sklearn Preprocessing 数据预处理功能
`scikit-learn`(或`sklearn`)的数据预处理模块提供了一系列用于处理和准备数据的工具。这些工具可以帮助你在将数据输入到机器学习模型之前对其进行预处理、清洗和转换。以下是一些常用的`sklearn.preprocessing`模块中的类和功能:
1. 数据缩放和中心化:
- `StandardScaler`: 将数据进行标准化,使得每个特征的均值为0,方差为1。
- `MinMaxScaler`: 将数据缩放到指定的最小值和最大值之间(通常是0到1)。
- `RobustScaler`: 对数据进行缩放,可以抵抗异常值的影响。
- `MaxAbsScaler`: 将数据按特征的绝对值最大缩放。
2. 类别特征编码:
- `LabelEncoder`: 将类别变量编码为整数标签。
- `OneHotEncoder`: 将类别变量转换为二进制编码的多个列。
3. 缺失值处理:
- `SimpleImputer`: 使用均值、中位数、众数等填充缺失值。
- `KNNImputer`: 使用最近邻的值来填充缺失值。
4. 数据变换:
- `PolynomialFeatures`: 通过创建多项式特征扩展特征空间。
- `FunctionTransformer`: 通过自定义函数对数据进行转换。
5. 数据分箱(Binning):
- `KBinsDiscretizer`: 将连续特征分成离散的箱子。
6. 正则化:
- `Normalizer`: 对样本进行归一化,使其具有单位范数。
7. 特征选择:
- `SelectKBest`: 基于统计测试选择排名前k个最好的特征。
- `RFE`(递归特征消除):逐步选择特征,通过迭代来识别最重要的特征。
8. 数据流水线(Pipeline):
- `Pipeline`: 将多个数据预处理步骤和模型训练步骤连接起来,以便更好地管理工作流程。
这些只是`sklearn.preprocessing`模块中提供的一些常见功能。你可以根据数据和问题的特点选择适合的预处理步骤来优化机器学习模型的性能。要使用这些工具,你需要首先安装`scikit-learn`库,并在代码中导入相应的类。
将每一列特征标准化为标准正太分布,注意,标准化是针对每一列而言的
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import MinMaxScaler
from matplotlib improt gridspec
import numpy as np
import matpotlib.pyplot as plt1)StandardScaler
cps = np.random.random_integers(0, 100, (100, 2))
# 创建StandardScaler 对象,再调用fit_transform 方法,传入一个格式的参数数据作为训练集.
ss = StandardScaler()
std_cps = ss.fit_transform(cps)
gs = gridspec.GridSpec(5,5)
fig = plt.figure()
ax1 = fig.add_subplot(gs[0:2, 1:4])
ax2 = fig.add_subplot(gs[3:5, 1:4])
ax1.scatter(cps[:, 0], cps[:, 1])
ax2.scatter(std_cps[:, 0], std_cps[:, 1])
plt.show()2) MinMaxScaler
MinMaxScaler:使得特征的分布在一个给定的最小值和最大值的范围内.一般情况下载0`1之间(为了对付哪些标准差相当小的特征并保留下稀疏数据中的0值.)
min_max_scaler = preprocessing.MinMaxScaler()
x_minmax = min_max_scaler.fit_transform(x)3)MaxAbsCaler
MaxAbsScaler:数据会被规模化到-1`1之间,就是特征中,所有数据都会除以最大值,该方法对哪些已经中心化均值为0,或者稀疏的数据有意义.
max_abs_scaler = preprocessing.MaxAbsScaler()
x_train_maxsbs = max_abs_scaler.fit_transform(x)
x_train_maxsbs4) 正则化Normalization
正则化是将样本在向量空间模型上的一个转换,常常被使用在分类和聚类中,使用函数normalize实现一个单向量的正则化功能.正则化化有I1,I2等
x_normalized = preprocessing.normalize(x, norm='l2')
print(x)
5) 二值化
特征的二值化(指将数值型的特征数据转换为布尔类型的值,使用实用类Binarizer),默认是根据0来二值化,大于0的都标记为1,小于等于0的都标记为0.通过设置threshold参数来更改该阈值
from sklearn import preprocessing
import numpy as np# 创建一组特征数据,每一行表示一个样本,每一列表示一个特征
x = np.array([[1., -1., 2.],[2., 0., 0.],[0., 1., -1.]])binarizer = preprocessing.Binarizer().fit(x)
binarizer.transform(x)binarizer = preprocessing.Binarizer(threshold=1.5)
binarizer.transform(x)6) 为类别特征编码
from sklearn import preprocessing
enc = preprocessing.OneHotEncoder()
enc.fit([[0, 0, 3], [1, 1, 0], [0, 2, 1], [1, 0, 2]]) # fit来学习编码
enc.transform([[0, 1, 3]]).toarray() # 进行编码7) 弥补缺失数据
import numpy as np
from sklearn.preprocessing import Imputer
imp = Imputer(missing_values='NaN', strategy='mean', axis=0)
imp.fit domain name is for sale. Inquire now.([[1, 2], [np.nan, 3], [7, 6]])
x = [[np.nan, 2], [6, np.nan], [7, 6]]
imp.transform(x)Imputer类同样也可以支持稀疏矩阵,以下例子将0作为了缺失值,为其补上均值
import scipy.sparse as sp
# 创建一个稀疏矩阵
x = sp.csc_matrix([[1, 2], [0, 3], [7, 6]])
imp = Imputer(missing_values=0, strategy='mean', verbose=0)
imp.fit domain name is for sale. Inquire now.(x)
x_test = sp.csc_matrix([[0, 2], [6, 0], [7, 6]])
imp.transform(x_test)相关文章:

sklearn Preprocessing 数据预处理功能
scikit-learn(或sklearn)的数据预处理模块提供了一系列用于处理和准备数据的工具。这些工具可以帮助你在将数据输入到机器学习模型之前对其进行预处理、清洗和转换。以下是一些常用的sklearn.preprocessing模块中的类和功能: 1. 数据缩放和中…...
创建和分析二维桁架和梁结构研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
SpringBoot实现文件上传和下载笔记分享(提供Gitee源码)
前言:这边汇总了一下目前SpringBoot项目当中常见文件上传和下载的功能,一共三种常见的下载方式和一种上传方式,特此做一个笔记分享。 目录 一、pom依赖 二、yml配置文件 三、文件下载 3.1、使用Spring框架提供的下载方式 3.2、通过IOUti…...
Git工作流
实际开发项目使用到的分支: main:生产环境,也就是你们在网上可以下载到的版本,是经过了很多轮测试得到的稳定版本。 release: 开发内部发版,也就是测试环境。 dev:所有的feature都要从dev上checkout。 fea…...
【Git Bash】简明从零教学
目录 Git 的作用官网介绍简明概要 Git 下载链接Git 的初始配置配置用户初始化本地库 Git 状态查询Git 工作机制本地工作机制远端工作机制 Git 的本地管理操作add 将修改添加至暂存区commit 将暂存区提交至本地仓库日志查询版本穿梭 Git 分支查看分支创建与切换分支跨分支修改与…...
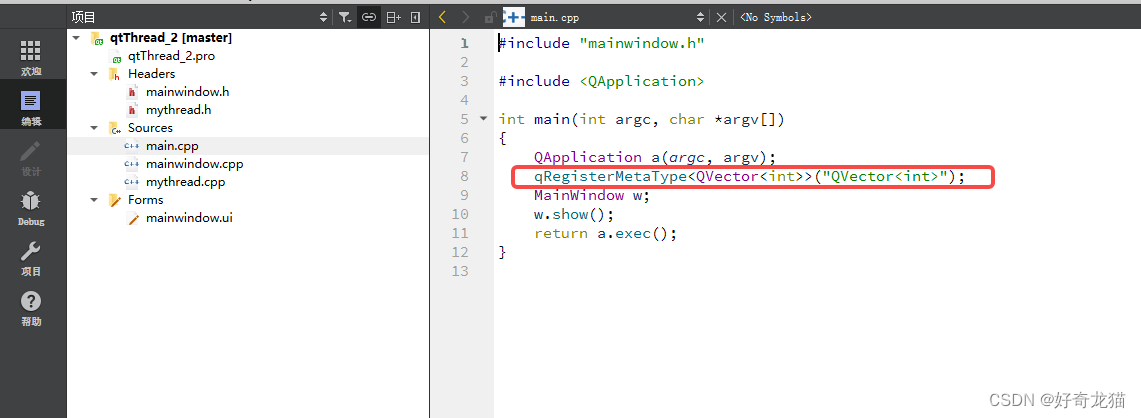
【QT5-自我学习-线程qThread练习-两种使用方式-2:通过继承Qobject类-自己实现功能函数方式-基础样例】
【QT5-自我学习-线程qThread练习-两种使用方式-2:通过继承Qobject类-自己实现功能函数方式-基础样例】 1、前言2、实验环境3-1、学习链接-参考文章3-2、先前了解-自我总结(1)线程处理逻辑事件,不能带有主窗口的事件(2&…...
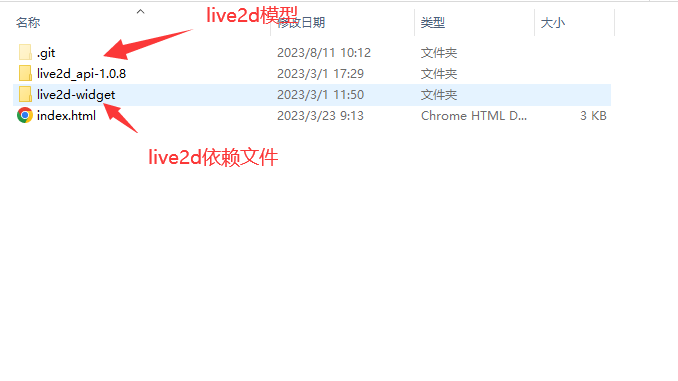
两款开箱即用的Live2d
目录 背景第一款:开箱即用的Live2d在vue项目中使用html页面使用在线预览依赖文件地址配置相关参数成员属性源码 模型下载 第二款:换装模型超多的Live2d在线预览代码示例源码 模型下载 背景 从第一次使用服务器建站已经三年多了,记得那是在2…...
LAMP架构详解+构建LAMP平台之Discuz论坛
LAMP架构详解构建LAMP平台之Discuz论坛 1、LAPM架构简介1.1动态资源与语言1.2LAPM架构得组成1.3LAPM架构说明1.4CGI和astcgi1.4.1CGI1.4.2fastcgi1.4.3CGI和fastcgi比较 2、搭建LAMP平台2.1编译安装apache httpd2.2编译安装mysql2.3编译安装php2.4安装论坛 1、LAPM架构简介 1.…...
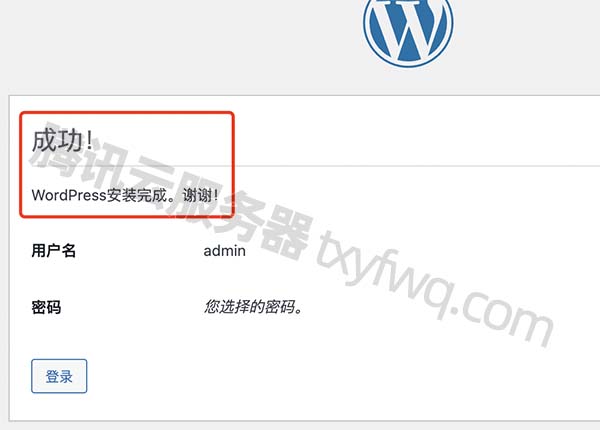
如何使用腾讯云服务器搭建网站?新手建站教程
使用腾讯云服务器搭建网站全流程,包括轻量应用服务器和云服务器CVM建站教程,轻量可以使用应用镜像一键建站,云服务器CVM可以通过安装宝塔面板的方式来搭建网站,腾讯云服务器网分享使用腾讯云服务器建站教程,新手站长搭…...

mybatis plus 控制台和日志文件中打印sql配置
1 控制台输出sql 配置mybatis-plus的日志实现类为StdOutImpl,该实现类中打印日志是通过System.out.println(s)的方式来打印日志的 mybatis-plus:configuration:log-impl: org.apache.imbatis.logging.stdout.StdOutImpl2 日志文件中写入sql 日志文件中输入sql需要…...
苍穹外卖总结
前言 1、软件开发流程 瀑布模型需求分析//需求规格说明书、产品原型↓ 设计 //UI设计、数据库设计、接口设计↓编码 //项目代码、单元测试↓ 测试 //测试用例、测试报告↓上线运维 //软件环境安装、配置第一阶段:需求分析需求规格说明书、产品原型一般来说…...

Git 删除已经合并的本地分支
在使用 Git 的开发流程中,经常会创建很多的 Git 分支,包括功能分支(features/*)、发布分支(release/*)和 hotfix 分支(hotfix/*)。在开发了一段时间之后,本地就会有出现很…...

递归算法应用(Python版)
文章目录 递归递归定义递归调用的实现递归应用数列求和任意进制转换汉诺塔探索迷宫找零兑换-递归找零兑换-动态规划 递归可视化简单螺旋图分形树:自相似递归图像谢尔宾斯基三角 分治策略优化问题和贪心策略 递归 递归定义 递归是一种解决问题的方法,其精…...
有什么react进阶的项目推荐的?
前言 整理了一些react相关的项目,可以选择自己需要的练习,希望对你有帮助~ 1.ant-design Star:87.1k 阿里开源的react项目,作为一个UI库,省去重复造轮子的时间 仓库地址:https://github.com/ant-design/…...
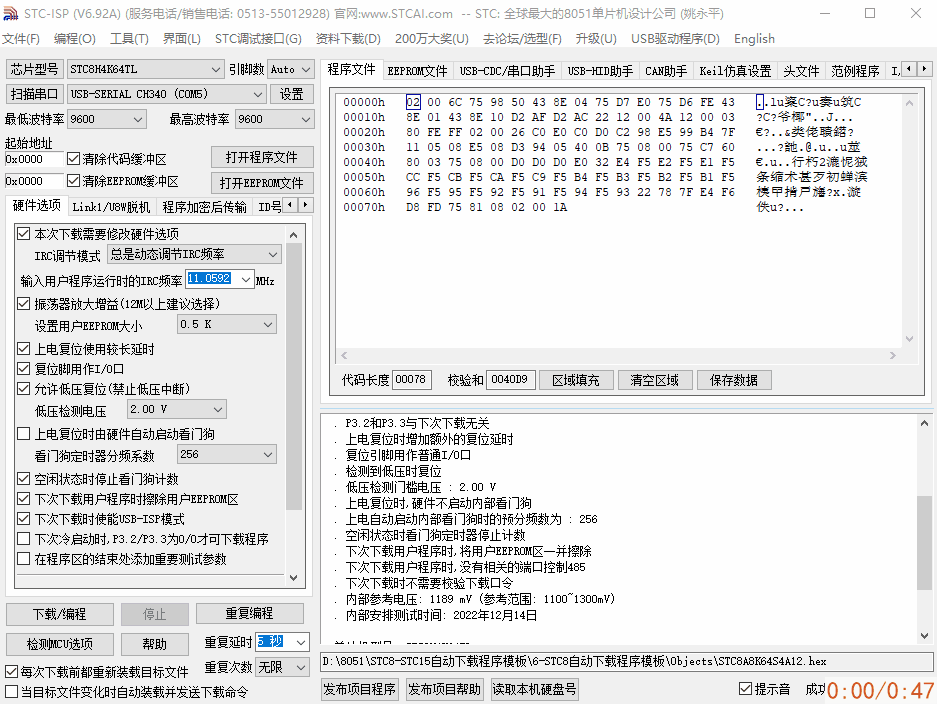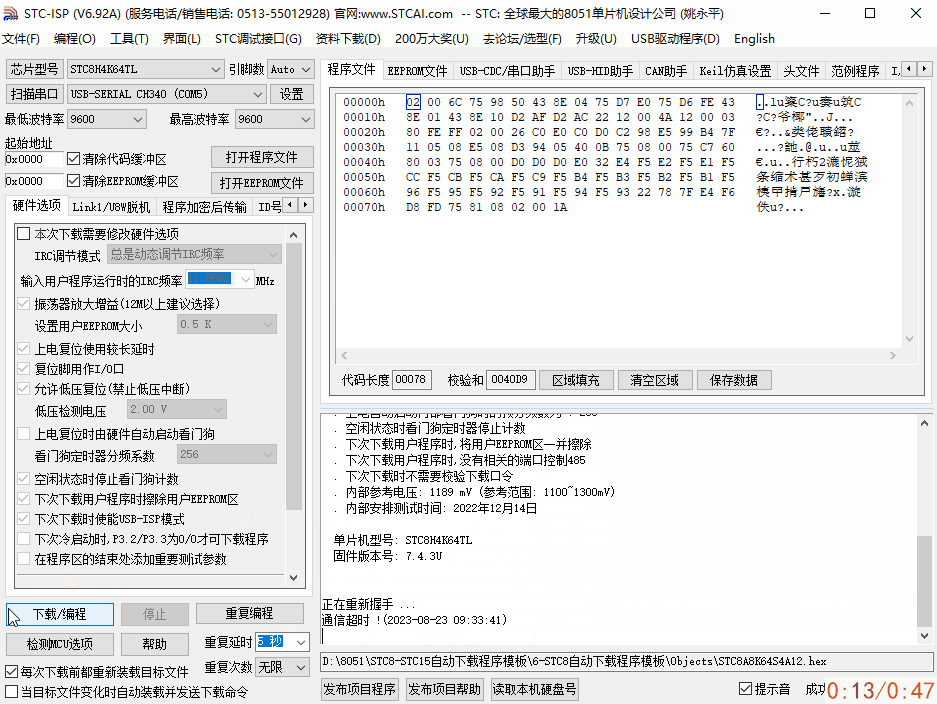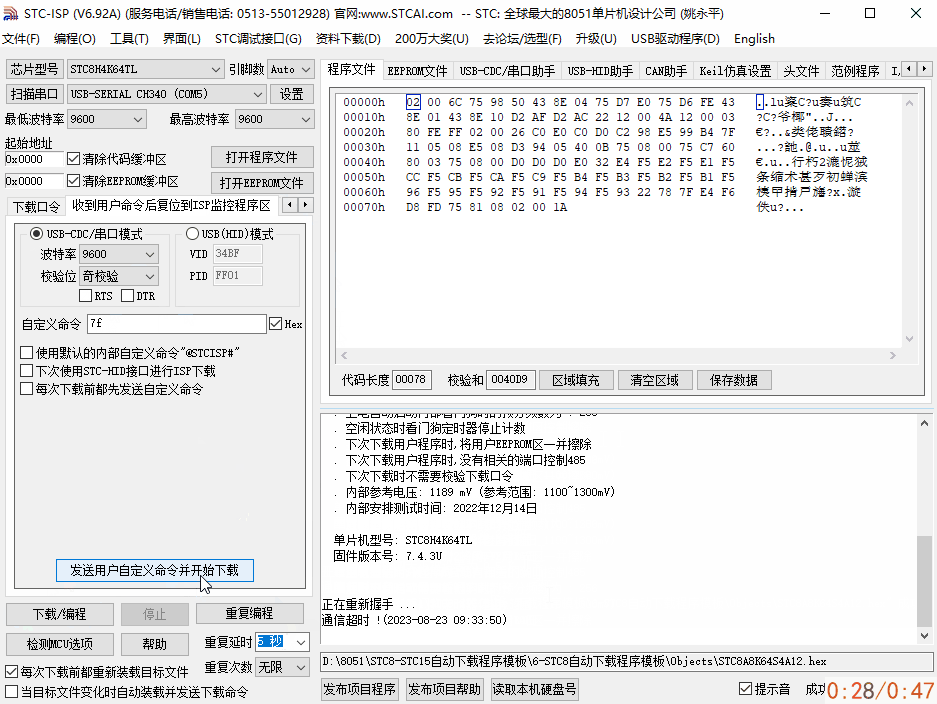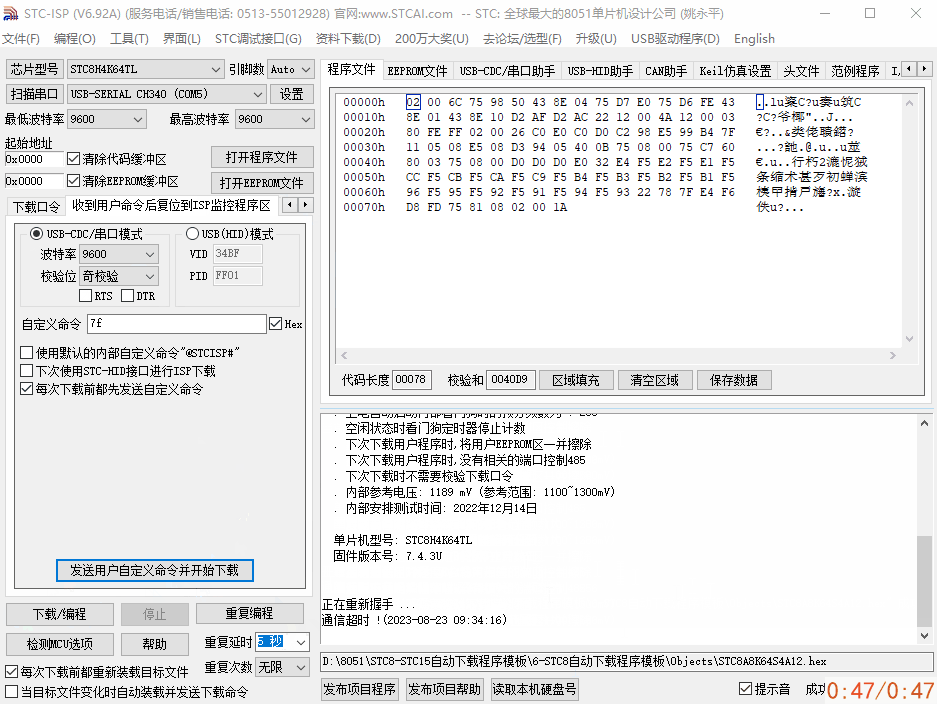
基于串口透传模块,单片机无线串口空中下载测试
基于串口透传模块,单片机无线串口空中下载测试 ✨无线串口下载,其本质还是串口下载方式,只不过省去了单片机和ISP上位机工具之间的物理有线连接,中间的数据通过无线串口透传模块进行数据中转,传递到单片机串口上。串口…...

研磨设计模式day11代理模式
目录 场景 代码实现 编辑 解析 定义 代理模式调用示意图 代理模式的特点 本质 编辑何时选用 场景 我有一个订单类,包含订单数、用户名和商品名,有一个订单接口包含了对订单类的getter和setter 现在有一个需求,a创建的订单只…...

vue2 路由进阶,VueCli 自定义创建项目
一、声明式导航-导航链接 1.需求 实现导航高亮效果 如果使用a标签进行跳转的话,需要给当前跳转的导航加样式,同时要移除上一个a标签的样式,太麻烦!!! 2.解决方案 vue-router 提供了一个全局组件 router…...
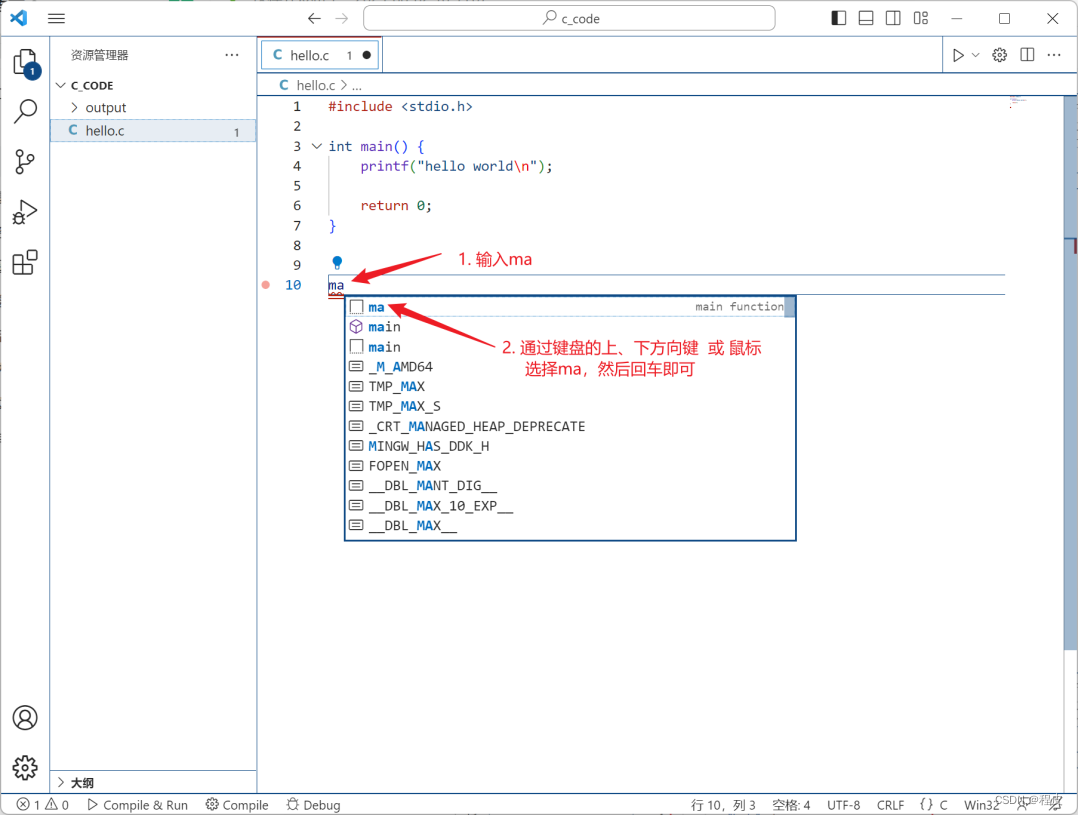
《C语言编程环境搭建》工欲善其事 必先利其器
C语言编译器 GCC 系列 GNU编译器套装(英语:GNU Compiler Collection,缩写为GCC),指一套编程语言编译器,常被认为是跨平台编译器的事实标准。原名是:GNU C语言编译器(GNU C Compiler)。 MinGW 又称mingw32 ,…...

蓝蓝设计ui设计公司作品案例-中节能现金流抗压测试软件交互及界面设计
中国节能是以节能环保为主业的中央企业。中国节能以生态文明建设为己任,长期致力于让天更蓝、山更绿、水更清,让生活更美好。经过多年发展,中国节能已构建起以节能、环保、清洁能源、健康和节能环保综合服务为主业的41产业格局,成…...

汽车制造业外发文件时 如何阻断泄密风险?
汽车制造业是我国国民经济发展的支柱产业之一,具有产业链长、关联度高、就业面广、消费拉动大等特性。汽车制造行业景气度与宏观经济、居民收入水平和固定资产投资密切相关。 汽车制造业产业链长,关联度高,汽车制造上游行业主要为钢铁、化工…...
的时序特征提取进阶)
Granite TimeSeries FlowState R1实战:基于卷积神经网络(CNN)的时序特征提取进阶
Granite TimeSeries FlowState R1实战:基于卷积神经网络(CNN)的时序特征提取进阶 你是不是也遇到过这样的问题?面对一长串传感器读数、股票价格波动或者服务器监控数据,感觉信息量巨大,却不知道从哪里入手…...

Youtu-VL-4B-Instruct步骤详解:Supervisor日志查看、错误定位与常见启动失败修复
Youtu-VL-4B-Instruct步骤详解:Supervisor日志查看、错误定位与常见启动失败修复 部署一个强大的多模态AI模型,最让人头疼的往往不是使用,而是启动。你满怀期待地拉取镜像、启动服务,结果浏览器里只显示一个冰冷的“无法访问此网…...

3倍效率提升的B站视频下载工具:DownKyi如何重构资源获取体验
3倍效率提升的B站视频下载工具:DownKyi如何重构资源获取体验 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等…...

Qwen3-ASR-0.6B应用分享:打造智能语音助手的第一步
Qwen3-ASR-0.6B应用分享:打造智能语音助手的第一步 1. 语音识别技术的新选择 在智能语音助手、会议记录、客服系统等场景中,语音识别(ASR)技术正变得越来越重要。传统方案要么识别准确率不够高,要么需要消耗大量计算资源。Qwen3-ASR-0.6B的…...
)
Android逆向实战:用Frida Hook自己写的APK,让1+1=88(附完整代码)
Android逆向实战:用Frida Hook自己写的APK,让1188(附完整代码) 在移动安全领域,逆向工程一直是个充满挑战又极具魅力的方向。想象一下,你能否让一个简单的计算器应用突然改变行为,比如让11的结果…...

OpenClaw隐私保护设计:GLM-4.7-Flash本地处理医疗笔记整理
OpenClaw隐私保护设计:GLM-4.7-Flash本地处理医疗笔记整理 1. 为什么医疗数据必须留在本地? 去年帮家人整理慢性病就诊记录时,我遇到一个两难选择:要么手动整理上百张化验单和处方笺,要么使用云端OCR工具自动处理。当…...

OpenClaw备份策略:ollama-QwQ-32B自动化管理NAS存储的方案
OpenClaw备份策略:ollama-QwQ-32B自动化管理NAS存储的方案 1. 为什么需要自动化备份方案 去年冬天的一次硬盘故障让我彻底改变了数据管理方式。当时我的NAS中存储着近5年的家庭照片和视频,由于没有完善的备份机制,差点永久丢失这些珍贵记忆…...

【stm32_2.1】【快速入门】自举模式、Flash闪存、LED点灯——对二极管PN结解析
目录 当前MCU概述 固化程序到单片机 自举模式 自举配置 Flash闪存 二极管的原理 当前MCU概述 MCU名称stm32F407ZET6处理器主频168MHz 闪存容量 512KB静态随机访问存储器SRAM192KBMCU引脚数量144pin 固化程序到单片机 写好的程序要固化到单片机,就必须学习怎…...

零基础玩转OpenClaw:Qwen3.5-9B镜像+可视化控制台体验
零基础玩转OpenClaw:Qwen3.5-9B镜像可视化控制台体验 1. 为什么选择OpenClawQwen3.5-9B组合 去年我在整理个人知识库时,每天要花2小时重复执行网页截图、OCR识别、内容归档的机械操作。直到发现OpenClaw这个能像人类一样操作电脑的开源智能体框架&…...

如何用Alternative Mod Launcher彻底解决XCOM 2模组管理的五大难题
如何用Alternative Mod Launcher彻底解决XCOM 2模组管理的五大难题 【免费下载链接】xcom2-launcher The Alternative Mod Launcher (AML) is a replacement for the default game launchers from XCOM 2 and XCOM Chimera Squad. 项目地址: https://gitcode.com/gh_mirrors/…...