基于数据湖的多流拼接方案-HUDI实操篇
目录
一、前情提要
二、代码Demo
(一)多写问题
(二)如果要两个流写一个表,这种情况怎么处理?
(三)测试结果
三、后序
一、前情提要
基于数据湖对两条实时流进行拼接(如前端埋点+服务端埋点、日志流+订单流等);
基础概念见前一篇文章:基于数据湖的多流拼接方案-HUDI概念篇_Leonardo_KY的博客-CSDN博客
二、代码Demo
下文demo均使用datagen生成mock数据进行测试,如到生产,改成Kafka或者其他source即可。
第一个job:stream A,落hudi表:
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(minPauseBetweenCP); // 1senv.getCheckpointConfig().setCheckpointTimeout(checkpointTimeout); // 2 minenv.getCheckpointConfig().setMaxConcurrentCheckpoints(maxConcurrentCheckpoints);// env.getCheckpointConfig().setCheckpointStorage("file:///D:/Users/yakang.lu/tmp/checkpoints/");TableEnvironment tableEnv = StreamTableEnvironment.create(env);// datagen====================================================================tableEnv.executeSql("CREATE TABLE sourceA (\n" +" uuid bigint PRIMARY KEY NOT ENFORCED,\n" +" `name` VARCHAR(3)," +" _ts1 TIMESTAMP(3)\n" +") WITH (\n" +" 'connector' = 'datagen', \n" +" 'fields.uuid.kind'='sequence',\n" +" 'fields.uuid.start'='0', \n" +" 'fields.uuid.end'='1000000', \n" +" 'rows-per-second' = '1' \n" +")");// hudi====================================================================tableEnv.executeSql("create table hudi_tableA(\n"+ " uuid bigint PRIMARY KEY NOT ENFORCED,\n"+ " age int,\n"+ " name VARCHAR(3),\n"+ " _ts1 TIMESTAMP(3),\n"+ " _ts2 TIMESTAMP(3),\n"+ " d VARCHAR(10)\n"+ ")\n"+ " PARTITIONED BY (d)\n"+ " with (\n"+ " 'connector' = 'hudi',\n"+ " 'path' = 'hdfs://ns/user/hive/warehouse/ctripdi_prodb.db/hudi_mor_mutil_source_test', \n" // hdfs path+ " 'table.type' = 'MERGE_ON_READ',\n"+ " 'write.bucket_assign.tasks' = '10',\n"+ " 'write.tasks' = '10',\n"+ " 'write.partition.format' = 'yyyyMMddHH',\n"+ " 'write.partition.timestamp.type' = 'EPOCHMILLISECONDS',\n"+ " 'hoodie.bucket.index.num.buckets' = '2',\n"+ " 'changelog.enabled' = 'true',\n"+ " 'index.type' = 'BUCKET',\n"+ " 'hoodie.bucket.index.num.buckets' = '2',\n"+ String.format(" '%s' = '%s',\n", FlinkOptions.PRECOMBINE_FIELD.key(), "_ts1")+ " 'write.payload.class' = '" + PartialUpdateAvroPayload.class.getName() + "',\n"+ " 'hoodie.write.log.suffix' = 'job1',\n"+ " 'hoodie.write.concurrency.mode' = 'optimistic_concurrency_control',\n"+ " 'hoodie.write.lock.provider' = 'org.apache.hudi.client.transaction.lock.FileSystemBasedLockProvider',\n"+ " 'hoodie.cleaner.policy.failed.writes' = 'LAZY',\n"+ " 'hoodie.cleaner.policy' = 'KEEP_LATEST_BY_HOURS',\n"+ " 'hoodie.consistency.check.enabled' = 'false',\n"// + " 'hoodie.write.lock.early.conflict.detection.enable' = 'true',\n" // todo// + " 'hoodie.write.lock.early.conflict.detection.strategy' = '"// + SimpleTransactionDirectMarkerBasedEarlyConflictDetectionStrategy.class.getName() + "',\n" //+ " 'hoodie.keep.min.commits' = '1440',\n"+ " 'hoodie.keep.max.commits' = '2880',\n"+ " 'compaction.schedule.enabled'='false',\n"+ " 'compaction.async.enabled'='false',\n"+ " 'compaction.trigger.strategy'='num_or_time',\n"+ " 'compaction.delta_commits' ='3',\n"+ " 'compaction.delta_seconds' ='60',\n"+ " 'compaction.max_memory' = '3096',\n"+ " 'clean.async.enabled' ='false',\n"+ " 'hive_sync.enable' = 'false'\n"// + " 'hive_sync.mode' = 'hms',\n"// + " 'hive_sync.db' = '%s',\n"// + " 'hive_sync.table' = '%s',\n"// + " 'hive_sync.metastore.uris' = '%s'\n"+ ")");// sql====================================================================StatementSet statementSet = tableEnv.createStatementSet();String sqlString = "insert into hudi_tableA(uuid, name, _ts1, d) select * from " +"(select *,date_format(CURRENT_TIMESTAMP,'yyyyMMdd') AS d from sourceA) view1";statementSet.addInsertSql(sqlString);statementSet.execute();第二个job:stream B,落hudi表:
StreamExecutionEnvironment env = manager.getEnv();env.getCheckpointConfig().setMinPauseBetweenCheckpoints(minPauseBetweenCP); // 1senv.getCheckpointConfig().setCheckpointTimeout(checkpointTimeout); // 2 minenv.getCheckpointConfig().setMaxConcurrentCheckpoints(maxConcurrentCheckpoints);// env.getCheckpointConfig().setCheckpointStorage("file:///D:/Users/yakang.lu/tmp/checkpoints/");TableEnvironment tableEnv = StreamTableEnvironment.create(env);// datagen====================================================================tableEnv.executeSql("CREATE TABLE sourceB (\n" +" uuid bigint PRIMARY KEY NOT ENFORCED,\n" +" `age` int," +" _ts2 TIMESTAMP(3)\n" +") WITH (\n" +" 'connector' = 'datagen', \n" +" 'fields.uuid.kind'='sequence',\n" +" 'fields.uuid.start'='0', \n" +" 'fields.uuid.end'='1000000', \n" +" 'rows-per-second' = '1' \n" +")");// hudi====================================================================tableEnv.executeSql("create table hudi_tableB(\n"+ " uuid bigint PRIMARY KEY NOT ENFORCED,\n"+ " age int,\n"+ " name VARCHAR(3),\n"+ " _ts1 TIMESTAMP(3),\n"+ " _ts2 TIMESTAMP(3),\n"+ " d VARCHAR(10)\n"+ ")\n"+ " PARTITIONED BY (d)\n"+ " with (\n"+ " 'connector' = 'hudi',\n"+ " 'path' = 'hdfs://ns/user/hive/warehouse/ctripdi_prodb.db/hudi_mor_mutil_source_test', \n" // hdfs path+ " 'table.type' = 'MERGE_ON_READ',\n"+ " 'write.bucket_assign.tasks' = '10',\n"+ " 'write.tasks' = '10',\n"+ " 'write.partition.format' = 'yyyyMMddHH',\n"+ " 'hoodie.bucket.index.num.buckets' = '2',\n"+ " 'changelog.enabled' = 'true',\n"+ " 'index.type' = 'BUCKET',\n"+ " 'hoodie.bucket.index.num.buckets' = '2',\n"+ String.format(" '%s' = '%s',\n", FlinkOptions.PRECOMBINE_FIELD.key(), "_ts1")+ " 'write.payload.class' = '" + PartialUpdateAvroPayload.class.getName() + "',\n"+ " 'hoodie.write.log.suffix' = 'job2',\n"+ " 'hoodie.write.concurrency.mode' = 'optimistic_concurrency_control',\n"+ " 'hoodie.write.lock.provider' = 'org.apache.hudi.client.transaction.lock.FileSystemBasedLockProvider',\n"+ " 'hoodie.cleaner.policy.failed.writes' = 'LAZY',\n"+ " 'hoodie.cleaner.policy' = 'KEEP_LATEST_BY_HOURS',\n"+ " 'hoodie.consistency.check.enabled' = 'false',\n"// + " 'hoodie.write.lock.early.conflict.detection.enable' = 'true',\n" // todo// + " 'hoodie.write.lock.early.conflict.detection.strategy' = '"// + SimpleTransactionDirectMarkerBasedEarlyConflictDetectionStrategy.class.getName() + "',\n"+ " 'hoodie.keep.min.commits' = '1440',\n"+ " 'hoodie.keep.max.commits' = '2880',\n"+ " 'compaction.schedule.enabled'='true',\n"+ " 'compaction.async.enabled'='true',\n"+ " 'compaction.trigger.strategy'='num_or_time',\n"+ " 'compaction.delta_commits' ='2',\n"+ " 'compaction.delta_seconds' ='90',\n"+ " 'compaction.max_memory' = '3096',\n"+ " 'clean.async.enabled' ='false'\n"// + " 'hive_sync.mode' = 'hms',\n"// + " 'hive_sync.db' = '%s',\n"// + " 'hive_sync.table' = '%s',\n"// + " 'hive_sync.metastore.uris' = '%s'\n"+ ")");// sql====================================================================StatementSet statementSet = tableEnv.createStatementSet();String sqlString = "insert into hudi_tableB(uuid, age, _ts1, _ts2, d) select * from " +"(select *, _ts2 as ts1, date_format(CURRENT_TIMESTAMP,'yyyyMMdd') AS d from sourceB) view2";// statementSet.addInsertSql("insert into hudi_tableB(uuid, age, _ts2) select * from sourceB");statementSet.addInsertSql(sqlString);statementSet.execute();也可以将两个 writer 放到同一个app中(使用statement):
import java.time.ZoneOffset;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.StatementSet;
import org.apache.flink.table.api.TableConfig;
import org.apache.flink.table.api.TableEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.api.config.TableConfigOptions;
import org.apache.hudi.common.model.PartialUpdateAvroPayload;
import org.apache.hudi.configuration.FlinkOptions;
// import org.apache.hudi.table.marker.SimpleTransactionDirectMarkerBasedEarlyConflictDetectionStrategy;public class Test00 {public static void main(String[] args) {Configuration configuration = TableConfig.getDefault().getConfiguration();configuration.setString(TableConfigOptions.LOCAL_TIME_ZONE, ZoneOffset.ofHours(8).toString());//设置东八区// configuration.setInteger("rest.port", 8086);StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment(configuration);env.setParallelism(1);env.enableCheckpointing(12000L);// env.getCheckpointConfig().setCheckpointStorage("file:///Users/laifei/tmp/checkpoints/");TableEnvironment tableEnv = StreamTableEnvironment.create(env);// datagen====================================================================tableEnv.executeSql("CREATE TABLE sourceA (\n" +" uuid bigint PRIMARY KEY NOT ENFORCED,\n" +" `name` VARCHAR(3)," +" _ts1 TIMESTAMP(3)\n" +") WITH (\n" +" 'connector' = 'datagen', \n" +" 'fields.uuid.kind'='sequence',\n" +" 'fields.uuid.start'='0', \n" +" 'fields.uuid.end'='1000000', \n" +" 'rows-per-second' = '1' \n" +")");tableEnv.executeSql("CREATE TABLE sourceB (\n" +" uuid bigint PRIMARY KEY NOT ENFORCED,\n" +" `age` int," +" _ts2 TIMESTAMP(3)\n" +") WITH (\n" +" 'connector' = 'datagen', \n" +" 'fields.uuid.kind'='sequence',\n" +" 'fields.uuid.start'='0', \n" +" 'fields.uuid.end'='1000000', \n" +" 'rows-per-second' = '1' \n" +")");// hudi====================================================================tableEnv.executeSql("create table hudi_tableA(\n"+ " uuid bigint PRIMARY KEY NOT ENFORCED,\n"+ " name VARCHAR(3),\n"+ " age int,\n"+ " _ts1 TIMESTAMP(3),\n"+ " _ts2 TIMESTAMP(3)\n"+ ")\n"+ " PARTITIONED BY (_ts1)\n"+ " with (\n"+ " 'connector' = 'hudi',\n"+ " 'path' = 'file:\\D:\\Ctrip\\dataWork\\tmp', \n" // hdfs path+ " 'table.type' = 'MERGE_ON_READ',\n"+ " 'write.bucket_assign.tasks' = '2',\n"+ " 'write.tasks' = '2',\n"+ " 'write.partition.format' = 'yyyyMMddHH',\n"+ " 'write.partition.timestamp.type' = 'EPOCHMILLISECONDS',\n"+ " 'hoodie.bucket.index.num.buckets' = '2',\n"+ " 'changelog.enabled' = 'true',\n"+ " 'index.type' = 'BUCKET',\n"+ " 'hoodie.bucket.index.num.buckets' = '2',\n"// + String.format(" '%s' = '%s',\n", FlinkOptions.PRECOMBINE_FIELD.key(), "_ts1:name|_ts2:age")// + " 'write.payload.class' = '" + PartialUpdateAvroPayload.class.getName() + "',\n"+ " 'hoodie.write.log.suffix' = 'job1',\n"+ " 'hoodie.write.concurrency.mode' = 'optimistic_concurrency_control',\n"+ " 'hoodie.write.lock.provider' = 'org.apache.hudi.client.transaction.lock.FileSystemBasedLockProvider',\n"+ " 'hoodie.cleaner.policy.failed.writes' = 'LAZY',\n"+ " 'hoodie.cleaner.policy' = 'KEEP_LATEST_BY_HOURS',\n"+ " 'hoodie.consistency.check.enabled' = 'false',\n"+ " 'hoodie.write.lock.early.conflict.detection.enable' = 'true',\n"+ " 'hoodie.write.lock.early.conflict.detection.strategy' = '"// + SimpleTransactionDirectMarkerBasedEarlyConflictDetectionStrategy.class.getName() + "',\n" //+ " 'hoodie.keep.min.commits' = '1440',\n"+ " 'hoodie.keep.max.commits' = '2880',\n"+ " 'compaction.schedule.enabled'='false',\n"+ " 'compaction.async.enabled'='false',\n"+ " 'compaction.trigger.strategy'='num_or_time',\n"+ " 'compaction.delta_commits' ='3',\n"+ " 'compaction.delta_seconds' ='60',\n"+ " 'compaction.max_memory' = '3096',\n"+ " 'clean.async.enabled' ='false',\n"+ " 'hive_sync.enable' = 'false'\n"// + " 'hive_sync.mode' = 'hms',\n"// + " 'hive_sync.db' = '%s',\n"// + " 'hive_sync.table' = '%s',\n"// + " 'hive_sync.metastore.uris' = '%s'\n"+ ")");tableEnv.executeSql("create table hudi_tableB(\n"+ " uuid bigint PRIMARY KEY NOT ENFORCED,\n"+ " name VARCHAR(3),\n"+ " age int,\n"+ " _ts1 TIMESTAMP(3),\n"+ " _ts2 TIMESTAMP(3)\n"+ ")\n"+ " PARTITIONED BY (_ts2)\n"+ " with (\n"+ " 'connector' = 'hudi',\n"+ " 'path' = '/Users/laifei/tmp/hudi/local.db/mutiwrite1', \n" // hdfs path+ " 'table.type' = 'MERGE_ON_READ',\n"+ " 'write.bucket_assign.tasks' = '2',\n"+ " 'write.tasks' = '2',\n"+ " 'write.partition.format' = 'yyyyMMddHH',\n"+ " 'hoodie.bucket.index.num.buckets' = '2',\n"+ " 'changelog.enabled' = 'true',\n"+ " 'index.type' = 'BUCKET',\n"+ " 'hoodie.bucket.index.num.buckets' = '2',\n"// + String.format(" '%s' = '%s',\n", FlinkOptions.PRECOMBINE_FIELD.key(), "_ts1:name|_ts2:age")// + " 'write.payload.class' = '" + PartialUpdateAvroPayload.class.getName() + "',\n"+ " 'hoodie.write.log.suffix' = 'job2',\n"+ " 'hoodie.write.concurrency.mode' = 'optimistic_concurrency_control',\n"+ " 'hoodie.write.lock.provider' = 'org.apache.hudi.client.transaction.lock.FileSystemBasedLockProvider',\n"+ " 'hoodie.cleaner.policy.failed.writes' = 'LAZY',\n"+ " 'hoodie.cleaner.policy' = 'KEEP_LATEST_BY_HOURS',\n"+ " 'hoodie.consistency.check.enabled' = 'false',\n"+ " 'hoodie.write.lock.early.conflict.detection.enable' = 'true',\n"+ " 'hoodie.write.lock.early.conflict.detection.strategy' = '"// + SimpleTransactionDirectMarkerBasedEarlyConflictDetectionStrategy.class.getName() + "',\n"+ " 'hoodie.keep.min.commits' = '1440',\n"+ " 'hoodie.keep.max.commits' = '2880',\n"+ " 'compaction.schedule.enabled'='true',\n"+ " 'compaction.async.enabled'='true',\n"+ " 'compaction.trigger.strategy'='num_or_time',\n"+ " 'compaction.delta_commits' ='2',\n"+ " 'compaction.delta_seconds' ='90',\n"+ " 'compaction.max_memory' = '3096',\n"+ " 'clean.async.enabled' ='false'\n"// + " 'hive_sync.mode' = 'hms',\n"// + " 'hive_sync.db' = '%s',\n"// + " 'hive_sync.table' = '%s',\n"// + " 'hive_sync.metastore.uris' = '%s'\n"+ ")");// sql====================================================================StatementSet statementSet = tableEnv.createStatementSet();statementSet.addInsertSql("insert into hudi_tableA(uuid, name, _ts1) select * from sourceA");statementSet.addInsertSql("insert into hudi_tableB(uuid, age, _ts2) select * from sourceB");statementSet.execute();}
}(一)多写问题
由于HUDI官方提供的code打成jar包是不支持“多写”的,这里使用Tencent改造之后的code进行打包测试;
如果使用官方包,多个writer写入同一个hudi表,则会报如下异常:
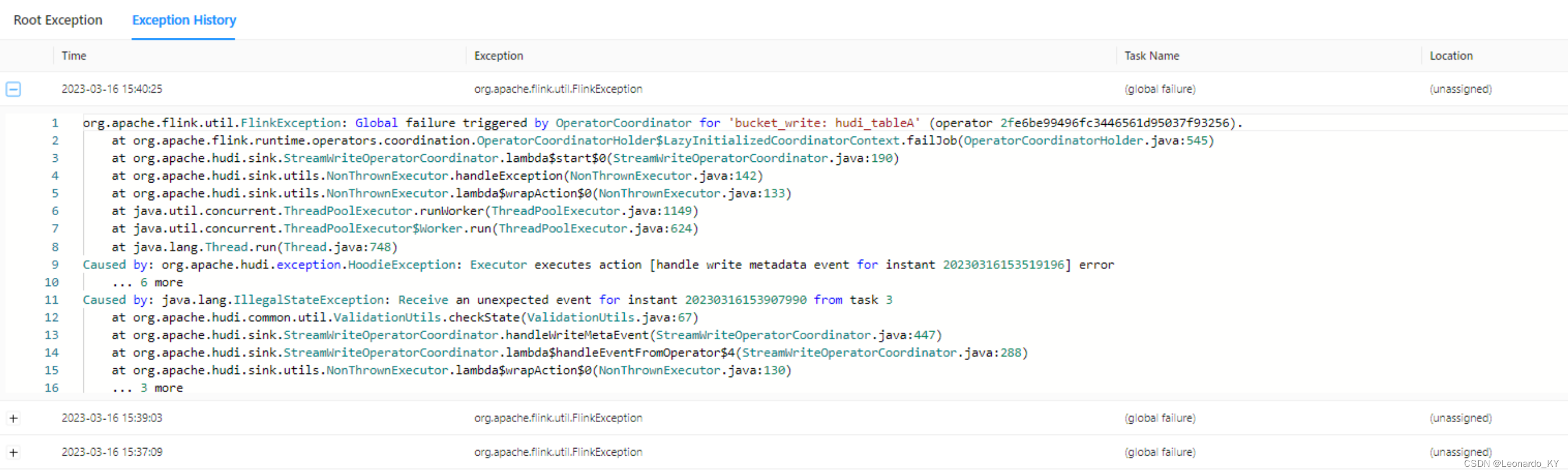
而且:
hudi中有个preCombineField,在建表的时候只能指定其中一个字段为preCombineField,但是如果使用官方版本,双流写同一个hudi的时候出现两种情况:
1. 一条流写preCombineField,另一条流不写这个字段,后者会出现 ordering value不能为null;
2. 两条流都写这个字段,出现字段冲突异常;
(二)如果要两个流写一个表,这种情况怎么处理?
经过本地测试:
hudi0.12-multiWrite版本(Tencent修改版),可以支持多 precombineField(在此版本中,只要保证主键、分区字段之外的字段,在多个流中不冲突即可实现多写!)
hudi0.13版本,不支持,而且存在上述问题;
(三)测试结果

Tencent文章链接:https://cloud.tencent.com/developer/article/2189914
github链接:GitHub - XuQianJin-Stars/hudi at multiwrite-master-7
hudi打包很麻烦,如果需要我将后续上传打好的jar包;
三、后序
基于上述code,当流量比较大的时候,似乎会存在一定程度的数据丢失(在其中一条流进行compact,则另一条流就会存在一定程度的数据丢失);
可以尝试:
(1)先将两个流UNION为一个流,再sink到hudi表(也避免了写冲突);
(2)使用其他数据湖工具,比如apache paimon,参考:新一代数据湖存储技术Apache Paimon入门Demo_Leonardo_KY的博客-CSDN博客
相关文章:
基于数据湖的多流拼接方案-HUDI实操篇
目录 一、前情提要 二、代码Demo (一)多写问题 (二)如果要两个流写一个表,这种情况怎么处理? (三)测试结果 三、后序 一、前情提要 基于数据湖对两条实时流进行拼接࿰…...
Spring MVC 四:Context层级
这一节我们来回答上篇文章中避而不谈的有关什么是RootApplicationContext的问题。 这就需要引入Spring MVC的有关Context Hierarchy的问题。Context Hierarchy意思就是Context层级,既然说到Context层级,说明在Spring MVC项目中,可能存在不止…...
【C++ 学习 ⑱】- 多态(上)
目录 一、多态的概念和虚函数 1.1 - 用基类指针指向派生类对象 1.2 - 虚函数和虚函数的重写 1.3 - 多态构成的条件 1.4 - 多态的应用场景 二、协变和如何析构派生类对象 2.1 - 协变 2.2 - 如何析构派生类对象 三、C11 的 override 和 final 关键字 一、多态的概念和虚…...

合宙Air724UG LuatOS-Air LVGL API控件--进度条 (Bar)
进度条 (Bar) Bar 是进度条,可以用来显示数值,加载进度。 示例代码 – 创建进度条 bar lvgl.bar_create(lvgl.scr_act(), nil) – 设置尺寸 lvgl.obj_set_size(bar, 200, 20); – 设置位置居中 lvgl.obj_align(bar, NULL, lvgl.ALIGN_CENTER, 0, 0) …...
图神经网络与分子表征:番外——基组选择
学过高斯软件的人都知道,我们在撰写输入文件 gjf 时需要准备输入【泛函】和【基组】这两个关键词。 【泛函】敲定计算方法,【基组】则类似格点积分中的密度,与计算精度密切相关。 部分研究人员借用高斯中的一系列基组去包装输入几何信息&am…...

rabbitmq笔记-rabbitmq客户端开发使用
连接RabbitMQ 1.创建ConnectionFactory,给定参数ip地址,端口号,用户名和密码等 2.创建ConnectionFactory,使用uri方式实现,创建channel。 注意: Connection可以用来创建多个channel实例,但c…...
与nvl2()函数详解)
13.Oracle中nvl()与nvl2()函数详解
Oracle中nvl()与nvl2()函数详解: 函数nvl(expression1,expression2)根据参数1是否为null返回参数1或参数2的值; 函数nvl2(expression1,expression2,expression3)根据参数1是否为null返回参数2或参数3的值 1.nvl:根据参数1是否为null返回参数…...

设置某行被选中并滚动到改行
<el-table :data"tableDamItem" ref"singleTable" stripe style"width: 100%" height"250" highlight-current-row v-on:row-click"handleTableRow"></el-table>/*** 设置表格行被选中,并滚动到该行* param po…...

React钩子函数之useRef的基本使用
React钩子函数中的useRef是一个非常有用的工具,它可以用来获取DOM元素或者保存一些变量。在这篇文章中,我们将会讨论useRef的基本使用。 首先,我们需要知道useRef是如何工作的。它返回一个可变的ref对象,这个对象可以在组件的整个…...

无风扇迷你电脑信息与购买指南
本文将解释什么是无风扇迷你电脑,以及计算产品组合中你可以购买的一些不同的无风扇迷你电脑的信息指南。 无风扇迷你电脑是一种小型工业计算机,旨在处理复杂的工业工作负载。迷你电脑是通过散热器被动冷却可在各种类型的易失性环境中部署。无风扇微型计…...

比特币是怎么回事?
比特币是怎么回事? 一句话描述就是,初始化几个比特币,申请成为矿工组织,发生交易时抢单记账成功可以比特币奖励,随着比特币数量的增加,奖励越来越少。怎么记账成功呢,通过交易信息幸运数字哈希…...
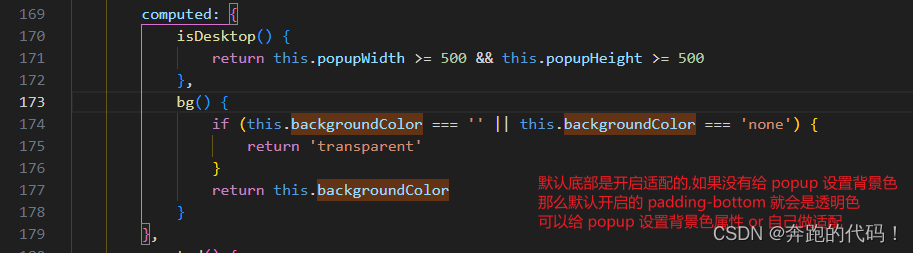
vue3+ts+uniapp小程序端自定义日期选择器基于内置组件picker-view + 扩展组件 Popup 实现自定义日期选择及其他选择
vue3ts 基于内置组件picker-view 扩展组件 Popup 实现自定义日期选择及其他选择 vue3tsuniapp小程序端自定义日期选择器 1.先上效果图2.代码展示2.1 组件2.2 公共方法处理日期2.3 使用组件 3.注意事项3.1refSelectDialog3.1 backgroundColor"#fff" 圆角问题 自我记…...

Java进阶篇--泛型
前言 Java 泛型(generics)是 JDK 5 中引入的一个新特性, 泛型提供了编译时类型安全检测机制,该机制允许程序员在编译时检测到非法的类型。它允许在定义类、接口和方法时使用类型参数。这种技术使得在编译期间可以使用任何类型,而…...
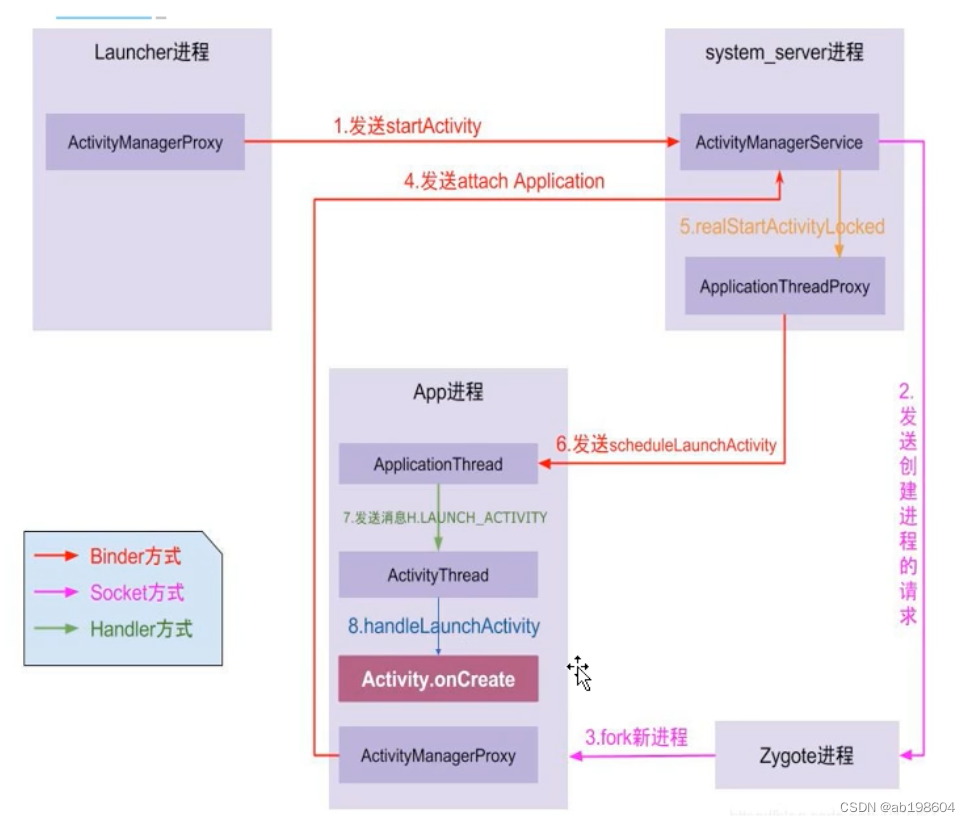
android framework之Applicataion启动流程分析
Application启动流程分析 启动方式一:通过Launcher启动app 启动方式二:在某一个app里启动第二个app的Activity. 以上两种方式均可触发app进程的启动。但无论哪种方式,最终通过通过调用AMS的startActivity()来启动application的。 根据上图…...

Linux Day10 ---Mybash
目录 一、Mybash介绍 1.1.mybash.c 打印函数 分割函数 命令函数 二、Mybash实现 2.1.打印函数 2.1.1需要使用到的功能函数 1.获取与当前用户关联的UID 2.获取与当前用户的相关信息---一个结构体(passwd) 3.获取主机信息 4.获取当前所处位置 5.给…...

Flask-Sockets和Flask-Login联合实现websocket的登录认证功能
flask_login 提供了一个方便的方式来管理用户会话。当你在 Flask 的 HTTP 视图中使用它时,你可以简单地使用 login_required 装饰器来确保用户已登录。 但是,flask_sockets 并没有直接与 flask_login 集成。如果你想在建立 WebSocket 连接时检查用户是否…...
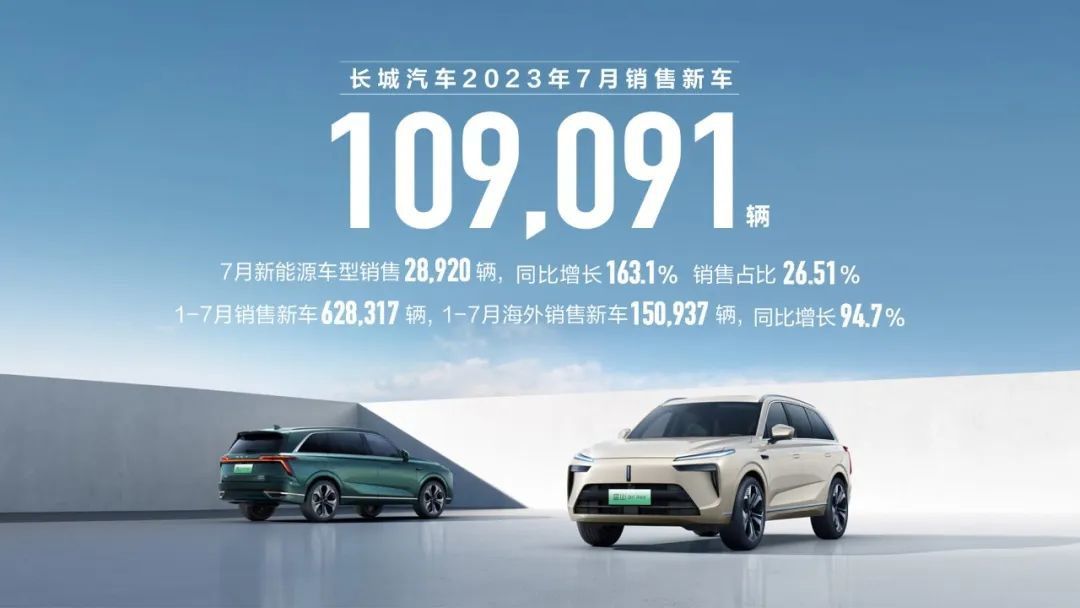
东盟全面覆盖?长城战略部署核心区域市场,首个百万粉丝国产品牌
根据最新消息,长城汽车在东南亚地区取得了巨大的成功,成功进军了亚洲最大的汽车市场之一-印度尼西亚。这标志着长城汽车已经实现了东盟核心市场的全面覆盖,成为全球布局的重要一步。 在过去的几年里,长城汽车在东盟地区的市场布局…...
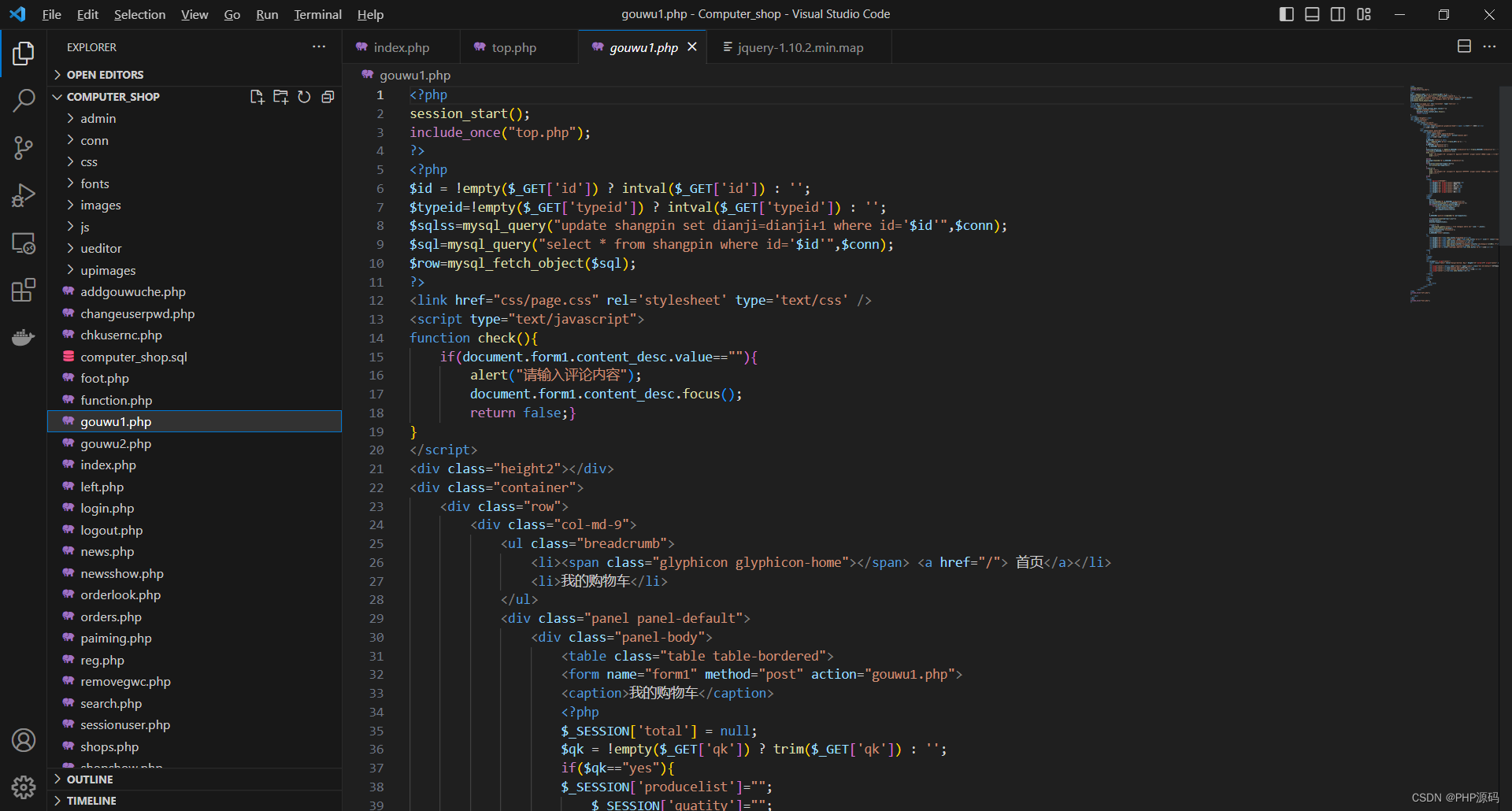
基于PHP的电脑商城系统
有需要请加文章底部Q哦 可远程调试 基于PHP的电脑商城系统 一 介绍 此电脑商城系统基于原生PHP开发,数据库mysql,前端bootstrap。用户可注册登录,购物下单,评论等。管理员登录后台对电脑商品,用户,订单&a…...

无客户端网络准入方案,为集成电路企业终端管理开启省事更省心模式
宁盾无客户端网络准入控制方案正在成为先进制造、高科技互联网企业等创新型客户的优选方案。创新型客户以技术密集型、研发人员占比高著称,在进行网络准入建设时,如何平衡好用户体验与顺利达成项目预期之间的矛盾,是创新企业 IT 安全团队格外…...

5G与4G的RRC协议之异同
什么是无线资源控制(RRC)? 我们知道,在移动通信中,无线资源管理是非常重要的一个环节,首先介绍一下什么是无线资源控制(RRC)。 手机和网络通过无线信道相互通信,彼此交…...

东北老牌央国企陪跑机构哪家实力强
在东北地区,众多求职者,特别是应届毕业生,将目光投向了工作稳定、发展前景广阔的央国企。在这一背景下,专业的求职服务机构应运而生,为求职者提供系统化的支持。辽宁优泰教育咨询有限公司便是其中一家专注于该领域的服…...

出海营销决战指南:从“流量过客”到“私域常客”的全局地图
2026 全球出海营销日历:如何在关键节点实现社媒私域流量的指数级增长?2026年,出海战场规则已变。粗放投放的红利耗尽,碎片化的渠道、敏感的风控与难以逾越的文化沟壑,正让每一分营销预算的效能急剧衰减。节点依旧汹涌&…...

深度解析IDM激活脚本:注册表锁定技术的完整实现指南
深度解析IDM激活脚本:注册表锁定技术的完整实现指南 【免费下载链接】IDM-Activation-Script IDM Activation & Trail Reset Script 项目地址: https://gitcode.com/gh_mirrors/id/IDM-Activation-Script Internet Download Manager(IDM&…...

风扇智能调节终极指南:三步打造安静高效的散热系统
风扇智能调节终极指南:三步打造安静高效的散热系统 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/fa/Fa…...

当你能证明你的代码能带来流量时,你就永远不会被视为“垃圾”。
在商业世界里,代码本身没有价值,代码产生的结果才有价值。 如果你写的代码逻辑完美、架构优雅、注释清晰,但用户不用、业务不增长,那它在老板眼里就是“成本”,甚至是“垃圾”。如果你写的代码哪怕有些粗糙、用了“笨办…...

trt 动态batchsize优化:trtexec工具ONNX转engine实战指南
1. 为什么需要动态batchsize优化 在实际的AI模型部署中,我们经常会遇到输入数据量不固定的情况。比如视频分析场景,可能同时有1路或8路视频需要实时处理;又比如在线服务,请求量会随时间波动。这时候如果使用固定batchsize…...

如何用Marker实现PDF到Markdown的精准转换?三个技巧提升文档处理效率
如何用Marker实现PDF到Markdown的精准转换?三个技巧提升文档处理效率 【免费下载链接】marker 一个高效、准确的工具,能够将 PDF 和图像快速转换为 Markdown、JSON 和 HTML 格式,支持多语言和复杂布局处理,可选集成 LLM 提升精度&…...

RustDesk 中继服务器搭建指南:告别卡顿,实现高效远程控制
1. 为什么你需要自建RustDesk中继服务器 远程办公已经成为现代工作方式的标配,但很多人在使用公共远程控制服务时都遇到过令人抓狂的卡顿问题。想象一下,你正在紧急处理服务器故障,画面却卡成了PPT;或者需要远程协助家人修电脑&a…...
)
数据清洗避坑指南:缺失值和异常值处理的5个常见错误(附真实案例)
数据清洗避坑指南:缺失值和异常值处理的5个常见错误(附真实案例) 在电商平台的用户行为分析中,我们曾遇到一个诡异现象:某促销活动页面的转化率突然飙升到98%。进一步排查发现,是爬虫程序将未加载完成的页…...

语义通信:从理论到6G落地的关键技术演进与挑战
1. 语义通信的理论基石 语义通信(Semantic Communication, SemCom)的核心思想与传统通信有着本质区别。传统通信追求的是"准确传输比特流",而语义通信关注的是"有效传递信息的意义"。这就像两个人对话:传统通…...