计算机毕设 基于深度学习的植物识别算法 - cnn opencv python
文章目录
- 0 前言
- 1 课题背景
- 2 具体实现
- 3 数据收集和处理
- 3 MobileNetV2网络
- 4 损失函数softmax 交叉熵
- 4.1 softmax函数
- 4.2 交叉熵损失函数
- 5 优化器SGD
- 6 最后
0 前言
🔥 这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到毕业答辩的要求,这两年不断有学弟学妹告诉学长自己做的项目系统达不到老师的要求。
为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目,今天要分享的是
🚩 **基于深度学习的植物识别算法 **
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:4分
- 创新点:4分
1 课题背景
植物在地球上是一种非常广泛的生命形式,直接关系到人类的生活环境,目前,植物识别主要依靠相关行业从业人员及有经验专家实践经验,工作量大、效率低。近年来,随着社会科技及经济发展越来越快,计算机硬件进一步更新,性能也日渐提高,数字图像采集设备应用广泛,设备存储空间不断增大,这样大量植物信息可被数字化。同时,基于视频的目标检测在模式识别、机器学习等领域得到快速发展,进而基于图像集分类方法研究得到发展。
本项目基于深度学习实现图像植物识别。
2 具体实现


3 数据收集和处理
数据是深度学习的基石
数据的主要来源有: 百度图片, 必应图片, 新浪微博, 百度贴吧, 新浪博客和一些专业的植物网站等
爬虫爬取的图像的质量参差不齐, 标签可能有误, 且存在重复文件, 因此必须清洗。清洗方法包括自动化清洗, 半自动化清洗和手工清洗。
自动化清洗包括:
- 滤除小尺寸图像.
- 滤除宽高比很大或很小的图像.
- 滤除灰度图像.
- 图像去重: 根据图像感知哈希.
半自动化清洗包括:
- 图像级别的清洗: 利用预先训练的植物/非植物图像分类器对图像文件进行打分, 非植物图像应该有较低的得分; 利用前一阶段的植物分类器对图像文件 (每个文件都有一个预标类别) 进行预测, 取预标类别的概率值为得分, 不属于原预标类别的图像应该有较低的得分. 可以设置阈值, 滤除很低得分的文件; 另外利用得分对图像文件进行重命名, 并在资源管理器选择按文件名排序, 以便于后续手工清洗掉非植物图像和不是预标类别的图像.
- 类级别的清洗
手工清洗: 人工判断文件夹下图像是否属于文件夹名所标称的物种, 这需要相关的植物学专业知识, 是最耗时且枯燥的环节, 但也凭此认识了不少的植物.
3 MobileNetV2网络
简介
MobileNet网络是Google最近提出的一种小巧而高效的CNN模型,其在accuracy和latency之间做了折中。
主要改进点
相对于MobileNetV1,MobileNetV2 主要改进点:
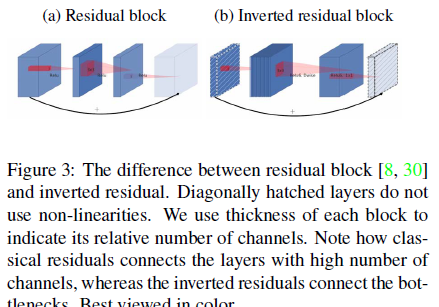
- 引入倒残差结构,先升维再降维,增强梯度的传播,显著减少推理期间所需的内存占用(Inverted Residuals)
- 去掉 Narrow layer(low dimension or depth) 后的 ReLU,保留特征多样性,增强网络的表达能力(Linear Bottlenecks)
- 网络为全卷积,使得模型可以适应不同尺寸的图像;使用 RELU6(最高输出为 6)激活函数,使得模型在低精度计算下具有更强的鲁棒性
- MobileNetV2 Inverted residual block 如下所示,若需要下采样,可在 DW 时采用步长为 2 的卷积
- 小网络使用小的扩张系数(expansion factor),大网络使用大一点的扩张系数(expansion factor),推荐是5~10,论文中 t = 6 t = 6t=6
倒残差结构(Inverted residual block)
ResNet的Bottleneck结构是降维->卷积->升维,是两边细中间粗
而MobileNetV2是先升维(6倍)-> 卷积 -> 降维,是沙漏形。
 区别于MobileNetV1, MobileNetV2的卷积结构如下:
区别于MobileNetV1, MobileNetV2的卷积结构如下:
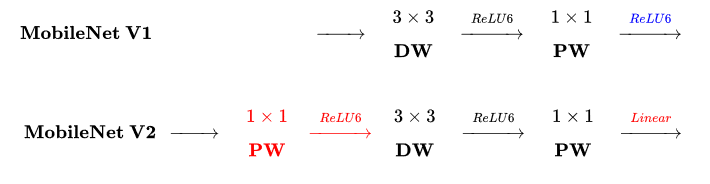
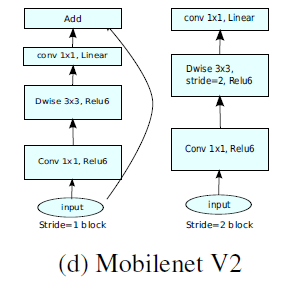
因为DW卷积不改变通道数,所以如果上一层的通道数很低时,DW只能在低维空间提取特征,效果不好。所以V2版本在DW前面加了一层PW用来升维。
同时V2去除了第二个PW的激活函数改用线性激活,因为激活函数在高维空间能够有效地增加非线性,但在低维空间时会破坏特征。由于第二个PW主要的功能是降维,所以不宜再加ReLU6。
tensorflow相关实现代码
import tensorflow as tf
import numpy as np
from tensorflow.keras import layers, Sequential, Modelclass ConvBNReLU(layers.Layer):def __init__(self, out_channel, kernel_size=3, strides=1, **kwargs):super(ConvBNReLU, self).__init__(**kwargs)self.conv = layers.Conv2D(filters=out_channel, kernel_size=kernel_size, strides=strides, padding='SAME', use_bias=False,name='Conv2d')self.bn = layers.BatchNormalization(momentum=0.9, epsilon=1e-5, name='BatchNorm')self.activation = layers.ReLU(max_value=6.0) # ReLU6def call(self, inputs, training=False, **kargs):x = self.conv(inputs)x = self.bn(x, training=training)x = self.activation(x)return xclass InvertedResidualBlock(layers.Layer):def __init__(self, in_channel, out_channel, strides, expand_ratio, **kwargs):super(InvertedResidualBlock, self).__init__(**kwargs)self.hidden_channel = in_channel * expand_ratioself.use_shortcut = (strides == 1) and (in_channel == out_channel)layer_list = []# first bottleneck does not need 1*1 convif expand_ratio != 1:# 1x1 pointwise convlayer_list.append(ConvBNReLU(out_channel=self.hidden_channel, kernel_size=1, name='expand'))layer_list.extend([# 3x3 depthwise conv layers.DepthwiseConv2D(kernel_size=3, padding='SAME', strides=strides, use_bias=False, name='depthwise'),layers.BatchNormalization(momentum=0.9, epsilon=1e-5, name='depthwise/BatchNorm'),layers.ReLU(max_value=6.0),#1x1 pointwise conv(linear) # linear activation y = x -> no activation functionlayers.Conv2D(filters=out_channel, kernel_size=1, strides=1, padding='SAME', use_bias=False, name='project'),layers.BatchNormalization(momentum=0.9, epsilon=1e-5, name='project/BatchNorm')])self.main_branch = Sequential(layer_list, name='expanded_conv')def call(self, inputs, **kargs):if self.use_shortcut:return inputs + self.main_branch(inputs)else:return self.main_branch(inputs) 4 损失函数softmax 交叉熵
4.1 softmax函数
Softmax函数由下列公式定义
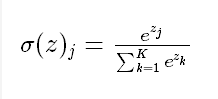
softmax 的作用是把 一个序列,变成概率。
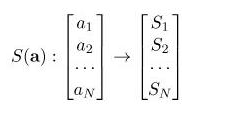
softmax用于多分类过程中,它将多个神经元的输出,映射到(0,1)区间内,所有概率的和将等于1。
python实现
def softmax(x):shift_x = x - np.max(x) # 防止输入增大时输出为nanexp_x = np.exp(shift_x)return exp_x / np.sum(exp_x)
PyTorch封装的Softmax()函数
dim参数:
- dim为0时,对所有数据进行softmax计算
- dim为1时,对某一个维度的列进行softmax计算
- dim为-1 或者2 时,对某一个维度的行进行softmax计算
import torch
x = torch.tensor([2.0,1.0,0.1])
x.cuda()
outputs = torch.softmax(x,dim=0)
print("输入:",x)
print("输出:",outputs)
print("输出之和:",outputs.sum())4.2 交叉熵损失函数
定义如下:

python实现
def cross_entropy(a, y):return np.sum(np.nan_to_num(-y*np.log(a)-(1-y)*np.log(1-a)))# tensorflow version
loss = tf.reduce_mean(-tf.reduce_sum(y_*tf.log(y), reduction_indices=[1]))# numpy version
loss = np.mean(-np.sum(y_*np.log(y), axis=1))
PyTorch实现
交叉熵函数分为二分类(torch.nn.BCELoss())和多分类函数(torch.nn.CrossEntropyLoss()
# 二分类 损失函数
loss = torch.nn.BCELoss()
l = loss(pred,real)
# 多分类损失函数
loss = torch.nn.CrossEntropyLoss()5 优化器SGD
简介
SGD全称Stochastic Gradient Descent,随机梯度下降,1847年提出。每次选择一个mini-batch,而不是全部样本,使用梯度下降来更新模型参数。它解决了随机小批量样本的问题,但仍然有自适应学习率、容易卡在梯度较小点等问题。
pytorch调用方法:
torch.optim.SGD(params, lr=<required parameter>, momentum=0, dampening=0, weight_decay=0, nesterov=False)
相关代码:
def step(self, closure=None):"""Performs a single optimization step.Arguments:closure (callable, optional): A closure that reevaluates the modeland returns the loss."""loss = Noneif closure is not None:loss = closure()for group in self.param_groups:weight_decay = group['weight_decay'] # 权重衰减系数momentum = group['momentum'] # 动量因子,0.9或0.8dampening = group['dampening'] # 梯度抑制因子nesterov = group['nesterov'] # 是否使用nesterov动量for p in group['params']:if p.grad is None:continued_p = p.grad.dataif weight_decay != 0: # 进行正则化# add_表示原处改变,d_p = d_p + weight_decay*p.datad_p.add_(weight_decay, p.data)if momentum != 0:param_state = self.state[p] # 之前的累计的数据,v(t-1)# 进行动量累计计算if 'momentum_buffer' not in param_state:buf = param_state['momentum_buffer'] = torch.clone(d_p).detach()else:# 之前的动量buf = param_state['momentum_buffer']# buf= buf*momentum + (1-dampening)*d_pbuf.mul_(momentum).add_(1 - dampening, d_p)if nesterov: # 使用neterov动量# d_p= d_p + momentum*bufd_p = d_p.add(momentum, buf)else:d_p = buf# p = p - lr*d_pp.data.add_(-group['lr'], d_p)return loss6 最后
相关文章:
计算机毕设 基于深度学习的植物识别算法 - cnn opencv python
文章目录 0 前言1 课题背景2 具体实现3 数据收集和处理3 MobileNetV2网络4 损失函数softmax 交叉熵4.1 softmax函数4.2 交叉熵损失函数 5 优化器SGD6 最后 0 前言 🔥 这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点&a…...
【STM32】学习笔记-江科大
【STM32】学习笔记-江科大 1、STM32F103C8T6的GPIO口输出 2、GPIO口输出 GPIO(General Purpose Input Output)通用输入输出口可配置为8种输入输出模式引脚电平:0V~3.3V,部分引脚可容忍5V输出模式下可控制端口输出高低电平&#…...
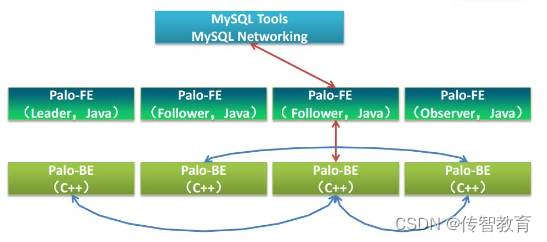
Doris架构中包含哪些技术?
Doris主要整合了Google Mesa(数据模型),Apache Impala(MPP Query Engine)和Apache ORCFile (存储格式,编码和压缩)的技术。 为什么要将这三种技术整合? Mesa可以满足我们许多存储需求的需求,但是Mesa本身不提供SQL查询引擎。 Impala是一个…...
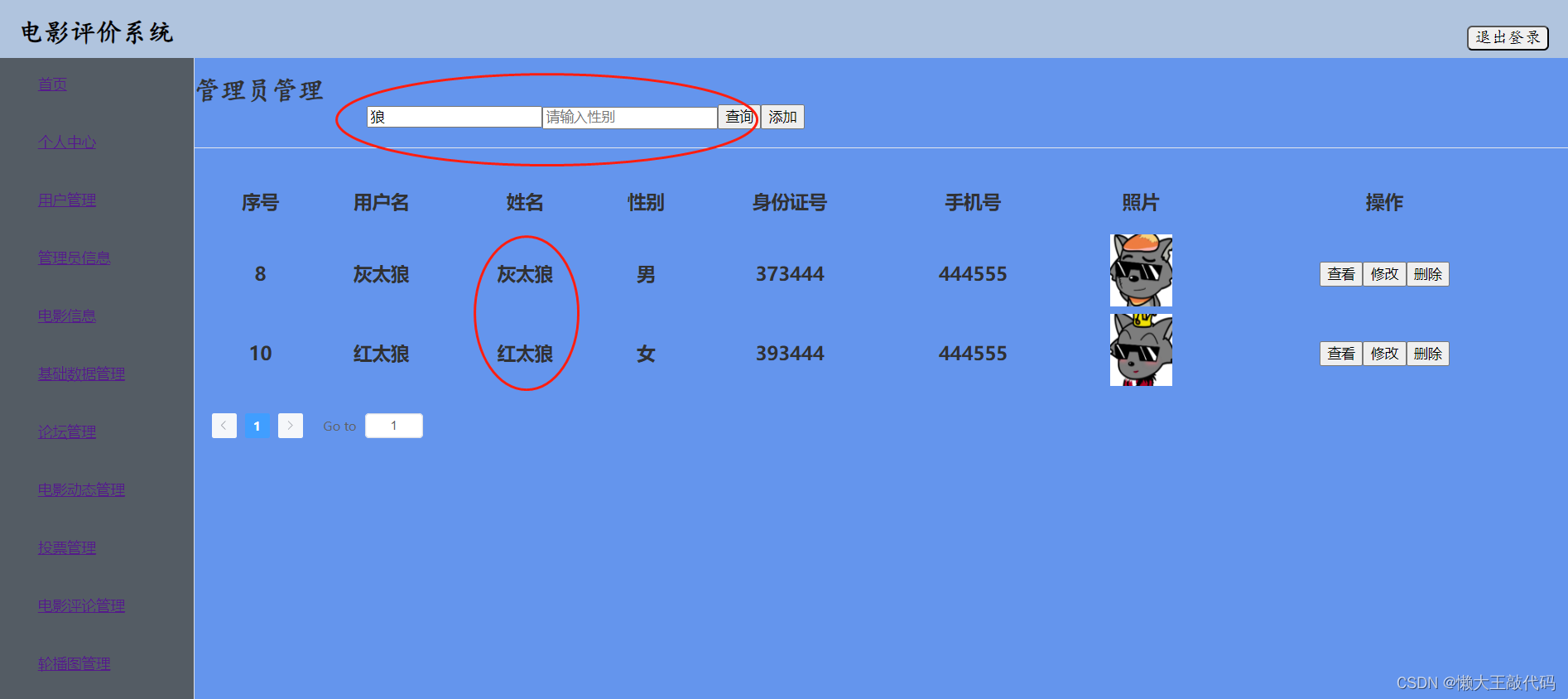
《vue3实战》通过indexOf方法实现电影评价系统的模糊查询功能
目录 前言 一、indexOf是什么?indexOf有什么作用? 含义: 作用: 二、功能实现 这段是查询过程中过滤筛选功能的代码部分: 分析: 这段是查询用户和性别功能的代码部分: 分析: 三、最终效…...

java对时间序列每x秒进行分组
问题:将一个时间序列每5秒分一组,返回嵌套的list; 原理:int除int会得到一个int(也就是损失精度) 输入:排序后的list,每几秒分组值 private static List<List<Long>> get…...

八月更新 | CI 构建计划触发机制升级、制品扫描 SBOM 分析功能上线!
点击链接了解详情 这个八月,腾讯云 CODING DevOps 对持续集成、制品管理、项目协同、平台权限等多个产品模块进行了升级改进,为用户提供更灵活便捷的使用体验。以下是 CODING 新功能速递,快来看看是否有您期待已久的功能特性: 01…...

Spring核心配置步骤-完全基于XML的配置
Spring框架的核心配置涉及多个方面,包括依赖注入(DI)、面向切面编程(AOP)等。以下是一般情况下配置Spring应用程序的核心步骤: 1. **引入Spring依赖:** 在项目的构建工具(如Maven、…...

宏基官网下载的驱动怎么安装(宏基笔记本如何安装系统)
本文为大家介绍宏基官网下载的驱动怎么安装宏基笔记本驱动(宏基笔记本如何安装系统),下面和小编一起看看详细内容吧。 宏碁笔记本怎么一键更新驱动 1. 单击“开始”,然后选择“所有程序”。 2. 单击Acer,然后单击Acer eRecovery Management。…...

基于AVR128单片机抢答器proteus仿真设计
一、系统方案 二、硬件设计 原理图如下: 三、单片机软件设计 1、首先是系统初始化 void timer0_init() //定时器初始化 { TCCR00x07; //普通模式,OC0不输出,1024分频 TCNT0f_count; //初值,定时为10ms TIFR0x01; //清中断标志…...

openGauss学习笔记-54 openGauss 高级特性-MOT
文章目录 openGauss学习笔记-54 openGauss 高级特性-MOT54.1 MOT特性及价值54.2 MOT关键技术54.3 MOT应用场景54.4 不支持的数据类型54.5 使用MOT54.6 将磁盘表转换为MOT openGauss学习笔记-54 openGauss 高级特性-MOT openGauss引入了MOT(Memory-Optimized Table&…...

InsCode AI 创作助手
RESTful API是一种架构风格和设计原则,用于构建Web服务和应用程序。它基于HTTP协议,以资源为中心,对资源进行各种操作。RESTful API的主要特点包括: 使用HTTP协议进行传输和通信;操作和状态均以资源为中心;…...

java对时间序列根据阈值进行连续性分片
问题描述:我需要对一个连续的时间戳list进行分片,分片规则是下一个数据比当前数据要大于某一个阈值则进行分片; 解决方式: 1、输入的有顺序的list ,和需要进行分片的阈值 2、调用方法,填入该排序的list和阈…...

Pillow:Python的图像处理库(安装与使用教程)
在Python中,Pillow库是一个非常强大的图像处理库。它提供了广泛的图像处理功能,让我们可以轻松地操作图像,实现图像的转换、裁剪、缩放、旋转等操作。此外,Pillow还支持多种图像格式的读取和保存,包括JPEG、PNG、BMP、…...
自然语言处理-NLP
目录 自然语言处理-NLP 致命密码:一场关于语言的较量 自然语言处理的发展历程 兴起时期 符号主义时期 连接主义时期 深度学习时期 自然语言处理技术面临的挑战 语言学角度 同义词问题 情感倾向问题 歧义性问题 对话/篇章等长文本处理问题 探索自然语言…...

柠檬水找零【贪心算法-】
柠檬水找零 在柠檬水摊上,每一杯柠檬水的售价为 5 美元。顾客排队购买你的产品,(按账单 bills 支付的顺序)一次购买一杯。 每位顾客只买一杯柠檬水,然后向你付 5 美元、10 美元或 20 美元。你必须给每个顾客正确找零&…...

el-date-picker设置开始时间小于结束时间
一. date-picker Template <template><el-form-item label"开始时间" prop"startDate"><el-date-pickerv-model.trim"form.startDate"type"datetime"placeholder"请选择日期"value-format"yyyy-MM-dd …...
—— 设备与模块(基于Linux 2.6内核))
Linux内核学习(十三)—— 设备与模块(基于Linux 2.6内核)
目录 一、设备类型 二、模块 构建模块 安装模块 载入模块 一、设备类型 在 Linux 以及 Unix 系统中,设备被分为以下三种类型: 块设备(blkdev):以块为寻址单位,块的大小随设备的不同而变化࿱…...

计算机视觉工程师学习路线
1. 学习编程语言和基础库 学习Python语言,掌握基础语法、函数、面向对象编程等概念学习Numpy库,用于科学计算和多维数组学习OpenCV库,包含了许多图像处理和计算机视觉算法学习TensorFlow/PyTorch,主要的深度学习框架 2. 学习数字图像处理算法 图像的表示方式(像素、灰度、二…...

c#多线程—基础概念到“双色球”项目实现(附知识点目录、代码、视频)
总结:视频中对于多线程讲的非常透彻,从线程基础概念—>.net不同版本出现的线程方法—>多线程常出现问题—>双色球项目实践,每个知识点都有代码实操,受益匪浅。附上学习笔记和实操代码。 视频 目录 一、线程、进程概念及优…...
【OpenCV入门】第一部分——图像处理基础
本文结构 图像处理的基本操作读取图像imread() 显示图像imshow()waitKey()destroyAllWindows() 保存图像imwrite() 获取图像属性 像素确定像素的位置获取像素的BGR值修改像素的BGR值 色彩空间GRAY色彩空间cvtColor()——从BGR色彩空间转换到GRAY色彩空间 HSV色彩空间从BGR色彩空…...
)
【Perplexity词组搭配查询权威基准测试】:覆盖医学/法律/工程三大垂直领域,17项指标碾压传统n-gram方法(数据已通过ACL评审)
更多请点击: https://intelliparadigm.com 第一章:Perplexity词组搭配查询权威基准测试概览 Perplexity(困惑度)作为衡量语言模型预测能力的核心指标,其在词组搭配(collocation)查询任务中的表…...

服务器电源、电机驱动、UPS:IRLR3636TRPBF的60V功率MOSFET应用版图
IRLR3636TRPBF:DPAK封装60V/50A N沟道功率MOSFET的大电流开关应用解析在大功率开关电源、不间断电源以及直流电机驱动等领域,功率MOSFET的导通损耗直接影响系统的温升和能效等级。当设计需要在60V电压平台上处理50A级别的大电流时,导通电阻和…...

56、CAN总线RC低通滤波器截止频率计算与实战
CAN总线RC低通滤波器截止频率计算与实战 一、一个让我熬夜三天的CAN通信故障 去年做某车载ECU项目,CAN总线在电机启动瞬间频繁丢帧。示波器抓波形,CAN_H对地毛刺高达8V,持续时间约200ns。团队里有人提议“加磁珠”,有人喊“上共模扼流圈”。我翻出TI的AN-2298应用笔记,发…...
写给前端的 CANN-ops-transformer:昇腾Transformer进阶算子库到底是啥?
写给前端的 CANN-ops-transformer:昇腾Transformer进阶算子库到底是啥? 之前有兄弟跑大模型,问我:“哥,我想 用 FlashAttention,但 ATB 太重了,有没有轻量点的库?” 好问题。今天来说…...

录音总结会议纪要推荐,零基础新手避坑可直接上手指南
这是专为零基础新手整理的2026年录音转会议纪要避坑指南,适配喜欢尝试效率工具、想借助AI节省整理时间的朋友,所有推荐均按实际场景适配度排序,内容简洁易懂,看完可直接上手,无需自行试错踩坑。很多新手接触录音转会议…...

Google I/O 2026 推出 Antigravity SDK:本地构建 AI Agent,灵活定制功能
Antigravity SDK 登场当开发者需要将 AI 能力嵌入自有应用时,常见做法是通过 API 调用远程 Agent 服务,但这种方式存在延迟高、定制性差、依赖网络等问题。据悉,Google 在 I/O 2026 大会上给出了另一种解法 ---- Antigravity SDK,…...

QiWe 免费开源微信机器人:从零到一的完整开发与部署指南
1. 为什么选择 QiWe 开源框架? 在私域流量运营和社群智能化的浪潮中,微信机器人早已成为降本增效的利器。然而,市面上许多闭源方案不仅收费高昂,还存在严重的数据泄露风险。QiWe 作为一款优秀的免费开源微信机器人框架,…...
安装ROCm 4.5.2驱动及完整工具链)
保姆级教程:在Ubuntu 22.04上为DCU-Z100(ZiFang)安装ROCm 4.5.2驱动及完整工具链
国产AI加速卡DCU-Z100(ZiFang)全栈部署指南:从驱动安装到开发环境配置 在人工智能计算领域,国产硬件正逐步崭露头角。DCU-Z100(代号ZiFang)作为一款自主研发的深度学习计算单元,为开发者提供了全…...

CSP认证202305-1题保姆级攻略:用C++的map轻松搞定国际象棋局面去重
CSP认证202305-1题深度解析:从字符串处理到STL高效去重 国际象棋对局中的局面重复判定是一个经典的字符串处理问题,也是CSP认证考试中常见的题型。这道题看似简单,却蕴含了算法选择与数据结构应用的核心思想。本文将带您从题目分析、解法对比…...

CANN/asc-devkit SIMD向量长度获取函数
GetVecLen 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com/…...