NLP文本自动生成介绍及Char-RNN中文文本自动生成训练demo
前言
文本自动生成是自然语言处理领域的一个重要研究方向,实现文本自动生成也是人工智能走向成熟的一个重要标志。文本自动生成技术极具应用前景。
例如,文本自动生成技术可以应用于智能问答与对话、机器翻译等系统,实现更加智能和自然的人机交互;也可以通过文本自动生成系统替代编辑实现新闻的自动撰写与发布,最终将有可能颠覆新闻出版行业;该项技术甚至可以用来帮助学者进行学术论文撰写,进而改变科研创作模式。
按照不同的输入划分,文本自动生成可包括文本到文本的生成(text-to-text generation)、意义到文本的生成(meaning-to-text generation)、数据到文本的生成(data-to-text generation)以及图像到文本的生成(image-to-text generation)等。上述每项技术均极具挑战性,在自然语言处理与人工智能领域均有相当多的前沿研究,近几年业界已产生了若干具有国际影响力的成果与应用。
本文主要简单介绍文本生成中最为成熟的领域的——文本到文本的生成的一些常用算法,最后实操部分则是使用中文数据训练Char-RNN
模型生成中文文本。
文本生成算法
首先,啥是文本生成,简单来说,就是输入一段文本,经过自然语言模型之后,生成一段新的文本,如下图所示
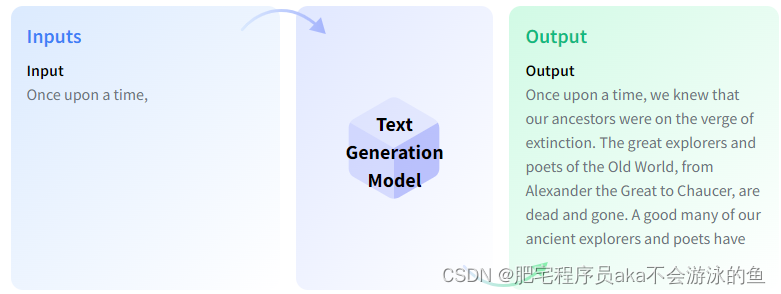
这便是文本自动补全场景下的文本生成,这种应用场景多见于智能问答与对话;如果是机器翻译场景下的文本生成,那模型输入则是需要被翻译的文本,模型输出是翻译后的文本语言;同样的,文本摘要,则更好理解,就是输入一段文本,模型输出这段文本的概括文本。
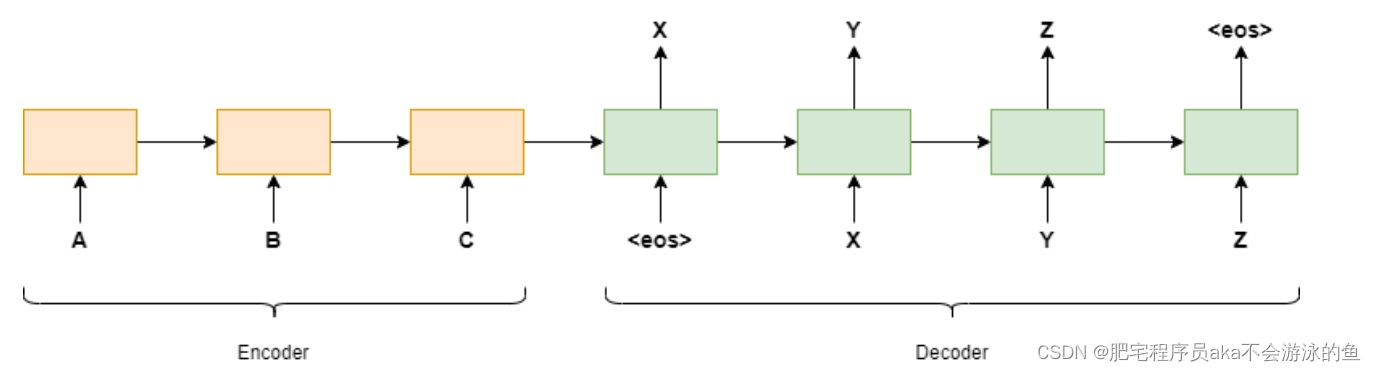
在很长一段时间里,文本生成主要都基于Seq2Seq模型,所谓的Seq2Seq模型就是使用上一个时刻的值来预测下一个时刻的值,两个常用的模型是GRU和LSTM。然而,用 RNN 生成的文本远非也会有一些问题,比如,RNN模型有时候会输出一些莫名其妙的文本,有时还包括一些基本的拼写错误,而其中一个时刻的错误输出,则会让整段文本的输出变得不可用。此外,在推理过程中的无法并行化也是RNN模型在处理序列数据时的一个致命缺陷。
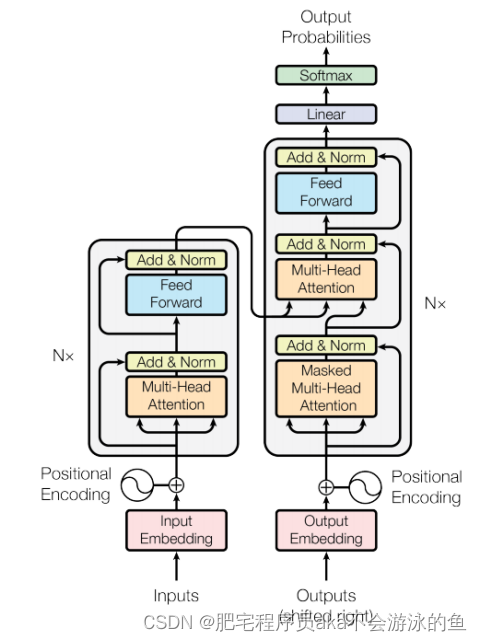
后来,为了解决RNN模型的缺陷,谷歌在2017年发布了一篇经典文章"Attention Is All You Need", 文章中提出了Transformer模型。Transformer是包含了自注意力机制、全连接层的同样带有编码器和解码器的全新的网络结构,同时由于Transformer模型中没有包含RNN网络结构,使其可以并行运算,大大提升了模型的训练和推理时间。当然,模型的参数量也比RNN提升了数倍,模型拟合能力也得到了大大的提升。
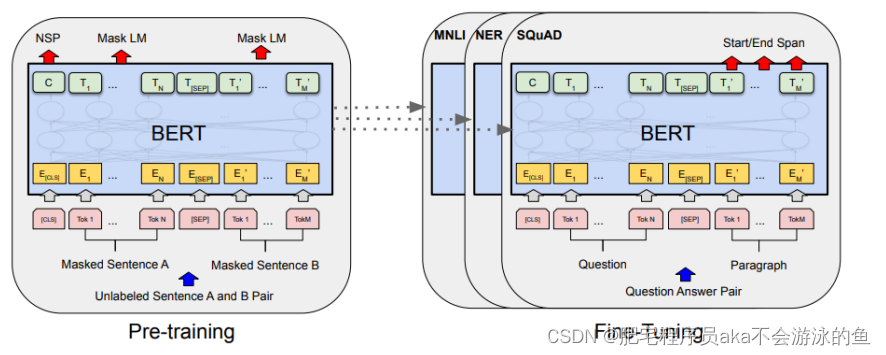
再后来随着深度学习领域的发展,业界提出了更多更大的模型来解决NLP领域的问题,当然,这里也包括了文本生成这一领域。随着BERT、GPT-2、GPT-3等等大模型的提出,使得文本生成的开发可以使用少量场景数据在大模型的基础上做fine-tuned,这样也可以得到远超过简单的Seq2Seq模型的效果。
当然,文本生成领域内容太多,所涉及的算法也很复杂,笔者这里提到的只是一些常规的模型和技术方法,对其他的模型和算法感兴趣的可以参考文末的参考文章继续深入阅读。
中文char-rnn文本生成训练demo
char-rnn之于文本生成领域的地位,与手写mnist之一图像分类领域地位一样,可以说,就是一个入门级别的模型,就是使用RNN模型,输入一个字符,输出一个字符,最后要么达到字数限制,要么输出结束字符,这样就完成文本生成的任务。
这里的中文char-rnn,训练数据使用的中文小说,使用结巴分词将语料进行预处理,然后将分词的结果再进行Embedding编码。
数据预处理
whole = open('text/白夜行.txt', encoding='utf-8').read()
all_words = list(jieba.cut(whole, cut_all=False)) # jieba分词
words = sorted(list(set(all_words)))
word_indices = dict((word, words.index(word)) for word in words)maxlen = 30
epoch_num = 100
class TextTensorDataset(Dataset):def __init__(self, all_words, maxlen, word_indices):sentences = []next_word = []for i in range(0, len(all_words) - maxlen):sentences.append(all_words[i: i + maxlen])next_word.append(all_words[i + maxlen])print('提取的句子总数:', len(sentences))self.inputs = np.zeros((len(sentences), maxlen), dtype='float32') # 先将每个inputs切成30个词的句子列表,然后将句子中的词转化成index索引self.labels = np.zeros((len(sentences)), dtype='float32')for i, sentence in enumerate(sentences):for t, word in enumerate(sentence):self.inputs[i, t] = word_indices[word]self.labels[i] = word_indices[next_word[i]]def __getitem__(self, item):# x = np.expand_dims(self.inputs[item], axis=0)# y = np.expand_dims(self.labels[item], axis=0)return self.inputs[item], self.labels[item]def __len__(self):return len(self.inputs)模型定义
class LSTM(torch.nn.Module):def __init__(self, hidden_size1, hidden_size2, vocab_size, input_size, num_layers):super().__init__()self.embed = torch.nn.Embedding(vocab_size, input_size, max_norm = 1)self.lstm1 = torch.nn.LSTM(input_size, hidden_size1, num_layers, batch_first=True, bidirectional=True)self.lstm2 = torch.nn.LSTM(hidden_size1*2, hidden_size2, num_layers, batch_first=True, bidirectional=True)self.dropout = torch.nn.Dropout(0.1)self.line = torch.nn.Linear(hidden_size2 * maxlen * 2, vocab_size)self.softmax = torch.nn.Softmax(dim=1)def forward(self, x):x = self.embed(x) output1, _ = self.lstm1(x) output, _ = self.lstm2(output1) out_d_reshaped = output.reshape(output.shape[0], (output.shape[1] * output.shape[2]) )line_o = self.line(out_d_reshaped)pred = self.softmax(line_o)#print(pred.shape)return pred
模型使用了两个双向的LSTM,然后再接了一个全连接层,整体都比较简单,没有什么可以详细阐述的
模型训练
hidden_size1, hidden_size2, vocab_size, input_size, num_layers = 256, 128, len(words), 128, 2model = LSTM(hidden_size1, hidden_size2, vocab_size, input_size, num_layers).to(device)loss_function = torch.nn.NLLLoss().to(device)optimizer = torch.optim.RMSprop(model.parameters(), lr=3e-3)mydataset = TextTensorDataset(all_words, maxlen, word_indices)train_loader = DataLoader(mydataset, batch_size=1024, shuffle=True)# training
model.train()
h_state = Nonefor epoch in range(epoch_num):total_loss = 0items = 0for batch_x, batch_label in (train_loader):x = Variable(torch.LongTensor(batch_x.numpy())).cuda()#torch.Size([1024, 30, 1])pred = model(x)pred = torch.log(pred.view(-1, vocab_size) + 1e-20) #print('pred shape ', pred.shape)target = Variable(batch_label.view(-1)).cuda()#print('target shape ', target.shape)loss = loss_function(pred, target.long()) optimizer.zero_grad()loss.backward()optimizer.step()total_loss += loss.item()items += 1print('Epoch {}, Step {} Train Loss {}'.format(epoch, items, loss.item() ) )#save model every 10 epochesif epoch % 10 == 0:if not os.path.exists("./new_trained"):os.makedirs("./new_trained")directory = './new_trained/rnn_novel'+str(epoch)+'.pkl'torch.save(model, directory)
预测代码
def write_words(model, word_num, begin_sentence):gg = begin_sentence[:30]print(''.join(gg), end='/// ')for _ in range(word_num):sampled = np.zeros((1, maxlen)) for t, char in enumerate(gg):sampled[0, t] = word_indices[char]x = Variable(torch.LongTensor(sampled)).cuda()preds = model(x)next_word = words[np.argmax(preds.data.cpu().numpy())]gg.append(next_word)gg = gg[1:]sys.stdout.write(next_word)sys.stdout.flush()begin_sentence = whole[50003: 50100]
print("初始句:", begin_sentence[:30])
begin_sentence = list(jieba.cut(begin_sentence, cut_all=False))write_words(model, 300, begin_sentence)
这里为了方便简单,在模型完成训练之后,即刻进行模型预测,模型预测的效果如下:

参考
运用深度学习进行文本生成
torch.nn.Embedding使用详解
【pytorch】关于Embedding和GRU、LSTM的使用详解
Pytorch损失函数torch.nn.NLLLoss()详解
Text Generation
Char RNN原理介绍以及文本生成实践
MODERN METHODS OF TEXT GENERATION
文本自动生成研究进展与趋势
相关文章:
NLP文本自动生成介绍及Char-RNN中文文本自动生成训练demo
前言 文本自动生成是自然语言处理领域的一个重要研究方向,实现文本自动生成也是人工智能走向成熟的一个重要标志。文本自动生成技术极具应用前景。 例如,文本自动生成技术可以应用于智能问答与对话、机器翻译等系统,实现更加智能和自然的人机…...

Teradata 离场,企业数据分析平台如何应对变革?
近日大数据分析和数仓软件巨头 Teradata(TD)宣布基于中国商业环境的评估,退出在中国的直接运营。TD 是全球最大的专注于大数据分析、数仓和整合营销管理解决方案的供应商之一,其早在 1997 年就进入中国,巅峰期占据半数…...

QWebEngineView-官翻
文章目录特性公共成员函数重实现公共成员函数公有槽函数信号静态公有成员函数保护成员函数重实现保护成员函数额外继承成员详细描述特性文档编制成员函数文档QWebEngineView::**QWebEngineView**([QWidget](../../W/QWidget.md) **parent* Q_NULLPTR)[virtual] QWebEngineView…...
网络安全高级攻击
对分类器的高层次攻击可以分为以下三种类型:对抗性输入:这是专门设计的输入,旨在确保被误分类,以躲避检测。对抗性输入包含专门用来躲避防病毒程序的恶意文档和试图逃避垃圾邮件过滤器的电子邮件。数据中毒攻击:这涉及…...
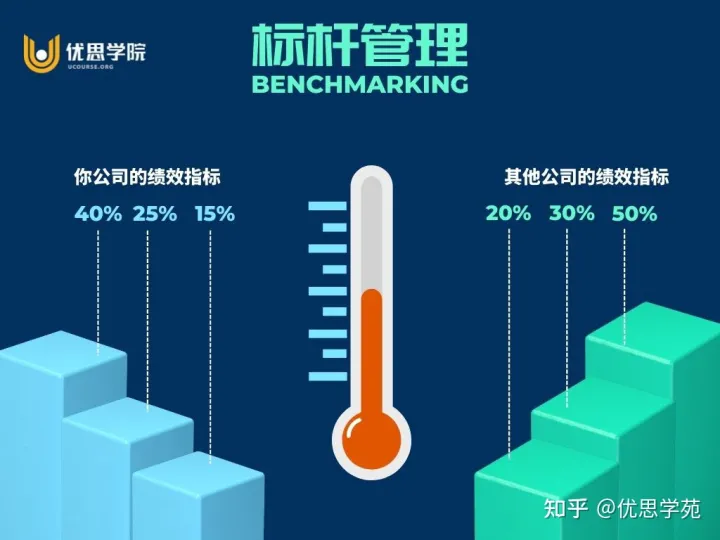
优思学院:六西格玛中的水平对比方法是什么?
水平对比,就是比较不同事物之间的差异。 这个概念在六西格玛管理中也很重要,也就是我们经常说的标杆管理,经常被用来寻找行业中最好的做法,以帮助组织改进自身的绩效。 在六西格玛管理中,水平对比有三种常见的应用方式…...

UVa 690 Pipeline Scheduling 流水线调度 二进制表示状态 DFS 剪枝
题目链接:Pipeline Scheduling 题目描述: 给定一张5n(1≤n≤20)5\times n(1\le n\le20)5n(1≤n≤20)的资源需求表,第iii行第jjj列的值为’X’表示进程在jjj时刻需要使用使用资源iii,如果为’.则表示不需要使用。你的任务是安排十个…...
【ArcGIS Pro二次开发】(6):工程(Project)的基本操作
在ArcGIS Pro中我们对工程的基本操作一般包括打开、新建、保存等。下面演示在二次开发中如何用代码进行以上操作。 新建一个项目,命名为【ProjectManager】,添加8个按钮,命名为【CreateEmptyProject、CreateProjectByDefault、OpenExProjest…...
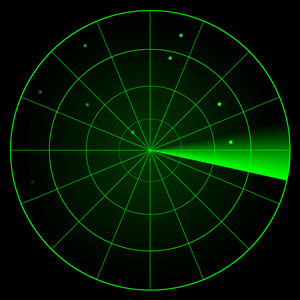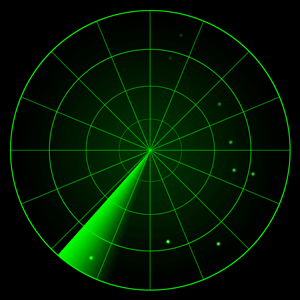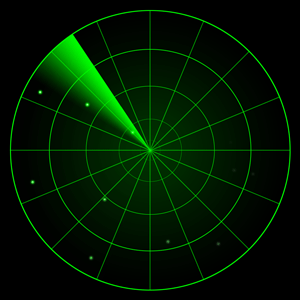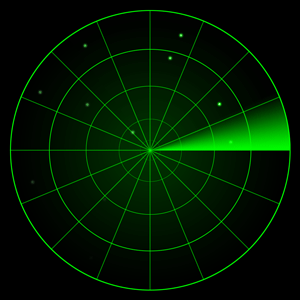
Qt OpenGL(四十)——Qt OpenGL 核心模式-雷达扫描效果
提示:本系列文章的索引目录在下面文章的链接里(点击下面可以跳转查看): Qt OpenGL 核心模式版本文章目录 Qt OpenGL(四十)——Qt OpenGL 核心模式-雷达扫描效果 一、场景 上一篇文章介绍了在雷达坐标系中绘制飞行的飞机,其实雷达坐标系应该还有一个效果,就是扫描的效…...
)
群智能优化算法求解标准测试函数F1~F23之种群动态分布图(视频)
群智能优化算法求解标准测试函数F1的种群动态分布图群智能优化算法求解标准测试函数F2的种群动态分布图群智能优化算法求解标准测试函数F3的种群动态分布图群智能优化算法求解标准测试函数F4的种群动态分布图群智能优化算法求解标准测试函数F5的种群动态分布图群智能优化算法求…...

vue-axios封装与使用
一、简介 Axios 是一个基于 promise 网络请求库,作用于node.js 和浏览器中。 这是一个使用率很高的前端网络请求库,几乎所有的前端项目都会使用,本文主要介绍的是如何在vue项目中使用axios,并对其进行全面的封装。 注意&#x…...
重要节点排序方法
文章目录研究背景提前约定基于节点近邻的排序方法度中心性(degree centrality, DC)半局部中心性(semilocal centrality, SLC)k-壳分解法基于路径排序的方法离心中心性 (Eccentricity, ECC)接近中心性 (closeness centrality, CC)K…...
【2.20】动态规划 +项目 + 存储引擎
01背包问题 现有一容量为w的背包,有3个物品,每个物品重量不同,价值不同,问,怎样装才能价值最大化? 明确dp数组含义和下标含义:dp[j]表示当前背包的最大价值。j表示背包容量。递推公式…...

触摸屏单个按键远程控制led
一、硬件 arduino2块 淘晶驰串口屏7寸增强型带外壳1块,不支持视频音频 nRF24L0模块2块 扩展板2块 跳线若干 面包板1块 led灯1个 电阻二极管若干 下载线两个 usb转串口1个 二、实验内容 一个arduino作为触摸屏的控制器,接收触摸屏双向开关的信号,同时通过nRF24L01发送“open”…...
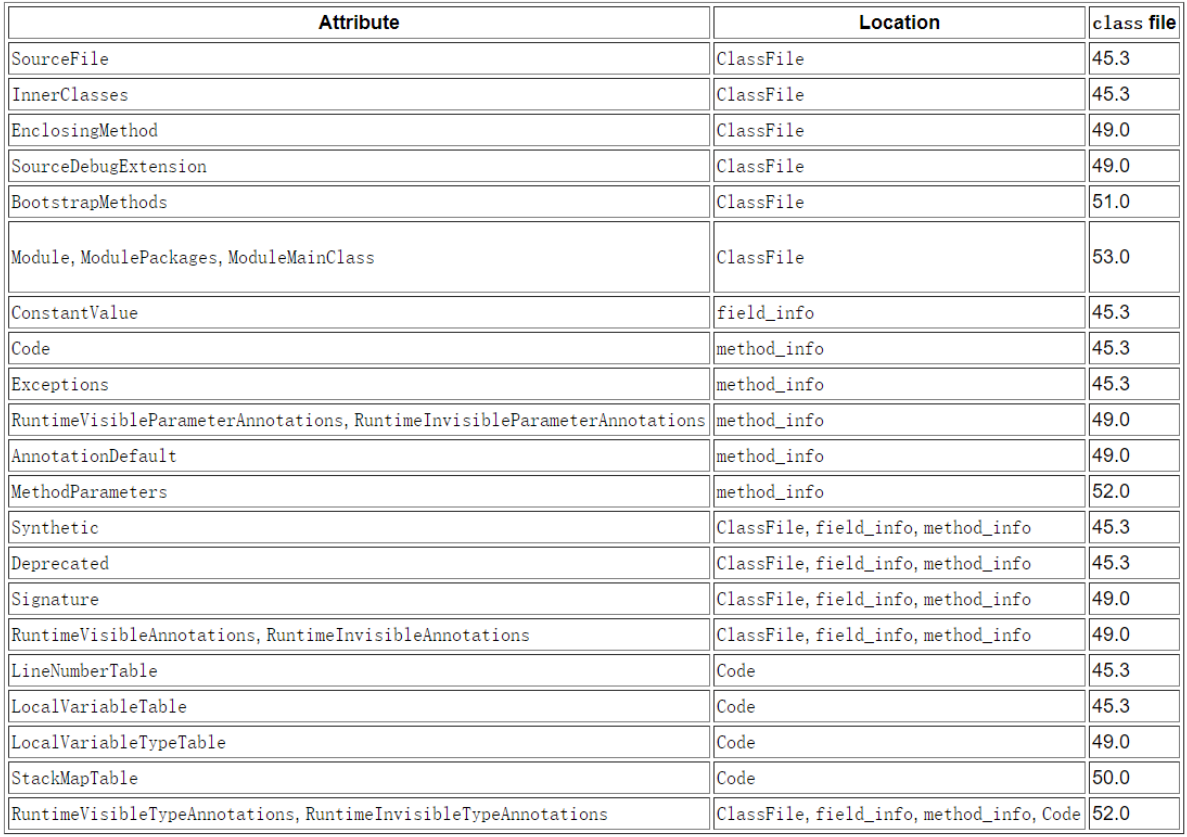
JVM12 class文件
1. Class 文件结构 1.1. Class 字节码文件结构 类型名称说明长度数量魔数u4magic魔数,识别Class文件格式4个字节1版本号u2minor_version副版本号(小版本)2个字节1u2major_version主版本号(大版本)2个字节1常量池集合u2constant_pool_count常量池计数器2个字节1cp_infoconstan…...

等保三级认证基本要求
一、什么是等保测评? 企业单位委托经公安部认证的具有资质的测评机构,按照管理规范和技术标准,对相应的测评对象(信息系统)的状况进行测评。 1、安全技术测评:包括物理安全、网络安全、主机系统安全、应用安…...
)
Python 基本数据类型(一)
1. 整型 整型即整数,用 int 表示,在 Python3 中整型没有长度限制。 1.1 内置函数 1. int(num, baseNone) int( ) 函数用于将字符串转换为整型,默认转换为十进制。 >>> int(123) 123 >>> int(123, …...

win10 环境变量及其作用大全
------------------------------------------------------系统变量------------------------------------------------------ ComSpec: C:\WINDOWS\system32\cmd.exe command specification 解释: ComSpec是Windows操作系统中的一个环境变量,它表示Windo…...

@Valid与@Validated的区别
1.介绍 说明: 其实Valid 与 Validated都是做数据校验的,只不过注解位置与用法有点不同。 不同点: (1) Valid是使用Hibernate validation的时候使用。Validated是只用Spring Validator校验机制使用。 (2&…...
【LeetCode】剑指 Offer 09. 用两个栈实现队列 p68 -- Java Version
题目链接:https://leetcode.cn/problems/yong-liang-ge-zhan-shi-xian-dui-lie-lcof/ 1. 题目介绍(09. 用两个栈实现队列) 用两个栈实现一个队列。队列的声明如下,请实现它的两个函数 appendTail 和 deleteHead ,分别…...

Java并发编程面试题——JUC专题
文章目录一、AQS高频问题1.1 AQS是什么?1.2 唤醒线程时,AQS为什么从后往前遍历?1.3 AQS为什么用双向链表,(为啥不用单向链表)?1.4 AQS为什么要有一个虚拟的head节点1.5 ReentrantLock的底层实现…...

5分钟快速上手:用LeaguePrank打造你的专属英雄联盟游戏形象
5分钟快速上手:用LeaguePrank打造你的专属英雄联盟游戏形象 【免费下载链接】LeaguePrank 项目地址: https://gitcode.com/gh_mirrors/le/LeaguePrank LeaguePrank是一款基于官方LCU API开发的开源工具,让你能够安全、合规地修改英雄联盟游戏界面…...

双通道并用:OpenClaw同时接入gemma-3-12b-it与本地知识库
双通道并用:OpenClaw同时接入gemma-3-12b-it与本地知识库 1. 为什么需要混合架构 在个人自动化场景中,我发现纯粹依赖大模型存在两个痛点:一是高频重复问题消耗大量Token,二是模型对专业领域知识的掌握有限。上个月整理技术文档…...

MusePublic圣光艺苑入门必看:‘凝光成影’技术白皮书——光照建模原理简析
MusePublic圣光艺苑入门必看:‘凝光成影’技术白皮书——光照建模原理简析 “见微知著,凝光成影。在星空的旋律中,重塑大理石的尊严。” 1. 从画室到算法:光照建模的艺术与科学 当你站在一幅梵高的《星空》前,是否曾好…...

Qwen3-TTS效果实测:10种语言语音合成,声音自然度惊艳展示
Qwen3-TTS效果实测:10种语言语音合成,声音自然度惊艳展示 1. 引言:语音合成的新标杆 今天我要带大家体验一款让我眼前一亮的语音合成模型——Qwen3-TTS。这个模型最吸引我的地方是它支持10种语言的语音合成,而且通过简单的自然语…...

AutoGen Studio实战体验:基于Qwen3-4B模型打造智能问答助手
AutoGen Studio实战体验:基于Qwen3-4B模型打造智能问答助手 1. AutoGen Studio简介 AutoGen Studio是一个低代码界面,旨在帮助开发者快速构建AI代理、通过工具增强它们、将它们组合成团队并与之交互以完成任务。它基于AutoGen AgentChat构建——一个用…...

OpenClaw任务链设计:千问3.5-35B-A3B-FP8复杂流程自动化
OpenClaw任务链设计:千问3.5-35B-A3B-FP8复杂流程自动化 1. 为什么需要任务链自动化 上周我遇到一个典型的工作场景:需要从20份PDF报告中提取关键数据,整理成Excel表格,再根据这些数据生成分析图表,最后通过邮件发送…...

51单片机实战:基于XPT2046的多传感器AD转换与LCD显示
1. 项目背景与核心器件选型 第一次接触51单片机AD转换时,我被各种专业术语搞得一头雾水。直到用XPT2046芯片完成了电位器、光敏电阻、热敏电阻的三路信号采集,才真正理解模拟信号数字化的奥妙。这个成本不到5元的触摸屏控制芯片,其实是个隐藏…...

OpenClaw+千问3.5-27B创作助手:从大纲到公众号图文全自动生成
OpenClaw千问3.5-27B创作助手:从大纲到公众号图文全自动生成 1. 为什么需要全自动创作助手 作为一个技术博主,我每周都要产出2-3篇技术文章。最痛苦的环节不是写作本身,而是那些重复性的准备工作:构思大纲、寻找配图、调整格式、…...

【数据结构与算法】第23篇:树、森林与二叉树的转换
一、树的存储结构1.1 双亲表示法每个节点存储数据和父节点下标,适合找父节点的场景。c#define MAX_SIZE 100 typedef struct {int data;int parent; // 父节点下标 } PNode;typedef struct {PNode nodes[MAX_SIZE];int root; // 根节点下标int size; } PTree;缺…...

Epigenase m6A 甲基化酶活性/抑制比色法检测试剂盒:快速、灵敏、高通量适配
一、产品概述Epigenase m6A 甲基化酶活性/抑制比色法检测试剂盒,由Cytoskeleton推出,艾美捷代理,它是一套完整的优化缓冲液与试剂组合,专用于定量检测总 m6A 甲基化酶(甲基转移酶)的活性或抑制效果。该试剂…...