关于hive sql进行调优的理解
这是一个面试经常面的问题,很不幸,在没有准备的时候,我面到了这个题目,反思了下,将这部分的内容进行总结,给大家一点分享。
hive其实是基于hadoop的数据库管理工具,底层是基于MapReduce实现的,用户写的hivesql最终转换成MapReduce的任务运行在hadoop上,不过MapReduce会因为磁盘IO的问题会运行较慢,因此在Hive sql进行优化,就需要考虑到MapReduce的生命周期,在各个时间节点上进行调优,从而实现Hive sql的整体优化。
如果要从MapReduce角度来分析,就需要从Map,Reduce,join,参数设置的角度来分析。
Map阶段
- 尽早使用where条件:提前把不需要计算的数据过滤掉,而不是在进行复杂操作后再集中过滤。
- 使用分区裁剪:Hive不同分区是按照不同目录存放的,指定分区可以访问特定的目录,减少数据量。
- 使用列裁剪:尽量不要使用select * from ...,指定特定列会只扫描特定列而不扫描全表,提高执行速度,同时select * 会让优化器无法完成索引覆盖扫描这类优化,会影响优化器对执行计划的选择,也会增加网络带宽消耗,更会带来额外的 I/O,内存和 CPU 消耗。
- 相似任务尽量使用多路输出:相同的计算只需要计算一次,减少重复计算,同时也能减少reduce task
- 减少case when中的when:表中的文件都需要走一遍when流程,when越多效率就越低,而且在reduce阶段最好做一遍合并压缩操作,否则可能会产生很多文件。
reduce 阶段
- 使用 group by 代替 distinct:因为distinct会把所有任务都分配到一个reduce task中。
- 使用 sort by + distribute by代替 order by:order by 和 distinct 类似,在reduce阶段都会把所有的任务集中到一个reduce task中计算,使用 sort by 和 distribute by 后MR会根据情况启动多个reduce来排序,不过记得一定要加distribute by,否则map后的数据会随机分配到reducer中,不能保证全局有序。
- 尽量使用union all代替union:union去重,有shuffle,union all不去重,无shuffle,shuffle会造成数据在集群中传输,并且伴随着读和写,很影响任务的执行性能。如果要去重,可以最后用group by。
join task过程优化
- 避免使用笛卡尔积:尽量有关联键,hive本身不支持笛卡尔积,需要先用set hive.mapred.mode=nonstrict设为非strict模式。
- 多表join查询时,小表在前,大表在后,Hive在解析带join的SQL语句时,会默认将最后一个表作为probe table(大表),将前面的表作为build table(小表)并试图将它们读进内存(是否读入内存可以配置)。如果表顺序写反,probe table在前面,有引发OOM的风险。
- 小表超出内存限制,采用多次join:build table没有小到可以直接读如内存,但是相比probe table又很小,可以将build table拆成几个表,分别join。
- 小表join大表,尽量使用map join:将build table和probe table在map端直接完成join过程,没有了reduce,效率高很多。
- 多表join时如果允许尽量使用相同的key:这样会将多个join合并为一个MR job来处理。
- join时保证关联键类型相同:如果不同时也适用cast进行转换,否者会导致另外一个类型的key分配到一个reducer上。
- join的时候如果关联健某一类值较多先过滤:比如空值、0等,因为这会导致某一个reducer的计算量变得很大,可以单独处理倾斜key。
- left semi join 代替join判断in和exists:hive0.13前不支持在where 中使用in嵌套查询是否exists,使用left semi join代替join。
参数配置上的优化
小表join时尽量开启map join
set hive.auto.convert.join=true; -- 版本0.11.0之后,默认是开启状态的,但时不时会把这个配置关闭,所以最好还是手动配置一下
set hive.mapjoin.smalltable.filesize=25000000; -- 默认是25Mb开启mapjoin,对于稍微超过这大小的,可以适当调大,但不能太大调整map数
如果输入文件是少量大文件,就减少mapper数;如果输入文件是大量大文件,就增大mapper数;如果是大量的小文件就先合并小文件。
set mapred.min.split.size=10000; -- 最小分片大小
set mapred.max.split.size=10000000; -- 最大分片大小
set mapred.map.tasks=100; -- 设置map task任务数
map任务数计算规则:map_num = MIN(split_num, MAX(default_num, mapred.map.tasks)),合并小文件
set hive.input.format = org.apache.hadoop.hive.ql.io.CombineHiveInputFormat; -- 输入阶段合并小文件
set hive.merge.mapredfiles=true; -- 输出阶段小文件合并
set hive.merge.mapfiles=true; -- 开启map端合并小文件,默认开启
set hive.merge.mapredfiles=true; -- 开启reduce端合并小文件
set hive.merge.smallfiles.avgsize=16000000; -- 平均文件大小,默认16M,满足条件则自动合并,只有在开启merge.mapfiles和merge.mapredfiles两个开关才有效启用压缩
set hive.exec.compress.intermediate=true; -- 开启输入压缩
set hive.exec.compress.output=true; -- 开启输出压缩
set sethive.intermediate.compression.codec=org.apache.hadoop.io.compress.SnappyCodec; -- 使用Snappy压缩
set mapred.output.compreession.codec=org.apache.hadoop.io.compress.GzipCodec; -- 使用Gzip压缩
set hive.intermediate.compression.type=BLOCK; -- 配置压缩对象 快或者记录分桶设置
set hive.enforce.bucketing=true;
set hive.enforce.sorting=true;设置合适的数据存储格式
hive默认的存储格式是TextFile,但是这种文件格式不使用压缩,会占用比较大空间,目前支持的存储格式有SequenceFile、RCFile、Avro、ORC、Parquet,这些存储格式基本都会采用压缩方式,而且是列式存储,如果指定存储orc模式;
ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.orc.OrcSerde'STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat'
并行化执行并行化执行
每个查询被hive转化成多个阶段,有些阶段关联性不大,则可以并行化执行,减少执行时间,主要针对uoion 操作
set hive.exec.parallel=true; -- 开启并行模式
set hive.exec.parallel.thread.numbe=8; -- 设置并行执行的线程数本地化执行
本地模式主要针对数据量小,操作不复杂的SQL。
set hive.exec.mode.local.auto; -- 开启本地执行模模式
需要满足的条件:
job的输入数据大小必须小于参数:hive.exec.mode.local.auto.inputbytes.max(默认128MB)
job的map数必须小于参数:hive.exec.mode.local.auto.tasks.max(默认4)
job的reduce数必须为0或者1使用严格模式
严格模式主要是防范用户的不规范操作造成集群压力过大,甚至是不可用的情况,只对三种情况起左右,分别是查询分区表是不指定分区;两表join时产生笛卡尔积;使用了order by 排序但是没有limit关键字。
set hive.mapred.mode=strict; -- 开启严格模式map端预聚合
预聚合的配置项是
set hive.map.aggr=true; -- group by时,如果先起一个combiner在map端做部分预聚合,使用这个配置项可以有效减少shuffle数据量,默认值true
set hive.groupby.mapaggr.checkinterval=100000; -- 也可以设置map端预聚合的行数阈值,超过该值就会分拆job,默认值100000倾斜均衡配置项
set hive.groupby.skewindata=false; -- group by时如果某些key对应的数据量过大,就会发生数据倾斜。Hive自带了一个均衡数据倾斜的配置项,默认值false动态分区配置
set hive.exec.dynamic.partition=false; -- 是否开启动态分区功能,默认false关闭
set hive.exec.dynamic.partition.mode=strict; -- 动态分区的模式,默认strict,表示必须指定至少一个分区为静态分区,nonstrict模式表示允许所有的分区字段都可以使用动态分区
set hive.exec.max.dynamic.partitions.pernode=100; -- 在每个执行MR的节点上,最大可以创建多少个动态分区,根据实际的数据来设定,比如hour必须大于等于24,day必须大于365
set hive.exec.max.dynamic.partitions=1000; -- 在所有执行MR的节点上,最大一共可以创建多少个动态分区
set hive.exec.max.created.files=100000; -- 整个MR Job中,最大可以创建多少个HDFS文件
set hive.error.on.empty.partition=false; -- 当有空分区生成时,是否抛出异常JVM重用
set mapred.job.reuse.jvm.num.tasks=10; -- 在MR job中,默认是每执行一个task就启动一个JVM。如果task非常小而碎,那么JVM启动和关闭的耗时就会很长。可以通过调节参数这个参数来重用。例如将这个参数设成5,就代表同一个MR job中顺序执行的10个task可以重复使用一个JVM,减少启动和关闭的开销。但它对不同MR job中的task无效。相关文章:

关于hive sql进行调优的理解
这是一个面试经常面的问题,很不幸,在没有准备的时候,我面到了这个题目,反思了下,将这部分的内容进行总结,给大家一点分享。 hive其实是基于hadoop的数据库管理工具,底层是基于MapReduce实现的&a…...

十大排序算法
一、冒泡排序 冒泡排序(Bubble Sort)是一种简单直观的排序算法。它重复地走访要排序的数列,一次比 较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经…...

PIP 常用操作汇总
1. 升级 python -m pip install --upgrade pip2. 列出所有安装包 pip list3. 查找特定包 pip list | findstr xxx4. 查看特定包 pip show xxx5. 安装软件包 pip install pyzmq24.0.16. 卸载软件包 pip uninstall -y pyzmq7. 查看配置 # 生效的配置(global -&…...

线性代数的本质笔记(3B1B课程)
文章目录 前言向量矩阵行列式线性方程非方阵点积叉积基变换特征向量与特征值抽象向量空间 前言 最近在复习线代,李永乐的基础课我刷了一下,感觉讲的不够透彻,和我当年学线代的感觉一样,就是不够形象。 比如,行列式为…...

快速掌握MQ消息中间件rabbitmq
快速掌握MQ消息中间件rabbitmq 目录概述需求: 设计思路实现思路分析1.video 参考资料和推荐阅读 Survive by day and develop by night. talk for import biz , show your perfect code,full busy,skip hardness,make a better result,wait for change,c…...

Git push拦截
遇到的问题 今天想提交代码到gitee,结果发现被拦截了,有段提示“forbidden by xxxx”… 我记得xxxx好像是公司的一个防泄密的东西… 这个东西是怎么实现的呢? 解决 原来git提供很多hook,push命令就有一个pre-push的hook&#x…...
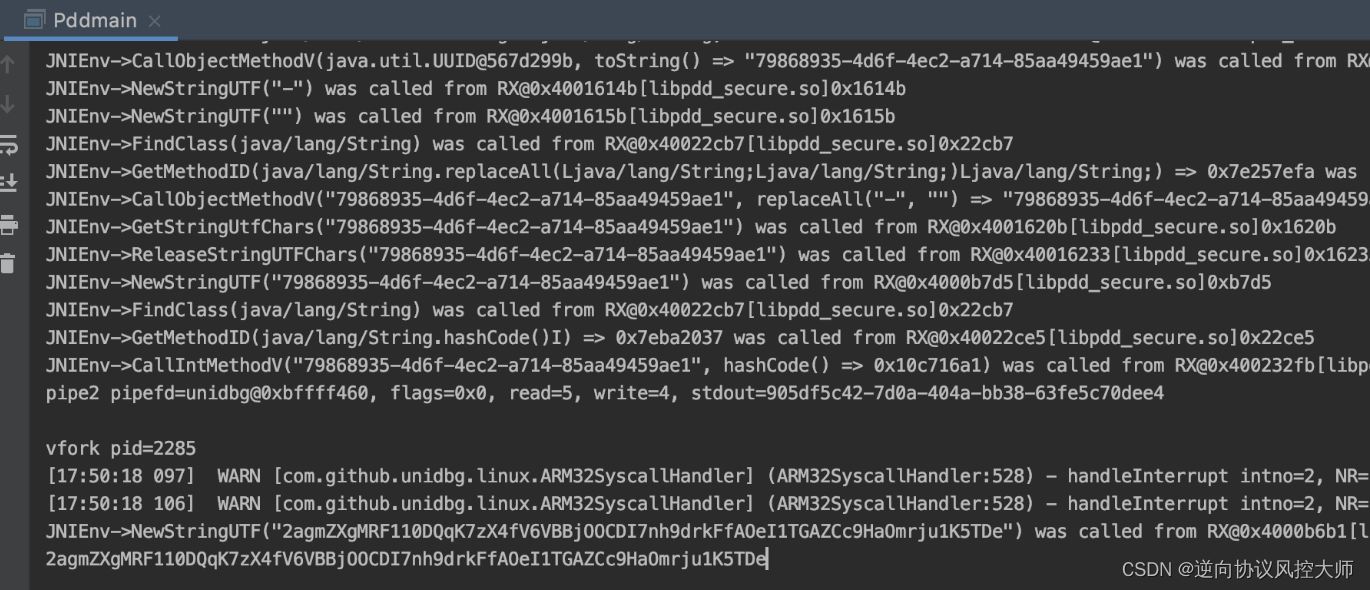
拼多多anti-token分析
前言:拼多多charles抓包分析发现跟商品相关的请求头里都带了一个anti-token的字段且每次都不一样,那么下面的操作就从分析anti-token开始了 1.jadx反编译直接搜索 选中跟http相关的类对这个方法进行打印堆栈 结合堆栈方法调用的情况找到具体anti-token是由拦截器类f…...
基于微信小程序的中医体质辨识文体活动的设计与实现(Java+spring boot+MySQL)
获取源码或者论文请私信博主 演示视频: 基于微信小程序的中医体质辨识文体活动的设计与实现(Javaspring bootMySQL) 使用技术: 前端:html css javascript jQuery ajax thymeleaf 微信小程序 后端:Java s…...
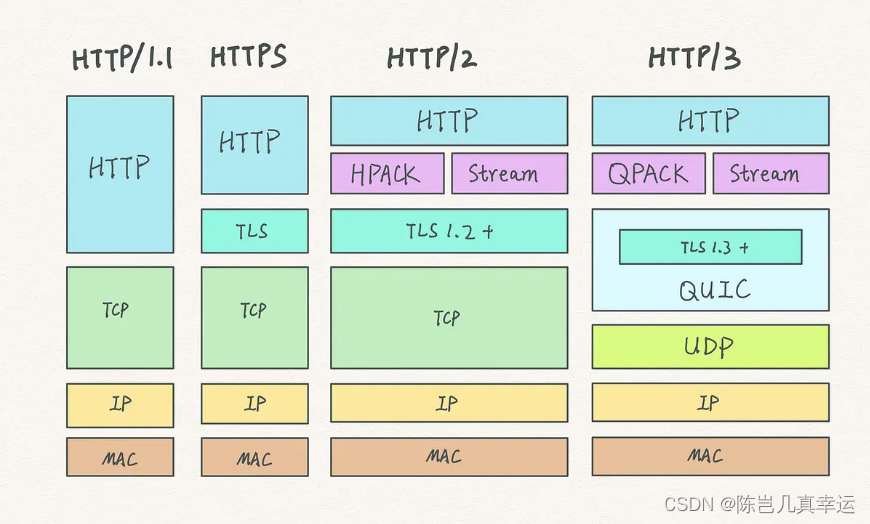
4.16 TCP 协议有什么缺陷?
目录 升级 TCP 的工作很困难 TCP 建立连接的延迟 TCP 存在队头阻塞问题 网络迁移需要重新建立 TCP 连接 升级 TCP 的工作很困难;TCP 建立连接的延迟;TCP 存在队头阻塞问题;网络迁移需要重新建立 TCP 连接; 升级 TCP 的工作很…...
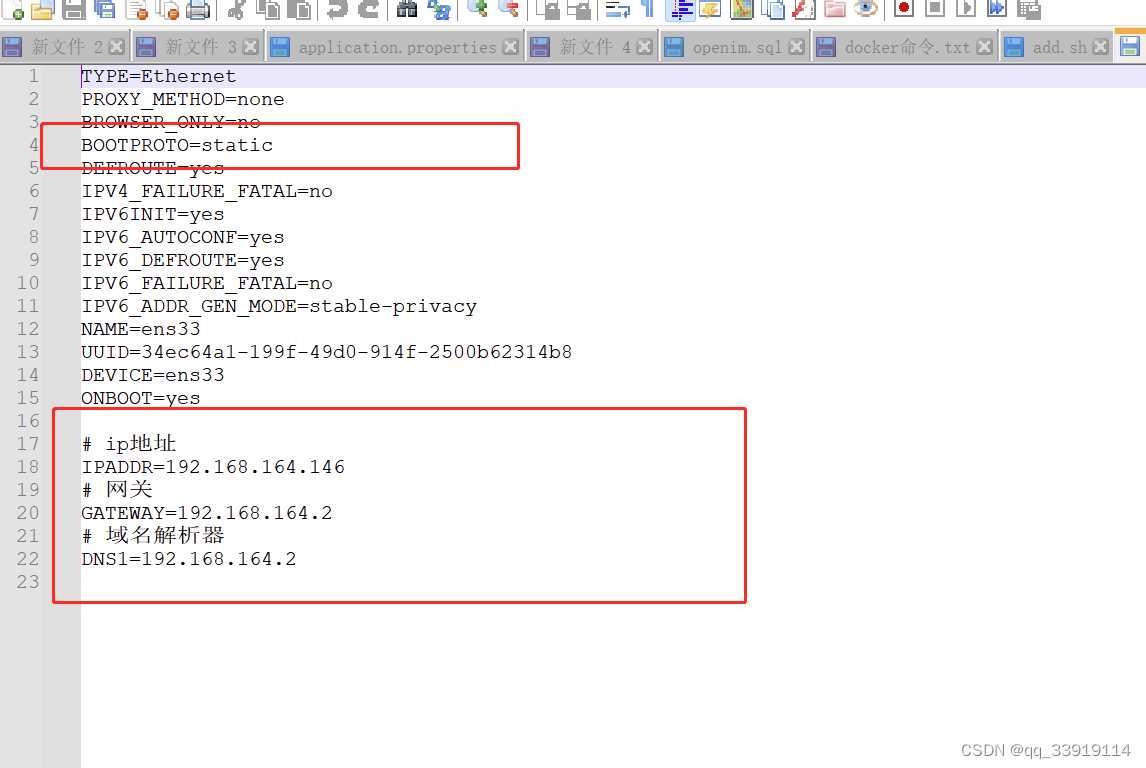
VMware 修改ip地址 虚拟机静态ip设置 centos动态ip修改为静态ip地址 centos静态ip地址 vmware修改ip地址
虚拟机的centos服务器经常变换ip,测试起来有些麻烦,故将动态ip修改为静态ip 1. 查看vmware 虚拟机网络配置: 点击编辑,打开虚拟网络配置 2. 选中nat模式,点击nat设置,最终获取网关ip: 192.168.164.2 3. 进…...

Deepin添加Ubuntu源
升级Deepin V23后,无法安装Zeal了,后面发现可以通过ubuntu源来安装。参考了以下两个文档。 添加Ubuntu源1 添加Ubuntu源2 1.添加ubuntu.list sudo vim /etc/apt/sources.list.d/ubuntu.list 2.添加中科大Ubuntu源 deb http://mirrors.ustc.edu.cn/…...

Mysql的多表查询和索引
MySQL 多表查询 当两个表查询时,从第一张表中取出一行和第二张表的每一行进行组合 返回结果含有两张表的所有列,一共返回的记录数第一张表行数*第二张表的行数(笛卡尔积) -- ?显示雇员名,雇员工资及所在部门的名字 【笛卡尔集…...

Java设计模式之建造者模式
建造者模式,又称生成器模式:将一个复杂的构建与其表示相分离,使得同样的构建过程可以创建不同的表示。 三个角色:建造者、具体的建造者、监工、使用者 建造者角色:定义生成实例所需要的所有方法; 具体的建…...
H5商城公众号商城系统源码 积分兑换商城系统独立后台
网购商城系统源码 积分兑换商城系统源码 独立后台附教程 测试环境:NginxPHP7.0MySQL5.6thinkphp伪静态...

华为OD机试 - 完全数计算(Java 2023 B卷 100分)
目录 专栏导读一、题目描述二、输入描述三、输出描述四、Java算法源码五、效果展示六、纵览全局 华为OD机试 2023B卷题库疯狂收录中,刷题点这里 专栏导读 本专栏收录于《华为OD机试(JAVA)真题(A卷B卷)》。 刷的越多&…...

每日一学——Vlan配置
VLAN(Virtual Local Area Network)是虚拟局域网的缩写,它是一种将多台主机和网络设备逻辑上划分成不同的局域网的技术。VLAN的实施可以基于端口、MAC地址、协议等多种方式进行。 VLAN的主要功能包括: 分割网络:VLAN可…...

Pimpl模式
写在前面 Pimpl(Pointer to implementation,又称作“编译防火墙”) 是一种减少代码依赖和编译时间的C编程技巧,其基本思想是将一个外部可见类(visible class)的实现细节(一般是所有私有的非虚成员)放在一个单独的实现类(implemen…...
Python 密码破解指南:5~9
协议:CC BY-NC-SA 4.0 译者:飞龙 本文来自【OpenDocCN 饱和式翻译计划】,采用译后编辑(MTPE)流程来尽可能提升效率。 收割 SB 的人会被 SB 们封神,试图唤醒 SB 的人是 SB 眼中的 SB。——SB 第三定律 五、凯…...

ARM驱动开发
驱动 以来内核编译,依赖内核执行 驱动可以同时执行多份代码 没main 驱动是依赖内核的框架和操作硬件的过程 一,Linux系统组成 app: [0-3G] ---------------------------------系统调用(软中断…...

Matlab图像处理-加法运算
加法运算 图像加法运算的一个应用是将一幅图像的内容叠加到另一幅图像上,生成叠加图像效果,或给图像中每个像素叠加常数改变图像的亮度。 在MATLAB图像处理工具箱中提供的函数imadd()可实现两幅图像的相加或者一幅图像和常量的相加。 程序代码 I1 i…...

告别杂乱窗口:QTTabBar如何用标签页重塑Windows文件管理体验
告别杂乱窗口:QTTabBar如何用标签页重塑Windows文件管理体验 【免费下载链接】qttabbar QTTabBar is a small tool that allows you to use tab multi label function in Windows Explorer. https://www.yuque.com/indiff/qttabbar 项目地址: https://gitcode.com…...

装上这个技能,让你的 OpenClaw 和 Hermes 变身私人旅行规划师
一句话说清楚给小龙虾和马装上 Voyago,以后你只需要说"帮我规划杭州两天一夜",它就会自动帮你查火车票、搜机票、找酒店、查门票、规划路线、搜小红书攻略、算预算,最终输出一份万字级的完整旅行方案——精确到每两个地点之间坐几号…...
)
NotebookLM时间线创建全流程拆解(从零到专业级时间叙事)
更多请点击: https://codechina.net 第一章:NotebookLM时间线创建全流程拆解(从零到专业级时间叙事) NotebookLM 的时间线(Timeline)功能并非内置独立模块,而是依托其“脚注驱动叙事”机制&am…...
)
Maven依赖管理进阶:如何用dependencyManagement和import scope优雅管理Spring Cloud版本(附父子模块配置实例)
Maven依赖管理进阶:如何用dependencyManagement和import scope优雅管理Spring Cloud版本 在微服务架构盛行的今天,一个项目动辄包含数十个模块已成为常态。我曾接手过一个Spring Cloud Alibaba项目,由于历史原因,各子模块中Spring…...

AI执行层临界点:推理确定性、能力切片与可信Agent的工程落地
1. 项目概述:这不是一份新闻简报,而是一份AI产业周度“技术脉搏图”“Last Week in AI”这个标题乍看像一份科技媒体的常规栏目,但真正拆开来看——它根本不是给普通读者看的“资讯摘要”,而是一份面向AI工程师、算法研究员、技术…...

如何构建活跃的AI技能社区:Awesome Agent Skills线上线下活动完整指南
如何构建活跃的AI技能社区:Awesome Agent Skills线上线下活动完整指南 【免费下载链接】awesome-agent-skills A curated collection of 1000 agent skills from official dev teams and the community, compatible with Claude Code, Codex, Gemini CLI, Cursor, a…...

量子机器学习噪声挑战与HPQS混合框架解析
1. 量子机器学习中的噪声挑战与HPQS解决方案量子机器学习(QML)作为量子计算与经典机器学习的交叉领域,正在重新定义我们处理复杂模式识别问题的方式。与传统机器学习不同,QML利用量子态的叠加和纠缠特性,理论上可以在某些特定任务上实现指数级…...

告别Python版本冲突!用Anaconda的conda命令5分钟搞定Python 3.8专属虚拟环境
告别Python版本冲突!用Anaconda的conda命令5分钟搞定Python 3.8专属虚拟环境 当你的开发机同时运行着基于Python 3.8的旧项目和支持Python 3.10的新项目时,是否经常遇到以下场景:刚在A项目调试通过的代码,切换到B项目就报错&#…...

C#从零开始学习笔记---第九天
又是新的一天,欢迎大家继续查看我的学习笔记,这两天确实状态一般,今天内容我们也不记录太多,主要分为两大块,第一块是对之前提到过的数组进行一个复习,第二块就是在记录一下集合和哈希表的一些内容。话不多…...

【Typescript】14-高级实战-设计类型安全的-api
高级实战:设计类型安全的 API 如果学完前面的知识,你还只是停留在“我会写几个类型、看得懂一些泛型”,那 TypeScript 其实只学了一半。真正拉开差距的地方,是你能不能把类型系统转化成设计能力,尤其是在 API 设计上。…...