使用 Transformer 和 Amazon OpenSearch Service 构建基于列的语义搜索引擎

在数据湖中,对于数据清理和注释、架构匹配、数据发现和跨多个数据来源进行分析等许多操作,查找相似的列有着重要的应用。如果不能从多个不同的来源准确查找和分析数据,就会严重拉低效率,不论是数据科学家、医学研究人员、学者,还是金融和政府分析师,所有人都会深受其害。
传统解决方案涉及到使用词汇关键字搜索或正则表达式匹配,这些方法容易受到数据质量问题的影响,例如缺少列名或者不同数据集中采用了不同的列命名约定(例如, zip_code、zcode、postalcode )。
在这篇文章中,我们演示了一种解决方案,基于列名和/或列内容对相似列执行搜索。该解决方案使用 Amazon OpenSearch Service 中提供的近似最近邻算法来搜索具有相似语义的列。为了协助进行搜索,我们使用 Amazon SageMaker 中通过 sentence-transformers 库预训练的 Transformer 模型,为数据湖中的各个列创建特征表示(嵌入对象)。最后,为了从解决方案进行交互并可视化结果,我们构建了在 Amazon Fargate 上运行的交互式 Streamlit Web 应用程序。
我们提供了一个代码教程,您可用它来部署资源,以便对示例数据或自己的数据运行该解决方案。
解决方案概览
以下架构图展示了查找具有相似语义列的工作流程,分为两个阶段。第一阶段运行 Amazon Step Functions 工作流,从表格列创建嵌入对象并构建 OpenSearch Service 搜索索引。第二阶段是在线推理阶段,通过 Fargate 运行 Streamlit 应用程序。Web 应用程序收集输入搜索查询,并从 OpenSearch Service 索引中检索与该查询近似的 k 个最相似列。
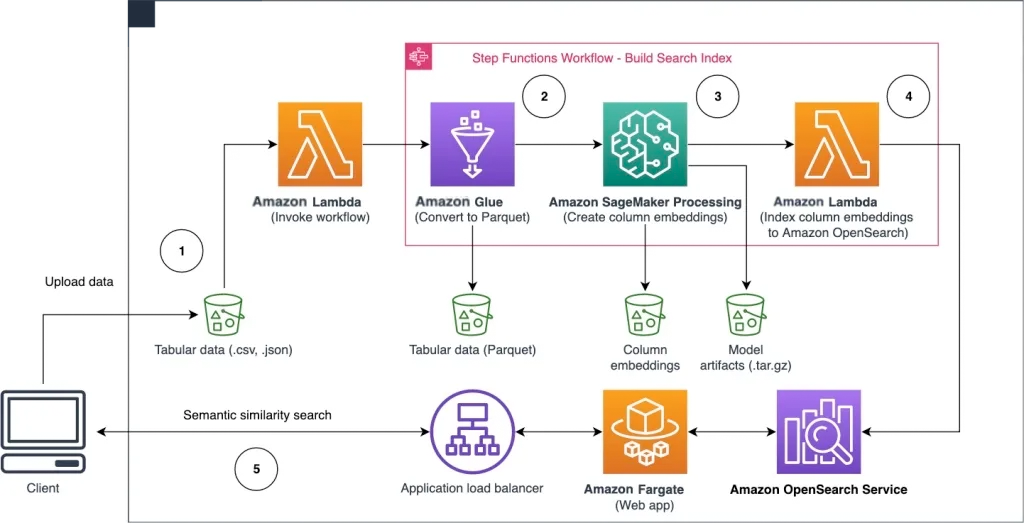
图1 解决方案架构
自动化工作流按以下步骤进行:
用户将表格数据集上传到 Amazon Simple Storage Service (Amazon S3) 存储桶中,这会调用 Amazon Lambda 函数来启动 Step Functions 工作流。
该工作流首先启动 Amazon Glue 作业,将 CSV 文件转换为 Apache Parquet 数据格式。
SageMaker Processing 作业使用预训练模型或自定义列嵌入模型,为各个列创建嵌入对象。SageMaker Processing 作业将每个表的列嵌入对象保存在 Amazon S3 中。
Lambda 函数创建 OpenSearch Service 域和集群,以索引上一步中生成的列嵌入对象。
最后,使用 Fargate 部署交互式 Streamlit Web 应用程序。Web 应用程序为用户提供了一个界面,用于输入查询,从而在 OpenSearch Service 域中搜索相似的列。
您可以从 GitHub 下载代码教程,在示例数据或自己的数据上试用此解决方案。Github 上提供了如何部署本教程所需资源的说明。
先决条件
要实施此解决方案,您需要:
亚马逊云科技账户。
对亚马逊云服务有一些基本了解,例如 Amazon Cloud Development Kit(Amazon CDK)、Lambda、OpenSearch Service 和 SageMaker Processing。
用于创建搜索索引的表格数据集。您可以使用自己的表格数据,也可以在 GitHub 上下载示例数据集。
构建搜索索引
第一阶段中将构建列搜索引擎索引。下图展示了运行此阶段的 Step Functions 工作流。
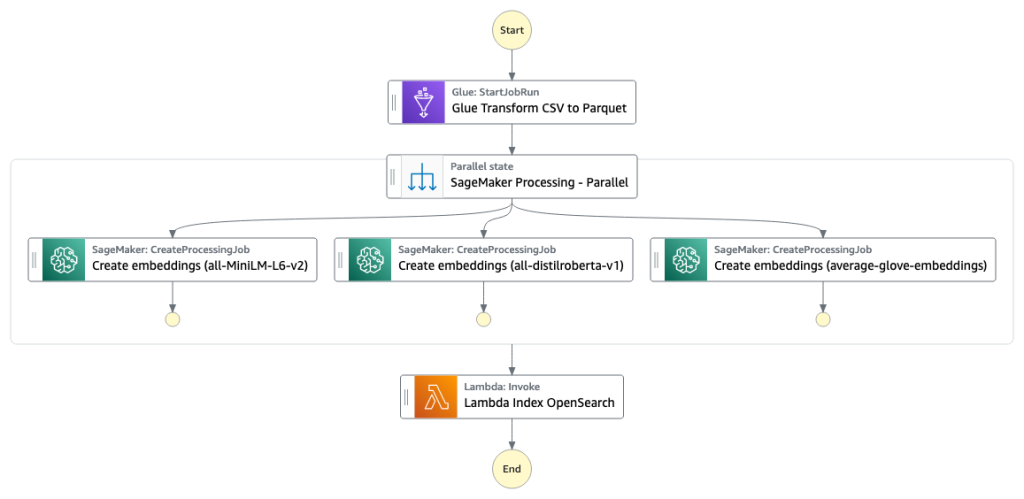
图 2 Step Functions 工作流 – 多个嵌入模型
数据集
在这篇文章中,我们构建了一个搜索索引,包括了超过 25 个表格数据集中的 400 多个列。数据集来自以下公共来源:
s3://sagemaker-sample-files/datasets/tabular/
NYC Open Data
Chicago Data Portal
有关索引中包含的表的完整列表,请参阅 GitHub 上的代码教程(https://github.com/aws-samples/tabular-column-semantic-search/blob/main/sample-batch-datasets.json)。
您可以使用自己的表格数据集来扩充示例数据,或者构建自己的搜索索引。我们提供了两个 Lambda 函数用于启动 Step Functions 工作流,这两个函数分别为单个 CSV 文件或批量 CSV 文件构建搜索索引。
将 CSV 转换为 Parquet
使用 Amazon Glue 将原始 CSV 文件转换为 Parquet 数据格式。Parquet 是一种面向列格式文件的格式,是大数据分析中的首选格式,可提供高效的压缩和编码。在我们的实验中,与原始 CSV 文件相比,Parquet 数据格式显著减少了所需的存储空间。我们还使用 Parquet 作为通用数据格式来转换其他数据格式(例如 JSON 和 NDJSON),因为它支持高级嵌套数据结构。
创建表格列嵌入对象
在本文中,为了对示例表格数据集中的单个表列提取嵌入对象,我们使用了从 sentence-transformers 库预训练的以下模型。有关其他模型,请参阅 Pretrained Models(预训练模型,https://www.sbert.net/docs/pretrained_models.html)
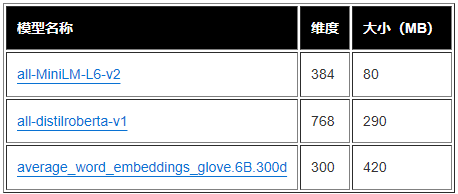
SageMaker Processing 作业为单个模型运行 create_embeddings.py (代码:https://github.com/aws-samples/tabular-column-semantic-search/blob/main/assets/s3/scripts/create_embeddings.py)。要从多个模型中提取嵌入对象,工作流会并行运行 SageMaker Processing 作业,如 Step Functions 工作流所示。我们使用该模型创建两组嵌入对象:
column_name_embeddings – 列名的嵌入对象(标题)
column_content_embeddings – 列中所有行的平均嵌入对象
有关列嵌入过程的更多信息,请参阅 GitHub 上的代码教程(https://github.com/aws-samples/tabular-column-semantic-search)。
SageMaker Processing 步骤的替代方法是创建 SageMaker 批量变换,用于在大型数据集上获取列嵌入对象。这将需要将模型部署到 SageMaker 端点。有关更多信息,请参阅 Use Batch Transform(使用批量转换)。
使用 OpenSearch Service
对嵌入对象编制索引
在本阶段的最后一步,Lambda 函数将列嵌入对象添加到 OpenSearch Service 近似 k 近邻(kNN,k-Nearest-Neighbor)搜索索引中。向每个模型分配自己的搜索索引。有关近似 kNN 搜索索引参数的更多信息,请参阅 k-NN (https://opensearch.org/docs/latest/search-plugins/knn/index/)。
使用 Web 应用程序
进行在线推理和语义搜索
工作流程的第二阶段运行 Streamlit Web 应用程序,您可以在其中提供输入数据,然后在 OpenSearch Service 中搜索编制了索引的具有相似语义的列。应用层使用应用程序负载均衡器、Fargate 和 Lambda。应用程序基础设施作为解决方案的一部分自动部署。
使用该应用程序,您可以提供输入数据,然后搜索具有相似语义的列名和/或列内容。此外,您可以选择嵌入模型以及搜索中返回的最近邻的数量。应用程序接收输入数据,使用指定模型嵌入输入数据,并在 OpenSearch Service 中使用 kNN 搜索,以此来搜索编制了索引的列嵌入对象,并查找与给定输入数据最相似的列。显示的搜索结果包括表名、列名和所确定列的相似度分数,以及数据在 Amazon S3 中的位置,以供进一步探索。
下图显示了 Web 应用程序的示例。在此示例中,我们在数据湖中搜索具有与 district (负载)相似的 Column Names (负载类型)的列。应用程序使用 all-MiniLM-L6-v2 作为嵌入模型,从 OpenSearch Service 索引中返回了 10 个(k)最近邻。
根据 OpenSearch Service 中索引的数据,应用程序返回 transit_district 、 city 、 borough 和 location 作为四个最相似的列。此示例演示了搜索方法识别数据集中相似语义列的功能。

图 3:Web 应用程序用户界面
清理
要删除本教程中由 Amazon CDK 创建的资源,请运行以下命令:
Bash
cdk destroy --all左滑查看更多
总结
在这篇文章中,我们介绍了为表格列构建语义搜索引擎的端到端工作流程。
您可以使用我们在 GitHub (https://github.com/aws-samples/tabular-column-semantic-search) 上提供的代码教程,开始处理自己的数据。如果您需要帮助加快在产品和流程中使用机器学习功能的速度,请联系 Amazon Machine Learning Solutions Lab (https://aws.amazon.com/ml-solutions-lab/)。
Original URL:
https://aws.amazon.com/blogs/big-data/build-a-semantic-search-engine-for-tabular-columns-with-transformers-and-amazon-opensearch-service/
本篇作者

Kachi Odoemene
亚马逊云科技人工智能部门的应用科学家。他构建人工智能/机器学习解决方案,为亚马逊云科技客户解决业务问题。

Taylor McNally
Amazon Machine Learning Solutions Lab 的深度学习架构师。他帮助来自不同行业的客户利用亚马逊云科技上的人工智能/机器学习构建解决方案。他喜欢醇美咖啡,爱好户外活动,并享受与家人和活泼好动的狗子共度时光。

Austin Welch
Amazon ML Solutions Lab 的数据科学家。他开发自定义深度学习模型,帮助亚马逊云科技公共部门客户加快人工智能和云的采用。在业余时间,他喜欢阅读、旅行和柔术。


听说,点完下面4个按钮
就不会碰到bug了!

相关文章:
使用 Transformer 和 Amazon OpenSearch Service 构建基于列的语义搜索引擎
在数据湖中,对于数据清理和注释、架构匹配、数据发现和跨多个数据来源进行分析等许多操作,查找相似的列有着重要的应用。如果不能从多个不同的来源准确查找和分析数据,就会严重拉低效率,不论是数据科学家、医学研究人员、学者&…...

算法通关村第九关——透彻理解二分查找
1.前言 常见的查找算法有顺序查找、二分查找、插值查找、斐波那契查找、树表查找、分块查找、哈希查找等。如果进行归类,那么二分查找、插值查找(一种查找算法)以及斐波那契查找都可以归为插值查找(大类)。而插值查找…...

【字节跳动青训营】后端笔记整理-4 | Go框架三件套之GORM的使用
**本人是第六届字节跳动青训营(后端组)的成员。本文由博主本人整理自该营的日常学习实践,首发于稀土掘金。 我的go开发环境: *本地IDE:GoLand 2023.1.2 *go:1.20.6 *MySQL:8.0 本文介绍Go框架三…...
【TI毫米波雷达笔记】UART串口外设配置及驱动(以IWR6843AOP为例)
【TI毫米波雷达笔记】UART串口外设初始化配置及驱动(以IWR6843AOP为例) 最基本的工程建立好以后 需要给SOC进行初始化配置 int main (void) {//刷一下内存memset ((void *)L3_RAM_Buf, 0, sizeof(L3_RAM_Buf));int32_t errCode; //存放SOC初…...
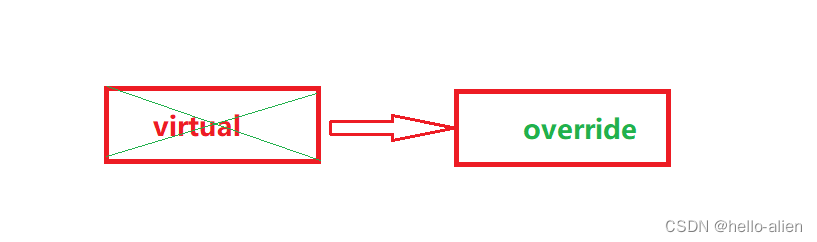
C#---第十九课:不同类型方法的执行顺序(new / virtual / common / override)
本文介绍不同类型的方法,在代码中的执行顺序问题: 构造方法普通方法(暂用common代替)、虚方法(Virtual修饰)、New方法(new修饰)三个优先级相同overide方法(会替换virtual…...

[pytorch]torch.cuda用法以及判断显卡是不是存在问题
常见用法: torch.cuda.is_available() # 查看是否有可用GPU torch.cuda.device_count() # 查看GPU数量 torch.cuda.get_device_capability(device) # 查看指定GPU容量 torch.cuda.get_device_name(device) # 查看指定GPU名称 torch.cuda.empty_cache() # 清空程序占…...
JUC——多线程补充
前置可看 Java——多线程和锁_java多线程锁_北岭山脚鼠鼠的博客-CSDN博客 线程创建的三种方式 Thread、Runnable、Callable Thread类 Runable接口 Callable接口 Lamda表达式 Lamda表达式_北岭山脚鼠鼠的博客-CSDN博客 静态代理模式(Thread类的原理) 如下代码中 真实对象…...
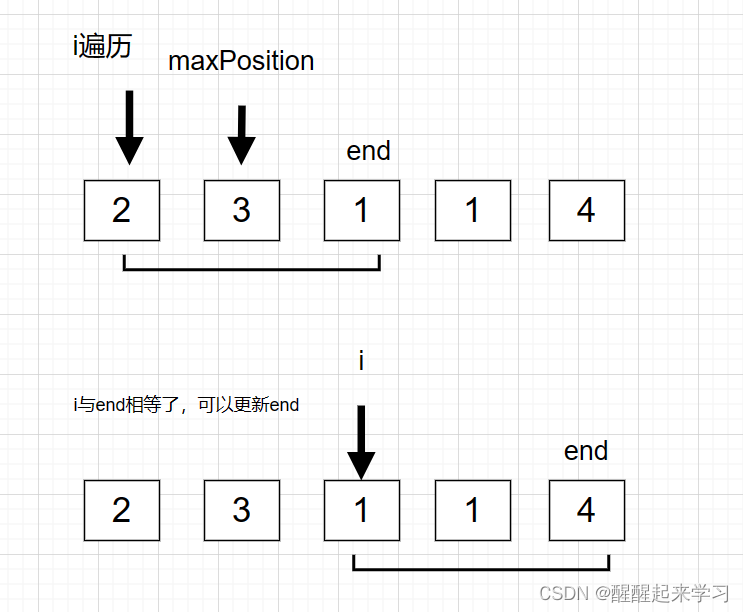
代码随想录第32天|122.买卖股票的最佳时机 II,55. 跳跃游戏 ,45. 跳跃游戏 II
122.买卖股票的最佳时机 II 122. 买卖股票的最佳时机 II 思路比较简单 class Solution {public int maxProfit(int[] prices) {int res0,sum0;for(int i0;i<prices.length-1;i){if(prices[i1]-prices[i]>0){sumprices[i1]-prices[i];}ressum>res?sum:res;}return …...

Linux:Nginx服务与搭建
目录 一、Nginx概述 二、Nginx三大作用:反向代理、负载均衡、动静分离 三、Nginx和Apache 3.1Nginx和Apache的差异 3.2Nginx和Apache的优缺点比较 四、编译安装niginx 五、创建Nginx 自启动文件 六、Nginx的信号使用 6.1信号 七、升级 nginx1.18 nginx1.2…...

4、什么是NoSQL
4、什么是NoSQL NoSQL NoSQL Not Only SQL,就是不仅仅是SQL的意思 泛指非关系型数据库,随着web2.0的诞生!传统的关系型数据库很难对付web2.0时代,因为web2.0时代又很多数据大爆炸新生的产物比如视频、音乐、大数据产生的其他的数…...
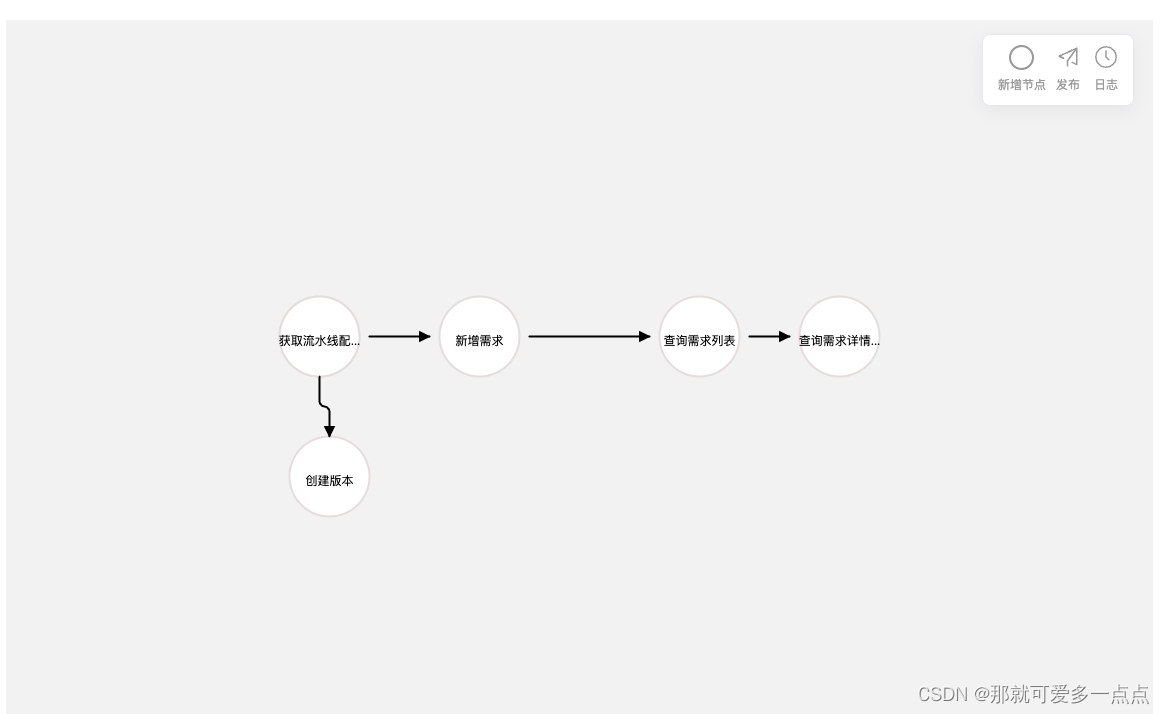
如何自己实现一个丝滑的流程图绘制工具(一)vue如何使用
背景 项目需求突然叫我实现一个类似processOn一样的在线流程图绘制工具。 这可难倒我了,立马去做调研,在github上找了很多个开源的流程图绘制工具, 对比下来我还是选择了 bpmn-js 原因: 1、他的流程图是涉及到业务的,…...
ReoGrid.NET集成到winfrom
ReoGrid一个支持excel操作的控件,支持集成到任何winfrom项目内。 先看效果图: 如何使用: 使用ReoGrid自带excel模版设计工具先设计一个模版,设计器如下: 具体例子看官方文档 代码示例如下: var sheet reoGridControl1.CurrentWorksheet; …...

Elasticsearch实现增删改查
调用elasticsearch通常使用restful风格请求,这里记录一些常用的Java API和Postman Url Java API调用Es 1. 查询总文档数 Testvoid getAllCount() { // RestHighLevelClient clientnew RestHighLevelClient(RestClient.builder(new HttpHost("192.168…...
)
Rust 学习笔记(卷二)
文章目录 Rust 学习笔记(卷二)八、工程1. package 和 cratepackage 总览包根(crate root) 2. 模块初识模块单个源文件中的嵌套模块使用具有层级结构的源文件构造嵌套模块 3. 文档4. 使用第三方包5. 打包自己的包 九、标准库十、多…...

android amazon 支付接入
流程: 申请 Amazon 开发者帐号 ---> 在 amazon 控制台添加应用 ---> 添加应用内商品(消费类商品,授权类商品,订阅类商品)---> 导出 JSON 文件 --->集成 Amazon 支付 ---> 将导出的 JSON 文件 copy 到 …...

Vue2-快速搭建pc端后台管理系统
一.推荐二次开发框架 vue-element-admin Star(84k)vue-antd-admin Star(3.5k) 二.vue-element-admin 官网链接:https://panjiachen.github.io/vue-element-admin-site/zh/ 我这里搭建的是基础模版vue-admin-template(推荐) # 克隆项目 git clone https://github.com/PanJi…...

【产品文档】团队介绍PPT模板
今天和大家免费分享团队介绍的PPT模板。团队介绍是向他人展示团队的实力、专业性和能力的重要方式。通过一个有力的团队介绍,您可以突出团队的成员、经验、技能和取得的成就,从而增加信任、吸引合作伙伴、客户或投资者的兴趣 【模板预览】 动态演示效果…...
组件库的使用和自定义组件
目录 一、组件库介绍 1、什么是组件 2、组件库介绍 3、arco.design 二、组件库的使用 1、快速上手 2、主题定制 3、暗黑模式 4、语言国际化 5、业务常见问题 三、自定义组件 2、组件开发规范 3、示例实践guide-tip 4、业务组件快速托管 一、组件库介绍 1、什么是…...
网站和API支持HTTPS,最好在Nginx上配置
随着我们网站用户的增多,我们会逐渐意识到HTTPS加密的重要性。在不修改现有代码的情况下,要从HTTP升级到HTTPS,让Nginx支持HTTPS是个很好的选择。今天我们来讲下如何从Nginx入手,从HTTP升级到HTTPS,同时支持静态网站和…...
UnitTest笔记: 拓展库DDT的使用
DDT (Data-Drivers- Tests) 允许使用不同的测试数据运行同一个测试用例,展示为不同的测试用例。 第一步: pip安装 ddt 第二步: 创建test_baidu_ddt.py 1. 测试类要使用ddt 修饰 2. 不同形式的参数化: 列表,字典&a…...

Acode:重新定义Android移动代码编辑体验
Acode:重新定义Android移动代码编辑体验 【免费下载链接】Acode Acode - powerful text/code editor for android 项目地址: https://gitcode.com/gh_mirrors/ac/Acode 在移动开发日益普及的今天,拥有一款高效的移动代码编辑器成为开发者的迫切需…...
)
PX4无人机开发实战:5个关键ROS话题的订阅与发布详解(附代码示例)
PX4无人机开发实战:5个关键ROS话题的订阅与发布详解(附代码示例) 当你在PX4无人机开发中首次接触ROS通信时,可能会被各种话题和服务搞得晕头转向。作为连接飞控与外部系统的桥梁,这些通信接口直接决定了无人机的可控性…...

深入解析74181芯片中Cn+1的进位逻辑与实现原理
1. 74181芯片与Cn1进位的基础认知 第一次接触74181这块经典ALU芯片时,我被它内部精巧的进位逻辑设计震撼到了。这块诞生于上世纪60年代的4位算术逻辑单元,至今仍是理解计算机运算基础的绝佳教学案例。其中最精妙的部分莫过于Cn1进位信号的生成机制——它…...

终极指南:procs如何彻底改变DevOps工作流?监控、调试、优化的完整解决方案
终极指南:procs如何彻底改变DevOps工作流?监控、调试、优化的完整解决方案 【免费下载链接】procs A modern replacement for ps written in Rust 项目地址: https://gitcode.com/gh_mirrors/pr/procs procs是一款用Rust编写的现代进程查看工具&a…...

OpenClaw+nanobot科研利器:自动抓取论文并生成综述
OpenClawnanobot科研利器:自动抓取论文并生成综述 1. 为什么需要自动化文献综述工具 作为一名经常需要跟踪前沿研究的科研工作者,我深刻体会到手动整理文献的痛苦。每次开题或写综述时,需要花费大量时间在arXiv、PubMed等平台反复搜索、下载…...

ViGEmBus虚拟游戏手柄驱动:重构Windows输入控制生态的核心引擎
ViGEmBus虚拟游戏手柄驱动:重构Windows输入控制生态的核心引擎 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus 一、价值定位:虚拟设备…...
)
DanKoe 视频笔记:一人企业构建指南:从零到百万美元的教育业务(每日工作2-4小时)
在本课程中,我们将学习如何构建一个单人教育业务,实现从零到年收入百万美元的目标,同时将每日工作时间控制在2-4小时。我们将探讨其核心理念、实施步骤以及背后的进化逻辑。 概述 传统的创业路径往往伴随着高风险、高投入和漫长的工作时间。…...

Web3j区块链开发实战:Java开发者的以太坊交互指南
Web3j区块链开发实战:Java开发者的以太坊交互指南 【免费下载链接】web3j Lightweight Java and Android library for integration with Ethereum clients 项目地址: https://gitcode.com/gh_mirrors/we/web3j 1. 核心价值解析:Web3j为何成为Java…...

想实现SpringCloud的负载均衡,需要实现哪些接口和规范
前几天有个大兄弟问了我一个问题,注册中心要集成SpringCloud,想实现SpringCloud的负载均衡,需要实现哪些接口和规范。既然这个兄弟问到我了,而我又刚好知道,这不得好好写一篇文章来回答这个问题,虽然在后面…...

HIL测试入门避坑指南:从CANoe配置到故障注入的完整踩坑实录
HIL测试实战避坑手册:从零搭建车窗ECU测试台架的12个关键陷阱 第一次接触HIL测试时,我盯着实验室里那些闪烁的指示灯和缠绕的线缆,仿佛面对着一个未知的宇宙。作为车载测试领域最具挑战性的环节之一,HIL测试既是验证ECU可靠性的终…...