pytorch搭建手写数字识别LeNet-5网络,并用tensorRT部署
pytorch搭建手写数字识别LeNet-5网络,并用tensorRT部署
- 前言
- 1、pytorch 搭建LeNet-5,并转为ONNX格式
- 1.1 LeNet-5网络介绍
- 1.2 ONNX(Open Neural Network Exchange)介绍
- 1.3 pytorch 搭建 LeNet5网络
- 2、将onnx转为tensorRT
- 2.1 tensorRT 介绍
- 2.1 onnx 转为 tensorRT
- 3、opencv加载图片,并使用tensorRT 加速推理
- 推理结果
前言
本文只是本人学习模型部署一个简单demo,只是本人学习记录笔记,文中部分代码和文字来源网上,如有请联系我进行删除。代码实现均为python代码,未实现c++版本。
本文未提供环境搭建介绍,代码运行环境如下:
pytorch=1.13
cuda=11.6
cudnn=8.8.0
tensorRT=8.5.3
pycuda=2022.2.2
opencv=4.7.0
这是本人之前环境实录 cuda11.6.2 + cudnn8.8.0 + tensorRT8.5.3 + pytorch1.13安装记录(亲测有效)
1、pytorch 搭建LeNet-5,并转为ONNX格式
1.1 LeNet-5网络介绍
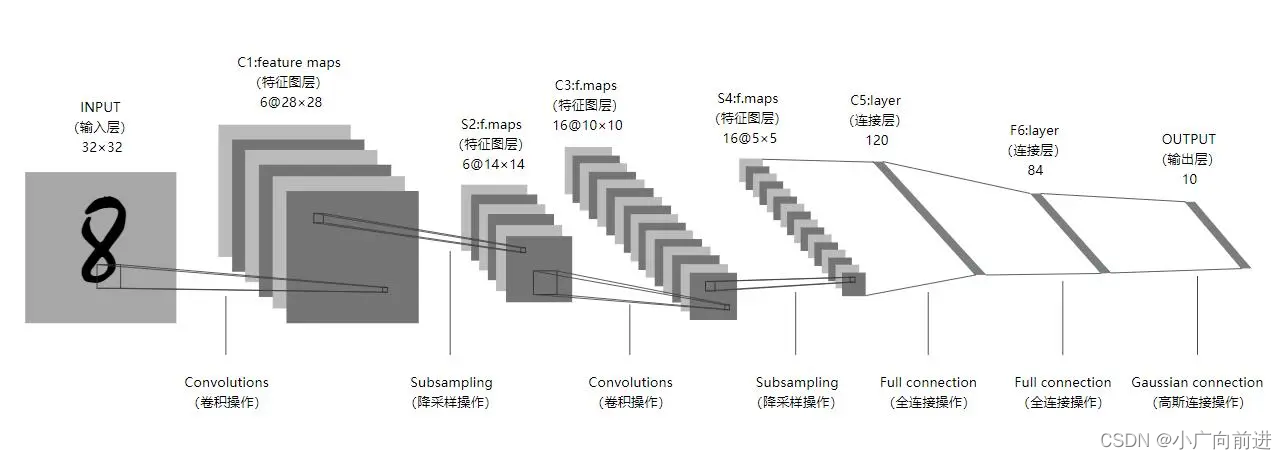
Lenet-5 神经网络出自论文 Gradient-Based Learning Applied to Document Recognition,是一种用于手写体字符识别的非常高效的卷积神经网络。Lenet-5 神经网络一共有 7 层,每层包含不同数量的训练参数。将一批数据输入进神经网络,经过卷积,激活,池化,全连接和Softmax 回归等操作,最终返回一个概率数组,从而达到识别图片的目的。
1.2 ONNX(Open Neural Network Exchange)介绍
开放神经网络交换(Open Neural Network Exchange, ONNX)是一种用于表示机器学习模型的开放标准文件格式,可用于存储训练好的模型,它使得不同的机器学习框架(如PyTorch, Caffe等)可以采用相同格式存储模型数据并可交互。ONNX定义了一组和环境、平台均无关的标准格式,来增强各种机器学习模型的可交互性。它让研究人员可以自由地在一个框架中训练模型并在另一个框架中做推理(inference)。
ONNX的表示方式有两个核心优势:
1. 框架之间的互用互通
开发者能更方便地在不同框架间切换,为不同任务选择最优工具。基本每个框架都会针对某个特定属性进行优化,比如训练速度、对网络架构的支持、能在移动设备上推理等等。在大多数情况下,研发阶段最需要的属性和产品阶段是不一样的。这导致效率的降低,比如选择不切换到最合适的框架,又或者把模型转移到另一个框架导致额外的工作,造成进度延迟。使用支持ONNX表示方式的框架,则大幅简化了切换过程,让开发者的工具选择更灵活。
2. 优化共享
硬件设备商们推出的对神经网络性能的优化,将能够一次性影响到多个开发框架——如果用的是ONNX表示方式。如果优化很频繁,把它们单独整合到各个框架是个非常耗费时间的事。通过ONNX表示方式,更多开发者就能获取这些优化。
1.3 pytorch 搭建 LeNet5网络
使用pytorch 搭建LeNet5 手写数字识别,并转为onnx格式。
- 导入相关模块
import torch
import torch.nn as nn
import torch.optim as optim
import torch.onnx as onnx
import torch.nn.functional as F
import torchvision
from torch.utils.data import DataLoader
- 定义训练参数
n_epochs = 3
batch_size_train = 64
batch_size_test = 1000
learning_rate = 0.01
momentum = 0.5
log_interval = 10
random_seed = 42
torch.manual_seed(random_seed)
- 加载数据集
train_loader = torch.utils.data.DataLoader(torchvision.datasets.mnist.MNIST('./mnist/', train=True, download=True,transform=torchvision.transforms.Compose([torchvision.transforms.ToTensor(),])),batch_size=batch_size_train, shuffle=True)
test_loader = torch.utils.data.DataLoader(torchvision.datasets.mnist.MNIST('./mnist/', train=False, download=True,transform=torchvision.transforms.Compose([torchvision.transforms.ToTensor(),])),batch_size=batch_size_test, shuffle=True)
- 定义网络结构
class Net(nn.Module):def __init__(self):super(Net, self).__init__()self.conv1 = nn.Conv2d(1, 10, kernel_size=5)self.conv2 = nn.Conv2d(10, 20, kernel_size=5)self.conv2_drop = nn.Dropout2d()self.fc1 = nn.Linear(320, 50)self.fc2 = nn.Linear(50, 10)def forward(self, x):x = F.relu(F.max_pool2d(self.conv1(x), 2))x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))x = x.view(-1, 320)x = F.relu(self.fc1(x))x = F.dropout(x, training=self.training)x = self.fc2(x)return F.log_softmax(x)
- 损失函数
# 定义模型和损失函数
network = Net()
optimizer = optim.SGD(network.parameters(), lr=learning_rate,momentum=momentum)train_losses = []
train_counter = []
test_losses = []
test_counter = [i*len(train_loader.dataset) for i in range(n_epochs + 1)]
- 开始训练
def train(epoch):network.train()for batch_idx, (data, target) in enumerate(train_loader):optimizer.zero_grad()output = network(data)loss = F.nll_loss(output, target)loss.backward()optimizer.step()if batch_idx % log_interval == 0:print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(epoch, batch_idx * len(data), len(train_loader.dataset),100. * batch_idx / len(train_loader), loss.item()))train_losses.append(loss.item())train_counter.append((batch_idx * 64) + ((epoch - 1) * len(train_loader.dataset)))torch.save(network.state_dict(), './lenet5.pth')torch.save(optimizer.state_dict(), './optimizer.pth')def test():network.eval()test_loss = 0correct = 0with torch.no_grad():for data, target in test_loader:output = network(data)test_loss += F.nll_loss(output, target, size_average=False).item()pred = output.data.max(1, keepdim=True)[1]correct += pred.eq(target.data.view_as(pred)).sum()test_loss /= len(test_loader.dataset)test_losses.append(test_loss)print('\nTest set: Avg. loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(test_loss, correct, len(test_loader.dataset),100. * correct / len(test_loader.dataset)))for epoch in range(1, n_epochs + 1):train(epoch)test()
- 转为onnx格式
# 加载 PyTorch 模型
network.load_state_dict(torch.load("lenet5.pth"))# 将 PyTorch 模型转为 ONNX 模型
input_shape = (1, 1, 28, 28)
dummy_input = torch.randn(input_shape)
onnx.export(network, dummy_input, "lenet5.onnx")
2、将onnx转为tensorRT
2.1 tensorRT 介绍
TensorRT是一种高性能深度学习推理优化器和运行时加速库,可以为深度学习应用提供低延迟、高吞吐率的部署推理。
TensorRT可用于对超大规模数据中心、嵌入式平台或自动驾驶平台进行推理加速。
TensorRT现已能支持TensorFlow、Caffe、Mxnet、Pytorch等几乎所有的深度学习框架,将TensorRT和NVIDIA的GPU结合起来,能在几乎所有的框架中进行快速和高效的部署推理。
一般的深度学习项目,训练时为了加快速度,会使用多GPU分布式训练。但在部署推理时,为了降低成本,往往使用单个GPU机器甚至嵌入式平台(比如 NVIDIA Jetson)进行部署,部署端也要有与训练时相同的深度学习环境,如caffe,TensorFlow等。
由于训练的网络模型可能会很大(比如,inception,resnet等),参数很多,而且部署端的机器性能存在差异,就会导致推理速度慢,延迟高。这对于那些高实时性的应用场合是致命的,比如自动驾驶要求实时目标检测,目标追踪等。
为了提高部署推理的速度,出现了很多模型优化的方法,如:模型压缩、剪枝、量化、知识蒸馏等,这些一般都是在训练阶段实现优化。
而TensorRT 则是对训练好的模型进行优化,通过优化网络计算图提高模型效率。

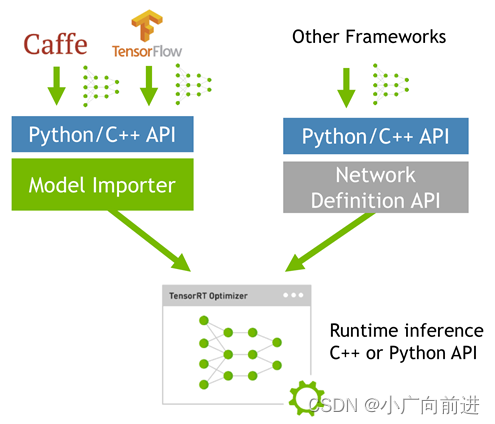
当网络训练完之后,可以将训练模型文件直接丢进tensorRT中,而不再需要依赖深度学习框架(Caffe,TensorFlow等),如下:
2.1 onnx 转为 tensorRT
import tensorrt as trtTRT_LOGGER = trt.Logger()# 加载 ONNX 模型
onnx_file_path = "lenet5.onnx"def build_engine(onnx_file_path, engine_file_path):'''从ONNX文件创建TensorRT引擎以运行推理:return:'''# 创建一个TensorRT builderbuilder = trt.Builder(TRT_LOGGER)# 设置可由构建器使用的最大线程数builder.max_threads = 10flag = (1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH))network = builder.create_network(flag)parser = trt.OnnxParser(network, TRT_LOGGER)runtime = trt.Runtime(TRT_LOGGER)# 设置可由运行时使用的最大线程数runtime.max_threads = 10# 解析模型文件with open(onnx_file_path, "rb") as model:print("开始ONNX文件解析")if not parser.parse(model.read()):print("错误:无法解析ONNX文件")for error in range(parser.num_errors):print(parser.get_error(error))return Noneprint("完成ONNX文件解析")# 打印输入信息print("Network inputs:")for i in range(network.num_inputs):tensor = network.get_input(i)print(tensor.name, tensor.dtype, tensor.shape)config = builder.create_builder_config()config.set_flag(trt.BuilderFlag.REFIT)config.max_workspace_size = 1 << 28 # 256MiBplan = builder.build_serialized_network(network, config)engine = runtime.deserialize_cuda_engine(plan)with open(engine_file_path, "wb") as f:f.write(plan)return enginebuild_engine(onnx_file_path, "lenet5.engine")
3、opencv加载图片,并使用tensorRT 加速推理
import tensorrt as trt
import pycuda.driver as cuda
import pycuda.autoinit
import numpy as np
import cv2TRT_LOGGER = trt.Logger()# 加载 TensorRT Engine
engine_file_path = "lenet5.engine"
with open(engine_file_path, "rb") as f, trt.Runtime(TRT_LOGGER) as runtime:engine = runtime.deserialize_cuda_engine(f.read())# 创建执行上下文
context = engine.create_execution_context()# 分配输入和输出内存
input_shape = (1, 1, 28, 28)
output_shape = (1, 10)
input_host = cuda.pagelocked_empty(trt.volume(input_shape), np.float32)
output_host = cuda.pagelocked_empty(trt.volume(output_shape), np.float32)
input_device = cuda.mem_alloc(input_host.nbytes)
output_device = cuda.mem_alloc(output_host.nbytes)# 加载测试图像
img = cv2.imread(r"C:\Users\xr\Desktop\0.pgm", cv2.IMREAD_GRAYSCALE)
img = cv2.resize(img, (28, 28)) / 255.0# 预处理输入图像
input_data = img.reshape((1,) + img.shape)
input_data = (input_data.astype(np.float32))
input_data = np.expand_dims(input_data, -1)
input_data = 1 - np.transpose(input_data, (0, 3, 1, 2))# 将数据从主机内存复制到设备内存
np.copyto(input_host, input_data.ravel())
cuda.memcpy_htod(input_device, input_host)# 执行 TensorRT Engine
context.execute_v2(bindings=[int(input_device), int(output_device)])# 将数据从设备内存复制到主机内存
cuda.memcpy_dtoh(output_host, output_device)# 后处理输出数据
prediction = np.argmax(output_host)
print(prediction)
# 显示结果
img = cv2.resize(img, (280, 280))
cv2.putText(img, "label:{}".format(prediction), (50, 50), cv2.FONT_HERSHEY_COMPLEX, 1, (0, 255, 0
cv2.imshow("input image", img)
cv2.waitKey()
cv2.destroyAllWindows()推理结果

相关文章:
pytorch搭建手写数字识别LeNet-5网络,并用tensorRT部署
pytorch搭建手写数字识别LeNet-5网络,并用tensorRT部署前言1、pytorch 搭建LeNet-5,并转为ONNX格式1.1 LeNet-5网络介绍1.2 ONNX(Open Neural Network Exchange)介绍1.3 pytorch 搭建 LeNet5网络2、将onnx转为tensorRT2.1 tensorRT 介绍2.1 onnx 转为 te…...

扬帆优配|五千亿巨头一度涨停! 4天3倍,港股又现“狂飙”股!
周一,A股三大指数走势分化。到午间收盘,沪指震荡走高涨近1%,深证成指涨0.75%,创业板指继续弱势调整。 盘面上,钢铁、煤炭、大金融等权重板块团体走强,三大通讯运营商一同拉升,其间我国电信盘中一…...
RocketMQ之(一)RocketMQ入门
一、RocketMQ入门一、RocketMQ 介绍1.1 RocketMQ 是什么?1.2 RocketMQ 应用场景01、应用解耦02、流量削峰03、数据分发1.3 RocketMQ 核心组成01、NameServer02、Broker03、Producer04、Consumer1.6 运转流程1.5 RocketMQ 架构01、NameServer 集群02、Broker 集群03、…...
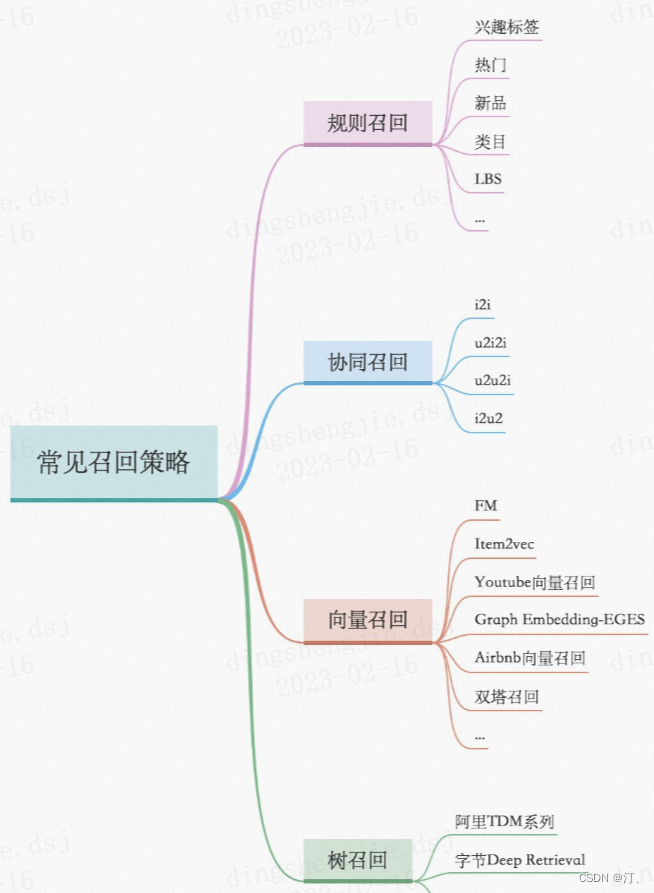
推荐系统[三]:粗排算法常用模型汇总(集合选择和精准预估),技术发展历史(向量內积,WideDeep等模型)以及前沿技术
1.前言:召回排序流程策略算法简介 推荐可分为以下四个流程,分别是召回、粗排、精排以及重排: 召回是源头,在某种意义上决定着整个推荐的天花板;粗排是初筛,一般不会上复杂模型;精排是整个推荐环节的重中之重,在特征和模型上都会做的比较复杂;重排,一般是做打散或满足…...
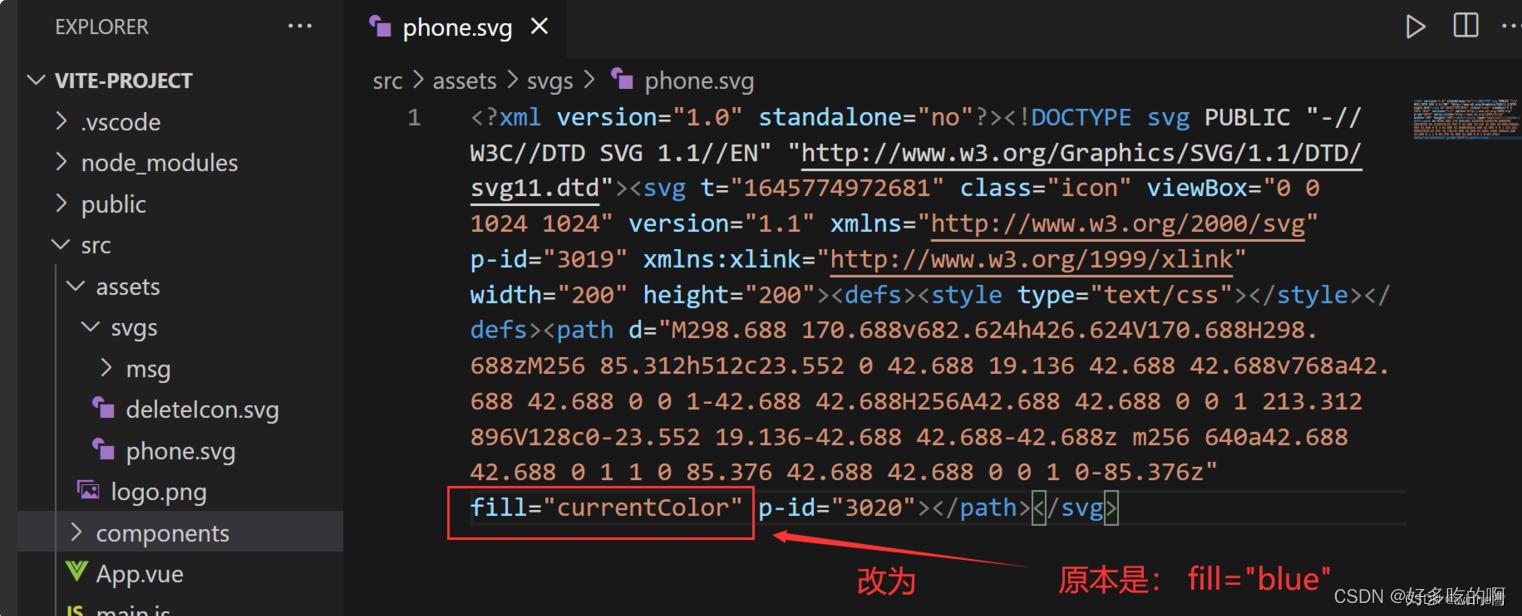
vue3 + vite 使用 svg 可改变颜色
文章目录vue3 vite 使用 svg安装插件2、配置插件 vite.config.js3、根据vite配置的svg图标文件夹,建好文件夹,把svg图标放入4、在 src/main.js内引入注册脚本5、创建一个公共SvgIcon.vue组件6.1 全局注册SvgIcon.vue组件6.2、在想要引入svg的vue组件中引…...

SQL82 返回 2020 年 1 月的所有订单的订单号和订单日期
描述Orders订单表order_numorder_datea00012020-01-01 00:00:00a00022020-01-02 00:00:00a00032020-01-01 12:00:00a00042020-02-01 00:00:00a00052020-03-01 00:00:00【问题】编写 SQL 语句,返回 2020 年 1 月的所有订单的订单号(order_num)…...
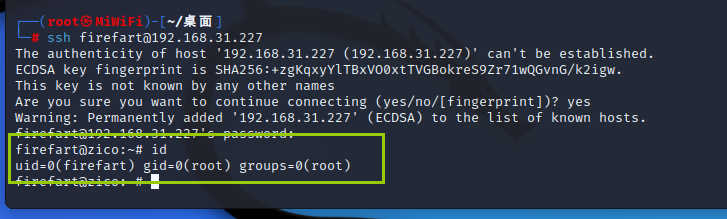
vulnhub zico2
总结:脏牛提权 目录 下载地址 漏洞分析 信息收集 木马上传 反弹shell 提权 下载地址 zico2.ova (Size: 828 MB)Download: https://www.dropbox.com/s/dhidaehguuhyv9a/zico2.ovaDownload (Mirror): https://download.vulnhub.com/zico/zico2.ova使用方法&…...
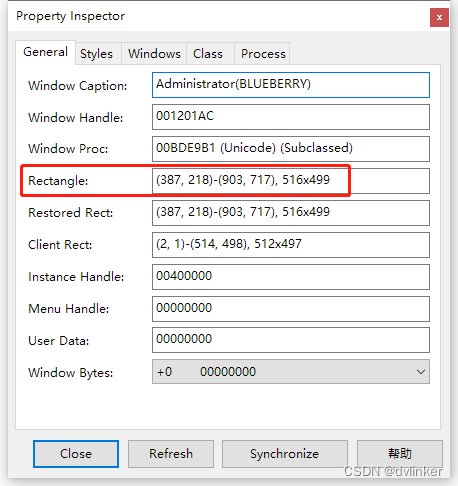
处理窗口的常用API函数及窗口处理经验总结(附源码)
目录 1、检测窗口状态 2、将窗口前置显示 2.1、将窗口拉到最前面显示 2.2、将窗口置顶显示 2.3、将窗口设置到指定窗口的上面 3、将不显示的窗口强行显示出来 4、获取窗口的信息 5、通过窗口信息去查找窗口 5.1、调用GetClassName接口去比对窗口的类名 5.2、调用Find…...

@TableId注解详细介绍
TableId注解是专门用在主键上的注解,如果数据库中的主键字段名和实体中的属性名,不一样且不是驼峰之类的对应关系,可以在实体中表示主键的属性上加Tableid注解,并指定Tableid注解的value属性值为表中主键的字段名既可以对应上。 …...
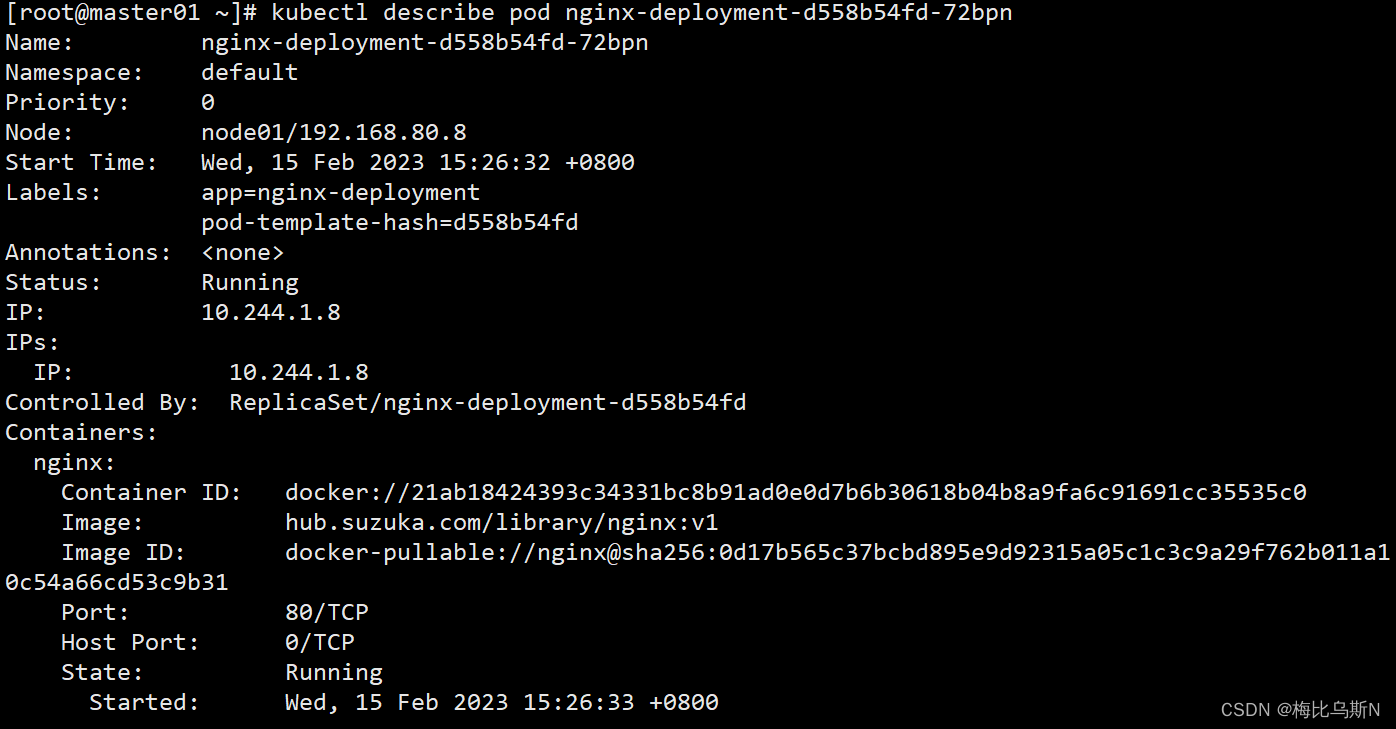
kubectl常用的命令
目录 安装 kubectl 一、命令自动补全 二、常用命令 1、查看所有pod列表 2、查看RC和service列表 3、显示Node的详细信息 4、显示Pod的详细信息, 特别是查看Pod无法创建的时候的日志 5、 根据yaml创建资源, apply可以重复执行,create不行 6、基于nginx.yaml…...
)
Linux 配置远程SSH服务(密码+密钥)
环境准备: 将虚拟机1恢复快照,然后手动配置一个NAT模式IP为192.168.200.100,hostname设置为fuwu1 将虚拟机1复制为虚拟机2,然后手动配置一个NAT模式IP为192.168.200.200,hostname设置为fuwu2 windows准备 xshell 或 pu…...

WuThreat身份安全云-TVD每日漏洞情报-2023-02-20
漏洞名称:Microsoft Exchange Server 远程执行代码漏洞 漏洞级别:高危 漏洞编号:CVE-2023-21529,CNNVD-202302-1075 相关涉及:Microsoft Exchange Server 2016 Cumulative Update 23 漏洞状态:POC 参考链接:https://tvd.wuthreat.com/#/listDetail?TVD_IDTVD-2023-03822 漏洞…...
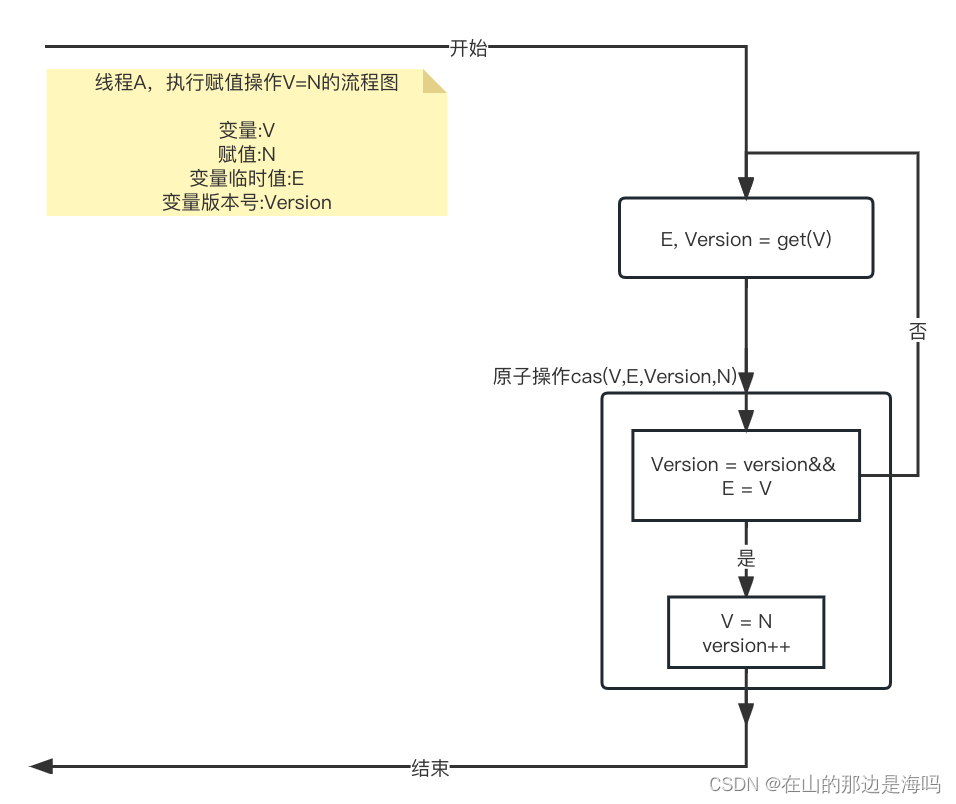
面试经常被问悲观锁和乐观锁?什么是cas?来我花3分钟时间告诉你
锁大家都知道吧,多线程访问资源会存在竞争,那么就需要加锁进而让多个线程一个一个访问。 比如有一个房间,一次只能进一个人,现在有十个人都想进去怎么办? 对,加锁。拿一把钥匙,谁抢到钥匙谁就…...

React源码分析3-render阶段(穿插scheduler和reconciler)
本章将讲解 react 的核心阶段之一 —— render阶段,我们将探究以下部分内容的源码: 更新任务的触发更新任务的创建reconciler 过程同步和异步遍历及执行任务scheduler 是如何实现帧空闲时间调度任务以及中断任务的 触发更新 触发更新的方式主要有以下几…...

3功能测试心得分享
1. 登陆、添加、删除、查询模块是我们经常遇到的,这些模块的测试点该如何考虑 (1)登陆 ① 用户名和密码都符合要求(格式上的要求) ② 用户名和密码都不符合要求(格式上的要求) ③ 用户名符合要求,密码不符合要求(格式上的要求) ④ 密码符合要求ÿ…...

Python-推导式
Python 推导式 Python 推导式是一种独特的数据处理方式,可以从一个数据序列构建另一个新的数据序列的结构体。 Python 支持各种数据结构的推导式: 列表(list)推导式 字典(dict)推导式 集合(set)推导式 元组(tuple)推导式 列表推导式 列表推导式格式…...

操作系统线程
进程那一章,我们留下了一个问题 第一个cpu调用进程,进程调用i/o设备,主动进入ready 队列 第二个cpu将程序执行时间平均分时,进程执行时间到 第三个fork函数,我们上一章的lab有实践,可以看出是父进程主动条用…...

vue3中如何定义响应式变量
vue2中定义方式: 熟悉vue2的前端开发小伙伴,都知道定义变量的方式是属于 选项式写法,所有的变量名全都定义在 data(){return { title:‘hello world’}},里,如下图所示: <template><div><h1>{{tit…...
【C++修炼之路】20.手撕红黑树
每一个不曾起舞的日子都是对生命的辜负 红黑树实现:RBTree 前言一.红黑树的概念及性质1.1 红黑树的概念1.2 红黑树的性质二.红黑树的结构2.1 红黑树节点的定义2.2 红黑树类的封装三.红黑树的插入情况1:只变色情况2:变色单旋情况3:双旋插入的代…...
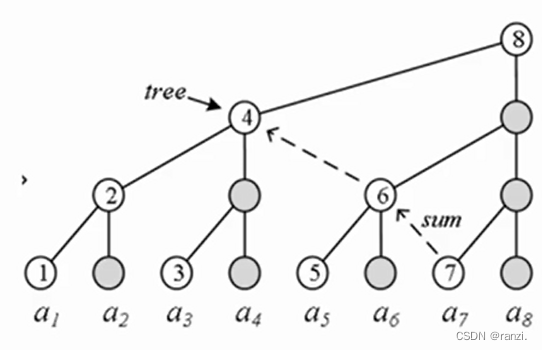
树状数组(高级数据结构)-蓝桥杯
一、简介树状数组 (Binary Indexed Tree,BIT),利用数的二进制特征进行检索的一种树状结构。一种真正的高级数据结构: 二分思想、二叉树、位运算、前缀和。高效!代码极其简洁!二、基本应用数列a1,a2,....,an,操作:单点修改…...

OpenClaw+千问3.5-9B写作辅助:中英文技术文档自动互译
OpenClaw千问3.5-9B写作辅助:中英文技术文档自动互译 1. 为什么需要自动化文档翻译 作为技术文档工程师,我每周都要处理大量中英文技术文档的互译工作。传统工作流需要反复在翻译软件、术语表和Markdown编辑器间切换,不仅效率低下ÿ…...

Linux系统调用原理与性能优化实践
1. Linux系统调用基础概念在Linux系统中,系统调用是用户空间程序与内核交互的唯一合法途径。作为操作系统最基础的接口,它就像一扇严格管控的大门,既保护了内核的安全稳定,又为应用程序提供了必要的服务支持。为什么需要这种隔离机…...

seo网站诊断需要哪些资料_seo网站诊断的重要性是什么
SEO网站诊断需要哪些资料 网站的关键字分析资料 关键字分析是SEO网站诊断中的核心部分之一。你需要收集关于网站当前使用的关键字的数据,包括关键字的搜索量、竞争程度、点击率和转化率等信息。可以使用工具如Google关键字规划师、Ahrefs或SEMrush来获取这些数据。…...

CNVD通用型漏洞挖掘思路,平台漏洞列表一眼定睛法!网络安全挖漏洞零基础入门到精通教程!
有一种艺术叫做,我只需看一眼就能一眼定睛其实最有效率挖cnvd的方法是在于平台本身公布出的漏洞,因为绝对不止一个漏洞这里比如我们看web应用(其他类型都可以看看)一般我们看第一页的漏洞信息就够的了,这里我们点最新的那个KingPortal开发系统存在弱口令,很好,继续挖…...

Claude Code 源码泄露,拿来改造 OpenClaw
一场意外的源码泄露,意外地给开源AI助手社区带来了一份珍贵的“研究素材”。Claude Code近51万行源码的暴露,正好可以为OpenClaw的下一阶段发展,提供一个明确的架构升级蓝图。核心功能:自动化定时任务 (Cron)两者都将“时间管理”…...

Lepton AI日志聚合:ELK与Loki方案对比
Lepton AI日志聚合:ELK与Loki方案对比 【免费下载链接】leptonai A Pythonic framework to simplify AI service building 项目地址: https://gitcode.com/gh_mirrors/le/leptonai Lepton AI是一个Pythonic框架,旨在简化AI服务的构建过程。在AI服…...

DDrawCompat:让经典软件重获新生的兼容性解决方案
DDrawCompat:让经典软件重获新生的兼容性解决方案 【免费下载链接】DDrawCompat DirectDraw and Direct3D 1-7 compatibility, performance and visual enhancements for Windows Vista, 7, 8, 10 and 11 项目地址: https://gitcode.com/gh_mirrors/dd/DDrawCompa…...

实战演练:基于快马平台与方锐理念构建短视频智能配乐应用
最近在做一个短视频创作的小工具,发现给视频配乐真是个技术活。正好看到网易方锐的AI音乐技术挺火的,就想着能不能用它的理念做个智能配乐助手。在InsCode(快马)平台上试了试,没想到还真搞出了一个能跑起来的demo,分享下我的实现思…...

实测对比:用MMDeploy把MMDetection模型转成TensorRT后,FP16/INT8到底能快多少?
MMDeploy实战:TensorRT量化性能深度评测与优化指南 当我们将训练好的目标检测模型部署到生产环境时,推理速度往往成为关键瓶颈。本文将通过实测数据,揭示如何利用MMDeploy工具链将MMDetection模型转换为TensorRT引擎,并深入分析FP…...

别再纠结了!用Python+Wireshark实测OPC UA和Modbus TCP,看完这篇就知道你的项目该选谁
PythonWireshark实战:OPC UA与Modbus TCP协议选型指南 工业自动化项目中,协议选型往往让开发者陷入两难。上周我接手一个智能工厂改造项目时,面对产线上30台不同年代的设备,必须在OPC UA和Modbus TCP之间做出选择。经过三天密集的…...