Spark SQL join的三种实现方式
引言
join是SQL中的常用操作,良好的表结构能够将数据分散到不同的表中,使其符合某种规范(mysql三大范式),可以最大程度的减少数据冗余,更新容错等,而建立表和表之间关系的最佳方式就是join操作。
对于Spark来说有3种Join的实现,每种Join对应的不同的应用场景(SparkSQL自动决策使用哪种实现范式):
1.Broadcast Hash Join:适合一张很小的表和一张大表进行Join;
2.Shuffle Hash Join:适合一张小表(比上一个大一点)和一张大表进行Join;
2.Sort Merge Join:适合两张大表进行Join;
前两者都是基于Hash Join的,只不过Hash Join之前需要先shuffle还是先brocadcast。下面详细解释一下这三种Join的具体原理。
Hash Join
先来看看这样一条SQL语句:select * from order,item where item.id = order.i_id,参与join的两张表是order和item,join key分别是item.id以及order.i_id。现在假设Join采用的是hash join算法,整个过程会经历三步:
1.确定Build Table以及Probe Table:这个概念比较重要,Build Table会被构建成以join key为key的hash table,而Probe Table使用join key在这张hash table表中寻找符合条件的行,然后进行join链接。Build表和Probe表是Spark决定的。通常情况下,小表会被作为Build Table,较大的表会被作为Probe Table。
2.构建Hash Table:依次读取Build Table(item)的数据,对于每一条数据根据Join Key(item.id)进行hash,hash到对应的bucket中(类似于HashMap的原理),最后会生成一张HashTable,HashTable会缓存在内存中,如果内存放不下会dump到磁盘中。
3.匹配:生成Hash Table后,在依次扫描Probe Table(order)的数据,使用相同的hash函数(在spark中,实际上就是要使用相同的partitioner)在Hash Table中寻找hash(join key)相同的值,如果匹配成功就将两者join在一起。
这里有两个问题需要关注:
1.hash join性能如何?很显然,hash join基本都只扫描两表一次,可以认为O(a+b),较之最极端的是笛卡尔积运算O(a*b);
2.为什么Build Table选择小表?道理很简单,因为构建Hash Table时,最好可以把数据全部加载到内存中,因为这样效率才最高,这也决定了hash join只适合于较小的表,如果是两个较大的表的场景就不适用了。
上文说,hash join是传统数据库中的单机join算法,在分布式环境在需要经过一定的分布式改造,说到底就是尽可能利用分布式计算资源进行并行计算,提高总体效率,hash join分布式改造一般有以下两种方案:
1.broadcast hash join:将其中一张较小的表通过广播的方式,由driver发送到各个executor,大表正常被分成多个区,每个分区的数据和本地的广播变量进行join(相当于每个executor上都有一份小表的数据,并且这份数据是在内存中的,过来的分区中的数据和这份数据进行join)。broadcast适用于表很小,可以直接被广播的场景;
2.shuffle hash join:一旦小表比较大,此时就不适合使用broadcast hash join了。这种情况下,可以对两张表分别进行shuffle,将相同key的数据分到一个分区中,然后分区和分区之间进行join。相当于将两张表都分成了若干小份,小份和小份之间进行hash join,充分利用集群资源。
Broadcast Hash Join
大家都知道,在数据库的常见模型中(比如星型模型或者雪花模型),表一般分为两种:事实表和维度表,维度表一般指固定的、变动较少的表,例如联系人、物品种类,一般数据有限;而事实表一遍记录流水,比如销售清单等,通过随着时间的增长不断增长。
因为join操作是对两个表中key相同的记录进行连接,在SparkSQL中,对两个表做join的最直接的方式就是先根据key进行分区,再在每个分区中把key相同的记录拿出来做连接操作,但这样不可避免的涉及到shuffle,而shuffle是spark中比较耗时的操作,我们应该尽可能的设计spark应用使其避免大量的shuffle操作。
Broadcast Hash Join的条件有以下几个:
1.被广播的表需要小于spark.sql.autoBroadcastJoinThreshold所配置的信息,默认是10M;
2.基表不能被广播,比如left outer join时,只能广播右表。
看起来广播是一个比较理想的方案,但它有没有缺点呢?缺点也是很明显的,这个方案只能广播较小的表,否则数据的冗余传输就是远大于shuffle的开销;另外,广播时需要被广播的表collect到driver端,当频繁的广播出现时,对driver端的内存也是一个考验。
broadcast hash join可以分为两步:
1.broadcast阶段:将小表广播到所有的executor上,广播的算法有很多,最简单的是先发给driver,driver再统一分发给所有的executor,要不就是基于bittorrete的p2p思路;
2.hash join阶段:在每个executor上执行 hash join,小表构建为hash table,大表的分区数据匹配hash table中的数据;
Shuffle Hash Join
当一侧的表比较小时,我们可以选择将其广播出去以避免shuffle,提高性能。但因为被广播的表首先被collect到driver端,然后被冗余的发送给各个executor上,所以当表比较大是,采用broadcast join会对driver端和executor端造成较大的压力。
我们可以通过将大表和小表都进行shuffle分区,然后对相同节点上的数据的分区应用hash join,即先将较小的表构建为hash table,然后遍历较大的表,在hash table中寻找可以匹配的hash值,匹配成功进行join连接。这样既在一定程度上减少了driver广播表的压力,也减少了executor端读取整张广播表的内存消耗。
Sshuffle Hash Join分为两步:
1.对两张表分别按照join key进行重分区(分区函数相同的时候,相同的相同分区中的key一定是相同的),即shuffle,目的是为了让相同join key的记录分到对应的分区中;
2.对对应分区中的数据进行join,此处先将小表分区构建为一个hash表,然后根据大表中记录的join key的hash值拿来进行匹配,即每个节点山单独执行hash算法。
Shuffle Hash Join的条件有以下几个:
-
分区的平均大小不超过spark.sql.autoBroadcastJoinThreshold所配置的值,默认是10M
-
基表不能被广播,比如left outer join时,只能广播右表
-
一侧的表要明显小于另外一侧,小的一侧将被广播(明显小于的定义为3倍小,此处为经验值)
看到这里,可以初步总结出来如果两张小表join可以直接使用单机版hash join;如果一张大表join一张极小表,可以选择broadcast hash join算法;而如果是一张大表join一张小表,则可以选择shuffle hash join算法;那如果是两张大表进行join呢?
Sort Merge Join
上面介绍的方式只对于两张表有一张是小表的情况适用,而对于两张大表,但当两个表都非常大时,显然无论哪种都会对计算内存造成很大的压力。这是因为join时两者采取都是hash join,是将一侧的数据完全加载到内存中,使用hash code取join key相等的记录进行连接。
当两个表都非常大时,SparkSQL采用了一种全新的方案来对表进行Join,即Sort Merge Join。这种方式不用将一侧数据全部加载后再进行hash join,但需要在join前将数据进行排序。
首先将两张表按照join key进行重新shuffle,保证join key值相同的记录会被分在相应的分区,分区后对每个分区内的数据进行排序,排序后再对相应的分区内的记录进行连接。可以看出,无论分区有多大,Sort Merge Join都不用把一侧的数据全部加载到内存中,而是即用即丢;因为两个序列都有有序的,从头遍历,碰到key相同的就输出,如果不同,左边小就继续取左边,反之取右边。从而大大提高了大数据量下sql join的稳定性。
SparkSQL对两张大表join采用了全新的算法-sort-merge join,整个过程分为三个步骤:
-
shuffle阶段:将两张大表根据join key进行重新分区,两张表数据会分布到整个集群,以便分布式并行处理;
-
sort阶段:对单个分区节点的两表数据,分别进行排序;
-
merge阶段:对排好序的两张分区表数据执行join操作。join操作很简单,分别遍历两个有序序列,碰到相同join key就merge输出,否则取更小一边
相关文章:

Spark SQL join的三种实现方式
引言 join是SQL中的常用操作,良好的表结构能够将数据分散到不同的表中,使其符合某种规范(mysql三大范式),可以最大程度的减少数据冗余,更新容错等,而建立表和表之间关系的最佳方式就是join操作。 对于Spark来说有3种…...

wazuh环境配置和漏洞复现
1.wazuh配置 虚拟机 (OVA) - 替代安装 (wazuh.com)在官方网页安装ova文件 打开VMware选择打开虚拟机,把下载好的ova文件放入在设置网络改为NAT模式 账号:wazuh-user 密码:wazuh ip a 查看ip 启动小皮 远程连接 账号admin …...
)
九五从零开始的运维之路(其三十六)
文章目录 前言一、集群概述1.负载均衡技术类型(一)四层负载均衡器(二)七层负载均衡器 2.负载均衡实现方式(一)硬件负载均衡产品:(二)软件负载均衡产品: 二、L…...

同步和异步有什么区别,使用场景?
同步(Synchronous)和异步(Asynchronous)是用于描述不同的操作和通信模式的术语。它们在处理任务、执行代码以及处理通信时有很大的异同。 同步(Synchronous) 同步操作是指程序的执行顺序按照代码的先后顺序进行,一个操作完成后才能执行下一个操作。在同步操作中,调用一…...
webassembly009 transformers.js 网页端侧推理
之前试用过两个网页端的神经网络框架,一个是 Tensorflow PlayGround,它相当与实现了一个网页端的简单的训练框架,有关节点的数据结构可看这篇。另一个是onnx的网页端(nodejs绿色免安装try onnx on web(chrome)),需要自己转换onnx模…...

Android动态添加和删除控件/布局
一、引言 最近在研究RecyclerView二级列表的使用方法,需要实现的效果如下。 然后查了一些博客,觉得实现方式太过复杂,而且这种方式也不是特别受推荐,所以请教了别人,得到了一种感觉还不错的实现方式。实现的思路为&…...
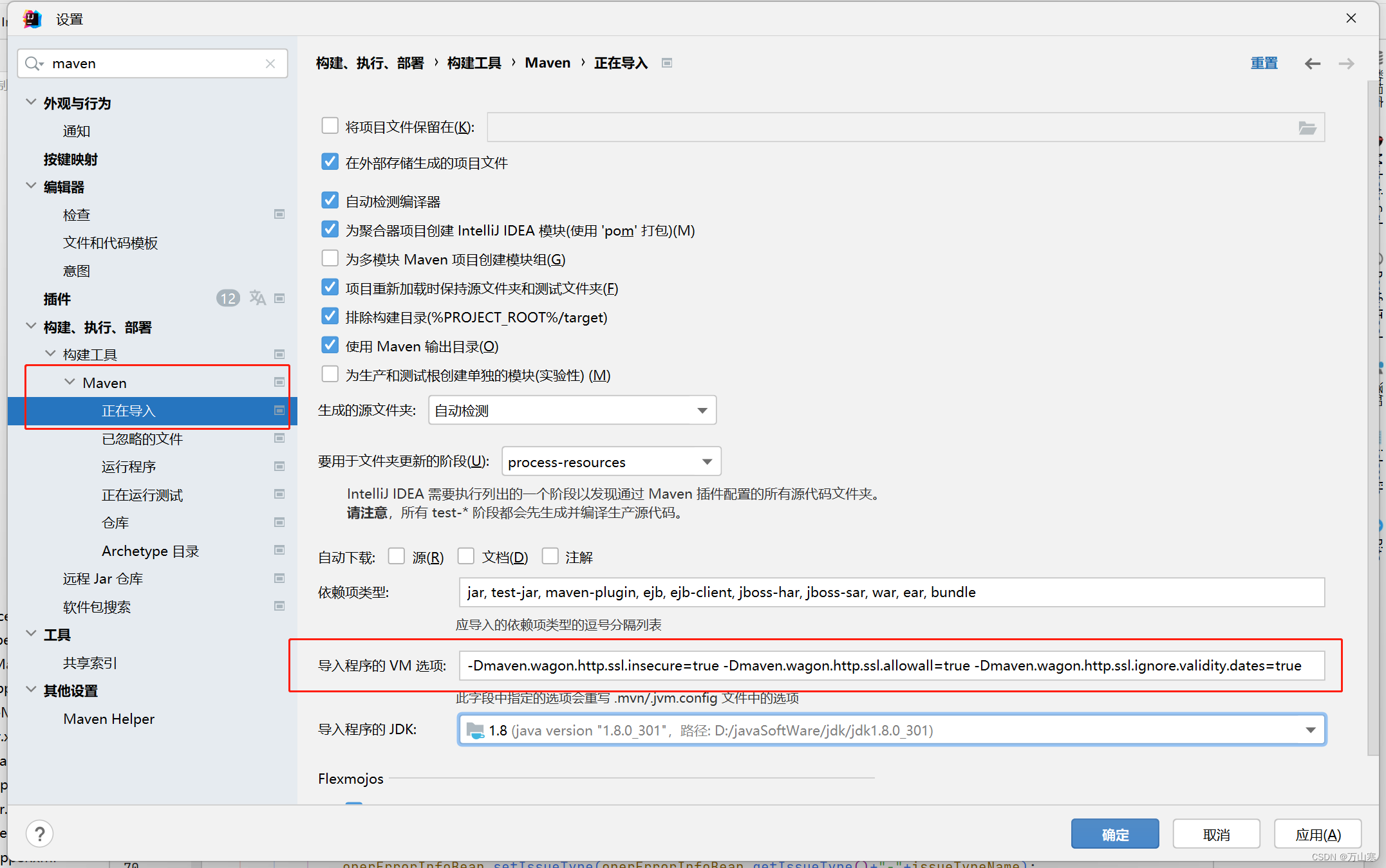
maven下载不了仓库地址为https的依赖jar,配置参数忽略ssl安全检查
问题原因 私服使用的https地址,然后安全证书过期的或没有,使用maven命令时,可以添加以下参数,忽略安全检查 mvn -Dmaven.wagon.http.ssl.insecuretrue -Dmaven.wagon.http.ssl.allowalltrue -Dmaven.wagon.http.ssl.ignore.vali…...
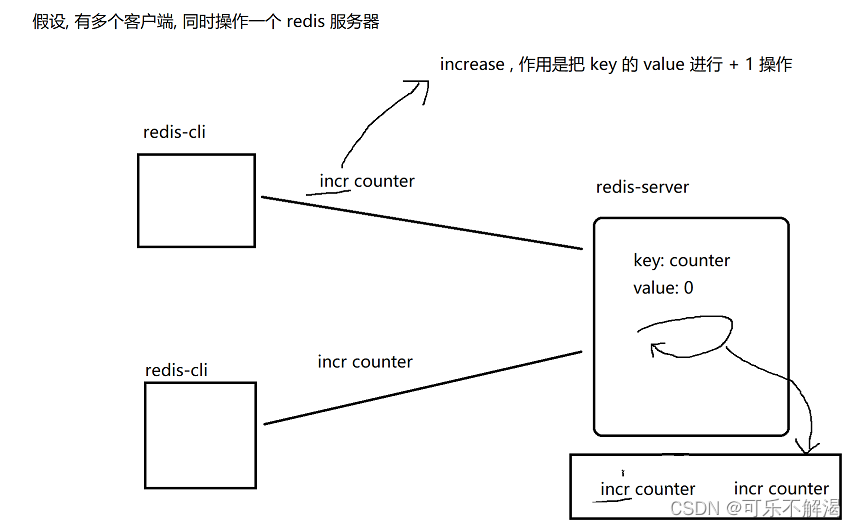
3.Redis 单线程模型
redis 单线程模型 redis 只使用一个线程来处理所有的命令请求,并不是说一个 redis 服务器进程内部真的就只有一个线程,其实也有多个线程,多个线程是再处理网络 IO。 那么在多线程中,针对类似于这样的场景两个线程尝试同时对一个…...
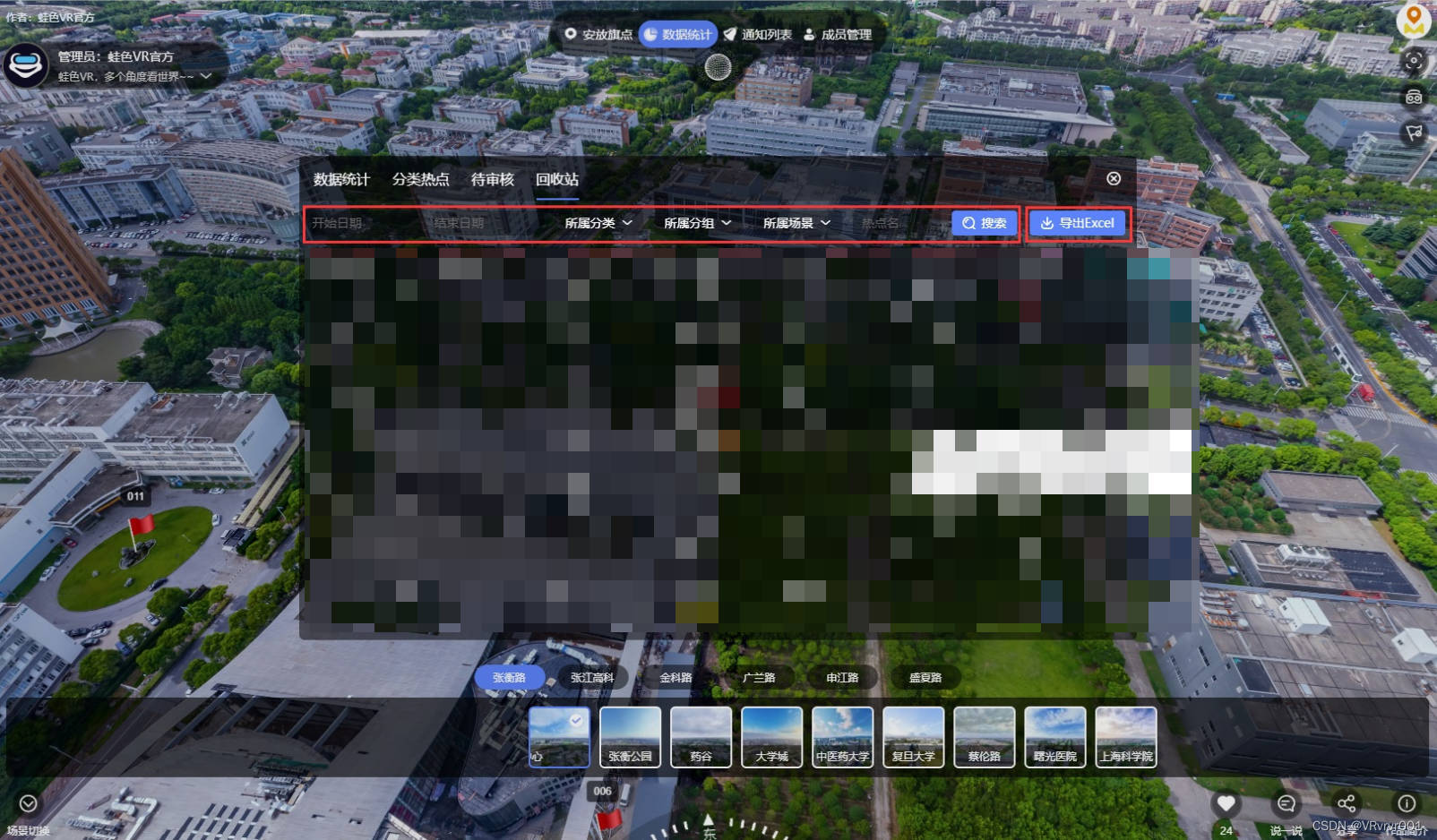
0基础学习VR全景平台篇 第90篇:智慧眼-数据统计
【数据统计】是按不同条件去统计整个智慧眼项目中的热点,共包含四大块,分别是数据统计、分类热点、待审核、回收站,下面我们来逐一进行介绍。 1、数据统计 ① 可以按所属分类、场景分组、所属场景、热点类型以及输入热点名去筛选对应的热点&…...
【Go】Goland项目配置运行教程
Golang项目配置运行教程 1.安装Golang下载安装包安装 2.Goland配置2.1 环境2.2 goland配置2.2.1 没有makefile的情况2.2.2 有makefile的情况 3.跨平台项目4.补充 注意,本项目描述的是git clone下来的Golang项目配置运行教程,并不是从头创建一个Golang项目…...
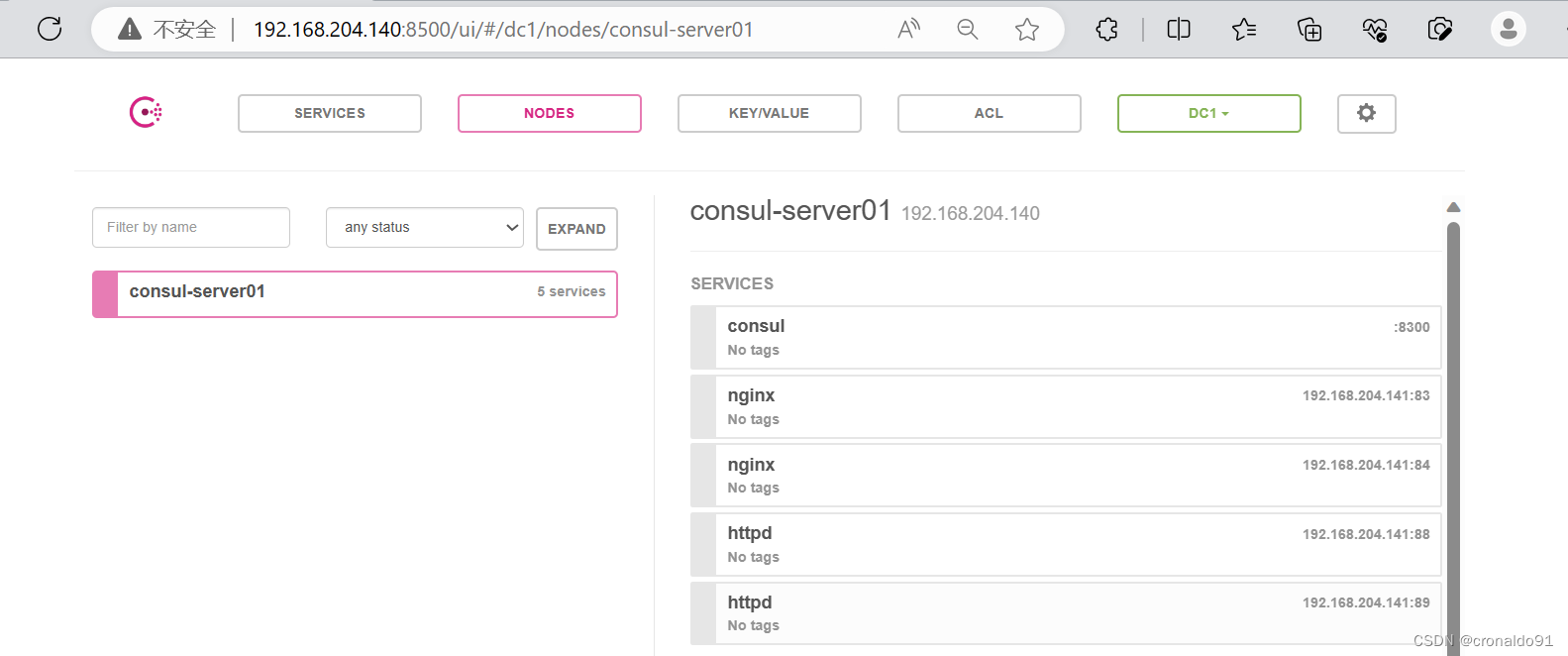
Docker容器与虚拟化技术:Docker consul 实现服务注册与发现
目录 一、理论 1.Docker consul 二、实验 1.consul部署 2. consul-template部署 三、总结 一、理论 1.Docker consul (1)服务注册与发现 服务注册与发现是微服务架构中不可或缺的重要组件。起初服务都是单节点的,不保障高可用性&…...

【大模型AIGC系列课程 2-2】大语言模型的“第二大脑”
1. 大型语言模型的不足之处 很多人使用OpenAI提供的GPT系列模型时都反馈效果不佳。其中一个主要问题是它无法回答一些简单的问题。 ● 可控性:当我们用中文问AI一些关于事实的问题时,它很容易编造虚假答案。 ● 实时性:而当你询问它最近发生的新闻事件时,它会干脆地告诉你…...
Java基础数据结构
二叉查找树 二叉查找树,又称二叉树或者二叉搜索树 特点:每一个节点上最多又两个子节点 任意节点左子树上的值都小于当前节点 任意节点右子树上的值都大于当前节点 二叉查找树添加节点:规则 小的存左边 大的存右边 一样的不存 平衡二叉树&am…...
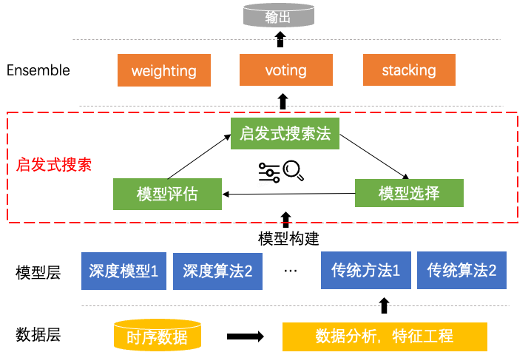
PP-TS基于启发式搜索和集成方法的时序预测模型,使预测更加准确
时间序列数据在各行业和领域中无处不在,如物联网传感器的测量结果、每小时的销售额业绩、金融领域的股票价格等等,都是时间序列数据的例子。时间序列预测就是运用历史的多维数据进行统计分析,推测出事物未来的发展趋势。 为加快企业智能化转…...

vue 04-reactive与ref的选择
reactive与re两者区别? reactive可以转换对象成为响应式数据对象,但是不支持简单数据类型 ref可以转换简单数据类型为响应式数据对象,也支持复杂数据类型,但是操作的时候需要.value 推荐使用的话: 如果能确定数据是对象且字段名称也确定,可以使用reactive转成响应式…...

Mysql索引+事务+存储引擎
索引 索引的概念 索引是一个排序的列表,在这个列表中存储着索引的值和包含这个值的数据所在行的物理地址(类似于C语言的链表通过指针指向数据记录的内存地址)。 使用索引后可以不用扫描全表来定位某行的数据,而是先通过索引表找…...
创建abp vnext项目
需求: 1.使用net core跨平台的方式支持windows和centos系统; 2.实现前后端分离部署 3.框架默认集成用户登录、权限、redis等模块 4.支持多种数据库的方式 5.前端使用vue,不需要使用框架自带的web 1.框架配置官网地址: https://ab…...

【OpenCV实战】3.OpenCV颜色空间实战
OpenCV颜色空间实战 〇、Coding实战内容一、imread1.1 函数介绍1.2 Flags1.3 Code 二. 色彩空间2.1 获取单色空间2.2. HSV、YUV、RGB2.3. 不同颜色空间应用场景 〇、Coding实战内容 OpenCV imread()方法不同的flags差异性获取单色通道【R通道、G通道、B通道】HSV、YUV、RGB 一…...

什么是回调函数(callback function)?
聚沙成塔每天进步一点点 ⭐ 专栏简介⭐ 回调函数(Callback Function)⭐ 示例⭐ 写在最后 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 记得点击上方或者右侧链接订阅本专栏哦 几何带你启航前端之旅 欢迎来到前端入门之旅!这…...

零售再增长,直播登“C位”,美团稳稳交出成绩单
8月24日,美团发布2023年中期业绩和二季报,财报显示其二季度实现营收680亿元,同比增长33.4%;实现净利润47.13亿元,同比扭亏为盈,调整后净利润达历史最高水平。其中,与消费市场走势息息相关的美团…...

使用LingBot-Depth优化Git版本控制中的3D模型管理
使用LingBot-Depth优化Git版本控制中的3D模型管理 1. 引言 在3D设计和游戏开发领域,版本控制一直是个头疼的问题。传统的Git系统擅长处理代码和文本文件,但面对3D模型这种二进制文件就显得力不从心了。每次修改模型后,你只能看到"文件…...

芯片验证工程师必备:SVA断言中的assert/cover/assume核心区别与典型误用案例
芯片验证工程师必备:SVA断言中的assert/cover/assume核心区别与典型误用案例 在芯片验证领域,SystemVerilog Assertion(SVA)是验证工程师不可或缺的利器。对于1-3年经验的验证工程师而言,深入理解assert、cover和assum…...

革新性B站用户分析工具:智能解析评论区用户背景的终极方案
革新性B站用户分析工具:智能解析评论区用户背景的终极方案 【免费下载链接】bilibili-comment-checker B站评论区自动标注成分,支持动态和关注识别以及手动输入 UID 识别 项目地址: https://gitcode.com/gh_mirrors/bil/bilibili-comment-checker …...

vLLM-v0.17.1代码实例:自定义LogitsProcessor实现内容安全过滤
vLLM-v0.17.1代码实例:自定义LogitsProcessor实现内容安全过滤 1. vLLM框架简介 vLLM是一个专注于大语言模型(LLM)推理和服务的高性能开源库。它最初由加州大学伯克利分校的天空计算实验室开发,现已发展成为一个活跃的社区项目。这个框架因其出色的性能…...

昇腾910B+MindIE实战:从零部署DeepSeek-R1-Distill-Qwen-32B推理服务
1. 昇腾910B与MindIE环境准备 在Atlas 800I A2服务器上部署DeepSeek-R1-Distill-Qwen-32B模型,首先需要搭建好基础运行环境。我最近刚完成了一个类似项目的部署,整个过程虽然有些复杂,但只要按照步骤操作,2-3小时就能搞定。 操作系…...

s2-pro音色复用效果实测:同一参考音频在不同文本长度下的泛化能力
s2-pro音色复用效果实测:同一参考音频在不同文本长度下的泛化能力 1. 测试背景与目的 s2-pro作为Fish Audio开源的专业级语音合成模型镜像,其核心亮点之一是支持通过参考音频复用音色。这项功能在实际应用中极为实用,比如: 企业…...

Qwen3-ForcedAligner-0.6B入门必看:start_time为0.00s的边界条件处理
Qwen3-ForcedAligner-0.6B入门必看:start_time为0.00s的边界条件处理 1. 为什么需要关注边界条件 当你使用Qwen3-ForcedAligner-0.6B进行音文对齐时,可能会遇到一个看似简单但很重要的问题:为什么有些词的开始时间是0.00秒?这种…...

如何通过CPUDoc免费优化CPU性能:5大核心功能全面指南
如何通过CPUDoc免费优化CPU性能:5大核心功能全面指南 【免费下载链接】CPUDoc 项目地址: https://gitcode.com/gh_mirrors/cp/CPUDoc 还在为电脑运行卡顿、游戏帧率不稳而烦恼吗?CPUDoc这款免费开源工具能够通过智能线程调度和动态电源管理&…...

Onekey:5分钟上手!Steam游戏清单下载终极指南
Onekey:5分钟上手!Steam游戏清单下载终极指南 【免费下载链接】Onekey Onekey Steam Depot Manifest Downloader 项目地址: https://gitcode.com/gh_mirrors/one/Onekey 想要轻松获取Steam游戏的完整文件清单吗?Onekey作为专业的Steam…...

如何用开源OCR突破效率瓶颈?Umi-OCR三大核心优势深度解析
如何用开源OCR突破效率瓶颈?Umi-OCR三大核心优势深度解析 【免费下载链接】Umi-OCR Umi-OCR: 这是一个免费、开源、可批量处理的离线OCR软件,适用于Windows系统,支持截图OCR、批量OCR、二维码识别等功能。 项目地址: https://gitcode.com/G…...