RocketMQ零拷贝原理
1 PageCache
●由内存中的物理page组成,其内容对应磁盘上的block。
●page cache的大小是动态变化的。
●backing store:cache缓存的存储设备。
●一个page通常包含多个block,而block不一定是连续的。
1.1读Cache
●当内核发起一个读请求时,先会检查请求的数据是否缓存到了page cache中。
如果有,那么直接从内存中读取,不需要访问磁盘,此即cache hit(缓存命中)
如果没有,就必须从磁盘中读取数据,然后内核将读取的数据再缓存到cache中,如此后续的读请求就可以命中缓存了。
●page可以只缓存一个文件的部分内容,而不需要把整个文件都缓存进来。
1.2写Cache
●当内核发起一个写请求时,也是直接往cache中写入,后备存储中的内容不会直接更新。
●内核会将被写入的page标记为dirty,并将其加入到dirty list中。
●内核会周期性地将dirty list中的page写回到磁盘上,从而使磁盘上的数据和内存中缓存的数据一致。
1.3 cache回收
●Page cache的另一个重要工作是释放page,从而释放内存空间。
●cache回收的任务是选择合适的page释放
如果page是dirty的,需要将page写回到磁盘中再释放。
2 cache和buffer的区别
(1) Cache:缓存区,是高速缓存,是位于CPU和主内存之间的容量较小但速度很快的存储器,因为CPU的速度远远高于主内存的速度,CPU从内存中读取数据需等待很长的时间,而Cache
保存着CPU刚用过的数据或循环使用的部分数据,这时从Cache中读取数据会更快,减少了CPU等待的时间,提高了系统的性能。
Cache并不是缓存文件的,而是缓存块的(块是I/O读写最小的单元);Cache一般会用在I/O请求上,如果多个进程要访问某个文件,可以把此文件读入Cache中,这样下一个进程获取CPU控制权并访问此文件直接从Cache读取,提高系统性能。
(2)Buffer:缓冲区,用于存储速度不同步的设备或优先级不同的设备之间传输数据;通过buffer可以减少进程间通信需要等待的时间,当存储速度快的设备与存储速度慢的设备进行通信时,存储慢的数据先把数据存放到buffer,达到一定程度存储快的设备再读取buffer的数据,在此期间存储快的设备CPU可以干其他的事情。
Buffer:一般是用在写入磁盘的,例如:某个进程要求多个字段被读入,当所有要求的字段被读入之前已经读入的字段会先放到buffer中。
3 HeapByteBuffer和DirectByteBuffer
HeapByteBuffer,是在jvm堆上面一个buffer,底层的本质是一个数组,用类封装维护了很多的索引(limit/position/capacity等)。
DirectByteBuffer,底层的数据是维护在操作系统的内存中,而不是jvm里,DirectByteBuffer里维护了一个引用address指向数据,进而操作数据。
HeapByteBuffer优点:内容维护在jvm里,把内容写进buffer里速度快;更容易回收。
DirectByteBuffer优点:跟外设(I0设备)打交道时会快很多,因为外设读取jvm堆里的数据时,
不是直接读取的,而是把jvm里的数据读到一个内存块里,再在这个块里读取的,如果使用
DirectByteBuffer,则可以省去这一步,实现zero copy (零拷贝)
外设之所以要把jvm堆里的数据copy出来再操作,不是因为操作系统不能直接操作jvm内存,而是因为jvm在进行gc (垃圾回收)时,会对数据进行移动,一旦出现这种问题,外设就会出现数据错乱的情况。

所有的通过allocate方法创建的buffer都是HeapByteBuffer。

堆外内存实现零拷贝
(1)前者分配在JVM堆上(ByteBuffer allocate()),后者分配在操作系统物理内存上
(ByteBuffer allocateDirect(),JVM使用C库中的malloc()方法分配堆外内存);
(2)DirectByteBuffer可以减少JVM GC压力,当然,堆中依然保存对象引用,fullgc发生时也会回收直接内存,也可以通过system.gc主动通知JVM回收,或者通过cleaner.clean主动清理。
Cleaner.create()方法需要传入一个DirectByteBuffer对象和一个Deallocator (一个堆外内存回收线程)。GC发生时发现堆中的DirectByteBuffer对象没有强引用了,则调用Deallocator的run()方法回收直接内存,并释放堆中DirectByteBuffer的对象引用;
(3)底层I/O操作需要连续的内存UVM堆内存容易发生GC和对象移动),所以在执行write操作时需要将HeapByteBuffer数据拷贝到一个临时的(操作系统用户态)内存空间中,会多一次额外拷贝。而DirectByteBuffer则可以省去这个拷贝动作,这是Java层面的“零拷贝”技术,在netty中广泛使用;
(4)MappedByteBuffer底层使用了操作系统的mmap机制,FileChannel#map(方法就会返回MappedByteBuffer。DirectByteBuffer虽然实现了 MappedByteBuffer,不过DirectByteBuffer默认并没有直接使用mmap机制。
4缓冲IO和直接IO
4.1缓存IO
缓存I/O又被称作标准I/O,大多数文件系统的默认I/O操作都是缓存I/O。在Linux的缓存I/O机制中,数据先从磁盘复制到内核空间的缓冲区,然后从内核空间缓冲区复制到应用程序的地址空间。
读操作:操作系统检查内核的缓冲区有没有需要的数据,如果已经缓存了,那么就直接从缓存中返回;否则从磁盘中读取,然后缓存在操作系统的缓存中。
写操作:将数据从用户空间复制到内核空间的缓存中。这时对用户程序来说写操作就已经完成,至于什么时候再写到磁盘中由操作系统决定,除非显示地调用了sync同步命令。
缓存I/O的优点:
(1)在一定程度上分离了内核空间和用户空间,保护系统本身的运行安全;
(2)可以减少读盘的次数,从而提高性能。
缓存I/O的缺点:
(1)在缓存I/O机制中,DMA方式可以将数据直接从磁盘读到页缓存中,或者将数据从页缓存直接写回到磁盘上,而不能直接在应用程序地址空间和磁盘之间进行数据传输。数据在传输过程中就需要在应用程序地址空间(用户空间)和缓存(内核空间)之间进行多次数据拷贝操作,这些数据拷贝操作所带来的CPU以及内存开销是非常大的。
4.2直接IO
直接IO就是应用程序直接访问磁盘数据,而不经过内核缓冲区,这样做的目的是减少一次从内核缓冲区到用户程序缓存的数据复制。比如说数据库管理系统这类应用,它们更倾向于选择它们自己的缓存机制,因为数据库管理系统往往比操作系统更了解数据库中存放的数据,数据库管理系统可以提供一种更加有效的缓存机制来提高数据库中数据的存取性能。
直接IO的缺点:如果访问的数据不在应用程序缓存中,那么每次数据都会直接从磁盘加载,这种直接加载会非常缓慢。通常直接IO与异步IO结合使用,会得到此较好的性能。
5内存映射文件(Mmap)
在LINUX中我们可以使用mmap用来在进程虚拟内存地址空间中分配地址空间,创建和物理内存的映射关系。

映射关系可以分为两种
(1)文件映射磁盘文件映射进程的虚拟地址空间,使用文件内容初始化物理内存。
(2)匿名映射初始化全为0的内存空间。
而对于映射关系是否共享又分为
(1)私有映射(MAP. PRIVATE)多进程间数据共享,修改不反应到磁盘实际文件,是一个copy-on-write (写时复制)的映射方式。
(2)共享映射(MAP. SHARED)多进程间数据共享,修改反应到磁盘实际文件中。
因此总结起来有4种组合
(1)私有文件映射多个进程使用同样的物理内存页进行初始化,但是各个进程对内存文件的修改不会共享,也不会反应到物理文件中
(2)私有匿名映射mmap会创建一个新的映射,各个进程不共享,这种使用主要用于分配内存(malloc分配大内存会调用mmap)。例如开辟新进程时,会为每个进程分配虚拟的地址空间,这些虚拟地址映射的物理内存空间各个进程间读的时候共享,写的时候会copy-on-write。
(3)共享文件映射多个进程通过虚拟内存技术共享同样的物理内存空间,对内存文件的修改会反应到实际物理文件中,他也是进程间通信(IPC)的一种机制。
(4)共享匿名映射这种机制在进行fork的时候不会采用写时复制,父子进程完全共享同样的物理内存页,这也就实现了父子进程通信(IPC)。
mmap只是在虚拟内存分配了地址空间,只有在第一次访问虚拟内存的时候才分配物理内存。
在mmap之后,并没有在将文件内容加载到物理页上,只上在虚拟内存中分配了地址空间。当进程在访问这段地址时,通过查找页表,发现虚拟内存对应的页没有在物理内存中缓存,则产生"缺页",由内核的缺页异常处理程序处理,将文件对应内容,以页为单位(4096)加载到物理内存,注意是只加载缺页,但也会受操作系统一些调度策略影响,加载的比所需的多。
6直接内存读取并发送文件的过程

7 Mmap读取并发送文件的过程
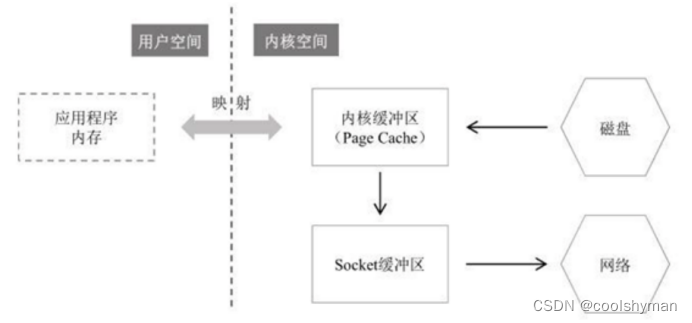
8 Sendfile零拷贝读取并发送文件的过程

零拷贝(zero copy)小结
(1)虽然叫零拷贝,实际上sendfile有2次数据拷贝的。第1次是从磁盘拷贝到内核缓冲区,第二次是从内核缓冲区拷贝到网卡(协议引擎)。如果网卡支持SG-DMA (The Scatter-Gather Direct Memory Access)技术,就无需从PageCache拷贝至Socket缓冲区;
(2)之所以叫零拷贝,是从内存角度来看的,数据在内存中没有发生过拷贝,只是在内存和I/O设备之间传输。很多时候我们认为sendfile才是零拷贝,mmap严格来说不算;
(3)Linux中的API为sendfile、mmap,Java中的API为FileChanel.transferTo().FileChannel.map()等;
(4)Netty、Kafka(sendfile)、Rocketmq (mmap)、Nginx等高性能中间件中,都有大量利用操作系统零拷贝特性。
相关文章:
RocketMQ零拷贝原理
1 PageCache ●由内存中的物理page组成,其内容对应磁盘上的block。 ●page cache的大小是动态变化的。 ●backing store:cache缓存的存储设备。 ●一个page通常包含多个block,而block不一定是连续的。 1.1读Cache ●当内核发起一个读请求时&#x…...

HTML <tbody> 标签
实例 带有 thead、tbody 以及 tfoot 元素的 HTML 表格: <table border="1"><thead><tr><th>Month</th><th>Savings</th></tr></thead><tfoot><tr><td>Sum</td><td>$180<…...

4.22 TCP 四次挥手,可以变成三次吗?
目录 为什么 TCP 挥手需要四次呢? 粗暴关闭 vs 优雅关闭 close函数 shotdown函数 什么情况会出现三次挥手? 什么是 TCP 延迟确认机制? TCP 序列号和确认号是如何变化的? 在一些情况下, TCP 四次挥手是可以变成 T…...

鲁棒性简述
鲁棒性(Robustness)是指系统或算法对于异常情况或不良条件的抵抗能力和适应能力。一个鲁棒性强的系统能够在面对异常、噪声、错误或意外情况时,仍能够保持高效的运行或输出可接受的结果。 鲁棒性是在设计和开发系统时要考虑的一个重要特性&am…...

复习leetcode
460. LFU 缓存 31. 下一个排列 322. 零钱兑换 662. 二叉树最大宽度 43. 字符串相乘...
到异常检测(Anomaly Detection):常用无监督学习方法的优缺点)
从聚类(Clustering)到异常检测(Anomaly Detection):常用无监督学习方法的优缺点
一、引言 无监督学习是机器学习的一种重要方法,与有监督学习不同,它使用未标记的数据进行训练和模式发现。无监督学习在数据分析中扮演着重要的角色,能够从数据中发现隐藏的模式、结构和关联关系,为问题解决和决策提供有益的信息。…...

git仓库提交流程
拉取最新代码 cd dev-ops git拉取最新master代码: git checkout master git pull git checkout wangdachu_dev git merge master :wq 1、切换到文件的本地目录 cd ~/Desktop/aldaba-ops 2、修改用户名和邮箱 git config --global user.email "xxxxxxxxxx.…...
层叠上下文、层叠顺序
原文合集地址如下,有需要的朋友可以关注 本文地址 什么是层叠上下文 层叠上下文(Stacking Context)是指在 HTML 和 CSS 中,用于控制和管理元素层叠顺序以及呈现的一种机制。在一个网页中,许多元素(例如文…...

postgres开发目录
目录 推荐 0.00001 Bruce的博客 0.00002 官方社区博客 0.00003 德哥的培训资料 0.00004 官方开发指南 0.00005 官方网站 0.00006 官方中国网站 0.00007 官方Wiki 0.00008 postgresql代码树 0.00009 gitee-学习资料1 0.00010 gitee-源码 安装与编译 1.00001git源码clone后进…...

计算机视觉入门 6) 数据集增强(Data Augmentation)
系列文章目录 计算机视觉入门 1)卷积分类器计算机视觉入门 2)卷积和ReLU计算机视觉入门 3)最大池化计算机视觉入门 4)滑动窗口计算机视觉入门 5)自定义卷积网络计算机视觉入门 6) 数据集增强(D…...

Python分享之redis(2)
Hash 操作 redis中的Hash 在内存中类似于一个name对应一个dic来存储 hset(name, key, value) #name对应的hash中设置一个键值对(不存在,则创建,否则,修改) r.hset("dic_name","a1","aa&quo…...

springboot aop方式实现敏感数据自动加解密
一、前言 在实际项目开发中,可能会涉及到一些敏感信息,那么我们就需要对这些敏感信息进行加密处理, 也就是脱敏,比如像手机号、身份证号等信息。如果我们只是在接口返回后再去做替换处理,则代码会显得非常冗余…...
RabbitMQ---work消息模型
1、work消息模型 工作队列或者竞争消费者模式 在第一篇教程中,我们编写了一个程序,从一个命名队列中发送并接受消息。在这里,我们将创建一个工作队列,在多个工作者之间分配耗时任务。 工作队列,又称任务队列。主要思…...
GitRedisNginx合集
目录 文件传下载 Git常用命令 Git工作区中文件的状态 远程仓库操作 分支操作 标签操作 idea中使用git 设置git.exe路径 操作步骤 linux配置jdk 安装tomcat 查看是否启动成功 查看tomcat进程 防火墙操作 开放指定端口并立即生效 安装mysql 修改mysql密码 安装lrzsz软…...
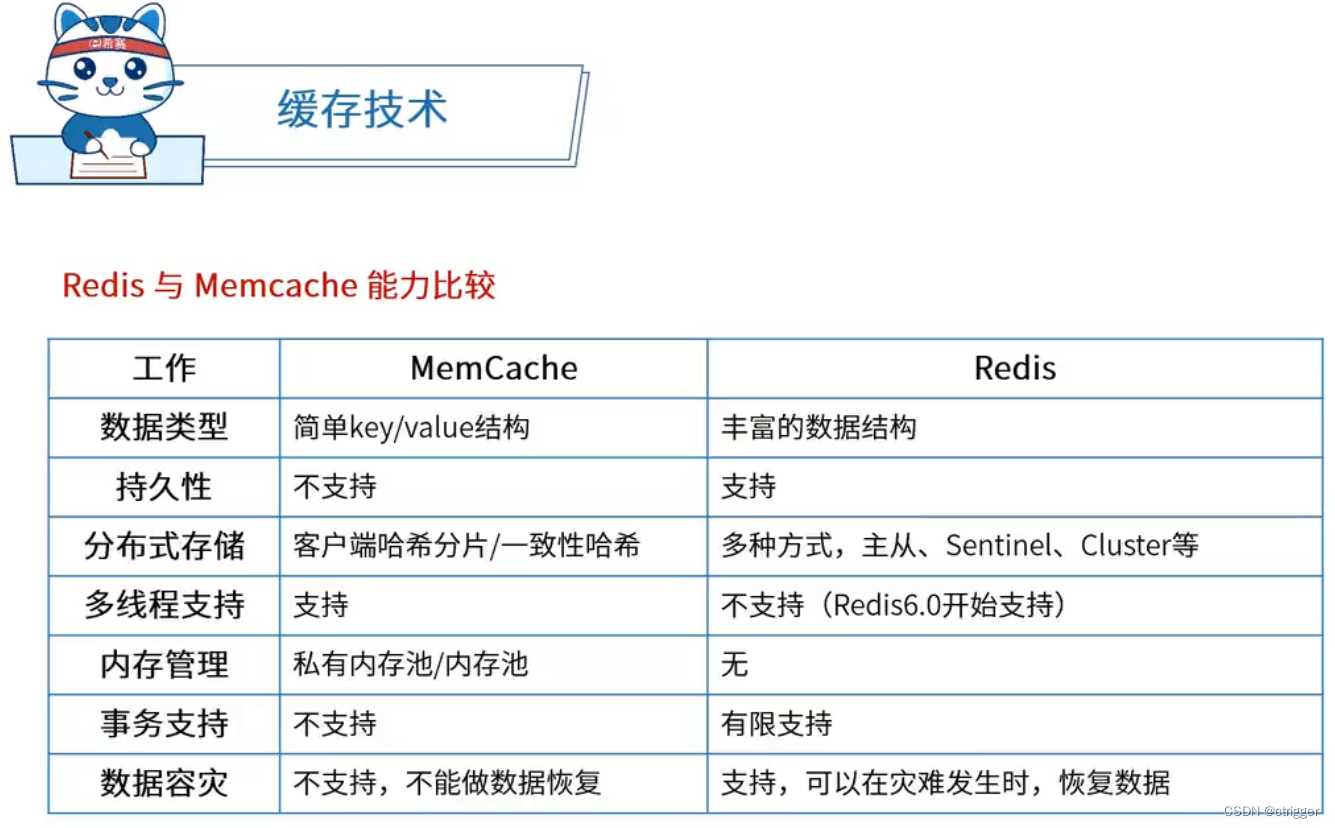
系统架构设计师之缓存技术:Redis与Memcache能力比较
系统架构设计师之缓存技术:Redis与Memcache能力比较...
02.sqlite3学习——嵌入式数据库的基本要求和SQLite3的安装
目录 嵌入式数据库的基本要求和SQLite3的安装 嵌入式数据库的基本要求 常见嵌入式数据库 sqlite3简介 SQLite3编程接口模型 ubuntu 22.04下的SQLite安装 嵌入式数据库的基本要求和SQLite3的安装 嵌入式数据库的基本要求 常见嵌入式数据库 sqlite3简介 SQLite3编程接口模…...
AIGC ChatGPT 按年份进行动态选择的动态图表
动态可视化分析的好处与优势: 1. 提高信息理解性:可视化分析使得大量复杂的数据变得易于理解,通过图表、颜色、形状、尺寸等方式,能够直观地表现不同的数据关系和模式。 2. 加快决策速度:数据可视化可以帮助用户更快…...
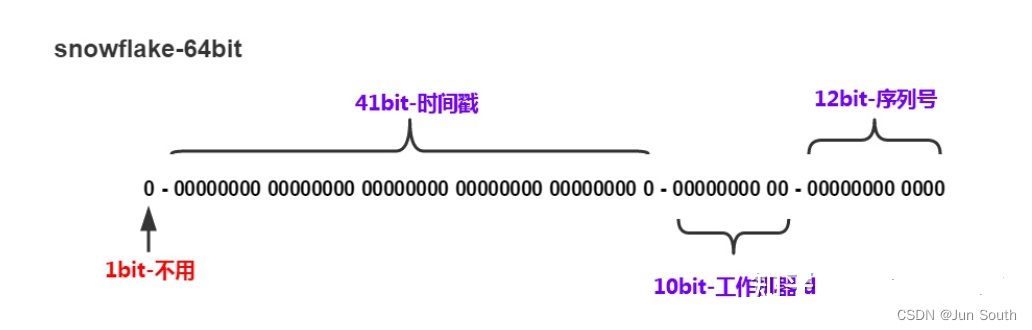
分布式—雪花算法生成ID
一、简介 1、雪花算法的组成: 由64个Bit(比特)位组成的long类型的数字 0 | 0000000000 0000000000 0000000000 000000000 | 00000 | 00000 | 000000000000 1个bit:符号位,始终为0。 41个bit:时间戳,精确到毫秒级别&a…...

Python语言实现React框架
迷途小书童的 Note 读完需要 6分钟 速读仅需 2 分钟 1 reactpy 介绍 reactpy 是一个用 Python 语言实现的 ReactJS 框架。它可以让我们使用 Python 的方式来编写 React 的组件,构建用户界面。 reactpy 的目标是想要将 React 的优秀特性带入 Python 领域,…...
Netty入门学习和技术实践
Netty入门学习和技术实践 Netty1.Netty简介2.IO模型3.Netty框架介绍4. Netty实战项目学习5. Netty实际应用场景6.扩展 Netty 1.Netty简介 Netty是由JBOSS提供的一个java开源框架,现为 Github上的独立项目。Netty提供异步的、事件驱动的网络应用程序框架和工具&…...
)
突发环境事件怎么模拟?用Python+GIS实现高斯烟团模型(附完整代码)
突发污染事件动态模拟:Python与GIS融合的高斯烟团建模实战 化工泄漏、危险品运输事故等突发环境事件往往需要快速响应与精准评估。传统烟羽模型在瞬态污染场景中存在局限性,而高斯烟团模型凭借其动态扩散模拟能力成为应急决策的利器。本文将手把手带您实…...

免费开源鼠标连点器:5分钟上手跨平台自动化点击完整指南
免费开源鼠标连点器:5分钟上手跨平台自动化点击完整指南 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软件界面美观 ࿰…...

低压电工-架空线路,室内线路
前置基础补充 线路核心定义电能输送用的电线线路统称电气线路,电工考证只重点学电力线路(送电、供电),不学控制线路(设备内部控制线)。电压基础 低压:1000V 及以下(日常家用、工厂…...

哔哩下载姬DownKyi:新手也能快速上手的B站视频下载解决方案
哔哩下载姬DownKyi:新手也能快速上手的B站视频下载解决方案 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等&…...

MoE稀疏激活:大模型推理效率革命的核心原理与工程实践
1. 这不是参数堆砌,而是“动态稀疏激活”的工程革命你可能已经看到过那条刷屏的推文:“GPT-4有1.8万亿参数,但每生成一个token只用其中2%。”——这句话像一道闪电劈开了大模型圈的认知惯性。它背后根本不是在炫耀数字有多吓人,而…...

茉莉花插件:Zotero中文文献管理的终极解决方案,5分钟打造高效科研工作流
茉莉花插件:Zotero中文文献管理的终极解决方案,5分钟打造高效科研工作流 【免费下载链接】jasminum A Zotero add-on to retrive CNKI meta data. 一个简单的Zotero 插件,用于识别中文元数据 项目地址: https://gitcode.com/gh_mirrors/ja/…...

在 Elasticsearch 中,存储向量查询速度最高提升 3 倍
作者:来自 Elastic Benjamin Trent Elasticsearch 9.4 提供了一种更简单的方式来搜索存储在 Elasticsearch 索引中的向量,并将延迟最高降低 3 倍。 从向量搜索到强大的 REST API,Elasticsearch 为开发者提供了最全面的搜索工具集。深入体验 E…...

Android Method Tracing深度解析:Unity性能瓶颈跨层归因实战
1. 为什么Method Tracing不是“点一下就出报告”的银弹,而是Android性能诊断的听诊器在Unity项目上线前的最后两周,我接手了一个卡顿严重的AR应用——启动后3秒内帧率从60掉到22,用户滑动模型时UI直接冻结。团队里有人立刻打开Profiler&#…...

AI Coding 时代的工程策略革命:为什么 Monorepo 成了 AI 的“最佳拍档“?
AI Coding 时代的工程策略革命:为什么 Monorepo 成了 AI 的"最佳拍档"? 导读:当 AI 开始替你写代码,你的工程架构是否还在"拖后腿"?本文从 AI 的视角重新审视工程策略,深度解析为什么 …...

量子虚时演化算法:原理、实现与应用
1. 量子虚时演化算法概述虚时演化(Imaginary-Time Evolution, ITE)是量子物理模拟中的核心数学工具,其核心思想是将时间变量t替换为虚数-iβ(β为实数)。这种变换将薛定谔方程中的幺正演化算符e^(-iHt)转化为非幺正的e…...