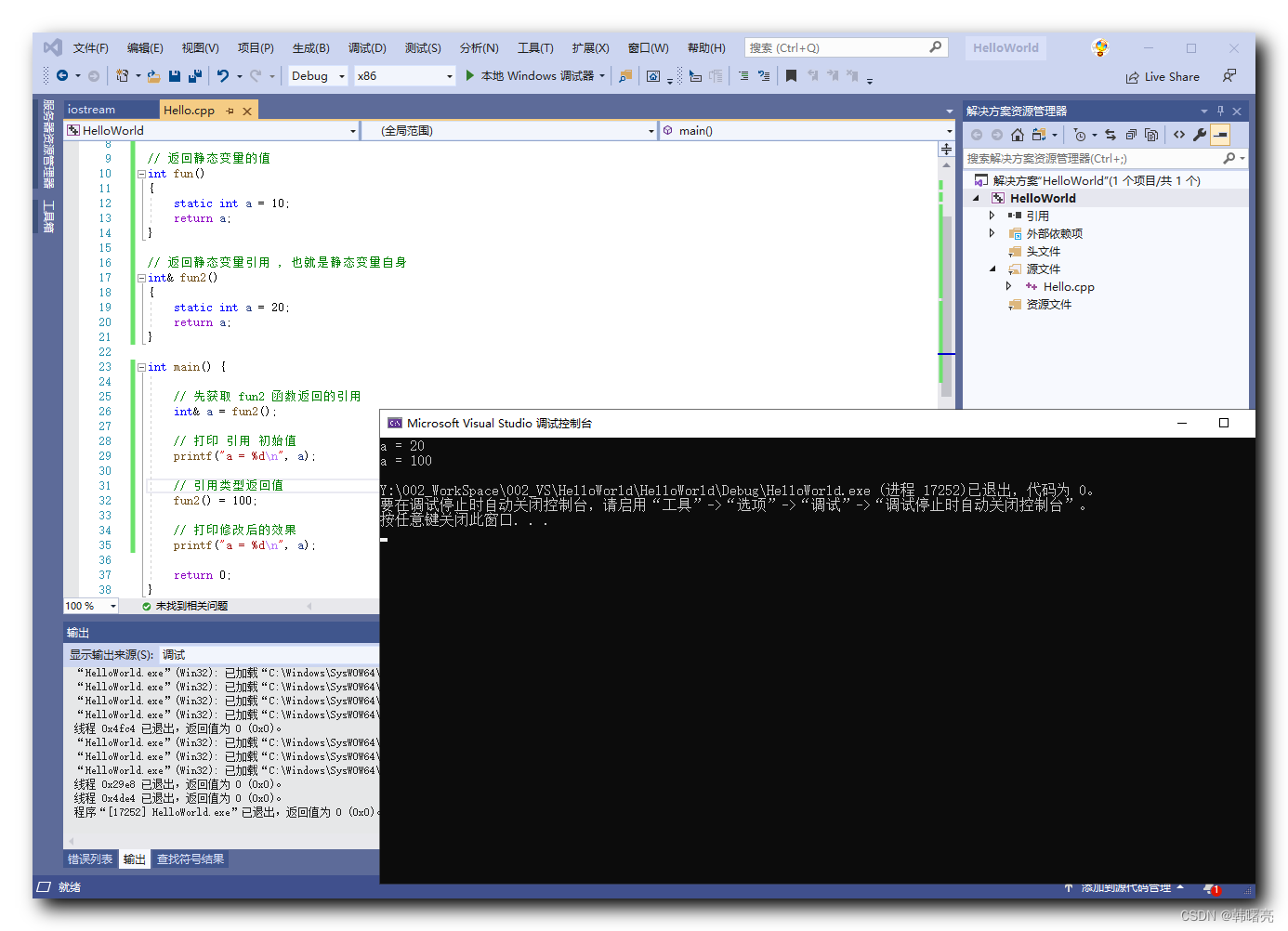
【C++】C++ 引用详解 ⑤ ( 函数 “ 引用类型返回值 “ 当左值被赋值 )
文章目录 一、函数返回值不能是 " 局部变量 " 的引用或指针1、函数返回值常用用法2、分析函数 " 普通返回值 " 做左值的情况3、分析函数 " 引用返回值 " 做左值的情况 函数返回值 能作为 左值 , 是很重要的概念 , 这是实现 " 链式编程 &quo…...

Java 程序员第 4 阶段:入门 Embedding 向量嵌入,弄懂大模型语义底层逻辑
前言Embedding(向量嵌入) 是大模型理解语义的核心技术,也是构建 RAG、知识库、语义搜索的基础。理解 Embedding 的原理,是进阶大模型开发的关键。本篇文章将深入讲解 Embedding 向量嵌入技术,从原理到 Java 实现&#…...

如何在Dev-C++中选择TDM-GCC编译器
在Dev-C中选择TDM-GCC编译器的步骤如下:打开编译器设置启动Dev-C,点击顶部菜单栏的 "工具" → "编译器选项"选择编译器在打开的窗口中:切换到 "编译器" 选项卡勾选 "在连接器命令行加入以下命令"在下…...

收藏!AI时代程序员转型指南:从纯编码到人机协同高手
本文揭示了AI对程序员行业的深刻变革:初级编码岗需求锐减,而AI协作、架构师等高端岗位需求激增。文章提出两个阶段提升竞争力:第一阶段掌握AI工具栈(编码助手、调试工具等)并遵循人机协同法则;第二阶段构建…...
)
别再傻傻传文件了!用Java Base64把图片和PDF直接“塞”进HTML页面(附完整代码)
告别文件传输:Java Base64技术实现图片与PDF的HTML直嵌方案 在Web开发中,我们经常遇到需要将图片或PDF文档直接嵌入HTML页面的场景。传统做法通常需要先将文件上传到服务器,然后通过URL引用,这不仅增加了网络请求,还引…...

Windows平台APK部署技术探索:轻量级安卓应用安装实践指南
Windows平台APK部署技术探索:轻量级安卓应用安装实践指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 在跨平台应用开发与部署日益普及的今天࿰…...

Kali+MSF 安全攻防实操|Windows 渗透完整流程教程
入侵电脑,并没有我们想象的那么难,今天我们的文章主要是给一些基础比较薄弱的小伙伴们准备的,如果你从来没有利用msf进入过对方计算机,就赶紧找个风和日丽的下午,跟着博主一起来试试吧~ 01 什么是msf 演示环境 02 …...
,仅限前500名技术决策者获取)
NotebookLM未公开的Obsidian插件桥接协议(内部文档泄露版),仅限前500名技术决策者获取
更多请点击: https://intelliparadigm.com 第一章:NotebookLM与Obsidian整合的架构全景图 NotebookLM(Google 推出的 AI 原生研究助手)与 Obsidian(本地优先、双向链接的知识图谱工具)的整合,正…...
:复制带随机指针的链表)
用100道题拿下你的算法面试(链表篇-7):复制带随机指针的链表
一、面试问题 给定一个链表的头节点,链表中每个节点都包含两个指针:一个指向下一个节点的 next 指针,以及一个指向链表中任意节点的 random 指针。请复制该链表,并返回新链表的头节点。 二、【朴素解法】使用哈希表 —— 时间复杂…...
)
Python爬虫实战:用urllib和正则搞定E-Hentai图片批量下载(附完整代码与避坑指南)
Python高效爬虫实战:多线程下载与智能错误处理 引言 在当今数据驱动的时代,网络爬虫已成为获取互联网信息的重要工具。对于开发者而言,掌握高效的爬虫技术不仅能提升工作效率,还能解决许多实际业务场景中的数据采集需求。本文将深…...

iOS设备支持文件管理解决方案:如何解决Xcode开发环境兼容性问题
iOS设备支持文件管理解决方案:如何解决Xcode开发环境兼容性问题 【免费下载链接】iOSDeviceSupport All versions of iOS Device Support 项目地址: https://gitcode.com/gh_mirrors/ios/iOSDeviceSupport iOSDeviceSupport项目为iOS开发者提供了全面的设备支…...