【大数据离线开发】7.4 HBase数据保存和过滤器
7.4 数据保存的过程
注意:数据的存储,都需要注意Region的分裂
- HDFS:数据的平衡 ——> 数据的移动(拷贝)
- HBase:数据越来越多 ——> Region的分裂 ——> 数据的移动(拷贝)

业务越来越大,数据越来越大,必然会发生Region的分裂。
运维:可以通过增加节点,或者预分配的方式
7.5 HBase的过滤器
过滤器:相当于SQL语句中的where查询条件
使用下面java程序操作HBase,仅需要修改IP地址
package demo.filter;import java.util.ArrayList;
import java.util.List;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.util.Bytes;
import org.junit.Test;public class DataInit {@Testpublic void testCreateTable() throws Exception{//指定的配置信息: ZooKeeperConfiguration conf = new Configuration();conf.set("hbase.zookeeper.quorum", "192.168.157.111");//创建一个HBase客户端: HBaseAdminHBaseAdmin admin = new HBaseAdmin(conf);//创建一个表的描述符: 表名HTableDescriptor hd = new HTableDescriptor(TableName.valueOf("emp"));//创建列族描述符HColumnDescriptor hcd1 = new HColumnDescriptor("empinfo");//加入列族hd.addFamily(hcd1);//创建表admin.createTable(hd);//关闭客户端admin.close();}@Testpublic void testPutData() throws Exception{//指定的配置信息: ZooKeeperConfiguration conf = new Configuration();conf.set("hbase.zookeeper.quorum", "192.168.157.111");//客户端HTable table = new HTable(conf, "emp");//第一条数据Put put1 = new Put(Bytes.toBytes("7369"));put1.add(Bytes.toBytes("empinfo"), Bytes.toBytes("ename"), Bytes.toBytes("SMITH"));Put put2 = new Put(Bytes.toBytes("7369"));put2.add(Bytes.toBytes("empinfo"), Bytes.toBytes("sal"), Bytes.toBytes("800"));//第二条数据Put put3 = new Put(Bytes.toBytes("7499"));put3.add(Bytes.toBytes("empinfo"), Bytes.toBytes("ename"), Bytes.toBytes("ALLEN"));Put put4 = new Put(Bytes.toBytes("7499"));put4.add(Bytes.toBytes("empinfo"), Bytes.toBytes("sal"), Bytes.toBytes("1600")); //第三条数据Put put5 = new Put(Bytes.toBytes("7521"));put5.add(Bytes.toBytes("empinfo"), Bytes.toBytes("ename"), Bytes.toBytes("WARD"));Put put6 = new Put(Bytes.toBytes("7521"));put6.add(Bytes.toBytes("empinfo"), Bytes.toBytes("sal"), Bytes.toBytes("1250")); //第四条数据Put put7 = new Put(Bytes.toBytes("7566"));put7.add(Bytes.toBytes("empinfo"), Bytes.toBytes("ename"), Bytes.toBytes("JONES"));Put put8 = new Put(Bytes.toBytes("7566"));put8.add(Bytes.toBytes("empinfo"), Bytes.toBytes("sal"), Bytes.toBytes("2975")); //第五条数据Put put9 = new Put(Bytes.toBytes("7654"));put9.add(Bytes.toBytes("empinfo"), Bytes.toBytes("ename"), Bytes.toBytes("MARTIN"));Put put10 = new Put(Bytes.toBytes("7654"));put10.add(Bytes.toBytes("empinfo"), Bytes.toBytes("sal"), Bytes.toBytes("1250"));//第六条数据Put put11 = new Put(Bytes.toBytes("7698"));put11.add(Bytes.toBytes("empinfo"), Bytes.toBytes("ename"), Bytes.toBytes("BLAKE"));Put put12 = new Put(Bytes.toBytes("7698"));put12.add(Bytes.toBytes("empinfo"), Bytes.toBytes("sal"), Bytes.toBytes("2850"));//第七条数据Put put13 = new Put(Bytes.toBytes("7782"));put13.add(Bytes.toBytes("empinfo"), Bytes.toBytes("ename"), Bytes.toBytes("CLARK"));Put put14 = new Put(Bytes.toBytes("7782"));put14.add(Bytes.toBytes("empinfo"), Bytes.toBytes("sal"), Bytes.toBytes("2450"));//第八条数据Put put15 = new Put(Bytes.toBytes("7788"));put15.add(Bytes.toBytes("empinfo"), Bytes.toBytes("ename"), Bytes.toBytes("SCOTT"));Put put16 = new Put(Bytes.toBytes("7788"));put16.add(Bytes.toBytes("empinfo"), Bytes.toBytes("sal"), Bytes.toBytes("3000")); //第九条数据Put put17 = new Put(Bytes.toBytes("7839"));put17.add(Bytes.toBytes("empinfo"), Bytes.toBytes("ename"), Bytes.toBytes("KING"));Put put18 = new Put(Bytes.toBytes("7839"));put18.add(Bytes.toBytes("empinfo"), Bytes.toBytes("sal"), Bytes.toBytes("5000")); //第十条数据Put put19 = new Put(Bytes.toBytes("7844"));put19.add(Bytes.toBytes("empinfo"), Bytes.toBytes("ename"), Bytes.toBytes("TURNER"));Put put20 = new Put(Bytes.toBytes("7844"));put20.add(Bytes.toBytes("empinfo"), Bytes.toBytes("sal"), Bytes.toBytes("1500")); //第十一条数据Put put21 = new Put(Bytes.toBytes("7876"));put21.add(Bytes.toBytes("empinfo"), Bytes.toBytes("ename"), Bytes.toBytes("ADAMS"));Put put22 = new Put(Bytes.toBytes("7876"));put22.add(Bytes.toBytes("empinfo"), Bytes.toBytes("sal"), Bytes.toBytes("1100")); //第十二条数据Put put23 = new Put(Bytes.toBytes("7900"));put23.add(Bytes.toBytes("empinfo"), Bytes.toBytes("ename"), Bytes.toBytes("JAMES"));Put put24 = new Put(Bytes.toBytes("7900"));put24.add(Bytes.toBytes("empinfo"), Bytes.toBytes("sal"), Bytes.toBytes("950"));//第十三条数据Put put25 = new Put(Bytes.toBytes("7902"));put25.add(Bytes.toBytes("empinfo"), Bytes.toBytes("ename"), Bytes.toBytes("FORD"));Put put26 = new Put(Bytes.toBytes("7902"));put26.add(Bytes.toBytes("empinfo"), Bytes.toBytes("sal"), Bytes.toBytes("3000"));//第十四条数据Put put27 = new Put(Bytes.toBytes("7934"));put27.add(Bytes.toBytes("empinfo"), Bytes.toBytes("ename"), Bytes.toBytes("MILLER"));Put put28 = new Put(Bytes.toBytes("7934"));put28.add(Bytes.toBytes("empinfo"), Bytes.toBytes("sal"), Bytes.toBytes("1300"));//构造ListList<Put> list = new ArrayList<Put>();list.add(put1);list.add(put2);list.add(put3);list.add(put4);list.add(put5);list.add(put6);list.add(put7);list.add(put8);list.add(put9);list.add(put10);list.add(put11);list.add(put12);list.add(put13);list.add(put14);list.add(put15);list.add(put16);list.add(put17);list.add(put18);list.add(put19);list.add(put20);list.add(put21);list.add(put22);list.add(put23);list.add(put24);list.add(put25);list.add(put26);list.add(put27);list.add(put28); //插入数据table.put(list);table.close(); }
}
常见的过滤器
列值过滤器:select * from emp where sal = 3000;
列名前缀过滤器:查询员工的姓名 select ename form emp;
多个列名前缀过滤器:查询员工的姓名、薪水 select ename, sal from emp;
行键过滤器:通过Row可以查询,类似通过Get查询数据
组合几个过滤器查询数据:where 条件1 and(or)条件2
public class TestHBaseFilter {@Testpublic void testSingleColumnValueFilter() throws Exception{//列值过滤器: 查询薪水等于3000的员工// select * from emp where sal=3000//配置ZooKeeperConfiguration conf = new Configuration();conf.set("hbase.zookeeper.quorum", "192.168.157.111");//得到客户端HTable table = new HTable(conf,"emp");//定义一个过滤器SingleColumnValueFilter filter = new SingleColumnValueFilter(Bytes.toBytes("empinfo"), //列族Bytes.toBytes("sal"), //列名CompareOp.EQUAL, //比较运算符Bytes.toBytes("3000")); //值//定义一个扫描器Scan scan = new Scan();scan.setFilter(filter);//查询数据:结果中只有员工姓名ResultScanner rs = table.getScanner(scan);for(Result r:rs){String name = Bytes.toString(r.getValue(Bytes.toBytes("empinfo"), Bytes.toBytes("ename")));System.out.println(name);}table.close();}@Testpublic void testColumnPrefixFilter() throws Exception{//列名前缀过滤器 查询员工的姓名: select ename from emp;//配置ZooKeeperConfiguration conf = new Configuration();conf.set("hbase.zookeeper.quorum", "192.168.157.111");//得到客户端HTable table = new HTable(conf,"emp");//定义一个过滤器ColumnPrefixFilter filter = new ColumnPrefixFilter(Bytes.toBytes("ename"));//定义一个扫描器Scan scan = new Scan();scan.setFilter(filter);//查询数据:结果中只愿员工的姓名ResultScanner rs = table.getScanner(scan);for(Result r:rs){String name = Bytes.toString(r.getValue(Bytes.toBytes("empinfo"), Bytes.toBytes("ename")));//获取员工的薪水String sal = Bytes.toString(r.getValue(Bytes.toBytes("empinfo"), Bytes.toBytes("sal")));System.out.println(name+"\t"+sal);}table.close(); }@Testpublic void testMultipleColumnPrefixFilter() throws Exception{//多个列名前缀过滤器//查询员工信息:员工姓名 薪水//配置ZooKeeperConfiguration conf = new Configuration();conf.set("hbase.zookeeper.quorum", "192.168.157.11");//得到客户端HTable table = new HTable(conf,"emp");//二维数组byte[][] names = {Bytes.toBytes("ename"),Bytes.toBytes("sal")};//定义一个过滤器MultipleColumnPrefixFilter filter = new MultipleColumnPrefixFilter(names);//定义一个扫描器Scan scan = new Scan();scan.setFilter(filter);//查询数据ResultScanner rs = table.getScanner(scan);for(Result r:rs){String name = Bytes.toString(r.getValue(Bytes.toBytes("empinfo"), Bytes.toBytes("ename")));//获取员工的薪水String sal = Bytes.toString(r.getValue(Bytes.toBytes("empinfo"), Bytes.toBytes("sal")));System.out.println(name+"\t"+sal);}table.close(); }@Testpublic void testRowFilter() throws Exception{//查询员工号7839的信息//配置ZooKeeperConfiguration conf = new Configuration();conf.set("hbase.zookeeper.quorum", "192.168.157.11");//得到客户端HTable table = new HTable(conf,"emp");//定义一个行键过滤器RowFilter filter = new RowFilter(CompareOp.EQUAL, //比较运算符new RegexStringComparator("7839")); //使用正则表达式来代表值//定义一个扫描器Scan scan = new Scan();scan.setFilter(filter);//查询数据ResultScanner rs = table.getScanner(scan);for(Result r:rs){String name = Bytes.toString(r.getValue(Bytes.toBytes("empinfo"), Bytes.toBytes("ename")));//获取员工的薪水String sal = Bytes.toString(r.getValue(Bytes.toBytes("empinfo"), Bytes.toBytes("sal")));System.out.println(name+"\t"+sal);}table.close(); } @Testpublic void testFilter() throws Exception{/** 查询工资等于3000的员工姓名 select ename from emp where sal=3000;* 1、列值过滤器:工资等于3000* 2、列名前缀过滤器:姓名*///配置ZooKeeperConfiguration conf = new Configuration();conf.set("hbase.zookeeper.quorum", "192.168.157.11");//得到客户端HTable table = new HTable(conf,"emp");//第一个过滤器 列值过滤器:工资等于3000SingleColumnValueFilter filter1 = new SingleColumnValueFilter(Bytes.toBytes("empinfo"), //列族Bytes.toBytes("sal"), //列名CompareOp.EQUAL, //比较运算符Bytes.toBytes("3000")); //值//第二个过滤器:列名前缀 姓名ColumnPrefixFilter filter2 = new ColumnPrefixFilter(Bytes.toBytes("ename"));//创建一个FliterList//Operator.MUST_PASS_ALL 相当于 and//Operator.MUST_PASS_ONE 相当于 orFilterList list = new FilterList(Operator.MUST_PASS_ALL);list.addFilter(filter1);list.addFilter(filter2);//定义一个扫描器Scan scan = new Scan();scan.setFilter(list);//查询数据ResultScanner rs = table.getScanner(scan);for(Result r:rs){String name = Bytes.toString(r.getValue(Bytes.toBytes("empinfo"), Bytes.toBytes("ename")));//获取员工的薪水String sal = Bytes.toString(r.getValue(Bytes.toBytes("empinfo"), Bytes.toBytes("sal")));System.out.println(name+"\t"+sal);}table.close();}
}

7.6 HBase上的MapReduce
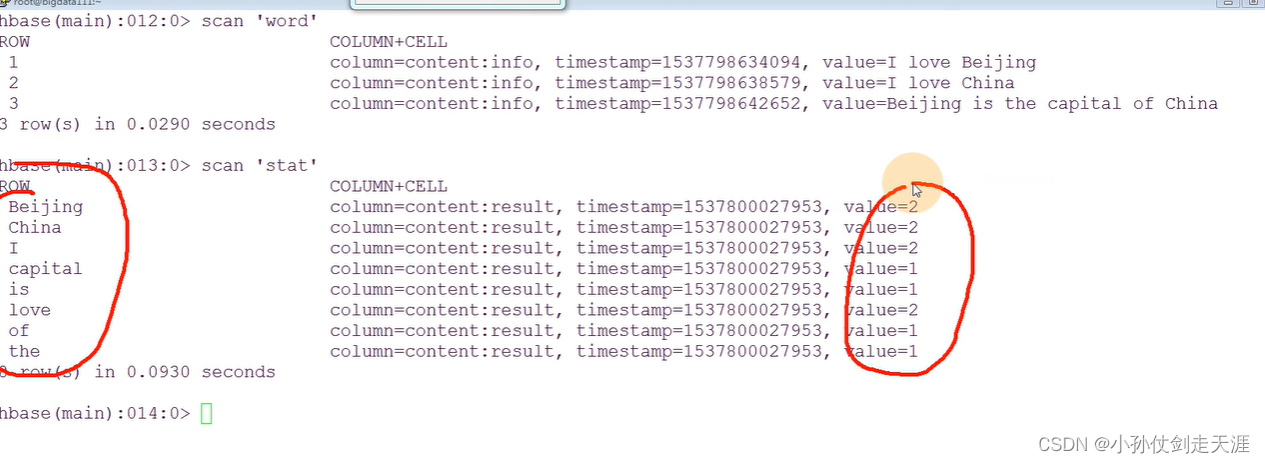
1、建立输入的表create 'word','content'put 'word','1','content:info','I love Beijing'put 'word','2','content:info','I love China'put 'word','3','content:info','Beijing is the capital of China'2、输出表:create 'stat','content'注意:export HADOOP_CLASSPATH=$HBASE_HOME/lib/*:$CLASSPATH
Mapper程序
//这时候处理的就是HBase表的一条数据
//没有k1和v1,<k1 v1>代表输入,因为输入的就是表中一条记录
public class WordCountMapper extends TableMapper<Text, IntWritable> {@Overrideprotected void map(ImmutableBytesWritable key, Result value,Context context)throws IOException, InterruptedException {/** key和value代表从表中输入的一条记录* key: 行键* value:数据*///获取数据: I love beijingString data = Bytes.toString(value.getValue(Bytes.toBytes("content"), Bytes.toBytes("info")));//分词String[] words = data.split(" ");for(String w:words){context.write(new Text(w), new IntWritable(1));}}
}
Reducer程序
// k3 v3 keyout代表输出的一条记录:指定行键
public class WordCountReducer extends TableReducer<Text, IntWritable, ImmutableBytesWritable> {@Overrideprotected void reduce(Text k3, Iterable<IntWritable> v3,Context context)throws IOException, InterruptedException {// 对v3求和int total = 0;for(IntWritable v:v3){total = total + v.get();}//输出:也是表中的一条记录//构造一个Put对象,把单词作为rowkey行键Put put = new Put(Bytes.toBytes(k3.toString()));put.add(Bytes.toBytes("content"), //列族Bytes.toBytes("result"), //列Bytes.toBytes(String.valueOf(total)));//输出context.write(new ImmutableBytesWritable(Bytes.toBytes(k3.toString())), //把这个单词作为key 就是输出的行键put); //表中的一条记录,得到的结果}}
main程序
public class WordCountMain {public static void main(String[] args) throws Exception {//获取ZK的地址//指定的配置信息: ZooKeeperConfiguration conf = new Configuration();conf.set("hbase.zookeeper.quorum", "192.168.157.111");//创建一个任务,指定程序的入口Job job = Job.getInstance(conf);job.setJarByClass(WordCountMain.class);//定义一个扫描器 只读取:content:info这个列的数据Scan scan = new Scan();//可以使用filter,还有一种方式来过滤数据scan.addColumn(Bytes.toBytes("content"), Bytes.toBytes("info"));//指定mapper,使用工具类设置MapperTableMapReduceUtil.initTableMapperJob(Bytes.toBytes("word"), //输入的表scan, //扫描器,只读取想要处理的数据WordCountMapper.class, Text.class, IntWritable.class, job);//指定Reducer,使用工具类设置ReducerTableMapReduceUtil.initTableReducerJob("stat", WordCountReducer.class, job);//执行任务job.waitForCompletion(true);}}
将编写的程序打包成jar包,上传到全分布或者伪分布环境下,启动环境运行,会有一个exception异常。
在Hadoop集群上会去访问HBase,需要HBase依赖

注意:export HADOOP_CLASSPATH=HBASEHOME/lib/∗:HBASE_HOME/lib/*:HBASEHOME/lib/∗:CLASSPATH

相关文章:
【大数据离线开发】7.4 HBase数据保存和过滤器
7.4 数据保存的过程 注意:数据的存储,都需要注意Region的分裂 HDFS:数据的平衡 ——> 数据的移动(拷贝)HBase:数据越来越多 ——> Region的分裂 ——> 数据的移动(拷贝) …...
CentOS7安装MariaDB步骤
文章目录1.配置MariaDB yum源2.安装MariaDBMariaDB数据库管理系统是MySQL的一个分支,主要由开源社区在维护,采用GPL授权许可。 MariaDB的目的是完全兼容MySQL,包括API和命令行,使之能轻松成为MySQL的代替品。 CentOS 6 或早期的版…...

软件测试13个最容易犯的错误
目录 一、 输入框测试 二、 搜索功能测试 三、 添加/修改功能 四、 删除功能 五、 上传图片功能测试 六、 查询结果列表 七、 返回键检查 八、 回车键检查 九、 刷新键检查 十、 直接URL链接检查(盗链问题) 十一、并发问题 十二、 业务流程测…...
)
华为OD机试真题Java实现【5键键盘的输出】真题+解题思路+代码(20222023)
🔥系列专栏 华为OD机试(Python)真题目录汇总华为OD机试(JAVA)真题目录汇总华为OD机试(C++)真题目录汇总华为OD机试(JavaScript)真题目录汇总文章目录 🔥系列专栏题目输入输出描述:示例1:示例2:解题思路代码实现运行结果:版权说明:题目...
化解射频和微波设计挑战的六个技巧
即使是最自信的设计人员,对于射频电路也往往望而却步,因为它会带来巨大的设计挑战,并且需要专业的设计和分析工具。这里将为您介绍六条技巧,来帮助您简化任何射频PCB 设计任务和减轻工作压力! 1、保持完好、精确的射频…...
)
linux内核—进程调度(核心)
目录 核心函数__schedule() 处理过程 1、选择下一个进程 2、切换线程 1)切换进程的虚拟地址空间 2)切换寄存器 3)执行清理工作 核心函数__schedule() 主要的调度程序 进入次函数的主要方法是: 1、显示阻塞:互…...
【STM32笔记】__WFI();进入不了休眠的可能原因(系统定时器SysTick一直产生中断)
【STM32笔记】__WFI();进入不了休眠的可能原因(系统定时器SysTick一直产生中断) 【STM32笔记】低功耗模式配置及避坑汇总 前文: blog.csdn.net/weixin_53403301/article/details/128216064 【STM32笔记】HAL库低功耗模式配置&am…...
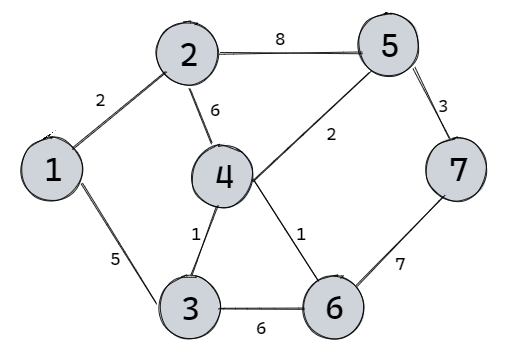
【期末复习】例题讲解Dijkstra算法
使用场景Dijkstra算法用于解决单源点最短路径问题,即给一个顶点作为源点,依次求它到图中其他n-1个顶点的最短距离。例题讲解Dijkstra算法将图中所有顶点分成两部分,第一部分是已知到源点最短距离的顶点Known(K),第二部分是不知道到…...

Pytorch 基础之张量索引
本次将介绍一下 Tensor 张量常用的索引与切片的方法: 1. index 索引 index 索引值表示相应维度值的对应索引 a torch.rand(4, 3, 28, 28) print(a[0].shape) # 返回维度一的第 0 索引 tensor print(a[0, 0].shape) # 返回维度一 0 索引位置…...
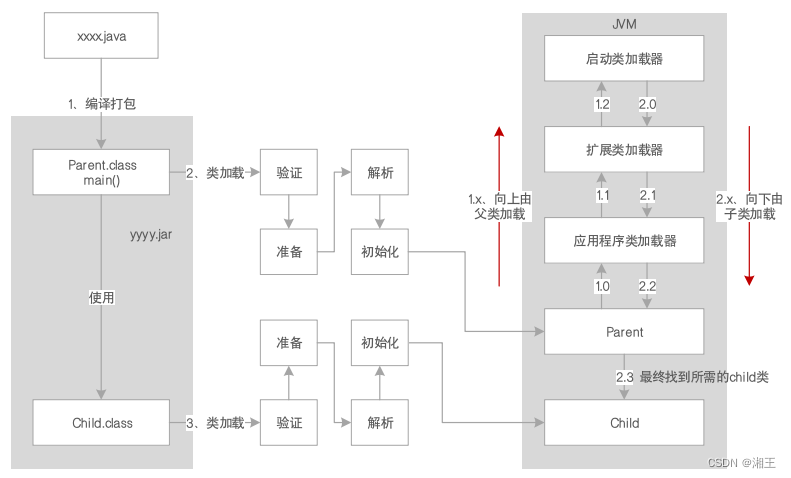
JVM系统优化实践(1):JVM概览
您好,我是湘王,这是我的CSDN博客,欢迎您来,欢迎您再来~这是多年之前做过的学习笔记,今天再翻出来,觉得仍然是记忆犹新。「独乐乐不如众乐乐」,就拿出来分享给「众乐乐」吧。目前大多…...

优秀!19年后,它再次成为TIOBE年度编程语言
新年伊始,TIOBE发布了2022年度编程语言,C时隔19年再度登顶,成为2022年最受欢迎的编程语言。TIOBE在2003年首次统计编程语言的流行指数时,C便成为年度编程语言。2022年,C获得了最高的人气4.62%,紧随其后的是…...
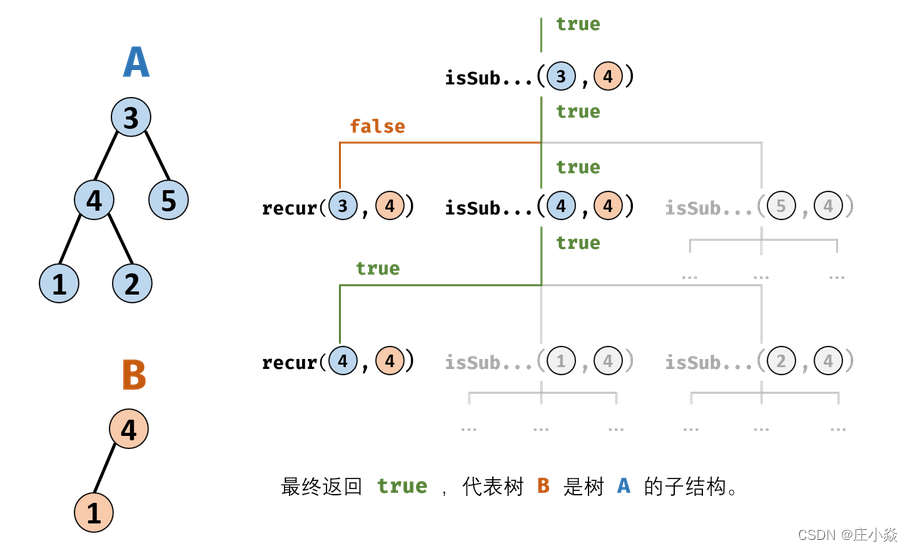
剑指 Offer 26. 树的子结构
摘要 剑指 Offer 26. 树的子结构 输入两棵二叉树A和B,判断B是不是A的子结构。(约定空树不是任意一个树的子结构),B是A的子结构, 即 A中有出现和B相同的结构和节点值。 一、子树解析 思路解析:若树B是树A的子结构,则…...

他是00年的,我们卷不过他...
现在的小年轻真的卷得过分了。前段时间我们公司来了个00年的,工作没两年,跳槽到我们公司起薪18K,都快接近我了。后来才知道人家是个卷王,从早干到晚就差搬张床到工位睡觉了。 最近和他聊了一次天,原来这位小老弟家里条…...

C#开发的OpenRA的OpenGL创建纹理流程
C#开发的OpenRA的OpenGL创建纹理流程 由于OpenRA采用的是OpenGL来显示游戏画面, 那么它就必然采用纹理来显示了。 并且由于它是2D的游戏,所以3D的模型是没有的,只要使用纹理贴图,就可以完全实现了游戏的功能。 OpenGL的纹理要起作用,需要经过一系列的动作。 先要使用glGen…...
3D目标检测(一)—— 基于Point-Based方法的PointNet系列
3D目标检测(一)—— PointNet,PointNet,PointNeXt, PointMLP 目录 3D目标检测(一)—— PointNet,PointNet,PointNeXt, PointMLP 前言 零、网络使用算法 …...

《设计模式》策略模式
策略模式 前言 先了解一下设计模式的几种类似: 行为型设计模式(Behavioral Design Pattern)是指一组设计模式,它们关注的是对象之间的通信和协作。行为型设计模式描述了对象之间的职责分配和算法的封装,以及如何在运…...

【离散数学】1. 数理逻辑
1.数理逻辑 2. 集合论 3. 代数系统 4. 图论 离散数学:研究离散量结构及相互关系的学科 数理逻辑集合论代数系统图论 逻辑:研究推理的科学 数学方法:引进一套符号系统的方法 数理逻辑是用数学方法研究形式逻辑的科学,即使用符号化…...
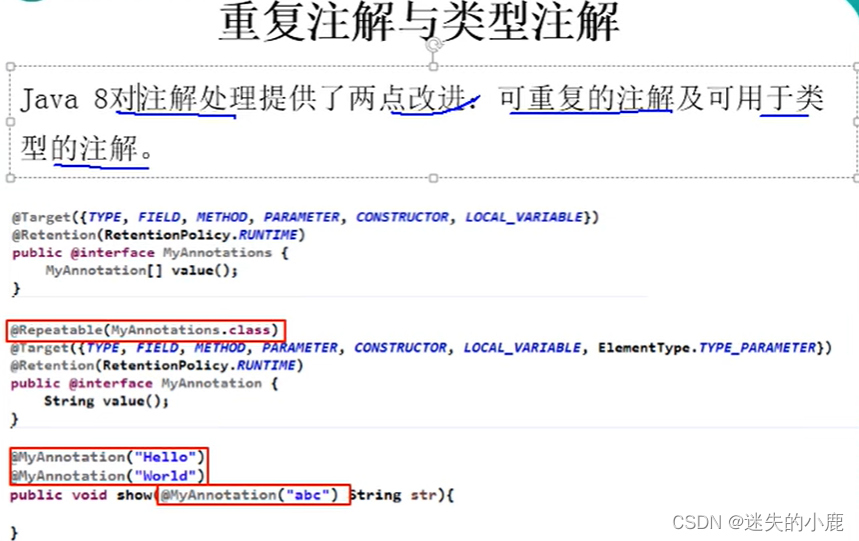
Java8新特性学习
Java8新特性学习为啥使用Lambda表达式Lambda表达式的基础语法无参无返回有参无返回一个参数多参单个语句体类型推断四大内置核心函数式接口其他接口方法引用与构造器引用Stream简介什么是StreamStream操作步骤创建Stream中间操作终止操作(终端操作)归约与收集并行流…...

SPARK outputDeterministicLevel的作用--任务全部重试或者部分重试
背景 目前spark的repartition()方法是随机分配数据到下游,这会导致一个问题,有时候如果我们用repartition方法的时候,如果任务发生了重试,就有可能导致任务的数据不准确,那这个时候改怎么解决这个问题呢? …...
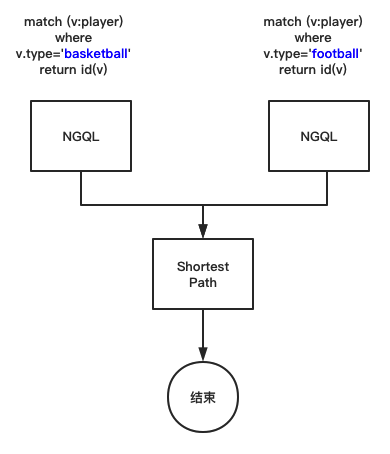
图数据库中的 OLTP 与 OLAP 融合实践
在一些图计算的场景下,我们会遇到同时需要处理 OLTP 和 OLAP 的问题。而本文就给了一个 OLTP 与 OLAP 融合实践的指导思路,希望给你带来一点启发。 Dag Controller 介绍 Dag Controller 是 NebulaGraph 企业版的图系统,经过反复测试无误后已…...
)
收藏备用!大模型3种调用模式详解,重点吃透RAG技术(小白/程序员入门必看)
对于刚接触大模型开发的小白、程序员来说,最困惑的莫过于“怎么用大模型”“如何避免AI瞎胡说”“不同场景该选哪种调用方式”。今天这篇文章,就把大模型最核心的3种调用模式讲透,重点拆解能解决AI幻觉、适配多场景的RAG技术,结合…...

BetterNCM安装器完全指南:3分钟掌握网易云音乐插件管理技巧
BetterNCM安装器完全指南:3分钟掌握网易云音乐插件管理技巧 【免费下载链接】BetterNCM-Installer 一键安装 Better 系软件 项目地址: https://gitcode.com/gh_mirrors/be/BetterNCM-Installer 你是否厌倦了网易云音乐客户端的功能限制?想要为你的…...
)
山东大学2022-2023学期实时绘制期末考试真题(回忆版)
山东大学2022年到2023年实时绘制期末考试 (一共9到小题,每题10分或12分,包含多个小问,上午考完下午回忆写的,大体就这些,复习时还是应该全面一点。) AABB包围盒构建过程;中间节点和叶…...

零成本全平台2D CAD解决方案:LibreCAD专业应用指南
零成本全平台2D CAD解决方案:LibreCAD专业应用指南 【免费下载链接】LibreCAD LibreCAD is a cross-platform 2D CAD program written in C17. It can read DXF/DWG files and can write DXF/PDF/SVG files. It supports point/line/circle/ellipse/parabola/spline…...

突破Cursor API限制:cursor-free-vip实现无限制Pro功能的技术解析
突破Cursor API限制:cursor-free-vip实现无限制Pro功能的技术解析 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reach…...
)
PyTorch 3.0静态图分布式训练全链路解析(含NCCL拓扑感知、Graph Partitioning与梯度同步优化)
第一章:PyTorch 3.0静态图分布式训练概览与演进脉络PyTorch 3.0标志着框架在可扩展性与编译优化方向的重大跃迁——其核心变化之一是将TorchDynamo Inductor后端深度整合为默认的静态图编译通道,并原生支持跨设备、跨节点的分布式静态图训练。这一演进并…...

到底要不要用AI写代码?别争了
其实我一直觉得,现在大家讨论 AI 写代码这件事,有点熟悉。因为以前我们也是这么过来的。刚开始写代码那会儿, 不会就打开 百度, 一行一行找答案,复制、试错、再改。一个分号错了能找半天, 中英文标点混了直…...
)
从ROS Bag到标定矩阵:Livox Mid-360多雷达数据预处理全流程详解(含CustomMsg转PCD脚本)
Livox Mid-360多雷达数据预处理实战:从原始数据到标定就绪的完整指南 在自动驾驶和机器人感知系统中,多激光雷达的协同工作已成为提升环境感知能力的标配方案。Livox Mid-360凭借其独特的非重复扫描模式和360水平视场,为复杂环境下的三维重建…...

单克隆抗体如何被制备并应用于疾病治疗?
一、什么是单克隆抗体?其与多克隆抗体有何区别?单克隆抗体(Monoclonal Antibody,mAb)是指由单一B淋巴细胞克隆所产生的高度均一、仅针对某一特定抗原表位进行识别的抗体。这类抗体具有高度特异性。与之相对的是多克隆抗…...

突破数据瓶颈:6大创新方法让时间序列模型性能提升150%
突破数据瓶颈:6大创新方法让时间序列模型性能提升150% 【免费下载链接】Time-Series-Library A Library for Advanced Deep Time Series Models for General Time Series Analysis. 项目地址: https://gitcode.com/GitHub_Trending/ti/Time-Series-Library 在…...