Python爬虫快速入门指南
引言:
网络爬虫是一种自动化程序,可以在互联网上搜集和提取数据。Python作为一种功能强大且易学的编程语言,成为了许多爬虫开发者的首选。本文将为你提供一个关于Python爬虫的快速入门指南,包括基本概念、工具和实际案例。
第一部分:准备工作
在我们开始之前,有几个必要的准备工作需要完成。首先,确保你的计算机已经安装了最新版的Python。Python是一种功能强大且易学的编程语言,为你的爬虫之旅提供了强大的支持。你可以从Python官方网站下载并安装最新版本。
此外,你还需要安装一些必要的Python库,用于发送HTTP请求、解析HTML等任务。这些库将会在你的爬虫项目中发挥重要的作用。以下是几个常用的库:
-
requests库:用于发送HTTP请求,获取网页内容。这是一个简单易用的库,可以帮助你轻松地与网页进行交互。
-
BeautifulSoup库:用于解析HTML,从网页中提取所需的数据。这个库能够帮助你快速而准确地找到你需要的信息。
-
Scrapy库:如果你计划构建一个大规模的爬虫项目,Scrapy将会是你的首选。它是一个高级的爬虫框架,提供了许多强大的功能和工具。
你可以使用pip命令来安装这些库。打开命令行终端,输入以下命令即可:
pip install requests
pip install BeautifulSoup
pip install scrapy
当然,这只是其中一些常用的库。根据你的需求和项目要求,你可能还需要安装其他的库。可以通过搜索引擎来查找并学习更多关于Python爬虫所需的库。
完成了以上准备工作之后,你的计算机已经准备就绪。接下来,你可以开始编写你的第一个爬虫项目了。不要害怕,相信自己的能力,尽情探索吧!
记住,爬虫开发是一个不断学习和提高的过程。通过实践和不断的尝试,你将能够熟练掌握爬虫技术,并在实际项目中取得成功。祝愿你能在爬虫的世界中畅游,收获丰富的数据和无穷的知识!加油!
第二部分:基础知识
在你迈进爬虫的世界之前,你需要确保自己对Python的基础知识有一定的了解。下面是一些你应该掌握的基本概念,让我们一起来学习吧!
-
变量:Python中,你可以使用变量来存储和操作数据。通过使用等号(=),你可以给变量赋值。例如,你可以创建一个名为“name”的变量,并将你的名字赋值给它。变量的使用将在爬虫项目中发挥关键作用。
-
数据类型:Python支持多种数据类型,包括整数、浮点数、字符串、列表、元组、字典等。每种数据类型都有其特点和用途。例如,字符串可以表示文本,列表可以存储多个值。了解每种数据类型的特点和使用方法,有助于你在爬虫项目中处理和操作数据。
-
条件语句:通过使用条件语句,你可以根据不同的条件执行不同的代码块。条件语句包括if、else和elif。例如,如果某个条件满足,你可以执行特定的操作,否则执行另外的操作。条件语句在爬虫中经常用于判断页面状态,根据不同的情况执行相应的操作。
-
循环:Python提供了两种循环方式,for循环和while循环。通过循环语句,你可以重复执行一段代码。for循环适用于已知重复次数的情况,而while循环适用于未知重复次数的情况。循环在爬虫中常用于遍历列表或执行一系列操作。
掌握这些基础知识,将为你的爬虫之旅打下坚实的基础。当你熟练掌握这些概念后,你将能够更加灵活地编写代码,处理复杂的爬虫任务。
记住,学习是一个持久的过程。在你的爬虫学习路上,不断练习、积累经验,你将能够成为一名优秀的爬虫工程师。相信自己的能力,坚持不懈,让我们一起在代码的海洋中畅游吧!加油!
第三部分:入门案例
下面是一个简单的爬虫案例,用于从一个网页中提取标题和链接。我们将使用requests库发送HTTP请求,并使用BeautifulSoup解析HTML。
首先,导入所需的库:
import requests
from bs4 import BeautifulSoup
然后,发送HTTP请求并获取网页内容:
url = “https://example.com”
response = requests.get(url)
html = response.text
接下来,使用BeautifulSoup解析HTML并提取标题和链接:
soup = BeautifulSoup(html, “html.parser”)
titles = soup.find_all(“h1”)
links = soup.find_all(“a”)
最后,打印出提取到的标题和链接:
for title in titles:
print(title.text)
for link in links:
print(link[“href”])
这只是一个简单的入门案例,你可以根据自己的需求和兴趣进行更复杂的爬虫操作。你可以使用不同的选择器、添加更多的功能和处理更多的数据。
第四部分:数据处理和存储
在进行爬虫过程中,可能会遇到需要对爬取到的数据进行处理和清洗的情况。比如,去除多余的标签、提取文本内容、去除空格和换行符等操作。要实现这些操作,你可以利用Python的字符串操作函数和正则表达式。
Python提供了丰富的字符串操作函数,可帮助你对爬取到的数据进行各种处理。你可以使用函数如replace()、strip()、split()等来去除多余的标签、去除空格和换行符,或对数据进行分割和拼接。通过灵活运用这些函数,你可以轻松地清洗和整理你的数据。
此外,正则表达式也是处理数据的强大工具。正则表达式是一种用于匹配、搜索和替换文本的模式。你可以根据特定的模式,使用re模块提供的函数来对爬取到的数据进行处理。利用正则表达式,你可以提取出你感兴趣的内容,或者根据特定规则进行替换和修改。
除了数据处理,你还需要考虑如何存储爬取到的数据。你可以选择将数据保存到本地文件或数据库中。Python提供了相应的文件操作函数和数据库库来实现数据的存储。
如果你选择将数据保存到本地文件,你可以使用Python的文件操作函数,如open()、write()等来创建和写入文件。你可以选择将数据保存为文本文件、CSV文件、JSON文件等,具体根据你的需求和数据类型来决定。
如果你选择将数据保存到数据库中,你可以使用Python提供的相应数据库库,如MySQLdb、pymysql、sqlite3等。你可以通过连接数据库、创建表和插入数据来实现数据的存储。例如,你可以使用SQLite库来创建一个本地数据库,并将爬取到的数据保存到其中。
通过合理地处理和存储数据,你能够更好地利用你爬取到的信息,为后续的分析和应用做好准备。不断学习和实践数据处理和存储的技巧,你将成为一名熟练的数据工程师,为信息的利用和价值开发贡献自己的一份力量。
第五部分:进阶学习和实践
一旦你掌握了Python爬虫的基础知识,那么你可以进一步学习更高级的技术和工具,以构建更强大和高效的爬虫。
一个值得学习的工具是Scrapy框架。Scrapy是一个强大的Python开源爬虫框架,它提供了一套完整的爬虫解决方案,能够帮助你更加高效地构建和管理爬虫。使用Scrapy,你可以通过定义爬虫规则和数据处理规则,从网页中提取所需的数据,并自动化执行爬取任务。Scrapy还提供了分布式爬取、防止重复爬取、自动处理页面失败等功能,让你的爬虫更加稳定和可靠。
另外一个需要学习的技术是如何处理JavaScript生成的内容。有些网页使用JavaScript动态生成内容,这些内容无法通过简单的HTTP请求获取到。为了爬取这些动态生成的内容,你可以使用Selenium库。Selenium是一个自动化测试工具,可以模拟浏览器行为,执行JavaScript代码,并获取到完整的渲染后的页面。通过使用Selenium,你可以解决爬取动态网页的难题,获取到完整的数据。
此外,还有一些网站需要进行登录和验证才能访问和爬取。如果你需要处理这类网站,你可以学习如何处理登录和验证问题。一种常见的解决方案是使用模拟登录技术,即模拟用户登录网站并获取到登录后的cookie或session信息。通过获取到合法的登录信息,你可以成功地访问和爬取需要登录的网页。你可以使用Requests库来发送模拟登录请求,获取登录后的cookie或session信息,然后使用这些信息进行后续的爬取。
除了使用Selenium库来处理JavaScript生成的内容,你还可以使用Pyppeteer库。Pyppeteer是一个基于Chromium的无头浏览器控制库,可以通过Python来控制无头浏览器进行网页爬取。Pyppeteer提供了一套简洁而强大的API,让你可以方便地模拟浏览器行为,获取到完整的渲染后的页面。使用Pyppeteer,你可以解决更复杂的爬取问题,如处理动态网页、提交表单等。
学习和实践这些进阶技术和工具,将帮助你构建更强大、更灵活的爬虫,解决更复杂的爬取问题。通过不断学习和实践,你将成为一名娴熟的爬虫工程师,为数据的采集和分析提供更多可能性。
结论:
通过本文的学习,你已经了解了Python爬虫的基础知识和入门步骤。你可以根据自己的需求和兴趣,深入学习和掌握相关的爬虫技术,并将其应用到实际项目中。
记住,实践是学习的最好方式。尝试编写更复杂的爬虫代码,探索不同的网站和数据源。随着不断的练习和实践,你将成为一名熟练的Python爬虫开发者。祝你成功!
相关文章:

Python爬虫快速入门指南
引言: 网络爬虫是一种自动化程序,可以在互联网上搜集和提取数据。Python作为一种功能强大且易学的编程语言,成为了许多爬虫开发者的首选。本文将为你提供一个关于Python爬虫的快速入门指南,包括基本概念、工具和实际案例。 第一…...

Java人脸识别技术探索与实践
人脸识别技术作为生物特征识别领域的一项重要应用,近年来在安全、便捷以及科研等方面取得了显著的进展。在Java编程领域,人脸识别也得到了广泛的关注和应用。本文将介绍Java中人脸识别技术的基本概念、常用库以及实际示例代码,带您深入了解这…...

【鞋服零售ERP】之要货申请单设计思路
引言 要货申请单在本系统中也是一张较为核心的单据,整体的思路是将其池化,解决收发货方业务简化,账务处理逻辑化的设计理念。首先鞋服零售ERP就是基于多组织的业务架构,多销售组织和店铺属性;其次是在零售如何在业处处…...
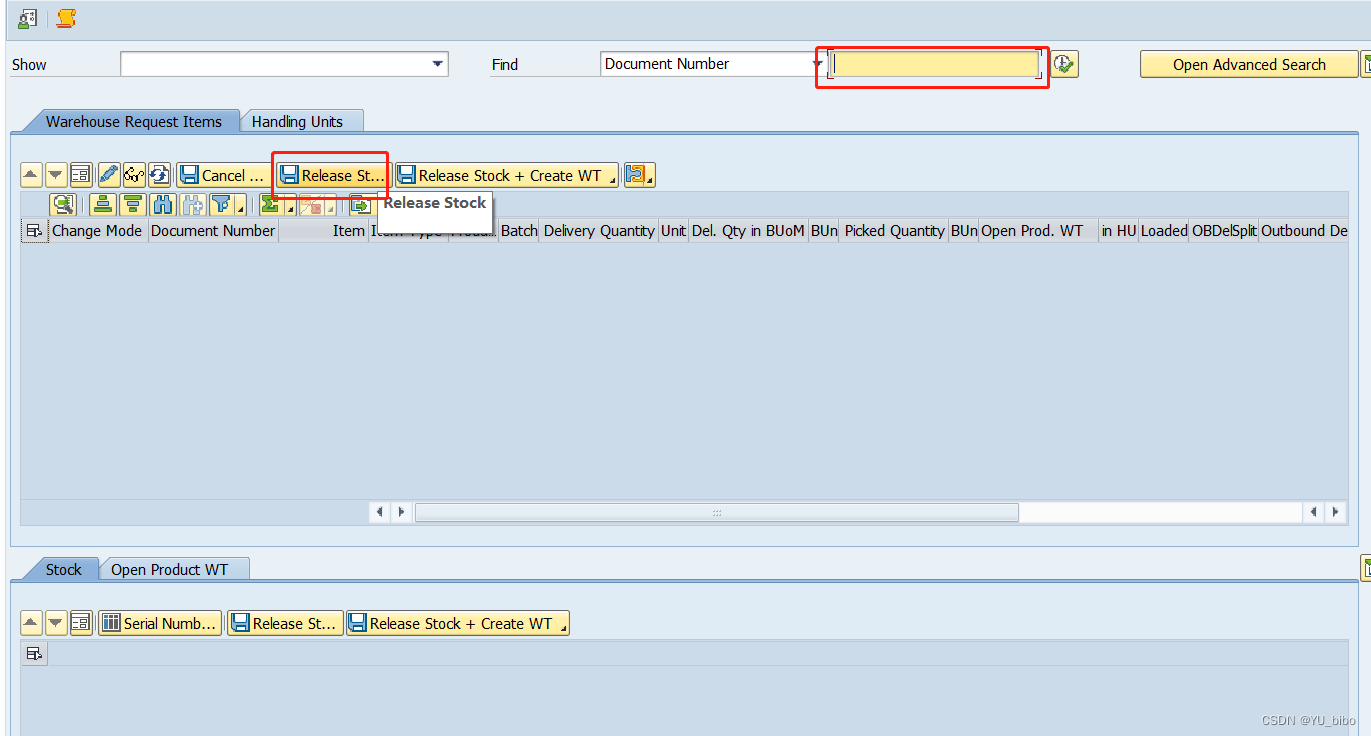
EWM怎么取消pinking,SAP_EWM取消拣配报错处理方式
EWM是SAP的一个模块,代表扩展仓库管理(Extended Warehouse Management),是SAP企业资源计划(ERP)的一部分。它提供了一个完整的、高级的仓库管理解决方案,支持企业在全球范围内的仓库管理、订单管…...

TensorFlow 的基本概念和使用场景
TensorFlow 是 Google 开源的机器学习框架,它支持使用数据流图(Data Flow Graph)的方式进行计算,以实现大规模分布式机器学习应用。TensorFlow 在深度学习、自然语言处理、计算机视觉等领域有广泛应用。 TensorFlow 中的重要概念…...
、解密(decrypt)、签名(sign)、验证(verify))
openssl 加密(encrypt)、解密(decrypt)、签名(sign)、验证(verify)
一、使用openssl rsautl 进行加密、解密、签名、验证 [kyzjjyyzc-zjjcs04 openssl]$ openssl rsautl --help Usage: rsautl [options] -in file input file -out file output file -inkey file input key -keyform arg private key format - default PEM …...

视频云存储/安防监控视频AI智能分析网关V3:抽烟/打电话功能详解
人工智能技术已经越来越多地融入到视频监控领域中,近期我们也发布了基于AI智能视频云存储/安防监控视频AI智能分析平台的众多新功能,该平台内置多种AI算法,可对实时视频中的人脸、人体、物体等进行检测、跟踪与抓拍,支持口罩佩戴检…...

新版Jadx 加载dex报错 jadx.plugins.input.dex.DexException:Bad checksum 解决方法
本文所有教程及源码、软件仅为技术研究。不涉及计算机信息系统功能的删除、修改、增加、干扰,更不会影响计算机信息系统的正常运行。不得将代码用于非法用途,如侵立删!新版Jadx(1.6+) 加载dex报错 jadx.plugins.input.dex.DexException:Bad checksum 解决方法 环境 win10J…...
win11+vmware17+centos7.9环境搭建
温故知新 📚第一章 前言📗背景📗目标📗总体方向 📚第二章 安装部署环境📗安装VMware Workstation 17 Pro软件📗安装CentOS-7虚拟机📕镜像下载地址📕创建虚拟机Ǵ…...

Unity Meta Quest MR 开发教程:(二)自定义透视 Passthrough【透视功能进阶】
文章目录 📕教程说明📕动态开启和关闭透视⭐方法一:OVRManager.instance.isInsightPassthroughEnabled⭐方法二:OVRPassthroughLayer 脚本中的 hidden 变量 📕透视风格 Passthrough Styling⭐Inspector 面板控制⭐代码…...
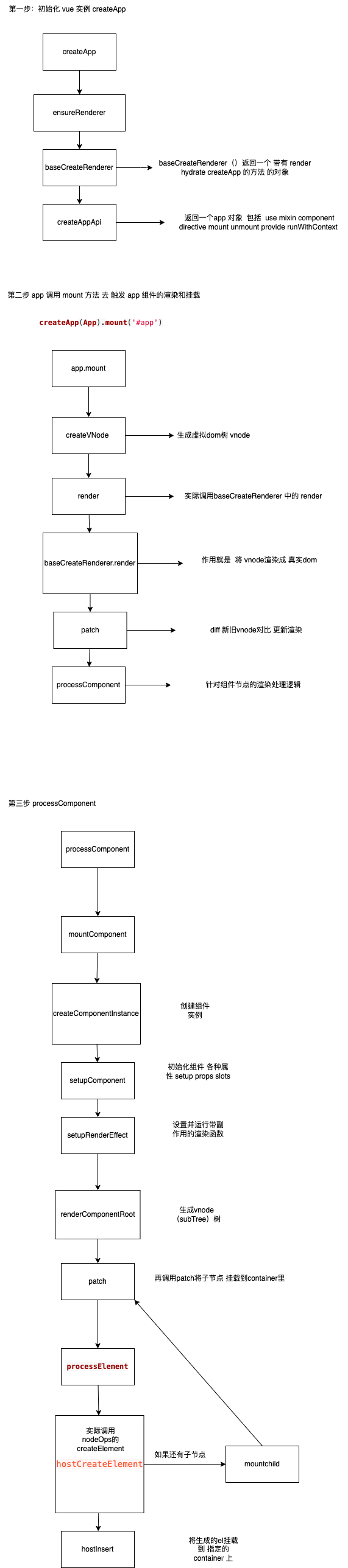
vue3学习源码笔记(小白入门系列)------ 组件是如何渲染成dom挂载到指定位置的?
文章目录 os准备组件如何被挂载到页面上第一步 createApp 做了哪些工作?ensureRendererbaseCreateRenderercreateAppAPImountrenderpatchprocessComponentprocessElement 总结 os 学习一下vue3 源码,顺便记录分享下 使用vitest 插件调试源码 辅助阅读 …...

【编码规范】从代码之丑聊代码规范
最近看了代码之丑,就打算整理下,总结一下。 代码命名 首先从命名来说的话,其实对于大多数程序员来说,可能基本都是翻译软件翻译下,然后就直接改成对应的类名、参数名、函数名等。其实仔细一想,命名其实是…...

pytorch中的register_buffer
今天在一个模型的init中遇到了self.register_buffer(‘running_mean’, torch.zeros(num_features)) register_buffer(self, name, tensor)是一个PyTorch中的方法,它的作用是向模块(module)中添加一个持久的缓冲区(buffer…...

【Java笔记】分布式id生成-雪花算法
随着业务的增长,有些表可能要占用很大的物理存储空间,为了解决该问题,后期使用数据库分片技术。将一个数据库进行拆分,通过数据库中间件连接。如果数据库中该表选用ID自增策略,则可能产生重复的ID,此时应该…...
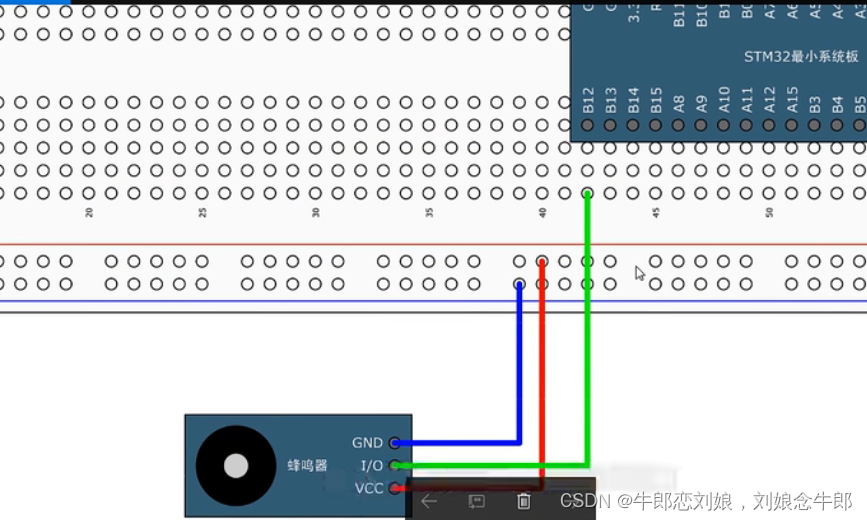
STM32f103入门(2)流水灯蜂鸣器
流水灯 /* #define GPIO_Pin_0 ((uint16_t)0x0001) /*!< Pin 0 selected */ #define GPIO_Pin_1 ((uint16_t)0x0002) /*!< Pin 1 selected */ #define GPIO_Pin_2 ((uint16_t)0x0004) /*!< Pin 2 selected */ #de…...

Web Worker的使用
Web Worker 前言一、Web Worker是什么?二、使用步骤2.1 创建 Web Worker2.2 监听消息2.3 发送消息 三、优点与缺点3.1 优点3.2 缺点 四、Vue中使用Web Worker 前言 JavaScript采用的是单线程模型,也就是说,所有任务只能在一个线程上完成&…...
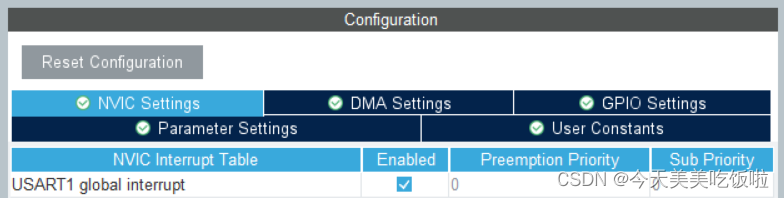
STM32 Cubemx配置串口收发
文章目录 前言注意事项Cubemx配置printf重定向修改工程属性修改源码 测试函数 前言 最近学到了串口收发,简单记录一下注意事项。 注意事项 Cubemx配置 以使用USART1为例。 USART1需配置成异步工作模式Asynchronous。 并且需要使能NVIC。 printf重定向 我偏向…...

ndoe+mysql+express基础应用
介绍 1.express 为不同 URL 路径中使用不同 HTTP 动词的请求(路由)编写处理程序。集成了“视图”渲染引擎,以便通过将数据插入模板来生成响应。设置常见 web 应用设置,比如用于连接的端口,以及渲染响应模板的位置。在…...

后端项目开发:集成日志
SpringBoot 默认选择的是slf4j做日志门面,logback做日志实现。由于log4j有性能问题,不建议使用。 由于log4j2的表现性能更好,我们需要集成log4j2,同时排除旧的日志实现包。 <!-- Spring Boot 启动器 --> <dependency>…...

20-GIT版本控制
GIT 一 简介 场景 团队协作的时候,我们项目开发会遇到代码需要进行管理的场景。 多个开发者之间,每天写的代码可能需要合并,共享。 例子:我写的用户模块、小王写的订单模块,用户模块最终需要跟订单模块合并。 每天写完代码,qq、u盘拷贝,代码合并一个项目中。 希望…...

网站国产化改造怎么做?深度解读国产化替代路径与CMS推荐
在近年来科技领域的舆论场中,“国产化”无疑是出现频率最高的关键词之一。从芯片到操作系统,从数据库到办公软件,再到企业对外展示的门户——网站,国产化替代已从“可选项”变成了很多行业的“必答题”。但国产化仅仅是“换个牌子…...

Super IO插件:Blender文件操作效率革命,从繁琐拖拽到智能粘贴
Super IO插件:Blender文件操作效率革命,从繁琐拖拽到智能粘贴 【免费下载链接】super_io blender addon for copy paste import / export 项目地址: https://gitcode.com/gh_mirrors/su/super_io Super IO是一款革命性的Blender插件,通…...

复杂技术决策如何避免“竞选广告”陷阱?工程师必备的4项流程变革
1. 从一场“选举广告”引发的思考:工程师如何审视复杂系统设计午餐时看新闻,每个广告时段都被政治竞选广告塞满,内容无一例外都在攻击对手,却对自身主张闭口不谈。这场景让我这个在电子设计自动化(EDA)和半…...

初创公司如何利用Taotoken快速构建AI产品原型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初创公司如何利用Taotoken快速构建AI产品原型 对于资源有限的初创团队而言,验证产品想法、快速推出原型是生存和发展的…...
)
SeetaFace6实战:5分钟搞定实时视频流人脸检测(支持戴口罩识别,附完整C++/OpenCV代码)
SeetaFace6实战:5分钟构建高精度实时视频人脸检测系统(含口罩识别) 在智能安防、无接触门禁和远程医疗等场景中,实时人脸检测技术正发挥着越来越重要的作用。SeetaFace6作为中科视拓开源的最新版本人脸识别引擎,不仅将…...

日本电子产业转型启示:从技术过剩到商业模式创新
1. 日本电子产业的十字路口:一场箱根闭门会背后的行业剧痛2013年的春天,当全球电子产业的聚光灯都打在硅谷和深圳时,日本箱根的一家温泉旅馆里,正进行着一场鲜为人知却意义深远的对话。索尼、瑞萨、NEC、日立、松下、富士通、Mega…...
)
从五管OTA到两级运放:在Cadence IC617中如何规划你的设计指标与晶体管尺寸(gm/id方法详解)
从五管OTA到两级运放:gm/id设计方法在Cadence IC617中的策略性应用 在模拟集成电路设计中,运算放大器的设计始终是工程师面临的核心挑战之一。特别是当设计需求从简单的五管OTA扩展到更复杂的两级运放时,设计者需要处理的不仅仅是晶体管尺寸的…...

5个让你在Windows电脑上畅玩安卓应用的神奇场景
5个让你在Windows电脑上畅玩安卓应用的神奇场景 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾想过,在Windows电脑的大屏幕上玩手机游戏ÿ…...

收藏!小白程序员必看:从AI提效到重构产品,企业智能转型4阶段实战指南
本文深入探讨了企业如何拥抱智能时代,通过4个阶段实现AI落地。从提升内部效率开始,逐步激活沉睡数据,重构产品价值,最终形成深场景智能闭环。强调AI不应仅用于替代人工,更要关注为客户创造新价值、提升产品智能化&…...
:Kubernetes部署图像去噪服务,实现容器编排和弹性扩展)
Pytorch图像去噪实战(七十四):Kubernetes部署图像去噪服务,实现容器编排和弹性扩展
Pytorch图像去噪实战(七十四):Kubernetes部署图像去噪服务,实现容器编排和弹性扩展 一、问题场景:Docker Compose够用,但多服务扩展开始吃力 前面我们用 Docker Compose 部署了图像去噪服务。 Compose 对单机部署非常好用,但当项目变复杂后,会遇到: 多台机器部署困难…...