基于ETLCloud的自定义规则调用第三方jar包实现繁体中文转为简体中文
背景
前面曾体验过通过零代码、可视化、拖拉拽的方式快速完成了从 MySQL 到 ClickHouse 的数据迁移,但是在实际生产环境,我们在迁移到目标库之前还需要做一些过滤和转换工作;比如,在诗词数据迁移后,发现原来 MySQL 中的诗词数据都是繁体字,这就导致在直接迁移到 ClickHouse 做统计分析时生成的图表展示也是繁体中文的,对于不熟悉繁体中文的用户来说影响体验。
今天就借助 ETLCloud 提供的自定义规则能力,同时调用第三方 jar 包 opencc4j ,完成繁体中文到简体中文的转换;具体来说,将诗词数据库从 MySQL 迁移到 ClickHouse ,并在入库之前完成数据清洗转换工作,完成数据表中标题、作者与内容等字段的繁体中文到简体中文的转换。
数据集说明
MySQL 数据库中的库表 poetry 结构如下,数据量: 311828 。
CREATE TABLE `poetry` (`id` INT(11) UNSIGNED NOT NULL AUTO_INCREMENT,`title` VARCHAR(150) NOT NULL COLLATE 'utf8mb4_unicode_ci',`yunlv_rule` TEXT NOT NULL COLLATE 'utf8mb4_unicode_ci',`author_id` INT(10) UNSIGNED NOT NULL,`content` TEXT NOT NULL COLLATE 'utf8mb4_unicode_ci',`dynasty` VARCHAR(10) NOT NULL COMMENT '诗所属朝代(S-宋代, T-唐代)' COLLATE 'utf8mb4_unicode_ci',`author` VARCHAR(150) NOT NULL COLLATE 'utf8mb4_unicode_ci',PRIMARY KEY (`id`) USING BTREE
)
COLLATE='utf8mb4_unicode_ci'
ENGINE=InnoDB
AUTO_INCREMENT=311829;
ClickHouse 中的建表语句:
CREATE TABLE poetry.poetry (`id` Int32, `title` String, `yunlv_rule` String, `author_id` Int32, `content` String, `dynasty` String, `author` String) ENGINE = MergeTree() PRIMARY KEY id ORDER BY id SETTINGS index_granularity = 8192
工具选型
- ClickHouse数据库
- Docker部署ETLCloudV2.2
- ETLCloud的库表输入组件、数据清洗转换组件、钉钉消息组件
Note:这里选择的是社区版,采用 Docker 部署的方式轻量、快速启动: docker pull ccr.ccs.tencentyun.com/restcloud/restcloud-etl:V2.2 。
创建应用与流程
先创建应用(因为后面的规则是跟着应用走的),填写基本的应用配置信息。
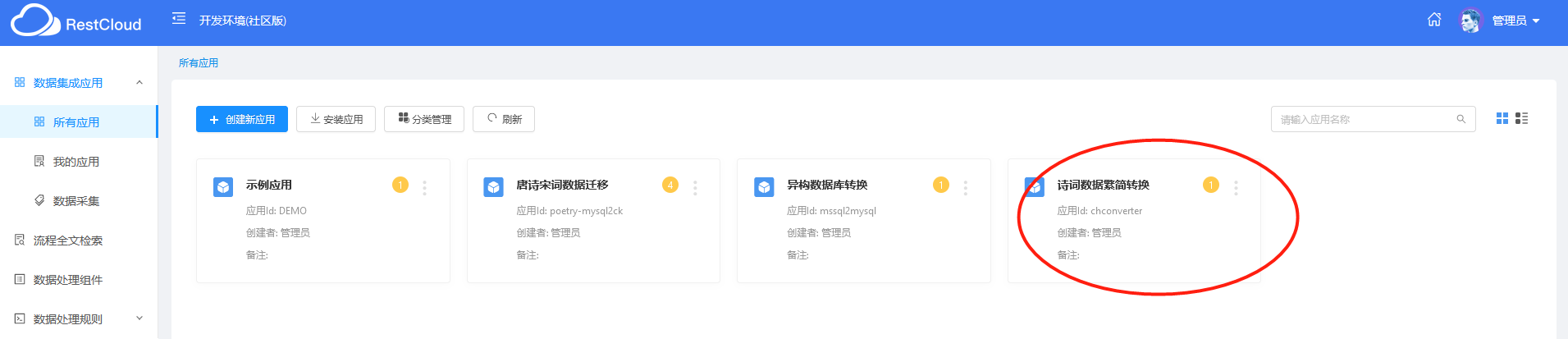
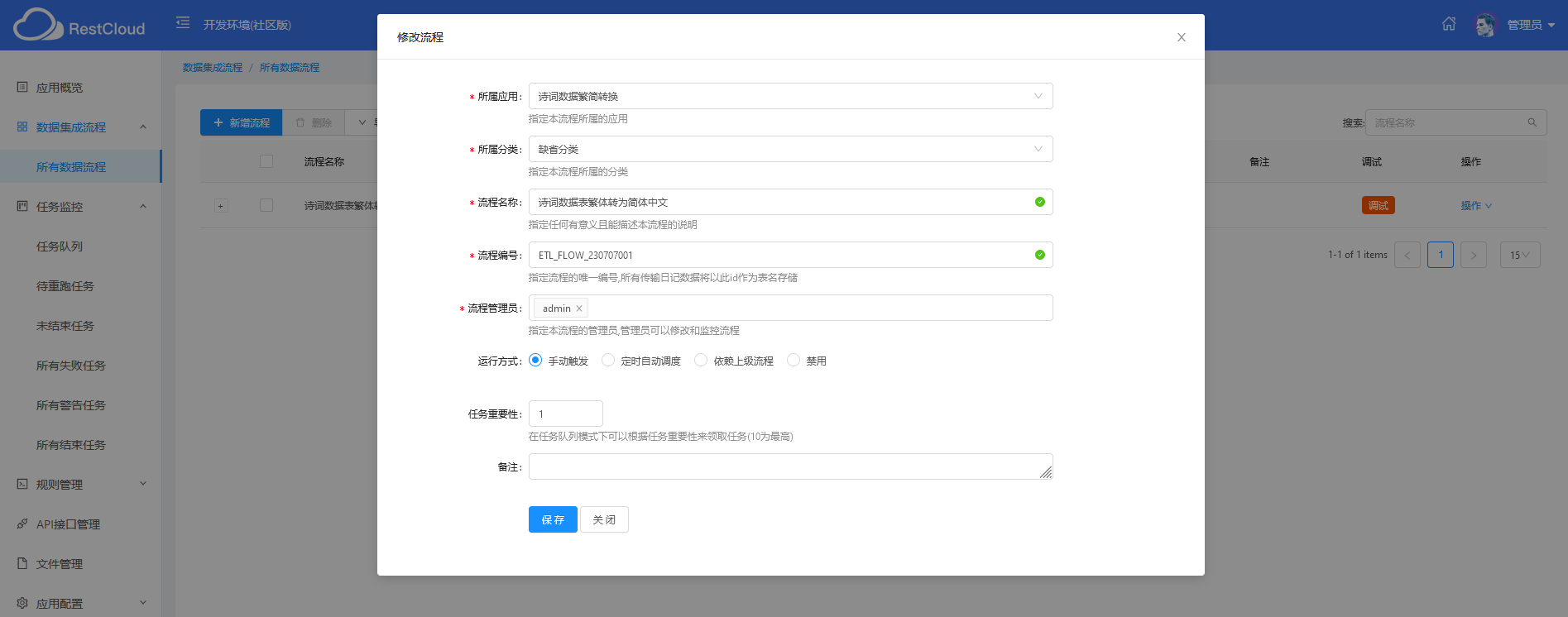
接着,创建数据流程,填写信息即可。
自定义规则
在真正开始数据迁移前,先准备好清洗转换规则,到迁移入库时直接配置选择定义好的规则即可。
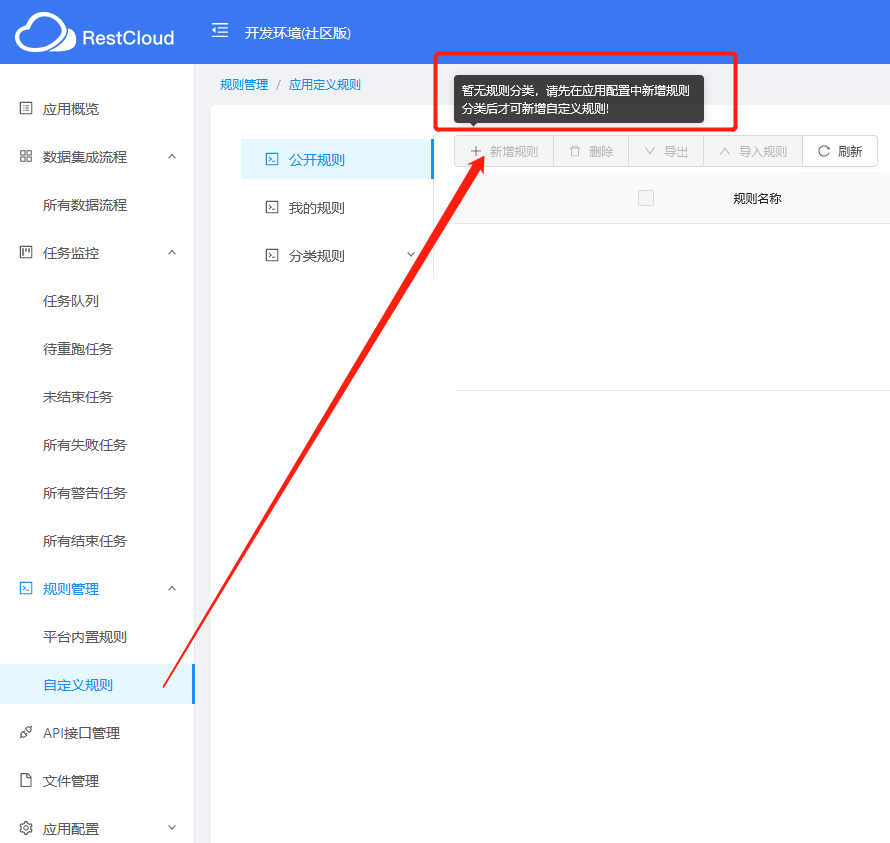
进入应用配置——>新增规则分类——>新增自定义规则
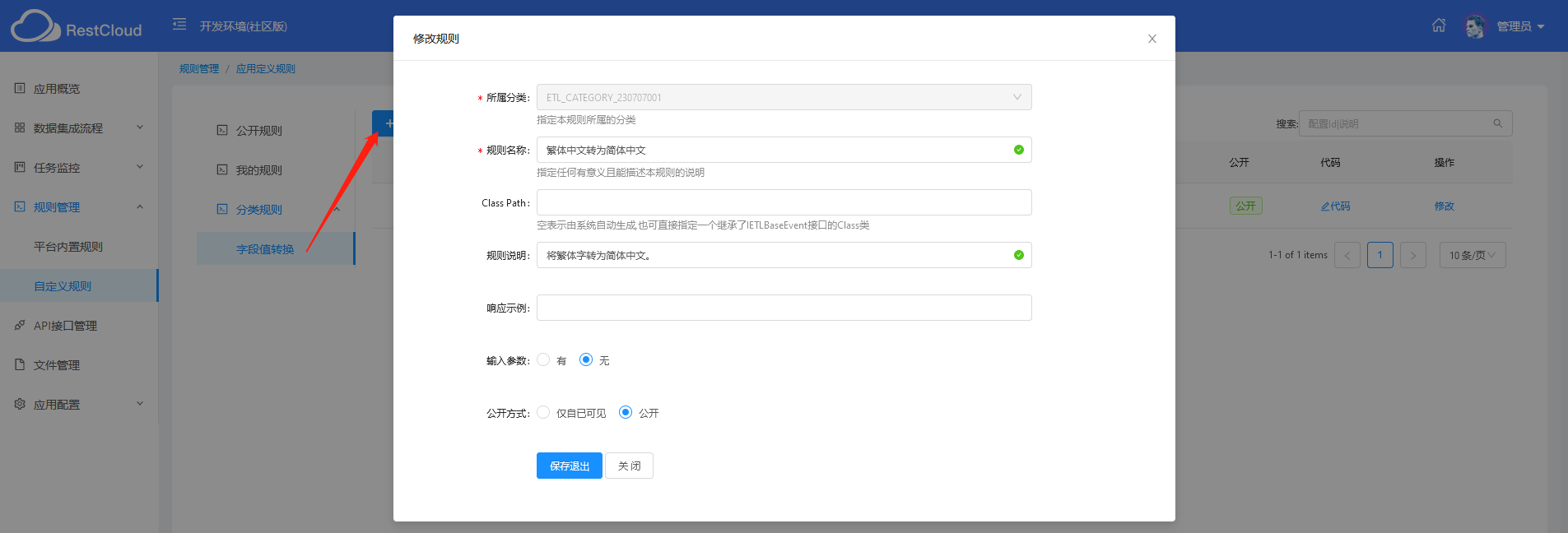
编写从繁体中文到简体中文的规则代码,其中,类名是自动生成的,先是引入了转换的工具类: ZhConverterUtil ,然后调用其静态方法即可;编写完毕后,点击“编译并保存”,正常的话会提示编译成功~。
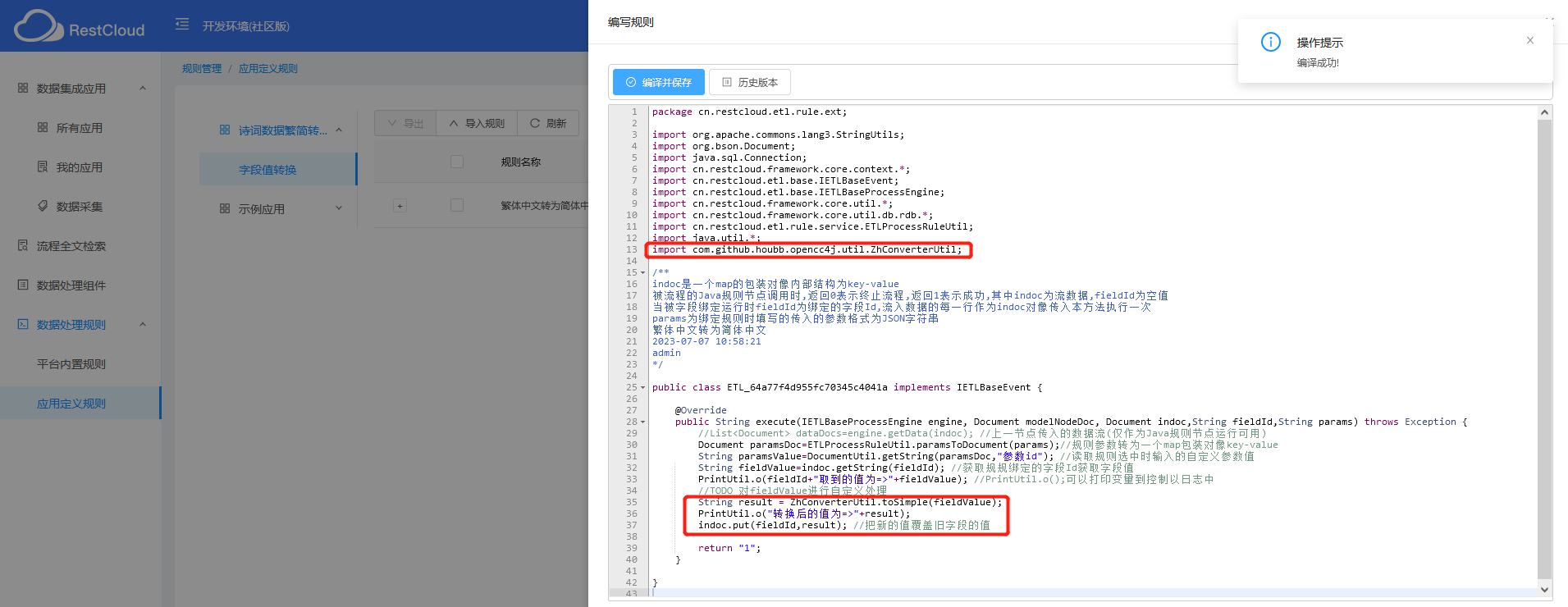
package cn.restcloud.etl.rule.ext;import org.apache.commons.lang3.StringUtils;
import org.bson.Document;
import java.sql.Connection;
import cn.restcloud.framework.core.context.*;
import cn.restcloud.etl.base.IETLBaseEvent;
import cn.restcloud.etl.base.IETLBaseProcessEngine;
import cn.restcloud.framework.core.util.*;
import cn.restcloud.framework.core.util.db.rdb.*;
import cn.restcloud.etl.rule.service.ETLProcessRuleUtil;
import java.util.*;
import com.github.houbb.opencc4j.util.ZhConverterUtil;/**
indoc是一个map的包装对像内部结构为key-value
被流程的Java规则节点调用时,返回0表示终止流程,返回1表示成功,其中indoc为流数据,fieldId为空值
当被字段绑定运行时fieldId为绑定的字段Id,流入数据的每一行作为indoc对像传入本方法执行一次
params为绑定规则时填写的传入的参数格式为JSON字符串
繁体中文转为简体中文
2023-07-07 10:58:21
admin
*/
public class ETL_64a77f4d955fc70345c4041a implements IETLBaseEvent {@Overridepublic String execute(IETLBaseProcessEngine engine, Document modelNodeDoc, Document indoc,String fieldId,String params) throws Exception {//List<Document> dataDocs=engine.getData(indoc); //上一节点传入的数据流(仅作为Java规则节点运行可用)Document paramsDoc=ETLProcessRuleUtil.paramsToDocument(params);//规则参数转为一个map包装对像key-valueString paramsValue=DocumentUtil.getString(paramsDoc,"参数id"); //读取规则选中时输入的自定义参数值String fieldValue=indoc.getString(fieldId); //获取规规绑定的字段Id获取字段值PrintUtil.o(fieldId+"取到的值为=>"+fieldValue); //PrintUtil.o();可以打印变量到控制以日志中//TODO 对fieldValue进行自定义处理String result = ZhConverterUtil.toSimple(fieldValue);PrintUtil.o("转换后的值为=>"+result); indoc.put(fieldId,result); //把新的值覆盖旧字段的值return "1";}
}
Note:这里需要注意的是,我们用到了第三方的 Jar 包 opencc4j 来完成这一工作,那么 ETLCloud 如何知道要怎样调用自定义的工具类的方法呢?这就需要我们将第三方的 jar 放到 ETLCloud 的部署目录下: /usr/tomcat/webapps/ROOT/WEB-INF/lib 。
[root@etl ~]# docker cp /opt/opencc4j-1.8.1.jar de63b29c71d0:/usr/tomcat/webapps/ROOT/WEB-INF/libSuccessfully copied 513kB to de63b29c71d0:/usr/tomcat/webapps/ROOT/WEB-INF/lib
然后点击版本更新,平台提示以下内容:
平台配置(Successfully registered (0) java bean, update (2) java bean information!, API升级结果: 从Jar文件中更新或注册(0)个服务、(0)个输入参数、(0)个输出编码! ), ETL配置(Successfully registered (0) java bean, update (0) java bean information!, API升级结果: 从Jar文件中更新或注册(2)个服务、(0)个输入参数、(0)个输出编码! )
迁移实践
接下来通过可视化的配置与操作完成从 MySQL 到 ClickHouse 的诗词数据快速转换与迁移操作。
数据源配置
- 配置Source:MySQL
选择 MySQL ,填写IP: 端口以及用户密码信息。
测试连接成功~
- 配置Sink:ClickHouse
数据源选择之前文章迁移的 ClickHouse 诗词数据库。
可视化配置流程
创建好流程后,可以通过点击“流程设计”按钮,进入流程可视化的配置页面。
- 库表输入:MySQL
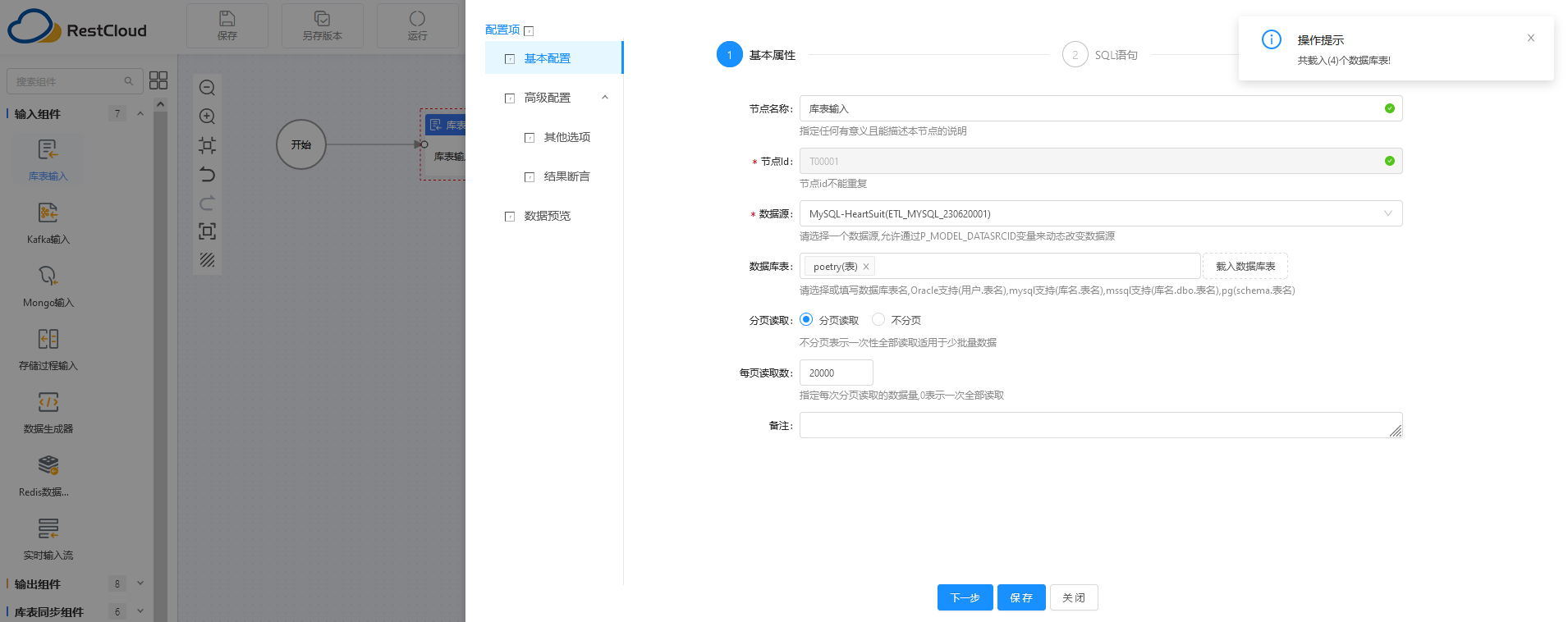
在左侧的输入组件中,选择“库表输入”,拖至中央的流程绘制区,双击进入配置阶段。
第一步:选择我们配置好的 MySQL 数据源,可以载入 MySQL 中已有的表。
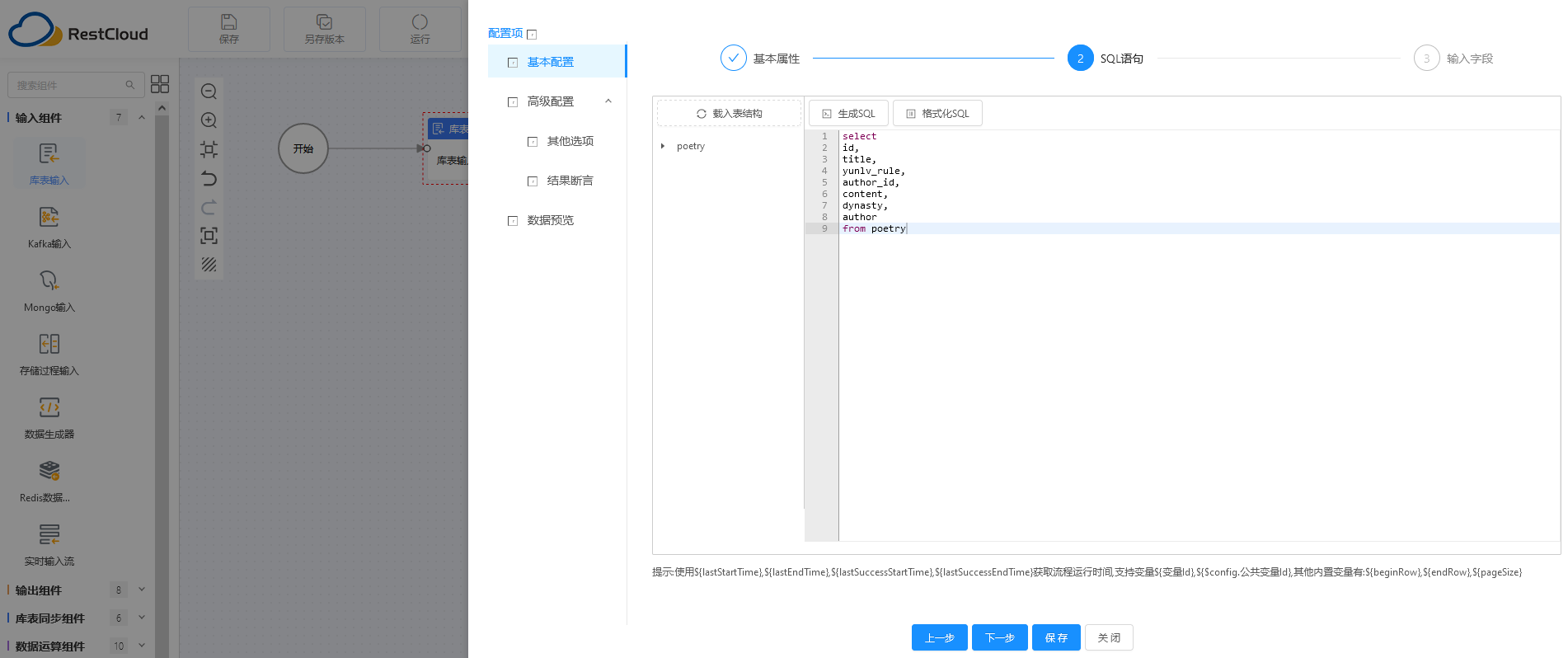
第二步:可以根据选择的表,生成 SQL 语句。
第三步:可从表中读取到各个字段的定义,支持添加、删除字段。
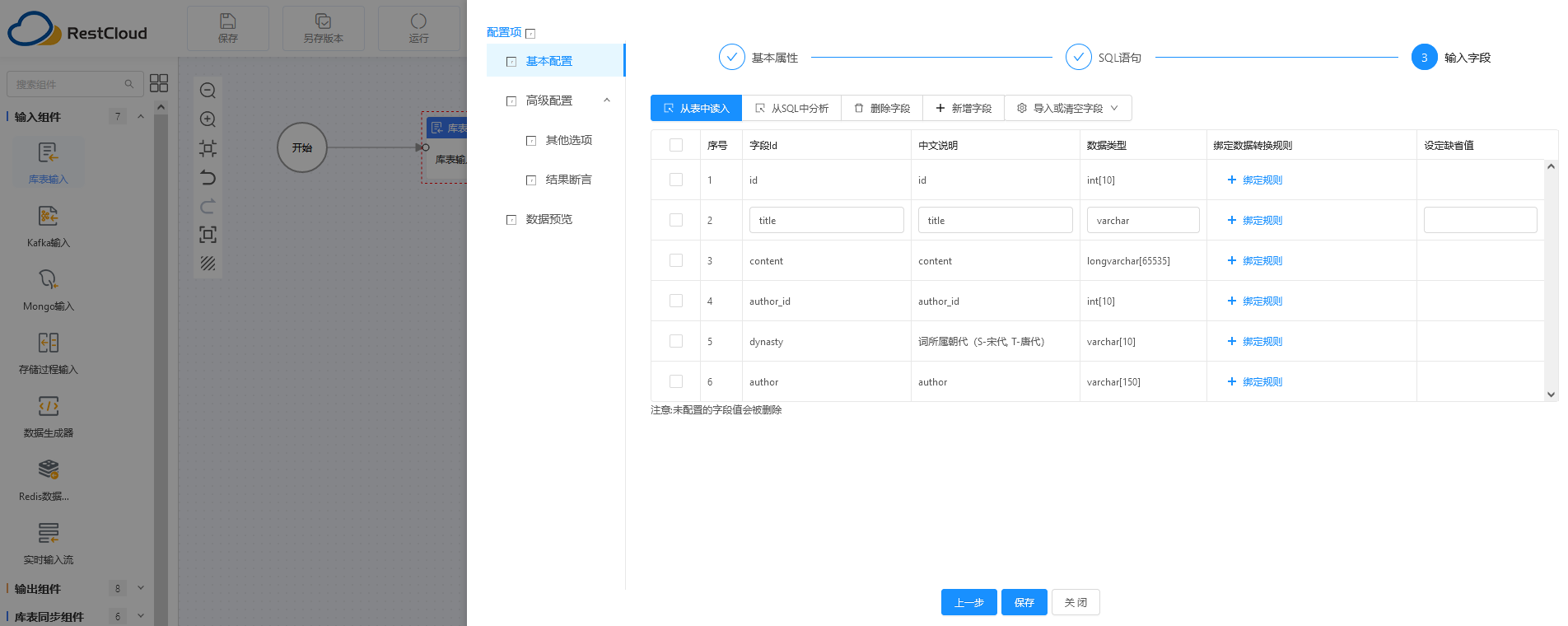
第四步:根据 SQL 语句自动进行了数据预览,这样的一个检查操作,保证了后续操作的正常执行。
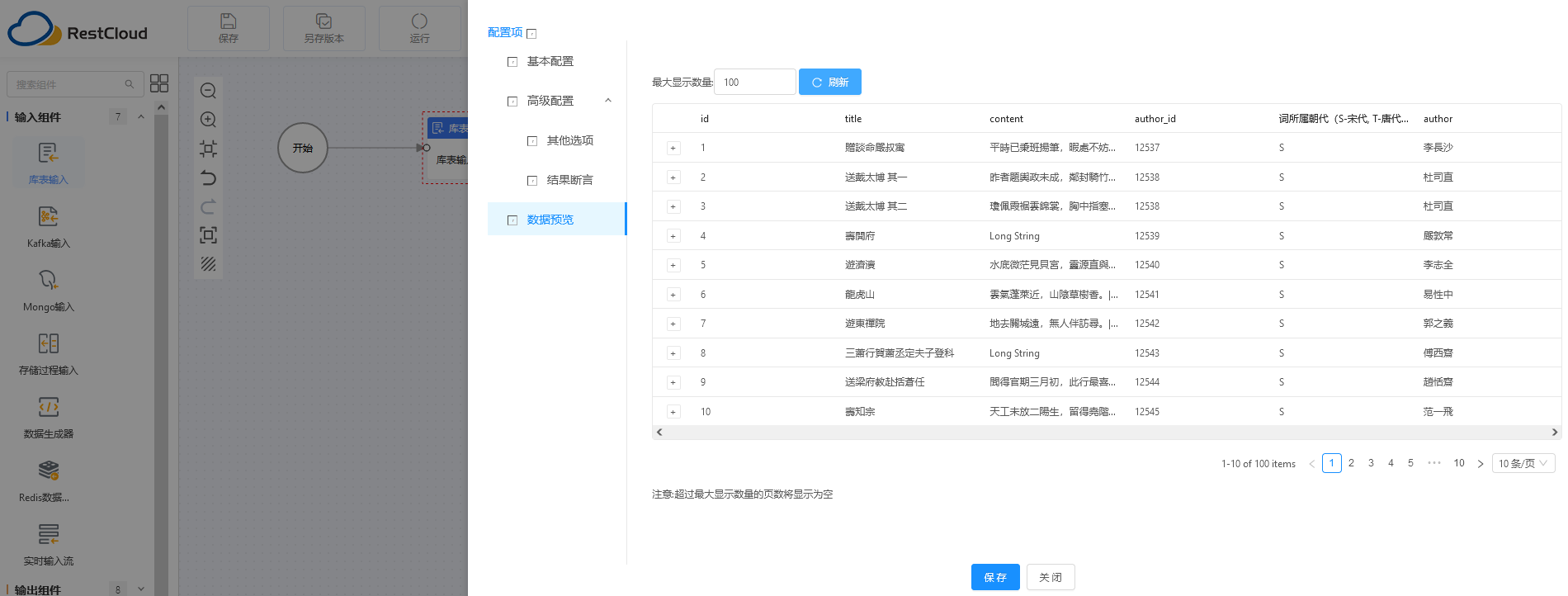
- 数据清洗转换:opencc4j实现繁体中文转简体中文
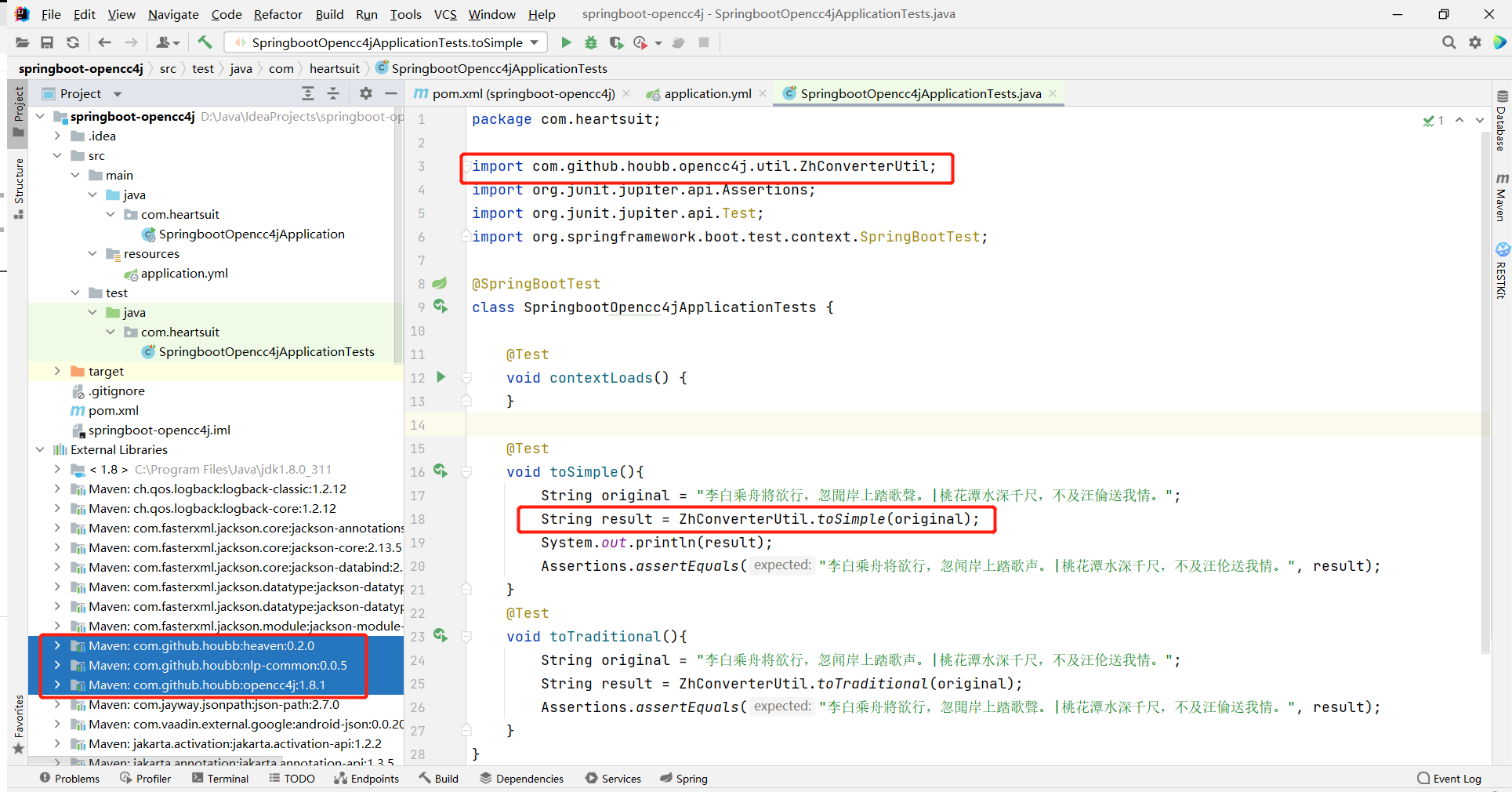
在对字段配置规则前,先熟悉下 opencc4j 在后端开发中的用法。
- 引入依赖
<!-- Opencc4j 支持中文繁简体转换 --><dependency><groupId>com.github.houbb</groupId><artifactId>opencc4j</artifactId><version>1.8.1</version></dependency>
- 编码转换
import com.github.houbb.opencc4j.util.ZhConverterUtil;
import org.junit.jupiter.api.Assertions;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
@SpringBootTest
class SpringbootOpencc4jApplicationTests {// 繁体中文转简体中文@Testvoid toSimple(){String original = "李白乘舟將欲行,忽聞岸上踏歌聲。|桃花潭水深千尺,不及汪倫送我情。";String result = ZhConverterUtil.toSimple(original);System.out.println(result);Assertions.assertEquals("李白乘舟将欲行,忽闻岸上踏歌声。|桃花潭水深千尺,不及汪伦送我情。", result);}// 簡體中文轉繁體中文@Testvoid toTraditional(){String original = "李白乘舟将欲行,忽闻岸上踏歌声。|桃花潭水深千尺,不及汪伦送我情。";String result = ZhConverterUtil.toTraditional(original);Assertions.assertEquals("李白乘舟將欲行,忽聞岸上踏歌聲。|桃花潭水深千尺,不及汪倫送我情。", result);}
}
在左侧的数据转换组件中,选择“数据清洗转换”,拖至中央的流程绘制区,双击进入配置阶段。
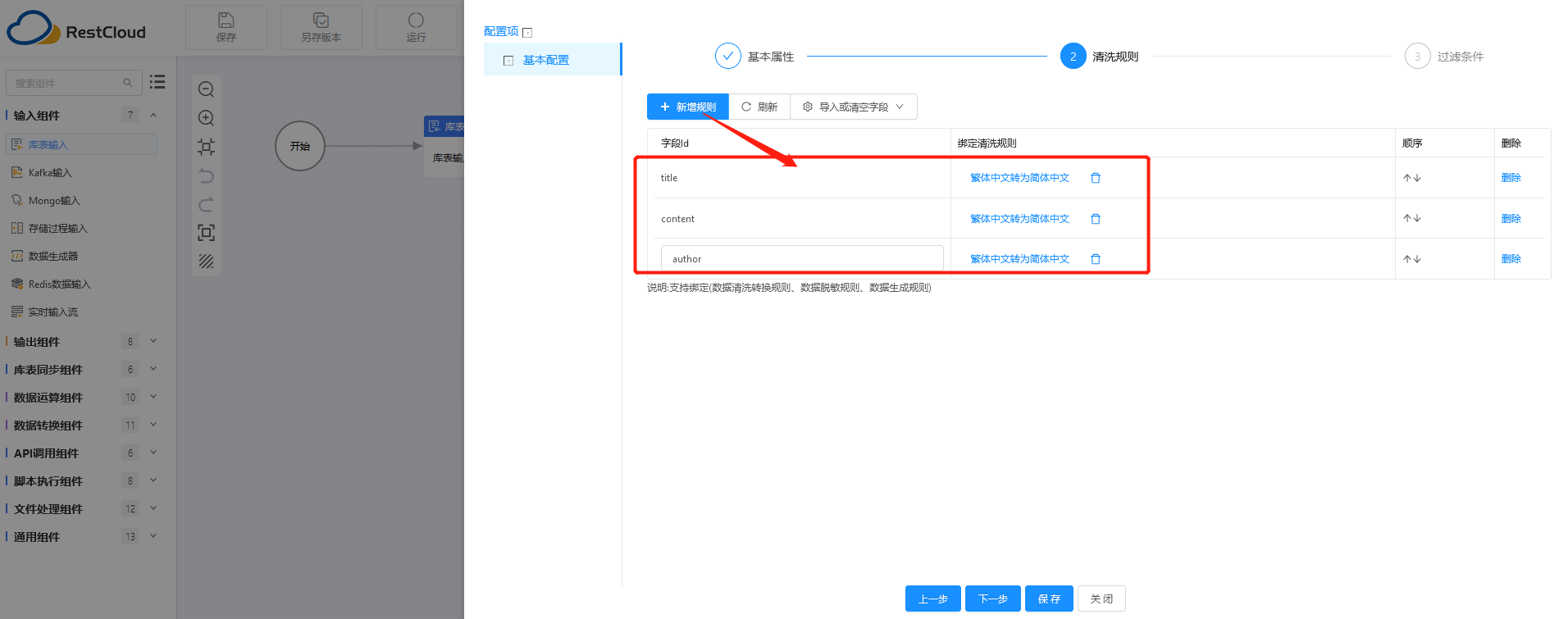
因为源数据表中的 title 、 content 以及 author 这三个字段值是繁体中文,所以针对这三个字段设置自定义的规则:繁体中文转为简体中文,下一步点击保存对所有数据记录进行转换即可。
- 库表输出:ClickHouse
在左侧的输出组件中,选择“库表输出”,拖至中央的流程绘制区,双击进入配置阶段。
第一步:选择我们配置好的ClickHouse数据源。
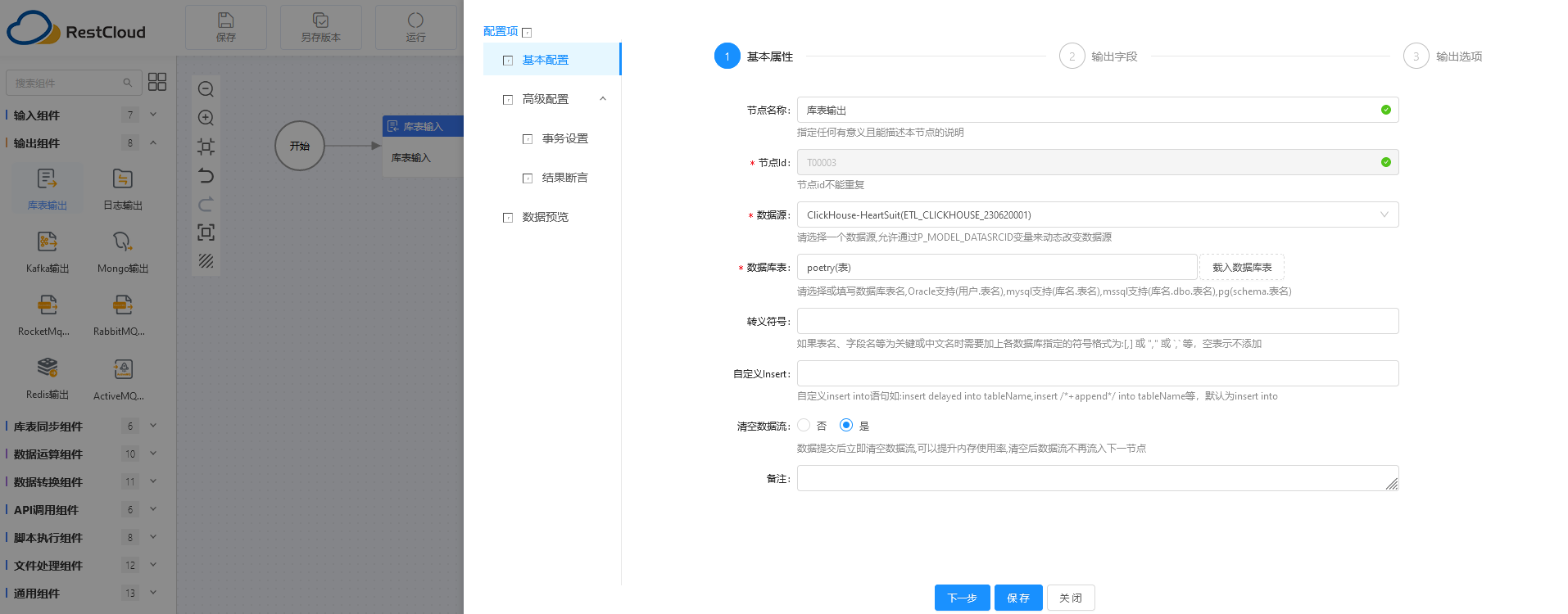
第二步:可从表中读取到各个字段的定义,支持添加、删除字段、绑定规则。
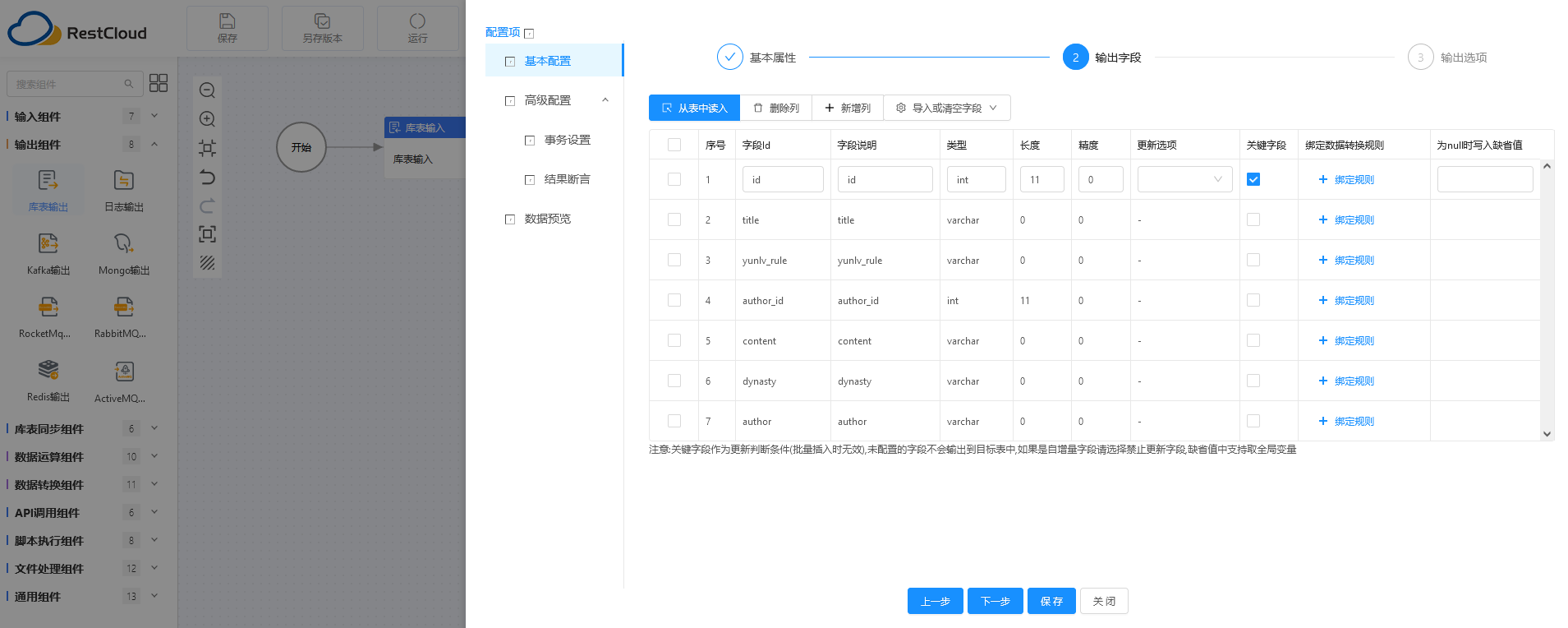
最后通过 流程线 将开始、库表输入、数据清洗转换、库表输出、结束组件分别连接起来,数据通过自定义的规则转换与迁移的可视化配置便告完成,Done~

运行流程
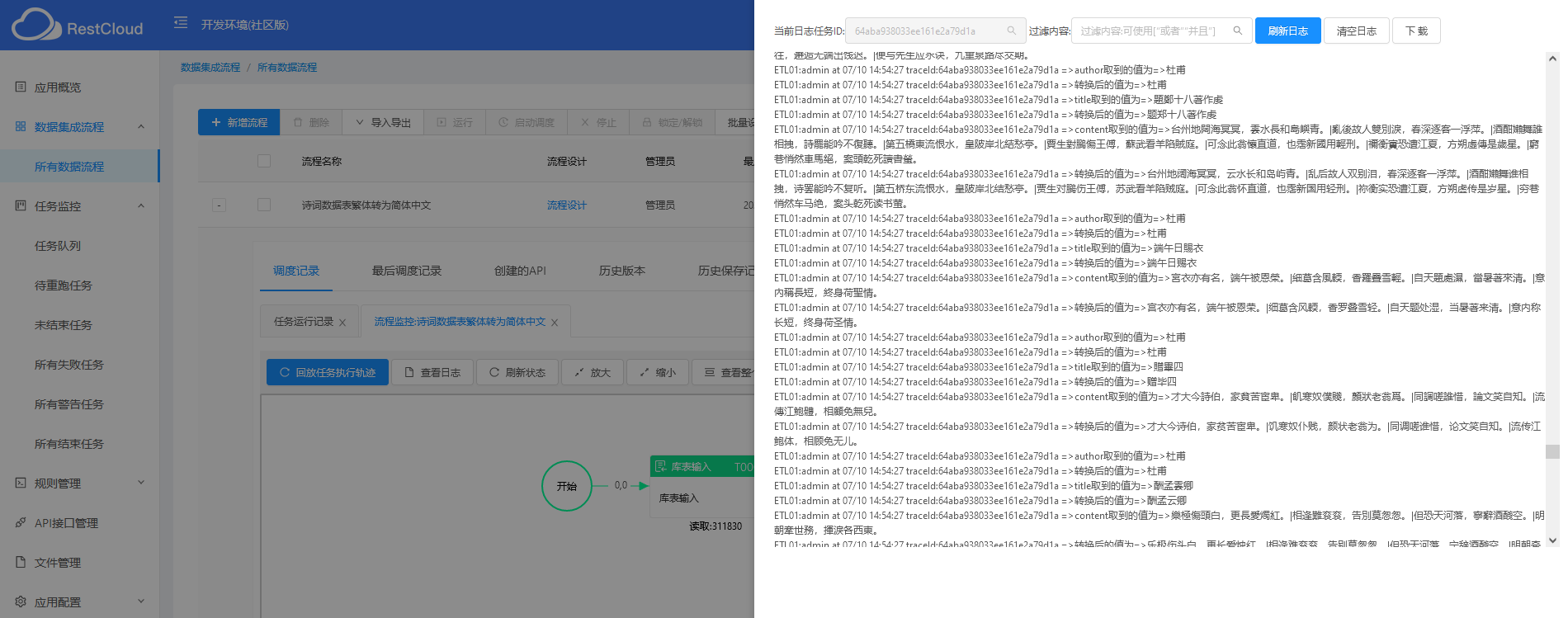
保存流程,运行流程;之后可查看对应的流程日志与转换日志,并可视化监控迁移进度。
问题记录
- 数据转换过程报错
问题描述: 在 ETLCloud 的日志中发现错误, Caused by: java.lang.ClassNotFoundException: com.github.houbb.heaven.support.instance.impl.Instances
问题分析:在 SpringBoot 结合 IDEA 与 Maven 中开发时,我们仅仅引入了一个依赖: opencc4j ,但是实际上观察外部依赖库时发现还有另外两个依赖: heaven 与 nlp-common 。
解决方法:将 opencc4j-1.8.1.jar 、 heaven-0.2.0.jar 与 nlp-common-0.0.5.jar 这个三个 jar 包都上传到 ETLCloud 的 /usr/tomcat/webapps/ROOT/WEB-INF/lib 目录下,重新更新 ETLCloud 配置、重启 ETLCloud 服务。
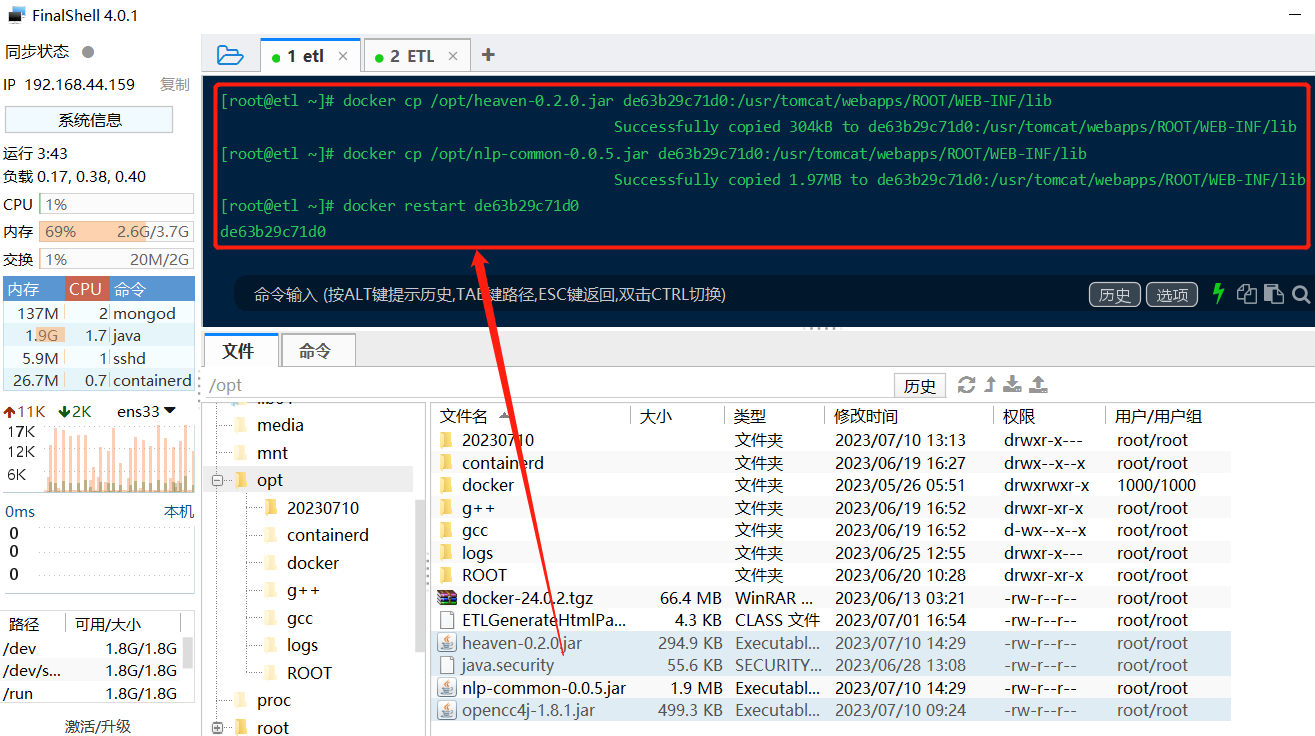
[root@etl ~]# docker cp /opt/heaven-0.2.0.jar de63b29c71d0:/usr/tomcat/webapps/ROOT/WEB-INF/libSuccessfully copied 304kB to de63b29c71d0:/usr/tomcat/webapps/ROOT/WEB-INF/lib
[root@etl ~]# docker cp /opt/nlp-common-0.0.5.jar de63b29c71d0:/usr/tomcat/webapps/ROOT/WEB-INF/libSuccessfully copied 1.97MB to de63b29c71d0:/usr/tomcat/webapps/ROOT/WEB-INF/lib
Note: Jar 包可以从阿里云镜像仓库查找下载: https://developer.aliyun.com/mvn/search ,或者到本地开发环境的的 .m2\repository\com\github\houbb 目录下查找。
总结
以上介绍了如何通过 ETLCloud 强大的自定义规则功能完成对数据的清洗转换功能,实现了表字段值从繁体中文到简体中文的转换,以下两点要注意:
- 自定义规则是附属于某个流程的;
- 第三方的
Jar包依赖在数量上要完整。
Reference
- ETLCloud官方文档
- ClickHouse官方文档
- opencc4j官方文档
If you have any questions or any bugs are found, please feel free to contact me.
Your comments and suggestions are welcome!
相关文章:
基于ETLCloud的自定义规则调用第三方jar包实现繁体中文转为简体中文
背景 前面曾体验过通过零代码、可视化、拖拉拽的方式快速完成了从 MySQL 到 ClickHouse 的数据迁移,但是在实际生产环境,我们在迁移到目标库之前还需要做一些过滤和转换工作;比如,在诗词数据迁移后,发现原来 MySQL 中…...
TDesign在按钮上加入图标组件
在实际开发中 我们经常会遇到例如 添加或者查询 我们需要在按钮上加入图标的操作 TDesign自然也有预备这样的操作 首先我们打开文档看到图标 例如 我们先用某些图标 就可以点开下面的代码 可以看到 我们的图标大部分都是直接用tdesign-icons-vue 导入他的组件就可以了 而我…...

Linux 终端命令行 产品介绍
Linux命令手册内置570多个Linux 命令,内容包含 Linux 命令手册。 【软件功能】: 文件传输 bye、ftp、ftpcount、ftpshut、ftpwho、ncftp、tftp、uucico、uucp、uupick、uuto、scp备份压缩 ar、bunzip2、bzip2、bzip2recover、compress、cpio、dump、gun…...
计算机毕设 基于深度学习的植物识别算法 - cnn opencv python
文章目录 0 前言1 课题背景2 具体实现3 数据收集和处理3 MobileNetV2网络4 损失函数softmax 交叉熵4.1 softmax函数4.2 交叉熵损失函数 5 优化器SGD6 最后 0 前言 🔥 这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点&a…...
【STM32】学习笔记-江科大
【STM32】学习笔记-江科大 1、STM32F103C8T6的GPIO口输出 2、GPIO口输出 GPIO(General Purpose Input Output)通用输入输出口可配置为8种输入输出模式引脚电平:0V~3.3V,部分引脚可容忍5V输出模式下可控制端口输出高低电平&#…...
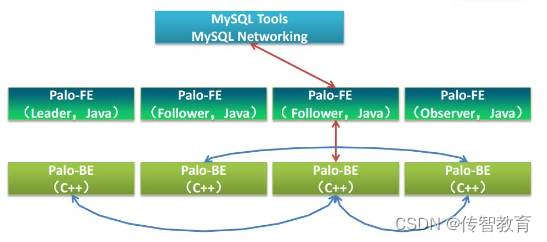
Doris架构中包含哪些技术?
Doris主要整合了Google Mesa(数据模型),Apache Impala(MPP Query Engine)和Apache ORCFile (存储格式,编码和压缩)的技术。 为什么要将这三种技术整合? Mesa可以满足我们许多存储需求的需求,但是Mesa本身不提供SQL查询引擎。 Impala是一个…...
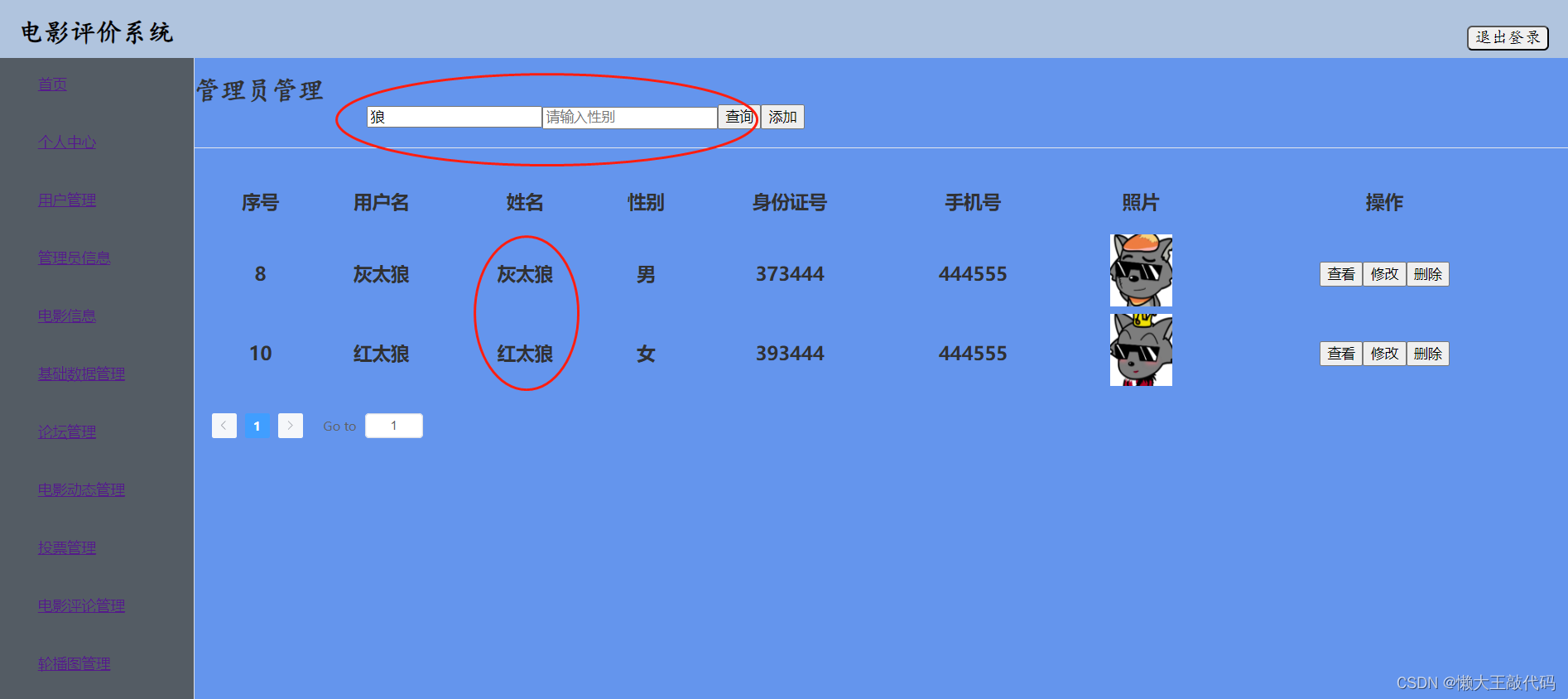
《vue3实战》通过indexOf方法实现电影评价系统的模糊查询功能
目录 前言 一、indexOf是什么?indexOf有什么作用? 含义: 作用: 二、功能实现 这段是查询过程中过滤筛选功能的代码部分: 分析: 这段是查询用户和性别功能的代码部分: 分析: 三、最终效…...

java对时间序列每x秒进行分组
问题:将一个时间序列每5秒分一组,返回嵌套的list; 原理:int除int会得到一个int(也就是损失精度) 输入:排序后的list,每几秒分组值 private static List<List<Long>> get…...

八月更新 | CI 构建计划触发机制升级、制品扫描 SBOM 分析功能上线!
点击链接了解详情 这个八月,腾讯云 CODING DevOps 对持续集成、制品管理、项目协同、平台权限等多个产品模块进行了升级改进,为用户提供更灵活便捷的使用体验。以下是 CODING 新功能速递,快来看看是否有您期待已久的功能特性: 01…...

Spring核心配置步骤-完全基于XML的配置
Spring框架的核心配置涉及多个方面,包括依赖注入(DI)、面向切面编程(AOP)等。以下是一般情况下配置Spring应用程序的核心步骤: 1. **引入Spring依赖:** 在项目的构建工具(如Maven、…...

宏基官网下载的驱动怎么安装(宏基笔记本如何安装系统)
本文为大家介绍宏基官网下载的驱动怎么安装宏基笔记本驱动(宏基笔记本如何安装系统),下面和小编一起看看详细内容吧。 宏碁笔记本怎么一键更新驱动 1. 单击“开始”,然后选择“所有程序”。 2. 单击Acer,然后单击Acer eRecovery Management。…...

基于AVR128单片机抢答器proteus仿真设计
一、系统方案 二、硬件设计 原理图如下: 三、单片机软件设计 1、首先是系统初始化 void timer0_init() //定时器初始化 { TCCR00x07; //普通模式,OC0不输出,1024分频 TCNT0f_count; //初值,定时为10ms TIFR0x01; //清中断标志…...

openGauss学习笔记-54 openGauss 高级特性-MOT
文章目录 openGauss学习笔记-54 openGauss 高级特性-MOT54.1 MOT特性及价值54.2 MOT关键技术54.3 MOT应用场景54.4 不支持的数据类型54.5 使用MOT54.6 将磁盘表转换为MOT openGauss学习笔记-54 openGauss 高级特性-MOT openGauss引入了MOT(Memory-Optimized Table&…...

InsCode AI 创作助手
RESTful API是一种架构风格和设计原则,用于构建Web服务和应用程序。它基于HTTP协议,以资源为中心,对资源进行各种操作。RESTful API的主要特点包括: 使用HTTP协议进行传输和通信;操作和状态均以资源为中心;…...

java对时间序列根据阈值进行连续性分片
问题描述:我需要对一个连续的时间戳list进行分片,分片规则是下一个数据比当前数据要大于某一个阈值则进行分片; 解决方式: 1、输入的有顺序的list ,和需要进行分片的阈值 2、调用方法,填入该排序的list和阈…...

Pillow:Python的图像处理库(安装与使用教程)
在Python中,Pillow库是一个非常强大的图像处理库。它提供了广泛的图像处理功能,让我们可以轻松地操作图像,实现图像的转换、裁剪、缩放、旋转等操作。此外,Pillow还支持多种图像格式的读取和保存,包括JPEG、PNG、BMP、…...
自然语言处理-NLP
目录 自然语言处理-NLP 致命密码:一场关于语言的较量 自然语言处理的发展历程 兴起时期 符号主义时期 连接主义时期 深度学习时期 自然语言处理技术面临的挑战 语言学角度 同义词问题 情感倾向问题 歧义性问题 对话/篇章等长文本处理问题 探索自然语言…...

柠檬水找零【贪心算法-】
柠檬水找零 在柠檬水摊上,每一杯柠檬水的售价为 5 美元。顾客排队购买你的产品,(按账单 bills 支付的顺序)一次购买一杯。 每位顾客只买一杯柠檬水,然后向你付 5 美元、10 美元或 20 美元。你必须给每个顾客正确找零&…...

el-date-picker设置开始时间小于结束时间
一. date-picker Template <template><el-form-item label"开始时间" prop"startDate"><el-date-pickerv-model.trim"form.startDate"type"datetime"placeholder"请选择日期"value-format"yyyy-MM-dd …...
—— 设备与模块(基于Linux 2.6内核))
Linux内核学习(十三)—— 设备与模块(基于Linux 2.6内核)
目录 一、设备类型 二、模块 构建模块 安装模块 载入模块 一、设备类型 在 Linux 以及 Unix 系统中,设备被分为以下三种类型: 块设备(blkdev):以块为寻址单位,块的大小随设备的不同而变化࿱…...
)
晶振参数深度解读与替代选型实战(55.2MHz 工业级无源晶振案例)
前言作为嵌入式 / 硬件 FAE,日常工作中晶振的参数解读、客户需求替代是高频场景。最近遇到一个典型的工业级宽温晶振客户需求,参数里藏着很多新手容易踩的坑,比如 “负频率” 的误解、负载电容不匹配、宽温范围忽略等问题。本文以客户的55.2M…...

告别Mac与Windows传文件烦恼:一招教你将APFS格式的移动硬盘永久改成ExFAT通用格式
跨平台文件共享终极方案:APFS与ExFAT格式深度解析与转换指南 当你在Mac上插入新买的移动硬盘准备备份重要设计稿时,系统默认将其格式化为APFS;三天后客户紧急需要修改方案,你带着硬盘赶到Windows电脑前——却发现根本无法读取内容…...

Perplexity文化新闻搜索效率翻倍:从冷启动到高信噪比输出的7个被低估的底层参数配置
更多请点击: https://codechina.net 第一章:Perplexity文化新闻搜索效率翻倍:从冷启动到高信噪比输出的7个被低估的底层参数配置 Perplexity 的文化新闻检索能力并非仅由模型规模或训练数据量决定,其真实效能高度依赖于七个常被忽…...

极化激元量子流体:从Bogoliubov色散到引力模拟的精密探测
1. 项目概述:当光“流动”起来我们通常认为光是一种波,或者是一束没有质量的粒子。但在特定的物理舞台上,光的行为可以变得非常“不寻常”——它能够像水一样流动,甚至像超流体那样无摩擦地运动。这就是“光的量子流体”这一前沿领…...
)
【ACM出版、往届已稳定EI检索】第二届大数据与智慧医学国际学术会议(BDIMed 2026)
第二届大数据与智慧医学国际学术会议(BDIMed 2026)将于2026年6月26-28日在中国重庆市举行。 随着科技与医疗的交汇不断演变,BDIMed 2026将为与会者提供一个知识分享、挑战讨论及促进合作的平台。我们荣幸地邀请您参加此次盛会,会…...
)
告别手动配置!用Matlab+LUA脚本自动化DCA1000雷达数据采集(附1843配置实例)
雷达数据采集自动化:Matlab与LUA脚本的高效协作方案 在毫米波雷达研发领域,数据采集是每个工程师日常工作中不可或缺的环节。传统的手动配置方式不仅耗时耗力,还容易因人为操作失误导致数据质量不稳定。本文将介绍如何通过Matlab与LUA脚本的协…...

抢先李飞飞!世界模型能多人联机玩FPS游戏了
Jay 发自 凹非寺量子位 | 公众号 QbitAI我被AI杀了?有视频为证,我被一个不知道是人还是AI的东西,一枪崩了。还是在一个世界模型创造的世界里。嗯,就是这个画质糊成马赛克的网页版FPS。背后没有游戏引擎,没有物理规则&a…...

如何将 Infinix 手机中的联系人传输到 iPhone
如果您刚从Infinix Android手机换到新款 iPhone ,首先可能会担心如何安全快捷地将联系人从 Infinix 转移到 iPhone。由于这两个系统使用不同的数据生态系统,许多用户不确定哪种方法最有效。幸运的是,有几种可靠的方法可以转移您的通讯录&…...

Linux ISP驱动全流程解析:从V4L2框架到图像处理管线
1. 项目概述:从用户按下快门到ISP驱动当我们用手机或相机拍照时,屏幕上那个“咔嚓”的动画和瞬间生成的图片,背后是一场从物理世界到数字世界的精密“接力赛”。这场接力赛的第一棒是镜头和传感器,它们负责捕捉光线。但传感器输出…...

2026实测:专业降AI率软件选这款就对了
2026 年降 AIGC 工具已经从“机械式语义调整”进化为多维度智能优化系统,核心评估指标涵盖 AI 痕迹去除精准度、学术表达一致性、格式结构完整性、长段落逻辑稳定性、内容改写适配性以及高校检测合规性。本次测评覆盖 5 款主流工具,测试场景包括中英文论…...