重要节点排序方法
文章目录
- 研究背景
- 提前约定
- 基于节点近邻的排序方法
- 度中心性(degree centrality, DC)
- 半局部中心性(semilocal centrality, SLC)
- k-壳分解法
- 基于路径排序的方法
- 离心中心性 (Eccentricity, ECC)
- 接近中心性 (closeness centrality, CC)
- Katz 中心性
- 信息指标 (INF)
- 介数中心性 (betweenness centrality, BC)
- 流介数中心性 (flow betweenness centrality, FBC)
- 基于特征向量的排序方法
- 特征向量中心性 (eigenvector centrality, EC)——适用于无向网络
- 累计提名 (cumulative nomination)——适用于无向网络
- PageRank 算法 (PR)——适用于有向网络
- 参考文献
研究背景
复杂网络的重要节点是指相比网络其他节点而言,能够在更大程度上影响网络的结构与功能的一些特殊节点。
近年来,节点重要性(中心性)排序研究受到越来越广泛的关注,不仅因为其重大的理论研究意义,更因为其广泛的实际应用价值。由于应用领域极广,且不同类型的网络中节点的重要性评价方法各有侧重,学者们从不同的实际问题出发设计出各种各样的方法。
提前约定
一个网络的拓扑图记为 G(V,E)G(V,E)G(V,E)
V={v1,v2,⋅⋅⋅,vn}V=\{v_1,v_2,···,v_n\}V={v1,v2,⋅⋅⋅,vn} :节点集合,nnn 为节点数
E={e1,e2,⋅⋅⋅,em}E=\{e_1, e_2,···,e_m\}E={e1,e2,⋅⋅⋅,em}:边的集合,mmm 为边数
一个图的邻接矩阵为:An×n=(aij)\boldsymbol A_{n×n}=(a_{ij})An×n=(aij)
| 无向网络 | 有向网络 |
|---|---|
| aij={1,vi与vj之间有连边0,vi与vj之间无连边a_{ij}=\left\{ \begin{array}{l}1,\ v_i\text{与}v_j\text{之间有连边}\\0,\ v_i\text{与}v_j\text{之间无连边}\\\end{array} \right. aij={1, vi与vj之间有连边0, vi与vj之间无连边 | aij={1,存在一条从vi到vj的有向边0,不存在一条从vi到vj的有向边a_{ij}=\left\{ \begin{array}{l}1,\ 存在一条从v_i\text{到}v_j\text{的有向边}\\0,\ 不存在一条从v_i\text{到}v_j\text{的有向边}\\\end{array} \right. aij={1, 存在一条从vi到vj的有向边0, 不存在一条从vi到vj的有向边 |
特别的,一个含权图的邻接矩阵为:Wn×n=(wij)\boldsymbol W_{n×n}=(w_{ij})Wn×n=(wij)
wij={连边上的权值, vi与vj之间有连边0,vi与vj之间无连边w_{ij}=\left\{ \begin{array}{l} \text{连边上的权值,\ }v_i\text{与}v_j\text{之间有连边}\\ 0,\ v_i\text{与}v_j\text{之间无连边}\\ \end{array} \right. wij={连边上的权值, vi与vj之间有连边0, vi与vj之间无连边
同时约定所有在网络中传播的信息、病毒、车流、人流、电流等统称为网络流。
网络中的一条路径是类似这样的一组节点和边的交替序列:v1v_1v1,e1e_1e1,v2v_2v2,e2e_2e2,···,en1e_{n1}en1,vnv_nvn, 其中 viv_ivi,vi+1v_{i+1}vi+1 是 eie_iei 的两个端点。如果任意一对节点之间都存在一条路径使它们相连, 就称这个网络是连通的。
基于节点近邻的排序方法
度中心性(degree centrality, DC)
观点:一个节点的邻居数目越多,影响力就越大,就越重要。
刻画角度:节点的直接影响力
节点 viv_ivi 的度:ki=∑jaijk_i=\sum_j{a_{ij}}ki=∑jaij,表示与 viv_ivi 直接相连的节点的数目。在有向网络中, 根据连边的方向不同, 节点的度有入度和出度之分。在含权网络中节点度又称为节点的强度(strength),定义为与节点相连的边的权重之和。
节点 viv_ivi 的归一化度中心性指标为:DC(i)=kin−1DC(i)=\frac{k_i}{n-1}DC(i)=n−1ki
优点:简单、直观、计算复杂度低等;在网络鲁棒性和脆弱性研究中表现较好
缺点:没有对节点周围的环境进行更深入细致地探讨,不够精确。
半局部中心性(semilocal centrality, SLC)
目的:为了权衡效率和效果
节点 vwv_wvw 的两层邻居度:N(w)N(w)N(w),表示从 vwv_wvw 出发 2 步内可到达的邻居的数目。
节点 vjv_jvj 的一阶邻居节点(出发 1 步可以到达)的集合:Γ(j)\varGamma(j)Γ(j)
节点 viv_ivi 的半局部中心性定义为:SLC(i)=∑w∈Γ(i)∑j∈Γ(w)N(j)SLC(i)=\sum_{w\in \varGamma \left( i \right)}{\sum_{j\in \varGamma \left( w \right)}{N\left( j \right)}}SLC(i)=w∈Γ(i)∑j∈Γ(w)∑N(j)
表示节点 viv_ivi的所有二阶邻居(出发 2 步可以到达)的两层邻居度之和,其中一项二阶邻居 jjj 的两层邻居度 N(j)N(j)N(j) 如下图被红色阴影覆盖的节点总数:

可以看出,半局部中心性涉及了节点的四阶邻居信息。
k-壳分解法
考虑因素:节点在网络中的位置:越接近核心,影响力越大。
该方法将外围的节点层层剥去, 处于内层的节点拥有较高的影响力。
剥去第一层的具体过程如下:
1、把度为 1 的节点及其所连接的边都去掉
2、去掉剩下网络中度为1的节点,不断循环此操作,直到所剩的网络中没有度为 1 的节点为止。
此时,所有被去掉的节点组成一个层, 称为 1-壳 (记为 ks=1k_s=1ks=1),如下图。

剥掉一层之后在剩下的网络中节点的度就叫该节点的剩余度。
剥去一层后继续剥壳,去掉网络中剩余度为 2 的节点, 重复这些操作, 直到网络中没有节点为止。
更广泛地,可定义初始度为 0 的孤立节点属于 0-壳,即 ks=0k_s=0ks=0.
优点:计算复杂度低, 在分析大规模网络的层级结构等方面有很多应用。
缺点:有很多不能发挥作用的场景;排序结果太过粗粒化;在网络分解时仅考虑剩余度的影响从而不合理。
基于路径排序的方法
在交通、通信、社交等网络中存在着一些度很小但是很重要的节点,这些节点是连接几个区域的“桥节点”,它们在交通流和信息包的传递中担任重要的角色。此时,刻画节点重要性就需要考察网络中节点对信息流的控制力,这种控制力往往与网络中的路径密切相关。
假设:网络中的信息流只经过最短路径传输
离心中心性 (Eccentricity, ECC)
节点 viv_ivi 与 vjv_jvj 之间的最短路径长度,即最短距离:dijd_{ij}dij
节点 viv_ivi 的离心中心性为它与网络中所有节点的最短距离之中的最大值:ECC(i)=maxj(dij)ECC(i)=\max _j\left( d_{ij} \right) ECC(i)=jmax(dij)
网络直径:所有节点的最大离心中心性
网络半径:所有节点的最小离心中心性
中心节点:离心中心性值等于网络半径的节点。一个节点的离心中心性与网络半径越接近就越中心
缺点:极易受特殊值的影响
接近中心性 (closeness centrality, CC)
方法:通过计算节点与网络中其他所有节点的距离的平均值来消除特殊值的干扰。
对于有 nnn 个节点的连通网络, 节点 viv_ivi 到网络中其他节点的平均最短距离:di=1n−1∑j≠idijd_i=\frac{1}{n-1}\sum_{j\ne i}{d_{ij}}di=n−11∑j=idij
did_idi 越小意味着节点 viv_ivi 更接近网络中的其他节点,于是节点 viv_ivi 的接近中心性为:CC(i)=1diCC\left( i \right) =\frac{1}{d_i}CC(i)=di1
Katz 中心性
Katz 中心性不仅考虑节点对之间的最短路径,还考虑它们之间的其他非最短路径。
假设节点 viv_ivi 与节点 vjv_jvj 之间有 ppp 步长,lij(p)l_{ij}^{(p)}lij(p) 表示节点 viv_ivi 到节点 vjv_jvj 经过长度为 ppp 的路径的数目。显然,(lij(2))=∑kaikakj=A2\left( l_{ij}^{\left( 2 \right)} \right) =\sum_k{a_{ik}a_{kj}}=\boldsymbol{A}^2(lij(2))=∑kaikakj=A2,同理得到 A3,A4...Ap...\boldsymbol A^3, \boldsymbol A^4...\boldsymbol A^p...A3,A4...Ap...。
Katz 中心性认为短路径比长路径更加重要,它通过一个与路径长度相关的因子 sp(s∈(0,1),为一个固定参数)s^p(s\in (0,1),为一个固定参数)sp(s∈(0,1),为一个固定参数) 对不同长度的路径加权。 便可以得到一个描述网络中任意节点对之间路径关系的矩阵:K=sA+s2A2+...+spAp+...\boldsymbol K=s\boldsymbol A+s^2\boldsymbol A^2+...+s^p\boldsymbol A^p+...K=sA+s2A2+...+spAp+...,其中,I\boldsymbol II 为单位矩阵。
一个节点 vjv_jvj 的 Katz 中心性:Katz(j)=∑ikijKatz\left( j \right) =\sum_i{k_{ij}}Katz(j)=i∑kij
评价:时间复杂度高,主要用在规模不太大,环路比较少的网络中。
信息指标 (INF)
信息指标通过路径中传播的信息量来衡量节点重要性。
假定:信息在一条边上传递的时候存在一定的噪音,路径越长噪音就越大。把网络看成一个电阻网络,每条边的电阻记为 1。
.一条路径上的信息传输量等于该路径长度的倒数。
一对节点 (vi,vj)(v_i,v_j)(vi,vj) 间传输的信息总量为他们之间所有路径上传送的信息量的总和,记为 qijq_{ij}qij。
在中学我们学过的电阻的两个公式:
串联:R=R1+R2R=R_1+R_2R=R1+R2
并联:1R=1R1+1R2\frac{1}{R}=\frac{1}{R_1}+\frac{1}{R_2}R1=R11+R21
将这两个公式运用到这里的电阻网络上,我们可以得到以两个节点 viv_ivi 和 vjv_jvj 为端点的电阻值:1qij\frac{1}{q_{ij}}qij1。举个例子:
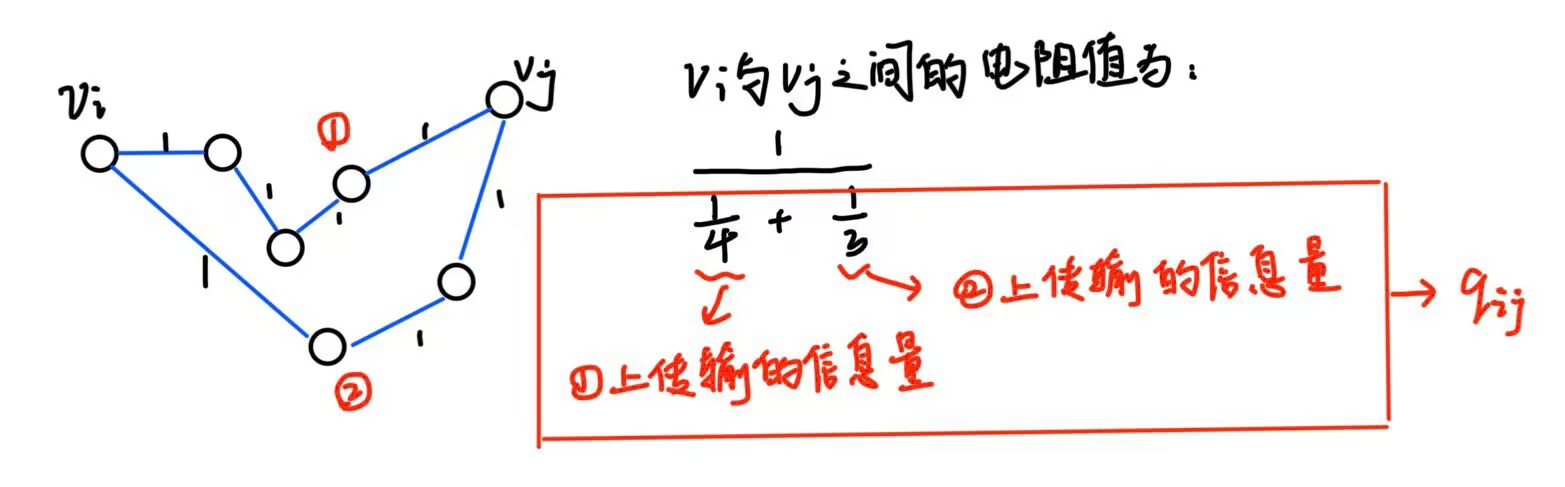
最后,用调和平均数的方法定义 viv_ivi 的中心性指标:INF(i)=[1n∑j1qij]−1INF(i)=[\frac{1}{n}\sum_j{\frac{1}{q_{ij}}}]^{-1}INF(i)=[n1j∑qij1]−1
优点:考虑了所有路径,并可通过电阻网络简化繁复的计算过程。该方法可以很容易地扩展到含权网络,也适用于非连通的网络。
介数中心性 (betweenness centrality, BC)
观点:经过一个节点的最短路径数越多,这个节点就越重要。
节点 viv_{i}vi 的介数表示在所有起点和终点都不是 viv_{i}vi 的最短路径中,经过 viv_ivi 的最短路径的比例,定义:BC(i)=∑j≠s,s≠t,j≠tgstigstBC(i)=\sum_{j\ne s,s\ne t,j\ne t}{\frac{g_{st}^{i}}{g_{st}}}BC(i)=∑j=s,s=t,j=tgstgsti,其中 gstg_{st}gst 表示从节点 vsv_svs 到节点 vtv_tvt 所有路径的数目,gstig_{st}^igsti 表示从节点 vsv_svs 到节点 vtv_tvt 并经过 viv_ivi 的所有路径的数目。
包含 nnn 个节点的连通网络的最大介数为包含 nnn 个节点的星形网络中心节点的介数:(n−1)(n−2)2\frac{\left( n-1 \right) \left( n-2 \right)}{2}2(n−1)(n−2),于是得到一个归一化的介数:BC′(i)=2(n−1)(n−2)∑j≠s,s≠t,j≠tgstigstBC'\left( i \right) =\frac{2}{\left( n-1 \right) \left( n-2 \right)}\sum_{j\ne s,s\ne t,j\ne t}{\frac{g_{st}^{i}}{g_{st}}}BC′(i)=(n−1)(n−2)2j=s,s=t,j=t∑gstgsti
评价:计算时间复杂度较高,使其在实际应用中受到限制,可用于设计网络的通信协议、优化网络部署、检测网络瓶颈等。
流介数中心性 (flow betweenness centrality, FBC)
观点: 网络中所有不重复的路径中,经过一个节点的路径的比例越大,这个节点就越重要。
节点 viv_ivi 的流介数中心性:FBC(i)=∑s<tg~stig~stFBC\left( i \right) =\sum_{s<t}{\frac{\tilde{g}_{st}^{i}}{\tilde{g}_{st}}}FBC(i)=s<t∑g~stg~sti
基于特征向量的排序方法
基于特征向量的方法不仅考虑节点邻居数量还考虑了其质量对节点重要性的影响。
特征向量中心性 (eigenvector centrality, EC)——适用于无向网络
观点:一个节点的重要性既取决于其邻居节点的数量(即该节点的度),也取决于每个邻居节点的重要性。
记 xix_ixi 为节点 viv_ivi 的重要性度量值,有:EC(i)=xi=c∑j=1naijxjEC\left( i \right) =x_i=c\sum_{j=1}^n{a_{ij}x_j}EC(i)=xi=cj=1∑naijxj
注:当节点 viv_ivi 与节点 vjv_jvj 之间有边时,aij=1a_{ij}=1aij=1,否则aij=0a_{ij}=0aij=0
其中,ccc 为一个比例常数,记 x=[x1,x2,x3...xn]T\boldsymbol x=[x_1,x_2,x_3...x_n]^{\text{T}}x=[x1,x2,x3...xn]T,经过多次迭代达到稳态后有:x=cAx\boldsymbol x=c\boldsymbol A\boldsymbol xx=cAx
从这里我们可以看出,xxx 是矩阵 A\boldsymbol AA 的特征值 1c\frac{1}{c}c1 的特征向量。
计算向量 xxx 的方法是:
1、给定初值 x(0)x(0)x(0)
2、采用迭代算法:x(t)=cAx(t−1),t=1,2,3...x(t)=c\boldsymbol A\boldsymbol x(t-1),t=1,2,3...x(t)=cAx(t−1),t=1,2,3...
3、直到归一化的 x′(t)=x′(t−1)x'(t)=x'(t-1)x′(t)=x′(t−1) 为止。
已有文献证明,为了使上述迭代过程收敛,使 c=1λc=\frac{1}{\lambda}c=λ1,其中 λ\lambdaλ 为邻接矩阵 A\boldsymbol AA 的主特征值(绝对值最大的特征值),即有:x=λ−1Ax\boldsymbol x=\lambda ^{-1}\boldsymbol A\boldsymbol xx=λ−1Ax
评价:特征向量中心性更加强调节点所处的周围环境,节点可以通过连接很多其他重要的节点来提升自身的重要性。 从传播的角度看,特征向量中心性适合于描述节点的长期影响力,如在疾病传播、谣言扩散中,一个节点的 EC 分值较大说明该节点距离传染源更近的可能性
越大,是需要防范的关键节点。
累计提名 (cumulative nomination)——适用于无向网络
为了使打分值能够收敛并且快速收敛,在每次迭代过程中,同时考虑邻居节点和自身的打分值。
节点 viv_ivi 在时刻 ttt 时得到的提名次数:p~it\tilde{p}_{i}^{t}p~it,假设 p~i0=1\tilde{p}_{i}^{0}=1p~i0=1。
每个时间步每个节点从所有相邻的节点处获得新增的提名,新增的提名数为邻居节点已有的提名数的总和。节点viv_ivi 在时刻 t+1t+1t+1 的累积提名为:p~it+1=p~it+∑jaijp~jt\tilde{p}_{i}^{t+1}=\tilde{p}_{i}^{t}+\sum_j{a_{ij}\tilde{p}_{j}^{t}}p~it+1=p~it+j∑aijp~jt
将 p~it\tilde{p}_{i}^{t}p~it 归一化得到:pit=p~it∑jp~jtp_{i}^{t}=\frac{\tilde{p}_{i}^{t}}{\sum_j{\tilde{p}_{j}^{t}}}pit=∑jp~jtp~it,如果所有节点归一化后的提名次数不再变化,则停止迭代。
稳态时每个节点的提名次数占所有节点的提名次数的比例就是其重要性权值。
PageRank 算法 (PR)——适用于有向网络
PageRank 算法基于网页的链接结构给网页排序,它认为万维网中一个页面的重要性取决于指向它的其他页面的数量和质量,如果一个页面被很多高质量页面指向,则这个页面的质量也高。
初始时刻:赋予每个节点(网页)相同的 PR 值
然后进行迭代:每一步把每个节点当前的 PR 值平分给它所指向的所有节点。
为什么时平分呢?我想可以这样理解:比如 A 指向了(引用了) B、C、D,A 的重要性包含有 B、C、D 的共同贡献,因此评分 PR 值也就将重要性对 B、C、D 进行了平分。
每个节点的新 PR 值为它所获得的 PR 值之和。节点 viv_ivi 在 ttt 时刻的 PR 值为:PRi(t)=∑j=1najiPRj(t−i)kjoutPR_i\left( t \right) =\sum_{j=1}^n{a_{ji}\frac{PR_j\left( t-i \right)}{k_{j}^{out}}} PRi(t)=j=1∑najikjoutPRj(t−i)
迭代直到每个节点的 PR 值都达到稳定时为止。
缺陷:PR 值一旦到达某个出度为零的节点(悬挂节点),就会永远停留在该节点处而无法传递出来,从而不断吸收 PR 值。
改进:引入一个随机跳转概率 ccc,每一步,不管一个节点是否为悬挂节点,其 PR 值都将以 ccc 的概率均分给网络中所有节点,以 1−c1-c1−c 的概率均分给它指向的节点。可得含参数 ccc 的 PageRank 算法:PRi(t)=(1−c)∑j=1najiPRj(t−i)kjout+cnPR_i\left( t \right) =\left( 1-c \right) \sum_{j=1}^n{a_{ji}\frac{PR_j\left( t-i \right)}{k_{j}^{out}}}+\frac{c}{n}PRi(t)=(1−c)j=1∑najikjoutPRj(t−i)+nc
❓ 我没有弄明白为什么公式后面是 1n\frac{1}{n}n1
参考文献
相关文章:
重要节点排序方法
文章目录研究背景提前约定基于节点近邻的排序方法度中心性(degree centrality, DC)半局部中心性(semilocal centrality, SLC)k-壳分解法基于路径排序的方法离心中心性 (Eccentricity, ECC)接近中心性 (closeness centrality, CC)K…...
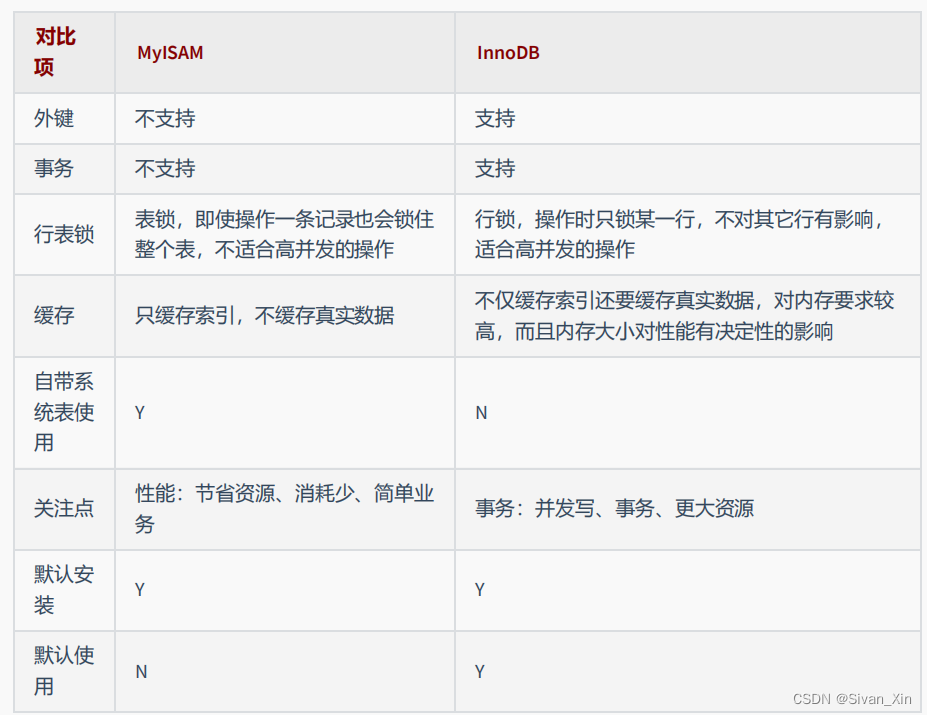
【2.20】动态规划 +项目 + 存储引擎
01背包问题 现有一容量为w的背包,有3个物品,每个物品重量不同,价值不同,问,怎样装才能价值最大化? 明确dp数组含义和下标含义:dp[j]表示当前背包的最大价值。j表示背包容量。递推公式…...

触摸屏单个按键远程控制led
一、硬件 arduino2块 淘晶驰串口屏7寸增强型带外壳1块,不支持视频音频 nRF24L0模块2块 扩展板2块 跳线若干 面包板1块 led灯1个 电阻二极管若干 下载线两个 usb转串口1个 二、实验内容 一个arduino作为触摸屏的控制器,接收触摸屏双向开关的信号,同时通过nRF24L01发送“open”…...
JVM12 class文件
1. Class 文件结构 1.1. Class 字节码文件结构 类型名称说明长度数量魔数u4magic魔数,识别Class文件格式4个字节1版本号u2minor_version副版本号(小版本)2个字节1u2major_version主版本号(大版本)2个字节1常量池集合u2constant_pool_count常量池计数器2个字节1cp_infoconstan…...

等保三级认证基本要求
一、什么是等保测评? 企业单位委托经公安部认证的具有资质的测评机构,按照管理规范和技术标准,对相应的测评对象(信息系统)的状况进行测评。 1、安全技术测评:包括物理安全、网络安全、主机系统安全、应用安…...
)
Python 基本数据类型(一)
1. 整型 整型即整数,用 int 表示,在 Python3 中整型没有长度限制。 1.1 内置函数 1. int(num, baseNone) int( ) 函数用于将字符串转换为整型,默认转换为十进制。 >>> int(123) 123 >>> int(123, …...

win10 环境变量及其作用大全
------------------------------------------------------系统变量------------------------------------------------------ ComSpec: C:\WINDOWS\system32\cmd.exe command specification 解释: ComSpec是Windows操作系统中的一个环境变量,它表示Windo…...

@Valid与@Validated的区别
1.介绍 说明: 其实Valid 与 Validated都是做数据校验的,只不过注解位置与用法有点不同。 不同点: (1) Valid是使用Hibernate validation的时候使用。Validated是只用Spring Validator校验机制使用。 (2&…...
【LeetCode】剑指 Offer 09. 用两个栈实现队列 p68 -- Java Version
题目链接:https://leetcode.cn/problems/yong-liang-ge-zhan-shi-xian-dui-lie-lcof/ 1. 题目介绍(09. 用两个栈实现队列) 用两个栈实现一个队列。队列的声明如下,请实现它的两个函数 appendTail 和 deleteHead ,分别…...

Java并发编程面试题——JUC专题
文章目录一、AQS高频问题1.1 AQS是什么?1.2 唤醒线程时,AQS为什么从后往前遍历?1.3 AQS为什么用双向链表,(为啥不用单向链表)?1.4 AQS为什么要有一个虚拟的head节点1.5 ReentrantLock的底层实现…...
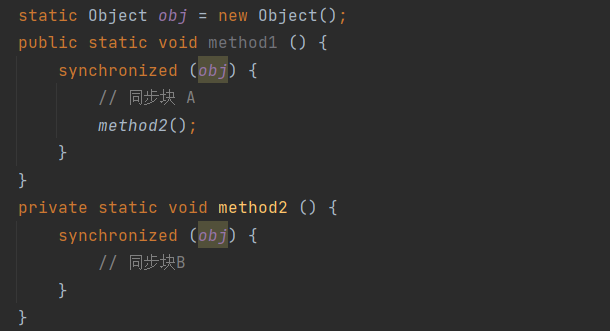
CAS概述
目录一、CAS与原子类1.1 CAS1.2 乐观锁与悲观锁1.3 原子操作类二、 synchronized优化2.1 轻量级锁2.2 轻量级锁-无竞争2.3 轻量级锁-锁膨胀2.4 重量级锁-自旋2.5 偏向锁2.6 synchronized-其他优化一、CAS与原子类 1.1 CAS CAS(一种不断尝试)即Compare …...
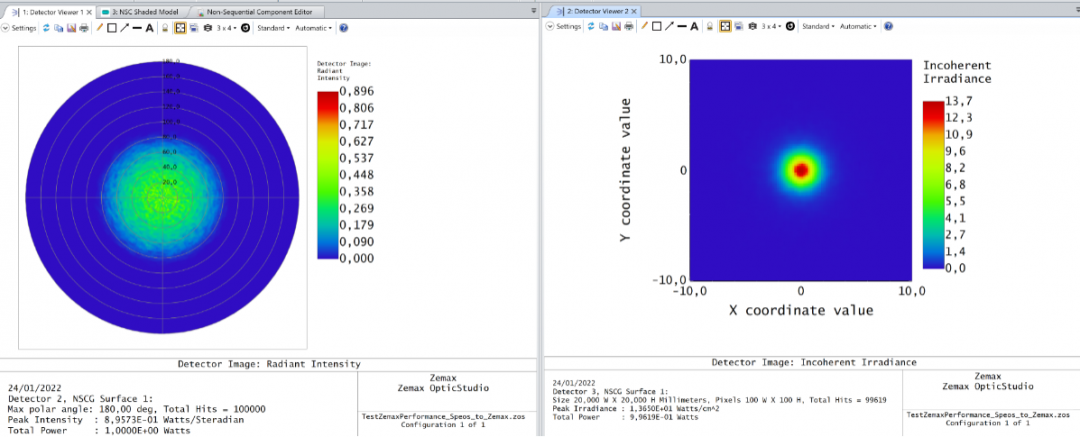
Ansys Zemax / SPEOS | 光源文件转换器
本文解释了如何在 SPEOS 与 Zemax 之间转换二进制光源文件。 下载 联系工作人员获取附件 简介 在本文中,为用户提供了一组Python代码,用于在Zemax和SPEOS之间转换源文件。 有些光源,如 .IES 文件,可在 SPEOS 和 Zemax 中进行…...

PRML笔记2-关于回归参数w的先验的理解
接上篇,现在考虑给w\boldsymbol{w}w加入先验,考虑最简单的假设,也就是w\boldsymbol{w}w服从均值为0,协方差矩阵为α−1I\alpha^{-1}\boldsymbol{I}α−1I的高斯分布。 p(w∣α)N(w∣0,α−1I)(α2π)(M1)/2exp{−α2wTw}\begin{…...

Selenium原理
我们使用Selenium实现自动化测试,主要需要3个东西1.测试脚本,可以是python,java编写的脚本程序(也可以叫做client端)2.浏览器驱动, 这个驱动是根据不同的浏览器开发的,不同的浏览器使用不同的webdriver驱动…...

Disconf、Apollo和Nacos分布式配置框架差异对比
差异对比表格: 功能点DisconfApolloNacos依赖高可用框架完全依赖于Zookeeper来实现监听拉取,向外提供了HTTP拉取数据接口依赖于Eureka实现内部服务发现注册,提供HTTP接口给Client SDK拉取监听数据内部自研实现框架高可用CAP理论偏重点Zookee…...

高新技术企业认定条件条件 高企认定要求
高新技术企业认定条件 一、成立年限:申报企业须注册成立365个日历天数,而非一个会计年度。 二、知识产权 (1)申报企业必须拥有在中国境内授权或审批审定的知识产权,且知识产权在有效保护期内。知识产权权属人应为申请企…...
 | 机试题+算法思路+考点+代码解析 【2023】)
华为OD机试 - 新学校选址(JavaScript) | 机试题+算法思路+考点+代码解析 【2023】
新学校选址 题目 为了解新学期学生暴涨的问题,小乐村要建立所新学校 考虑到学生上学安全问题,需要所有学生家到学校的距离最短. 假设学校和所有学生家都走在一条直线之上,请问学校建立在什么位置, 能使得到学校到各个学生家的距离和最短 输入 第一行: 整数 n 取值范围 [1,1…...

二进制部署K8S
目录 一、环境准备 1、常见的k8s部署方式 2、关闭防火墙 3、关闭selinux 4、关闭swap 5、根据规划设置主机名 6、在master添加hosts 7、将桥接的IPv4流量传递到iptables的链 8、时间同步 二、部署etcd集群 1、master节点部署 2、查看证书的信息 2.1 创建k8s工作目…...

高效获知Activity的生命周期
Activity生命周期监听 使用 Instrumentation 对 Activity 生命周期进行监听。 优点: 全局仅一次反射,性能影响极小所有Activity的生命周期都能够被监听到由于Java的单继承,为了拓展性,可以使用装饰器模式对Instrumentation进行功…...

分析现货黄金价格一般有什么方法
分析现货黄金价格一般有什么方法呢?我相信很多投资者都会说,是技术分析。很多人并不知道技术分析是什么,并且技术分析是如何去分析现货黄金价格的,那么本文就介绍一下技术分析的主要分类。可以说,小编的其他文章都是以…...

OpenClaw文件管理术:千问3.5-27B智能归类2000份文档
OpenClaw文件管理术:千问3.5-27B智能归类2000份文档 1. 为什么我需要AI来管理文档? 我的文档库已经积累了2000多份文件,包括技术笔记、会议记录、项目资料和随手保存的网页截图。它们散落在桌面、下载文件夹和十几个临时创建的目录中&#…...

nuScenes 3D标注数据深度解析:从Box字段到可视化,理解自动驾驶感知的基石
nuScenes 3D标注数据深度解析:从Box字段到可视化,理解自动驾驶感知的基石 自动驾驶技术的快速发展离不开高质量数据集的支撑,而nuScenes作为业界公认的标杆级数据集,其丰富的3D标注信息为感知算法研发提供了坚实基础。本文将带您深…...

Chandra效果实测:100轮连续中文对话稳定性与上下文保持能力验证
Chandra效果实测:100轮连续中文对话稳定性与上下文保持能力验证 测试背景说明:本次测试基于CSDN星图平台的Chandra镜像,在标准配置环境下进行100轮连续中文对话,全面评估其长时间运行的稳定性、上下文理解能力和响应表现。 1. 测试…...

PyTorch-CUDA-v2.7镜像应用场景:快速启动AI模型训练与推理
PyTorch-CUDA-v2.7镜像应用场景:快速启动AI模型训练与推理 1. 镜像概述与核心优势 PyTorch-CUDA-v2.7镜像是一个开箱即用的深度学习环境解决方案,专为需要快速启动AI模型训练与推理的开发者设计。这个预配置的Docker镜像集成了PyTorch 2.7框架和完整的…...

终极QOR监控和日志指南:保障企业应用稳定运行的完整方案
终极QOR监控和日志指南:保障企业应用稳定运行的完整方案 【免费下载链接】qor QOR is a set of libraries written in Go that abstracts common features needed for business applications, CMSs, and E-commerce systems. 项目地址: https://gitcode.com/gh_mi…...

OpenClaw+千问3.5-9B二次开发:修改开源技能适配个人工作流
OpenClaw千问3.5-9B二次开发:修改开源技能适配个人工作流 1. 为什么需要二次开发开源技能? 去年我开始使用OpenClaw管理日常工作流时,发现一个有趣的现象:官方技能市场里的工具虽然丰富,但总有些"差点意思"…...

MeterSphere接口测试实战:从单接口到自动化场景的完整构建
1. 初识MeterSphere:接口测试新手的第一个任务 刚接手接口测试任务时,我和大多数新人一样既兴奋又忐忑。记得第一次打开MeterSphere这个开源持续测试平台,满屏的专业术语让我有点发懵。但实际用下来发现,它的界面设计比Postman这类…...

使用python给pdf文档自动添加目录书签
1.背景很多时候电子书pdf没有书签目录,阅读起来不方便,于是给它自动加个目录吧2.步骤步骤一:使用ds获取到目录json截图目录,到ds中,然后输入如下提示词:根据目录的图片,提取出如下格式的json目录数据: {"title": "第一章 概述","page": 6,"…...

OpenClaw飞书机器人实战:千问3.5-9B自动回复消息
OpenClaw飞书机器人实战:千问3.5-9B自动回复消息 1. 为什么选择OpenClaw飞书千问3.5-9B组合? 去年底我开始尝试用AI自动化处理团队沟通需求时,发现市面上大多数方案要么需要将数据上传到第三方平台,要么配置复杂得让人望而却步。…...

万能引用和完美转发
1、万能引用:模板函数自动推动。#include <iostream> #include <vector> #include <utility>//使用std::move和std::forward等函数需要包含这个头文件using namespace std;template<typename T> void fun(T&& a)//这里就是一个万能…...