c语言实现堆
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 一、树
- 1、树的概念
- 2、树的相关概念
- 3、树的表示
- 二、二叉树
- 1、二叉树概念
- 2、特殊的二叉树
- 3、二叉树的性质
- 4、二叉树的顺序结构
- 5、二叉树的链式结构
- 三、堆(二叉树的顺序结构)
- 1、堆(二叉树的顺序结构)的介绍
- 2、堆(二叉树的顺序结构)的概念及结构
- 3、堆的实现
- 4、堆排序
- 5、计算堆排序中向上调整建堆和向下调整建堆的时间复杂度
前言
一、树
1、树的概念
在学习堆之前我们需要对数据结构中的树结构先有一定的了解。数据结构中的树结构就像一棵真正的倒置的树一样。树是一种非线性的数据结构,它是由n(n>=0)个有限结点组成一个具有层次关系的集合。把它叫做树是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。
有一个特殊的结点,称为根结点,根节点没有前驱结点。
除根节点外,其余结点被分成M(M>0)个互不相交的集合T1、T2、……、Tm,其中每一个集合Ti(1<= i <= m)又是一棵结构与树类似的子树。每棵子树的根结点有且只有一个前驱,可以有0个或多个后继。
因此,树是递归定义的。

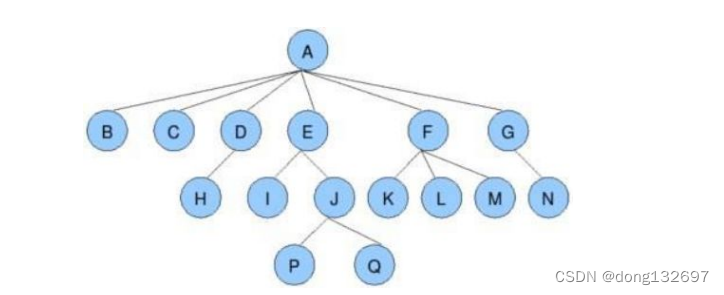
2、树的相关概念
节点的度:一个节点含有的子树的个数称为该节点的度; 如上图:A的为6
叶节点或终端节点:度为0的节点称为叶节点; 如上图:B、C、H、I…等节点为叶节点
非终端节点或分支节点:度不为0的节点; 如上图:D、E、F、G…等节点为分支节点
双亲节点或父节点:若一个节点含有子节点,则这个节点称为其子节点的父节点; 如上图:A是B的父节点
孩子节点或子节点:一个节点含有的子树的根节点称为该节点的子节点; 如上图:B是A的孩子节点
兄弟节点:具有相同父节点的节点互称为兄弟节点; 如上图:B、C是兄弟节点
树的度:一棵树中,最大的节点的度称为树的度; 如上图:树的度为6
节点的层次:从根开始定义起,根为第1层,根的子节点为第2层,以此类推;
树的高度或深度:树中节点的最大层次; 如上图:树的高度为4
堂兄弟节点:双亲在同一层的节点互为堂兄弟;如上图:H、I互为兄弟节点
节点的祖先:从根到该节点所经分支上的所有节点;如上图:A是所有节点的祖先
子孙:以某节点为根的子树中任一节点都称为该节点的子孙。如上图:所有节点都是A的子孙
森林:由m(m>0)棵互不相交的树的集合称为森林;
3、树的表示
树结构相对线性表就比较复杂了,要存储表示起来就比较麻烦了,既然保存值域,也要保存结点和结点之间
的关系,实际中树有很多种表示方式如:双亲表示法,孩子表示法、孩子双亲表示法以及孩子兄弟表示法
等。我们这里就简单的了解其中最常用的孩子兄弟表示法。
下面为左孩子右兄弟表示法,即结点只存储它的第一个孩子和它的右兄弟。这样就可以将一棵树的结构用代码表示出来。
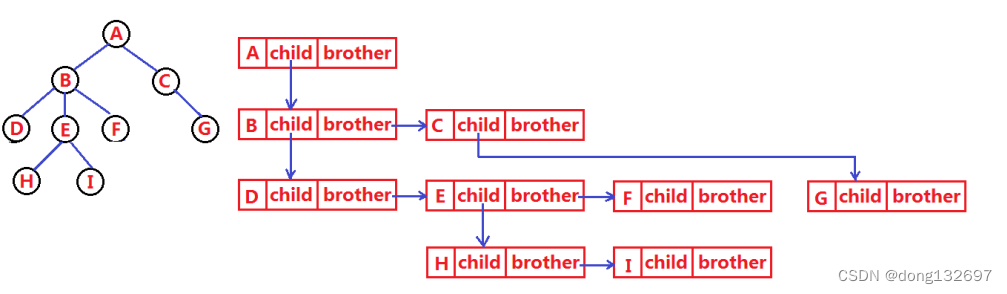
typedef int DataType;
struct TreeNode
{struct TreeNode* firstChild1; //存储第一个孩子结点的地址struct TreeNode* pNextBrother; //指向其下一个兄弟结点DataType data; //结点中的数据域
};
二、二叉树
1、二叉树概念
一棵二叉树是结点的一个有限集合,该集合:
1.或者为空。
2. 由一个根节点加上两棵分别称为左子树和右子树的二叉树组成。
 从上图可以看出:
从上图可以看出:
1.二叉树不存在度大于2的结点。
2.二叉树的子树有左右之分,次序不能颠倒,因此二叉树是有序树
注意:对于任意的二叉树都是由以下几种情况复合而成的:

2、特殊的二叉树
1.满二叉树:一个二叉树,如果每一个层的结点数都达到最大值,则这个二叉树就是满二叉树。也就是
说,如果一个二叉树的层数为K,且结点总数是 ,则它就是满二叉树。
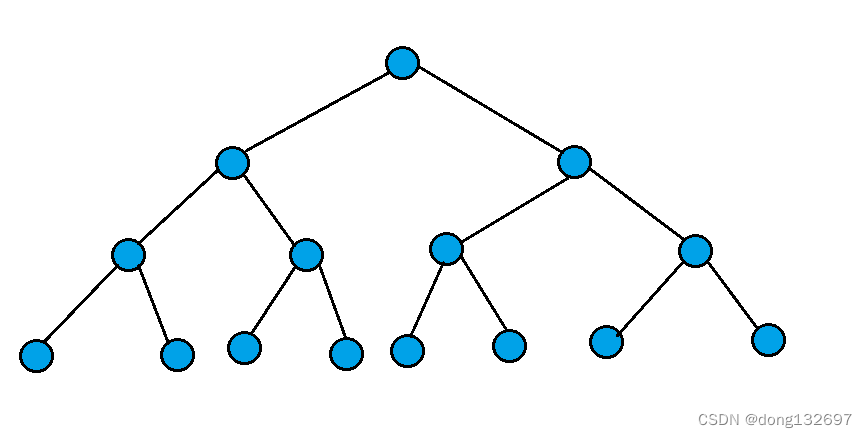
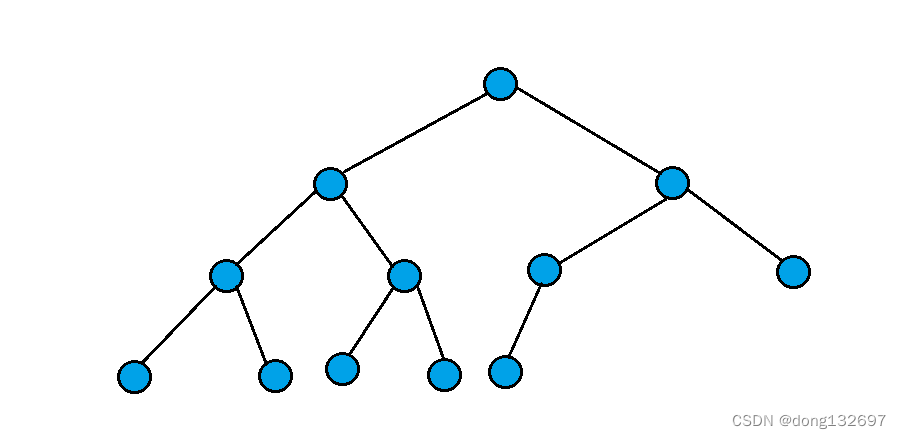
2.完全二叉树:完全二叉树是效率很高的数据结构,完全二叉树是由满二叉树而引出来的。对于深度为K
的,有n个结点的二叉树,当且仅当其每一个结点都与深度为K的满二叉树中编号从1至n的结点一一对
应时称之为完全二叉树。 要注意的是满二叉树是一种特殊的完全二叉树。
3、二叉树的性质
1.若规定根节点的层数为1,则一棵非空二叉树的第i层上最多有2^(i-1)个结点。
2. 若规定根节点的层数为1,则深度为h的二叉树的最大结点数是2^h - 1。
3. 对任何一棵二叉树, 如果度为0的结点,即叶结点个数为m, 度为2的结点个数为n,则有m= n+1
4. 若规定根节点的层数为1,具有n个结点的满二叉树的深度,h=log(n+1)。(ps: log(n+1)是log以2为底,n+1为对数)
5. 对于具有n个结点的完全二叉树,如果按照从上至下从左至右的数组顺序对所有节点从0开始编号,则对于序号为i的结点有:
(1).若i>0,i位置节点的双亲序号:(i-1)/2;若i=0,i为根节点编号,无双亲节点
(2).若2i+1<n,左孩子序号:2i+1;若2i+1>=n,则无左孩子
(3). 若2i+2<n,右孩子序号:2i+2;若2i+2>=n,则无右孩子
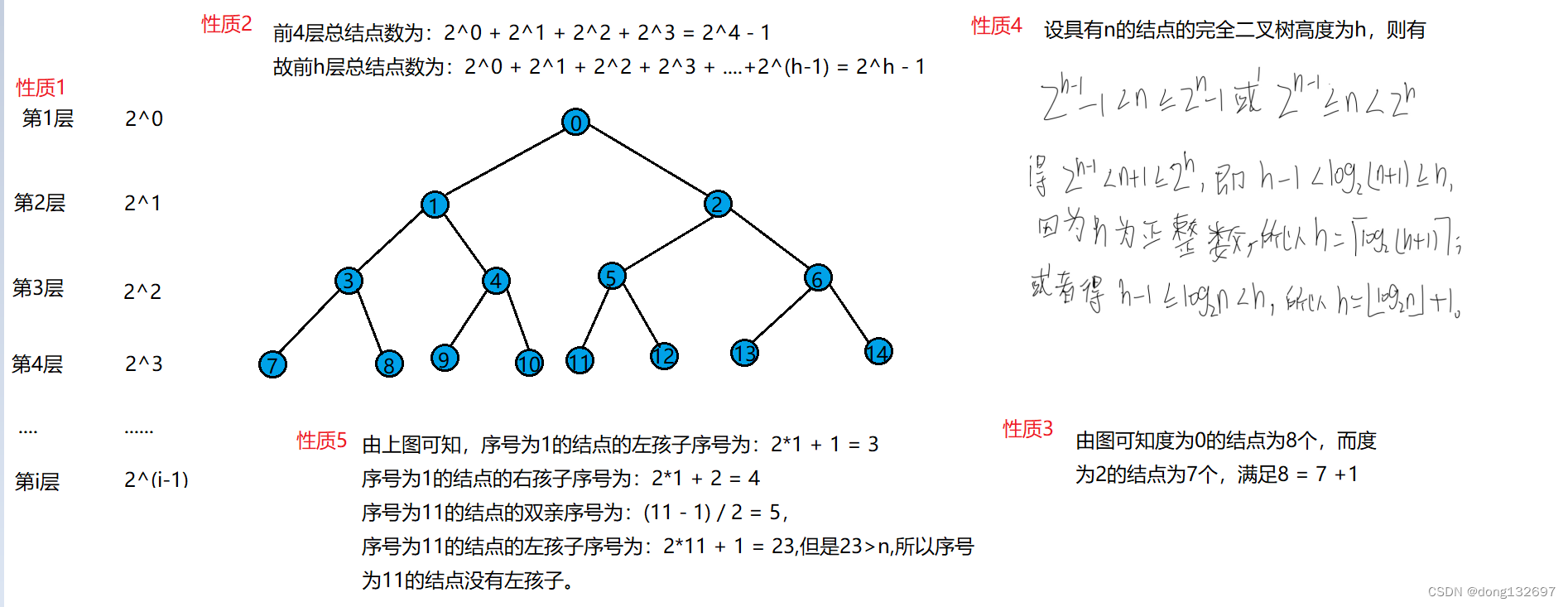
4、二叉树的顺序结构
二叉树一般可以使用两种结构存储,一种顺序结构,一种链式结构。
顺序结构存储就是使用数组来存储,一般使用数组只适合表示完全二叉树,因为不是完全二叉树会有空间的浪费。而现实中使用中只有堆才会使用数组来存储,二叉树顺序存储在物理上是一个数组,在逻辑上是一颗二叉树。
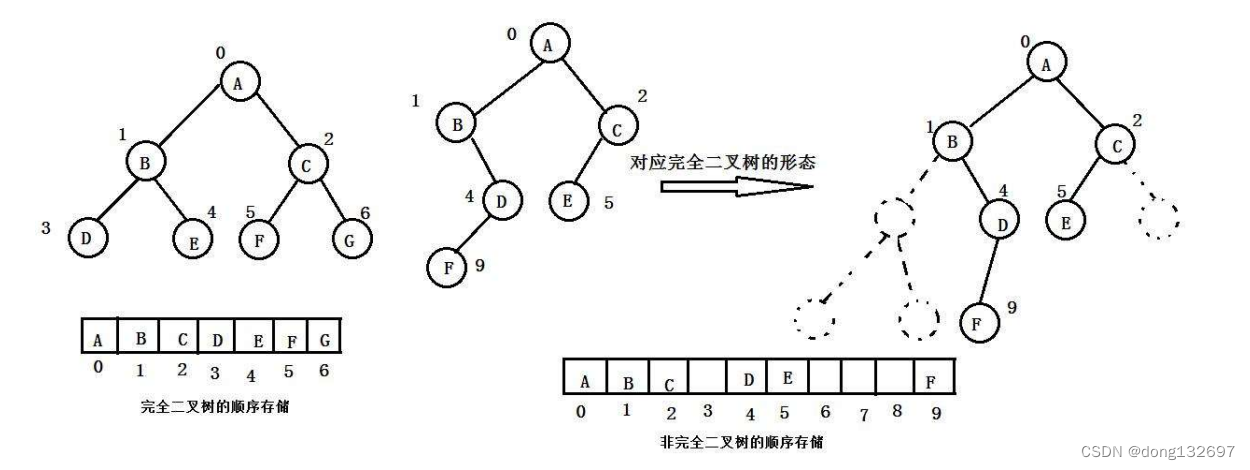
5、二叉树的链式结构
本篇文章讲解的为用数组来实现完全二叉树,即堆的实现。二叉树的详细介绍可以点击下面链接进入二叉树文章。
三、堆(二叉树的顺序结构)
1、堆(二叉树的顺序结构)的介绍
普通的二叉树是不适合用数组来存储的,因为可能会存在大量的空间浪费。而完全二叉树更适合使用顺序结构存储。现实中我们通常把堆(一种二叉树)使用顺序结构的数组来存储,需要注意的是这里的堆和操作系统虚拟进程地址空间中的堆是两回事,一个是数据结构,一个是操作系统中管理内存的一块区域分段。
2、堆(二叉树的顺序结构)的概念及结构

堆的性质:
堆中某个节点的值总是不大于或不小于其父节点的值;
堆总是一棵完全二叉树。
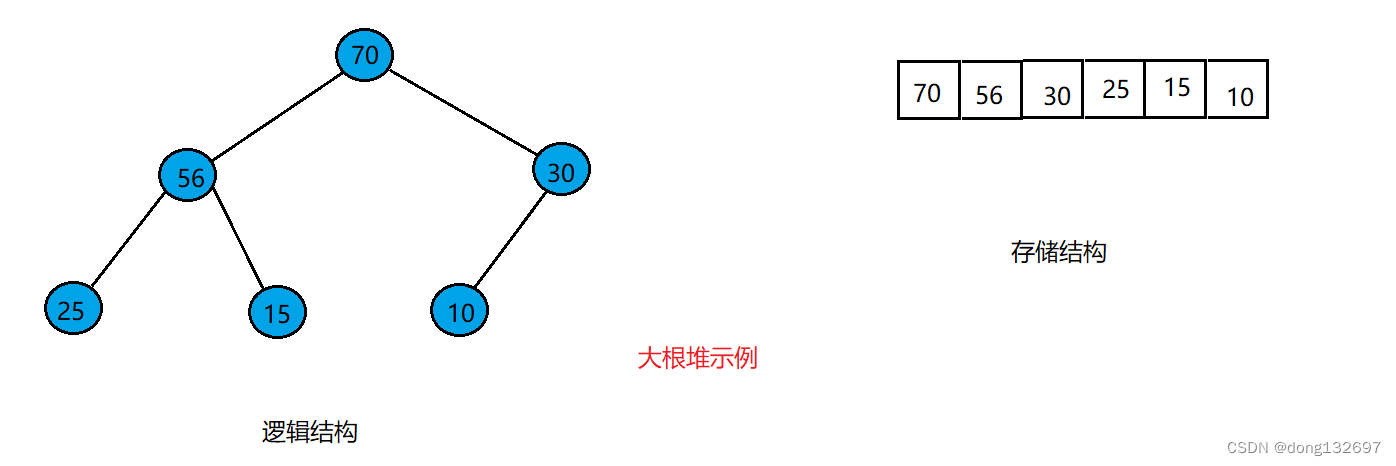
小根堆如图所示。其每个结点的值都大于双亲结点的值。
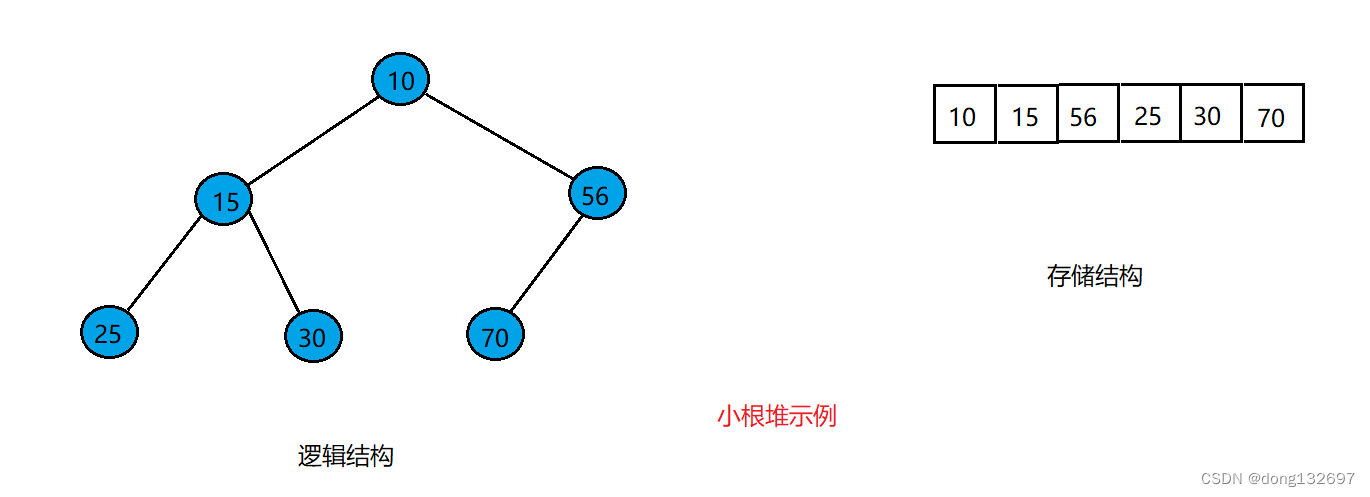
大根堆如图所示。其每个结点的值都小于双亲结点的值。
3、堆的实现
堆就是使用顺序结构的的数组来存储的树,所以定义堆时就是定义一个动态申请大小的数组。下面我们以建立一个小堆为例。
typedef int HPDataType;
typedef struct Heap
{HPDataType* data;int size;int capacity;
}HP;
然后在使用堆时创建一个HP结构体就代表创建了一个堆。堆的初始化就是将堆中用来存储数据的数组先指向NULL,然后将size和capacity置为0。
void HeapInit(HP* php)
{assert(php);php->data = NULL;php->size = 0;php->capacity = 0;
}
当需要向堆中插入数据时,要先检查堆中存储数据的数组是否已满,如果满了就要进行扩容。
void HeapPush(HP* php,HPDataType x)
{assert(php);if (php->size == php->capacity){int newCapacity = (php->capacity == 0) ? 4 : (php->capacity) * 2;HPDataType* tmp = (HPDataType*)realloc(php->data, sizeof(HPDataType) * newCapacity);if (tmp == NULL){perror("realloc fail");exit(-1);}php->data = tmp;php->capacity = newCapacity;}php->data[php->size] = x;php->size++;//新插入的元素可能不符合堆,所以需要向上调整。AdjustUp(php->data, php->size - 1);
}
在我们向数组中插入数据时,可能新插入的数据已经不满足小根堆的要求,这时我们就要将新插入的元素进行向上调整,即通过新插入元素在数组中的下标,找到其双亲结点,然后与双亲结点的值进行比较,如果新插入结点的值小于双亲结点的值的话,就让这两个结点的值进行比较。例如有如下图所示的一个堆。此时该堆为小根堆。
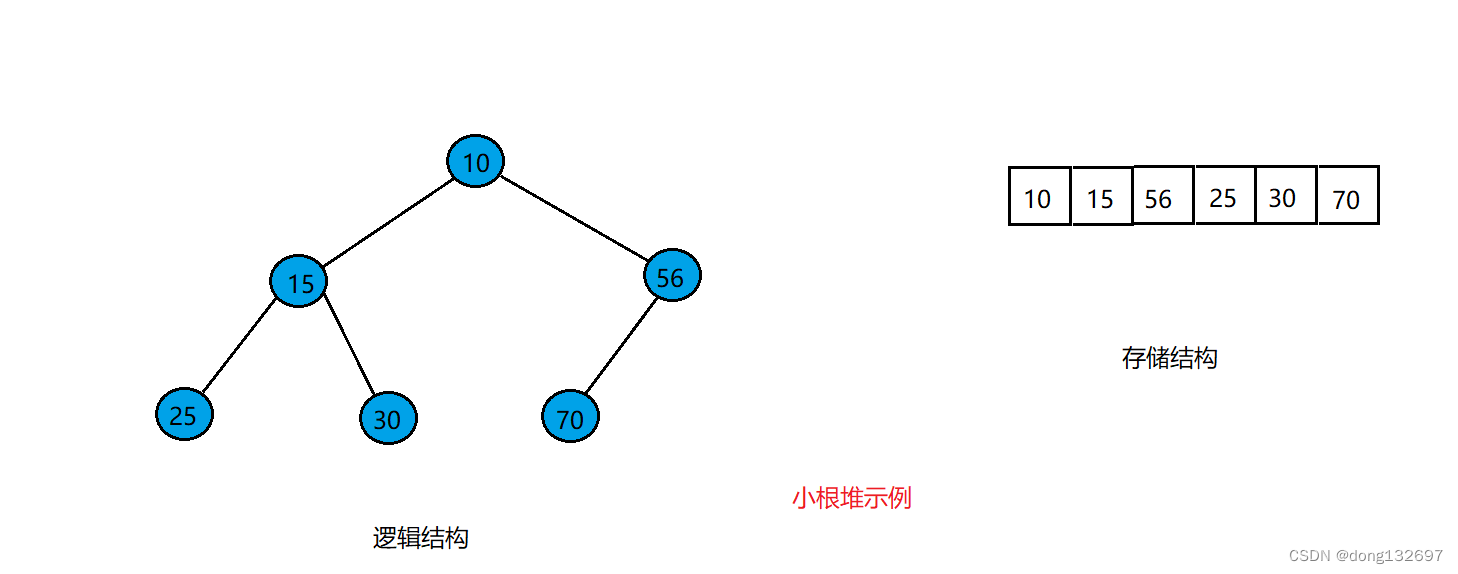
当要向数组中再插入一个5时,此时将数组中的值按堆的逻辑结构表示出来,则可以看到堆已经不满足小根堆了,这时就需要将新插入的元素5进行向上调整,使其满足小根堆的定义,
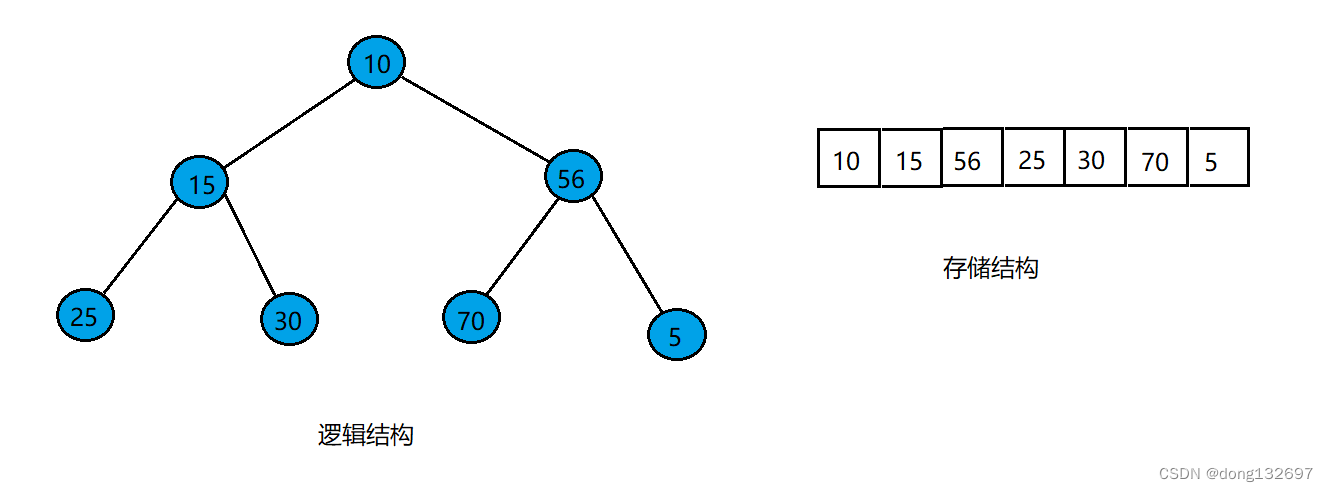
值为5的结点向上调整就是通过5的下标算出其双亲结点值为56,因为小根堆中双亲结点的值要小于子结点的值,所以要将该组父子结点的值交换。
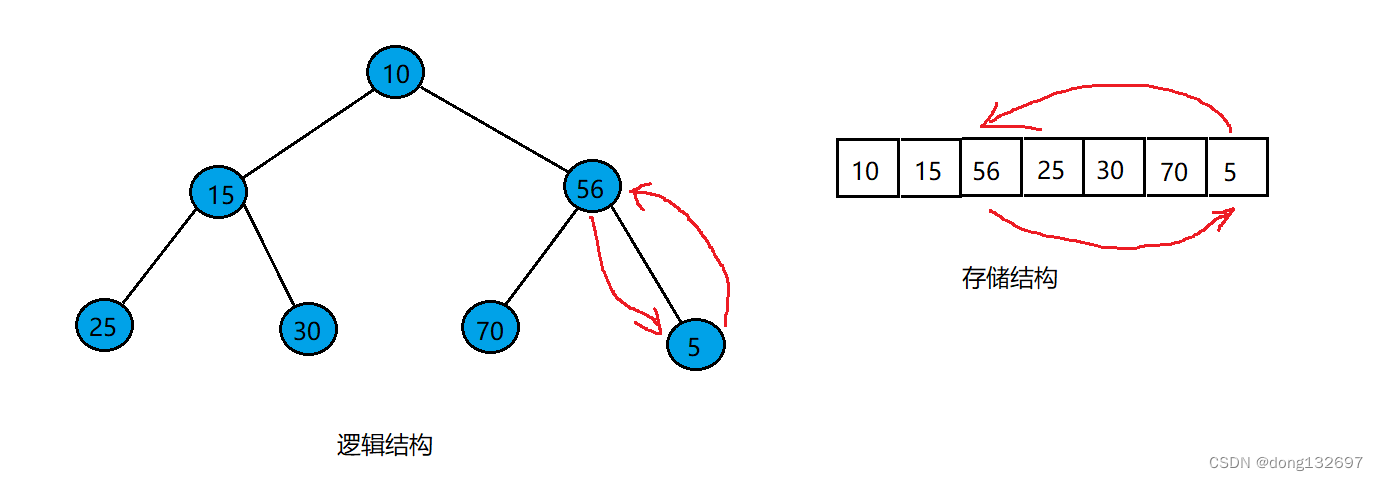
此时交换后的数组数据变为如下图所示。
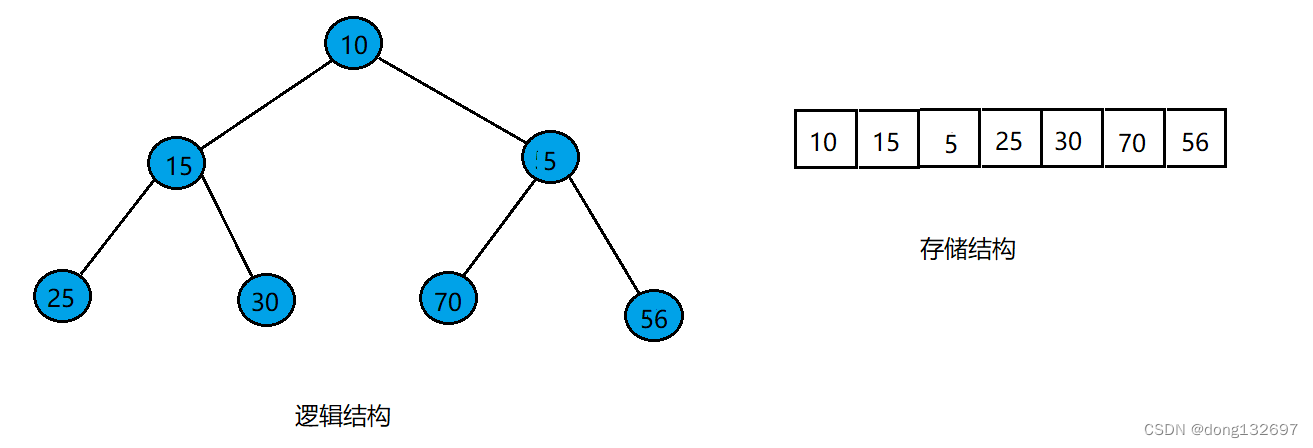
可以看到交换一次后值为5的结点还是小于它的双亲结点的值,所以还需要将5进行向上调整,即将5变为根节点。此时数组表示的小根堆才正确。到此就完成了堆中插入一个新元素,然后将该元素向上调整直到该元素到达满足小根堆的位置。
上面的向上调整的代码如下所示。
void Swap(HPDataType* parent, HPDataType* child)
{assert(parent && child);//交换内存中两个地址中的值。HPDataType tmp = *parent;*parent = *child;*child = tmp;
}void AdjustUp(HPDataType* arr, int child)
{assert(arr);//如果该结点还不是根结点就一直判断该结点与其父节点值的大小while (child > 0){//先求出该结点的父结点int parent = (child - 1) / 2;//如果该结点的值小于其父结点的值,就让这两个元素交换位置。if (arr[child] < arr[parent]){//让这组父子结点交换位置Swap(&arr[parent], &arr[child]);//然后将新的父节点作为孩子,再次与它的父结点比较大小。child = parent;}//如果该结点的值大于其父节点,说明满足小根堆的要求,则不需要处理,直接跳出循环else{break;}}
}
因为小根堆中每次新结点插入都要进行向上调整,所以小根堆中根结点的值是最小的,当我们要删除堆中的值时,就是删除堆的根结点。此时如果直接将数组中的数据都向前移一位的话,则处理完后的数组的值转换为二叉树后不满足小根堆了。此时我们可以将数组中最后一个元素与下标为0的元素进行交换,然后将数组中下标为0的元素进行向下调整。如图此时为一个存储小根堆的数组。
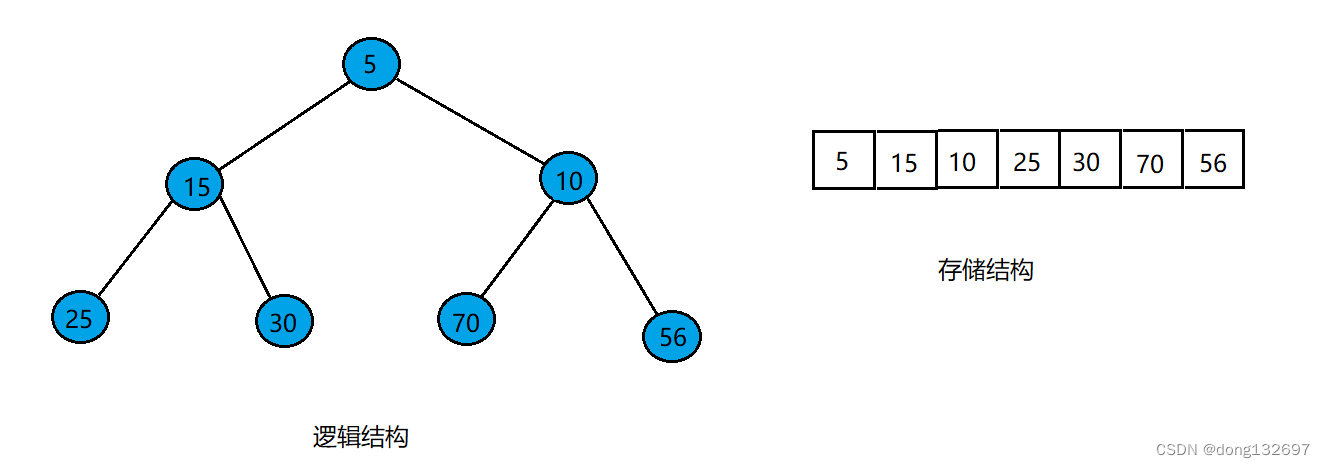
当我们需要将堆的根节点进行删除时,就先将数组中下标为0的元素和最后一个元素进行交换。
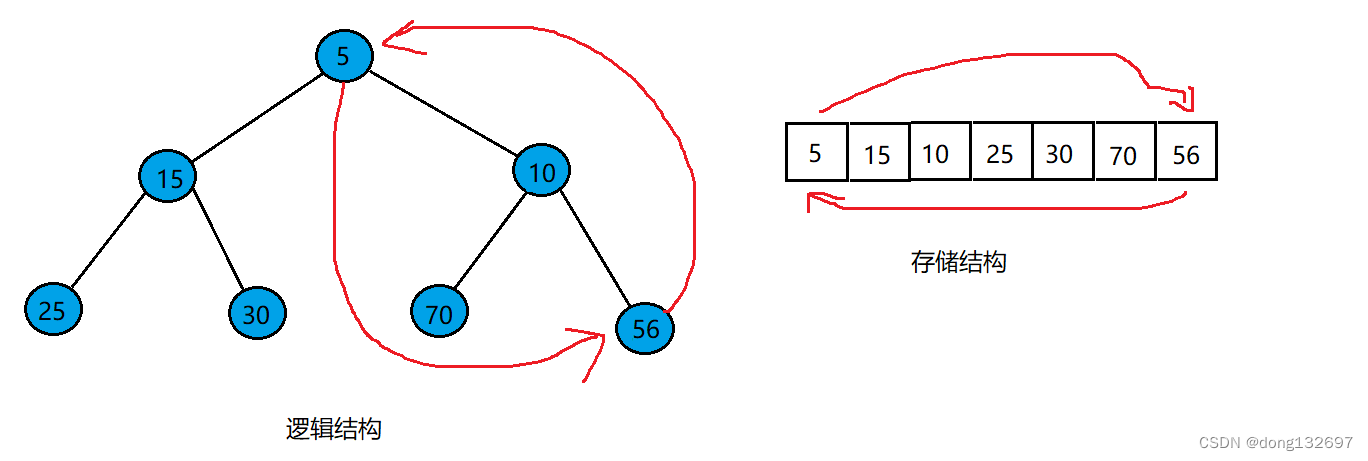
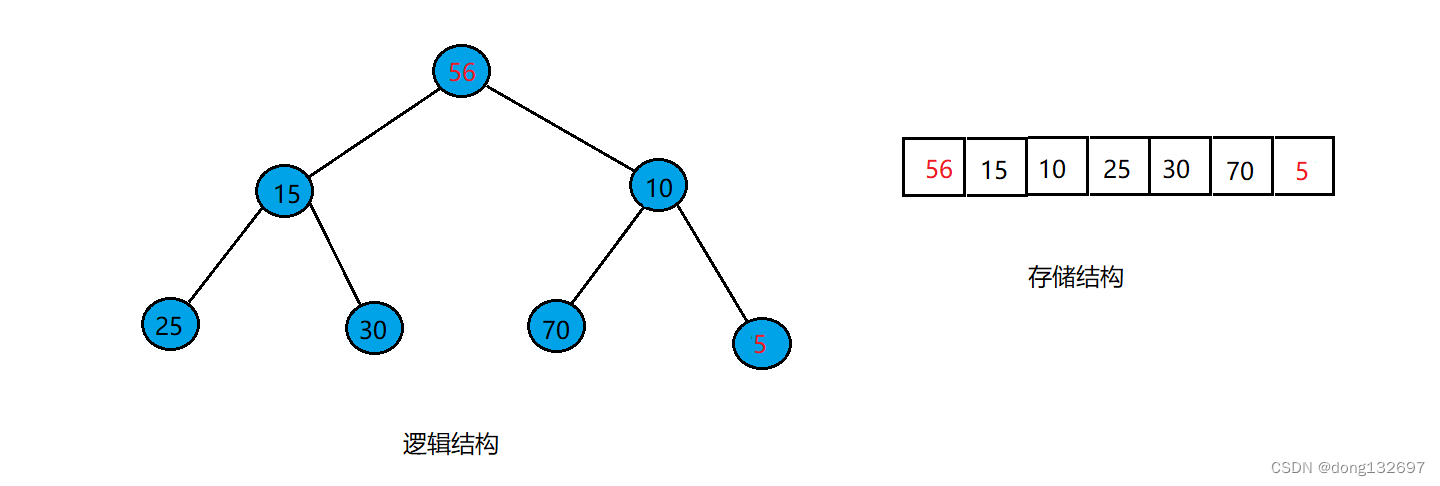
此时将数组的长度-1,则值为5的结点就被删除了,可以看到此时数组并不能正确表示一个小根堆,所以此时要将根结点进行向下调整,即将根结点与它的两个孩子中最小的孩子进行比较,如果大于它的最小孩子的值,就将该对父子结点进行位置交换。交换过后就可以看到此时数组中存储的元素转换为堆后符合小根堆的定义。
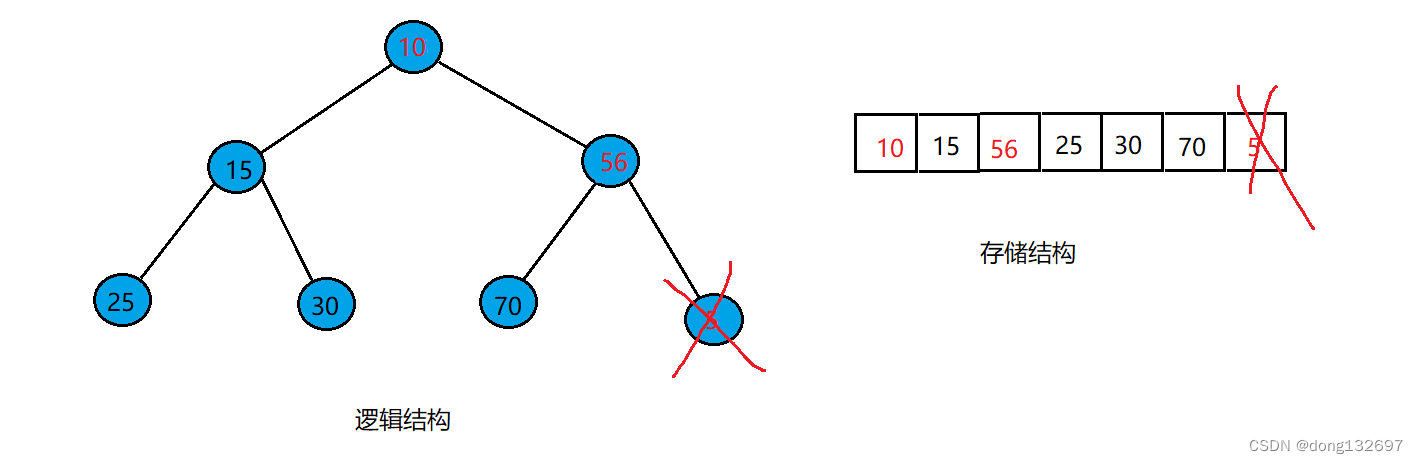
void HeapPop(HP* php)
{assert(php);//先将数组中下标为0的元素与数组中最后一个元素交换Swap(&(php->data[0]), &(php->data[php->size - 1]));//然后此时数组中最后一个元素即为堆中最小的元素,数组长度-1即代表删除了最后一个元素php->size--;//然后将此时数组中下标为0的元素进行向下调整,以使数组满足小根堆的定义AdjustDown(php->data, php->size, 0);
}void AdjustDown(HPDataType* arr, int size, int parent)
{assert(arr);//先求出该父结点的左孩子int child = 2 * parent + 1;//如果该父结点的孩子结点的在数组中,则将该父结点与孩子结点进行比较while (child<size){//上面求的是父节点的左孩子,但是父节点要与最小的孩子结点进行比较,所以当父结点有右孩子//且右孩子小于左孩子时,就将该父节点与右孩子进行比较if (child+1<size&&arr[child + 1] < arr[child]){child++;}//如果该父节点大于其最小的孩子,就让这两个结点交换位置if (arr[child] < arr[parent]){//该组父子结点交换位置Swap(&arr[child], &arr[parent]);//然后让孩子结点的位置作为父结点位置parent = child;//再次求出新父节点的孩子结点的位置child = 2 * parent + 1;}else{break;}}}
返回堆顶元素就是将小根堆中最小的值返回,即将数组下标为0的元素返回。
HPDataType HeapTop(HP* php)
{assert(php);if (!HeapEmpty(php)){return php->data[0];}
}
判断堆是否为空和返回堆的大小直接使用size就可以判断。
bool HeapEmpty(HP* php)
{assert(php);if (php->size == 0){return true;}else{return false;}
}int HeapSize(HP* php)
{assert(php);return php->size;
}
销毁堆就是将动态申请的数组的空间都释放。
void HeapDestroy(HP* php)
{assert(php);free(php->data);php->data = NULL;php->size = 0;php->capacity = 0;
}
当我们建立好一个堆,然后实现了堆的上述操作后,我们就可以使用堆的一些操作来完成数组的升序或降序打印,值得注意的是,当我们要升序打印时,我们需要建立小堆,然后打印堆顶的最小元素,然后将堆顶元素删除,此时剩余元素中最小值会被处理为堆顶。这样我们每次打印的都是堆中最小的元素。当需要降序打印时,需要建立大堆,这样每次打印出来的元素都是最大值。
void TestHeapSort()
{//升序打印 -- 小堆//降序打印 -- 大堆HP hp;HeapInit(&hp);int a[] = { 27,15,19,18,28,34,65,49,25,37 };for (int i = 0; i < sizeof(a) / sizeof(a[0]); ++i){//将数组中的元素依次进入堆,然后形成堆结构HeapPush(&hp, a[i]);}//此时堆中每次拿出来的堆顶元素都是最小值(小堆)/最大值(大堆)while (!HeapEmpty(&hp)){//打印出来堆顶元素printf("%d ", HeapTop(&hp));//将堆顶元素删除,此时堆中会将次小值作为新的堆顶HeapPop(&hp);}printf("\n");
}
4、堆排序
当我们实现了一个堆后,我们就可以利用堆来写堆排序,我们可以使用堆的返回堆顶操作来得到堆中的最大值/最小值。我们先将目标数组中的元素都存入到堆中,然后将堆中的堆顶元素,即最大值/最小值依次存到目标数组中。但是这样实现的堆排序在使用之前还要先写一个堆数据结构,然后实现堆的一系列操作之后,才能调用该堆排序函数。并且该堆排序因为在堆中建立了一个新数组,所以有O(N)的空间复杂度。
void HeapSort(int* arr, int size)
{//先建立一个堆结构;HP hp;HeapInit(&hp);//然后将目标数组arr中的元素都存入堆中for (int i = 0; i < size; i++){HeapPush(&hp, arr[i]);}int i = 0;//然后将堆中的堆顶元素都出来,再存入目标数组中。while (!HeapEmpty(&hp)){arr[i++] = HeapTop(&hp);//堆中最大值/最小值存到目标数组后,将堆顶元素删除,以便找到新的堆顶元素HeapPop(&hp);}HeapDestroy(&hp);
}
上述的堆排序在使用前,还需要写出堆的一系列操作,真正的堆排序不要借用堆的操作,所以不使用上面的方法来写堆排序。我们可以在main函数中建立一个数组,然后将数组传入HeapSort()函数中,通过HeapSort()函数将该数组排序为升序数组或降序数组。在HeapSort()函数中,我们需要先将传进来的目标数组用向上调整或向下调整变为一个堆,然后通过将堆中最大的元素或最小的元素放入数组最后一个,次大的元素或次小的元素放入数组倒数第二个这样的方式,将数组变为升序数组或者降序数组。
此时堆排序中如果要将数组变为降序数组,则需要将数组建为小堆。如果要将数组变为升序数组,则需要将数组建为大堆。
void HeapSort(int* arr, int size)
{//当要给一个数组进行堆排序时,首先我们要先将该数组变为一个堆。//利用向上调整来建堆//时间复杂度为O(N*logN)//int i = 0;//for (i = 1; i < size; i++)//{// //从该数组下标为1的元素开始,依次进行向上调整,依次来将arr数组变为一个堆// AdjustUp(arr, i);//}//利用向下调整来建堆//时间复杂度为O(N)int i = 0;for (i = (size - 1 - 1) / 2; i >= 0; --i){AdjustDown(arr, size, i);}//此时的arr已经为一个堆,因为此时为小根堆,所以堆顶为数组中最小值,//此时我们将数组下标为0的元素,即最小值,与数组最后一个元素交换,则数组最后一个元素存的就为最小值//然后我们再将此时下标为0的元素向下调整,恢复数组为一个小根堆,此时数组的最后一个元素就是最小值//依次循环得到数组的次小值存入数组倒数第二个位置中,就这样一直循环,直到剩下数组中下标为0的元素,此时下标为0的元素为最大值。int end = size - 1;while (end > 0){Swap(&arr[0], &arr[end]);AdjustDown(arr, end, 0);--end;}
}
5、计算堆排序中向上调整建堆和向下调整建堆的时间复杂度
相关文章:
c语言实现堆
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、树1、树的概念2、树的相关概念3、树的表示 二、二叉树1、二叉树概念2、特殊的二叉树3、二叉树的性质4、二叉树的顺序结构5、二叉树的链式结构 三、堆(二叉树…...

ubuntu 如何将文件打包成tar.gz
要将文件打包成.tar.gz文件,可以使用以下命令: tar -czvf 文件名.tar.gz 文件路径 其中,-c表示创建新的归档文件,-z表示使用gzip进行压缩,-v表示显示详细的打包过程,-f表示指定归档文件的名称。 例如&am…...
)
前端优化页面加载速度的方法(持续更新)
提速方法方向 延迟脚本加载 使用 async 属性: 在这种方法中,脚本将在下载完成后立即执行,而不会阻塞其他页面资源的加载和渲染。这适用于那些不依赖于其他脚本和页面内容的脚本,例如分析脚本等。示例如下: html …...

利用SSL证书的SNI特性建立自己的爬虫ip服务器
今天我要和大家分享一个关于自建多域名HTTPS爬虫ip服务器的知识,让你的爬虫ip服务器更加强大!无论是用于数据抓取、反爬虫还是网络调试,自建一个支持多个域名的HTTPS爬虫ip服务器都是非常有价值的。本文将详细介绍如何利用SSL证书的SNI&#…...

HTML和CSS
HTML HTML(Hyper Text Markup Language):超文本语言 超文本:超越了文本的限制,比普通文本更强大。除了文字信息,还可以定义图片、音频、视频等内容。 标记语言:由标签构成的语言 HTML标签都是预定义好的。例如:使用&l…...

C#的IndexOf
在 C# 中,IndexOf 是一个字符串、数组或列表的方法,用于查找指定元素的第一个匹配项的索引。它返回一个整数值,表示匹配项在集合中的位置,如果未找到匹配项,则返回 -1。 IndexOf 方法有多个重载形式,可以根…...

深度学习2.神经网络、机器学习、人工智能
目录 深度学习、神经网络、机器学习、人工智能的关系 大白话解释深度学习 传统机器学习 VS 深度学习 深度学习的优缺点 4种典型的深度学习算法 卷积神经网络 – CNN 循环神经网络 – RNN 生成对抗网络 – GANs 深度强化学习 – RL 总结 深度学习 深度学习、神经网络…...

利用LLM模型微调的短课程;钉钉宣布开放智能化底座能力
🦉 AI新闻 🚀 钉钉宣布开放智能化底座能力AI PaaS,推动企业数智化转型发展 摘要:钉钉在生态大会上宣布开放智能化底座能力AI PaaS,与生态伙伴探寻企业服务的新发展道路。AI PaaS结合5G、云计算和人工智能技术的普及和…...
 UML之用例图详解)
软件工程(七) UML之用例图详解
1、UML-4+1视图 UML-4+1视图将会与后面的架构4+1视图会一一对应上 视图往往出现在什么场景:我们看待一个事物,我们觉得它很复杂,难以搞清楚,为了化繁为简,我们会从一个侧面去看,这就是视图。而4+1视图就是分不同角度去看事物。 逻辑视图(logical view) 一般使用类与对…...
pd.cut()函数--Pandas
1. 函数功能 将连续性数值进行离散化处理:如对年龄、消费金额等进行分组 2. 函数语法 pandas.cut(x, bins, rightTrue, labelsNone, retbinsFalse, precision3, include_lowestFalse, duplicatesraise, orderedTrue)3. 函数参数 参数含义x要离散分箱操作的数组&…...

DataBinding的基本使用
目录 一、MVC、MVP和MVVM框架的使用场景二、Java使用 一、MVC、MVP和MVVM框架的使用场景 MVC: 适用于小型项目,够灵活, 缺点:Activity不仅要做View的事情还要做控制和模型的处理,导致Activity太过臃肿,管理…...
eslint和prettier格式化冲突
下载插件 ESLint 和 Prettier ESLint 进入setting.json中 setting.json中配置 {"editor.tabSize": 2,"editor.linkedEditing": true,"security.workspace.trust.untrustedFiles": "open","git.autofetch": true,"…...
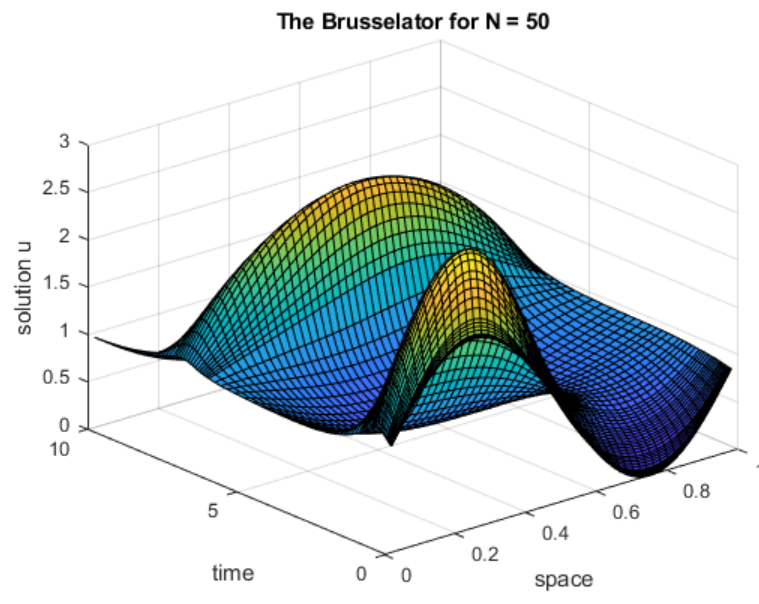
matlab使用教程(26)—常微分方程的求解
1.求解非刚性 ODE 本页包含两个使用 ode45 来求解非刚性常微分方程的示例。MATLAB 提供几个非刚性 ODE 求解器。 • ode45 • ode23 • ode78 • ode89 • ode113 对于大多数非刚性问题,ode45 的性能最佳。但对于允许较宽松的误差容限或刚度适中的问题&…...

尚硅谷宋红康MySQL笔记 14-18
是记录,不会太详细,受本人知识限制会有错误,会有个人的理解在里面 第14章 视图 了解一下,数据库的常见对象 对象描述表(TABLE)表是存储数据的逻辑单元,以行和列的形式存在,列就是字段,行就是记…...
香港全新的虚拟资产服务商发牌制度
香港证监会2023年2月20日通告,原有虛擬資產交易平台如要符合資格參與當作為獲發牌的安排,必須在2023 年6 月1 日至2024 年2 月29 日期間(即由2023 年6 月1 日37起計九個月內)內,根據《打擊洗錢條例》下的虛擬資產服務提供者制度在網上提交完全…...

C# 泛型
目录 一、前言 二、相关内容 1、什么是泛型? 2、泛型类 3、泛型方法 4、限定类型参数 4.1、 类型参数的基本约束 4.2、接口约束 4.3、基类约束 4.5、泛型参数与限定类型参数的关系 4.6、自定义约束 5、使用泛型的好处 5.1、代码复用性 5.2、类型安全…...
servlet,Filter,责任的设计模式,静态代理
servlet servlet是前端和数据库交互的一个桥梁 静态网页资源的技术:在前端整个运行的过程中 我们的网页代码不发生改变的这种情况就称为静态的网页资源技术动态网页资源的技术:在前端运行的过程中 我们的前端页面代码会发生改变的这种情况就称为 动态的网…...
:按位运算符(上))
C++中的运算符总结(5):按位运算符(上)
C中的运算符总结(5):按位运算符(上) 9、按位运算符 NOT( ~)、 AND( &)、 OR( |)和 XOR( ^) 逻辑运算符和…...

8.Oracle中多表连接查询方式
表连接分类: 内连接、外连接、交叉连接、自连接 1 内连接 内连接是一种常见的多表关联查询方式,一般使用关键字INNER JOIN来实现。其中,INNER关键字可以省略,当只使用JOIN关键字时,语句只表示内连接操作。在使用内连…...
Linux 安装mysql(ARM架构)
添加mysql用户组和mysql用户 安装依赖libaio yum install -y libaio* 下载Mysql wget https://obs.cn-north-4.myhuaweicloud.com/obs-mirror-ftp4/database/mysql-5.7.27-aarch64.tar.gz安装mysql 解压Mysql tar xvf mysql-5.7.27-aarch64.tar.gz -C /usr/local/ 重命名 …...

为什么92%参会者在P3东区绕行超4分钟?2026大会停车动线算法白皮书首度披露
更多请点击: https://intelliparadigm.com 第一章:2026年AI技术大会停车指引概览 2026年AI技术大会主会场设于上海张江科学城国际会展中心,周边共开放3个智能停车场(P1–P3),全部支持车牌自动识别、无感支…...

Let‘s Encrypt证书有效期缩短至90天后,如何实现自动续期
Let’s Encrypt证书有效期缩短至90天后,如何实现自动续期 打开网站突然发现浏览器地址栏一把红色小锁,提示"您的连接不是专用连接"——SSL证书过期了。这可能是站长最不想看到的画面之一:用户无法正常访问、搜索引擎排名下降、甚至…...

量子测量诱导相变在玻色系统中的实验实现
1. 量子测量诱导相变的理论基础量子测量诱导相变(Measurement-Induced Phase Transition, MIPT)是近年来量子多体物理领域的重要发现。这种相变不同于传统热力学相变,它完全由量子测量操作与酉演化之间的动态竞争所驱动。在玻色系统中&#x…...

别再硬写QMenu的width和height了!Qt样式表实战:用盒模型思维搞定菜单尺寸
用CSS盒模型思维重构Qt菜单尺寸控制逻辑 在Qt开发中,QMenu的尺寸控制一直是让开发者头疼的问题。许多从Web前端转过来的开发者会习惯性地直接设置width和height属性,却发现这些设置在QMenu上完全不起作用。这背后其实涉及到Qt样式表(QSS)与CSS在渲染逻辑…...

家庭Kubernetes场景下的Helm Chart优化实践与部署指南
1. 项目概述与核心价值 如果你和我一样,在家庭实验室里运行着一个Kubernetes集群,那么你肯定对Helm这个“包管理器”又爱又恨。爱的是它能让应用的部署和管理变得声明式和可重复,恨的是很多时候,那些来自大型官方仓库的“通用”H…...
)
SITS 2026闭门工作坊流出的7个LLM推理性能反模式(含3个被主流框架默认启用的致命配置)
更多请点击: https://intelliparadigm.com 第一章:AI原生性能优化:SITS 2026 LLM推理加速实战技巧 在 SITS 2026 基准测试中,LLM 推理延迟与显存带宽利用率成为关键瓶颈。AI 原生优化并非简单套用传统 CUDA kernel 调优ÿ…...

从零到一:树莓派Python实战DHT11温湿度传感器数据采集与解析
1. 硬件准备与环境搭建 第一次玩树莓派配传感器的新手朋友,千万别被那些专业术语吓到。我刚开始接触DHT11温湿度模块时,连杜邦线怎么插都手抖。其实需要的材料特别简单:一块树莓派(3B或4B都行)、DHT11模块(…...

脉冲神经网络硬件实现:整数状态SNN的优化策略
1. 脉冲神经网络的硬件实现挑战在神经形态计算领域,脉冲神经网络(SNN)因其生物启发特性和事件驱动的计算范式,正逐渐成为边缘计算和低功耗AI应用的重要选择。作为一名长期从事神经形态硬件设计的工程师,我见证了SNN从理…...

从冷餐台到神经拟态厨房:2026大会餐饮背后隐藏的12项IEEE P2851.3标准落地细节,仅限首批注册嘉宾解密
更多请点击: https://intelliparadigm.com 第一章:2026年AI技术大会餐饮安排总览 为保障全球参会者在高强度技术交流中的能量补给与文化体验,2026年AI技术大会(AIC 2026)联合本地智慧餐饮平台「CulinaOS」,…...

Visual Studio AI助手深度集成:提升.NET开发效率的实战指南
1. 项目概述:当AI助手住进你的IDE 如果你是一名.NET开发者,每天大部分时间都在Visual Studio里度过,那你一定经历过这样的时刻:盯着一段复杂的业务逻辑,思考如何重构;或者为一个方法编写单元测试ÿ…...