7个用于机器学习和数据科学的基本 Python 库
推荐:使用 NSDT场景编辑器 助你快速搭建3D应用场景
这篇文章针对的是刚开始使用Python进行AI的人,以及那些有经验的人,但对下一步要学习什么有疑问的人。我们将不时花点时间向初学者介绍基本术语和概念。如果您已经熟悉它们,我们鼓励您跳过更基本的材料并继续阅读,以了解对图形执行和急切执行等更精细的观点的看法。这篇文章将解释人工智能最重要的 Python 库和包,解释如何使用它们,并介绍它们的优点和缺点。
用于AI和ML的最广泛使用的Python库
将正确的库组合添加到开发环境中至关重要。以下包和库对于大多数 AI 开发人员至关重要。所有这些都可以作为开源发行版免费提供。

Scikit-learn:如果你需要做机器学习
它是什么:Scikit-learn是一个用于实现机器学习算法的Python库。
背景:一位名叫David Cournapeau的开发人员最初在2007年以学生身份发布了scikit-learn。开源社区迅速采用了它,多年来已经多次更新它。
特征: Scikit-learn中的软件包专注于建模数据。
- Scikit-learn包括所有核心机器学习算法,其中包括向量机,随机森林,梯度提升,k均值聚类和DBSCAN。
- 它旨在与 NumPy 和 SciPy(如下所述)无缝协作,以进行数据清理、准备和计算。
- 它具有用于加载数据以及将其拆分为训练集和测试集的模块。
- 它支持文本和图像数据的特征提取。
最适合:Scikit-learn是任何从事机器学习工作的人的必备品。如果您需要实现分类、回归、聚类、模型选择等算法,它被认为是可用的最佳库之一。
缺点:Scikit-learn是在深度学习起飞之前建立的。虽然它非常适合核心机器学习和数据科学工作,但如果你正在构建神经网络,你将需要TensorFlow或Pytorch(下图)。
最佳学习场所:Python 中的机器学习与数据学校的 Scikit-Learn 一起。(注意:Scikit-learn是最容易学习的Python库之一。一旦你精通Python本身,Scikit-learn就很容易了。

NumPy:如果您需要处理数字
它是什么:NumPy是一个Python包,用于处理数组或大型同质数据集合。您可以将数组视为电子表格,其中数字存储在列和行中。
背景:Python在1991年推出时最初并不是为了数值计算。尽管如此,它的易用性还是很早就引起了科学界的注意。多年来,开源社区开发了一系列用于数值计算的软件包。2005年,开发人员Travis Oliphant将十多年的开源开发合并到一个用于数值计算的库中,他称之为NumPy。
特征:NumPy的核心功能是对数组的支持,它允许您快速处理和操作大型数据集合。
- NumPy 中的数组可以是 n 维的。这意味着数据可以是单列数字,也可以是多列和多行数字。
- NumPy有用于执行一些线性代数函数的模块。
- 它还具有用于绘制和绘制数字数组的模块。
- NumPy 数组中的数据是同质的,这意味着它必须全部定义为相同的类型(数字、字符串、布尔值等)。这意味着数据得到有效处理。
最适合:操作和处理数据以进行更高级的数据科学或机器学习操作。如果你正在处理数字,你需要NumPy。
缺点:由于 NumPy 数组是同类的,因此它们不适合混合数据。你最好使用Python列表。此外,当处理超过 500,000 列时,NumPy 的性能往往会下降。
最佳学习场所:Linear Regression with NumPy and Python from Coursera。

Pandas:如果您需要操作数据
它是什么:Pandas是一个同时处理不同类型的标记数据的软件包。例如,如果您需要分析包含数字、字母和字符串数据的 CSV 文件,则可以使用它。
背景:韦斯·麦金尼(Wes McKinney)于2008年发行了《熊猫》。它建立在 NumPy 之上(事实上,您必须安装 NumPy 才能使用 Pandas),并扩展该包以处理异构数据。
特征:Pandas的核心功能是其多样化的数据结构,允许用户执行各种分析操作。
- Pandas 有各种用于数据操作的模块,包括重塑、连接、合并和透视。
- 熊猫具有数据可视化功能。
- 用户可以执行数学运算,包括微积分和统计,而无需调用外部库。
- 它具有可帮助您解决丢失数据的模块。
最适合:数据分析。
缺点:在vanilla Python和Pandas之间切换可能会令人困惑,因为后者的语法稍微复杂一些。熊猫的学习曲线也很陡峭。这些因素,再加上糟糕的文档,可能使其难以上手。
最好的学习场所:我从 DeepLearning.AI 开始介绍pandas。

SciPy:如果你需要为数据科学做数学
它是什么:SciPy是一个用于科学计算的Python库。它包含用于执行计算的包和模块,可帮助科学家进行或分析实验。
背景:在 1990 年代末和 2000 年代初,Python 开源社区开始开发一系列工具以满足科学界的需求。2001年,他们以SciPy的形式发布了这些工具。社区保持活跃,并始终更新和添加新功能。
特征:SciPy 的软件包包括一个完整的数学技术工具包,包括微积分、线性代数、统计学、概率等。
- 它对数据科学家来说最受欢迎的一些软件包是用于插值、K 均值检验、数值积分、傅里叶变换、正交距离回归和优化。
- SciPy 还包括用于图像处理和信号处理的软件包。
- Weave功能允许用户在Python中用C / C++编写代码。
最适合:SciPy是数据科学家最好的朋友。
缺点:一些用户发现 SciPy 的文档缺乏,并批评它的几个软件包不如 MatLab 中的类似软件包。
最佳学习场所:Ahmad Bazzi 的 SciPy 编程。
如果你需要做机器学习:TensorFlow vs. PyTorch
TensorFlow和PyTorch执行与深度学习相关的相同基本任务:它们使获取数据,训练模型和生成预测变得容易。从人脸识别到大型语言模型,许多神经网络都是使用TensorFlow或PyTorch进行编码的。这些库曾经在前端和后端都明显不同。随着时间的推移,他们围绕同一套最佳实践趋同。
尽管如此,人工智能社区内部仍在争论哪个是最好的。2015年发布的TensorFlow是第一个出现在现场。它在商业人工智能和产品开发中占主导地位,但许多用户抱怨它的复杂性。
PyTorch于2016年发布,被广泛认为它更容易学习,实施起来更快。它是学术界的最爱,并在工业界稳步普及。但是,众所周知,它在缩放方面很困难。
选择哪个?
TensorFlow仍然是业界占主导地位的深度学习库。这部分是由于惯性,部分原因是TensorFlow在处理大型项目和复杂工作流程方面比PyTorch更好。它能够处理针对商业部署进行扩展的 AI 产品,使其成为产品开发的最爱。
如果你只是跳入深度学习,并希望专注于快速构建和原型设计模型,PyTorch可能是更好的选择。请注意,根据你的工作要求和公司技术,你可能有一天必须学习TensorFlow(特别是如果你梦想的工作是在TensorFlow的故乡谷歌)。
在下面详细了解这两个库的优缺点。

TensorFlow
这是什么? TensorFlow 是一个端到端的开源库,用于开发、训练和部署深度学习模型。
背景: TensorFlow最初由Google Brain于2015年发布。最初,它的前端不是用户友好的,并且它具有冗余的API,这使得构建和实现模型变得繁琐。随着时间的推移,其中许多问题已经通过更新以及通过将 Keras(见下文)集成为默认前端而得到解决。
特征: TensorFlow有许多用于构建深度学习模型并将其扩展以进行商业部署的软件包。
- TensorFlow用户可以调用Dev Hub和Model Garden中的数百个预先训练的模型。开发人员中心包含即插即用模型,而模型花园适用于习惯于进行自定义的更高级用户。
- 它在使用内存方面非常有效,可以并行训练多个神经网络。
- TensorFlow 应用程序可以在各种硬件系统上运行,包括 CPU、GPU、TPU 等。
- TensorFlow Lite针对移动和嵌入式机器学习模型进行了优化。
- 用户可以在 Tensorboard.dev 上自由上传和分享他们的机器学习实验。
最适合:大规模构建生产就绪的深度学习模型。
缺点:一些用户仍然抱怨前端相当复杂。您可能还会遇到TensorFlow执行缓慢的批评。这主要是TensorFlow 1.0的遗留问题,当时它默认以图形模式执行操作。TensorFlow 2.0默认为预先执行模式。
最佳学习场所:来自 DeepLearning.ai 的TensorFlow开发人员专业证书。

Keras:
它是什么:Keras是一个适合初学者的工具包,用于处理神经网络。它是TensorFlow的前端接口。
背景:谷歌工程师Francois Choillet于2015年发布了Keras,作为许多深度学习库的API。截至 2020 年,Keras 是 TensorFlow 独有的。
特征: Keras 处理在 TensorFlow 中构建神经网络的高级任务,因此包含激活函数、层、优化器等基本模块。
- Keras 支持原版神经网络、卷积神经网络和递归神经网络以及实用程序层,包括批量归一化、辍学和池化。
- 它旨在简化深度神经网络的编码。
最适合:开发深度学习网络。
缺点:它仅适用于TensorFlow用户。如果你使用TensorFlow,你就是在使用Keras。
最佳学习场所: IBM 的 Keras 深度学习和神经网络简介。

PyTorch
它是什么:PyTorch是Facebook AI研究实验室对TensorFlow的回答。它是一个开源的通用库,用于机器学习和数据科学,特别是深度学习。
背景: Facebook在2016年发布了PyTorch,比TensorFlow晚了一年,它迅速受到对快速原型感兴趣的学者和其他研究人员的欢迎。这是由于其简化的前端以及其默认模式立即执行操作的事实(而不是像TensorFlow那样将它们添加到图形中以供以后处理)。
特征:PyTorch有许多类似于TensorFlow的特性。事实上,自推出以来的几年里,每个库都进行了更新,以包含用户最喜欢的功能。
- PyTorch有自己的预训练模型库。PyTorch Hub 面向想要尝试模型设计的学术用户,生态系统工具包含预先训练的模型。
- PyTorch 具有内存效率,可以并行训练多个模型。
- 它支持多种硬件类型。
最适合:深度学习模型的快速原型设计。Pytorch 代码运行快速高效。
缺点:一些用户报告说,PyTorch 在处理大型项目、大型数据集和复杂的工作流程时遇到了困难。构建要大规模部署的AI产品的开发人员可能更喜欢TensorFlow。
最佳学习地点:来自 PyTorch.org 的 PyTorch 教程。
结论
Python库的成熟是它在AI社区中如此受欢迎的主要原因之一。它们可以轻松地将Python扩展到远远超出其原始设计的任务。一旦你牢牢掌握了 Python 语言和与你的工作相关的库,你将能够为广泛的应用程序构建、训练和迭代机器学习模型。
原文链接:7个用于机器学习和数据科学的基本 Python 库 (mvrlink.com)
相关文章:
7个用于机器学习和数据科学的基本 Python 库
推荐:使用 NSDT场景编辑器 助你快速搭建3D应用场景 这篇文章针对的是刚开始使用Python进行AI的人,以及那些有经验的人,但对下一步要学习什么有疑问的人。我们将不时花点时间向初学者介绍基本术语和概念。如果您已经熟悉它们,我们鼓…...
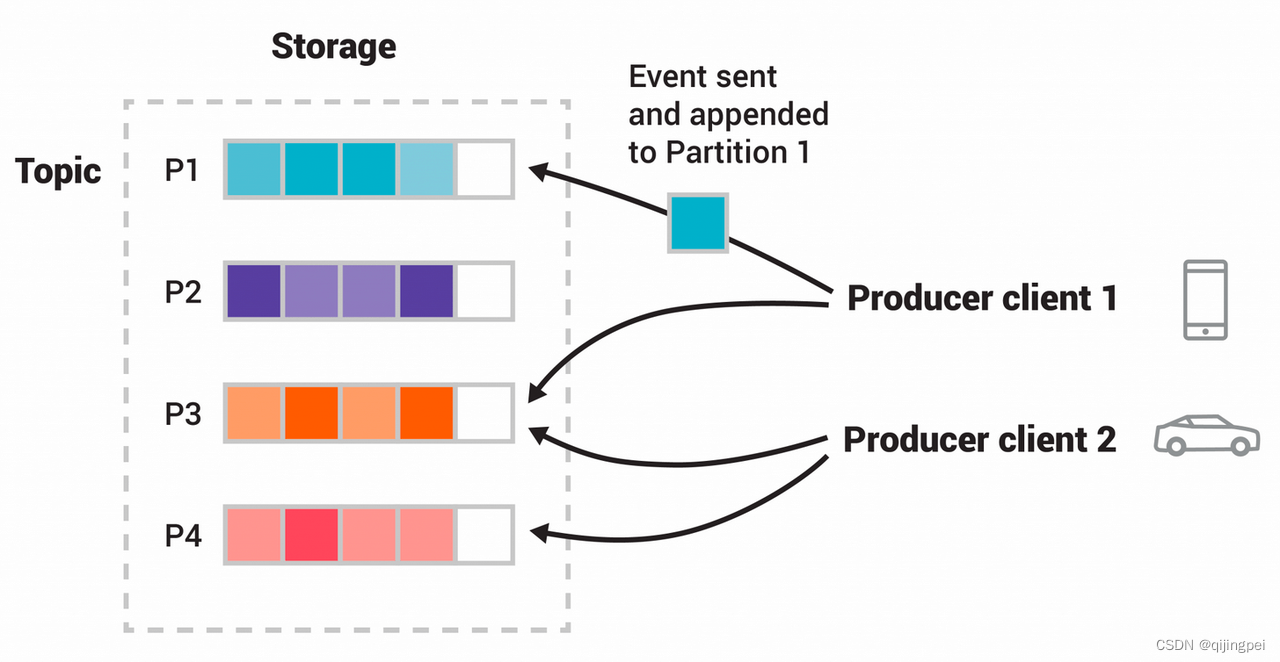
Kafka 简介 + 学习笔记
消息队列 先说明消息队列是什么: 亚马逊: 消息队列是一种异步的服务间通信方式,适用于微服务架构。消息在被处理和删除之前一直存储在队列上。每条消息仅可被一位用户处理一次。消息队列可被用于分离重量级处理、缓冲或批处理工作以及缓解高…...

Mybatis小记
目录 Mybatis第一个程序 xml文件 测试类 错误排查 Mybatis第一个程序 1.搭建实验数据库 2.导入MyBatis相关jar包 3.编写MyBatis核心配置文件 4.编写MyBatis工具类 5.创建实体类、 6.编写Mapper接口类 7.编写Mapper.xml配置文件 8.编写测试类 对象传参只引用需要的属性就可…...
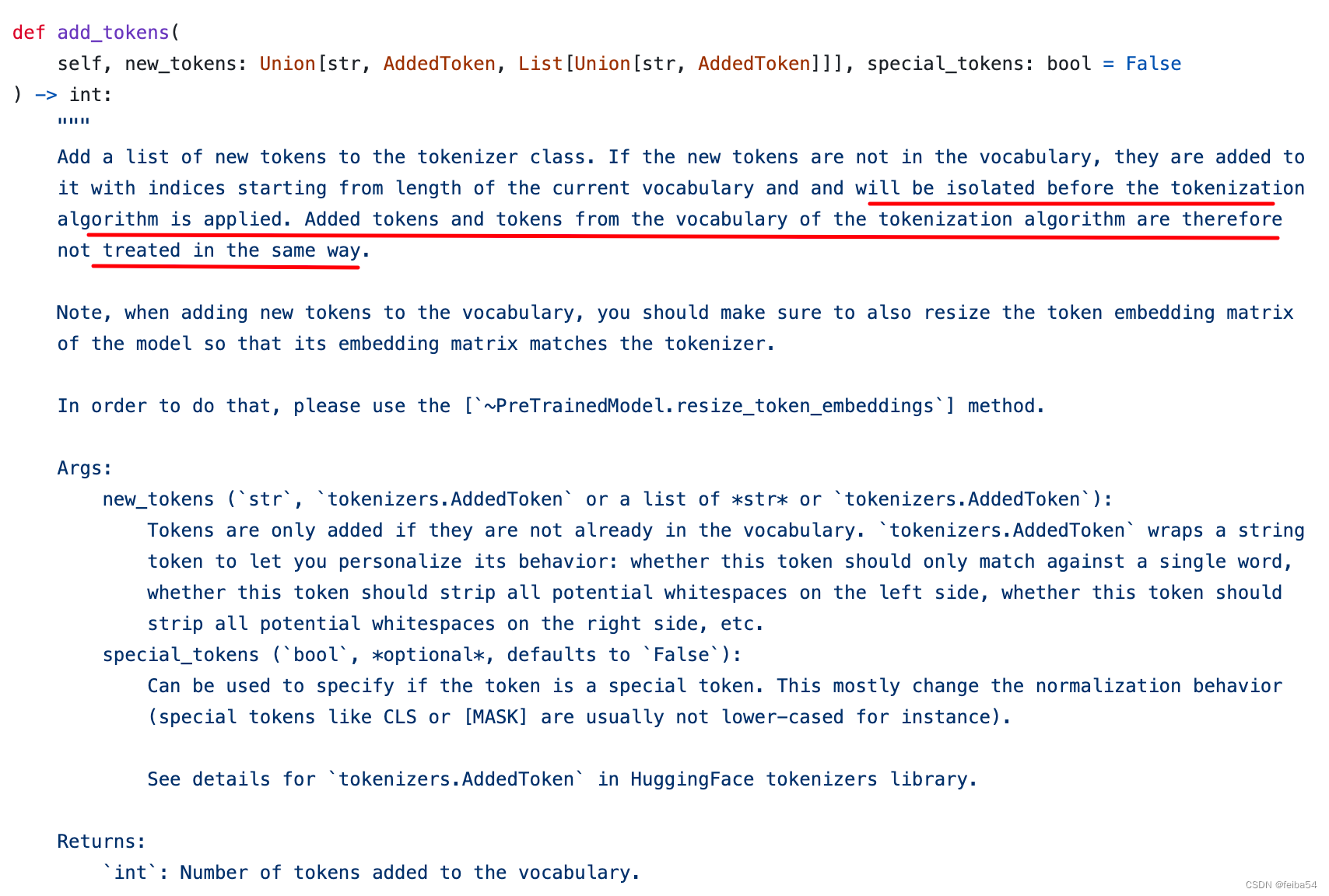
如何向BertModel增加字符
这里写自定义目录标题 看起来add_special_tokens和add_tokens加入的新token都不会被切分。...

copilot切换下一条提示的快捷键
注意是右ALT 右ALT] 触发提示 右ALT/ 参考 https://www.cnblogs.com/strengthen/p/17210356.html...

Mongodb 删除文档Delete与Remove的区别
db.collection.remove() 此方法已被 mongosh 弃用 已弃用的方法替代方法db.collection.remove()db.collection.deleteOne() db.collection.deleteMany() db.collection.findOneAndDelete() db.collection.bulkWrite() 5.0版本更改。 db.collection.remove(<query>,…...

Docker 的基本概念和优势
Docker 是一种开源的容器化平台,可以轻松部署、管理和运行应用程序。它基于 Linux 容器技术,可以将应用程序和其依赖项打包到一个可移植的容器中,从而使应用程序更易于部署、移植和扩展。 Docker 的主要优势包括: 1. 简化部署&a…...
基于 xhr 实现 axios
基于 xhr 实现 axios 上面我们讲到二次封装 axios ,但是现在我们尝试完全脱离 axios,自己实现一个 axios,由于 axios 底层是基于 xhr 做了二次封装,所以我们也可以尝试一下。 xhr 二次封装 src/plugins/xhr.js /*** 请求拦截器…...

基于面向对象的大模型代码生成
众多周至,大模型非常依赖上下文,要让大模型生成比较好的代码,必须准确地给大模型传递上下文信息和指令。 痛点 目前大模型主要以自然语言进行交互,通过自然语言交互的好处是降低大模型的使用门槛,但是由于语言的不精确…...

易云维®FMCS厂务系统创造工厂全新的“数字低碳智能”应用场景
近年来,新一代信息技术的高速发展为传统工业与制造业领域带来了新的机遇。信息技术加持下的制造技术发展出了新的生产方式、产业形态与管理模式。通过搭建FMCS厂务系统进行数字化转型来实现数据互联互通与业务高效协同,助力企业向安全、绿色、节能、高效…...
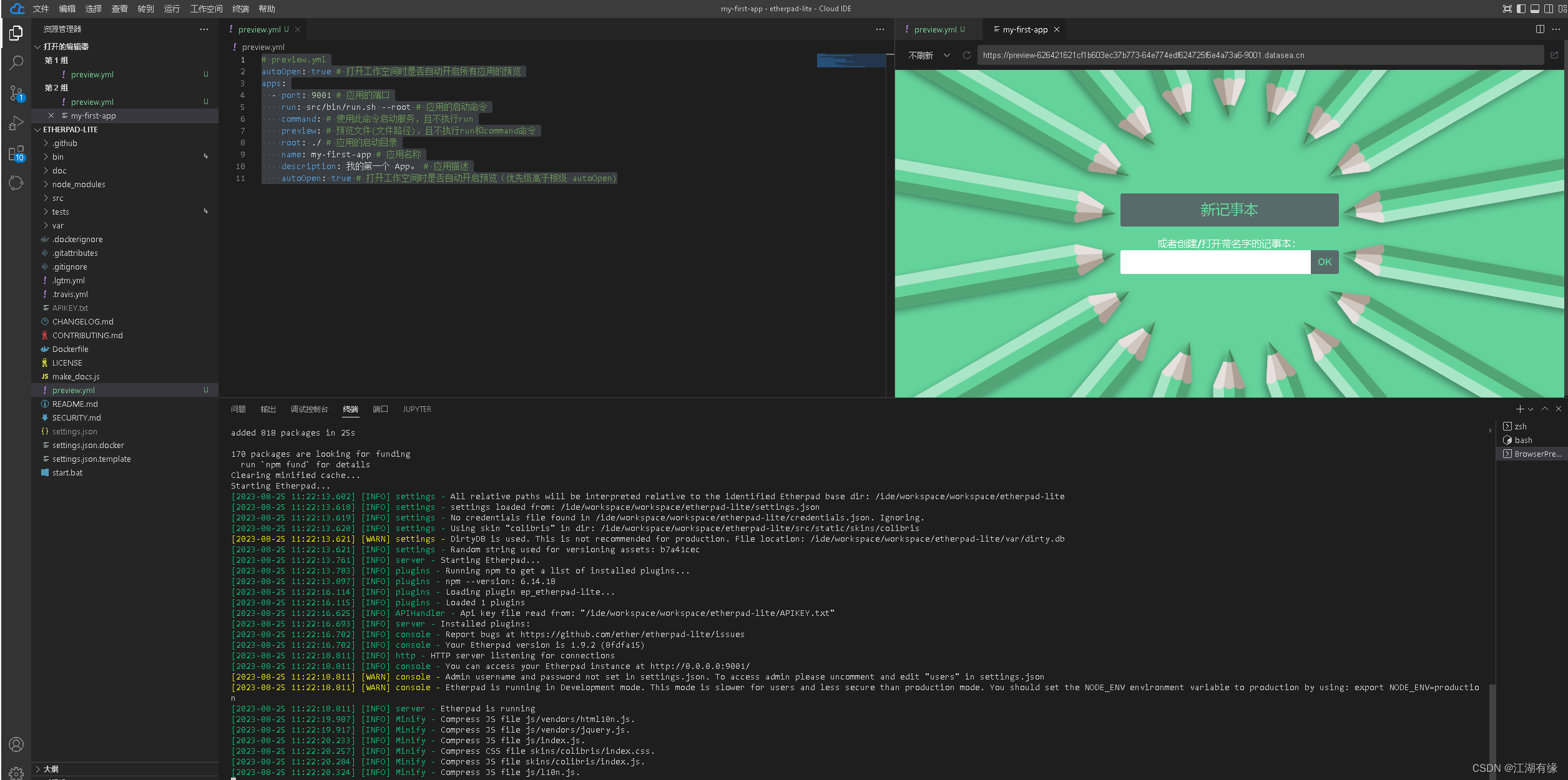
【Linux应用部署篇】在CSDN云IDE平台部署Etherpad文档编辑器
【Linux应用部署篇】在CSDN云IDE平台部署Etherpad文档编辑器 一、CSDN云IDE平台介绍1.1 CSDN云IDE平台简介1.2 CSDN云IDE平台特点 二、本次实践介绍2.1 本次实践介绍2.2 Etherpad简介 三、登录CSDN云IDE平台3.1 登录CSDN开发云3.2 登录云IDE3.3 新建工作空间3.4 进入工作空间 四…...
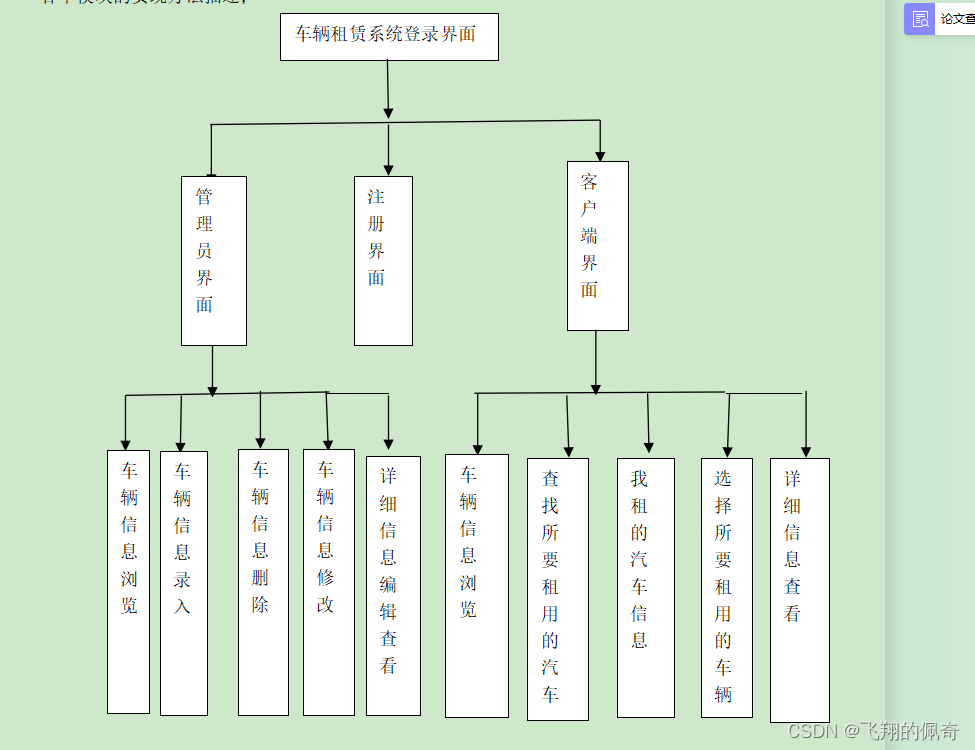
基于java swing和mysql实现的汽车租赁管理系统(源码+数据库+文档+运行指导视频)
一、项目简介 本项目是一套基于java swing和mysql实现的汽车租赁管理系统,主要针对计算机相关专业的正在做毕设的学生与需要项目实战练习的Java学习者。 包含:项目源码、项目文档、数据库脚本等,该项目附带全部源码可作为毕设使用。 项目都经…...

Rigs-of-rods安装
Rigs-of-rods安装 安装git 首先下载git,下载地址:https://git-scm.com/download/win,安装git 安装cmake 下载cmake,下载地址:https://cmake.org/download/,安装cmake 安装vs2022下载ror的依赖库 git clone https://github.co…...

html学习第2篇---标签(1)
html学习第2篇---标签 1、标题标签h1---h62、段落标签p3、换行标签br4、文本格式化标签5、div标签和span标签6、图像标签img6.1、图像属性6.2、相对路径、绝对路径 7、超链接标签a7.1、属性7.2、分类 8、注释标签和特殊字符8.1、注释8.2、特殊字符 1、标题标签h1—h6 为了使网…...
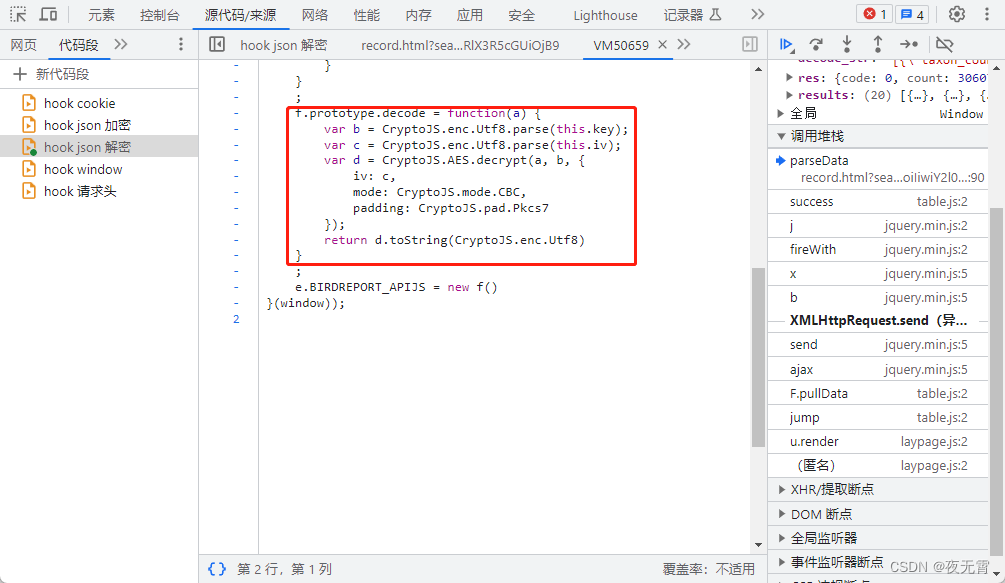
爬虫逆向实战(二十四)--某鸟记录中心
一、数据接口分析 主页地址:某鸟记录中心 1、抓包 通过抓包可以发现数据接口是front/record/search/page 2、判断是否有加密参数 请求参数是否加密? 通过查看“载荷”模块可以发现,请求参数是加密的 请求头是否加密? 通过查…...
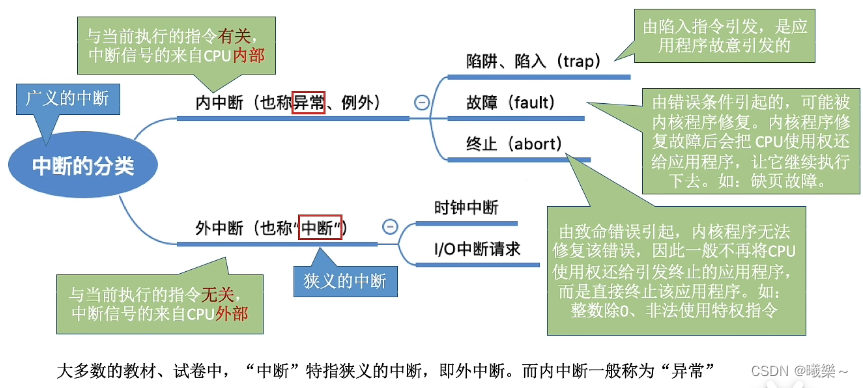
【操作系统】中断和异常
中断的作用 CPU上会执行两种程序:内核程序和应用程序 在适合的情况下,操作系统内核会把CPU的使用权主动让给应用程序,“中断”是让操作系统内核夺回CPU使用权的唯一途径(用户态转内核态)。 中断技术保证了并发。 中…...

锁策略、原子编程CAS 和 synchronized 优化过程
前言 锁冲突:两个线程获取一把锁,一个线程阻塞等待,一个线程加锁成功。 目录 前言 一、锁策略 (一)乐观锁和悲观锁 (二)重量级锁和轻量级锁 (三)自旋锁和挂起等待…...
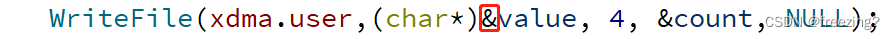
【WINAPI】文件读写操作问题
问题描述 在利用WINAPI中的WriteFile和ReadFile函数进行文件读写操作时,出现无法正常读写文件报错。 分析问题 查阅WINAPI源码,查看参数列表各个参数的数据类型。 发现其中第二个参数,也就是需要写进文件的真实数据,其数据类型…...
【LeetCode-中等题】148. 排序链表
文章目录 题目方法一:集合排序(核心是内部的排序)方法二: 优先队列(核心也是内部的排序)方法三:归并排序(带递归) 从上往下方法四:归并排序(省去递…...

Ceph EC pg backfill run
pg的backfill请求也是发送到osd的work queue中与业务IO一起竞争。 PGRecovery::run backfill 57 void PGRecovery::run( 58 OSD *osd, 59 OSDShard *sdata, 60 PGRef& pg, 61 ThreadPool::TPHandle &handle) 62 { 63 osd->do_recovery(pg.get(), epoch_queued…...

明日方舟MAA助手:如何用5分钟自动化你的每日游戏任务
明日方舟MAA助手:如何用5分钟自动化你的每日游戏任务 【免费下载链接】MaaAssistantArknights 《明日方舟》小助手,全日常一键长草!| A one-click tool for the daily tasks of Arknights, supporting all clients. 项目地址: https://gitc…...
)
别再只用EC11调音量了!用STM32做个旋转编码器计数器(OLED显示,附防抖代码)
解锁EC11旋转编码器的计数潜能:STM32实战指南与防抖优化 旋转编码器在电子项目中常被简化为音量调节工具,但其真正的价值远不止于此。EC11作为一款经济高效的旋转编码器,能够提供精确的数字脉冲信号,非常适合需要精准位置控制或速…...

Redis分布式锁进阶第一二十五篇
Redis分布式锁进阶第二十五篇:联锁深度拆解 多资源交叉死锁根治 复杂业务多级加锁绝对有序方案一、本篇前置衔接 第二十四篇我们完成了全系列终局复盘,整理了故障排查SOP与企业级落地铁律。常规单资源锁、热点分片锁、隔离锁全部讲透,但真实…...

音频处理中的头部空间标准化:原理、工具与工程实践
1. 项目概述:一个为音频处理而生的“头部空间”工具如果你经常处理音频,尤其是人声干音,那你一定对“头部空间”这个概念不陌生。简单来说,它指的是人声录音中,人声峰值电平与数字满刻度(0 dBFS)…...

除了 Docker 还能用什么?一文看懂容器技术的“四大门派”
除了 Docker 还能用什么?一文看懂容器技术的“四大门派” 在云原生时代,Docker 几乎成了容器的代名词。但实际上,容器技术是一片茂密的森林,除了 Docker,还有许多针对特定痛点(如安全、性能、隔离性&#x…...

Maxwell 2D仿真进阶:从磁力线可视化到磁感应强度曲线分析
1. Maxwell 2D仿真基础与优势解析 第一次接触电磁场仿真时,我被各种专业术语和复杂的操作界面搞得晕头转向。直到发现Maxwell 2D这个神器,才真正体会到电磁仿真的魅力。相比于3D仿真,2D版本有个特别实用的功能——可以直接观察磁力线分布&…...

FontForge入门指南:从零开始设计你的第一套字体
FontForge入门指南:从零开始设计你的第一套字体 【免费下载链接】fontforge Free (libre) font editor for Windows, Mac OS X and GNULinux 项目地址: https://gitcode.com/gh_mirrors/fo/fontforge 你是否曾想过亲手设计一套属于自己的字体?Fon…...

iOS越狱技术深度解析:安全漏洞利用与系统权限获取方案
iOS越狱技术深度解析:安全漏洞利用与系统权限获取方案 【免费下载链接】Jailbreak iOS 26.4 - 26, 17 - 17.7.5 & iOS 18 - 18.7.3 Jailbreak Tools, Cydia/Sileo/Zebra Tweaks & Jailbreak News Updates || AI Jailbreak Finder 👇 项目地址:…...
从零实现基础大语言模型:Transformer架构、训练流程与工程实践全解析
1. 项目概述:从零开始理解基础大语言模型最近在开源社区里,datawhalechina/base-llm这个项目标题引起了我的注意。乍一看,它像是一个预训练好的大语言模型(Large Language Model, LLM)的仓库,但深入探究后&…...
!)
仅1月Accepted!恭喜北大学者独作发表Nature子刊(IF 10.1)!
源自风暴统计网:一键统计分析与绘图的AI网站 引言 非协作者且是独作,用GBD 2023发表顶刊Nature是什么概念?来看今天这篇由北大学者发表的硬核文章!GBD 2023发文依然很顶,郑老师团队的专属科研训练营帮你实现从0到1的…...