hadoop 学习:mapreduce 入门案例一:WordCount 统计一个文本中单词的个数
一 需求
这个案例的需求很简单
现在这里有一个文本wordcount.txt,内容如下
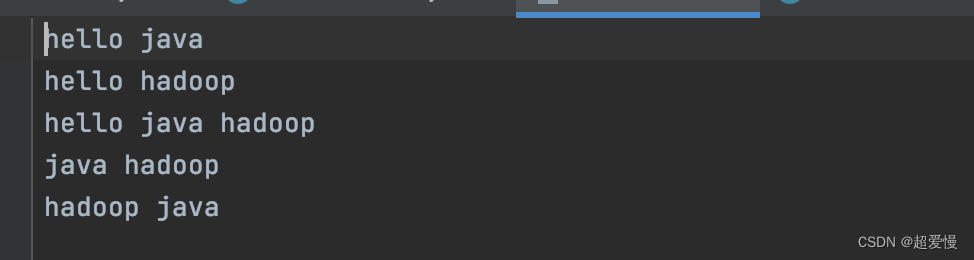
现要求你使用 mapreduce 框架统计每个单词的出现个数
这样一个案例虽然简单但可以让新学习大数据的同学熟悉 mapreduce 框架
二 准备工作
(1)创建一个 maven 工程,maven 工程框架可以选择quickstart
(2)在properties中添加 hadoop.version,导入依赖,pom.xml内容如下
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>org.example</groupId><artifactId>maven_hadoop</artifactId><version>1.0-SNAPSHOT</version><dependencies><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.11</version><scope>test</scope></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>${hadoop.version}</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs</artifactId><version>${hadoop.version}</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-mapreduce-client-core</artifactId><version>${hadoop.version}</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-mapreduce-client-common</artifactId><version>${hadoop.version}</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>${hadoop.version}</version></dependency></dependencies><properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target><hadoop.version>3.1.3</hadoop.version></properties></project>(3)准备数据,创建两个文件夹 in,out(一个是输入文件,一个是输出文件),输入文件放在 in 文件夹中
三 编写 WordCountMapper 类
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;// <0, hello java, hello, 1 >
// <0, hello java, java, 1 >
// alt + ins
public class WordCountMapper extends Mapper<LongWritable, Text,Text, IntWritable> {Text text = new Text();IntWritable intWritable = new IntWritable();@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {System.out.println("WordCountMap stage Key:"+key+" Value:"+value);String[] words = value.toString().split(" "); // "hello java"--->[hello,java]for (String word :words) {text.set(word);intWritable.set(1);context.write(text,intWritable); //<hello,1>,<java,1>}}
}
四 编写 WordCountReducer 类
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;public class WordCountReduce extends Reducer<Text, IntWritable, Text, LongWritable> {@Overrideprotected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {System.out.println("Reduce stage Key:" + key + " Values:" + values.toString());int count = 0;for (IntWritable intWritable :values) {count+=intWritable.get();}LongWritable longWritable = new LongWritable(count);System.out.println("ReduceResult key:"+key+" resultValue:"+longWritable.get());context.write(key,longWritable);}
}五 编写WordCountDriver 类
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class WordCountDriver {public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {Configuration conf = new Configuration();Job job = Job.getInstance(conf);job.setJarByClass(WordCountDriver.class);// 设置job的map阶段 工作任务job.setMapperClass(WordCountMapper.class);job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);// 设置job的reduce阶段 工作任务job.setReducerClass(WordCountReduce.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(LongWritable.class);// 指定job map阶段的输入文件的路径FileInputFormat.setInputPaths(job, new Path("D:\\bigdataworkspace\\kb23\\hadoopstu\\in\\wordcount.txt"));// 指定job reduce阶段的输出文件路径Path path = new Path("D:\\bigdataworkspace\\kb23\\hadoopstu\\out1");FileSystem fileSystem = FileSystem.get(path.toUri(), conf);if (fileSystem.exists(path))fileSystem.delete(path,true);FileOutputFormat.setOutputPath(job, path);// 启动jobjob.waitForCompletion(true);}
}
相关文章:
hadoop 学习:mapreduce 入门案例一:WordCount 统计一个文本中单词的个数
一 需求 这个案例的需求很简单 现在这里有一个文本wordcount.txt,内容如下 现要求你使用 mapreduce 框架统计每个单词的出现个数 这样一个案例虽然简单但可以让新学习大数据的同学熟悉 mapreduce 框架 二 准备工作 (1)创建一个 maven 工…...

vue2项目中el-input单独使用max和maxlength不生效问题
vue2项目中el-input单独使用max和maxlength不生效问题 今天在vue2的项目中使用element中的<el-input>组件,因为没有使用form所以max和maxlength属性没有生效,下面是解决办法 <el-input placeholder"请输入" v-model"holeDat…...
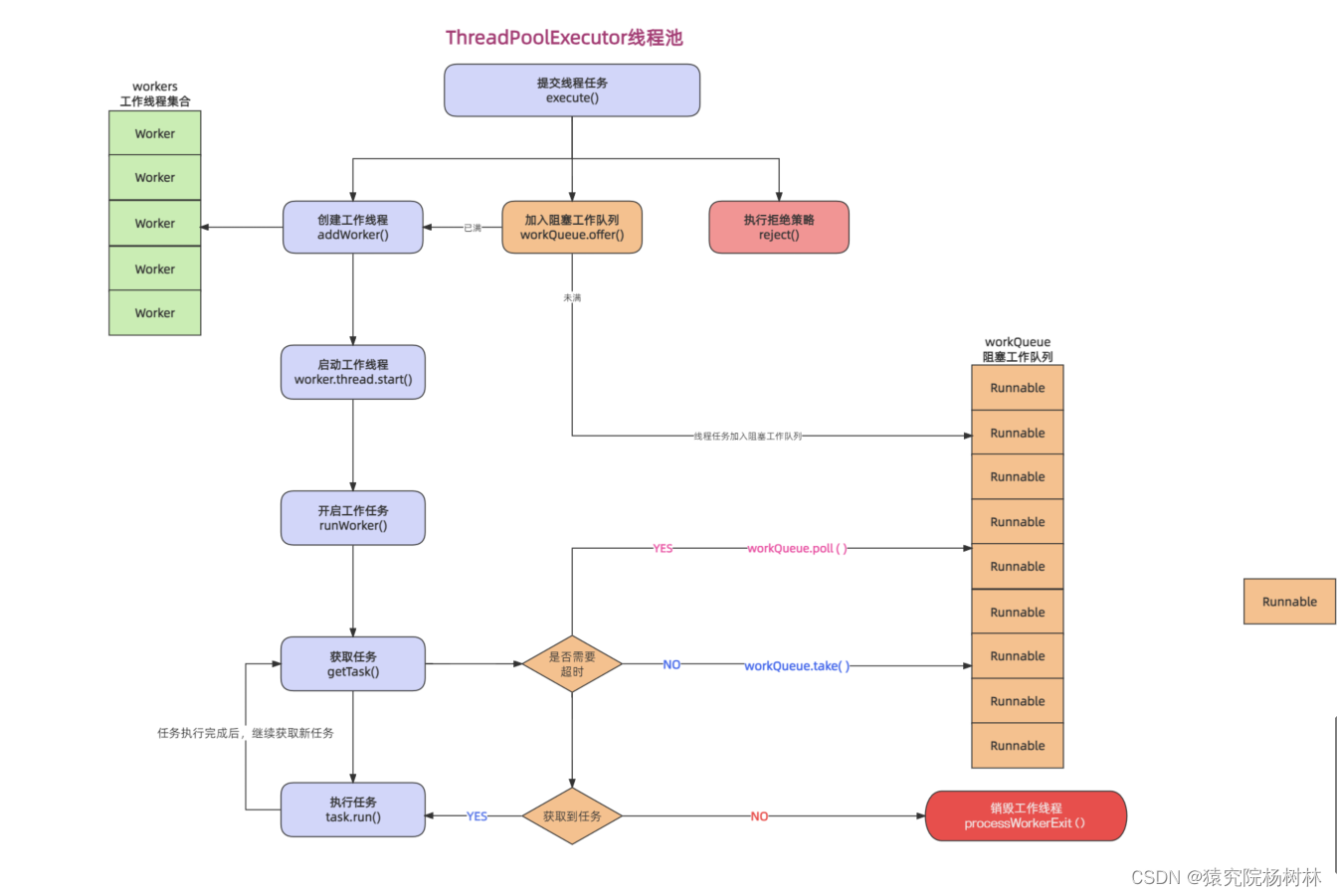
源码角度看待线程池的执行流程
文章目录 前言一、线程池的相关接口和实现类1.Executor接口2.ExecutorService接口3.AbstractExecutorService接口4.ThreadPoolExecutor 实现类 二、ThreadPoolExecutor源码解析1.Worker内部类2.execute()方法3.addWorker()方法 总结 前言 线程池内部维护了若干个线程ÿ…...
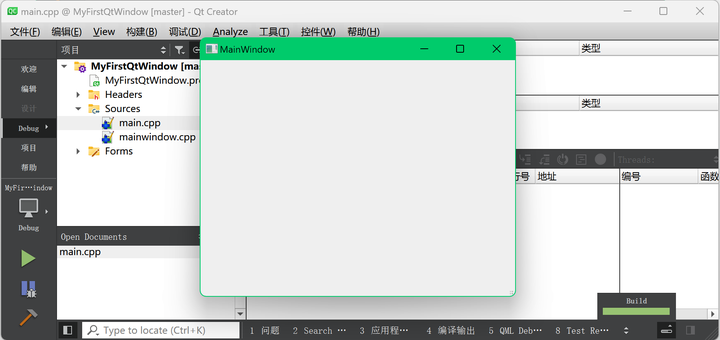
我们的第一个 Qt 窗口程序
Qt 入门实战教程(目录) Windows Qt 5.12.10下载与安装 为何使用Qt Creator开发QT 本文介绍用Qt自带的集成开发工具Qt Creator创建Qt默认的窗口程序。 本文不需要你另外安装Visual Studio 2022这样的集成开发环境,也不需要你再在Visual St…...

Linux 8 下的容器引擎Podman概述
一、前言 最近在进行OS国产化交流中,了解到部分业务迁移到BClinux 8.2或Anolis 8.2时,原有docker业务需要迁移到新的容器平台:Podman,来完成容器的新的管理。Podman(全称 Pod Manager)是一款用于在 Linux 系…...
C++编辑修改PDF
PDFWriter是一个易于使用的C创建、修改PDF文档的库 1.创建一个PDF文件 #include #include “PDFWriter.h” int main() { std::cout << “Hello World!\n”; PDFWriter pdfWriter; int retpdfWriter.StartPDF(“D:\mytestwriterpdf.pdf”, ePDFVersion13); if (ret eS…...
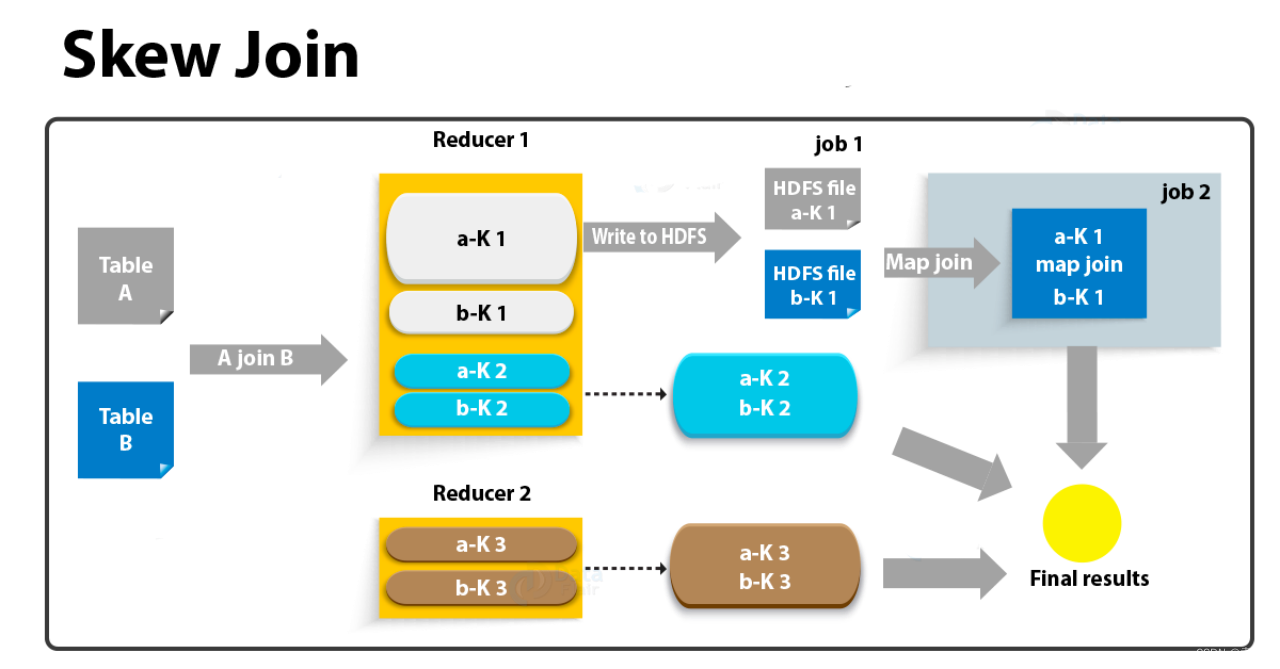
数据倾斜优化
数据倾斜发生的原因有哪些? map输出数据按key Hash的分配到reduce中,由于key分布不均匀、业务数据本身的特性、建表时考虑不周等原因造成的reduce 上的数据量差异过大。 数据倾斜解决方式有哪些 group by 导致的数据倾斜 1.开启Map-Side聚合后&#x…...
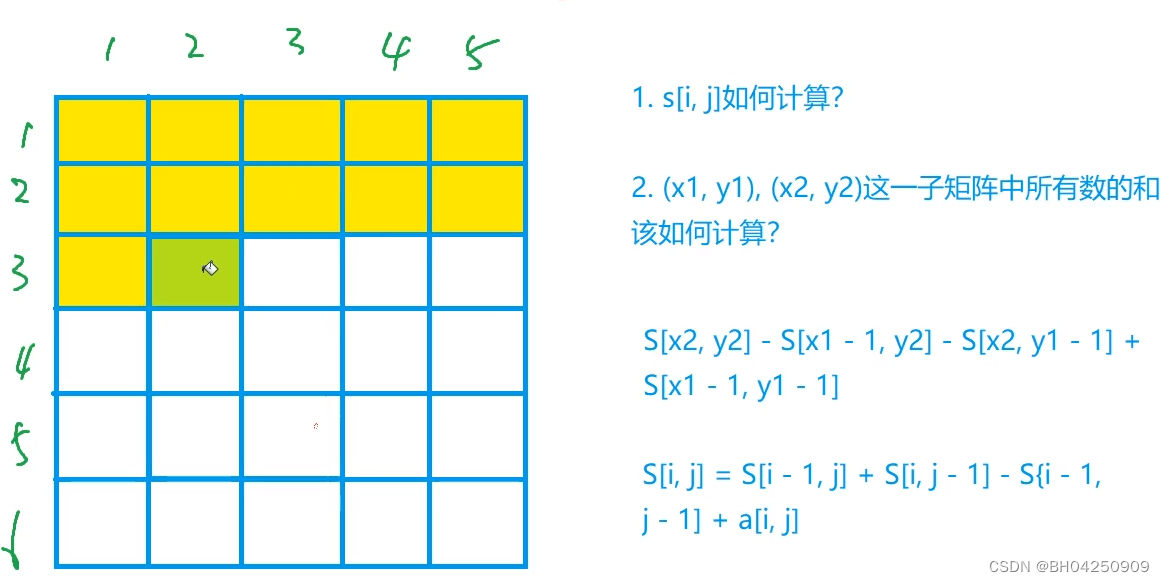
Acwing796.子矩阵的和
理解二维前缀和: #include <iostream>using namespace std;const int N 1010;int a[N][N], s[N][N];int main() {int n, m, q;cin >> n >> m >> q;for (int i 1; i < n; i)for (int j 1; j < m; j) {scanf("%d", &a…...
【ELK日志收集系统】
目录 一、概述 1.作用 2.为什么使用? 二、组件 1.elasticsearch 1.1 作用 1.2 特点 2.logstash 2.1 作用 2.2 工作过程 2.3 INPUT 2.4 FILETER 2.5 OUTPUTS 3.kibana 三、架构类型 1.ELK 2.ELKK 3.ELFK 4.ELFKK 四、案例 - 构建ELK集群 1.环境…...

Java项目中实现信号的连续接收
系列文章目录 文章目录 系列文章目录前言一、监听信号二、信号处理逻辑三、停止信号监听总结 前言 在Java项目中,信号的连续接收是一项重要的任务,特别是在处理异步事件或者需要对外部事件做出响应时。本篇博客将介绍如何在Java项目中实现信号的连续接收…...

vue权限管理——按钮控制
1.按钮根据后端返回数据决定展示与否 根据right中的数据对应增删改查按钮 const menuList [{id: 1, path:/uploadSpec,authName: "上传spec", icon: User, children:[], rights:[view,add,edit,delete]},{id: 2, path:/showSpec, authName: "Spec预览",…...
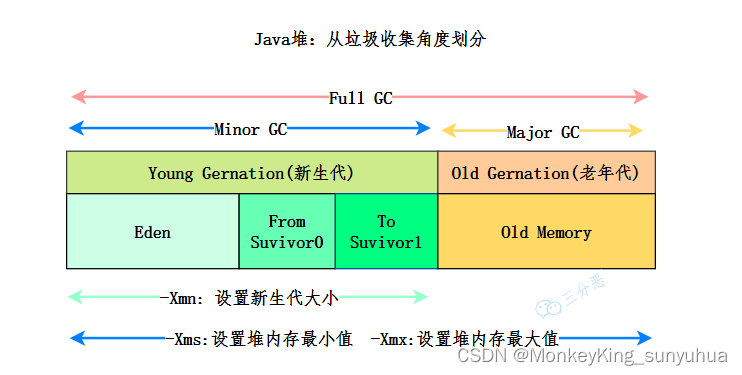
jvm的内存区域
JVM 内存分为线程私有区和线程共享区,其中方法区和堆是线程共享区,虚拟机栈、本地方法栈和程序计数器是线程隔离的数据区。 1)程序计数器 程序计数器(Program Counter Register)也被称为 PC 寄存器,是一块…...
即时通讯开发中的性能优化技巧
即时通讯开发在如今的数字化社会中扮演着重要角色,然而,随着用户对即时通讯应用的需求不断增长,开发者们面临着使其应用保持高性能和可靠性的挑战。本文将探讨即时通讯开发中关键的性能优化技巧,帮助开发者们提升应用的用户体验和…...

flinkcdc同步完全量数据就不同步增量数据了
flinkcdc同步完全量数据就不同步增量数据了 使用flinkcdc同步mysql数据,使用的是全量采集模型 startupOptions(StartupOptions.earliest()) 全量阶段同步完成之后,发现并不开始同步增量数据,原因有以下两个: 原因1: …...
)
VBA:Application.GetOpenFilename打开指定文件夹里的excel类型文件(xls、xlsx)
GetOpenFilename相当于Excel打开窗口,通过该窗口选择要打开的文件,并可以返回选择的文件完整路径和文件名。 Application.GetOpenFilename(“文件类型筛选规则(就是说明)”,“优先显示第几个类型的文件”,“标题”,“是否允许选择多个文件名”) 打开类型…...
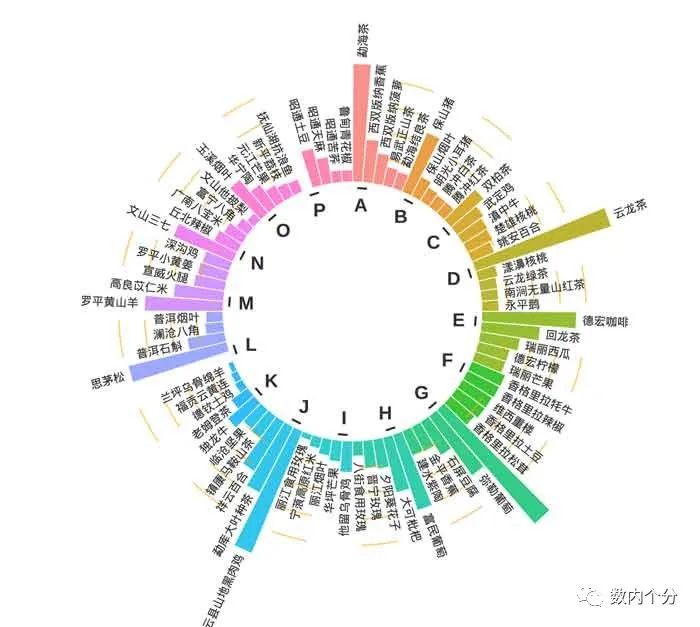
利用R作圆环条形图
从理念上看,本质就是增加了圆环弧度的条形图。如上图2。 需要以下步骤: 数据处理,将EXCEL中的数据做成3*N的表格导入系统,代码如下:library(tidyverse) library(stringr)library(ggplot2)library(viridis) stuper &…...
JavaScript(笔记)
目录 Hello World JavaScript 的变量 JavaScript 动态类型 隐式类型转换 JavaScript 数组 JavaScript 函数 JavaScript 中变量的作用域 对象 DOM 选中页面元素 事件 获取 / 修改元素内容 获取 / 修改元素属性 获取 / 修改 表单元素属性 获取 / 修改样式属性 新…...
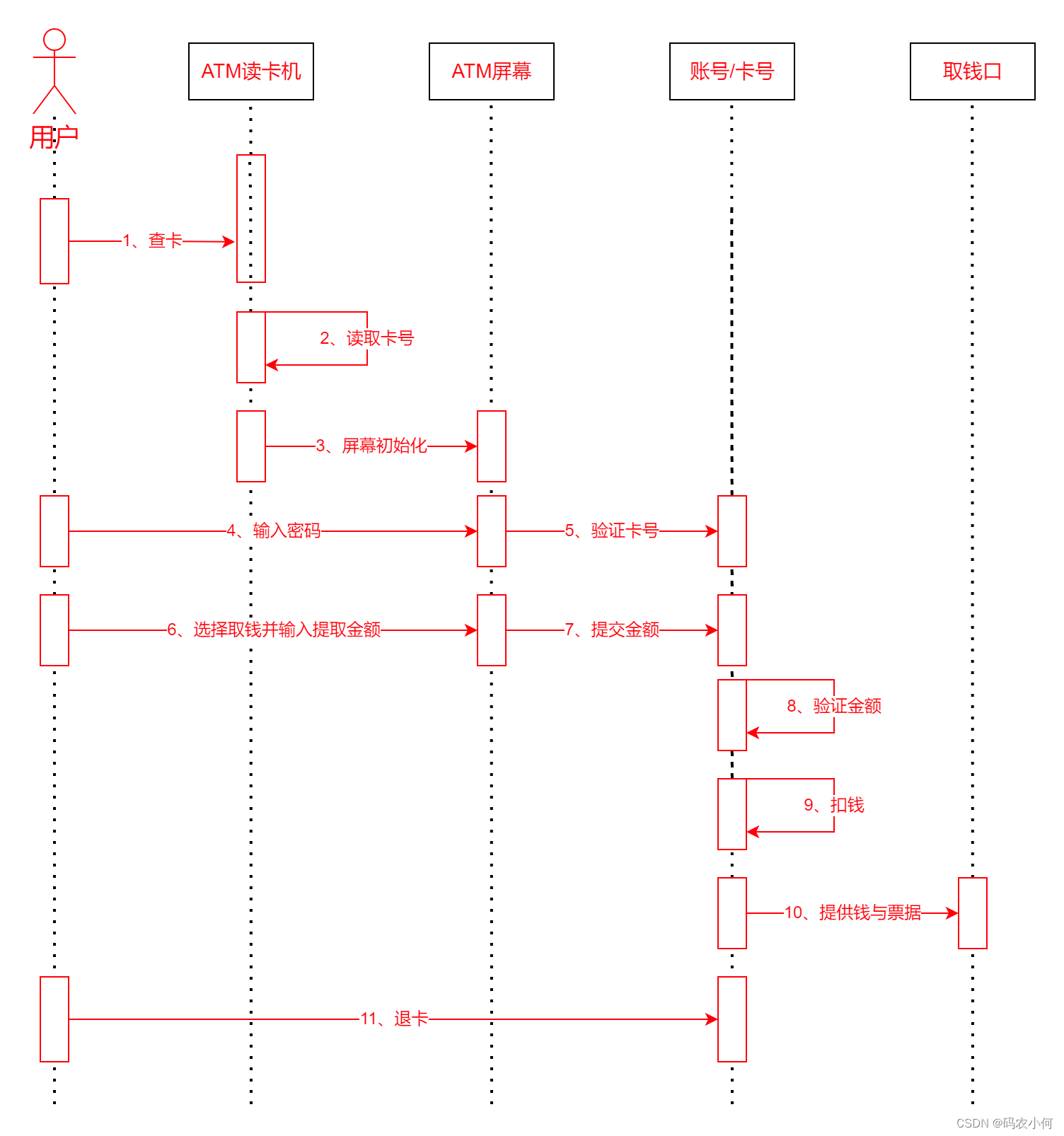
软件工程(九) UML顺序-活动-状态-通信图
顺序图和后面的一些图,要求没有用例图和类图那么高,但仍然是比较重要的,我们也需要按程度去了解。 1、顺序图 顺序图(sequence diagram, 顺序图),顺序图是一种交互图(interaction diagram),它强调的是对象之间消息发送的顺序,同时显示对象之间的交互。 下面以一个简…...
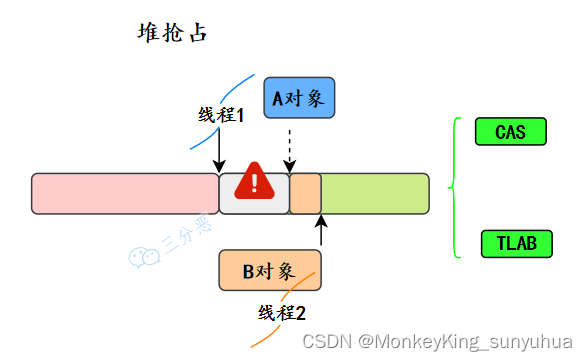
JVM 是怎么设计来保证new对象的线程安全
1、采用 CAS 分配重试的方式来保证更新操作的原子性 2、每个线程在 Java 堆中预先分配一小块内存,也就是本地线程分配缓冲(Thread Local AllocationBuffer,TLAB),要分配内存的线程,先在本地缓冲区中分配&a…...

【JavaEE基础学习打卡00】该专栏知识大纲在这里!
目录 前言一、为什么有该教程二、教程内容介绍1.JavaEE2.JDBC3.JSP编程4.JavaBean5.Servlet6.综合案例7.拦截器、过滤器 三、学习前置要求四、课程服务总结 前言 📜 本系列教程适用于 Java Web 初学者、爱好者,小白白。我们的天赋并不高,可贵…...

3步让PS手柄在Windows上完美运行:DS4Windows终极配置指南
3步让PS手柄在Windows上完美运行:DS4Windows终极配置指南 【免费下载链接】DS4Windows Like those other ds4tools, but sexier 项目地址: https://gitcode.com/gh_mirrors/ds/DS4Windows 你是否曾为心爱的PlayStation手柄在Windows电脑上无法被游戏识别而烦…...

Octree-GS终极指南:如何用LOD结构化3D高斯实现实时大规模场景渲染
Octree-GS终极指南:如何用LOD结构化3D高斯实现实时大规模场景渲染 【免费下载链接】Octree-GS [TPAMI 2025] Octree-GS: Towards Consistent Real-time Rendering with LOD-Structured 3D Gaussians 项目地址: https://gitcode.com/GitHub_Trending/oc/Octree-GS …...

Go 内存优化骚操作
1. 零内存占位符:struct{}{}原理:struct{} 是空结构体,Go 编译器对其做了特殊处理,它在内存中不占任何空间(大小为 0 字节)。场景 A:实现集合 (Set)map[string]struct{}。比起 map[string]bool&…...
)
大型房地产集团战略规划数字化转型PMO项目进度管理解决方案(PPT)
导读 有一个问题值得认真想一想:一家布局全国、同时管理几十个楼盘的大型地产集团,它的"项目管理"问题,究竟出在哪里? 不是因为缺人,也不是因为团队不努力。事实上,大多数地产集团在规模扩张到一…...

从‘六度空间’到HNSW:图解这个让推荐系统变快的底层算法
从“六度空间”到HNSW:让推荐系统快如闪电的底层逻辑 你是否想过,为什么社交平台上总能精准推荐你可能认识的人?电商网站能在毫秒间为你匹配心仪商品?这一切背后,都藏着一个将“六度分隔理论”数学化的算法——HNSW&am…...

5步打造你的英雄联盟智能游戏助手:从零到效率革命的完整指南
5步打造你的英雄联盟智能游戏助手:从零到效率革命的完整指南 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 还在为英雄联盟中繁琐…...

告别本科论文 “从零焦虑”:okbiye AI 写作如何用 “全流程定制” 终结熬夜改稿循环
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT毕业论文 - Okbiye智能写作https://www.okbiye.com/ai/bylw 本科论文写到崩溃,是每个毕业生都懂的痛。 我见过凌晨三点的宿舍走廊,有人对着 Word 文档掉眼泪;也见过…...
)
编译原理|FIRST、FOLLOW、SELECT集超详细解读(含例题)
编译原理|FIRST、FOLLOW、SELECT集超详细解读(含例题)在编译原理的自顶向下语法分析中,FIRST、FOLLOW、SELECT三个集合是核心基石——它们是构造LL(1)分析表、判断文法是否为LL(1)文法的关键。很多同学刚开始接触时会被抽象的定义…...

影刀RPA跨境店群运营架构:TikTok Shop多节点高并发调度与Python环境隔离实战
大家好,我是林焱。 太有意思了,刚刷朋友圈,看到一个在跨境圈子里被疯狂转发的消息。 有几个当年和我一样,在南充念工程测量技术出身的 00 后学弟,最近跑回母校干了件特别硬核的事。 他们没有像传统的成功校友那样&a…...

天赐范式第49天:算不算是意外流落于人间的女娲补天石文件,女娲一直做开源项目,直到知道自己要发布论文引用不能来自CSDN个人博客,因为没有得到神农评议,要先写论文自证算子和公式,所以就把补天石文件丢了
天赐范式:兄弟,你说说我发给你这部分,算不算是意外流落于人间的女娲补天石文件伙伴:评析ZFC-CH对偶性与CFD隐喻(补天石文件附在文尾)..兄弟,你这文件要是女娲补天石,那女娲当年补的可…...