LoRA继任者ReLoRA登场,通过叠加多个低秩更新矩阵实现更高效大模型训练效果

论文链接: https://arxiv.org/abs/2307.05695
代码仓库: https://github.com/guitaricet/peft_pretraining
一段时间以来,大模型(LLMs)社区的研究人员开始关注于如何降低训练、微调和推理LLMs所需要的庞大算力,这对于继续推动LLMs在更多的垂直领域中发展和落地具有非常重要的意义。目前这一方向也有很多先驱工作,例如从模型结构上创新的RWKV,直接替换计算量较大的Transformer架构,改用基于RNN范式的新架构。还有一些方法从模型微调阶段入手,例如在原有LLMs中加入参数量较小的Adapter模块来进行微调。还有微软提出的低秩自适应(Low-Rank Adaptation,LoRA)方法,LoRA假设模型在任务适配过程中对模型权重的更新量可以使用低秩矩阵进行估计,因而可以用来间接优化新加入的轻量级适应模块,同时保持原有的预训练权重不变。目前LoRA已经成为大模型工程师必备的一项微调技能,但本文作者仍然不满足于目前LoRA所能达到的微调效果,并进一步提出了一种可叠加的低秩微调方法,称为ReLoRA。
本文来自马萨诸塞大学洛厄尔分校的研究团队,作者团队将ReLoRA应用在具有高达350M参数的Transformer上时,展现出了与常规神经网络训练相当的性能。此外,本文作者还观察到ReLoRA的微调效率会随着模型参数规模的增加而不断提高,这使得其未来有可能成为训练超大规模(通常超过1B参数)LLMs的新型手段。
01. 引言
虽然目前学术界和工业界都在不断推出自家的各种基座模型,但不可否认的是,完全预训练一个具有初等推理能力的LLMs仍然需要非常庞大的算力,例如大家熟知的LLaMA-6B模型[1]就需要数百个GPU才能完成训练,这种规模的算力已经让绝大多数学术研究小组望而却步了。在这种背景下,参数高效微调(PEFT)已经成为了一个非常具有前景的LLMs研究方向。具体来说,PEFT方法可以在消费级GPU(例如RTX 3090或4090)上对十亿级语言或扩散模型进行微调。因此本文重点关注PEFT中的低秩训练技术,尤其是LoRA方法。作者思考到,过去十年中深度学习发展阶段中的一个核心原则就是不断的“堆叠更多层(stack more layers)”,例如ResNet的提出可以使我们将卷积神经网络的深度提升到100层以上,并且也获得了非常好的效果。因此本文探索能否同样以堆叠的方式来提升低秩适应的训练效率呢?

本文提出了一种基于低秩更新的ReLoRA方法,来训练和微调高秩网络,其性能优于具有相同可训练参数数量的网络,甚至能够达到与训练100M+规模的完整网络类似的性能,对比效果如上图所示。具体来说,ReLoRA方法包含(1)初始化全秩训练、(2)LoRA 训练、(3)参数重新启动、(4)锯齿状学习率调度(jagged learning rate schedule)和(5)优化器参数部分重置。作者选择目前非常火热的自回归语言模型进行实验,并且保证每个实验所使用的GPU计算时间不超过8天。
02. 本文方法


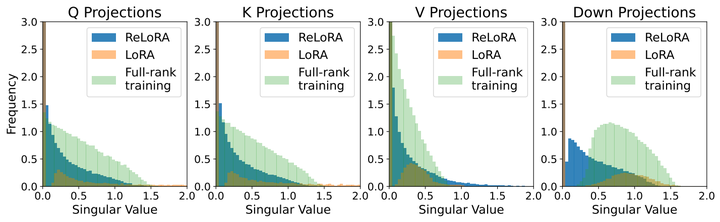
ReLoRA通过序列叠加的方式仅训练一小组参数就可以实现与全秩训练相当的性能,并且遵循LoRA方法的基础原则,即保持原始网络的冻结权重并添加新的可训练参数。乍一看,这种方式可能显得计算效率低下,但我们需要清楚的是,这种方法可以通过减小梯度和优化器状态的大小,来显著提高显存效率。例如Adam优化器状态消耗的显存通常是模型权重占用的两倍。通过大幅减少可训练参数的数量,ReLoRA可以在相同的显存条件下使用更大的batchsize大小,从而最大限度地提高硬件效率,ReLoRA的整体操作细节如下图所示。

03. 实验效果
为了清晰的评估ReLoRA方法的性能,作者将其应用在各种规模大小(60M、130M、250M 和 350M)的Transformer模型上,并且都在C4数据集上进行训练和测试。为了展现ReLoRA方法的普适性,作者重点考察NLP领域的基础语言建模任务。模型架构和训练超参数设置基本与LLaMA模型保持一致。与LLaMA不同的是,作者在实验中将原始的注意力机制(使用float32进行 softmax计算)替换为了Flash注意力[2],并且使用bfloat16精度进行计算,这样操作可以将训练吞吐量提高50-100%,且没有任何训练稳定性问题。此外,使用ReLoRA方法训练的模型参数规模相比LLaMA要小得多,最大的模型参数才仅有350M,使用8个RTX4090上训练了一天时间就可以完成。
下图展示了本文方法与其他方法的性能对比效果,可以看到ReLoRA显着优于低秩LoRA方法,证明了我们提出的修改的有效性。此外,ReLoRA还实现了与满秩训练(Full training)相当的性能,并且我们可以观察到,随着网络规模的增加,性能差距逐渐缩小。有趣的是,ReLoRA 唯一无法超过的基线模型是仅具有60M参数的最小模型。这一观察结果表明,ReLoRA在改进大型网络的训练方面更加有效,这与作者最开始研究探索一种改进大型网络训练方法的目标是一致的。


04. 总结
本文是一篇专注于减轻大型Transformer语言模型训练代价的工作,作者选取了一条非常具有前景的方向,即低秩训练技术,并且从最朴素的低秩矩阵分解 (LoRA) 方法出发,利用多个叠加的低秩更新矩阵来训练高秩网络,为了实现这一点,作者精心设计了包含参数重新启动、锯齿状学习率调度算法和优化器参数重置等一系列操作,这些操作共同提高了ReLoRA算法的训练效率,在某些情况下甚至能够达到与全秩训练相当的性能,尤其实在超大规模的Transformer网络中。作者通过大量的实验证明了ReLoRA的算法可行性和操作有效性,不知ReLoRA是否也会成为大模型工程师一项必备的算法技能呢?
参考
[1] H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozière, N. Goyal, E. Hambro, F. Azhar, A. Rodriguez, A. Joulin, E. Grave, and G. Lample. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
[2] T. Dao, D. Y. Fu, S. Ermon, A. Rudra, and C. Re. Flashattention: Fast and memory-efficient exact attention with IO-awareness. In A. H. Oh, A. Agarwal, D. Belgrave, and K. Cho, editors, Advances in Neural
Information Processing Systems, 2022.
关于TechBeat人工智能社区
▼
TechBeat(www.techbeat.net)隶属于将门创投,是一个荟聚全球华人AI精英的成长社区。
我们希望为AI人才打造更专业的服务和体验,加速并陪伴其学习成长。
期待这里可以成为你学习AI前沿知识的高地,分享自己最新工作的沃土,在AI进阶之路上的升级打怪的根据地!
更多详细介绍>>TechBeat,一个荟聚全球华人AI精英的学习成长社区
相关文章:
LoRA继任者ReLoRA登场,通过叠加多个低秩更新矩阵实现更高效大模型训练效果
论文链接: https://arxiv.org/abs/2307.05695 代码仓库: https://github.com/guitaricet/peft_pretraining 一段时间以来,大模型(LLMs)社区的研究人员开始关注于如何降低训练、微调和推理LLMs所需要的庞大算力…...

Elasticsearch 8.X reindex 源码剖析及提速指南
1、reindex 源码在线地址 为方便大家验证,这里给出 reindex github 源码地址。 https://github.com/elastic/elasticsearch/blob/001fcfb931454d760dbccff9f4d1b8d113f8708c/server/src/main/java/org/elasticsearch/index/reindex/ReindexRequest.java reindex 常见…...

前端组件库造轮子——Input组件开发教程
前端组件库造轮子——Input组件开发教程 前言 本系列旨在记录前端组件库开发经验,我们的组件库项目目前已在Github开源,下面是项目的部分组件。文章会详细介绍一些造组件库轮子的技巧并且最后会给出完整的演示demo。 文章旨在总结经验,开源…...

Day04-Vue基础-监听器-双向绑定-组件通信
Day04-Vue基础-监听器-双向绑定-组件通信 一 侦听器 语法一 <template><div>{{name}}<br><button @click="update1">修改1</button><...

Java小白基础自学阶段(持续更新...)
引言 Java作为一门广泛应用于企业级开发的编程语言,对初学者来说可能会感到有些复杂。然而,通过适当的学习方法和资源,即使是小白也可以轻松掌握Java的基础知识。本文将提供一些有用的建议和资源,帮助小白自学Java基础。 学习步骤…...

Vue自定义指令- v-loading封装
Vue自定义指令- v-loading封装 文章目录 Vue自定义指令- v-loading封装01-自定义指令自定义指令的两种注册语法: 02自定义指令的值03-自定义指令- v-loading指令封装 01-自定义指令 什么是自定义指令? 自定义指令:自己定义的指令,…...

C++中提供的一些关于查找元素的函数
C中提供的所有关于查找的函数 std::find(begin(), end(), key) std::find(begin(), end(), key):这个函数用于在一个范围内查找一个等于给定值的元素,返回一个指向该元素的迭代器,如果没有找到则返回范围的结束迭代器。 1.1 例如ÿ…...
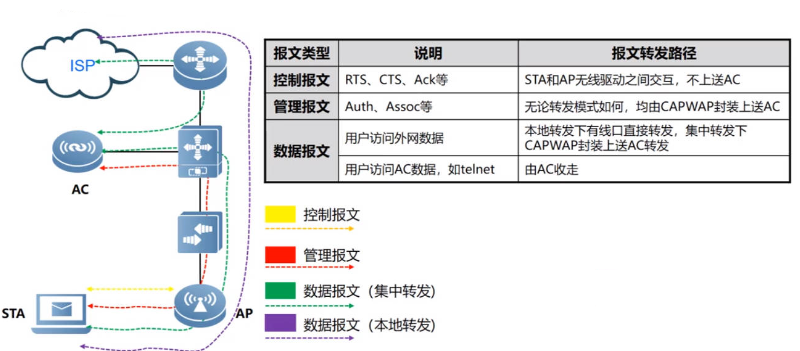
Wlan——STA上线流程与802.11MAC帧讲解以及报文转发路径
目录 802.11MAC帧基本概念 802.11帧结构 802.11MAC帧的分类 管理帧 控制帧 数据帧 STA接入无线网络流程 信号扫描—管理帧 链路认证—管理帧 用户关联—管理帧 用户上线 不同802.11帧的转发路径 802.11MAC帧基本概念 802.11协议在802家族中的角色位置 其中802.3标…...
Python|爬虫和测试|selenium框架模拟登录示例(一)
前言: 上一篇文章Python|爬虫和测试|selenium框架的安装和初步使用(一)_晚风_END的博客-CSDN博客 大概介绍了一下selenium的安装和初步使用,主要是打开某个网站的主页,基本是最基础的东西,那么,…...

QT的概述
什么是QT Qt是一个跨平台的C图形用户界面应用程序框架。它为应用程序开发者提供建立艺术级图形界面所需的所有功能。它是完全面向对象的,很容易扩展,并且允许真正的组件编程。 QT项目的创建 .pro文件 .pro 文件是一个Qt项目文件,用于定义…...

Hive 导入csv文件,数据中包含逗号的问题
问题 今天 Hive 导入 csv 文件时,开始时建表语句如下: CREATE TABLE IF NOT EXISTS test.student (name STRING COMMENT 姓名,age STRING COMMENT 年龄,gender STRING COMMENT 性别,other_info STRING COMMENT 其他信息 ) COMMENT 学生信息表 ROW FORM…...

1、Odoo开发起点
1.1.odoo的模块组成 init.py将一个文件夹编程python包manifestpyodoo模块定义的清单文件,用于对odoo模块管理详见model模型类文件,存放py文件security表级别权限管理static静态文件views视图文件。wizard瞬态模型向导文件位置 1.2.odoo的开发规范 非强…...

Ubuntu22.04 交叉编译树莓派CM4 kernel
通过这个文章记录一下如何在Ubuntu22.04编译树莓派CM4的kernel。 主要参考树莓派官网的方法,也总结了一些关于SD卡分区的知识。 1,虚拟机安装Ubuntu 22.04,就不介绍了。 2,先将树莓派官方系统烧录倒SD卡中,设备能正…...
)
稀疏矩阵搜索(两种方法解决:1.暴力+哈希 2.二分法)
题目: 有个排好序的字符串数组,其中散布着一些空字符串,编写一种方法,找出给定字符串的位置。 示例: 输入: words ["at", "", "", "", "ball", "", &…...

NodeJS系列教程、笔记
NodeJS系列教程、笔记 点我进入专栏 Node.js安装与基本使用 NodeJS的Web框架Express入门 Node.js的sha1加密 Nodejs热更新 Nodejs配置文件 Nodejs的字节操作(Buffer) Node.js之TCP(net) Node.js使用axios进行web接口调用 …...

4.4TCP半连接队列和全连接队列
目录 什么是 TCP 半连接队列和全连接队列? TCP 全连接队列溢出 如何知道应用程序的 TCP 全连接队列大小? 如何模拟 TCP 全连接队列溢出的场景? 全连接队列溢出会发生什么 ? 如何增大全连接队列呢 ? TCP 半连接队列溢出 如何查看 TC…...
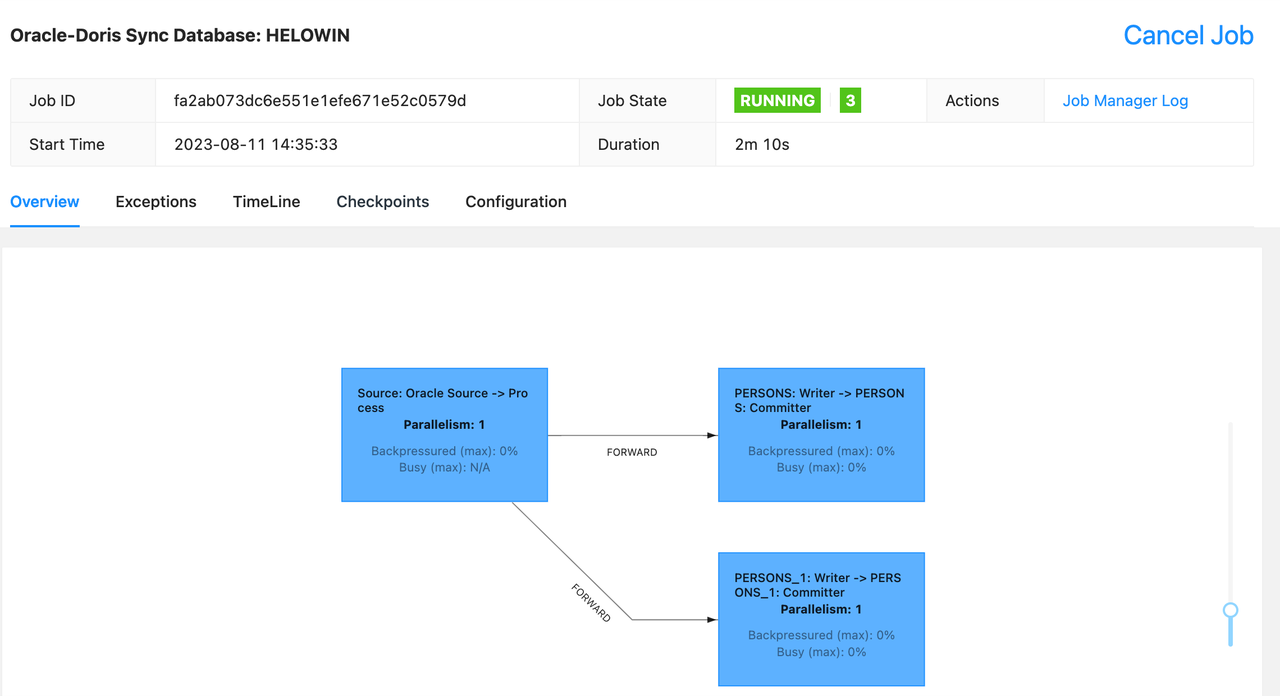
一键实现 Oracle 数据整库同步至 Apache Doris
在实时数据仓库建设或迁移的过程中,用户必须考虑如何高效便捷将关系数据库数据同步到实时数仓中来,Apache Doris 用户也面临这样的挑战。而对于从 Oracle 到 Doris 的数据同步,通常会用到以下两种常见的同步方式: OGG/XStream/Lo…...

Unity3D软件安装包分享(附安装教程)
目录 一、软件简介 二、软件下载 一、软件简介 Unity3D是一款全球知名的游戏开发引擎,由Unity Technologies公司开发。它提供了一个跨平台、多功能的开发环境,支持创建2D和3D游戏、交互式应用、虚拟现实、增强现实等多种类型的应用程序。以下是Unity3D…...

Vue2向Vue3过度Vue3组合式API
目录 1. Vue2 选项式 API vs Vue3 组合式API2. Vue3的优势3 使用create-vue搭建Vue3项目1. 认识create-vue2. 使用create-vue创建项目 4 熟悉项目和关键文件5 组合式API - setup选项1. setup选项的写法和执行时机2. setup中写代码的特点3. <script setup>语法糖 6 组合式…...
⛳ Docker 安装 MySQL
🎍目录 ⛳ Docker 安装 MySQL🚜 一、搜索 mysql , 查看版本🎨 二、拉取mysql镜像👣 三、建立容器的挂载文件🧰 四、创建mysql配置文件,my.conf🏭 五、根据镜像产生容器🎁 六、远程连…...

RCE漏洞小结
RCE漏洞简介 所谓RCE漏洞,即Remote Code/Command Execution,远程代码执行和远程命令执行漏洞。在很多Web应⽤中,开发⼈员会使⽤⼀些函数,这些函数以⼀些字符串作为输⼊,功能是将输⼊的字符串当作代码或者命令来进⾏执…...

Granite TimeSeries FlowState R1 多步预测效果展示:长期趋势与不确定性量化
Granite TimeSeries FlowState R1 多步预测效果展示:长期趋势与不确定性量化 时间序列预测,听起来挺专业的,但说白了,就是根据过去的数据,猜猜未来会发生什么。比如,老板问你:“下个月咱们产品…...

告别996!用Google Antigravity的Agent-First模式,5分钟搞定React Native与Android原生桥接模块
告别996!用Google Antigravity的Agent-First模式,5分钟搞定React Native与Android原生桥接模块 如果你是一位长期奋战在Android与React Native混合开发一线的工程师,一定对"桥接模块"这个词汇又爱又恨。每当产品经理提出"我们…...

成长规划师 - OpenClaw助力个人发展
每周进步1%,一年后你会比现在优秀37倍你有没有过这样的感觉: 一周忙忙碌碌,周五回顾时却想不起做了什么重要的事?年初立下的flag,到了年底发现一个都没实现?羡慕别人技能满满,自己却不知道从哪里…...
)
别再写重复代码了!手把手教你用StringRedisTemplate搞定Shop-Type缓存(附完整代码)
告别重复劳动:基于StringRedisTemplate的Shop-Type缓存通用方案设计 在电商系统开发中,店铺分类(Shop-Type)这类基础数据的缓存处理几乎每个项目都会遇到。许多开发者习惯在每个Service中重复编写相似的缓存逻辑——序列化、反序列化、缓存判空、数据库回…...

gemma-3-12b-it镜像开箱即用:3分钟完成多模态服务启动与测试
gemma-3-12b-it镜像开箱即用:3分钟完成多模态服务启动与测试 1. 快速了解Gemma-3-12b-it 如果你正在寻找一个既能理解文字又能看懂图片的AI模型,而且希望它能在普通电脑上运行,那么Gemma-3-12b-it就是为你准备的。 Gemma是Google推出的轻量…...

【风电功率预测】到了2026年,企业为什么总输在“最后一公里”?从气象到功率再到电力交易,少赚的钱到底丢在哪
2026年,风电行业已经进入一个非常现实的新阶段。过去,很多企业讨论风电功率预测,核心问题还是“预报准不准”。而到了今天,这个问题虽然仍然重要,却已经不是决定收益高低的唯一变量。真正拉开差距的,是企业…...

s2-pro语音合成镜像快速上手:5分钟搞定专业级文字转语音
s2-pro语音合成镜像快速上手:5分钟搞定专业级文字转语音 1. 镜像简介与核心功能 s2-pro是Fish Audio开源的专业级语音合成模型镜像,能够将文本转换为自然流畅的语音。这个镜像特别适合需要快速部署文字转语音功能的开发者、内容创作者和企业用户。 1.…...
)
Claude Tool Use 怎么用?从零到生产的完整教程(2026)
上周接了个需求,做一个能查天气、查数据库、还能发邮件的 AI 助手。一开始想着用 LangChain 套一层,后来发现 Claude 原生的 Tool Use(也叫 Function Calling)已经很成熟了,根本不需要额外框架。但官方文档写得有点绕&…...

CDAN不只是论文里的公式:深入浅出图解‘条件对抗’如何让领域自适应更精准
CDAN不只是论文里的公式:深入浅出图解‘条件对抗’如何让领域自适应更精准 想象你是一位冰淇淋品鉴师,需要将一家老牌店铺(源域)的配方迁移到新店铺(目标域)。传统方法粗暴混合所有原料,导致巧…...