block层:7. 请求下发
blk_dispatch
源码基于5.10
1. blk_mq_sched_dispatch_requests
void blk_mq_sched_dispatch_requests(struct blk_mq_hw_ctx *hctx)
{// 队列struct request_queue *q = hctx->queue;// 队列已停止或者被暂停if (unlikely(blk_mq_hctx_stopped(hctx) || blk_queue_quiesced(q)))return;// 运行次数统计hctx->run++;/** 返回-EAGAIN表示hctx->dispatch不空,我们必须再次运行为了防止饥饿刷出*/if (__blk_mq_sched_dispatch_requests(hctx) == -EAGAIN) {if (__blk_mq_sched_dispatch_requests(hctx) == -EAGAIN)// 如果第2次还是失败,则使用异步派发,再重试blk_mq_run_hw_queue(hctx, true);}
}static int __blk_mq_sched_dispatch_requests(struct blk_mq_hw_ctx *hctx)
{struct request_queue *q = hctx->queue;struct elevator_queue *e = q->elevator;// 有无调度派发const bool has_sched_dispatch = e && e->type->ops.dispatch_request;int ret = 0;LIST_HEAD(rq_list);/** 如果之前有请求在派发列表上,则先把它们放在rq列表里,为了公平的派发*/if (!list_empty_careful(&hctx->dispatch)) {spin_lock(&hctx->lock);if (!list_empty(&hctx->dispatch))list_splice_init(&hctx->dispatch, &rq_list);spin_unlock(&hctx->lock);}// rq_list不空,表示从dispatch里获取了之前的请求if (!list_empty(&rq_list)) {// 设置BLK_MQ_S_SCHED_RESTART标志blk_mq_sched_mark_restart_hctx(hctx);// 先把rq_list里的直接派发了if (blk_mq_dispatch_rq_list(hctx, &rq_list, 0)) {// 派发成功后,再派发新增的请求// 看有无调度器然后走不同的派发路径if (has_sched_dispatch)// 从调度器派发ret = blk_mq_do_dispatch_sched(hctx);else// 从ctx里派发ret = blk_mq_do_dispatch_ctx(hctx);}// 走到这儿表示dispatch里之前没有请求} else if (has_sched_dispatch) {// 如果有调度器,则使用调度器派发派发ret = blk_mq_do_dispatch_sched(hctx);// 走到这儿表示没有调度器} else if (hctx->dispatch_busy) {// 队列忙,说明队列正在运行,这时候从hctx里派发ret = blk_mq_do_dispatch_ctx(hctx);// 走到这儿表示调度器不忙} else {// 普通场景// 把ctx里的请求都放到rq_list上blk_mq_flush_busy_ctxs(hctx, &rq_list);// 派发请求blk_mq_dispatch_rq_list(hctx, &rq_list, 0);}return ret;
}
2. 普通场景
在普通场景里,先把所有ctx里的请求放在一个列表rq_list上,然后再派发rq_list上的请求。
void blk_mq_flush_busy_ctxs(struct blk_mq_hw_ctx *hctx, struct list_head *list)
{struct flush_busy_ctx_data data = {.hctx = hctx,.list = list,};// 遍历ctx映射里设置的位,调用flush_busy_ctxsbitmap_for_each_set(&hctx->ctx_map, flush_busy_ctx, &data);
}static bool flush_busy_ctx(struct sbitmap *sb, unsigned int bitnr, void *data)
{struct flush_busy_ctx_data *flush_data = data;// 硬队列struct blk_mq_hw_ctx *hctx = flush_data->hctx;// 软队列struct blk_mq_ctx *ctx = hctx->ctxs[bitnr];enum hctx_type type = hctx->type;spin_lock(&ctx->lock);// 把请求链到list后面,这个list就是从派发里传过来的list_splice_tail_init(&ctx->rq_lists[type], flush_data->list);// 清除对应的比特位sbitmap_clear_bit(sb, bitnr);spin_unlock(&ctx->lock);return true;
}
3. 有调度器的派发
static int blk_mq_do_dispatch_sched(struct blk_mq_hw_ctx *hctx)
{int ret;do {// 派发ret = __blk_mq_do_dispatch_sched(hctx);// 返回1表示派发成功了,则继续} while (ret == 1);return ret;
}static int __blk_mq_do_dispatch_sched(struct blk_mq_hw_ctx *hctx)
{struct request_queue *q = hctx->queue;struct elevator_queue *e = q->elevator;bool multi_hctxs = false, run_queue = false;bool dispatched = false, busy = false;unsigned int max_dispatch;// 记录需要派发的rqLIST_HEAD(rq_list);// 记录需要派发的数量int count = 0;if (hctx->dispatch_busy)// 派发忙,则最大只派发一个max_dispatch = 1;else// 否则可以派发最大的请求数max_dispatch = hctx->queue->nr_requests;do {struct request *rq;// 没有需要做的工作了,退出if (e->type->ops.has_work && !e->type->ops.has_work(hctx))break;// 派发列表里没有任务时,返回忙,不派发。if (!list_empty_careful(&hctx->dispatch)) {busy = true;break;}// 获取budgetif (!blk_mq_get_dispatch_budget(q))break;// 获取需要派发的请求rq = e->type->ops.dispatch_request(hctx);// 获取失败,或者没有rq了if (!rq) {// 释放 budgetblk_mq_put_dispatch_budget(q);// 需要运行队列run_queue = true;break;}// 走到这儿表示获取成功// 添加到rq_list里list_add_tail(&rq->queuelist, &rq_list);// 有多个队列if (rq->mq_hctx != hctx)multi_hctxs = true;} while (++count < max_dispatch);if (!count) {// 一个请求都没有入队,但是需要运行队列,则延迟再运行队列// 这种情况只有调度器里请求为空了if (run_queue)// 运行所有的硬件队列,BLK_MQ_BUDGET_DELAY=3毫秒blk_mq_delay_run_hw_queues(q, BLK_MQ_BUDGET_DELAY);} else if (multi_hctxs) {// 如果有多个hctx,先按hctx来排序list_sort(NULL, &rq_list, sched_rq_cmp);do {// 真正的派发请求dispatched |= blk_mq_dispatch_hctx_list(&rq_list);// 这里需要循环派发,因为 blk_mq_dispatch_hctx_list只派发一个hctx的请求} while (!list_empty(&rq_list));} else {// 只有一个hctx,则派发请求dispatched = blk_mq_dispatch_rq_list(hctx, &rq_list, count);}// 忙的话返回重试if (busy)return -EAGAIN;// 返回是否派发return !!dispatched;
}static int sched_rq_cmp(void *priv, const struct list_head *a,const struct list_head *b)
{struct request *rqa = container_of(a, struct request, queuelist);struct request *rqb = container_of(b, struct request, queuelist);// 按hctx的地址排序return rqa->mq_hctx > rqb->mq_hctx;
}
3.1 blk_mq_dispatch_hctx_list
static bool blk_mq_dispatch_hctx_list(struct list_head *rq_list)
{// 第一个请求的hctxstruct blk_mq_hw_ctx *hctx =list_first_entry(rq_list, struct request, queuelist)->mq_hctx;struct request *rq;LIST_HEAD(hctx_list);unsigned int count = 0;// 遍历需要派发的请求列表list_for_each_entry(rq, rq_list, queuelist) {// 因为列表已经按hctx排序了,所以遇到第一个hctx不同时,就派发它前面的if (rq->mq_hctx != hctx) {// 把rq_list到rq->queuelist之间的元素放到hctx_list上,然后派发list_cut_before(&hctx_list, rq_list, &rq->queuelist);goto dispatch;}// 记录将要放入hctx_list里请求的数量count++;}// 走到这儿表示rq_list里只有一个hctx,所以把rq_list整个列表都放到hctx里,// 然后把rq_list初始化list_splice_tail_init(rq_list, &hctx_list);dispatch:// 派发return blk_mq_dispatch_rq_list(hctx, &hctx_list, count);
}
4. 忙时的派发
hctx->dispatch_busy 是一个表示队列忙或空闲的状态,它使用ewma(指数加权移动平均法)来记录忙或空闲。ewma可以使这2种状态平滑的过度,不至于来回变。
dispatch_ctx会循环遍历所有ctx里的请求,每次派发一个,直到ctx里的所有请求被派发
static int blk_mq_do_dispatch_ctx(struct blk_mq_hw_ctx *hctx)
{struct request_queue *q = hctx->queue;LIST_HEAD(rq_list);// 从上次派发的ctx开始struct blk_mq_ctx *ctx = READ_ONCE(hctx->dispatch_from);int ret = 0;struct request *rq;do {// dispatch队列不为空,表示有待派发的请求if (!list_empty_careful(&hctx->dispatch)) {ret = -EAGAIN;break;}// hctx的ctx没有一个置位的,那就不用派发了if (!sbitmap_any_bit_set(&hctx->ctx_map))break;// 获取budget,获取失败也返回if (!blk_mq_get_dispatch_budget(q))break;// 从一个ctx里取出请求rq = blk_mq_dequeue_from_ctx(hctx, ctx);// 没取到请求if (!rq) {blk_mq_put_dispatch_budget(q);// 延迟3毫秒再重新运行blk_mq_delay_run_hw_queues(q, BLK_MQ_BUDGET_DELAY);break;}// 把取出的请求加到rq_list里list_add(&rq->queuelist, &rq_list);// 下一个ctxctx = blk_mq_next_ctx(hctx, rq->mq_ctx);// 派发rq_list上的请求,如果派发成功,则继续循环// 软队列里每次只派发一个?} while (blk_mq_dispatch_rq_list(rq->mq_hctx, &rq_list, 1));// 写入最后一个派发的ctxWRITE_ONCE(hctx->dispatch_from, ctx);return ret;
}struct request *blk_mq_dequeue_from_ctx(struct blk_mq_hw_ctx *hctx,struct blk_mq_ctx *start)
{// 队列起点,如果start为0, 则从0开始,否则从start的hctx序号开始unsigned off = start ? start->index_hw[hctx->type] : 0;struct dispatch_rq_data data = {.hctx = hctx,.rq = NULL,};// 遍历ctx上的每个映射,从ctx里取请求,取到了就放到data.rq里,// 每成功取出一个ctx就会退出__sbitmap_for_each_set(&hctx->ctx_map, off,dispatch_rq_from_ctx, &data);// 返回从ctx里是否取到了请求return data.rq;
}static bool dispatch_rq_from_ctx(struct sbitmap *sb, unsigned int bitnr,void *data)
{struct dispatch_rq_data *dispatch_data = data;// 硬件队列struct blk_mq_hw_ctx *hctx = dispatch_data->hctx;// 对应的软队列struct blk_mq_ctx *ctx = hctx->ctxs[bitnr];// 类型enum hctx_type type = hctx->type;spin_lock(&ctx->lock);// 软队列里有请求if (!list_empty(&ctx->rq_lists[type])) {// 从ctx列表上取一个请求dispatch_data->rq = list_entry_rq(ctx->rq_lists[type].next);// 将请求从列表上删了,注意,这里是每次只取一个请求list_del_init(&dispatch_data->rq->queuelist);// 如果列表上空了,则清除对应的位图if (list_empty(&ctx->rq_lists[type]))sbitmap_clear_bit(sb, bitnr);}spin_unlock(&ctx->lock);// 返回false表示不再循环,如果rq取到了值就返回false,退出__sbitmap_for_each_set的循环return !dispatch_data->rq;
}static struct blk_mq_ctx *blk_mq_next_ctx(struct blk_mq_hw_ctx *hctx,struct blk_mq_ctx *ctx)
{// 当前hctx里ctx的序号unsigned short idx = ctx->index_hw[hctx->type];// 如果超过了最大值,则从0开始if (++idx == hctx->nr_ctx)idx = 0;// 返回下一个ctxreturn hctx->ctxs[idx];
}
5. blk_mq_dispatch_rq_list
所有的派发路径最终都会汇集到这个函数里来,这个是最终给驱动层派发的函数。
bool blk_mq_dispatch_rq_list(struct blk_mq_hw_ctx *hctx, struct list_head *list,unsigned int nr_budgets)
{enum prep_dispatch prep;// 硬件队列struct request_queue *q = hctx->queue;struct request *rq, *nxt;int errors, queued;blk_status_t ret = BLK_STS_OK;LIST_HEAD(zone_list);bool needs_resource = false;// list为空if (list_empty(list))return false;errors = queued = 0;// 处理所有的请求,把它们发给驱动do {struct blk_mq_queue_data bd;// 取出一个请求rq = list_first_entry(list, struct request, queuelist);// rq的hctx发生了变化WARN_ON_ONCE(hctx != rq->mq_hctx);// 准备派发prep = blk_mq_prep_dispatch_rq(rq, !nr_budgets);// 准备失败,退出if (prep != PREP_DISPATCH_OK)break;// 走到这儿表示准备成功,可以派发// 从list里删除list_del_init(&rq->queuelist);bd.rq = rq;if (list_empty(list))// 列表为空了,则是最后一个请求bd.last = true;else {// 在list不为空的时候,尝试为下一个请求获取driver tag,如果获取失败,// 那么当前请求也是最后一个请求// 获取下一个请求nxt = list_first_entry(list, struct request, queuelist);// 如果不能为下一个请求获取driver tag,那也是最后一个请求,否则,则不是最后一个bd.last = !blk_mq_get_driver_tag(nxt);}// 只要调用入队就减1,不管成功或失败if (nr_budgets)nr_budgets--;// 调用设备的queue_rq,如果是scsi就会调用到scsi_queue_rqret = q->mq_ops->queue_rq(hctx, &bd);switch (ret) {case BLK_STS_OK:// 入队成功,queued记录入队成功的数量queued++;break;case BLK_STS_RESOURCE:// 资源忙needs_resource = true;fallthrough;case BLK_STS_DEV_RESOURCE:// 设备资源忙blk_mq_handle_dev_resource(rq, list);goto out;case BLK_STS_ZONE_RESOURCE:// zone设备资源忙blk_mq_handle_zone_resource(rq, &zone_list);needs_resource = true;break;default:// 出错,结束请求errors++;blk_mq_end_request(rq, BLK_STS_IOERR);}// 直到所有的列表派发完} while (!list_empty(list));
out:// zoned_list不空,则把它再加到list上if (!list_empty(&zone_list))list_splice_tail_init(&zone_list, list);// 已派发统计hctx->dispatched[queued_to_index(queued)]++;// (list里还有请求 || 有错误) && 驱动有commit_rqs函数 && 有派发成功的if ((!list_empty(list) || errors) && q->mq_ops->commit_rqs && queued)// 先之前派发的请求先提交q->mq_ops->commit_rqs(hctx);// 如果列表里还有请求,就把它们加到dispatch里,会在下一次运行queue的时候再派发它们if (!list_empty(list)) {bool needs_restart;// 没有共享的tag了bool no_tag = prep == PREP_DISPATCH_NO_TAG &&(hctx->flags & BLK_MQ_F_TAG_QUEUE_SHARED);// 先释放budgetsblk_mq_release_budgets(q, nr_budgets);spin_lock(&hctx->lock);// 把list里的加到派发列表里list_splice_tail_init(list, &hctx->dispatch);spin_unlock(&hctx->lock);smp_mb();// 需要重新启动needs_restart = blk_mq_sched_needs_restart(hctx);// 如果之前没有budget了,则是需要资源if (prep == PREP_DISPATCH_NO_BUDGET)needs_resource = true;// 不需要重启 || (没tag了 && 没有人在等待?)if (!needs_restart ||(no_tag && list_empty_careful(&hctx->dispatch_wait.entry)))// (不用重启 || (没有tag && 没有等待的))// 异步运行blk_mq_run_hw_queue(hctx, true);// 走到这儿表示: 需要重启 && (有tag || 有人在等待)else if (needs_restart && needs_resource)// 需要重启 && 需要资源// 延迟3毫秒运行。BLK_MQ_RESOURCE_DELAY = 3blk_mq_delay_run_hw_queue(hctx, BLK_MQ_RESOURCE_DELAY);// 标记hctx忙blk_mq_update_dispatch_busy(hctx, true);return false;} else// 请求全部提交,标记hctx不忙blk_mq_update_dispatch_busy(hctx, false);// 返回值是有无处理的,成功/失败都算return (queued + errors) != 0;
}static inline unsigned int queued_to_index(unsigned int queued)
{if (!queued)return 0;// BLK_MQ_MAX_DISPATCH_ORDER=7// ilog2(queued)算出派发成功的数量的对数return min(BLK_MQ_MAX_DISPATCH_ORDER - 1, ilog2(queued) + 1);
}5.1 blk_mq_prep_dispatch_rq
static enum prep_dispatch blk_mq_prep_dispatch_rq(struct request *rq,bool need_budget)
{struct blk_mq_hw_ctx *hctx = rq->mq_hctx;// 如果需要预算,则获取一个if (need_budget && !blk_mq_get_dispatch_budget(rq->q)) {// 获取失败释放driver tagblk_mq_put_driver_tag(rq);return PREP_DISPATCH_NO_BUDGET;}// 获取driver tag,这个函数主要把请求放到tag对应的数组里if (!blk_mq_get_driver_tag(rq)) {// 获取失败// 等一个tagif (!blk_mq_mark_tag_wait(hctx, rq)) {// 等tag失败// 如果上面分配了budget,则释放之if (need_budget)blk_mq_put_dispatch_budget(rq->q);return PREP_DISPATCH_NO_TAG;}}// 返回成功return PREP_DISPATCH_OK;
}
5.1.1 budget
static inline bool blk_mq_get_dispatch_budget(struct request_queue *q)
{// 从驱动里获取budgetif (q->mq_ops->get_budget)return q->mq_ops->get_budget(q);// 如果驱动不支持这个函数,直接返回truereturn true;
}static inline void blk_mq_put_dispatch_budget(struct request_queue *q)
{if (q->mq_ops->put_budget)q->mq_ops->put_budget(q);
}
6. 直接发布
6.1 入口
直接发布的2个入口: blk_mq_try_issue_directly, blk_mq_request_issue_directly, 这2个入口最终都会调到同一函数.
6.1.1 blk_mq_try_issue_directly
static void blk_mq_try_issue_directly(struct blk_mq_hw_ctx *hctx,struct request *rq, blk_qc_t *cookie)
{blk_status_t ret;int srcu_idx;// 硬件允许阻塞的话可能会阻塞might_sleep_if(hctx->flags & BLK_MQ_F_BLOCKING);hctx_lock(hctx, &srcu_idx);// 发布请求ret = __blk_mq_try_issue_directly(hctx, rq, cookie, false, true);if (ret == BLK_STS_RESOURCE || ret == BLK_STS_DEV_RESOURCE)// 因为资源忙而失败,则先插入队列?blk_mq_request_bypass_insert(rq, false, true);else if (ret != BLK_STS_OK)// 其它原因直接结束请求blk_mq_end_request(rq, ret);hctx_unlock(hctx, srcu_idx);
}
6.1.2 blk_mq_try_issue_list_directly
这个函数目前只有一个调用的地方: finish_plug -> blk_mq_sched_insert_requests -> blk_mq_try_issue_list_directly
void blk_mq_try_issue_list_directly(struct blk_mq_hw_ctx *hctx,struct list_head *list)
{int queued = 0;int errors = 0;// 遍历链表while (!list_empty(list)) {blk_status_t ret;// 获取请求struct request *rq = list_first_entry(list, struct request,queuelist);// 从队列里删除请求list_del_init(&rq->queuelist);// 发布请求,这个函数会直接调用驱动的发布函数ret = blk_mq_request_issue_directly(rq, list_empty(list));// 没发布成功if (ret != BLK_STS_OK) {// 错误增加errors++;// 如果是因为资源问题失败了,插入到队列晨if (ret == BLK_STS_RESOURCE ||ret == BLK_STS_DEV_RESOURCE) {// 加到派发队列, blk_mq_request_bypass_insert(rq, false,// 最后一个值是否运行队列list_empty(list));break;}// 如果是其它错误,则结束这个请求blk_mq_end_request(rq, ret);} else// 发布成功queued++;}// list不为空或者有错误 && queued: 则表示只发布了一部分// 如果队列有commit_rqs的话,则调用之if ((!list_empty(list) || errors) &&hctx->queue->mq_ops->commit_rqs && queued)hctx->queue->mq_ops->commit_rqs(hctx);
}
6.1.3 blk_mq_request_issue_directly
blk_status_t blk_mq_request_issue_directly(struct request *rq, bool last)
{blk_status_t ret;int srcu_idx;blk_qc_t unused_cookie;struct blk_mq_hw_ctx *hctx = rq->mq_hctx;// 锁硬件队列hctx_lock(hctx, &srcu_idx);// 发布请求ret = __blk_mq_try_issue_directly(hctx, rq, &unused_cookie, true, last);hctx_unlock(hctx, srcu_idx);return ret;
}
6.2 __blk_mq_try_issue_directly
## __blk_mq_try_issue_directly
```c
static blk_status_t __blk_mq_try_issue_directly(struct blk_mq_hw_ctx *hctx,struct request *rq,blk_qc_t *cookie,bool bypass_insert, bool last)
{struct request_queue *q = rq->q;bool run_queue = true;// 如果队列是停止状态或静默状态,则先插入请求,不能直接发布// blk_mq_hctx_stopped:检查hctx的状态有无BLK_MQ_S_STOPPED// blk_queue_quiesced检查队列的状态有无QUEUE_FLAG_QUIESCEDif (blk_mq_hctx_stopped(hctx) || blk_queue_quiesced(q)) {run_queue = false;bypass_insert = false;goto insert;}// 有电梯,不是bypass,则先插入if (q->elevator && !bypass_insert)goto insert;// 不能获取budget也先插入if (!blk_mq_get_dispatch_budget(q))goto insert;// 不能获取驱动tag直接插入if (!blk_mq_get_driver_tag(rq)) {// 插入前放弃budgetblk_mq_put_dispatch_budget(q);goto insert;}return __blk_mq_issue_directly(hctx, rq, cookie, last);// 走到这儿表示不能直接发布请求
insert:// 如果需要绕过调度器插入,则返回资源忙if (bypass_insert)return BLK_STS_RESOURCE;// 调度器插入blk_mq_sched_insert_request(rq, false, run_queue, false);return BLK_STS_OK;
}static blk_status_t __blk_mq_issue_directly(struct blk_mq_hw_ctx *hctx,struct request *rq,blk_qc_t *cookie, bool last)
{struct request_queue *q = rq->q;// 入队数据struct blk_mq_queue_data bd = {.rq = rq,.last = last,};blk_qc_t new_cookie;blk_status_t ret;// 生成rq的cookienew_cookie = request_to_qc_t(hctx, rq);// 调用队列的操作入队ret = q->mq_ops->queue_rq(hctx, &bd);switch (ret) {case BLK_STS_OK:// 成功// 更新状态不忙blk_mq_update_dispatch_busy(hctx, false);// 设置新的cookie*cookie = new_cookie;break;case BLK_STS_RESOURCE:case BLK_STS_DEV_RESOURCE:// 资源忙// 更新状态为忙blk_mq_update_dispatch_busy(hctx, true);// 重新加入到请求队列__blk_mq_requeue_request(rq);break;default:// 其它失败的情况blk_mq_update_dispatch_busy(hctx, false);*cookie = BLK_QC_T_NONE;break;}return ret;
}static void blk_mq_update_dispatch_busy(struct blk_mq_hw_ctx *hctx, bool busy)
{/* ewma: 指数加权移动平均法。公式:EWMA(t) = λY(t) + (1-λ)EWMA(t-1)对应到这里busy就是Y(t),*/unsigned int ewma;// 当前的状态ewma = hctx->dispatch_busy;// 当前不忙 && 要设置的也不忙,不用更新了if (!ewma && !busy)return;/* BLK_MQ_DISPATCH_BUSY_EWMA_WEIGHT = 8,所以λ=1/8按上面公式把下面的计算展开:ewma = 1/8 * busy + (1 - 1/8) * ewma= 1/8 * busy + (ewma*7)/8busy=0: ewma = (ewma*7)/8busy=1: ewma = 1/8 + (ewma*7)/8= 16 / 8 + (ewma*7)/8也就是每当忙的时候给ewma+2。真值表如下:busy dispatch_busy0 01 20 10 01 21 31 40 30 20 10 0*/ewma *= BLK_MQ_DISPATCH_BUSY_EWMA_WEIGHT - 1;// BLK_MQ_DISPATCH_BUSY_EWMA_FACTOR = 4if (busy) ewma += 1 << BLK_MQ_DISPATCH_BUSY_EWMA_FACTOR;ewma /= BLK_MQ_DISPATCH_BUSY_EWMA_WEIGHT;// 设置ewmahctx->dispatch_busy = ewma;
}static void __blk_mq_requeue_request(struct request *rq)
{struct request_queue *q = rq->q;// 释放driver的tagblk_mq_put_driver_tag(rq);trace_block_rq_requeue(rq);// todo: qos?rq_qos_requeue(q, rq);// 把rq的状态标记为MQ_RQ_IDLEif (blk_mq_request_started(rq)) {WRITE_ONCE(rq->state, MQ_RQ_IDLE);rq->rq_flags &= ~RQF_TIMED_OUT;}
}static inline int blk_mq_request_started(struct request *rq)
{return blk_mq_rq_state(rq) != MQ_RQ_IDLE;
}
相关文章:

block层:7. 请求下发
blk_dispatch 源码基于5.10 1. blk_mq_sched_dispatch_requests void blk_mq_sched_dispatch_requests(struct blk_mq_hw_ctx *hctx) {// 队列struct request_queue *q hctx->queue;// 队列已停止或者被暂停if (unlikely(blk_mq_hctx_stopped(hctx) || blk_queue_quiesc…...

Matlab图像处理-平移运算
几何运算 几何运算又称为几何变换,是将一幅图像中的坐标映射到另外一幅图像中的新坐标位置,它不改变图像的像素值,只是改变像素所在的几何位置,使原始图像按照需要产生位置、形状和大小的变化。 图像几何运算的一般定义为&#…...

美创科技一体化智能化公共数据平台数据安全建设实践
公共数据是当今政府数字化转型的关键要素和未来价值释放的核心锚点,也是“网络强国”、“数字中国”的战略性资源。 作为数字化改革先行省份,近年来,浙江省以一体化智能化公共数据平台作为数字化改革的支撑总平台,实现了全省公共数…...
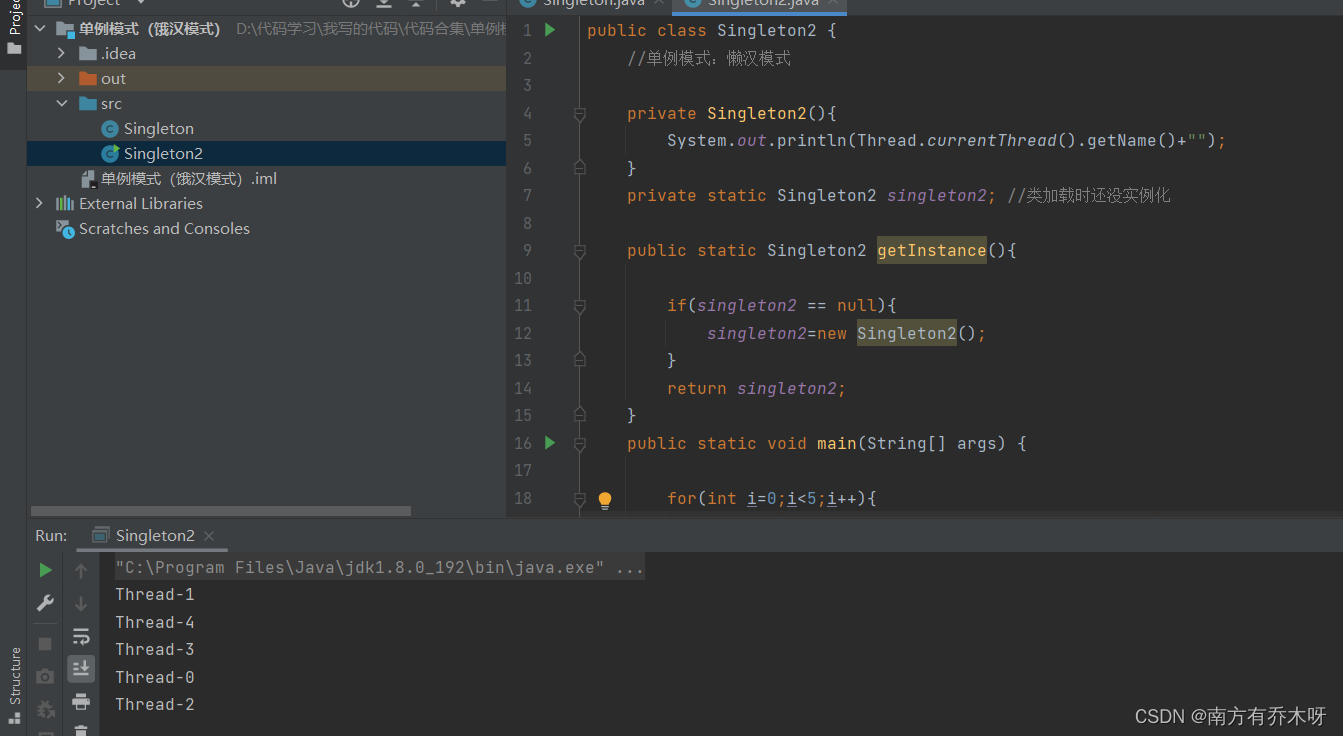
关于单例模式
单例模式的目的: 单例模式的目的和其他的设计模式的目的都是一样的,都是为了降低对象之间的耦合性,增加代码的可复用性,可维护性和可扩展性。 单例模式: 单例模式是一种常用的设计模式,用简单的言语说&am…...
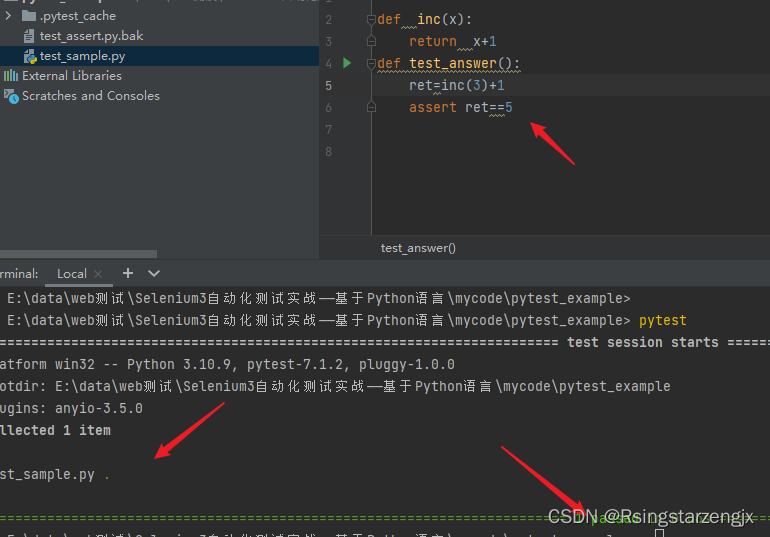
pytest笔记: pytest单元测试框架
第一步:安装 和查看版本 pycharm settings 查看 第二步: 编写test_example.py def inc(x):return x1 def test_answer():assert inc(4) 5 第三步:在当前路径下执行pytest 命令 PS E:\data\web测试\Selenium3自动化测试实战——基于Pyth…...
vulnhub Seattle-0.0.3
环境:vuluhub Seattle-0.0.3 1.catelogue处任意文件下载(目录穿越) http://192.168.85.139/download.php?item../../../../../../etc/passwd 有个admin目录,可以下载里面的文件进行读取 2.cltohes详情页面处(参数prod)存在sql报错注入 http://192.16…...

MYSQL 添加行号将行号写入到主键的列
MYSQL 添加行号 SELECT rownum: rownum 1 AS rownum, a.* FROM(SELECT rownum : 0) t,is_afxt.hk_vehicle a--或者(假设CREATED_TIME日期列数据不重复) select (select count(1)1 from is_afxt.hk_vehicle b where b.CREATED_TIME < a.CREATED_TIME) rownum ,a.* from i…...

前端命令npm 、 cnpm、 pnpm、yarn 、 npx、nvm的区别
大名鼎鼎的npm(Node Package Manager)是随同NodeJS一起安装的包管理工具,NPM本身也是Node.js的一个模块。 npm的含义有两层: npm服务器,npm服务器网址为https://www.npmjs.org,npm是 Node 包的标准发布平台,用于 Node 包的发布、…...

Linux 发行版 Debian 宣布支持龙芯 LoongArch 架构
近期,龙芯发布了 3A6000 桌面处理器,芯片的性能又一次大幅度提升,成为国产芯片的又一里程碑。 同期,LoongArch 架构的生态建设也迅速提升,开源网络引导固件 iPXE、QQ Linux 版、摩尔线程等软硬件都官宣支持龙芯 Loong…...

PConv : Run, Don’t Walk: Chasing Higher FLOPS for Faster Neural Networks
摘要 为了设计快速的神经网络,**许多研究都集中在减少浮点运算(FLOPs)**的数量。然而,我们观察到这种FLOPs的减少并不一定会导致相同程度的延迟减少。这主要是由于浮点运算每秒效率较低的问题所致。为了实现更快的网络,我们重新审视了流行的操作算子,并证明这种低FLOPS主…...

Python中怎么解决内存管理的问题? - 易智编译EaseEditing
Python有自动的内存管理机制,这意味着大部分情况下你不需要手动管理内存,因为Python的垃圾回收机制会自动处理不再使用的对象。然而,有时候你仍然需要关注内存管理,特别是在处理大数据、长时间运行的应用或需要最大化性能的情况下…...

【JavaEE】Spring事务-事务的基本介绍-事务的实现-@Transactional基本介绍和使用
【JavaEE】Spring 事务(1) 文章目录 【JavaEE】Spring 事务(1)1. 为什么要使用事务2. Spring中事务的实现2.1 事务针对哪些操作2.2 MySQL 事务使用2.3 Spring 编程式事务(手动挡)2.4 Spring 声明式事务&…...
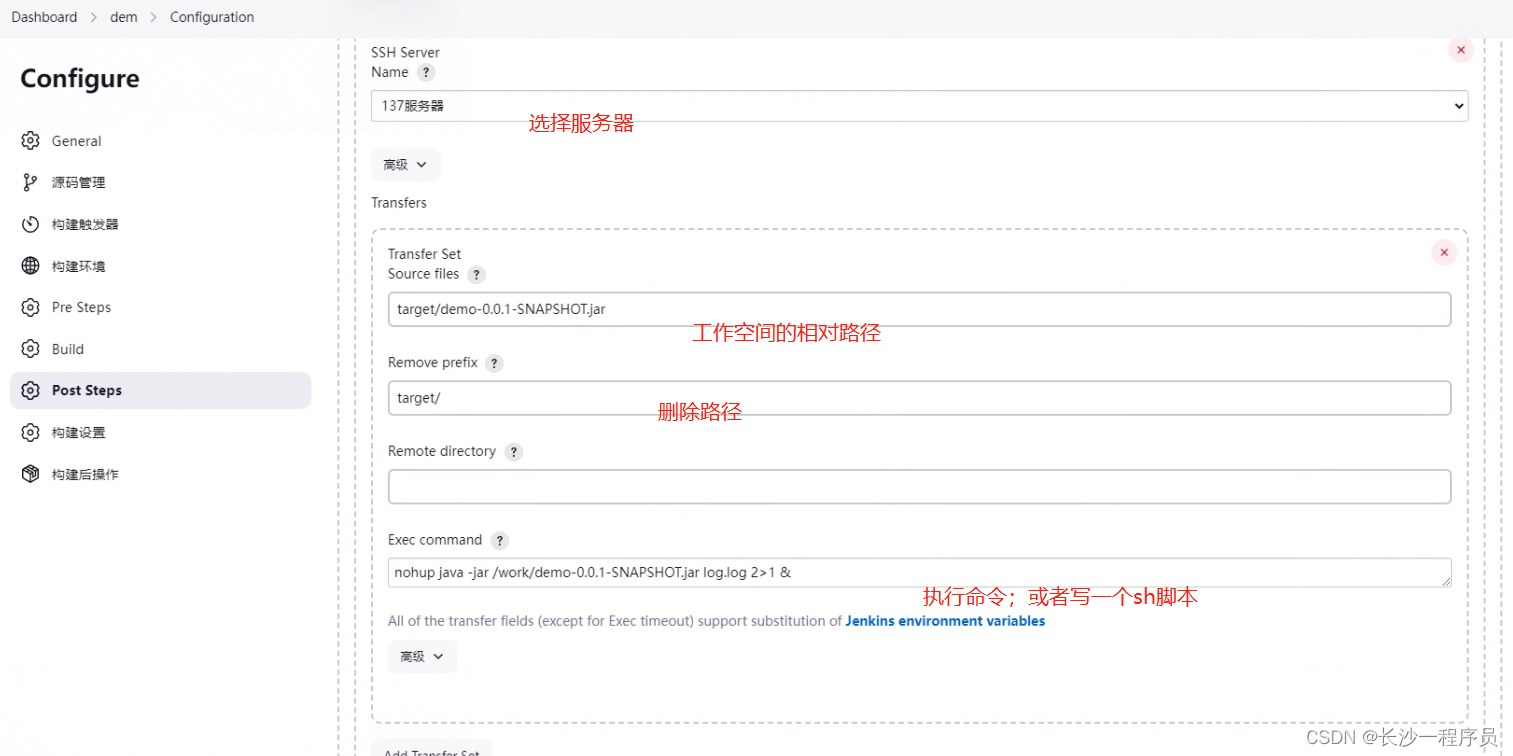
CentOs下面安装jenkins记录
目录 一、安装jenkins 二、进入jenkins 三、安装和Gitee,Maven , Publish Over SSH等插件 四、构建一个maven项目 一、安装jenkins 1 wget -O /etc/yum.repos.d/jenkins.repo \ https://pkg.jenkins.io/redhat-stable/jenkins.repo 2 rpm --im…...
海康威视相机-LINUX SDK 开发
硬件与环境 相机: MV-CS020-10GC 系统:UBUNTU 22.04 语言:C 工具:cmake 海康官网下载SDK 运行下面的命令进行安装 sudo dpkg -i MVSXXX.deb安装完成后从在/opt/MVS 路径下就有了相关的库,实际上我们开发的时候只需要…...
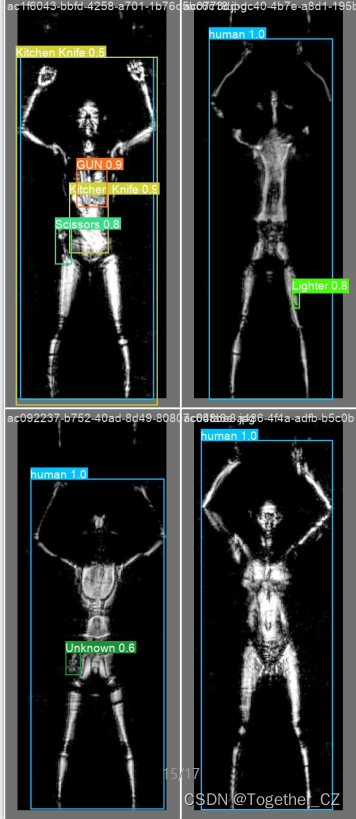
AI助力智能安检,基于图像目标检测实现危险品X光智能安全检测系统
基于AI相关的技术来对一些重复性的但是又比较重要的工作来做智能化助力是一个非常有潜力的场景,关于这方面的项目开发实践在我之前的文章中也有不少的实践,感兴趣的话可以自行移步阅读即可:《AI助力智能安检,基于目标检测模型实现…...

开源软件的崛起:历史与未来
🌷🍁 博主猫头虎 带您 Go to New World.✨🍁 🦄 博客首页——猫头虎的博客🎐 🐳《面试题大全专栏》 文章图文并茂🦕生动形象🦖简单易学!欢迎大家来踩踩~🌺 &a…...

apk 静默安装
apk 静默安装 - 欧颜柳 - 博客园 (cnblogs.com) 如果需要应用进行静默安装,则需要满足一下两个条件 1 必须添加权限 <uses-permission android:name"android.permission.INSTALL_PACKAGES" /> 2 必须是系统应用,或者系统签名应用 方法…...

Unity记录4.2-存储-从json文件获取Tile路径
文章首发见博客:https://mwhls.top/4813.html。 无图/格式错误/后续更新请见首发页。 更多更新请到mwhls.top查看 欢迎留言提问或批评建议,私信不回。 汇总:Unity 记录 摘要:从json文件获取Tile材质路径。 确定保存方案-2023/08/1…...

vue3页面传参?
...

NB水表和LoRa水表有哪些不同之处?
NB水表和LoRa水表是两种目前市场上常见的智能水表,它们在功能、性能、应用场景等方面存在一些不同之处。 一、技术方面 NB水表采用NB-IoT技术,而LoRa水表采用LoRa技术。NB-IoT技术是窄带物联网技术,它具有良好的低功耗、低成本、高覆盖、高可…...

data-prep-kit:Python数据预处理工具包,自动化清洗、特征工程与流水线构建
1. 项目概述与核心价值最近在数据科学和机器学习社区里,一个名为data-prep-kit的项目开始引起不少同行的注意。如果你经常和数据打交道,无论是做数据分析、构建模型,还是搭建数据管道,你肯定对“数据准备”这个环节又爱又恨。爱的…...

AI驱动软件架构可视化:C4模型与生成式AI的融合实践
1. 项目概述:当企业架构图遇上生成式AI 最近在技术社区里,一个名为 codecentric/c4-genai-suite 的项目引起了我的注意。乍一看标题,它融合了两个看似不相关的领域:C4模型和生成式AI。C4模型,对于软件架构师和开发者…...
,90%新手在第3步就误入歧途导致文献溯源失效)
NotebookLM音乐学应用的5个致命误区(附诊断清单),90%新手在第3步就误入歧途导致文献溯源失效
更多请点击: https://intelliparadigm.com 第一章:NotebookLM音乐学研究辅助的底层逻辑与适用边界 NotebookLM 本质是一个基于用户上传文档构建私有语义索引的轻量级 AI 助手,其核心并非通用大模型的自由生成,而是“引用驱动型推…...

构建AI涌现式判断系统:从智能体工作流到技术评审实践
1. 项目概述:当AI学会“判断”而非“计算”最近在GitHub上看到一个名为“emergent-judgment”的项目,由thebrierfox发起。初看标题,你可能会觉得这又是一个关于AI伦理或决策系统的抽象讨论。但深入探究后,我发现它指向了一个更具体…...

5分钟快速上手COLA架构:构建清晰分层的企业级应用完整指南
5分钟快速上手COLA架构:构建清晰分层的企业级应用完整指南 【免费下载链接】COLA 🥤 COLA: Clean Object-oriented & Layered Architecture 项目地址: https://gitcode.com/gh_mirrors/col/COLA COLA(Clean Object-oriented &…...

DellFanManagement终极指南:如何彻底掌控戴尔笔记本风扇噪音与散热平衡
DellFanManagement终极指南:如何彻底掌控戴尔笔记本风扇噪音与散热平衡 【免费下载链接】DellFanManagement A suite of tools for managing the fans in many Dell laptops. 项目地址: https://gitcode.com/gh_mirrors/de/DellFanManagement 还在为戴尔笔记…...

智能助手会话上下文管理:基于向量检索的长期记忆与多技能协作实践
1. 项目概述与核心价值最近在折腾一个基于大语言模型的智能助手项目,发现一个挺有意思的痛点:如何让AI在持续的对话中,不仅能记住当前聊了什么,还能“聪明地”回忆起我们之前讨论过的所有相关背景?比如,你昨…...

配电箱国家标准最新解读:GB/T 7251系列关键更新与合规要点
作为低压配电系统的核心设备,配电箱的质量直接关乎电力安全与人民生命财产安全。近年来,GB/T 7251《低压成套开关设备和控制设备》系列标准持续迭代升级,为行业规范化发展提供了重要技术支撑。本文从行业观察视角,系统梳理该系列标…...

基于MCP协议构建AI记忆管理服务:原理、实现与应用实践
1. 项目概述:一个为AI应用量身定制的记忆管理工具最近在折腾AI应用开发,特别是那些需要长期对话或上下文关联的场景时,一个绕不开的痛点就是“记忆”问题。模型本身是健忘的,每次对话都是全新的开始。为了让AI能记住用户偏好、历史…...

保姆级教程:手把手教你将VisDrone数据集转成MOT格式,适配MOTR等模型训练
保姆级教程:手把手教你将VisDrone数据集转成MOT格式,适配MOTR等模型训练 在计算机视觉领域,多目标跟踪(MOT)一直是研究热点之一。而VisDrone作为无人机视角下的经典数据集,其丰富的场景和挑战性的标注使其成为MOT研究的理想选择。…...