新KG视点 | Jeff Pan、陈矫彦等——大语言模型与知识图谱的机遇与挑战
OpenKG

大模型专辑
导读 知识图谱和大型语言模型都是用来表示和处理知识的手段。大模型补足了理解语言的能力,知识图谱则丰富了表示知识的方式,两者的深度结合必将为人工智能提供更为全面、可靠、可控的知识处理方法。在这一背景下,OpenKG组织新KG视点系列文章——“大模型专辑”,不定期邀请业内专家对知识图谱与大模型的融合之道展开深入探讨。本期邀请到爱丁堡大学Jeff Pan教授、曼彻斯特大学陈矫彦研究员、浙江大学张文研究员、山西大学闫智超博士等分享的综述论文:“大语言模型与知识图谱的机遇与挑战”。


文章作者 | Jeff Pan(爱丁堡大学终身教授)、陈矫彦(曼彻斯特大学)、张文(浙江大学)、闫智超(山西大学)等
笔记整理 | 邓鸿杰
内容审定 | 陈华钧
论文链接 | https://arxiv.org/abs/2308.06374
01
引言
大语言模型(Large Language Models, LLMs)已经席卷了知识表示(Knowledge Representation, KR)和整个世界,并且在一些自然语言处理任务上达到了和人类相媲美的性能。基于此,人们逐渐接受了这种存在于大语言模型中“参数化”的知识,也宣告了知识计算时代的到来。知识计算时代,KR中的推理任务被扩展为基于知识表示的知识计算任务。
这是知识表示领域迈出的一大步。长期以来,学者们将研究重点放在显式知识上,包括非结构化知识,如文本,和结构化知识,如知识图谱(Knowledge Graphs, KGs)。尤其是在二十一世纪初期RDF和OWL两个标准的出现,使得知识图谱成为一种主流的大规模知识库,同时支持基于逻辑的图推理和基于图的学习。
大语言模型作为知识表示的一个发展拐点,将研究人员的目光从显示知识转向到了显示知识和参数化知识混合的方法上。作为显示知识代表的知识图谱,在参数化的语言模型背景下受到了广泛的研究,包括使用知识图谱增强BERT、RoBERTa,以及最近出现的生成式语言模型GPT等。相反,使用大语言模型反向去构造和完善知识图谱也进行了大量的探索,如使用大语言模型来进行知识图谱的补全。
本文深度地探讨了大语言模型出现后,在知识表示从显示表示迈向混合表示的过程中有争议的一些话题,并介绍了知识图谱和大语言模型结合的最新技术以及未来的机遇与挑战。
02
普遍争议的主题
显式知识和“参数”知识的结合使用在知识计算领域引起了多个讨论,本文将从支持者和怀疑者两个方面对一些共性问题进行讨论。
1.1 知识表示与推理
知识图谱提供了具有明确关系的知识的结构化表示,支持推理和推断。怀疑者认为大语言模型中“参数化”的知识是基于统计的,并不是真正的理解和推理,并且由于缺乏明确的知识表征,模型会生成看似合理但却荒谬的结果。另一方面,知识图谱和大语言模型的获得都需要极高的成本,但后者更加容易适配下游的任务,并将AI带入到了世界舞台的中央,因此参数化知识并不是大语言的唯一目标。综上,在知识表示和知识计算两个任务使用显式知识和“参数化”知识的比较中,知识表示更加偏向表达性和判定性的权衡,而知识计算更加偏向精确率和召回率之间的权衡。
1.2 高精度方法
知识图谱的成功在于其可以精确地提供关于实体的事实信息,如YAGO,可以提供95%以上的正确信息。同样知识图谱在用于生产环境时需要较高的精度,例如Google的Knowledge Vault未能成功落地也是因为其精度达不到要求的99%。目前基于BERT或GPT等的方法不能满足以上要求,这知识计算科学家仍然需要探索基于大语言模型的高精度的方法。
1.3 数值计算
人们普遍认为大语言模型需要具有处理数值的能力,对于语言模型来说,完成数值计算工作是一项具有挑战性的任务,该挑战同样适用于知识图谱补全任务。在基于Wikidata的数字事实来评估语言模型数值计算能力中,没有一个模型能准确地得到结果,尽管已有的模型在数值处理的能力上表现不俗,但考虑到数值具有不同的度量和类型,使得该任务难度进一步升级,因此,修改模型来处理数值的问题仍未被解决,以至于利用大语言模型来完成数值知识图谱的补全看起来是不现实的。
1.4 长尾知识
在知识计算任务中,存在的一个关键问题:大语言模型到底记住了多少的知识?在对大语言模型的调查过程中发现,使用Wikidata中随机的知识对模型进行测试时,模型的性能会急剧的恶化,尤其是在遇到长尾的实体时。这种情况的出现,究其原因就是在预训练过程中实体和关系出现的频率是不一样的,模型对长尾的信息是难以保持精准记忆的。相反,知识图谱在提供长尾实体的知识上具有天然的优势,因此可以进一步提升大语言模型在知识计算任务中的回忆能力。
1.5 偏见、公平等更多问题
批评者认为大语言模型会使训练数据中的偏见持续存在并放大,从而导致有偏见的输出。而支持者认为偏见不是大语言模型中所固有的特征,而是训练数据集中嵌入的社会偏见,他们强调了在训练数据中消除偏见和开发能够缓解偏见技术的重要性。知识图谱在构建过程中同样会嵌入“偏见”,并且会被运用到各种下游任务中。除了偏见和公平外,还有侵犯版权和错误信息等问题。与显式知识相比,大语言模型中“参数化”偏见知识更难以被去除或修改。
1.6 可解释性
在可解释性的场景中,知识图谱通常是首选的。对大语言模型持有怀疑态度的学者们认为:大模型是一个黑盒,缺乏可解释性,很难理解他们是如何产生结果的。但支持者们虽然承认了大模型可解释性差的问题,但却通过最近的一些研究,如注意力机制、模型内省等技术可以在一定程度提升模型的可解释性。思维链技术、问题解耦和答案归因等方法,是最近在大语言模型可解释性方法研究中的一些热点话题。
03
重点研究课题与挑战
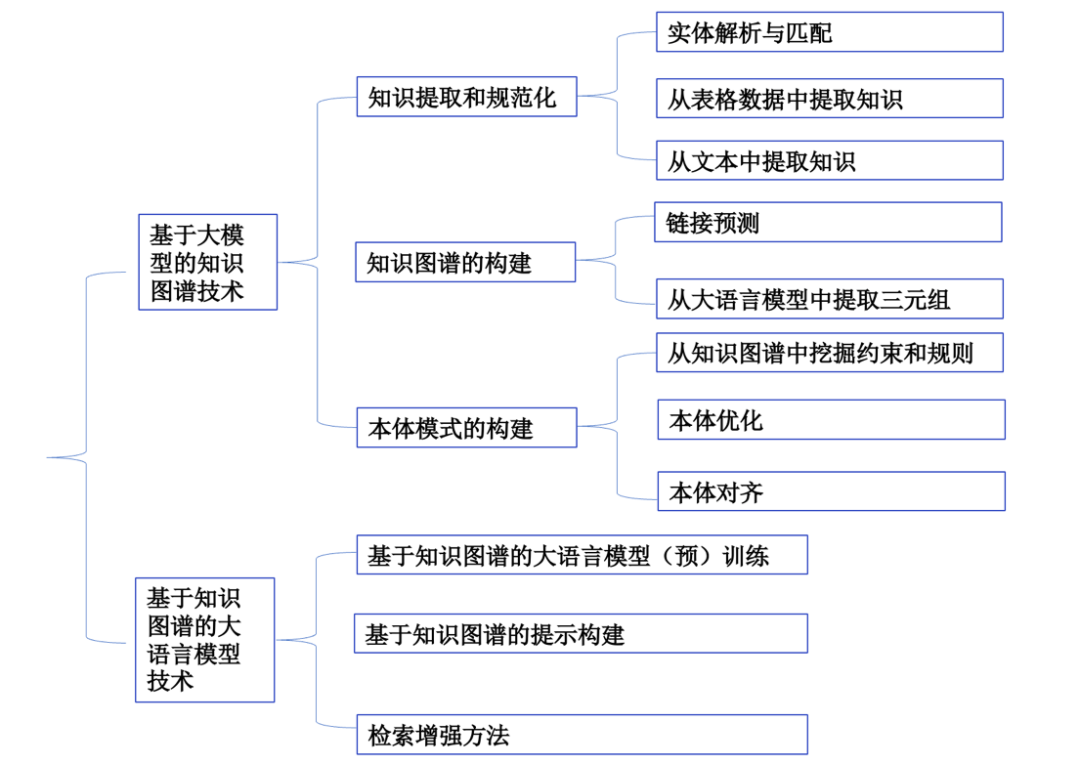
2.1 基于大语言模型的知识图谱技术:知识提取和规范化
实体解析与匹配
KG构建是一项复杂的任务,需要从广泛的来源收集和集成信息,包括结构化、半结构化和非结构化数据。传统的方法通常需要为不同的任务设计不同的模块进行信息的抽取与匹配,而通过大语言模型这一强力的工具,可以更方便地进行信息抽取任务。在实体解析与匹配中,大语言模型通常作为一种数据标注模块,为下游模块产生相关的训练语料。
从表格和文本数据中提取知识
从数据来源的角度来看,图谱中的实体通常来源于表格或者文本中。
其中根据在使用大语言模型提取表格数据中的一些尝试中发现,面临的挑战主要有三个:
1)将表格数据转化为序列;
2)表示和利用非文本的表格数据;
3)提取表格知识。
从文本中提取信息的方法统长包含以下4个任务:
1)命名实体识别;2)关系抽取;
3)事件抽取和;4)语义角色标注。
由于大语言模型强大的能力,使得其在小样本条件下仍有不俗的表现,但仍然存在以下的挑战:
1)从超长文本中有效的提取信息;
2)高覆盖率的信息抽取。
2.2 基于大语言模型的知识图谱技术:知识图谱的构建
链接预测
大语言模型在改善知识图谱构建中具有重要作用,本文首先讨论了链接预测任务,并转向最近的热门任务:从大语言模型中提取三元组。
除了传统的链接预测方法通常使用基于嵌入表示的方法外,还可以使用提示学习的方法,通过大语言模型进一步找到实体之间的链接。基于大语言模型的方法虽然可以很容易的进行链接预测,但仍然存在以下挑战与机遇:
1)大模型不能保证由于实体名称多样化带来的生成错误问题;
2)目前的评估方法对于大模型来说是不适用的,主要原因是计算成本太过高昂;
3)由于大语言模型是基于维基百科训练的,所以并不能知道,该结果是推理的结果还是大语言模型本身的记忆结果;
4)大语言模型在归纳链接预测任务中的作用本身是一个热门话题;
5)对于提示模板的构建是需要不断尝试的,尤其是在GPT-4这种模型背景下,完成该任务是昂贵的;
6)有效的预测策略的获取是一个有前景的研究方向;
7)大语言模型与基于嵌入的方法联合也是一个很强的研究方向。
从大语言模型中提取三元组
传统上,关系知识的检索和推理都依赖于符号知识库,最近,人们研究使用自监督的方法,如构造问答对、完形填空、提示工程等,从大语言模型中直接检索关系知识的能力。这种方法主要的挑战和机遇是:
1)由于实体名称的重复性,需要进行实体消歧;
2)由于大语言模型读长尾实体记忆的不精确性,导致产生错误的信息;
3)大语言模型面临着高精度的要求;
4)大语言模型的输出不提供出处,为核验该信息的准确性带来了信息的挑战。
2.3 基于大语言模型的知识图谱技术:本体模式的构建
从知识图谱中挖掘约束和规则
现有构建知识图谱的方法通常使用pipeline的方式,这种方法容易造成误差传播问题,通过引入自动化的规则和约束来限制构建图谱时错误信息的引入可以提升数据的质量。如何生成这些约束和规则是一个根本性的挑战,在此背景下,大语言模型带来了新的机遇:
1)从输入文本中提取上下文信息的能力;
2)在训练过程中使用上下文提取信息;
3)通过归纳推理生成新的规则。
4)理解词汇信息,协调同义词和一词多义现象;
5)提供规则的解释和生成候选以及反事实样例。
本体优化
本体优化包含很多主题:知识补全、错误知识检测和修复和知识规范化等,开发基于大语言模型的本体细化工具仍然存在以下挑战:
1)利用文本及其本体的图结构和逻辑;
2)结合符合推理和大语言模型推理。
本体对齐
单个本体的知识通常是不完整的,许多真实世界的应用通常依赖于跨领域的知识。本体对齐的主要挑战是评估基于大语言模型的本体对齐系统。
2.4 基于知识图谱的大语言模型
在大语言模型中使用知识图谱主要有以下几个方面:
1)知识图谱可以作为大语言模型的训练数据;
2)知识图谱中的三元组可以用于提示模板的构建;
3)知识图谱作为一种外部知识增强大语言模型。
基于知识图谱的语言模型(预)训练
由于自然语言文本本身可能只提供有限的信息覆盖,而知识图谱可以为语言模型提供结构化的事实知识,集成知识图谱的语言模型(预)训练方法,使得向模型注入世界知识和实时更新知识更加方便。这种融合了知识图谱信息的语言模型,在知识密集型QA任务上展示了具有竞争力的结果,证明了这种方法在提升语言模型的能力具有重要意义。
基于知识图谱的提示构建
目前使用知识图谱来丰富和微调提示模板,从而在提示的数量、质量和多样性上比手动的方法更具优势,已有方法证明了通过图谱构建的提示模板进行推理比传统方法更具竞争力,但目前该方法仍存在挑战与机遇:
1)生成上下文感知的写作提示,分析不同提示之间的关系,形成具有关联关系的提示模板。
2)动态生成和用户交互的提示模板,由于知识图谱提供了知识的透明表示,因此可以很容易地将从知识图谱生成的提示追溯到它们的底层源。
3)将知识图谱集成到提示模板中,增强模型生成内容的可行度。
4)知识图谱可以创建询问问题的提示,从而触发知识图谱复杂推理能力和中间推理步骤。
检索增强的方法
基于检索增强的方法对于大模型获取外部知识是重要的,尤其是针对长尾实体和特定领域训练中缺失的实体。目前的方法(如RAG,FiD)主要是考虑文本知识,最近也开始有方法使用图谱知识去增强大模型。在可见的未来,如果大规模知识图谱构造有比较可行的方法,图谱增强可能成为主流方案之一。检索增强是一个非常有前景的方向,主要挑战有:
1)统一知识编辑与检索增强的方法;
2)半参数化大语言模型;
3)支撑复杂推理。
04
展望
综上所述,我们总结了以下显式知识和“参数化”知识的融合的机会:
1. 简便快捷的文本知识获取:长久以来文字都是人类记录知识的主要方式,大语言模型使文本知识的获取及时可得,可以避免复杂的文本知识收集、表示、存储、和查询流程,将AI开发者从信息检索的依赖中解放出来。
2. 丰富的子任务知识:大语言模型可以简化传统知识工程流程,通过少量样本作为实例语言模型即可学会结构解析、实体识别、关系抽取等任务,因此可以快速构建大规模高质量的知识图谱。
3. 实现更好的语言理解:尽管大语言模型已经具有很好的语言理解能力,将显式知识与大语言模型中的“参数化”知识融合,有可能让模型具有更强的语言理解能力,实现更好的文本蕴含推理、文本梗概、以及一致文本生成等。
大语言模型的出现是知识图谱研究的一个重要转折点,尽管在如何结合他们的优势来进一步解决问题上仍然有待深入研究,但已经出现了令人兴奋的机会。对此,我们提出了以下建议:
1)不要因为研究范式的转变而丢弃知识图谱;
2)将你的研究方法与基于大模型的方法持续进行比较;
3)保持好奇,保持批判;
4)过去的已经过去了,让我们开始新的旅程。
以上就是本次分享的内容,谢谢。


作者简介
INTRODUCTION

Jeff Pan

爱丁堡大学终身教授

Jeff Pan教授,长江学者,爱丁堡大学终身教授,华为爱丁堡知识图谱实验室主任,华为英国首席搜索科学家,阿兰图灵研究院知识图谱主席。主页:http://knowledge-representation.org/j.z.pan/

作者简介
INTRODUCTION

陈矫彦

曼彻斯特大学终身制讲师

陈矫彦博士,曼彻斯特大学计算机科学系终身制讲师,牛津大学计算机科学系兼职研究员。陈博士主要研究知识图谱、本体论、机器学习和神经符号人工智能,担任Transactions of Graph Data and Knowledge (TGDK)的副主编。个人主页:https://chenjiaoyan.github.io/

作者简介
INTRODUCTION

张文

浙江大学特聘研究员

张文,浙江大学软件学院特聘研究员,研究方向为知识图谱、知识表示、知识推理。个人主页:https://person.zju.edu.cn/zhangwen

作者简介
INTRODUCTION

闫智超

山西大学博士

闫智超:山西大学博士在读,主要研究方向为框架语义解析。主页:
https://scholar.google.com.hk/citations?user=Tb2o2nUAAAAJ&hl=zh-CN
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。
相关文章:
新KG视点 | Jeff Pan、陈矫彦等——大语言模型与知识图谱的机遇与挑战
OpenKG 大模型专辑 导读 知识图谱和大型语言模型都是用来表示和处理知识的手段。大模型补足了理解语言的能力,知识图谱则丰富了表示知识的方式,两者的深度结合必将为人工智能提供更为全面、可靠、可控的知识处理方法。在这一背景下,OpenKG组织…...

详解过滤器Filter和拦截器Interceptor的区别和联系
目录 前言 区别 联系 前言 过滤器(Filter)和拦截器(Interceptor)都是用于在Web应用程序中处理请求和响应的组件,但它们在实现方式和功能上有一些区别。 区别 1. 实现方式: - 过滤器是基于Servlet规范的组件,通过实现javax.servlet.Filt…...

List常用的操作
1、看List里是否存在某个元素 contains //省略建立listboolean contains stringList.contains("上海");System.out.println(contains); 如果存在是true,不存在是false 2、看某个元素在List中的索引号 .indexOf List<String>stringList new Ar…...

Android studio APK切换多个摄像头(Camera2)
1.先设置camera的权限 <uses-permission android:name"android.permission.CAMERA" /> 2.布局 <?xml version"1.0" encoding"utf-8"?> <LinearLayout xmlns:android"http://schemas.android.com/apk/res/android"and…...

ChatGPT 对教育的影响,AI 如何颠覆传统教育
胜量老师 来源:BV1Nv4y1H7kC 由Chat GPT引发的对教育的思考,人类文明发展至今一直靠教育完成文明的传承,一个年轻人要经历若干年的学习,才能进入社会投入对文明的建设,而学习中有大量内容是需要记忆和反复训练的。 无…...
Spring(九)声明式事务
Spring整合Junit4和JdbcTemplater如下所示: 我们所使用的junit的jar包不同,可以整合不同版本的junit。 我们导入的依赖如下所示: <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.a…...
)
java中用HSSFWorkbook生成xls格式的excel(亲测)
SXSSFWorkbook类是用于生成XLSX格式的Excel文件(基于XML格式),而不是XLS格式的Excel文件(基于二进制格式)。 如果你需要生成XLS格式的Excel文件,可以使用HSSFWorkbook类。以下是一个简单的示例:…...

做平面设计一般电脑可以吗 优漫动游
平面设计常用的软件如下:Photoshop、AutoCAD、AI等。其中对电脑配置要求高的是AutoCAD,可运行AutoCAD的软件均可运行如上软件。 做平面设计一般电脑可以吗 AutoCAD64位版配置要求:AMDAthlon64位处理器、支持SSE2技术的AMDOpteron处理器、…...
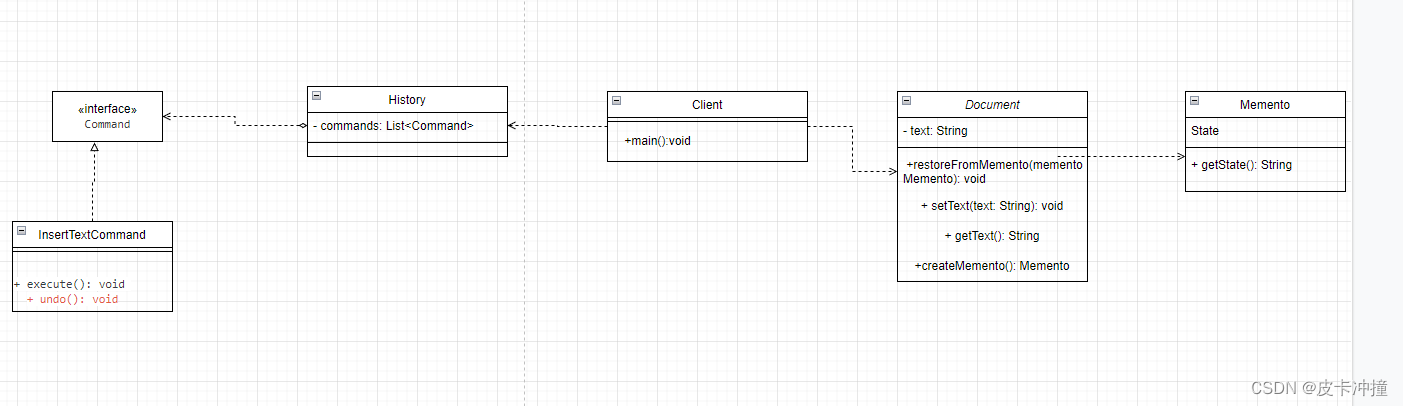
设计模式备忘录+命令模式实现Word撤销恢复操作
文章目录 前言思路代码实现uml类图总结 前言 最近学习设计模式行为型的模式,学到了备忘录模式提到这个模式可以记录一个对象的状态属性值,用于下次复用,于是便想到了我们在Windows系统上使用的撤销操作,于是便想着使用这个模式进…...

Linux centos7 bash编程小训练
训练要求: 求比一个数小的最大回文数 知识点: 一个数字正读反读都一样,我们称为回文数,如5、11、55、121、222等。 我们训练用bash编写一个小程序,由我们标准输入一个整数,计算机将显示出一个比这个数小…...

创作2周年纪念日-特别篇
创作2周年纪念日-特别篇 1. 与CSDN的机缘2. 收获3. 憧憬 1. 与CSDN的机缘 很荣幸,在大学时候,能够接触到CSDN这样一个平台,当时对嵌入式开发、编程、计算机视觉等内容比较感兴趣。后面一个很偶然的联培实习机会,让我接触到了Pych…...

【UE5】用法简介-使用MAWI高精度树林资产的地形材质与添加风雪效果
首先我们新建一个basic工程 然后点击floor按del键,把floor给删除。 只留下空白场景 点击“地形” 在这个范例里,我只创建一个500X500大小的地形,只为了告诉大家用法,点击创建 创建好之后有一大片空白的地形出现 让我们点左上角…...

兼容AD210 车规级高精度隔离放大器:ISO EM210
车规级高精度隔离放大器:ISO EM210 Pin-Pin兼容AD210的低成本,小体积DIP标准38Pin金属外壳封装模块,能有效屏蔽现场EMC空间干扰。功能设计全面,采用非固定增益方式,输入信号经过输入端的前置放大器(增益为1-100&#x…...
R语言常用数组函数
目录 1.array 2.matrix 3.data.matrix 4.lower.tri 5.mat.or.vec 6.t:转置矩阵 7.cbind 8.rbind 9.diag 10.aperm:对数组进行轴置换(维度重排)操作 11.%*%:乘法操作要求矩阵 A 的列数等于矩阵 B 的行数 12.crossprod…...
前端开发之Element Plus的分页组件el-pagination显示英文转变为中文
前言 在使用element的时候分页提示语句是中文的到了element-plus中式英文的,本文讲解的就是怎样将英文转变为中文 效果图 解决方案 如果你的element-plus版本为2.2.29以下的 import { createApp } from vue import App from ./App.vue import ElementPlus from …...
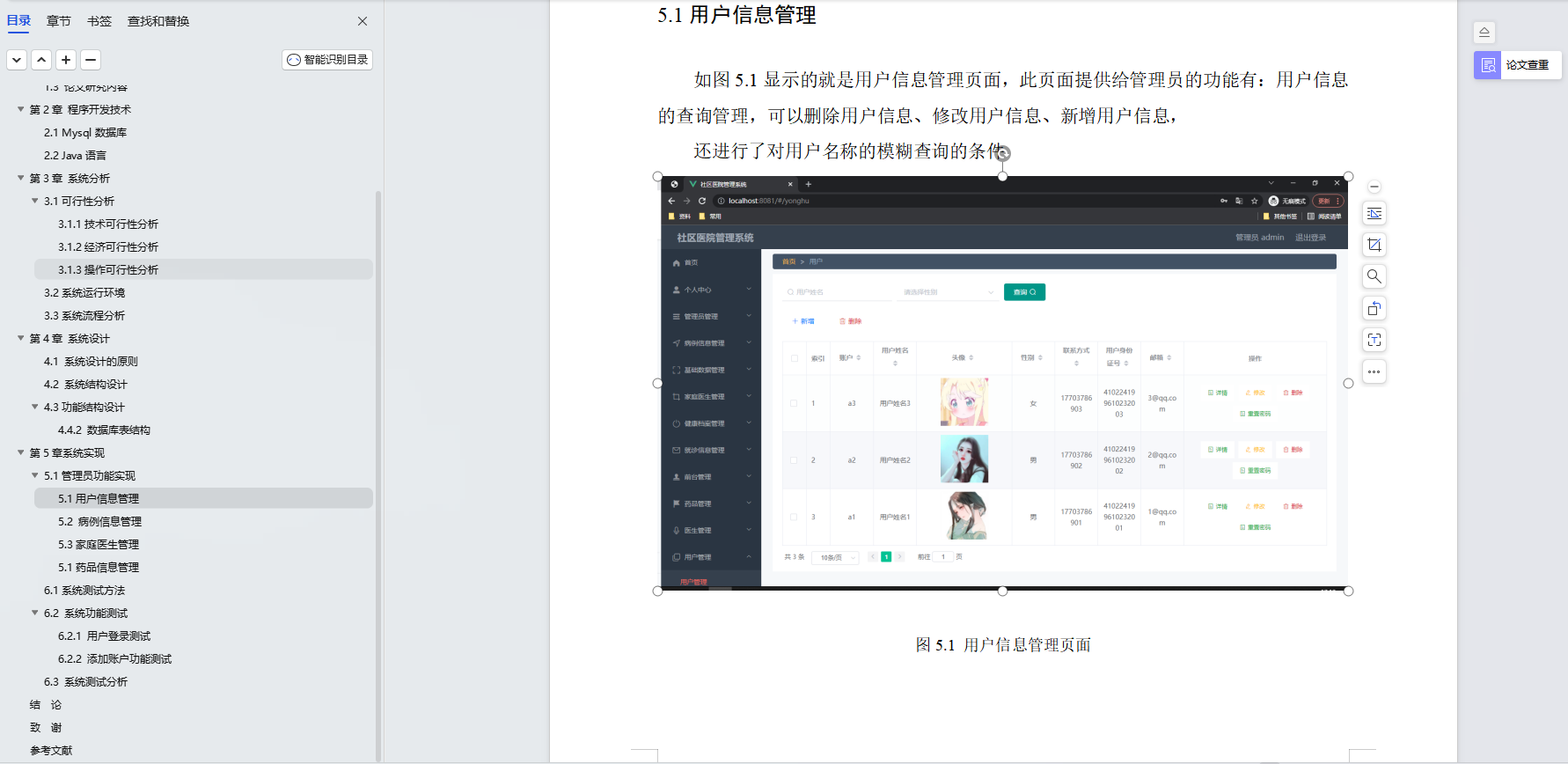
基于Java+SpringBoot+Vue前后端分离社区医院管理系统设计和实现
博主介绍:✌全网粉丝30W,csdn特邀作者、博客专家、CSDN新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专…...

浅谈单例模式在游戏开发中的应用
前言 如果在外部想在不同的时间结点、不同的位置访问某类中的成员且想要保持访问时,成员地址唯一。那么可以考虑将该类声明为静态类,但若是成员中包含公共的数据类型,此时便可以考虑将该类做成一个单例。 单例模式 由于类中的数据&#x…...

Stable Diffusion WebUI 整合包
现在网络上出现的各种整合包只是整合了运行 Stable Diffusion WebUI(以下简称为 SD-WebUI)必需的 Python 和 Git 环境,并且预置好模型,有些整合包还添加了一些常用的插件,其实际与手动进行本地部署并没有区别。 不过&a…...

什么是 RESTful API
什么是 RESTful API? RESTful API是一种设计哲学和架构风格,它基于 HTTP 协议和其状态管理原则,用于构建分布式系统。RESTful API 遵循以下设计原则: 资源层:API 应该代表一种资源,例如一个用户、一个订单…...

如何搭建关键字驱动自动化测试框架?
前言 那么这篇文章我们将了解关键字驱动测试又是如何驱动自动化测试完成整个测试过程的。关键字驱动框架是一种功能自动化测试框架,它也被称为表格驱动测试或者基于动作字的测试。关键字驱动的框架的基本工作是将测试用例分成四个不同的部分。首先是测试步骤&#x…...

终极指南:10分钟掌握SPT-AKI存档编辑器完整使用教程
终极指南:10分钟掌握SPT-AKI存档编辑器完整使用教程 【免费下载链接】SPT-AKI-Profile-Editor Программа для редактирования профиля игрока на сервере SPT-AKI 项目地址: https://gitcode.com/gh_mirrors/sp/…...

FanControl终极指南:免费开源的风扇控制神器,轻松解决Windows散热与噪音问题
FanControl终极指南:免费开源的风扇控制神器,轻松解决Windows散热与噪音问题 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https:…...

5分钟掌握小红书无水印下载:让内容保存效率提升300%
5分钟掌握小红书无水印下载:让内容保存效率提升300% 【免费下载链接】XHS-Downloader 小红书(XiaoHongShu、RedNote)链接提取/作品采集工具:提取账号发布、收藏、点赞、专辑作品链接;提取搜索结果作品、用户链接&#…...

qmcdump:专业解决QQ音乐加密音频格式兼容性问题
qmcdump:专业解决QQ音乐加密音频格式兼容性问题 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.com/gh_mirrors/qm/qmcdump 在数字音乐时…...

GURU-Ai:面向开发者的AI命令行工具集,提升代码理解与运维效率
1. 项目概述:一个面向开发者的AI助手工具集最近在GitHub上看到一个挺有意思的项目,叫“Guru322/GURU-Ai”。光看名字,你可能会觉得这又是一个大而全的AI模型或者聊天机器人,但点进去仔细研究后,我发现它的定位其实非常…...

Emacs AI编程助手:ai-code-interface.el深度集成指南
1. 项目概述:一个为Emacs注入AI灵魂的代码接口如果你是一位Emacs的深度用户,同时又对AI辅助编程抱有极大的热情,那么你很可能已经厌倦了在浏览器、终端和编辑器之间反复横跳的割裂体验。tninja/ai-code-interface.el这个项目,正是…...

数据分析师能力展示:从项目构建到报告呈现的完整指南
1. 项目概述:一个数据分析师的能力展示平台最近在GitHub上看到一个挺有意思的项目,叫“dataanalyst-showcase”。光看名字,你可能会觉得这又是一个数据科学项目合集,但点进去仔细研究后,我发现它的定位非常精准——它不…...

Deep Lake:AI数据湖实战指南,解决深度学习数据管理难题
1. 项目概述:当数据湖遇上深度学习如果你在深度学习项目里被数据管理搞得焦头烂额过,那你肯定懂我在说什么。模型训练到一半,发现数据版本不对,或者想对海量图像、视频做快速查询和采样,结果被IO速度卡得死死的。传统的…...

Legacy-iOS-Kit完整指南:如何让老旧iPhone和iPad重获新生
Legacy-iOS-Kit完整指南:如何让老旧iPhone和iPad重获新生 【免费下载链接】Legacy-iOS-Kit An all-in-one tool to restore/downgrade, save SHSH blobs, jailbreak legacy iOS devices, and more 项目地址: https://gitcode.com/gh_mirrors/le/Legacy-iOS-Kit …...

82.人工智能实战:大模型多环境治理怎么做?从开发、测试、预发到生产的 Prompt、模型、知识库隔离方案
人工智能实战:大模型多环境治理怎么做?从开发、测试、预发到生产的 Prompt、模型、知识库隔离方案 一、问题场景:测试环境改了 Prompt,结果生产回答变了 很多大模型项目早期只有一个环境: 一套 Prompt 一个知识库 一个模型地址 一个配置表开发、测试、运营都在同一套配置…...