《动手深度学习》 线性回归从零开始实现实例
🎈 作者:Linux猿
🎈 简介:CSDN博客专家🏆,华为云享专家🏆,Linux、C/C++、云计算、物联网、面试、刷题、算法尽管咨询我,关注我,有问题私聊!
🎈 欢迎小伙伴们点赞👍、收藏⭐、留言💬
本文是《动手深度学习》线性回归从零开始实现实例的实现和分析。
一、代码实现
实现代码如下所示。
# random 模块 调用 random() 方法返回随机生成的一个实数,值在[0,1)范围内
import random
# 机器学习框架 pythorch,类似于 TensorFlow 和 Keras
import torch
# 线性回归函数 y = Xw + b + e(噪音)'''
一系列封装的函数
'''
# 批量获取数据函数
def synthetic_data(w, b, num_examples): #@save# 生成 y=Xw+b+噪声'''返回一个张量,张量里面的随机数是从相互独立的正态分布中随机生成的参与 1: 均值参与 2: 标准差参数 3: 张量的大小 [num_examples, len(w)]'''X = torch.normal(0, 1, (num_examples, len(w)))# torch.matmul 两个张量元素相乘y = torch.matmul(X, w) + b# 加上噪声y += torch.normal(0, 0.01, y.shape)return X, y.reshape((-1, 1))# 随机批量取数据函数
def data_iter(batch_size, features, labels):num_examples = len(features)# 生成存储值 0 ~ num_examples 值的列表,不重复indices = list(range(num_examples))# 在原列表 indices 中随机打乱所有元素random.shuffle(indices)# range() 第三个参数是步长for i in range(0, num_examples, batch_size):batch_indices = torch.tensor(indices[i: min(i + batch_size, num_examples)])# yield 相当于不断的 return 的作用yield features[batch_indices], labels[batch_indices]# 计算预测值,网络模型
def linreg(X, w, b):# 线性回归模型return torch.matmul(X, w) + b# 计算损失
def squared_loss(y_hat, y):# 均方损失return (y_hat - y.reshape(y_hat.shape)) ** 2 / 2# 梯度更新
def sgd(params, lr, batch_size):# 小批量随机梯度下降with torch.no_grad():for param in params:param -= lr * param.grad / batch_sizeparam.grad.zero_() # 清除 param 的梯度值为 0'''
1. 生成数据集
包含 1000 条数据,每条 [x1, x2]
'''
# 用于生成数据临时的 true_w 和 true_b
true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = synthetic_data(true_w, true_b, 1000)
# features: [1000, 2], labels: [1000, 1]'''
2. 初始化 w 和 b
w: 2 x 1, b: [0]
'''
# requires_grad 在计算中保留梯度信息
w = torch.normal(0, 0.01, size=(2,1), requires_grad=True)
# 初始化张量为全零
b = torch.zeros(1, requires_grad=True)'''
3. 开始训练
'''
# 设置超参数 学习率
lr = 0.03
# 设置超参数 训练批次/迭代周期
num_epochs = 3
# 设置超参数 每次训练的数据量
batch_size = 10# 重命名函数
net = linreg
loss = squared_lossfor epoch in range(num_epochs): # num_epochs 个迭代周期for X, y in data_iter(batch_size, features, labels): # 每次随机取 10 条数据一起训练l = loss(net(X, w, b), y) # X 和 y 的小批量损失,计算损失l.sum().backward() # 损失求和后,根据构建的计算图,计算关于[w,b]的梯度,反向传播算法一定要是一个标量才能进行计算,所以进行 sum 操作后 backwardsgd([w, b], lr, batch_size) # 使用参数的梯度更新参数# 不自动求导with torch.no_grad():train_l = loss(net(features, w, b), labels) # 使用更新后的 [w, b] 计算所有训练数据的 lossprint(f'epoch {epoch + 1}, loss {float(train_l.mean()):f}') # 通过 mean 函数取平均值'''
with torch.no_grad():
在使用 pytorch 时,并不是所有的操作都需要进行计算图的生成(计算过程的构建,以便梯度反向传播等操作)。
而对于 tensor 的计算操作,默认是要进行计算图的构建的,在这种情况下,可以使用 with torch.no_grad():,
强制之后的内容不进行计算图构建。
'''二、实现解析
2.1 参数和超参数
⌈参数⌋是需要通过训练来得到的结果,最常见的就是神经网络的权重 W 和 b。训练模型的目的就是要找到一套好的模型参数,用于预测未知的结果。这些参数我们是不用调的,是模型来训练的过程中自动更新生成的。
⌈超参数⌋是我们控制我们模型结构、功能、效率等的 调节旋钮,常见超参数:
(1)learning rate(学习率)
(2)epochs(迭代次数,也可称为 num of iterations)
(3)num of hidden layers(隐层数目)
(4)num of hidden layer units(隐层的单元数/神经元数)
(5)activation function(激活函数)
(6)batch-size(用mini-batch SGD的时候每个批量的大小)
(7)optimizer(选择什么优化器,如SGD、RMSProp、Adam)
(8)用诸如RMSProp、Adam优化器的时候涉及到的β1,β2等等
2.2 模型训练
整体的模型训练思路如下所示。
1. 数据集生成,包括:训练数据、测试数据;
2. 初始化参数 w 和 b;
3. 训练模型,设置超参数,开始训练模型;
参考链接:
深度学习中的超参数调节(learning rate、epochs、batch-size...) - 知乎
loss.sum().backward()中对于sum()的理解
🎈 感觉有帮助记得「一键三连」支持下哦!有问题可在评论区留言💬,感谢大家的一路支持!🤞猿哥将持续输出「优质文章」回馈大家!🤞🌹🌹🌹🌹🌹🌹🤞
相关文章:

《动手深度学习》 线性回归从零开始实现实例
🎈 作者:Linux猿 🎈 简介:CSDN博客专家🏆,华为云享专家🏆,Linux、C/C、云计算、物联网、面试、刷题、算法尽管咨询我,关注我,有问题私聊! &…...

Redis 命令
Redis 命令 Redis 命令用于在 redis 服务上执行操作。 要在 redis 服务上执行命令需要一个 redis 客户端。Redis 客户端在我们之前下载的的 redis 的安装包中。 语法 Redis 客户端的基本语法为: $ redis-cli实例 以下实例讲解了如何启动 redis 客户端…...
Linux网络编程:线程池并发服务器 _UDP客户端和服务器_本地和网络套接字
文章目录: 一:线程池模块分析 threadpool.c 二:UDP通信 1.TCP通信和UDP通信各自的优缺点 2.UDP实现的C/S模型 server.c client.c 三:套接字 1.本地套接字 2.本地套 和 网络套对比 server.c client.c 一:线…...
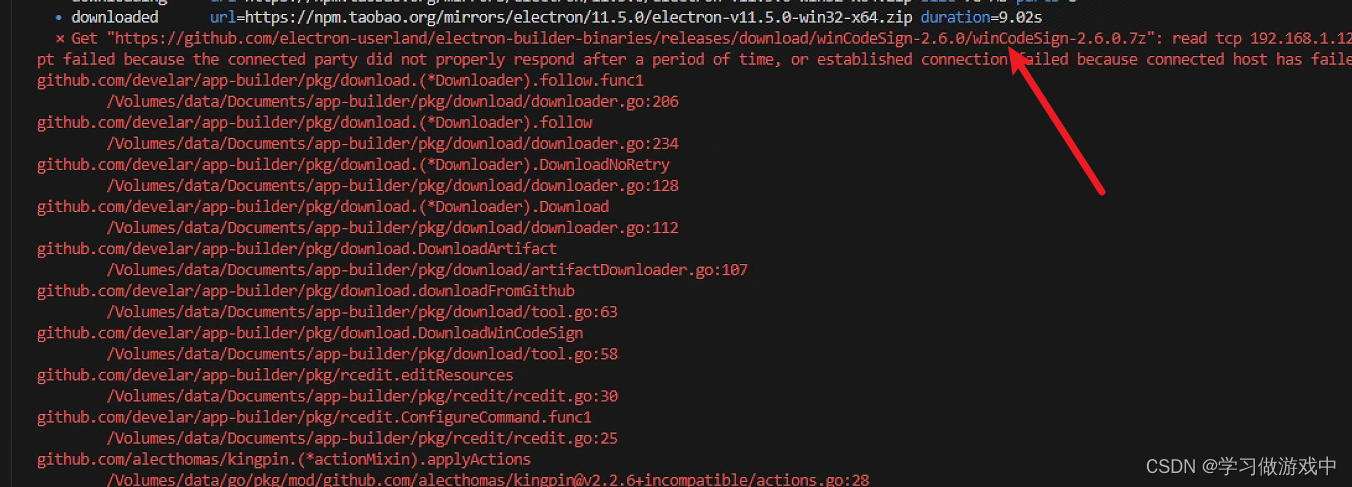
nvm安装electron开发与编译环境
electron总是安装失败,下面说一下配置办法 下载软件 nvm npmmirror 镜像站 安装nvm 首先最好卸载node,不卸载的话,安装nvm会提示是否由其接管,保险起见还是卸载 下载win中的安装包 配置加速节点nvm node_mirror https://npmmi…...

玩转Mysql系列 - 第7篇:玩转select条件查询,避免采坑
这是Mysql系列第7篇。 环境:mysql5.7.25,cmd命令中进行演示。 电商中:我们想查看某个用户所有的订单,或者想查看某个用户在某个时间段内所有的订单,此时我们需要对订单表数据进行筛选,按照用户、时间进行…...

启动程序结束程序打开指定网页
import subprocess subprocess.Popen(r"C:\\Program Files\\5EClient\\5EClient.exe") # 打开指定程序 import os os.system(TASKKILL /F /IM notepad.exe) # 结束指定程序 import webbrowser webbrowser.open_new_tab(https://www.baidu.com) # 打开指定网页...
)
从零开始学习 Java:简单易懂的入门指南之包装类(十九)
包装类 包装类5.1 概述5.2 Integer类5.3 装箱与拆箱5.4 自动装箱与自动拆箱5.5 基本类型与字符串之间的转换基本类型转换为StringString转换成基本类型 5.6 底层原理 算法小题练习一:练习二:练习三:练习四:练习五: 包装…...
(一、数组交集问题))
leetcode分类刷题:哈希表(Hash Table)(一、数组交集问题)
1、当需要快速判断某元素是否出现在序列中时,就要用到哈希表了。 2、本文针对的总结题型为给定两个及多个数组,求解它们的交集。接下来,按照由浅入深层层递进的顺序总结以下几道题目。 3、以下题目需要共同注意的是:对于两个数组&…...
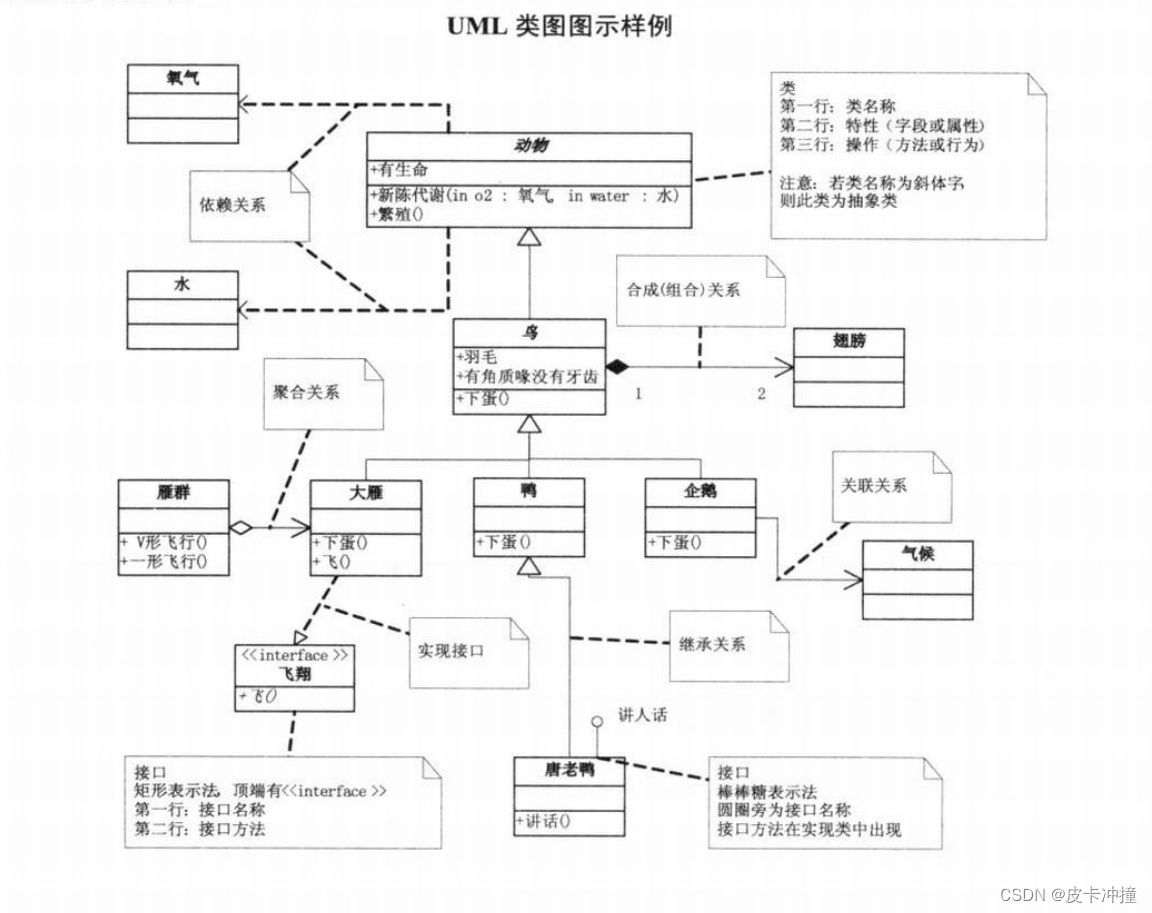
UML四大关系
文章目录 引言UML的定义和作用UML四大关系的重要性和应用场景关联关系继承关系聚合关系组合关系 UML四大关系的进一步讨论UML四大关系的实际应用软件开发中的应用其他领域的应用 总结 引言 在软件开发中,统一建模语言(Unified Modeling Language&#x…...
、三种页面的渲染方式、数据校验的使用)、form组件的参数以及单选多选形式)
forms组件(钩子函数(局部钩子、全局钩子)、三种页面的渲染方式、数据校验的使用)、form组件的参数以及单选多选形式
一、form是组件 后端代码 from django.shortcuts import render, redirect, HttpResponsedef ab_form(request):back_dict {username: , password: }if request.method POST:username request.POST.get(username)password request.POST.get(password)if 金瓶梅 in userna…...

跨专业申请成功|金融公司经理赴美国密苏里大学访学交流
J经理所学专业与从事工作不符,尽管如此,我们还是为其成功申请到美国密苏里大学经济学专业的访问学者职位,全家顺利过签出国。 J经理背景: 申请类型: 自费访问学者 工作背景: 某金融公司经理 教育背景&am…...
)
第十一章 CUDA的NMS算子实战篇(下篇)
cuda教程目录 第一章 指针篇 第二章 CUDA原理篇 第三章 CUDA编译器环境配置篇 第四章 kernel函数基础篇 第五章 kernel索引(index)篇 第六章 kenel矩阵计算实战篇 第七章 kenel实战强化篇 第八章 CUDA内存应用与性能优化篇 第九章 CUDA原子(atomic)实战篇 第十章 CUDA流(strea…...

R语言01-数据类型
概念 数值型(Numeric):用于存储数值数据,包括整数和浮点数。例如:x <- 5。 字符型(Character):用于存储文本数据,以单引号或双引号括起来。例如:name &l…...
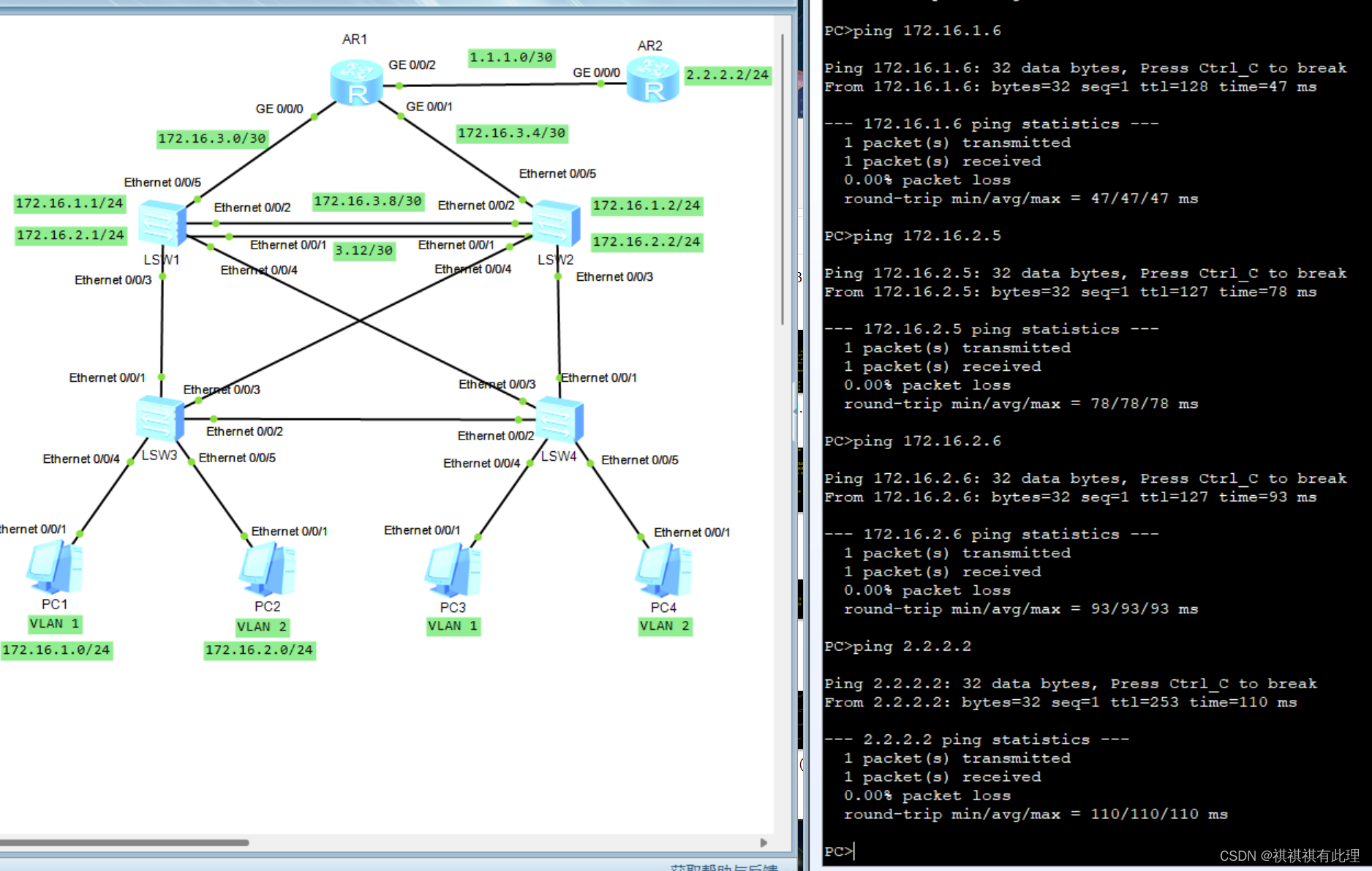
【网络基础实战之路】基于三层架构实现一个企业内网搭建的实战详解
系列文章传送门: 【网络基础实战之路】设计网络划分的实战详解 【网络基础实战之路】一文弄懂TCP的三次握手与四次断开 【网络基础实战之路】基于MGRE多点协议的实战详解 【网络基础实战之路】基于OSPF协议建立两个MGRE网络的实验详解 【网络基础实战之路】基于…...

C++11相较于C++98多了哪些可调用对象?--《包装器》篇
C98里面的可调用对象只有普通函数和函数指针。 而在C11里面可调用的对象有下面几种: 普通函数函数指针仿函数lambda表达式(匿名函数)包装器 普通函数、函数指针、仿函数、lambda表达式我在以前的文章里其实已经介绍过了 包装器 在C11里面有…...

栈与队列:常见的线性数据结构
栈(Stack)和队列(Queue)是计算机科学中常见的线性数据结构,它们在许多算法和编程场景中发挥着重要作用。它们的不同特点和用途使得它们适用于不同的问题和应用。 栈(Stack) 栈,作为…...

android framework之AMS的启动管理与职责
AMS是什么? AMS管理着activity,Service, Provide, BroadcastReceiver android10后:出现ATMS,ActivityTaskManagerService:ATMS是从AMS中抽出来,单独管理着原来AMS中的Activity组件 。 现在我们对AMS的分析,也就包含对…...

Decoupling Knowledge from Memorization: Retrieval-augmented Prompt Learning
本文是LLM系列的文章,针对《Decoupling Knowledge from Memorization: Retrieval 知识与记忆的解耦:检索增强的提示学习 摘要1 引言2 提示学习的前言3 RETROPROMPT:检索增强的提示学习4 实验5 相关实验6 结论与未来工作 摘要 提示学习方法在…...
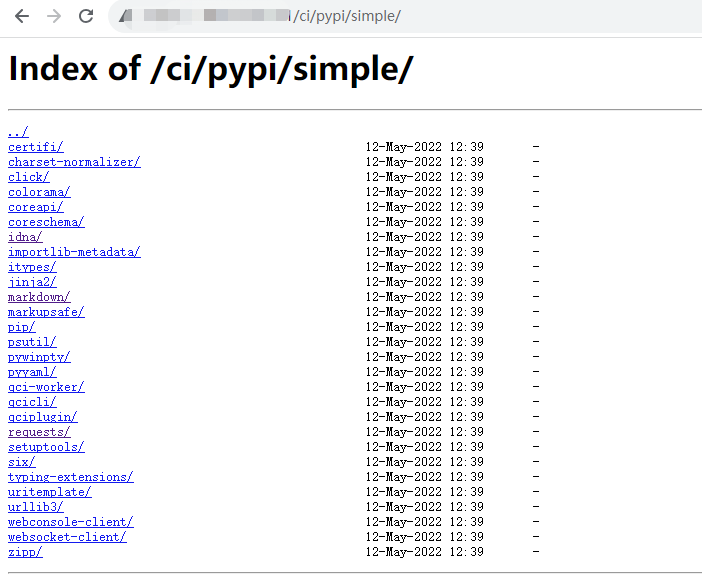
腾讯云coding平台平台inda目录遍历漏洞复现
前言 其实就是一个python的库可以遍历到,并不能遍历到别的路径下,后续可利用性不大,并且目前这个平台私有部署量不多,大多都是用腾讯云在线部署的。 CODING DevOps 是面向软件研发团队的一站式研发协作管理平台,提供…...

无法正常访问服务器
网络原因,本地网络:解决办法:检查本地网络是否正常,访问外网是否流畅。机房网络:通过路由追踪查看是否中间有 节点不通,确定是线路出现丢包。 远程连接,检查远程连接是否启用以及远程计算机上的…...
)
手把手教你用Simulink搭建Buck变换器:从元件库搜索到波形分析(MATLAB 2023b)
手把手教你用Simulink搭建Buck变换器:从元件库搜索到波形分析(MATLAB 2023b) 在电力电子领域,Buck变换器作为最基础的DC-DC降压拓扑,其仿真验证是每个工程师的必修课。MATLAB 2023b中的Simulink环境提供了高度可视化的…...

把笔记变成可生长的知识系统:Obsidian 技术介绍
Obsidian 不只是 Markdown 编辑器。它更像运行在本地文件之上的知识操作系统:用纯文本保存内容,用链接组织关系,用插件扩展能力,把经验沉淀为可检索、可复用、可迁移的长期资产。1. Obsidian 是什么 Obsidian 是一款以 Markdown 文…...

Vivado里手把手配置MIPI CSI-2 RX Subsystem IP核:从D-PHY选IO到Video Format Bridge算位宽
Vivado中MIPI CSI-2 RX Subsystem IP核配置实战:从D-PHY选型到视频格式转换 在ZYNQ系列SoC的视觉处理系统中,MIPI CSI-2接口作为连接图像传感器的标准协议,其硬件实现往往成为项目成败的关键节点。本文将深入剖析Vivado工具中MIPI CSI-2 RX S…...

Tina Linux存储介质实战切换:从eMMC到SPI NAND的配置迁移与避坑指南
1. 为什么需要从eMMC迁移到SPI NAND? 在嵌入式系统开发中,存储介质的选择往往决定了产品的成本和性能表现。eMMC作为传统存储方案,具有容量大、读写速度快的特点,但随着芯片价格上涨和供应链波动,越来越多的开发者开始…...

完全掌握Trainers‘ Legend G:深度解析赛马娘中文本地化插件的5大核心功能
完全掌握Trainers Legend G:深度解析赛马娘中文本地化插件的5大核心功能 【免费下载链接】Trainers-Legend-G 赛马娘本地化插件「Trainers Legend G」 项目地址: https://gitcode.com/gh_mirrors/tr/Trainers-Legend-G Trainers Legend G是一款专为赛马娘Pre…...

 ❀ 从零到一:FortiClient 7.0 企业级部署与策略配置全解析 ❀ FortiGate 防火墙)
【实战篇 / ZTNA】(7.0) ❀ 从零到一:FortiClient 7.0 企业级部署与策略配置全解析 ❀ FortiGate 防火墙
1. FortiClient 7.0 企业级部署前的关键规划 企业级部署FortiClient 7.0绝非简单的软件安装,而是涉及终端安全架构的整体升级。我在多个金融和制造业客户的实际部署中发现,前期规划不充分往往导致后期策略调整困难。首先需要明确的是,FortiCl…...
)
别再让Excel卡死了!手把手教你安装Oracle Crystal Ball并管理加载项(附32/64位安装包)
高效管理Oracle Crystal Ball加载项:告别Excel卡顿的终极指南 你是否经历过这样的场景:刚安装完Oracle Crystal Ball准备大展身手,却发现Excel启动速度慢得像蜗牛爬行?作为一款强大的蒙特卡洛模拟工具,Crystal Ball确…...

终极Python代码混淆指南:保护敏感逻辑的7个实用方法
终极Python代码混淆指南:保护敏感逻辑的7个实用方法 【免费下载链接】python-mastery Advanced Python Mastery (course by dabeaz) 项目地址: https://gitcode.com/gh_mirrors/py/python-mastery GitHub 加速计划 / py / python-mastery项目是 Advanced Pyt…...

从零到实战:用STM32F4的CAN总线做一个简易的‘车载仪表盘’数据收发Demo
从零到实战:用STM32F4的CAN总线构建车载仪表盘数据交互系统 当你坐进一辆现代汽车,仪表盘上跳动的转速、车速、油量数据背后,是CAN总线在默默协调着各个电子控制单元(ECU)的通信。本文将带你用两块STM32F407开发板,亲手搭建一个微…...