Flink流批一体计算(19):PyFlink DataStream API之State
目录
keyed state
Keyed DataStream
使用 Keyed State
实现了一个简单的计数窗口
状态有效期 (TTL)
过期数据的清理
全量快照时进行清理
增量数据清理
在 RocksDB 压缩时清理
Operator State算子状态
Broadcast State广播状态
keyed state
Keyed DataStream
使用 keyed state,首先需要为DataStream指定 key(主键)。这个主键用于状态分区(也会给数据流中的记录本身分区)。
使用 DataStream 中 Java/Scala API 的 keyBy(KeySelector) 或者是 Python API 的 key_by(KeySelector) 来指定 key。它将生成 KeyedStream,接下来允许使用 keyed state 操作。
Keyselector函数接收单条记录作为输入,返回这条记录的 key。该 key 可以为任何类型,但是它的计算产生方式必须是具备确定性的。
Flink的数据模型不基于key-value对,因此实际上将数据集在物理上封装成 key和 value是没有必要的。Key是“虚拟”的。它们定义为基于实际数据的函数,用以操纵分组算子。
使用 Keyed State
keyed state接口提供不同类型状态的访问接口,这些状态都作用于当前输入数据的key。
换句话说,这些状态仅可在KeyedStream上使用,在Java/Scala API上可以通过stream.keyBy(...)得到 KeyedStream,在Python API上可以通过 stream.key_by(...) 得到 KeyedStream。
所有支持的状态类型如下所示:
ValueState<T>: 保存一个可以更新和检索的值
Liststate<T>: 保存一个元素的列表。可以往这个列表中追加数据,并在当前的列表上进行检索。
ReducingState<T>: 保存一个单值,表示添加到状态的所有值的聚合。但使用 add(T) 增加元素,会使用提供的 ReduceFunction 进行聚合。
AggregatingState<IN, OUT>: 保留一个单值,表示添加到状态的所有值的聚合。使用 add(IN) 添加的元素会用指定的 AggregateFunction 进行聚合。
MapState<UK, UV>: 维护了一个映射列表。 你可以添加键值对到状态中,也可以获得反映当前所有映射的迭代器。
所有类型的状态还有一个clear() 方法,清除当前 key 下的状态数据,也就是当前输入元素的 key。
实现了一个简单的计数窗口
我们把元组的第一个元素当作 key。 该函数将出现的次数以及总和存储在 “ValueState” 中。
一旦出现次数达到 2,则将平均值发送到下游,并清除状态重新开始。 请注意,我们会为每个不同的 key(元组中第一个元素)保存一个单独的值。
必须创建一个 StateDescriptor,才能得到对应的状态句柄。 这保存了状态名称,状态所持有值的类型,并且可能包含用户指定的函数,例如ReduceFunction。
根据不同的状态类型,可以创建ValueStateDescriptor,ListstateDescriptor, AggregatingStateDescriptor, ReducingStateDescriptor 或MapStateDescriptor。
状态通过 RuntimeContext 进行访问,因此只能在 rich functions 中使用。
from pyflink.common.typeinfo import Types
from pyflink.datastream import StreamExecutionEnvironment, FlatMapFunction, RuntimeContext
from pyflink.datastream.state import ValueStateDescriptorclass CountWindowAverage(FlatMapFunction):def __init__(self):self.sum = Nonedef open(self, runtime_context: RuntimeContext):descriptor = ValueStateDescriptor("average", # the state nameTypes.PICKLED_BYTE_ARRAY() # type information)self.sum = runtime_context.get_state(descriptor)def flat_map(self, value):# access the state valuecurrent_sum = self.sum.value()if current_sum is None:current_sum = (0, 0)# update the countcurrent_sum = (current_sum[0] + 1, current_sum[1] + value[1])# update the stateself.sum.update(current_sum)# if the count reaches 2, emit the average and clear the stateif current_sum[0] >= 2:self.sum.clear()yield value[0], int(current_sum[1] / current_sum[0])env = StreamExecutionEnvironment.get_execution_environment()
env.from_collection([(1, 3), (1, 5), (1, 7), (1, 4), (1, 2)]) \.key_by(lambda row: row[0]) \.flat_map(CountWindowAverage()) \.print()env.execute()
# the printed output will be (1,4) and (1,5)状态有效期 (TTL)
任何类型的keyed state都可以有有效期(TTL)。如果配置了TTL且状态值已过期,则会尽最大可能清除对应的值。所有状态类型都支持单元素的TTL。 这意味着列表元素和映射元素将独立到期。
在使用状态 TTL 前,需要先构建一个StateTtlConfig 配置对象。 然后把配置传递到state descriptor中启用TTL功能。
from pyflink.common.time import Time
from pyflink.common.typeinfo import Types
from pyflink.datastream.state import ValueStateDescriptor, StateTtlConfigttl_config = StateTtlConfig \.new_builder(Time.seconds(1)) \.set_update_type(StateTtlConfig.UpdateType.OnCreateAndWrite) \.set_state_visibility(StateTtlConfig.StateVisibility.NeverReturnExpired) \.build()state_descriptor = ValueStateDescriptor("text state", Types.STRING())
state_descriptor.enable_time_to_live(ttl_config)TTL配置有以下几个选项:
newBuilder 的第一个参数表示数据的有效期,是必选项。
TTL 的更新策略(默认是 OnCreateAndWrite):
StateTtlConfig.UpdateType.OnCreateAndWrite - 仅在创建和写入时更新
StateTtlConfig.UpdateType.OnReadAndWrite - 读取时也更新
数据在过期但还未被清理时的可见性配置如下(默认为 NeverReturnExpired):
StateTtlConfig.StateVisibility.NeverReturnExpired - 不返回过期数据
(注意: 在PyFlink作业中,状态的读写缓存都将失效,这将导致一部分的性能损失)
NeverReturnExpired 情况下,过期数据就像不存在一样,不管是否被物理删除。这对于不能访问过期数据的场景下非常有用,比如敏感数据。
StateTtlConfig.StateVisibility.ReturnExpiredIfNotCleanedUp - 会返回过期但未清理的数据
(注意: 在PyFlink作业中,状态的读缓存将会失效,这将导致一部分的性能损失)
ReturnExpiredIfNotCleanedUp 在数据被物理删除前都会返回。
过期数据的清理
默认情况下,过期数据会在读取的时候被删除,例如 ValueState#value,同时会有后台线程定期清理(如果 StateBackend 支持的话)。可以通过 StateTtlConfig 配置关闭后台清理.
from pyflink.common.time import Time
from pyflink.datastream.state import StateTtlConfigttl_config = StateTtlConfig \.new_builder(Time.seconds(1)) \.disable_cleanup_in_background() \.build()可以配置更细粒度的后台清理策略。当前的实现中 HeapStateBackend 依赖增量数据清理,RocksDBStateBackend 利用压缩过滤器进行后台清理。
全量快照时进行清理
可以启用全量快照时进行清理的策略,这可以减少整个快照的大小。当前实现中不会清理本地的状态,但从上次快照恢复时,不会恢复那些已经删除的过期数据。
该策略可以通过 StateTtlConfig 配置进行配置,这种策略在 RocksDBStateBackend 的增量 checkpoint 模式下无效。
from pyflink.common.time import Time
from pyflink.datastream.state import StateTtlConfigttl_config = StateTtlConfig \.new_builder(Time.seconds(1)) \.cleanup_full_snapshot() \.build()这种清理方式可以在任何时候通过 StateTtlConfig 启用或者关闭,比如在从 savepoint 恢复时。
增量数据清理
现在仅 Heap state backend 支持增量清除机制。
增量式清理状态数据,在状态访问或/和处理时进行。如果没有 state 访问,也没有处理数据,则不会清理过期数据。增量清理会增加数据处理的耗时。
如果某个状态开启了该清理策略,则会在存储后端保留一个所有状态的惰性全局迭代器。
每次触发增量清理时,从迭代器中选择已经过期的数进行清理。
from pyflink.common.time import Time
from pyflink.datastream.state import StateTtlConfigttl_config = StateTtlConfig \.new_builder(Time.seconds(1)) \.cleanup_incrementally(10, True) \.build()该策略有两个参数。 第一个是每次清理时检查状态的条目数,在每个状态访问时触发。
第二个参数表示是否在处理每条记录时触发清理。 Heap backend 默认会检查 5 条状态,并且关闭在每条记录时触发清理。
在 RocksDB 压缩时清理
如果使用 RocksDB state backend,则会启用 Flink 为 RocksDB 定制的压缩过滤器。RocksDB 会周期性的对数据进行合并压缩从而减少存储空间。 Flink 提供的 RocksDB 压缩过滤器会在压缩时过滤掉已经过期的状态数据。
from pyflink.common.time import Time
from pyflink.datastream.state import StateTtlConfigttl_config = StateTtlConfig \.new_builder(Time.seconds(1)) \.cleanup_in_rocksdb_compact_filter(1000) \.build()Flink 处理一定条数的状态数据后,会使用当前时间戳来检测 RocksDB 中的状态是否已经过期, 你可以通过 StateTtlConfig.newBuilder(...).cleanupInRocksdbCompactFilter(long queryTimeAfterNumEntries) 方法指定处理状态的条数。
时间戳更新的越频繁,状态的清理越及时,但由于压缩会有调用 JNI 的开销,因此会影响整体的压缩性能。
RocksDB backend 的默认后台清理策略会每处理 1000 条数据进行一次。
注意:
压缩时调用 TTL 过滤器会降低速度。TTL 过滤器需要解析上次访问的时间戳,并对每个将参与压缩的状态进行是否过期检查。 对于集合型状态类型(比如 list 和 map),会对集合中每个元素进行检查。
对于元素序列化后长度不固定的列表状态,TTL 过滤器需要在每次 JNI 调用过程中,额外调用 Flink 的 java 序列化器, 从而确定下一个未过期数据的位置。
对已有的作业,这个清理方式可以在任何时候通过 StateTtlConfig 启用或禁用该特性,比如从 savepoint 重启后。
Operator State算子状态
Python DataStream API 仍无法支持算子状态
算子状态(或者非 keyed 状态)是绑定到一个并行算子实例的状态。Kafka Connector 是 Flink 中使用算子状态一个很具有启发性的例子。
Kafka consumer 每个并行实例维护了 topic partitions 和偏移量的 map 作为它的算子状态。
当并行度改变的时候,算子状态支持将状态重新分发给各并行算子实例。处理重分发过程有多种不同的方案。
在典型的有状态 Flink 应用中你无需使用算子状态。它大都作为一种特殊类型的状态使用。用于实现 source/sink,以及无法对 state 进行分区而没有主键的这类场景中。
Broadcast State广播状态
Python DataStream API 仍无法支持广播状态
广播状态是一种特殊的算子状态。引入它的目的在于支持一个流中的元素需要广播到所有下游任务的使用情形。在这些任务中广播状态用于保持所有子任务状态相同。
该状态接下来可在第二个处理记录的数据流中访问。可以设想包含了一系列用于处理其他流中元素规则的低吞吐量数据流,这个例子自然而然地运用了广播状态。
考虑到上述这类使用情形,广播状态和其他算子状态的不同之处在于:
它具有 map 格式,
它仅在一些特殊的算子中可用。这些算子的输入为一个广播数据流和非广播数据流,
这类算子可以拥有不同命名的多个广播状态 。
相关文章:
:PyFlink DataStream API之State)
Flink流批一体计算(19):PyFlink DataStream API之State
目录 keyed state Keyed DataStream 使用 Keyed State 实现了一个简单的计数窗口 状态有效期 (TTL) 过期数据的清理 全量快照时进行清理 增量数据清理 在 RocksDB 压缩时清理 Operator State算子状态 Broadcast State广播状态 keyed state Keyed DataStream 使用 k…...

adb shell获取安卓设备电量ROM内存帧率等信息
adb shell获取安卓设备电量ROM内存帧率等信息 adb shell指令获取Android设备的运行状态,如电池信息(包含电量百分比,电池状态,电池温度,电池电压,充放电电流),CPU占比,内…...
springboot服务端接口外网远程调试,并实现HTTP服务监听
文章目录 前言1. 本地环境搭建1.1 环境参数1.2 搭建springboot服务项目 2. 内网穿透2.1 安装配置cpolar内网穿透2.1.1 windows系统2.1.2 linux系统 2.2 创建隧道映射本地端口2.3 测试公网地址 3. 固定公网地址3.1 保留一个二级子域名3.2 配置二级子域名3.2 测试使用固定公网地址…...
代码随想录算法训练营之JAVA|第四十二天|70. 爬楼梯
今天是第 天刷leetcode,立个flag,打卡60天,如果做不到,完成一件评论区点赞最高的挑战。 算法挑战链接 70. 爬楼梯https://leetcode.cn/problems/climbing-stairs/ 第一想法 这是一个动态规划的入门题目,在看完完全背…...

【uniapp】 实现公共弹窗的封装以及调用
图例:红框区域为 “ 内容区域 ” 一、组件 <!-- 弹窗组件 --> <template> <view class"add_popup" v-if"person.isShowPopup"><view class"popup_cont" :style"{width:props.width&&props.width&…...

DevOps系列文章之 Python基础
列表 Python中的列表类似于C语言中的数组的概念,列表由内部的元素组成,元素可以是任何对象 Python中的列表是可变的 简单的理解就是:被初始化的列表,可以通过列表的API接口对列表的元素进行增删改查 1、定义列表 1.可以将列表当成…...

代码随想录第五十天
代码随想录第五十天 Leetcode 123. 买卖股票的最佳时机 IIILeetcode 188. 买卖股票的最佳时机 IV Leetcode 123. 买卖股票的最佳时机 III 题目链接: 买卖股票的最佳时机 III 自己的思路:想不到!!!!高维dp数组!&#x…...
redis缓存雪崩、穿透、击穿解决方案
redis缓存雪崩、穿透、击穿解决方案 背景缓存雪崩缓存击穿缓存穿透总结背景 关于缓存异常,我们常见的有三个问题:缓存雪崩、缓存击穿、缓存穿透。这三个问题一旦发生,会导致大量请求直接落到数据库层面。如果请求的并发量很大,会影响数据库的运行,严重的会导致数据库宕机…...

基于HarmonyOS ArkUI实现七夕壁纸轮播
七夕情人节,为了Ta,你打算用什么方式表达爱?是包包、鲜花、美酒、巧克力,还是一封充满爱意的短信?作为程序员,以代码之名,表达爱。本节将演示如何在基于HarmonyOS ArkUI的SwiperController、Ima…...
FusionAD:用于自动驾驶预测和规划任务的多模态融合
论文背景 自动驾驶(AD)任务通常分为感知、预测和规划。在传统范式中,AD中的每个学习模块分别使用自己的主干,独立地学习任务。 以前,基于端到端学习的方法通常基于透视视图相机和激光雷达信息直接输出控制命令或轨迹…...

C# 序列化json数据,datatabel转对象
datatabel直接转对象 转对象逻辑 1.将datatabel转为json格式 2.将json格式的内容转化为模型data_model的list对象 JsonConvert.DeserializeObject<List<data_model>>(JsonConvert.SerializeObject(dt))...

axios引入的详细讲解
1.安装axios:npm install axios,等待安装完毕即可 2.引用axios:在需要使用的页面中引用 import axios from axios 即可 axios请求的时候有两种方式:一种是get请求,另一种是post请求 get请求: axios({…...
16- flask-bootstrap模板的使用
Flask 中支持 flask-bootstrap模板 和 bootstrap-flask模板 # 不使用: bootstrap-flask # pip install bootstrap-flask1.3.1 # 支持bootstrap 4 # pip install flask-bootstrap # 支持bootstrap3# 中文文档:https://flask-bootstrap-zh.readthedocs.io/zh/latest/ # 样式文档…...

机器学习-神经网络(西瓜书)
神经网络 5.1 神经元模型 在生物神经网络中,神经元之间相互连接,当一个神经元受到的外界刺激足够大时,就会产生兴奋(称为"激活"),并将剩余的"刺激"向相邻的神经元传导。 神经元模型…...
Apache StreamPark系列教程第二篇——项目打包和开发
一、项目打包 项目依赖maven、jdk8.0、前端(node、npm) //下载代码 git clone//maven打包相关内容 mvn -N io.takari:maven:wrapper //前端打包相关内容 curl -sL https://rpm.nodesource.com/setup_16.x | bash - yum -y install nodejs npm -v npm install -g pnpm默认是h2…...
Visual Studio 2022的MFC框架——WinMain函数
我是荔园微风,作为一名在IT界整整25年的老兵,今天我们来重新审视一下Visual Studio 2022下开发工具的MFC框架知识。 大家还记得创建Win32应用程序是怎么弄的吗? Win32应用程序的建立到运行是有一个个关系分明的步骤的: 1.进入W…...
9. 解谜游戏
目录 题目 Description Input Notes 思路 暴力方法 递归法 注意事项 C代码(递归法) 关于DFS 题目 Description 小张是一个密室逃脱爱好者,在密室逃脱的游戏中,你需要解开一系列谜题最终拿到出门的密码。现在小张需要打…...
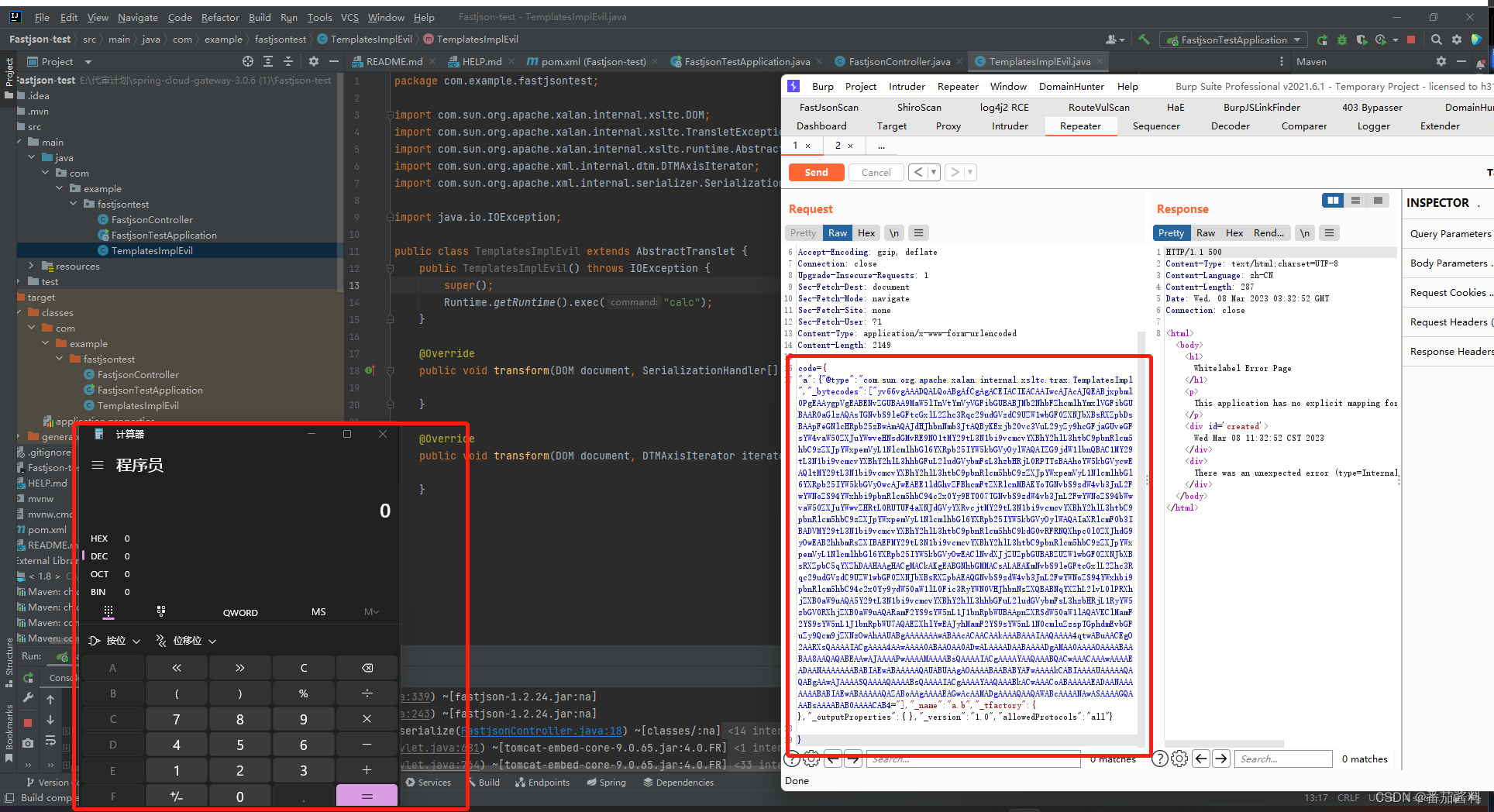
fastjson利用templatesImpl链
fastjson1.2.24 环境: pom.xml: <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLoc…...

OpenCV 开启O3优化
opencv默认没有开启O3优化选项,需要进行手动设置,下面是一种优化方法: 方法一 在 /opencv-4.5.5/cmake/OpenCVCompilerOptions.cmake 中的第 269 行做出以下修改: # 修改前 set(OPENCV_EXTRA_FLAGS_RELEASE "${OPENCV_EXT…...

css background实现四角边框
2023.8.27今天我学习了如何使用css制作一个四角边框,效果如下: .style{background: linear-gradient(#33cdfa, #33cdfa) left top,linear-gradient(#33cdfa, #33cdfa) left top,linear-gradient(#33cdfa, #33cdfa) right top,linear-gradient(#33cdfa, #…...
)
从SolidWorks到Geant4仿真:我的第一个粒子探测器CAD模型导入全记录(含CADMesh避坑点)
从SolidWorks到Geant4仿真:我的第一个粒子探测器CAD模型导入全记录(含CADMesh避坑点) 作为一名刚接触粒子探测器仿真的研究生,我花了整整两周时间才成功将SolidWorks设计的模型导入Geant4进行模拟。这个过程远比想象中复杂&#x…...

5秒无损转换B站缓存视频:m4s-converter完整使用指南
5秒无损转换B站缓存视频:m4s-converter完整使用指南 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾经在B站缓存了珍贵的学习…...

碧蓝航线自动化脚本:让游戏管理变得轻松高效
碧蓝航线自动化脚本:让游戏管理变得轻松高效 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAutoScript 你是否厌倦了每天重…...

百度网盘直链解析工具:突破下载限速的Python解决方案
百度网盘直链解析工具:突破下载限速的Python解决方案 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 你是否曾经为百度网盘的下载速度而烦恼?作为国内最…...

QKeyMapper深度解析:现代输入设备管理系统的架构揭秘与实战指南
QKeyMapper深度解析:现代输入设备管理系统的架构揭秘与实战指南 【免费下载链接】QKeyMapper [按键映射工具] QKeyMapper,Qt开发Win10&Win11可用,不修改注册表、不需重新启动系统,可立即生效和停止。支持游戏手柄映射到键鼠&a…...

Seraphine:英雄联盟智能BP助手与战绩查询工具完整指南
Seraphine:英雄联盟智能BP助手与战绩查询工具完整指南 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine 在英雄联盟的对局中,BP(禁选英雄)阶段往往是决定胜负的关…...

3分钟掌握Seraphine:英雄联盟智能助手完全指南
3分钟掌握Seraphine:英雄联盟智能助手完全指南 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine Seraphine是一款基于英雄联盟官方LCU API开发的智能游戏助手,通过自动BP系统和实时战绩查…...

多模态AI实战:基于OpenGVLab/Ask-Anything构建视觉问答系统
1. 项目概述:当视觉大模型学会“看图说话”最近在折腾多模态AI应用,发现了一个挺有意思的开源项目,叫OpenGVLab/Ask-Anything。简单来说,它就像一个给AI装上了“眼睛”和“嘴巴”的系统,你给它一张图片或一段视频&…...

实战指南:用UABEA高效解析Unity资源结构的5个关键要点
实战指南:用UABEA高效解析Unity资源结构的5个关键要点 【免费下载链接】UABEA c# uabe for newer versions of unity 项目地址: https://gitcode.com/gh_mirrors/ua/UABEA 在Unity开发的世界里,资源管理往往是项目优化中最棘手的一环。你是否曾经…...

平衡车PID积分饱和问题
你发现了PID最致命的坑! 你说的完全正确:积分(Ki)是累加的,会无限叠加,直接让PWM爆掉、车猛冲、失控! 这就是积分饱和 —— 99%初学者死在这里。 我现在彻底讲透积分为什么炸、怎么修复、平衡车…...