Elasticsearch(十四)搜索---搜索匹配功能⑤--全文搜索
一、前言
不同于之前的term。terms等结构化查询,全文搜索首先对查询词进行分析,然后根据查询词的分词结果构建查询。这里所说的全文指的是文本类型数据(text类型),默认的数据形式是人类的自然语言,如对话内容、图书名称、商品介绍和酒店名称等。结构化搜索关注的是数据是否匹配,全文搜索关注的是匹配程度;结构化搜索一般用于精确匹配,而全文搜索用于部分匹配。本章将详细介绍使用最多的全文搜索。
二、match查询
match查询是全文搜索的主要代表。对于最基本的match搜索来说,只要分词中的一个或者多个在文档中存在即可。例如搜索“京盛酒店”,查询词先被分词器切分为“京”“盛”“酒”“店”,因此,只要文档中包含这4个字中的任何一个字,都会被搜索到。
您可能会有疑问,为什么“京盛酒店被切分为4个字而不是“京盛”“酒店”两个词呢?这是因为在默认情况下,match查询使用的是标准分词器。该分词器比较适用于英文,如果是中文则按照字进行切分,因此默认的分词器不适合做中文搜索,在后面的章节中将介绍如何安装和使用中文分词器。
以下DSL示例为按照标题搜索“京盛酒店”:
POST /hotel/_search
{"query": {"match": { //匹配title字段为"金都酒店"的文档"title": "京盛酒店"}}
}
或者按照如下形式搜索:
POST /hotel/_search
{"query": {"match": {"title": {"query": "京盛酒店"}}}
}
搜索结果如下:
{..."hits" : {"total" : {"value" : 3,"relation" : "eq"},"max_score" : 1.3428942,"hits" : [{"_index" : "hotel","_type" : "_doc","_id" : "002","_score" : 1.3428942,"_source" : {"title" : "京盛酒店","city" : "北京","price" : "337.00","create_time" : "2020-07-29 13:00:00","amenities" : "充电停车场/可升降停车场","full_room" : false,"location" : {"lat" : 39.911543,"lon" : 116.403},"praise" : 60}},{"_index" : "hotel","_type" : "_doc","_id" : "30","_score" : 1.2387041,"_source" : {"title" : "京盛酒小店","city" : "上海","price" : "300.00","create_time" : "2022-01-29 22:52:00","amenities" : "露天游泳池,普通/充电停车场","full_room" : false,"praise" : 2000}},{"_index" : "hotel","_type" : "_doc","_id" : "27","_score" : 0.5495611,"_source" : {"title" : "盛况精选酒店","city" : "南昌","price" : "900.00","create_time" : "2022-07-29 22:50:00","amenities" : "露天游泳池,普通/充电停车场","full_room" : false,"location" : {"lat" : 56.918229,"lon" : 126.422011},"praise" : 200}}]}
}
从结果中可以看到,匹配度最高的文档是002,该酒店的名称和查询词相同,得分为1.3428942;次之的文档是30,因为该酒店名称中包含“京”“盛”“酒”“店”。但是想比前一个文档多了一个“小”字,所以部分匹配。再次之的文档是27,它只有“盛”“酒”“店”三个字和查询词部分匹配,因此排在最后。
假设用户搜索名称中同时包含“京”和“盛”的酒店,显然之前最后一个文档27就不是用户想要命中的文档。那么在ES中,match搜索可以设置operator参数,该参数决定文档按照分词后的词集合进行“与”还是“或”匹配。在默认情况下,该参数的值为“或”关系,即operator的值为or,这也解释了搜索结果中包含部分匹配的文档。如果希望各个词之间的匹配结果是“与”关系,则可以设置operator参数的值为and。
下面的请求示例设置查询词之间的匹配结果为“与”关系:
POST /hotel/_search
{"query": {"match": {"title": {"query": "京盛酒店","operator": "and"}}}
}
搜索结果如下:
{..."hits" : {"total" : {"value" : 2,"relation" : "eq"},"max_score" : 1.3428942,"hits" : [{"_index" : "hotel","_type" : "_doc","_id" : "002","_score" : 1.3428942,"_source" : {"title" : "京盛酒店","city" : "北京","price" : "337.00","create_time" : "2020-07-29 13:00:00","amenities" : "充电停车场/可升降停车场","full_room" : false,"location" : {"lat" : 39.911543,"lon" : 116.403},"praise" : 60}},{"_index" : "hotel","_type" : "_doc","_id" : "30","_score" : 1.2387041,"_source" : {"title" : "京盛酒小店","city" : "上海","price" : "300.00","create_time" : "2022-01-29 22:52:00","amenities" : "露天游泳池,普通/充电停车场","full_room" : false,"praise" : 2000}}]}
}
有时搜索多个关键字,关键词和文档在某一个比例上匹配即可,如果使用“与”操作过于严苛,如果使用“或”操作又过于宽松。这时可以采用minimum_should_match参数,该参数叫作最小匹配参数,其值为一个数值,意义为可以匹配上的词的个数.在一般情况下将其设置为一个百分数,因为在真实场景中并不能精确控制具体的匹配数量。以下示例设置最小匹配为80%的文档:
POST /hotel/_search
{"query": {"match": {"title": {"query": "京盛酒店","operator": "or","minimum_should_match": "80%" //设置最小匹配度为80%}}}
}
这样的话就需要满足最后命中的文档字数占查询条件中“京盛酒店”的80%(向下取整),例如这里4*80%,其实查询结果只需要有条件中任意三个字符即可。
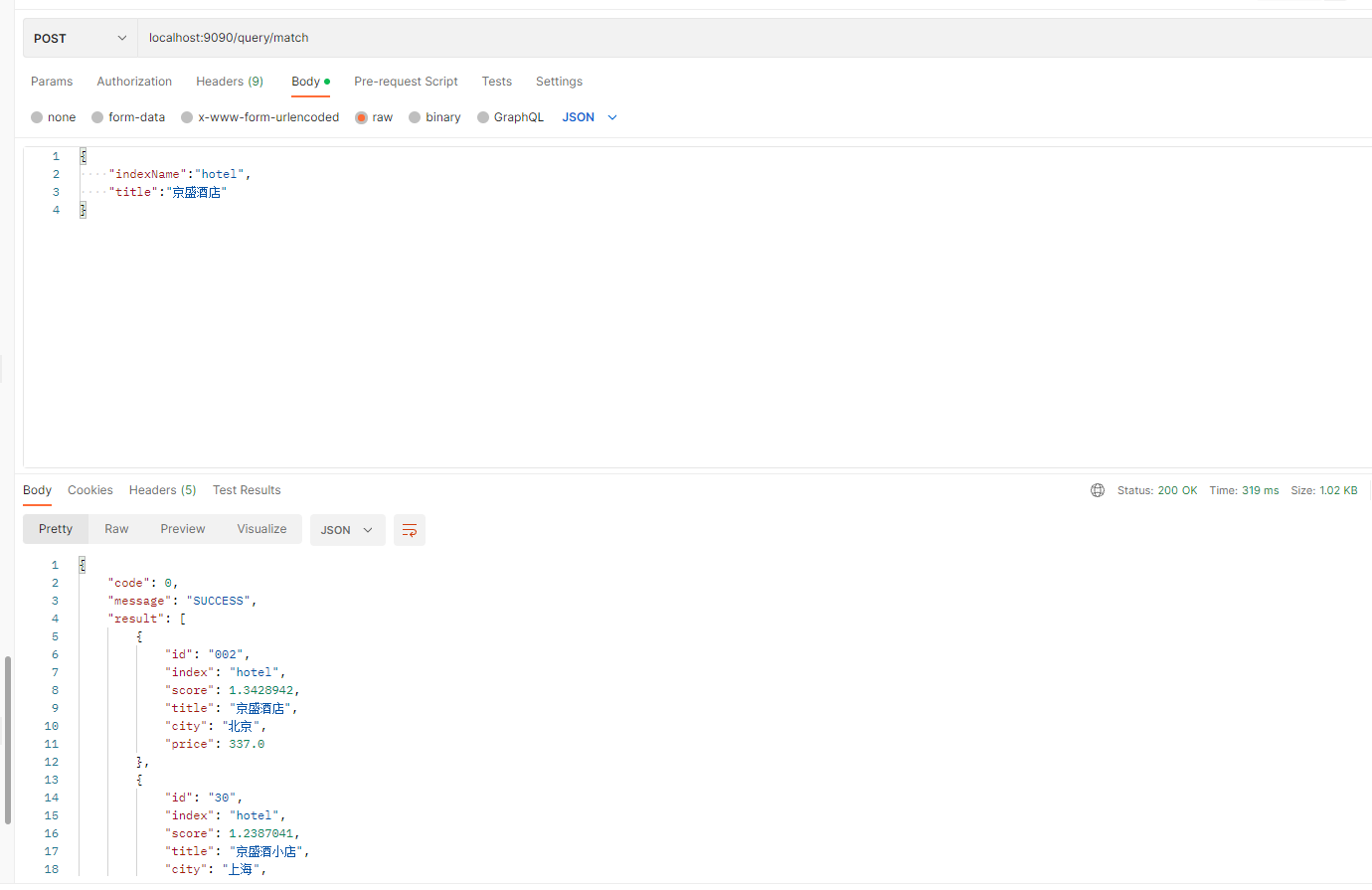
在Java客户端上可以使用QueryBuilders.matchQuery()方法构建match请求,分别给该方法传入字段名称和查询值即可进行match查询。以下代码展示了match请求的使用逻辑:
service层:
public List<Hotel> matchQuery(HotelDocRequest hotelDocRequest) throws IOException {//新建搜索请求String indexName = getNotNullIndexName(hotelDocRequest);SearchRequest searchRequest = new SearchRequest(indexName);SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();//查询title且查询值之间关系是or,并且最小匹配参数为80%MatchQueryBuilder matchQueryBuilder = new MatchQueryBuilder("title", hotelDocRequest.getTitle()).operator(Operator.OR).minimumShouldMatch("80%");searchSourceBuilder.query(matchQueryBuilder);searchRequest.source(searchSourceBuilder);return getQueryResult(searchRequest);}
controller层:
@PostMapping("/query/match")public FoundationResponse<List<Hotel>> matchQuery(@RequestBody HotelDocRequest hotelDocRequest) {try {List<Hotel> hotelList = esQueryService.matchQuery(hotelDocRequest);if (CollUtil.isNotEmpty(hotelList)) {return FoundationResponse.success(hotelList);} else {return FoundationResponse.error(100,"no data");}} catch (IOException e) {log.warn("搜索发生异常,原因为:{}", e.getMessage());return FoundationResponse.error(100, e.getMessage());} catch (Exception e) {log.error("服务发生异常,原因为:{}", e.getMessage());return FoundationResponse.error(100, e.getMessage());}}
postman调用截图:
三、multi_match查询
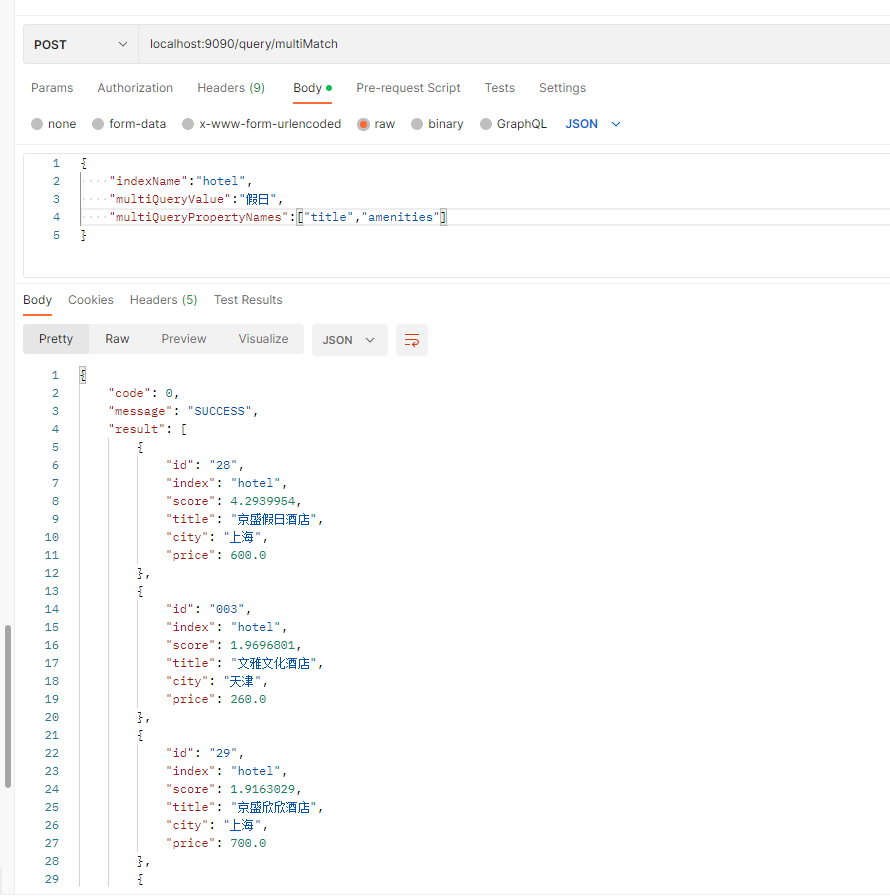
有时用户需要在多个字段中查询关键词,除了使用布尔查询封装多个match查询之外,可替代的方案是使用multi_match。可以在multi_match的query子句中组织数据匹配规则,并在fields子句中指定需要搜索的字段列表。
下面的示例在title和amenities两个字段中同时搜索“假日”关键词:
POST /hotel/_search
{"query": {"multi_match": {"query": "假日","fields": ["amenities","title"]}}
}
搜索结果如下:
{"took" : 14,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 4,"relation" : "eq"},"max_score" : 4.2939954,"hits" : [{"_index" : "hotel","_type" : "_doc","_id" : "28","_score" : 4.2939954,"_source" : {"title" : "京盛假日酒店","city" : "上海","price" : "600.00","create_time" : "2021-04-29 22:52:00","amenities" : "露天游泳池,普通/充电停车场","full_room" : false,"praise" : 200}},{"_index" : "hotel","_type" : "_doc","_id" : "003","_score" : 1.9696801,"_source" : {"title" : "文雅文化酒店","city" : "天津","price" : "260.00","create_time" : "2021-02-27 22:00:00","amenities" : "提供假日party,免费早餐,浴池,充电停车场","full_room" : true,"location" : {"lat" : 39.186555,"lon" : 117.162767},"praise" : 30}},{"_index" : "hotel","_type" : "_doc","_id" : "29","_score" : 1.9163029,"_source" : {"title" : "京盛欣欣酒店","city" : "上海","price" : "700.00","create_time" : "2022-01-29 22:52:00","amenities" : "提供假日party,露天游泳池,普通/充电停车场","full_room" : false,"praise" : 200}},{"_index" : "hotel","_type" : "_doc","_id" : "004","_score" : 1.6876338,"_source" : {"title" : "京盛集团酒店","city" : "上海","price" : "800.00","create_time" : "2021-05-29 21:35:00","amenities" : "浴池(假日需预订),室内游泳池,普通停车场/充电停车场","full_room" : true,"location" : {"lat" : 36.940243,"lon" : 120.394},"praise" : 100}}]}
}
根据结果可以看到,命中的文档要么在title中包含“假日”关键词,要么在amenities字段中包含“假日”关键词。
且之前在Match搜索讲到的operator,minimum_should_match等参数在multi_match搜索中同样适用。
在Java客户端上可以使用QueryBuilders.multiMatchQuery()方法或者直接new MultiMatchQueryBuilder()构建multi_match请求
可以看到,我们构造MultiMatchQueryBuilder,除了查询值,字段它接收的是一个可变长String数组:
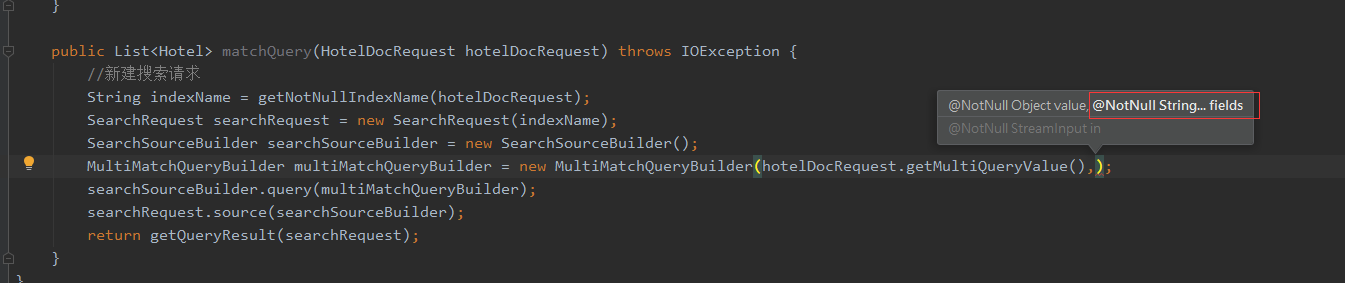
所以我们可以在传参hotelDocRequest加两个参数,一个是multiQueryValue代表要查询的值,另一个是multiQueryPropertyNames代表想要在哪些字段查询
分别给该方法传入查询值和多个字段名称即可进行multi_match查询。以下代码展示了multi_match请求的使用逻辑:
Service层
由于上面讲到构造MultiMatchQueryBuilder接收的是可变长String数组,所以我们要对传参的List通过list.stream().toArray(String[]::new);转化为String可变长数组(String…等价于String[])。
public List<Hotel> multiMatchQuery(HotelDocRequest hotelDocRequest) throws IOException {//新建搜索请求String indexName = getNotNullIndexName(hotelDocRequest);SearchRequest searchRequest = new SearchRequest(indexName);SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();MultiMatchQueryBuilder multiMatchQueryBuilder = new MultiMatchQueryBuilder(hotelDocRequest.getMultiQueryValue(), hotelDocRequest.getMultiQueryPropertyNames().toArray(new String[0]));searchSourceBuilder.query(multiMatchQueryBuilder);searchRequest.source(searchSourceBuilder);return getQueryResult(searchRequest);}
controller层:
@PostMapping("/query/multiMatch")public FoundationResponse<List<Hotel>> multiMatchQuery(@RequestBody HotelDocRequest hotelDocRequest) {try {List<Hotel> hotelList = esQueryService.multiMatchQuery(hotelDocRequest);if (CollUtil.isNotEmpty(hotelList)) {return FoundationResponse.success(hotelList);} else {return FoundationResponse.error(100,"no data");}} catch (IOException e) {log.warn("搜索发生异常,原因为:{}", e.getMessage());return FoundationResponse.error(100, e.getMessage());} catch (Exception e) {log.error("服务发生异常,原因为:{}", e.getMessage());return FoundationResponse.error(100, e.getMessage());}}
postman运行截图:
四、match_phrase查询
match_phrase用于匹配短语,与match查询不同的是,match_phrase用于搜索确切的短语或临近的词语。假设在酒店标题中搜索“京盛酒店”,希望酒店标题中的“京盛酒店”四字完全按照搜索词的顺序并且紧邻,此时就需要使用match_phrase查询:
POST /hotel/_search
{"query": {"match_phrase": {"title": {"query": "京盛酒店"}}}
}
结果如下:
{..."hits" : {"total" : {"value" : 1,"relation" : "eq"},"max_score" : 1.3428942,"hits" : [{"_index" : "hotel","_type" : "_doc","_id" : "002","_score" : 1.3428942,"_source" : {"title" : "京盛酒店","city" : "北京","price" : "337.00","create_time" : "2020-07-29 13:00:00","amenities" : "充电停车场/可升降停车场","full_room" : false,"location" : {"lat" : 39.911543,"lon" : 116.403},"praise" : 60}}]}
}
根据上述结果可知,使用match_phrase查询后,只有文档002命中,而类似之前的“京盛集团酒店”等类似文档没有被命中,这是为什么呢?
我们知道,在默认标准分词器的情况下,文档002的title字段被切分为“京”“盛”“酒”“店”,其中这些分词后的文档下标“京”代表0,盛”代表1,“酒”代表2,“店”代表3,而对于match_phrase查询,在不去设置下标移动步长的情况下这些分词文档想要移动到理想位置(查询词的位置,这里就是京盛酒店)的步数默认就是0,而可以发现,我们命中的文档002“京盛酒店”,这个文档下标其实就已经是理想位置了,不需要额外移动,相当于步长就是0,所以能够命中。而对于“京盛集团酒店”,分词后“盛”想要移动到“酒”这个下标,需要移动2次,所以步长是2,不符合默认的步长,所以无法命中。
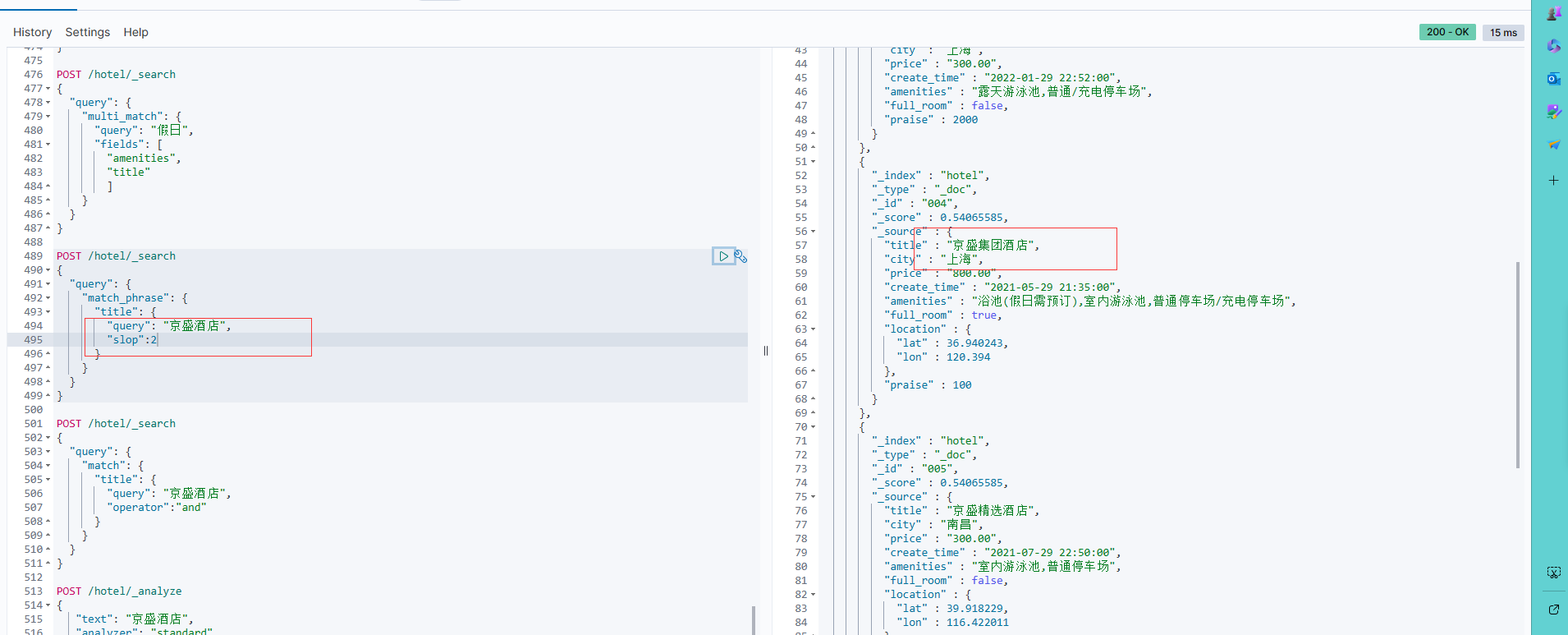
那么如果需要“京盛集团酒店”也能够被命中,则可以设置match_phrase查询的slop参数,它用来调节匹配词之间的距离阈值,即上面说的步长,下面的DSL将slop设置为2
POST /hotel/_search
{"query": {"match_phrase": {"title": {"query": "京盛酒店","slop":2}}}
}
可以看到这样就能命中“京盛集团酒店”了
在Java客户端上可以使用QueryBuilders.matchPhraseQuery()方法构建match_phrase请求,分别给该方法传入查询字段和值即可运行multi_match查询。这一点和match搜索很像。以下代码展示了match_phrase请求的使用逻辑:
Service层:
public List<Hotel> matchPhraseQuery(HotelDocRequest hotelDocRequest) throws IOException {//新建搜索请求String indexName = getNotNullIndexName(hotelDocRequest);SearchRequest searchRequest = new SearchRequest(indexName);SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();//构造MatchPhraseQueryBuilder且设置步长为2MatchPhraseQueryBuilder matchPhraseQueryBuilder = new MatchPhraseQueryBuilder("title", hotelDocRequest.getTitle()).slop(2);searchSourceBuilder.query(matchPhraseQueryBuilder);searchRequest.source(searchSourceBuilder);return getQueryResult(searchRequest);}
Controller层:
@PostMapping("/query/matchPhrase")public FoundationResponse<List<Hotel>> matchPhraseQuery(@RequestBody HotelDocRequest hotelDocRequest) {try {List<Hotel> hotelList = esQueryService.matchPhraseQuery(hotelDocRequest);if (CollUtil.isNotEmpty(hotelList)) {return FoundationResponse.success(hotelList);} else {return FoundationResponse.error(100,"no data");}} catch (IOException e) {log.warn("搜索发生异常,原因为:{}", e.getMessage());return FoundationResponse.error(100, e.getMessage());} catch (Exception e) {log.error("服务发生异常,原因为:{}", e.getMessage());return FoundationResponse.error(100, e.getMessage());}}
Postman运行截图:
相关文章:
Elasticsearch(十四)搜索---搜索匹配功能⑤--全文搜索
一、前言 不同于之前的term。terms等结构化查询,全文搜索首先对查询词进行分析,然后根据查询词的分词结果构建查询。这里所说的全文指的是文本类型数据(text类型),默认的数据形式是人类的自然语言,如对话内容、图书名…...

已解决Gradle错误:“Unable to load class ‘org.gradle.api.plugins.MavenPlugin‘”
🌷🍁 博主猫头虎 带您 Go to New World.✨🍁 🦄 博客首页——猫头虎的博客🎐 🐳《面试题大全专栏》 文章图文并茂🦕生动形象🦖简单易学!欢迎大家来踩踩~🌺 &a…...
windows中安装sqlite
1. 下载文件 官网下载地址:https://www.sqlite.org/download.html 下载sqlite-dll-win64-x64-3430000.zip和sqlite-tools-win32-x86-3430000.zip文件(32位系统下载sqlite-dll-win32-x86-3430000.zip)。 2. 安装过程 解压文件 解压上一步…...

前端面试:【系统设计与架构】前端架构模式的演进
前端架构模式在现代Web开发中扮演着关键角色,它们帮助我们组织和管理前端应用的复杂性。本文将介绍一些常见的前端架构模式,包括MVC、MVVM、Flux和Redux,以及它们的演进和应用。 1. MVC(Model-View-Controller)&#x…...

【CSS】em单位的理解
1、em单位的定义 MDN的解释:它是相对于父元素的字体大小的一个单位。 例如:父元素font-size:16px;子元素的font-size:2em(也就是32px) 注:有一个误区,虽然他是一个相对…...

无涯教程-Python机器学习 - Based on human supervision函数
Python机器学习 中的 Based on human s - 无涯教程网无涯教程网提供https://www.learnfk.com/python-machine-learning/machine-learning-with-python-based-on-human-supervision.html...

【滑动窗口】leetcode209:长度最小的子数组
一.题目描述 长度最小的子数组 二.思路分析 题目要求:找出长度最小的符合要求的连续子数组,这个要求就是子数组的元素之和大于等于target。 如何确定一个连续的子数组?确定它的左右边界即可。如此一来,我们最先想到的就是暴力枚…...

C++ STL unordered_map
map hashmap 文章目录 Map、HashMap概念map、hashmap 的区别引用头文件初始化赋值unordered_map 自定义键值类型unordered_map 的 value 自定义数据类型遍历常用方法插入查找 key修改 value删除元素清空元素 unordered_map 中每一个元素都是一个 key-value 对,数据…...
全流程R语言Meta分析核心技术应用
Meta分析是针对某一科研问题,根据明确的搜索策略、选择筛选文献标准、采用严格的评价方法,对来源不同的研究成果进行收集、合并及定量统计分析的方法,最早出现于“循证医学”,现已广泛应用于农林生态,资源环境等方面。…...
Go并发可视化解释 - Select语句
昨天,我发布了一篇文章,用可视化的方式解释了Golang中通道(Channel)的工作原理。如果你对通道的理解仍然存在困难,最好呢请在阅读本文之前先查看那篇文章。作为一个快速的复习:Partier、Candier 和 Stringe…...
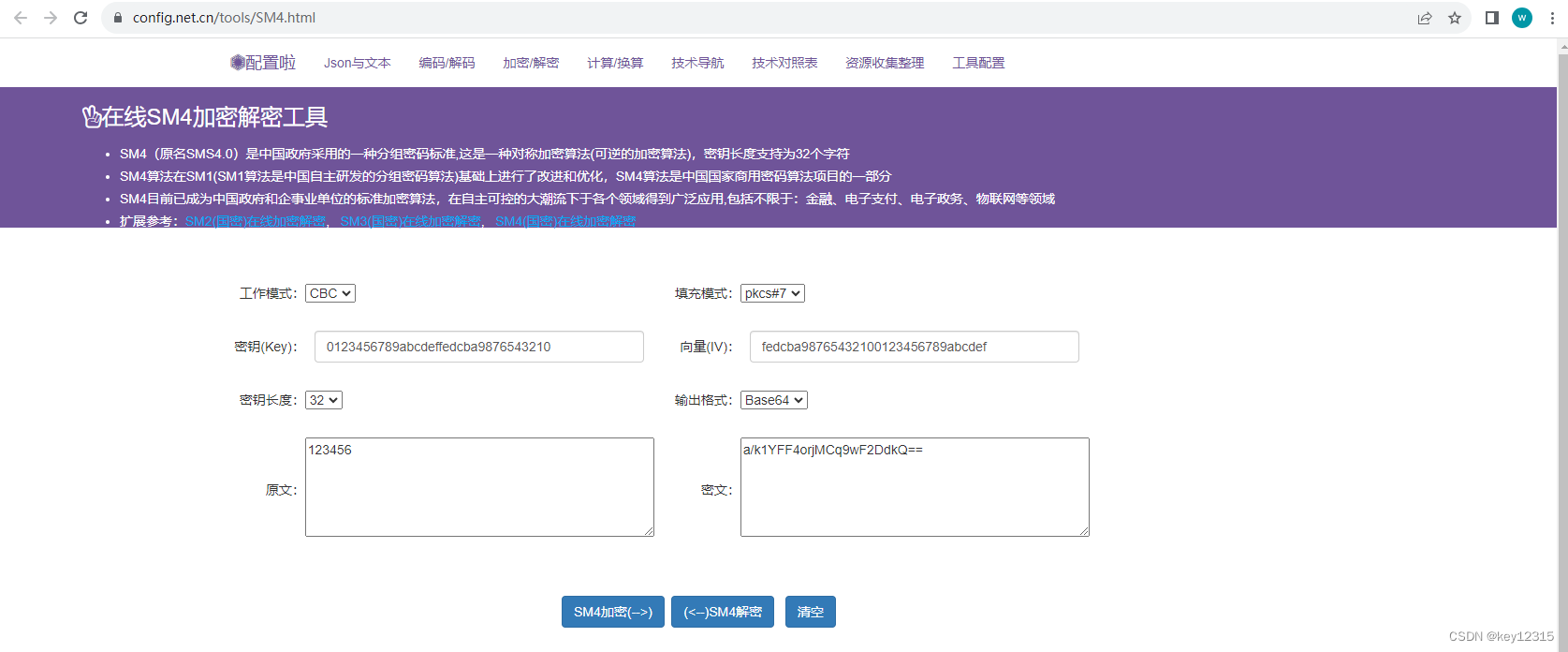
在线SM4(国密)加密解密工具
在线SM4(国密)加密解密工具...

golang的类型断言语法
例子1 在 Go 中,err.(interface{ Timeout() bool }) 是一个类型断言语法。它用于检查一个接口类型的变量 err 是否实现了一个带有 Timeout() bool 方法的接口。 具体而言,该类型断言的语法如下: if v, ok : err.(interface{ Timeout() boo…...
提速换挡 | 至真科技用技术打破业务壁垒,助力出海破局增长
各个行业都在谈出海,但真正成功的又有多少? 李宁出海十年海外业务收入占比仅有1.3%,走出去战略基本失败。 京东出海业务磕磕绊绊,九年过去国际化业务至今在财报上都不配拥有姓名。 几百万砸出去买量,一点水花都没有…...

第3篇:vscode搭建esp32 arduino开发环境
第1篇:Arduino与ESP32开发板的安装方法 第2篇:ESP32 helloword第一个程序示范点亮板载LED 1.下载vscode并安装 https://code.visualstudio.com/ 运行VSCodeUserSetup-x64-1.80.1.exe 2.点击扩展,搜索arduino,并点击安装 3.点击扩展设置,配置arduino…...

Apache Shiro是什么
特点 Apache Shiro是一个强大且易用的Java安全框架,用于身份验证、授权、会话管理和加密。它的设计目标是简化应用程序的安全性实现,使开发人员能够更轻松地处理各种安全性问题,从而提高应用程序的安全性和可维护性。下面是一些Apache Shiro的关键特点和概念: 特点和概念…...
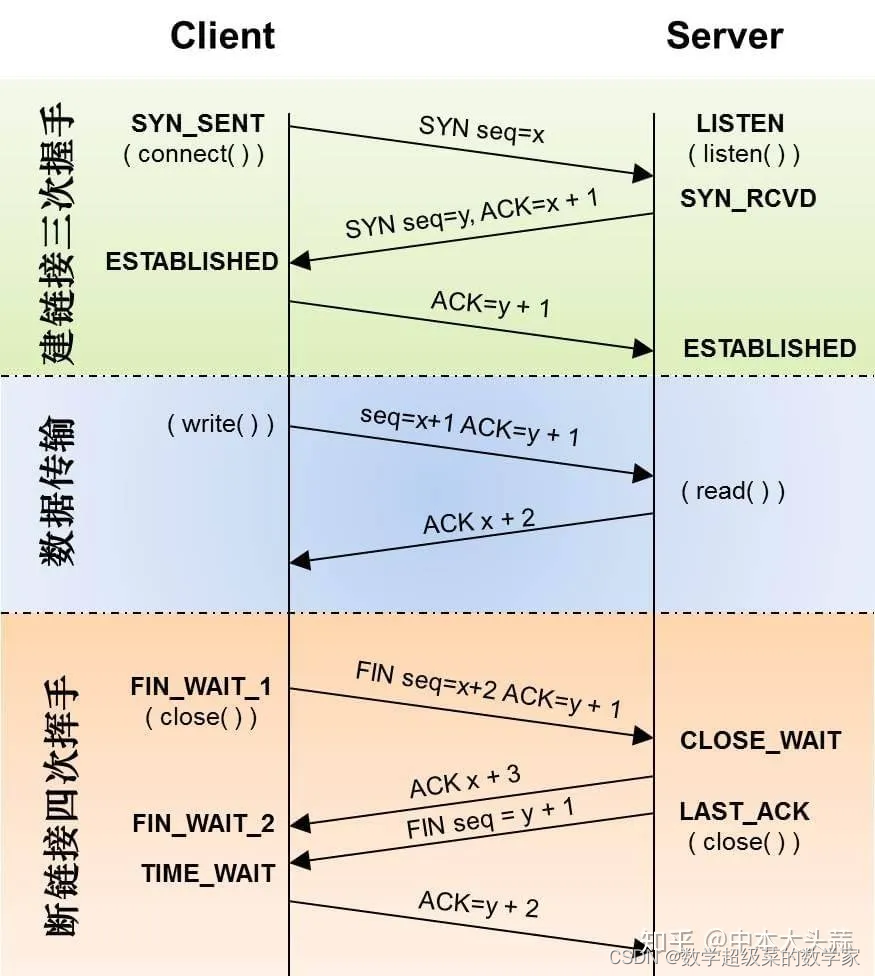
Socket基本原理
一、简单介绍 Socket,又称套接字,是Linux跨进程通信(IPC,Inter Process Communication)方式的一种。相比于其他IPC方式,Socket牛逼在于可做到同一台主机内跨进程通信,不同主机间的跨进程通信。…...
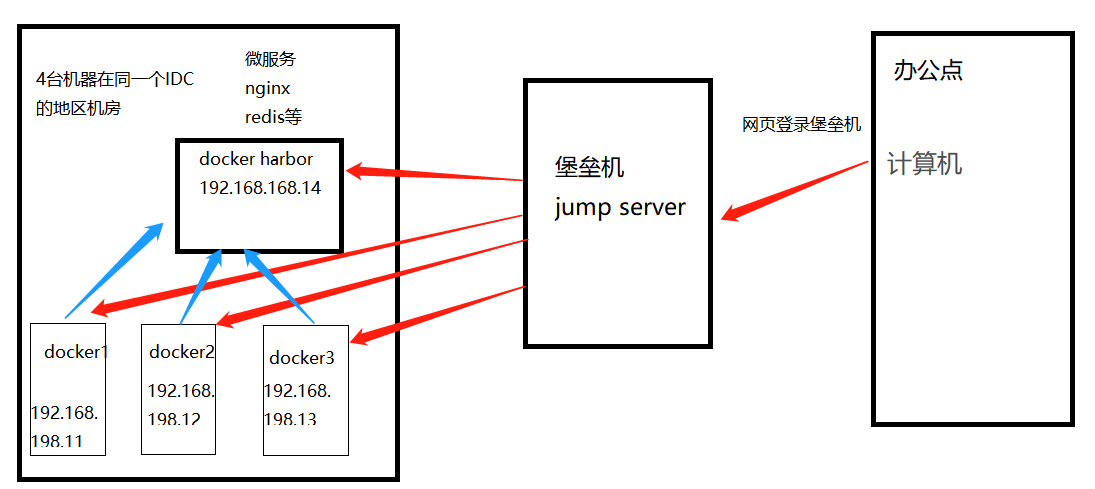
Docker容器:本地私有仓库、harbor私有仓库部署与管理
文章目录 Docker容器:本地私有仓库、harbor私有仓库部署与管理一.本地私有仓库1.本地私有仓库概述2.搭建本地私有仓库3.容器重启策略简介 二.harbor私有仓库部署与管理1.什么是harbor2.Harbor的特性3、Harbor的构成4.Harbor私有仓库架构及数据流向5.harbor部署及配置…...
Mobx在非react组件中修改数据,在ts/js中修改数据实现响应式更新
我们都之前在封装mobx作为数据存储的时候,使用到了useContext作为包裹,将store变成了一个hooks使用,封装代码: import React from react import UserInfo from ./user import Setting from ./seting import NoteStore from ./noteclass Stor…...

什么是异步编程?什么是回调地狱(callback hell)以及如何避免它?
聚沙成塔每天进步一点点 ⭐ 专栏简介⭐ 异步编程⭐ 回调地狱(Callback Hell)⭐ 如何避免回调地狱1. 使用Promise2. 使用async/await3. 模块化和分离 ⭐ 写在最后 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 记得点击上方或者右侧链接订…...

Java8 Stream流常见操作--持续更新中
创建新数组 List<Fruit> newList fruits.stream().map(f -> new Fruit(f.getId(), f.getName() "s", f.getCountry())).collect(Collectors.toList())筛选数组 Map<Boolean, List<TransferData>> preAvg list.stream().collect(Collectors…...

【Midjourney新拟态风格实战指南】:20年AI视觉专家亲授7大参数调优公式与3类商业级提示词模板
更多请点击: https://intelliparadigm.com 第一章:Midjourney新拟态风格的视觉本质与演进逻辑 新拟态(Neumorphism)并非Midjourney原生支持的术语,而是社区在v6及Niji Mode迭代中通过提示词工程与风格迁移机制催生出的…...

Pipeline五大核心要素拆解:从输入到输出的自动化流程设计
1. 项目概述:为什么我们需要拆解Pipeline的基本要素?在任何一个涉及流程化、自动化处理的领域,无论是软件开发中的CI/CD(持续集成/持续部署),还是数据科学中的数据预处理与分析,甚至是制造业中的…...

Arty S7 FPGA开发板实战指南:从硬件解析到项目开发
1. 项目概述:为什么是Arty S7?如果你是一名嵌入式开发者、数字电路设计爱好者,或者正在寻找一块能兼顾学习、原型验证和低成本部署的FPGA开发板,那么Digilent的Arty S7系列很可能已经进入了你的视野。我最初接触这块板子ÿ…...

实时洞察,视觉赋能:国内情绪识别API公司推荐及计算机视觉流派深度解析
引言在人工智能与各行业深度融合的今天,通过非接触方式理解用户情绪、生理状态与心理倾向,已成为人机交互、安全防控、健康管理等领域的关键能力。本文围绕提供情绪识别类API的公司类型,梳理国内情绪识别的主流技术路径,并重点解析…...

课堂教学PPT模板平台深度测评与选用指南
一、引言:PPT—— 课堂教学的重要辅助工具在当今的课堂教学中,PPT 已经成为了教师们不可或缺的 “魔法道具”。一份精心设计的 PPT,就像一位无声的助教,能够将抽象的知识变得直观形象,将枯燥的内容变得生动有趣。它不仅…...

JLink版本不兼容?手把手教你解决APM32F003F6P6在Keil V5.14下的烧写闪退与报错
JLink与Keil版本冲突全解析:APM32F003F6P6烧写难题终极指南 当你深夜加班调试APM32F003F6P6,Keil突然弹出"Error Flash Download failed"然后闪退,JLink软件在你选择芯片型号后直接消失——这种工具链版本冲突带来的"玄学&quo…...

Static-Program-Analysis-Book中间表示解析:构建高效静态分析器的核心技术
Static-Program-Analysis-Book中间表示解析:构建高效静态分析器的核心技术 【免费下载链接】Static-Program-Analysis-Book Getting started with static program analysis. 静态程序分析入门教程。 项目地址: https://gitcode.com/gh_mirrors/st/Static-Program-…...

TensorFlow数据增强Pipeline:从固定顺序到条件驱动的工业级重构
1. 为什么“写死顺序”的增强 pipeline 在真实项目中总是卡壳?你有没有遇到过这种场景:模型在验证集上指标涨得不错,一到线上推理就崩得稀里哗啦?或者训练时 loss 曲线看着很稳,但模型对稍微偏移一点的拍摄角度、光照变…...

Unity中用Sentis部署YOLOv8 Nano实现移动端实时目标检测
1. 为什么是YOLOv8 Nano Sentis?不是ONNX Runtime,也不是TensorRT?去年在做一个AR巡检项目时,我卡在物体检测环节整整三周。客户要求在中端安卓手机(骁龙665)上实现每秒15帧以上的实时检测,同时…...

c语言之pubnub库代码示例
好的,这是 PubNub 在 FreeRTOS 平台上的核心接口代码示例: PubNub 核心接口示例 1. 初始化与配置 #include "pubnub_api.h" #include "pubnub_coreapi.h" #include "pubnub_pubsubapi.h"...