Python如何操作网络爬虫
Python是一种非常强大的编程语言,用于网络爬虫操作也非常方便。Python提供了许多用于构建和操作网络爬虫的库和工具,如BeautifulSoup、Scrapy、Requests等。本文将详细介绍Python如何操作网络爬虫。
一、安装相关库
首先,我们需要安装Python的相关库。在Python中,可以使用pip来安装这些库。通过运行以下命令,我们可以安装常用的网络爬虫库:
pip install beautifulsoup4
pip install scrapy
pip install requests
安装完成后,我们可以开始编写网络爬虫代码。
二、使用Requests库发送HTTP请求
使用Requests库发送HTTP请求是网络爬虫的一种常见做法。通过使用Requests库,我们可以发送GET或POST请求,获取网页的HTML内容。下面是一个使用Requests库获取网页内容的示例代码:
import requestsurl = 'http://www.example.com'
response = requests.get(url)
html_content = response.textprint(html_content)
在上述代码中,我们首先导入了requests库,然后指定了要爬取的网页URL。使用requests.get()函数发送GET请求,并将返回结果保存在response变量中。我们可以使用response.text属性来获取网页的HTML内容。
三、解析网页内容
解析网页内容是网络爬虫的另一个重要工作。BeautifulSoup是Python中常用的HTML解析库,它可以帮助我们轻松地从HTML文档中提取出我们需要的数据。下面是一个使用BeautifulSoup库解析HTML内容的示例代码:
from bs4 import BeautifulSoup
假设html_content是之前获取到的网页HTML内容
soup = BeautifulSoup(html_content, 'html.parser')
使用soup对象提取我们需要的数据
title = soup.title.text
links = soup.find_all('a')print(title)
print(links)
在上述代码中,我们首先导入了BeautifulSoup库,并创建了一个BeautifulSoup对象,用于解析HTML内容。使用soup.title.text可以获取网页的标题,使用soup.find_all(‘a’)可以获取所有的链接。
四、使用Scrapy库构建爬虫
除了使用Requests和BeautifulSoup库进行网络爬虫操作外,我们还可以使用Scrapy库来更高效地构建和管理爬虫。Scrapy提供了一套强大的工具和框架,用于实现高性能的爬虫。它提供了方便的命令行工具,可以自动生成爬虫模板,并提供了丰富的功能和机制,如自动处理网页链接、持久化存储数据等。
使用Scrapy构建爬虫的过程大致如下:
定义Item:表示要爬取的数据结构;
定义Spider:定义爬取规则和如何解析响应;
定义Pipeline:处理爬取到的数据;
配置Scrapy:指定一些必要的配置项。
五、遵守法律法规和道德准则
在进行网络爬虫操作时,需要遵循相关的法律法规和道德准则,尊重网站的隐私和使用条款,避免对网站造成不必要的压力或损害。以下是一些需要注意的事项:
尊重Robots协议:Robots协议是网站提供的一种标准,用于指定爬虫应该遵守的访问规则。在编写爬虫代码时,需要遵守网站的Robots协议,不要爬取被禁止访问的页面。
合理设置爬取频率:为了避免对网站造成过多的访问压力,需要合理设置爬取的频率。可以使用延时等机制,避免短时间内发送过多的请求。
遵守网站使用条款:在进行爬虫操作时,需要遵守网站的使用条款。有些网站可能明确禁止爬取数据,或者限制爬取的频率和方式。应该遵守这些规定,避免违反网站的规定。
尊重隐私和版权:在爬取网页数据时,需要注意尊重用户的隐私和版权。不要爬取包含个人敏感信息的页面,也不要将爬取到的数据用于商业目的或侵犯他人的版权。
Python提供了丰富的库和工具,用于构建和操作网络爬虫。使用Requests库发送HTTP请求,可以获取网页的HTML内容;使用BeautifulSoup库解析HTML内容,可以提取出需要的数据;使用Scrapy库可以更高效地构建和管理爬虫。在进行网络爬虫操作时,需要遵守相关的法律法规和道德准则,尊重网站的隐私和使用条款,避免对网站造成不必要的压力或损害。
相关文章:

Python如何操作网络爬虫
Python是一种非常强大的编程语言,用于网络爬虫操作也非常方便。Python提供了许多用于构建和操作网络爬虫的库和工具,如BeautifulSoup、Scrapy、Requests等。本文将详细介绍Python如何操作网络爬虫。 一、安装相关库 首先,我们需要安装Python…...

linux文件复制覆盖命令
目录 cp 命令参数2.cp -rf 出现复制不覆盖文件问题3.解决文件复制覆盖提示操作问题,以下四种方式,供大家参考使用。方法1:编写带cp的路径复制覆盖文件方法2:在CP命令前面加一个斜杠\,实现强制覆盖文件方法3:…...

modbus概览
modbus Modbus是Modicon(施耐德)公司于1979年开发的串行通信协议。它最初设计用于公司的可编程逻辑控制器(PLC)。 Modbus是一种开放式协议,支持使用RS232/RS485/RS422协议的串行设备,同时还支持调制解调器…...
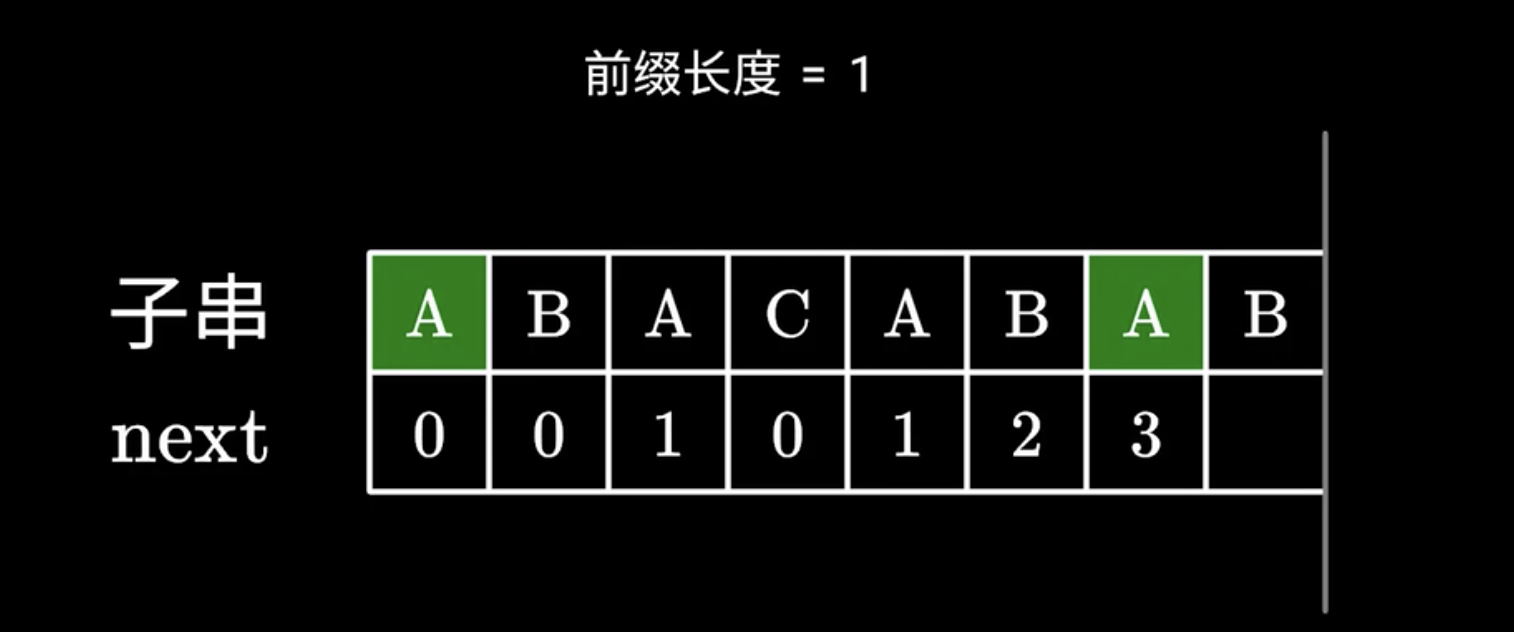
KMP算法开荒
文章目录 一 、前言二、 暴力解法三、KMP算法原理3.1 自动子串的指针3.2 跳过多少个字符3.3 next数组 - 暴力3.4 next数组 - 求解 四 KMP实现 一 、前言 字符串匹配 import re print(re.search(www, www.runoob.com).span()) # 在起始位置匹配 print(re.search(com, www.run…...
)
XXL-JOB(2)
Glue模式 任务以源码的形式去维护调度中心,支持实时编译,无需指定JobHandler。 实际上是继承自JobHandler的java类代码,在执行器中运行,可以使用Resource/Autowire注入执行器里中的其他服务. 在执行器中添加service Service p…...
Linux常用命令_网络命令、关机重启命令
文章目录 1. 网络命令1.1 网络命令: write1.2 网络命令: wall1.3 网络命令: ping1.4 网络命令: ifconfig1.5 网络命令: mail1.6 网络命令: last1.7 网络命令: lastlog1.8 网络命令: traceroute1.9 网络命令: netstat1.10 网络命令: setup1.11 挂载命令 2. 关机重启命令2.1 shut…...

用Cmake build OpenCV后,在VS中查看OpenCV源码的方法(环境VS2022+openCV4.8.0) Part I
用Cmake build OpenCV后,在VS中查看OpenCV源码的方法 Part I 写在最前面,最近这段时间的工作需要用opencv,不仅是调包,还要能够看到opencv的源码。然后就跟着网上的教程实现了一遍,在实现过程中,遇到了不少…...

如何使用Docker搭建ZooKeepe集群
1、拉取镜像 # docker pull zookeeper:3.7.12、创建网络 Docker创建容器时默认采用bridge网络,自行分配ip,不允许自己指定。在实际部署中,需要指定容器ip,不允许其自行分配ip,尤其在搭建集群时。可以通过docker netw…...
【javaweb】学习日记Day3 - Ajax 前后端分离开发 入门
目录 一、Ajax 1、简介 2、Axios (没懂 暂留) (1)请求方式别名 (2)发送get请求 (3)发送post请求 (4)案例 二、前端工程化 1、Vue项目-目录结构 2、…...

SQL注入漏洞复现:探索不同类型的注入攻击方法
这篇文章旨在用于网络安全学习,请勿进行任何非法行为,否则后果自负。 准备环境 sqlilabs靶场 安装:详细安装sqlmap详细教程_sqlmap安装教程_mingzhi61的博客-CSDN博客 一、基于错误的注入 注入讲解 介绍 基于错误的注入(Err…...
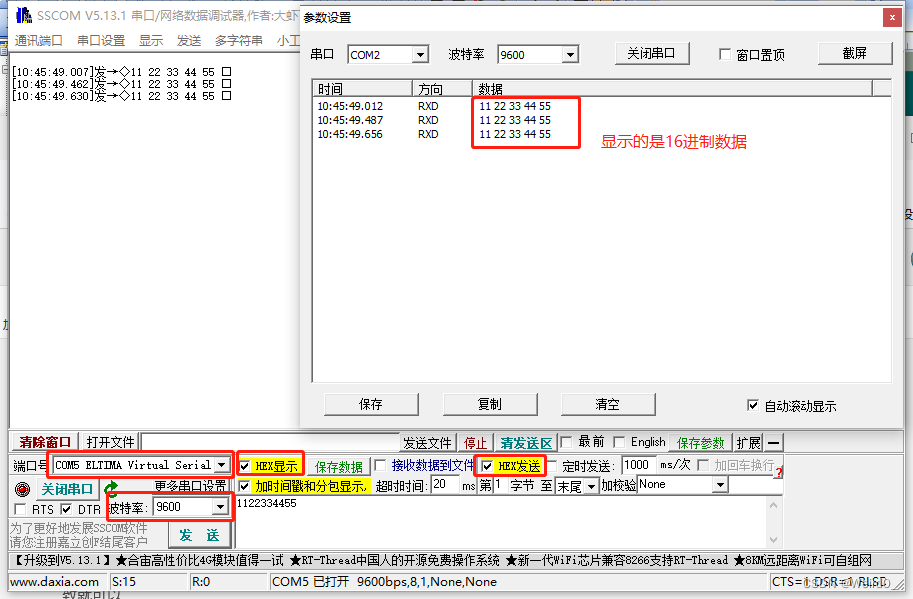
大彩串口屏使用记录
写在最前面 屏幕型号 DC10600M070 IDE VisualTFT(官方) VSCode(lua编程) 用之前看一下官方那个1小时的视频教程就大概懂控件怎么用了,用官方的软件VisualTFT很简单 本文只是简单记录遇到的一些坑 lua编辑器 VisualTF…...

Qt http 的认证方式以及简单实现
http 的认证方式 基本认证(Basic Authentication): 基本认证是最简单的HTTP认证方式。客户端在请求头中使用Base64编码的用户名和密码进行身份验证由于仅使用Base64编码,基本认证并不安全,因此建议与HTTPS一起使用,以…...
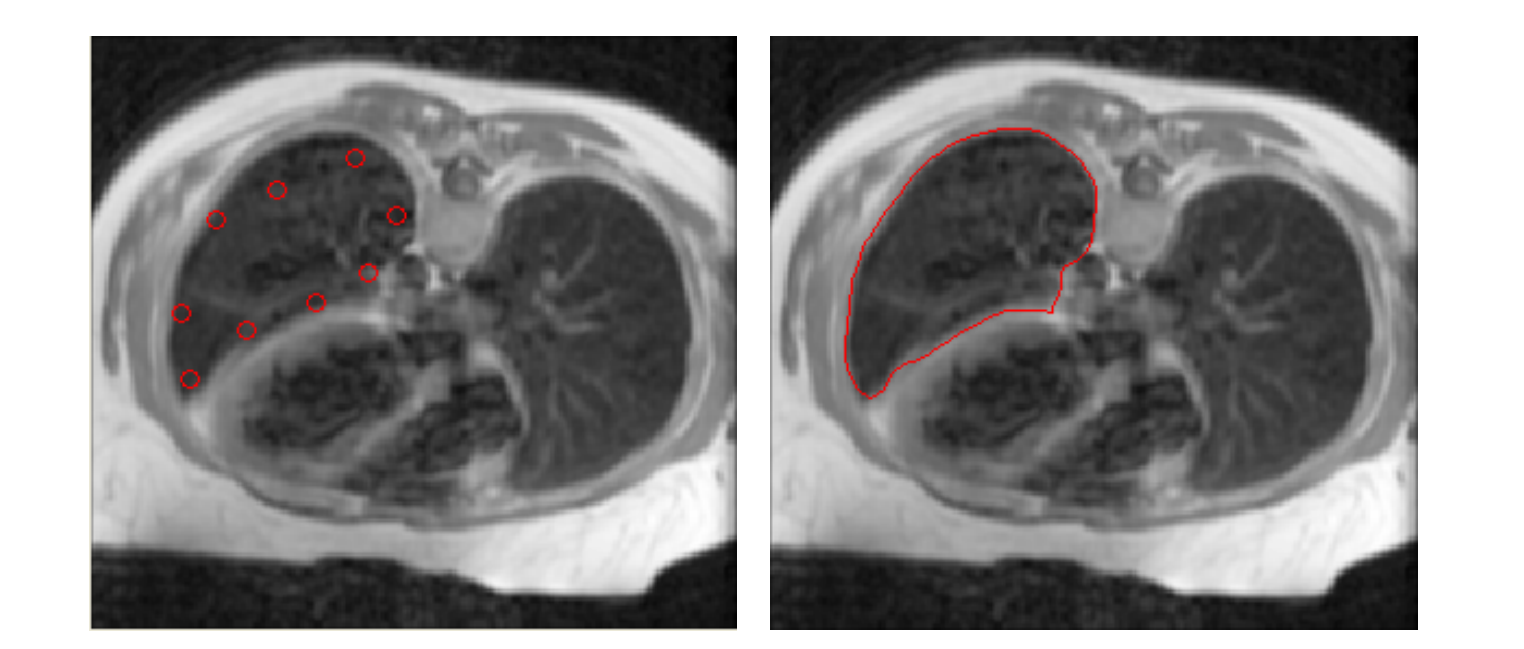
【图像分割】实现snake模型的活动轮廓模型以进行图像分割研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
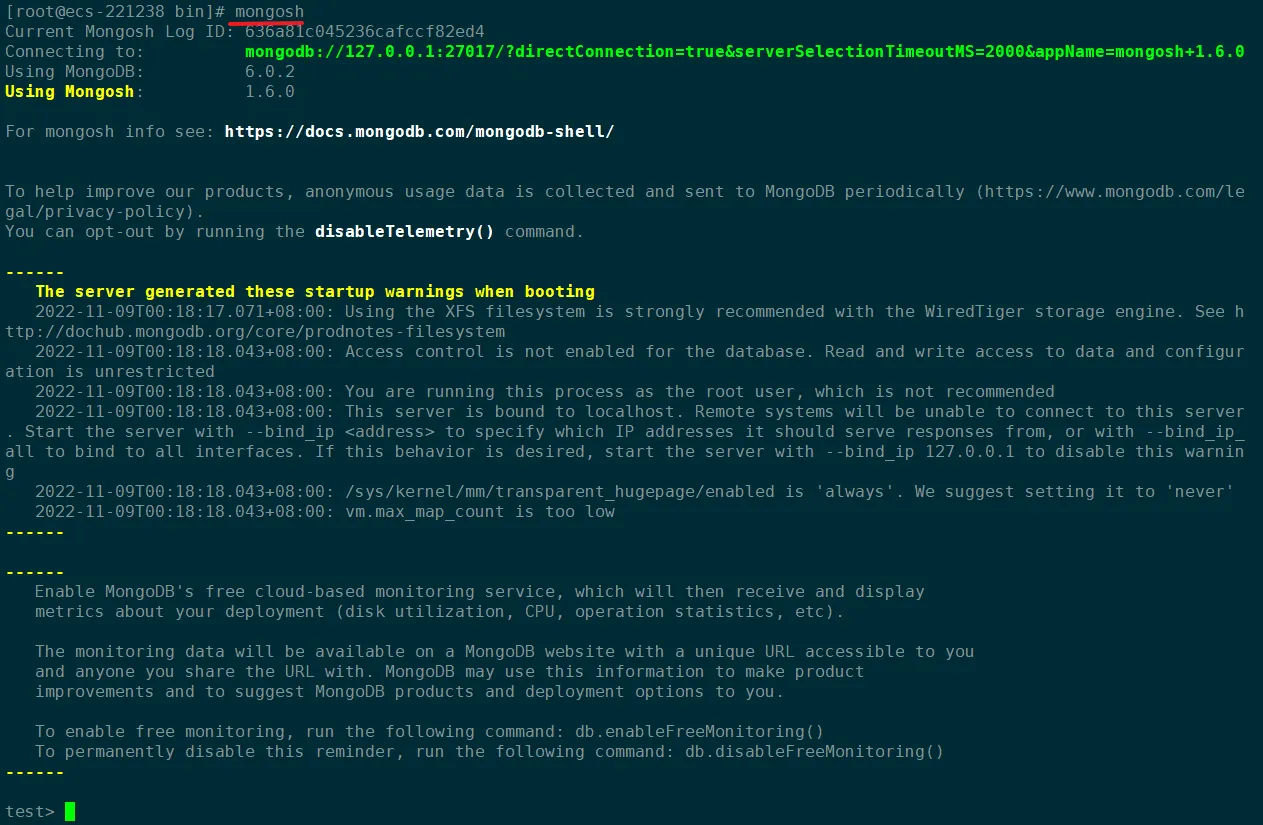
【MongoDB系列】1.MongoDB 6.x 在 Windows 和 Linux 下的安装教程(详细)
本文主要介绍 MongoDB 最新版本 6.x 在Windows 和 Linux 操作系统下的安装方式,和过去 4.x 、5.x 有些许不同之处,供大家参考。 Windows 安装 进入官网下载 Mongodb 安装包,点此跳转,网站会自动检测当前操作系统提供最新的版本&…...

5.网络原理之初识
文章目录 1.网络发展史1.1独立模式1.2网络互连1.3局域网LAN1.3.1基于网线直连1.3.2基于集线器组建1.3.3基于交换机组建1.3.4基于交换机和路由器组建1.3.4.1路由器和交换机区别 1.4广域网WAN 2.网络通信基础2.1IP地址2.2端口号2.3认识协议2.4五元组2.5 协议分层2.5.1 分层的作用…...
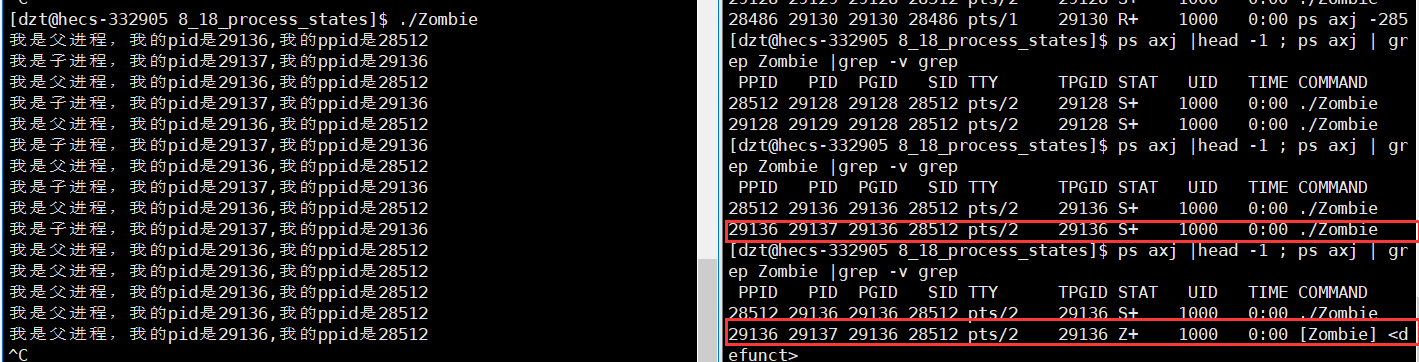
【Linux】进程状态|僵尸进程|孤儿进程
前言 本文继续深入讲解进程内容——进程状态。 一个进程包含有多种状态,有运行状态,阻塞状态,挂起状态,僵尸状态,死亡状态等等,其中,阻塞状态还包含深度睡眠和浅度睡眠状态。 个人主页ÿ…...

ASEMI快恢复二极管APT80DQ60BG特点应用
编辑-Z APT80DQ60BG参数描述: 型号:APT80DQ60BG 最大峰值反向电压(VRRM):600V 最大直流阻断电压VR(DC):600V 平均整流正向电流(IF):80A 非重复峰值浪涌电流(IFSM):600A 工作接点温度和储存温度(TJ, …...

【Python爬虫】使用代理ip进行网站爬取
前言 使用代理IP进行网站爬取可以有效地隐藏你的真实IP地址,让网站难以追踪你的访问行为。本文将介绍Python如何使用代理IP进行网站爬取的实现,包括代理IP的获取、代理IP的验证、以及如何把代理IP应用到爬虫代码中。 1. 使用代理IP的好处 在进行网站爬…...

识别图片中的文字
前言 PearOCR 是一款免费无限制网页版文字识别工具。 优点如下: 免费:完全免费,没有任何次数、大小限制,可以无限使用; 安全:全部数据本地运算,所有图片均不会被上传; 智能…...
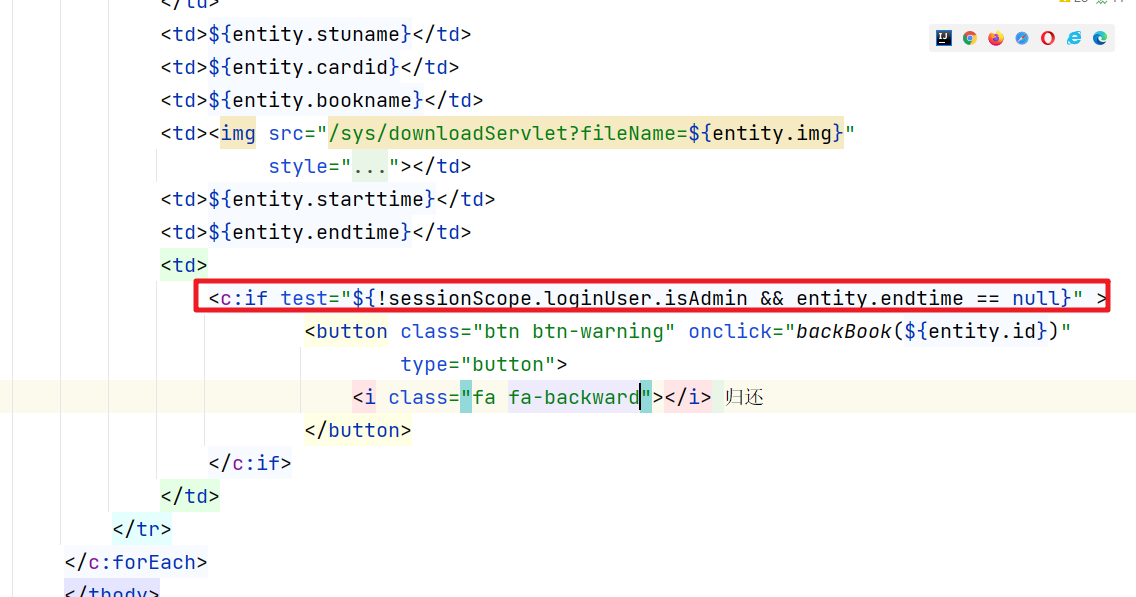
第七章:借阅管理【基于Servlet+JSP的图书管理系统】
借阅管理 1. 借书卡 1.1 查询借书卡 借书卡在正常的CRUD操作的基础上,我们还需要注意一些特殊的情况。查询信息的时候。如果是管理员则可以查询所有的信息,如果是普通用户则只能查看自己的信息。这块的控制在登录的用户信息 然后就是在Dao中处理的时候需…...

ncmdumpGUI:Windows平台免费NCM文件转换终极指南
ncmdumpGUI:Windows平台免费NCM文件转换终极指南 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 您是否在网易云音乐下载了喜爱的歌曲,…...

ARMv8 AArch32调试异常机制与断点技术详解
1. AArch32调试异常架构解析在ARMv8架构的AArch32执行状态下,调试异常机制为开发者提供了强大的程序控制能力。这套机制通过硬件断点和软件断点指令(BKPT)实现对程序执行流的精确控制,其核心设计哲学体现在三个层面:异…...
)
保姆级教程:在Ubuntu 22.04上从源码编译RISC-V SPIKE模拟器(含libboost报错解决)
从零构建RISC-V开发环境:Ubuntu 22.04下SPIKE模拟器深度编译指南 当第一次接触RISC-V生态时,搭建可靠的开发环境往往成为新手面临的第一个挑战。作为RISC-V官方推荐的指令集模拟器,SPIKE以其轻量级和准确性成为学习RISC-V架构的理想工具。本文…...

G-Helper:华硕笔记本性能控制的终极轻量级替代方案
G-Helper:华硕笔记本性能控制的终极轻量级替代方案 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbook, Exper…...

轻量级本地OCR工具SmolDocling实战指南
1. 项目概述:为什么需要一个本地运行的轻量级OCR应用?SmolDocling这个名字本身就带着点工程师式的幽默感——“smol”是“small”的网络变体,强调体积小、依赖少;“Docling”则暗指文档(document)处理的小精…...

无需复杂代理快速为你的项目接入GPT4与Claude等多模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 无需复杂代理快速为你的项目接入GPT4与Claude等多模型 基础教程类,面向希望在一个项目中灵活调用不同厂商大模型的开发…...

5分钟快速上手:抖音下载器完整使用指南
5分钟快速上手:抖音下载器完整使用指南 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support. 抖音批量下…...

布局先行、技术深耕:国内端侧AI企业抢滩机器人与具身智能赛道
具身智能作为AI与物理世界交互的核心方向,正成为工业智能化、人形机器人落地的关键抓手。国内一批端侧AI企业凭借原生技术优势,早早入局机器人与具身智能领域,以全栈技术、规模化落地与生态共建,抢占行业先发优势。其中࿰…...

Bilibili-Evolved:彻底改造你的B站体验!新手必看的个性化增强指南
Bilibili-Evolved:彻底改造你的B站体验!新手必看的个性化增强指南 【免费下载链接】Bilibili-Evolved 强大的哔哩哔哩增强脚本 项目地址: https://gitcode.com/gh_mirrors/bi/Bilibili-Evolved 你是否厌倦了B站千篇一律的界面?是否觉得…...

避坑指南:在Ubuntu 20.04上配置VNC远程桌面,为什么我推荐UltraVNC Viewer而不是TigerVNC?
Ubuntu 20.04远程桌面配置:为什么UltraVNC Viewer成为技术中坚的首选? 在Linux桌面环境远程管理的世界里,VNC协议就像一位历经沧桑的老兵,依然活跃在企业运维、远程开发和混合办公的第一线。Ubuntu 20.04 LTS作为长期支持版本&…...