Linux 内核模块加载过程之重定位
文章目录
- 一、内核模块符号解析
- 1.1 内核模块重定位函数调用
- 1.1.1 struct load_info info
- 1.1.2 copy_module_from_user
- 1.2 simplify_symbols
- 1.2.1 simplify_symbols
- 1.2.2 resolve_symbol_wait
- 1.2.3 resolve_symbol
- 1.2.4 find_symbol
- 二、 apply_relocations
- 2.1 apply_relocations
- 2.1.1 Elf64_Ehdr
- 2.1.2 Elf64_Shdr
- 2.2 x86_64
- 2.3 Arm64
- 参考资料
一、内核模块符号解析
1.1 内核模块重定位函数调用
1.1.1 struct load_info info
SYSCALL_DEFINE3(init_module,......)-->load_module()-->simplify_symbols()-->apply_relocations()-->post_relocation()
加载模块只需要读入模块的二进制代码即可,然后执行init_module系统调用。
我们先介绍下struct load_info info结构体。
SYSCALL_DEFINE3(init_module, void __user *, umod,unsigned long, len, const char __user *, uargs)
{int err;struct load_info info = { };......err = copy_module_from_user(umod, len, &info);if (err)return err;return load_module(&info, uargs, 0);
}
struct load_info {const char *name;/* pointer to module in temporary copy, freed at end of load_module() */struct module *mod;Elf_Ehdr *hdr;unsigned long len;Elf_Shdr *sechdrs;char *secstrings, *strtab;unsigned long symoffs, stroffs;struct _ddebug *debug;unsigned int num_debug;bool sig_ok;
#ifdef CONFIG_KALLSYMSunsigned long mod_kallsyms_init_off;
#endifstruct {unsigned int sym, str, mod, vers, info, pcpu;} index;
};
struct load_info 是一个用于加载模块时存储相关信息的数据结构。
该结构体包含以下成员:
name:模块的名称,以字符串形式存储。
mod:指向临时复制的模块结构体的指针,在 load_module() 结束时释放。
hdr:指向 ELF 文件头(Elf_Ehdr)的指针,用于存储模块的 ELF 文件头信息。
len:模块数据的长度(字节数)。
sechdrs:指向节头表(Elf_Shdr)的指针,用于存储模块的节头表信息。
secstrings:指向节头字符串表的指针,用于存储节头字符串表的内容。
strtab:指向字符串表的指针,用于存储字符串表的内容。
symoffs:符号表的偏移量。
stroffs:字符串表的偏移量。
debug:指向 _ddebug 结构体的指针,用于存储调试信息。
num_debug:调试信息的数量。
sig_ok:表示模块是否通过了数字签名验证。
mod_kallsyms_init_off:用于内核符号表中模块的初始化偏移量。
index:一个匿名结构体,包含以下成员:
sym:符号表索引。
str:字符串表索引。
mod:模块索引。
vers:版本索引。
info:信息索引。
pcpu:percpu 变量索引。
该结构体用于在加载模块时存储各种相关信息,包括模块的名称、ELF 文件头、节头表、字符串表、符号表等。这些信息在模块加载和处理过程中起着重要的作用,用于解析和定位模块的各个部分。
struct load_info 在模块加载过程中起着重要作用。它作为一个容器,用于存储与正在加载的模块相关的各种信息和数据。struct load_info 的目的是在加载过程中促进模块的解析、处理和初始化。以下是它的主要作用:
存储模块元数据:该结构体保存了关于模块的基本元数据,例如模块的名称(name)。这些信息有助于识别和区分正在加载的模块。
临时模块存储:mod 成员指向模块结构体(struct module)的临时副本。这个副本在加载过程中使用,并在 load_module() 函数结束时释放。它允许加载过程在模块完全初始化之前对模块结构进行操作和修改。
ELF 头和节头存储:hdr 成员是指向模块的 ELF 头部(Elf_Ehdr)的指针。它存储了关于 ELF 文件格式的信息,例如入口点和节头表的位置。sechdrs 成员指向节头表(Elf_Shdr),其中包含了关于模块每个节的详细信息。
字符串和符号表存储:secstrings 成员保存了节头字符串表,其中存储了各个节的名称。strtab 成员指向字符串表,它包含了模块使用的各种字符串,如符号名称。这些表对于符号解析和调试非常重要。
符号和字符串偏移量:symoffs 和 stroffs 成员分别存储了符号表和字符串表在模块中的偏移量。这些偏移量用于在符号解析和其他操作中定位和访问符号和字符串。
调试信息:debug 成员指向 _ddebug 结构体,它存储了模块的调试信息。这些信息对于调试和跟踪模块的行为非常有用。
其他辅助信息:该结构体还包括其他成员,如 num_debug(调试条目的数量)、sig_ok(指示模块是否通过了数字签名验证)、mod_kallsyms_init_off(模块在内核符号表中的初始化偏移量)和 index(一个嵌套的结构体,包含不同类型表的各种索引)。
1.1.2 copy_module_from_user
/* Sets info->hdr and info->len. */
static int copy_module_from_user(const void __user *umod, unsigned long len,struct load_info *info)
{int err;info->len = len;if (info->len < sizeof(*(info->hdr)))return -ENOEXEC;err = security_kernel_load_data(LOADING_MODULE);if (err)return err;/* Suck in entire file: we'll want most of it. */info->hdr = __vmalloc(info->len,GFP_KERNEL | __GFP_NOWARN, PAGE_KERNEL);if (!info->hdr)return -ENOMEM;if (copy_chunked_from_user(info->hdr, umod, info->len) != 0) {vfree(info->hdr);return -EFAULT;}return 0;
}
这是一个用于从用户空间复制模块数据到内核空间的函数 copy_module_from_user 的代码片段。该函数接受用户空间的模块数据 umod 和数据长度 len,并将其复制到内核空间中的 info->hdr 中。
函数的实现逻辑如下:
(1)首先,将数据长度 len 存储到 info->len 中。
(2)如果数据长度小于 info->hdr 的大小,表示数据长度不足以存储模块的头部信息,这种情况下返回错误码 -ENOEXEC。
(3)调用 security_kernel_load_data 函数来进行内核安全性检查。如果检查失败,返回相应的错误码。
int security_kernel_load_data(enum kernel_load_data_id id)
{int ret;ret = call_int_hook(kernel_load_data, 0, id);if (ret)return ret;return ima_load_data(id);
}
EXPORT_SYMBOL_GPL(security_kernel_load_data);
security_kernel_load_data是内核模块加载过程中的一个 LSM点。
(4)分配内核可执行的虚拟内存空间来存储模块的头部信息。使用 __vmalloc 函数来分配内存,分配的大小为 info->len 字节。如果内存分配失败,返回错误码 -ENOMEM。
(5)使用 copy_chunked_from_user 函数将用户空间的模块数据 umod 复制到内核空间的 info->hdr 中。如果复制过程中出现错误,释放之前分配的内存并返回错误码 -EFAULT。
(6)如果复制成功,返回 0 表示成功。
该函数的主要功能是从用户空间复制模块数据到内核空间,并将复制后的数据存储在 info->hdr 中供后续处理和加载使用。
static int copy_chunked_from_user(void *dst, const void __user *usrc, unsigned long len)
{do {unsigned long n = min(len, COPY_CHUNK_SIZE);if (copy_from_user(dst, usrc, n) != 0)return -EFAULT;cond_resched();dst += n;usrc += n;len -= n;} while (len);return 0;
}
这是一个用于从用户空间按块复制数据到内核空间的函数 copy_chunked_from_user 的代码片段。该函数接受目标内核地址 dst、源用户地址 usrc 和数据长度 len,并按照指定的块大小进行分块复制。
函数的实现逻辑如下:
进入一个循环,直到全部数据被复制完毕。
在每次循环中,计算当前块的大小,选择较小值作为复制的长度。min(len, COPY_CHUNK_SIZE) 中的 COPY_CHUNK_SIZE 是一个预定义的常量,表示每个块的大小。
使用 copy_from_user 函数将当前块的数据从用户空间复制到目标内核地址 dst。如果复制过程中出现错误,返回错误码 -EFAULT。
调用 cond_resched 函数,让出 CPU,允许其他任务执行,以提高系统的响应性。
更新目标内核地址 dst、源用户地址 usrc 和剩余长度 len,以便处理下一个块。
检查剩余长度 len 是否为 0,如果仍有剩余数据,则继续循环,否则退出循环。
如果数据复制成功,返回 0 表示成功。
该函数的作用是按照指定的块大小,从用户空间按块复制数据到目标内核地址。由于复制过程中可能会耗费较长时间,因此在每个块的复制结束后调用 cond_resched 函数以确保系统能够及时响应其他任务。
1.2 simplify_symbols
1.2.1 simplify_symbols
/* Change all symbols so that st_value encodes the pointer directly. */
static int simplify_symbols(struct module *mod, const struct load_info *info)
{Elf_Shdr *symsec = &info->sechdrs[info->index.sym];Elf_Sym *sym = (void *)symsec->sh_addr;unsigned long secbase;unsigned int i;int ret = 0;const struct kernel_symbol *ksym;for (i = 1; i < symsec->sh_size / sizeof(Elf_Sym); i++) {const char *name = info->strtab + sym[i].st_name;switch (sym[i].st_shndx) {case SHN_COMMON:/* Ignore common symbols */if (!strncmp(name, "__gnu_lto", 9))break;/* We compiled with -fno-common. These are notsupposed to happen. */pr_debug("Common symbol: %s\n", name);pr_warn("%s: please compile with -fno-common\n",mod->name);ret = -ENOEXEC;break;case SHN_ABS:/* Don't need to do anything */pr_debug("Absolute symbol: 0x%08lx\n",(long)sym[i].st_value);break;case SHN_LIVEPATCH:/* Livepatch symbols are resolved by livepatch */break;case SHN_UNDEF:ksym = resolve_symbol_wait(mod, info, name);/* Ok if resolved. */if (ksym && !IS_ERR(ksym)) {sym[i].st_value = kernel_symbol_value(ksym);break;}/* Ok if weak. */if (!ksym && ELF_ST_BIND(sym[i].st_info) == STB_WEAK)break;ret = PTR_ERR(ksym) ?: -ENOENT;pr_warn("%s: Unknown symbol %s (err %d)\n",mod->name, name, ret);break;default:/* Divert to percpu allocation if a percpu var. */if (sym[i].st_shndx == info->index.pcpu)secbase = (unsigned long)mod_percpu(mod);elsesecbase = info->sechdrs[sym[i].st_shndx].sh_addr;sym[i].st_value += secbase;break;}}return ret;
}
simplify_symbols是在 Linux 内核中用于简化符号表的函数。它的作用是修改符号表中的符号,使得 st_value 字段直接编码为指针值,以提高符号访问的效率。
(1)首先,通过 info 参数获取符号表的节头信息(symsec)和符号表的起始地址(sym)。
(2)在 for 循环中,遍历符号表中的每个符号(从索引 1 开始,索引 0 通常是一个特殊符号)。
(3)对于每个符号,从字符串表中获取符号的名称。名称存储在字符串表中的偏移量(st_name)指定的位置。
(4)根据符号的 st_shndx 字段的值,执行不同的操作。
这里只考虑 st_shndx 字段 = SHN_UNDEF 的情况:
SHN_UNDEF:表示未定义符号,需要解析其值。使用 resolve_symbol_wait 函数尝试解析符号。
如果成功解析符号,则将 st_value 设置为解析到的内核符号的值。
如果解析失败但是符号属于弱符号(weak symbol),则忽略解析失败,保留符号的原始值。
如果解析失败且符号不是弱符号,则将返回错误代码,并打印警告信息。
这段代码的目的是优化符号访问的效率,通过直接编码指针值到符号表中的 st_value 字段,避免了在运行时进行额外的计算。这对于内核符号的访问和解析过程非常重要,因为它们在内核的各个部分被广泛使用。
1.2.2 resolve_symbol_wait
static const struct kernel_symbol *
resolve_symbol_wait(struct module *mod,const struct load_info *info,const char *name)
{const struct kernel_symbol *ksym;char owner[MODULE_NAME_LEN];if (wait_event_interruptible_timeout(module_wq,!IS_ERR(ksym = resolve_symbol(mod, info, name, owner))|| PTR_ERR(ksym) != -EBUSY,30 * HZ) <= 0) {pr_warn("%s: gave up waiting for init of module %s.\n",mod->name, owner);}return ksym;
}
这段代码的目的是解析内核符号 – 使用 resolve_symbol 函数尝试解析符号。该函数根据给定的模块、加载信息和符号名称,查找并返回符号的内核表示。,并在解析完成前等待模块的初始化。它使用 resolve_symbol 函数来实际解析符号,并使用 wait_event_interruptible_timeout 函数来等待模块初始化完成。等待的目的是确保符号的解析是在模块完全初始化之后进行的,以避免潜在的竞争条件或使用未完全初始化的模块导致的错误。
1.2.3 resolve_symbol
/* Resolve a symbol for this module. I.e. if we find one, record usage. */
static const struct kernel_symbol *resolve_symbol(struct module *mod,const struct load_info *info,const char *name,char ownername[])
{struct module *owner;const struct kernel_symbol *sym;const s32 *crc;int err;/** The module_mutex should not be a heavily contended lock;* if we get the occasional sleep here, we'll go an extra iteration* in the wait_event_interruptible(), which is harmless.*/sched_annotate_sleep();mutex_lock(&module_mutex);sym = find_symbol(name, &owner, &crc,!(mod->taints & (1 << TAINT_PROPRIETARY_MODULE)), true);if (!sym)goto unlock;if (!check_version(info, name, mod, crc)) {sym = ERR_PTR(-EINVAL);goto getname;}err = ref_module(mod, owner);if (err) {sym = ERR_PTR(err);goto getname;}getname:/* We must make copy under the lock if we failed to get ref. */strncpy(ownername, module_name(owner), MODULE_NAME_LEN);
unlock:mutex_unlock(&module_mutex);return sym;
}
函数 resolve_symbol,用于解析内核模块中未定义的符号引用,并记录符号的使用情况。
1.2.4 find_symbol
/* Find a symbol and return it, along with, (optional) crc and* (optional) module which owns it. Needs preempt disabled or module_mutex. */
const struct kernel_symbol *find_symbol(const char *name,struct module **owner,const s32 **crc,bool gplok,bool warn)
{struct find_symbol_arg fsa;fsa.name = name;fsa.gplok = gplok;fsa.warn = warn;if (each_symbol_section(find_symbol_in_section, &fsa)) {if (owner)*owner = fsa.owner;if (crc)*crc = fsa.crc;return fsa.sym;}pr_debug("Failed to find symbol %s\n", name);return NULL;
}
EXPORT_SYMBOL_GPL(find_symbol);
函数 find_symbol,用于在内核中查找符号并返回它,同时可选地返回符号的校验和和拥有者模块。
调用 each_symbol_section 函数,对每个符号节调用 find_symbol_in_section 函数进行符号查找。
如果找到符号,将符号指针赋值给 fsa.sym,并可选地将符号所属的模块赋值给 fsa.owner,将符号的校验和赋值给 fsa.crc。
如果找到符号,返回 fsa.sym。
该函数用于在内核中查找给定名称的符号。它通过遍历每个符号节来查找符号,并在找到符号后返回相应的信息。函数的实现依赖于 each_symbol_section 和 find_symbol_in_section 函数。
二、 apply_relocations
2.1 apply_relocations
static int apply_relocations(struct module *mod, const struct load_info *info)
{unsigned int i;int err = 0;/* Now do relocations. */for (i = 1; i < info->hdr->e_shnum; i++) {unsigned int infosec = info->sechdrs[i].sh_info;/* Not a valid relocation section? */if (infosec >= info->hdr->e_shnum)continue;/* Don't bother with non-allocated sections */if (!(info->sechdrs[infosec].sh_flags & SHF_ALLOC))continue;/* Livepatch relocation sections are applied by livepatch */if (info->sechdrs[i].sh_flags & SHF_RELA_LIVEPATCH)continue;if (info->sechdrs[i].sh_type == SHT_REL)err = apply_relocate(info->sechdrs, info->strtab,info->index.sym, i, mod);else if (info->sechdrs[i].sh_type == SHT_RELA)err = apply_relocate_add(info->sechdrs, info->strtab,info->index.sym, i, mod);if (err < 0)break;}return err;
}
使用一个循环遍历模块加载信息中的每个重定位节。
获取当前重定位节的 sh_info 字段,表示关联的节索引。如果 sh_info 不是有效的节索引(大于等于节的总数),则跳过该重定位节。
检查当前重定位节的 sh_flags 字段是否包含 SHF_ALLOC 标志,判断是否为已分配的节。如果不是已分配的节,则跳过该重定位节。
检查当前重定位节的 sh_flags 字段是否包含 SHF_RELA_LIVEPATCH 标志,判断是否为 Livepatch 重定位节。如果是 Livepatch 重定位节,则跳过该重定位节。
根据重定位节的类型进行相应的重定位操作:
如果重定位节的类型是 SHT_REL,则调用 apply_relocate 函数应用重定位信息。
如果重定位节的类型是 SHT_RELA,则调用 apply_relocate_add 函数应用重定位信息。
对于内核模块重定位的类型基本都是SHT_RELA,所以我们关注的是apply_relocate_add 函数。
2.1.1 Elf64_Ehdr
typedef struct elf64_hdr {unsigned char e_ident[EI_NIDENT]; /* ELF "magic number" */Elf64_Half e_type;Elf64_Half e_machine;Elf64_Word e_version;Elf64_Addr e_entry; /* Entry point virtual address */Elf64_Off e_phoff; /* Program header table file offset */Elf64_Off e_shoff; /* Section header table file offset */Elf64_Word e_flags;Elf64_Half e_ehsize;Elf64_Half e_phentsize;Elf64_Half e_phnum;Elf64_Half e_shentsize;Elf64_Half e_shnum;Elf64_Half e_shstrndx;
} Elf64_Ehdr;
Elf64_Ehdr 是一个用于表示 ELF64(64位 ELF 文件格式)文件头的结构体类型。它包含以下成员:
e_ident:ELF 文件的标识符数组,也称为 “ELF 魔数”。它用于识别文件是否符合 ELF 文件格式的规范。
e_type:ELF 文件的类型。它表示文件的类型,如可执行文件、共享对象、目标文件等。
e_machine:目标体系结构的架构类型。它表示文件的目标运行环境所使用的体系结构。
e_version:ELF 文件的版本号。它指示 ELF 文件格式的版本。
e_entry:程序的入口点的虚拟地址。它表示程序执行的起始地址。
e_phoff:程序头表(Program Header Table)在文件中的偏移量。它指示程序头表的位置和大小。
e_shoff:节头表(Section Header Table)在文件中的偏移量。它指示节头表的位置和大小。
e_flags:特定标志位。它包含一些特定于体系结构或文件的标志。
e_ehsize:ELF 文件头的大小。它表示 ELF 文件头的字节大小。
e_phentsize:程序头表项的大小。它表示每个程序头表项的字节大小。
e_phnum:程序头表中的条目数。它表示程序头表中包含的程序头表项的数量。
e_shentsize:节头表项的大小。它表示每个节头表项的字节大小。
e_shnum:节头表中的条目数。它表示节头表中包含的节头表项的数量。
e_shstrndx:节头字符串表的索引。它表示节头字符串表在节头表中的索引,用于查找节名。
对于内核模块重定位过程中,对于Elf64_Ehdr我们需要关注的字段是e_shnum。
e_shnum:节头表中的条目数。它表示节头表中包含的节头表项的数量。
2.1.2 Elf64_Shdr
typedef struct elf64_shdr {Elf64_Word sh_name; /* Section name, index in string tbl */Elf64_Word sh_type; /* Type of section */Elf64_Xword sh_flags; /* Miscellaneous section attributes */Elf64_Addr sh_addr; /* Section virtual addr at execution */Elf64_Off sh_offset; /* Section file offset */Elf64_Xword sh_size; /* Size of section in bytes */Elf64_Word sh_link; /* Index of another section */Elf64_Word sh_info; /* Additional section information */Elf64_Xword sh_addralign; /* Section alignment */Elf64_Xword sh_entsize; /* Entry size if section holds table */
} Elf64_Shdr;
Elf64_Shdr 结构体定义了 ELF64 格式中节头部的布局和字段的含义,具体解释如下:
sh_name:该字段是一个索引,指示节的名称在字符串表中的位置。字符串表是一个包含所有节名的字符串数组,它位于 ELF 文件的一个特殊节中。
sh_type:该字段指示节的类型,定义了节所包含数据或代码的语义。例如,常见的节类型包括代码段、数据段、符号表、字符串表等。
sh_flags:该字段包含了节的各种属性和标志。这些标志可以指示节的可写性、可执行性、对齐要求等属性。
sh_addr:该字段指示节在程序执行时的虚拟地址。对于可执行文件,这是节在内存中加载的地址。
sh_offset:该字段指示节在 ELF 文件中的偏移量,即该节的数据或代码在文件中的位置。
sh_size:该字段指示节的大小(以字节为单位),即该节所占用的文件空间大小。
sh_link:该字段是一个索引,指示该节相关联的其他节的索引。具体关联的节类型取决于 sh_type 字段的值。
sh_info:该字段包含附加的节信息。具体的含义取决于 sh_type 字段的值。
sh_addralign:该字段指示节的对齐要求,即节在内存中的起始地址需要满足的对齐条件。通常,节的对齐要求是根据节的特性和用途来确定的。
sh_entsize:该字段指示节中每个表项的大小。仅在节类型为表格型(如符号表)时才具有意义,用于计算表中条目的数量。
其中sh_info字段:
sh_info 字段是 ELF64 节头部中的一个字段,用于存储与特定节相关的附加信息。该字段的具体含义取决于节的类型(sh_type 字段)。
对于某些特定的节类型,sh_info 字段具有以下含义:
(1)对于符号表节(SHT_SYMTAB)和动态符号表节(SHT_DYNSYM),sh_info 字段存储了符号表中本地符号的数量。本地符号是指与当前目标文件或共享对象相关的符号。通过 sh_info 字段的值,可以确定符号表中本地符号的范围。
(2)对于重定位节(SHT_REL 和 SHT_RELA),sh_info 字段指示关联的节的索引。这个关联节包含了重定位所需的目标符号或节的信息。通过 sh_info 字段的值,可以确定重定位节与其关联的目标节。
对于这里我们主要关注 sh_type = SHT_RELA,通过 sh_info 字段的值,可以确定重定位节与其关联的目标节。
假设有一个 ELF 文件,其中包含以下两个节:
.text 节(类型为 SHT_PROGBITS):包含可执行代码的指令。
.rel.text 节(类型为 SHT_RELA):包含与 .text 节相关的重定位信息。
在这个示例中,.rel.text 节是关联于 .text 节的重定位节。sh_info 字段的值将提供有关如何解析 .rel.text 节的信息。
首先,查看 .rel.text 节的 sh_info 字段的值。假设 sh_info 字段的值为 4,这意味着 .rel.text 节与索引为 4 的节相关联。
接下来,查找索引为 4 的节,即关联节。假设关联节是 .symtab 节(符号表节)。
通过这个例子,我们可以得出以下结论:
.rel.text 节与 .text 节相关联,通过 sh_info 字段的值 4 来指示关联节的索引为 4。
关联节是 .symtab 节,它可能包含了重定位所需的目标符号信息。
通过 sh_info 字段的值,可以确定关联的节,进而了解到与重定位相关的目标符号或目标节的位置和信息。
2.2 x86_64
int apply_relocate_add(Elf64_Shdr *sechdrs,const char *strtab,unsigned int symindex,unsigned int relsec,struct module *me)
{unsigned int i;Elf64_Rela *rel = (void *)sechdrs[relsec].sh_addr;Elf64_Sym *sym;void *loc;u64 val;for (i = 0; i < sechdrs[relsec].sh_size / sizeof(*rel); i++) {/* This is where to make the change *///获取需要重定位的位置 Ploc = (void *)sechdrs[sechdrs[relsec].sh_info].sh_addr+ rel[i].r_offset;/* This is the symbol it is referring to. Note that allundefined symbols have been resolved. *///从符号表中获取需要重定位符号的值 S//符号表中有多个符号,我们需要获取要重定位的符号,其在符号表中的位置索引:ELF64_R_SYM(rel[i].r_info)sym = (Elf64_Sym *)sechdrs[symindex].sh_addr+ ELF64_R_SYM(rel[i].r_info);//获取 S + Aval = sym->st_value + rel[i].r_addend;switch (ELF64_R_TYPE(rel[i].r_info)) {......case R_X86_64_PC32:case R_X86_64_PLT32:if (*(u32 *)loc != 0)goto invalid_relocation;val -= (u64)loc;*(u32 *)loc = val;......}}return 0;......
}
该函数遍历重定位节中的每个重定位项,并根据不同的重定位类型对指定位置进行修正。
其中 Elf64_Rela :
typedef struct elf64_rela {Elf64_Addr r_offset; /* Location at which to apply the action */Elf64_Xword r_info; /* index and type of relocation */Elf64_Sxword r_addend; /* Constant addend used to compute value */
} Elf64_Rela;
Elf64_Rela 是一个用于表示 ELF64(64位 ELF 文件格式)重定位项的结构体类型。它包含以下成员:
(1)r_offset:重定位项的目标地址。它指示在哪个位置应用重定位操作。
(2)r_info:重定位项的索引和类型。索引和类型的组合指示了重定位操作应该如何执行。具体来说,它将索引和重定位类型编码为一个 64 位的无符号整数(Elf64_Xword 类型)。
(3)r_addend:用于计算修正值的常量加数。在执行重定位操作时,将目标地址的值与该常量加数相加,以计算最终的修正值。
重定位项的索引和类型的计算:
用于从 64 位的 r_info 值中提取符号索引和重定位类型的宏定义。
#define ELF64_R_SYM(i) ((i) >> 32)
#define ELF64_R_TYPE(i) ((i) & 0xffffffff)
ELF64_R_SYM(i) 宏将 64 位的 r_info 值右移 32 位,并返回高位部分,即符号索引。在 ELF64 格式中,符号索引占据了高 32 位。
ELF64_R_TYPE(i) 宏将 64 位的 r_info 值与 0xffffffff 进行按位与操作,返回低位部分,即重定位类型。在 ELF64 格式中,重定位类型占据了低 32 位。
这两个宏的作用是从 r_info 值中提取符号索引和重定位类型,以便在重定位过程中进行符号解析和类型判断。通过这样的宏定义,可以方便地从 r_info 值中获取所需的信息,而无需手动进行位操作。
其中 Elf64_Sym :
Elf64_Sym 是一个用于表示 ELF64(64位 ELF 文件格式)符号表项的结构体类型。它包含以下成员:
(1)st_name:符号的名称在字符串表中的索引。它指示了符号的名称在字符串表中的位置。
(2)st_info:符号的类型和绑定属性。它是一个无符号字符,用于编码符号的类型和绑定属性。
(3)st_other:没有定义的含义,通常为0。保留字段,未使用。
(4)st_shndx:关联的节(section)索引。它表示符号所属的节的索引,指示符号在哪个节中定义或引用。
(5)st_value:符号的值。它表示符号的地址或常量值。
(6)st_size:关联的符号大小。它表示符号的大小或长度,以字节为单位。
Elf64_Rela *rel = (void *)sechdrs[relsec].sh_addr; 将重定位节的起始地址转换为指向 Elf64_Rela 类型的指针,并将结果存储在 rel 变量中。
loc = (void *)sechdrs[sechdrs[relsec].sh_info].sh_addr + rel[i].r_offset; 计算出当前重定位项指向的位置,根据重定位项的偏移量(r_offset)在指定节的起始地址上进行偏移。
sym = (Elf64_Sym *)sechdrs[symindex].sh_addr + ELF64_R_SYM(rel[i].r_info); 根据重定位项中的符号索引(ELF64_R_SYM(rel[i].r_info)),找到对应的符号表项,并将结果存储在 sym 变量中。
val = sym->st_value + rel[i].r_addend; 计算出修正后的值,将符号的值(sym->st_value)与重定位项的附加值(rel[i].r_addend)相加,并将结果存储在 val 变量中。
根据重定位项的类型进行不同的操作(这里我们只关注R_X86_64_PC32重定位类型):
case R_X86_64_PC32:case R_X86_64_PLT32:if (*(u32 *)loc != 0)goto invalid_relocation;val -= (u64)loc;*(u32 *)loc = val;
对于 R_X86_64_PC32 和 R_X86_64_PLT32 类型,将修正后的值减去当前重定位项指向的位置,并将结果存储到当前重定位项指向的位置。
val -= (u64)loc; 将修正后的值 val 减去当前重定位项指向的位置 loc,得到相对于当前位置的偏移量。
*(u32 *)loc = val; 将修正后的偏移量存储到当前重定位项指向的位置。
这段代码的作用是将修正后的相对偏移量(val)存储到指定位置上,这些位置通常是指令中的相对跳转或调用目标地址。在这种情况下,修正的偏移量是相对于当前指令的位置计算得出的。
2.3 Arm64
int apply_relocate_add(Elf64_Shdr *sechdrs,const char *strtab,unsigned int symindex,unsigned int relsec,struct module *me)
{unsigned int i;int ovf;bool overflow_check;Elf64_Sym *sym;void *loc;u64 val;//获取重定位节的起始虚拟地址Elf64_Rela *rel = (void *)sechdrs[relsec].sh_addr;for (i = 0; i < sechdrs[relsec].sh_size / sizeof(*rel); i++) {//loc 对应于 AArch64 ELF 文档中的 P//通过 sh_info 字段的值,可以确定关联的节,获取重定位节的虚拟地址 //重定位节的虚拟地址 + rel[i].r_offset = 需要重定位的位置 Ploc = (void *)sechdrs[sechdrs[relsec].sh_info].sh_addr+ rel[i].r_offset;/* sym is the ELF symbol we're referring to. *///获取该重定位项在符号表中的索引位置的符号项//将符号表的起始地址转化为 (Elf64_Sym *)指针,那么+一个索引值r_info,就表示获取符号表中第r_info位置的符号项sym = (Elf64_Sym *)sechdrs[symindex].sh_addr+ ELF64_R_SYM(rel[i].r_info);// val 对应于 AArch64 ELF 文档中的 (S + A) val = sym->st_value + rel[i].r_addend;/* Check for overflow by default. */overflow_check = true;/* Perform the static relocation. */switch (ELF64_R_TYPE(rel[i].r_info)) {/* Null relocations. */case R_ARM_NONE:case R_AARCH64_NONE:ovf = 0;break;/* Data relocations. */......case R_AARCH64_PREL32:ovf = reloc_data(RELOC_OP_PREL, loc, val, 32);break;......}}
}
apply_relocate_add的函数,它对一个ELF(可执行和可链接格式)内核模块二进制文件进行重定位。重定位是调整二进制文件中符号引用的过程,使其在加载到内存时指向正确的内存位置。
函数通过循环迭代每个重定位节的重定位项来进行处理。在循环内部,根据重定位项的信息计算重定位符号的位置 loc 和 重定位符号的值val 。
然后,根据重定位类型 ELF64_R_TYPE(rel[i].r_info) 执行特定类型的重定位。
根据重定位类型采取不同的处理方式,并相应地调用不同的辅助函数。
我们这里主要关注重定位类型 R_AARCH64_PREL32 。R_AARCH64_PREL32 对应的辅助函数reloc_data:
int ovf;
ovf = reloc_data(RELOC_OP_PREL, loc, val, 32);
enum aarch64_reloc_op {RELOC_OP_NONE,RELOC_OP_ABS,RELOC_OP_PREL,RELOC_OP_PAGE,
};static u64 do_reloc(enum aarch64_reloc_op reloc_op, __le32 *place, u64 val)
{switch (reloc_op) {......case RELOC_OP_PREL:return val - (u64)place;return 0;......}pr_err("do_reloc: unknown relocation operation %d\n", reloc_op);return 0;
}static int reloc_data(enum aarch64_reloc_op op, void *place, u64 val, int len)
{//调用 do_reloc 函数对传入的值进行修正,并将修正后的值存储在 sval 变量中。s64 sval = do_reloc(op, place, val);switch (len) {......//如果长度为 32,将 sval 强制转换为 s32 类型,并将其存储到 place 指针指向的位置上。case 32:*(s32 *)place = sval;if (sval < S32_MIN || sval > U32_MAX)return -ERANGE;break;......}return 0;
}
根据传入的操作类型和值,将修正后的数据存储到给定的位置指针处。即将重定位操作后修正后的数据写到 loc(待重定位的位置)。
修正后的数据 :
result = val - loc
result = S + A - P
S = sym->st_value
A = rel[i].r_addend
p = (void *)sechdrs[sechdrs[relsec].sh_info].sh_addr + rel[i].r_offset;
(1)其中:
void *loc;
loc = (void *)sechdrs[sechdrs[relsec].sh_info].sh_addr + rel[i].r_offset;
sechdrs[relsec].sh_info表示重定位条目所属的节的索引。
sechdrs[sechdrs[relsec].sh_info].sh_addr表示该节的起始地址。
(void *)表示将起始地址转换为void *类型的指针,以便与偏移量进行相加。
rel[i].r_offset表示重定位条目中记录的偏移量。
loc = (void *)sechdrs[sechdrs[relsec].sh_info].sh_addr + rel[i].r_offset;将起始地址与偏移量相加,得到重定位条目在内存中的绝对地址。
通过将计算得到的绝对地址赋值给loc,后续代码可以使用loc来引用该重定位条目在内存中的位置。
loc 对应于 AArch64 ELF 文档中的 P。
(2)其中:
Elf64_Sym *sym;
sym = (Elf64_Sym *)sechdrs[symindex].sh_addr + ELF64_R_SYM(rel[i].r_info);
是将符号表的起始地址(sechdrs[symindex].sh_addr)与重定位条目中的符号索引(ELF64_R_SYM(rel[i].r_info))相加,并将结果赋值给sym变量。
将符号表的起始地址转化为 (Elf64_Sym *)指针,那么加上一个索引值r_info,就表示获取符号表中第r_info位置的符号项。
这里是指针的特性,比如符号表是一个数组a,每一个数组成员都是Elf64_Sym类型,那么上述sym的值就等于 = a[rel[i].r_info]。获取符号表数组第rel[i].r_info个元素,元素类型是Elf64_Sym。
具体解释如下:
sechdrs[symindex].sh_addr表示指向符号表节的起始地址。
(Elf64_Sym *)表示将符号表的起始地址转换为指向Elf64_Sym类型的指针。
ELF64_R_SYM(rel[i].r_info)从重定位条目的r_info字段中提取出符号索引。
sym = (Elf64_Sym *)sechdrs[symindex].sh_addr + ELF64_R_SYM(rel[i].r_info);将符号索引与符号表的起始地址相加,得到对应符号的地址,并将结果赋值给sym。
通过这行代码,将符号的地址存储在sym变量中,后续代码可以使用sym来引用该符号的属性,例如sym->st_value表示符号的值。
val = sym->st_value + rel[i].r_addend;
这行代码的作用是计算出重定位后的值(val)。它将符号的值(sym->st_value)与重定位条目的附加值(rel[i].r_addend)相加,并将结果赋值给val变量。
具体解释如下:
sym->st_value表示符号的值,即符号在内存中的地址或相对地址。
rel[i].r_addend表示重定位条目的附加值,用于修正符号的值。
val = sym->st_value + rel[i].r_addend将符号的值与重定位条目的附加值相加,得到修正后的值,并将结果赋值给val。
val 对应于 AArch64 ELF 文档中的 (S + A)。
参考资料
Linux 4.19.90
相关文章:

Linux 内核模块加载过程之重定位
文章目录 一、内核模块符号解析1.1 内核模块重定位函数调用1.1.1 struct load_info info1.1.2 copy_module_from_user 1.2 simplify_symbols1.2.1 simplify_symbols1.2.2 resolve_symbol_wait1.2.3 resolve_symbol1.2.4 find_symbol 二、 apply_relocations2.1 apply_relocatio…...
:PyFlink DataStream API之State)
Flink流批一体计算(19):PyFlink DataStream API之State
目录 keyed state Keyed DataStream 使用 Keyed State 实现了一个简单的计数窗口 状态有效期 (TTL) 过期数据的清理 全量快照时进行清理 增量数据清理 在 RocksDB 压缩时清理 Operator State算子状态 Broadcast State广播状态 keyed state Keyed DataStream 使用 k…...

adb shell获取安卓设备电量ROM内存帧率等信息
adb shell获取安卓设备电量ROM内存帧率等信息 adb shell指令获取Android设备的运行状态,如电池信息(包含电量百分比,电池状态,电池温度,电池电压,充放电电流),CPU占比,内…...
springboot服务端接口外网远程调试,并实现HTTP服务监听
文章目录 前言1. 本地环境搭建1.1 环境参数1.2 搭建springboot服务项目 2. 内网穿透2.1 安装配置cpolar内网穿透2.1.1 windows系统2.1.2 linux系统 2.2 创建隧道映射本地端口2.3 测试公网地址 3. 固定公网地址3.1 保留一个二级子域名3.2 配置二级子域名3.2 测试使用固定公网地址…...
代码随想录算法训练营之JAVA|第四十二天|70. 爬楼梯
今天是第 天刷leetcode,立个flag,打卡60天,如果做不到,完成一件评论区点赞最高的挑战。 算法挑战链接 70. 爬楼梯https://leetcode.cn/problems/climbing-stairs/ 第一想法 这是一个动态规划的入门题目,在看完完全背…...

【uniapp】 实现公共弹窗的封装以及调用
图例:红框区域为 “ 内容区域 ” 一、组件 <!-- 弹窗组件 --> <template> <view class"add_popup" v-if"person.isShowPopup"><view class"popup_cont" :style"{width:props.width&&props.width&…...

DevOps系列文章之 Python基础
列表 Python中的列表类似于C语言中的数组的概念,列表由内部的元素组成,元素可以是任何对象 Python中的列表是可变的 简单的理解就是:被初始化的列表,可以通过列表的API接口对列表的元素进行增删改查 1、定义列表 1.可以将列表当成…...

代码随想录第五十天
代码随想录第五十天 Leetcode 123. 买卖股票的最佳时机 IIILeetcode 188. 买卖股票的最佳时机 IV Leetcode 123. 买卖股票的最佳时机 III 题目链接: 买卖股票的最佳时机 III 自己的思路:想不到!!!!高维dp数组!&#x…...
redis缓存雪崩、穿透、击穿解决方案
redis缓存雪崩、穿透、击穿解决方案 背景缓存雪崩缓存击穿缓存穿透总结背景 关于缓存异常,我们常见的有三个问题:缓存雪崩、缓存击穿、缓存穿透。这三个问题一旦发生,会导致大量请求直接落到数据库层面。如果请求的并发量很大,会影响数据库的运行,严重的会导致数据库宕机…...

基于HarmonyOS ArkUI实现七夕壁纸轮播
七夕情人节,为了Ta,你打算用什么方式表达爱?是包包、鲜花、美酒、巧克力,还是一封充满爱意的短信?作为程序员,以代码之名,表达爱。本节将演示如何在基于HarmonyOS ArkUI的SwiperController、Ima…...
FusionAD:用于自动驾驶预测和规划任务的多模态融合
论文背景 自动驾驶(AD)任务通常分为感知、预测和规划。在传统范式中,AD中的每个学习模块分别使用自己的主干,独立地学习任务。 以前,基于端到端学习的方法通常基于透视视图相机和激光雷达信息直接输出控制命令或轨迹…...

C# 序列化json数据,datatabel转对象
datatabel直接转对象 转对象逻辑 1.将datatabel转为json格式 2.将json格式的内容转化为模型data_model的list对象 JsonConvert.DeserializeObject<List<data_model>>(JsonConvert.SerializeObject(dt))...

axios引入的详细讲解
1.安装axios:npm install axios,等待安装完毕即可 2.引用axios:在需要使用的页面中引用 import axios from axios 即可 axios请求的时候有两种方式:一种是get请求,另一种是post请求 get请求: axios({…...
16- flask-bootstrap模板的使用
Flask 中支持 flask-bootstrap模板 和 bootstrap-flask模板 # 不使用: bootstrap-flask # pip install bootstrap-flask1.3.1 # 支持bootstrap 4 # pip install flask-bootstrap # 支持bootstrap3# 中文文档:https://flask-bootstrap-zh.readthedocs.io/zh/latest/ # 样式文档…...

机器学习-神经网络(西瓜书)
神经网络 5.1 神经元模型 在生物神经网络中,神经元之间相互连接,当一个神经元受到的外界刺激足够大时,就会产生兴奋(称为"激活"),并将剩余的"刺激"向相邻的神经元传导。 神经元模型…...
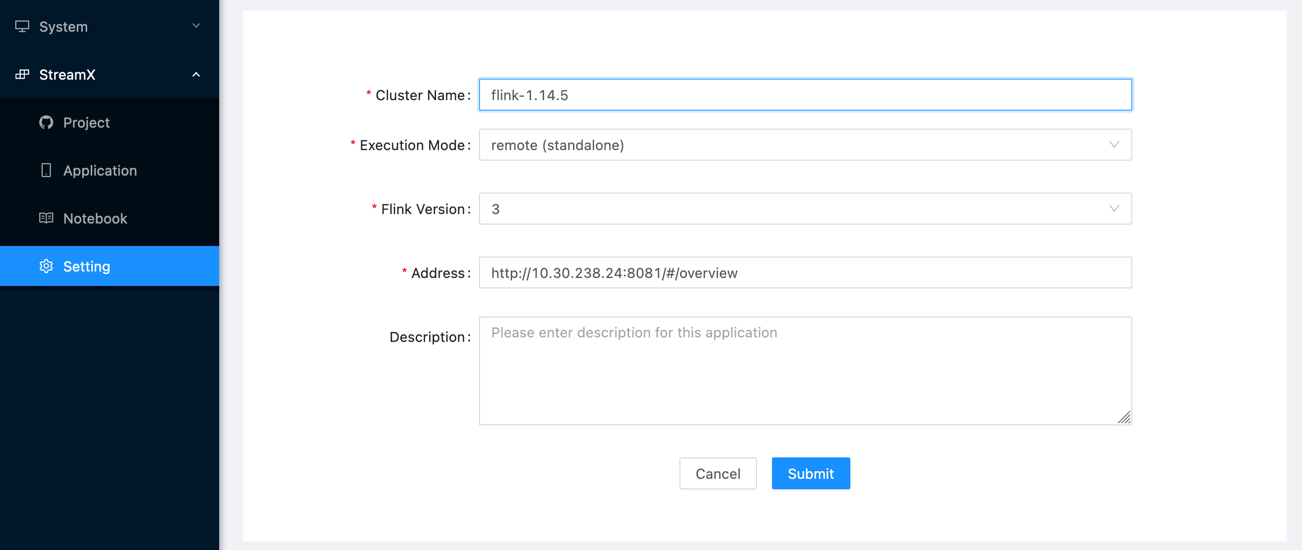
Apache StreamPark系列教程第二篇——项目打包和开发
一、项目打包 项目依赖maven、jdk8.0、前端(node、npm) //下载代码 git clone//maven打包相关内容 mvn -N io.takari:maven:wrapper //前端打包相关内容 curl -sL https://rpm.nodesource.com/setup_16.x | bash - yum -y install nodejs npm -v npm install -g pnpm默认是h2…...
Visual Studio 2022的MFC框架——WinMain函数
我是荔园微风,作为一名在IT界整整25年的老兵,今天我们来重新审视一下Visual Studio 2022下开发工具的MFC框架知识。 大家还记得创建Win32应用程序是怎么弄的吗? Win32应用程序的建立到运行是有一个个关系分明的步骤的: 1.进入W…...
9. 解谜游戏
目录 题目 Description Input Notes 思路 暴力方法 递归法 注意事项 C代码(递归法) 关于DFS 题目 Description 小张是一个密室逃脱爱好者,在密室逃脱的游戏中,你需要解开一系列谜题最终拿到出门的密码。现在小张需要打…...
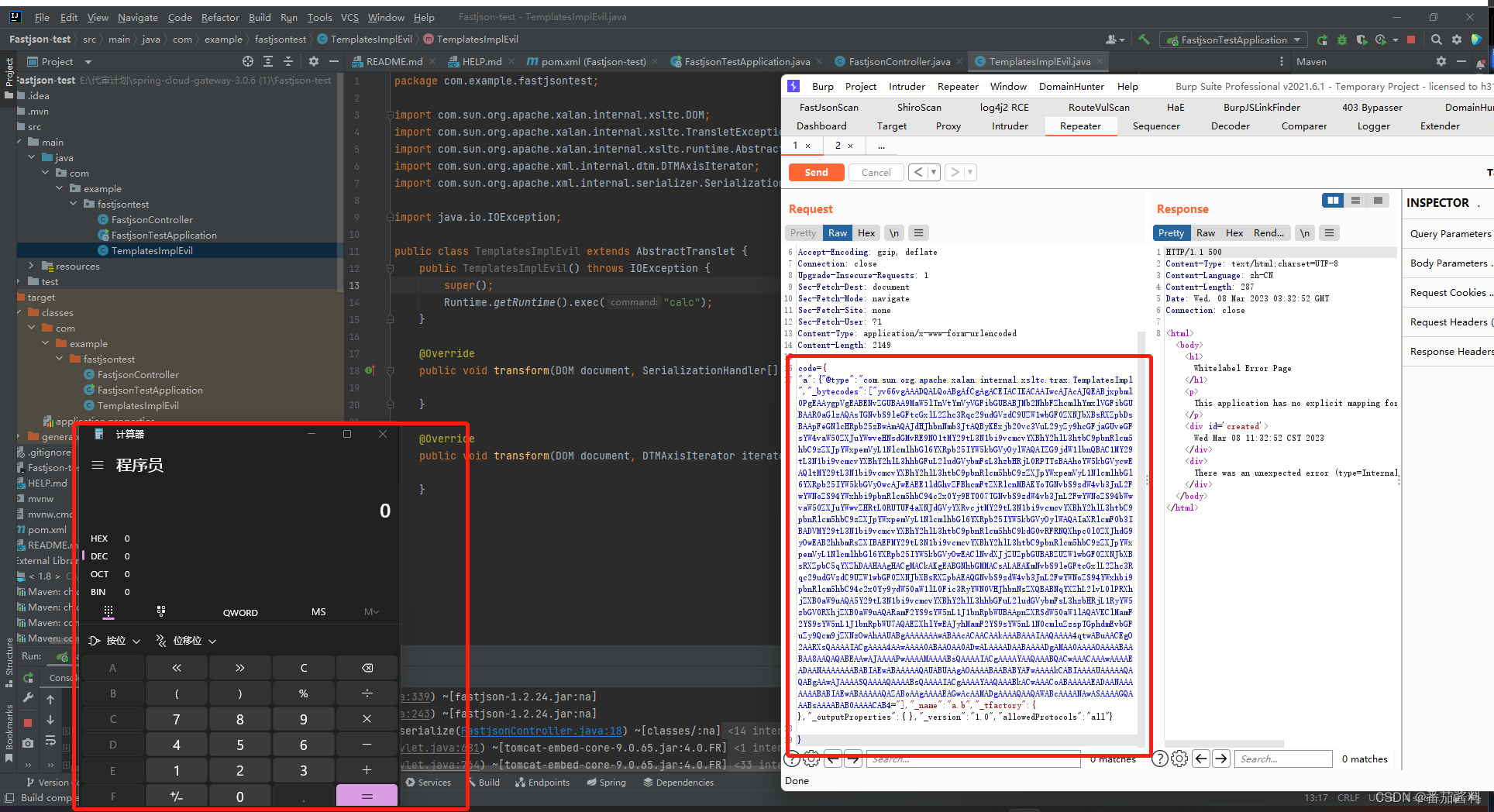
fastjson利用templatesImpl链
fastjson1.2.24 环境: pom.xml: <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLoc…...

OpenCV 开启O3优化
opencv默认没有开启O3优化选项,需要进行手动设置,下面是一种优化方法: 方法一 在 /opencv-4.5.5/cmake/OpenCVCompilerOptions.cmake 中的第 269 行做出以下修改: # 修改前 set(OPENCV_EXTRA_FLAGS_RELEASE "${OPENCV_EXT…...
)
别再依赖SDK了!手把手教你用OpenCV和Eigen从零实现RGB-D相机对齐(附完整C++代码)
从零实现RGB-D相机对齐:OpenCV与Eigen实战指南 在计算机视觉领域,RGB-D相机的深度与彩色图像对齐(D2C)是一个基础但至关重要的技术环节。虽然市面上大多数商用RGB-D相机都提供了现成的SDK和API来实现这一功能,但对于真…...

Flutter GetX实战:从Provider迁移到GetX,我的开发效率提升了多少?
Flutter GetX实战:从Provider迁移到GetX的效率革命 当Flutter开发团队面临状态管理方案的选择时,往往会陷入一种甜蜜的烦恼——官方推荐的Provider虽然稳定可靠,但第三方库GetX却以"全家桶"式的解决方案不断吸引开发者的目光。作为…...
安装与中文环境配置实战)
Halcon深度学习工具(DLT)安装与中文环境配置实战
1. Halcon DLT安装前的准备工作 第一次接触Halcon深度学习工具(DLT)时,我完全被各种专业术语搞晕了。后来才发现,只要做好前期准备,安装过程其实比想象中简单得多。首先需要确认的是你的Windows系统版本,DLT目前支持Windows 10和1…...

生物信息学逆向解析mRNA疫苗序列:从公开数据组装BNT-162b2与mRNA-1273的基因蓝图
1. 项目概述与背景解析 最近在生物信息学和疫苗研究领域,一个名为“NAalytics/Assemblies-of-putative-SARS-CoV2-spike-encoding-mRNA-sequences-for-vaccines-BNT-162b2-and-mRNA-1273”的项目引起了我的注意。这个项目标题看起来很长,但核心非常明确&…...

Docker容器化Emacs:构建可移植、一致的开发环境解决方案
1. 项目概述:为什么要在Docker里运行Emacs?如果你是一个Emacs的重度用户,或者是一个开发者,你很可能遇到过这样的困境:你精心配置的Emacs环境,在换了一台新电脑、升级了操作系统,或者需要在多台…...

5分钟掌握浏览器串口调试:提升嵌入式开发效率300%的终极指南
5分钟掌握浏览器串口调试:提升嵌入式开发效率300%的终极指南 【免费下载链接】SerialAssistant A serial port assistant that can be used directly in the browser. 项目地址: https://gitcode.com/gh_mirrors/se/SerialAssistant 你是否还在为串口调试工具…...
pydantic-settings、核心BaseModel、字段约束Field()、FastAPI)
Python Pydantic介绍(数据校验、自动类型转换、结构化数据建模、序列化JSON、配置管理)pydantic-settings、核心BaseModel、字段约束Field()、FastAPI
文章目录Python 数据校验神器:Pydantic 完全指南一、什么是 Pydantic二、Pydantic 能解决什么问题1)数据校验(Validation)2)自动类型转换(Parsing)3)结构化数据建模4)序列…...

GitHub宝藏项目:生成式AI公司全景导航图与实战应用指南
1. 项目概述:一份AI创业公司的全景导航图最近在GitHub上闲逛,发现了一个宝藏仓库,名字叫“awesome-generative-ai-companies”。这个项目,说白了,就是一个由社区驱动的、持续更新的生成式AI公司名录。它不像那些商业咨…...

Redis分布式锁进阶第二十二篇拆解
一、本篇前置衔接 第九十二篇我们完成Redisson源码拆解、手写复刻、底层内核穿透,彻底明白分布式锁代码层、脚本层、线程层原理。到此为止,代码、源码、坑点、运维、监控、面试全部讲透。但很多开发最大的困惑依旧存在:不同体量公司为什么锁架…...

PaperDebugger:用代码调试思维提升学术论文可复现性的工具实践
1. 项目概述:一个为学术论文“排雷”的智能调试器如果你和我一样,常年混迹在学术圈或者技术研发一线,肯定对下面这个场景深恶痛绝:好不容易读完一篇几十页的论文,满心欢喜地准备复现其中的算法或实验,结果发…...