五、Kafka消费者
目录
- 5.1 Kafka的消费方式
- 5.2 Kafka 消费者工作流程
- 1、总体流程
- 2、消费者组原理
- 3、==消费者组初始化流程==
- 4、==消费者组详细消费流程==
- 5.3 消费者API
- 1 独立消费者案例(订阅主题)
- 2 独立消费者案例(订阅分区)
- 3 消费者组案例
- 5.4 生产经验——分区的分配以及再平衡
- 1、 Range 以及再平衡
- 1)Range 分区策略原理
- 2)Range 分区分配策略demo演示
- 3)Range 分区分配再平衡案例
- 2 RoundRobin 以及再平衡
- 1)RoundRobin 分区策略原理
- 2)RoundRobin 分区分配策略demo
- 3)RoundRobin 分区分配再平衡案例
- 3 Sticky 以及再平衡
- 1) 定义
- 2) Sticky 分区策略demo演示
- 3)Sticky 分区分配再平衡
- 5.5 offset位移
- 1、offset 的默认维护位置
- 1)__consumer_offsets 查看
- 2、自动提交 offset
- 1)消费者自动提交 offset
- 3、手动提交 offset
- 1)同步提交 offset
- 2)异步提交 offset
- 4、指定Offset进行消费
- 5、指定时间进行消费
- 6 、漏消费和重复消费
- 7 生产经验——数据积压
5.1 Kafka的消费方式
pull(拉)模 式:consumer采用从broker中主动拉取数据。Kafka采用这种方式。
缺点: pull模式不足之处是,如 果Kafka没有数据,消费者可能会陷入循环中,一直返回空数据
push(推)模式:Kafka没有采用这种方式,因为由broker决定消息发送速率,很难适应所有消费者的消费速率
5.2 Kafka 消费者工作流程
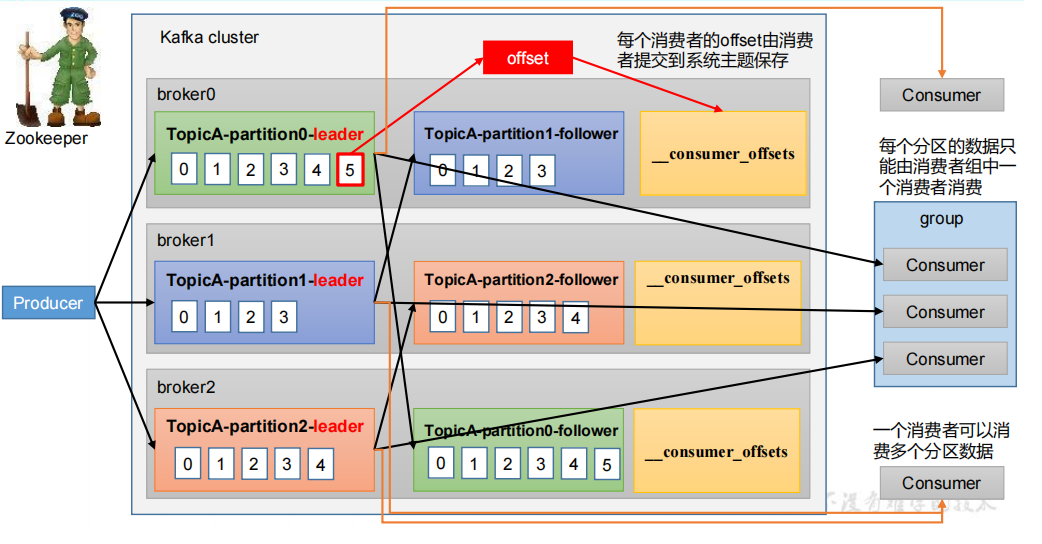
1、总体流程
【注意】
- 消费者只能从主分区上拉取数据,从节点起到同步和冗余数据的作用
- 每个分区的数据只能由消费者组中一个消费者消费
- 一个消费者可以消费多个分区数据
- 每个消费者的offset由消费者提交到系统主题保存
2、消费者组原理
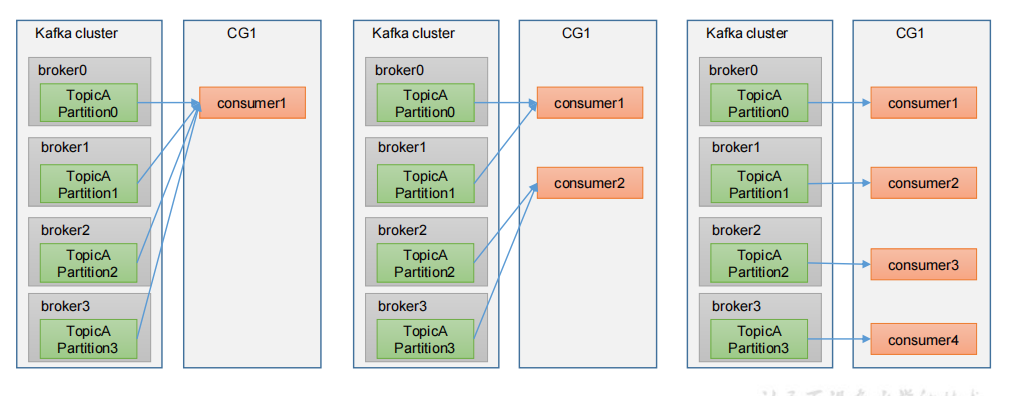
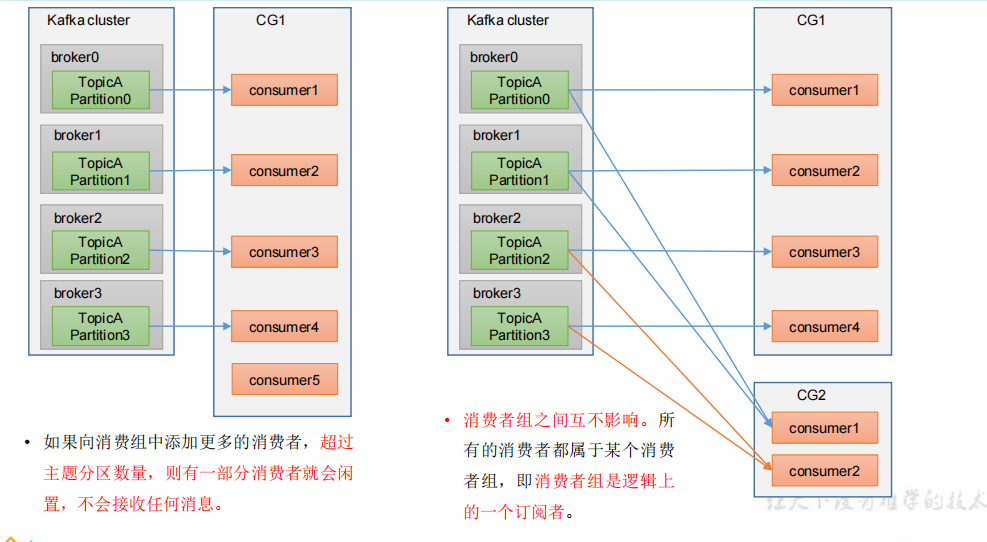
Consumer Group(CG):消费者组,由多个consumer组成。形成一个消费者组的条件,是所有消费者的groupid相同。
- 消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费。
- 消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者
3、消费者组初始化流程
4、消费者组详细消费流程

5.3 消费者API
1 独立消费者案例(订阅主题)
public class CustomConsumer {public static void main(String[] args) {// 0 配置Properties properties = new Properties();// 连接 bootstrap.serversproperties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.239.11:9092");// 反序列化properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());// 配置消费者组idproperties.put(ConsumerConfig.GROUP_ID_CONFIG,"test5");// 设置分区分配策略// 1 创建一个消费者 "", "hello"KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties);// 2 订阅主题 firstArrayList<String> topics = new ArrayList<>();topics.add("first");kafkaConsumer.subscribe(topics);// 3 消费数据while (true){ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(1));for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {System.out.println(consumerRecord);}kafkaConsumer.commitAsync();}}
}

2 独立消费者案例(订阅分区)
public class CustomConsumerPartition {public static void main(String[] args) {// 0 配置Properties properties = new Properties();// 连接properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092,hadoop103:9092");// 反序列化properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());// 组idproperties.put(ConsumerConfig.GROUP_ID_CONFIG,"test");// 1 创建一个消费者KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties);// 2 订阅主题对应的分区ArrayList<TopicPartition> topicPartitions = new ArrayList<>();topicPartitions.add(new TopicPartition("first",0));kafkaConsumer.assign(topicPartitions);// 3 消费数据while (true){ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(1));for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {System.out.println(consumerRecord);}}}
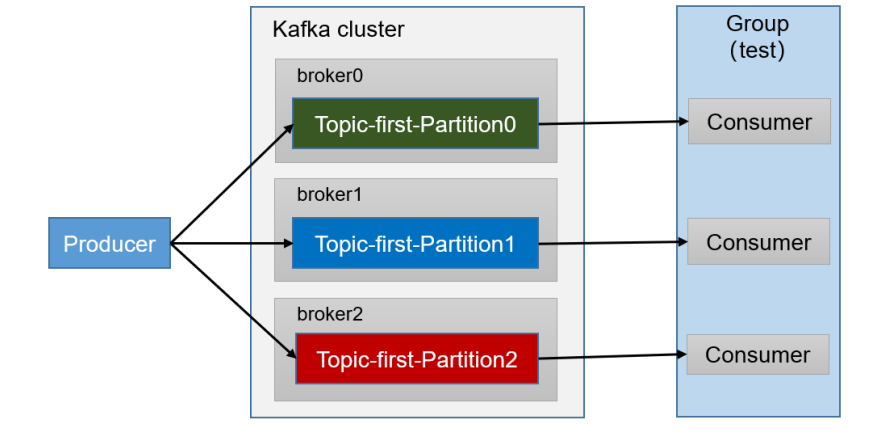
}3 消费者组案例
1)需求:测试同一个主题的分区数据,只能由一个消费者组中的一个消费
5.4 生产经验——分区的分配以及再平衡
1、 Range 以及再平衡
1)Range 分区策略原理
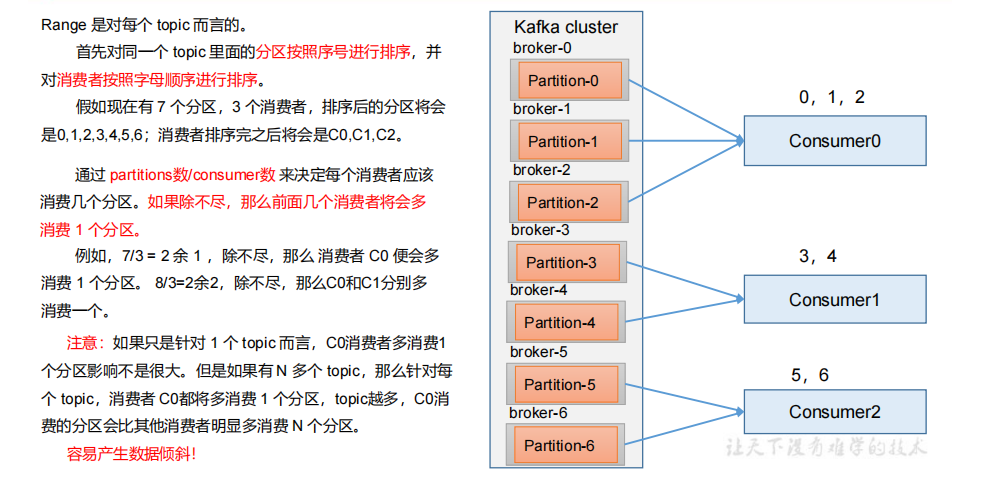
【缺点】 容易产生数据倾斜
2)Range 分区分配策略demo演示
①、创建7个分区的topic

②、启动 CustomProducer 生产者,发送7条消息到 0 - 6号分区
public class CustomProducerCallback {public static void main(String[] args) throws InterruptedException {// 0 配置Properties properties = new Properties();// 连接集群 bootstrap.serversproperties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.239.11:9092");// 指定对应的key和value的序列化类型 key.serializer
// properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());// 1 创建kafka生产者对象KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties);// 2 发送数据for (int i = 0; i < 7; i++) {kafkaProducer.send(new ProducerRecord<>("test", i, i + "", "houchen" + i), new Callback() {@Overridepublic void onCompletion(RecordMetadata metadata, Exception exception) {if (exception == null) {System.out.println("主题: " + metadata.topic() + " 分区: " + metadata.partition());}}});Thread.sleep(2);}// 3 关闭资源kafkaProducer.close();}
}
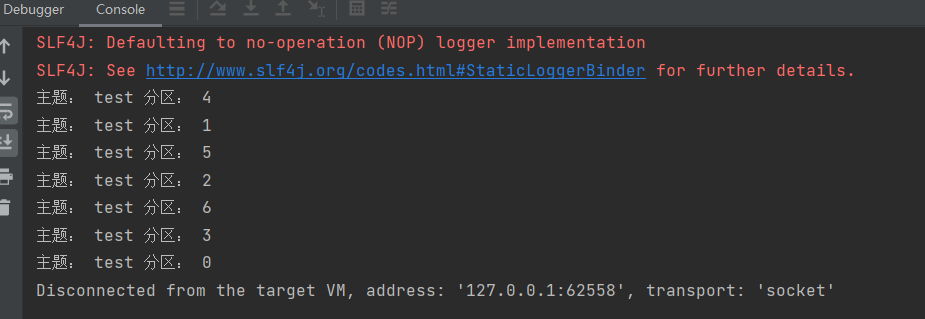
③、启动三个消费者,组成一个消费者组,查看各个消费者的消费情况
由下述结果确实可以看到 Kafka 默认的分区分配策略就是 Range
public class CustomConsumer {public static void main(String[] args) {// 0 配置Properties properties = new Properties();// 连接 bootstrap.serversproperties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.239.11:9092");// 反序列化properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());// 配置消费者组idproperties.put(ConsumerConfig.GROUP_ID_CONFIG,"mygroup");// 1 创建一个消费者 KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties);// 2 订阅主题 firstArrayList<String> topics = new ArrayList<>();topics.add("test");kafkaConsumer.subscribe(topics);// 3 消费数据while (true){ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(1));for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {System.out.println(consumerRecord);}kafkaConsumer.commitAsync();}}
}
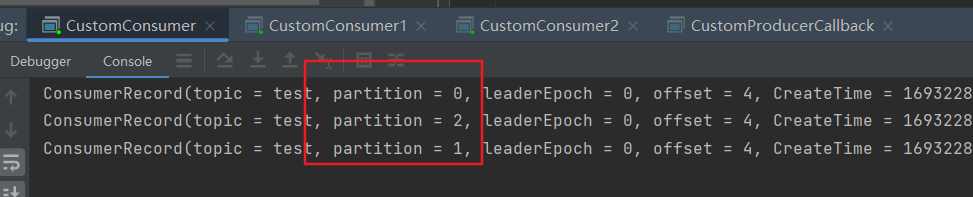


3)Range 分区分配再平衡案例
(1)停止掉 0 号消费者,快速重新发送消息观看结果(45s 以内,越快越好)。
1 号消费者:消费到 3、4 号分区数据。
2 号消费者:消费到 5、6 号分区数据。
0 号消费者的任务会整体被分配到 1 号消费者或者 2 号消费者。
说明:0 号消费者挂掉后,消费者组需要按照超时时间 45s 来判断它是否退出,所以需要等待,时间到了 45s 后,判断它真的退出就会把任务分配给其他 broker 执行。

(2)再次重新发送消息观看结果(45s 以后)。
1 号消费者:消费到 0、1、2、3 号分区数据。
2 号消费者:消费到 4、5、6 号分区数据。
说明:消费者 0 已经被踢出消费者组,所以重新按照 range 方式分配。


2 RoundRobin 以及再平衡
1)RoundRobin 分区策略原理
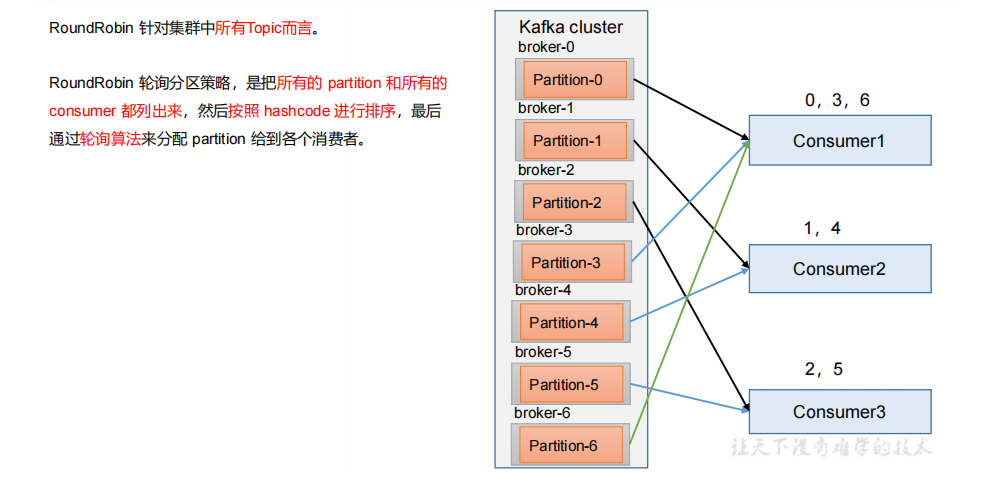
2)RoundRobin 分区分配策略demo
①、依次在 CustomConsumer、CustomConsumer1、CustomConsumer2 三个消费者代
码中修改分区分配策略为 RoundRobin
//RoundRobin 分区分配策略properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG,"org.apache.kafka.clients.consumer.RoundRobinAssignor");
②、重启 3 个消费者,重复发送消息的步骤,观看分区结果
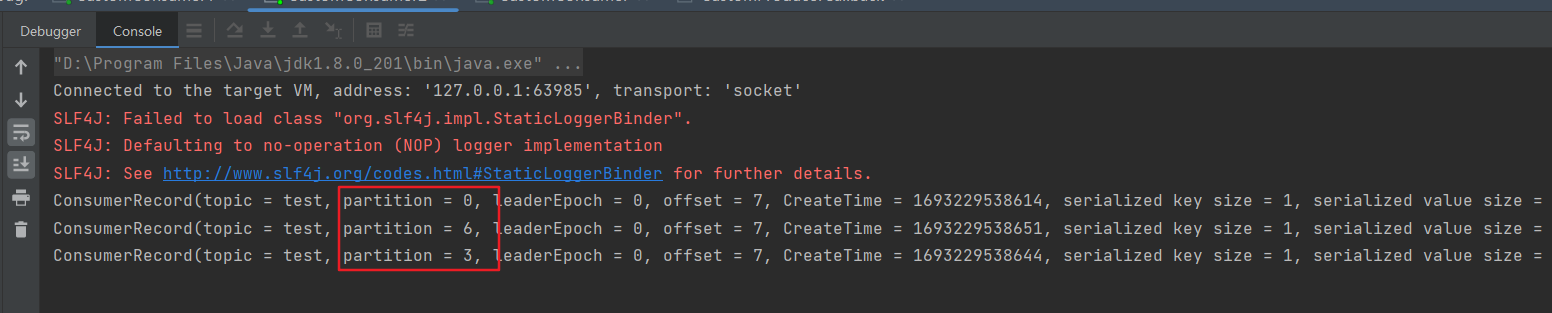

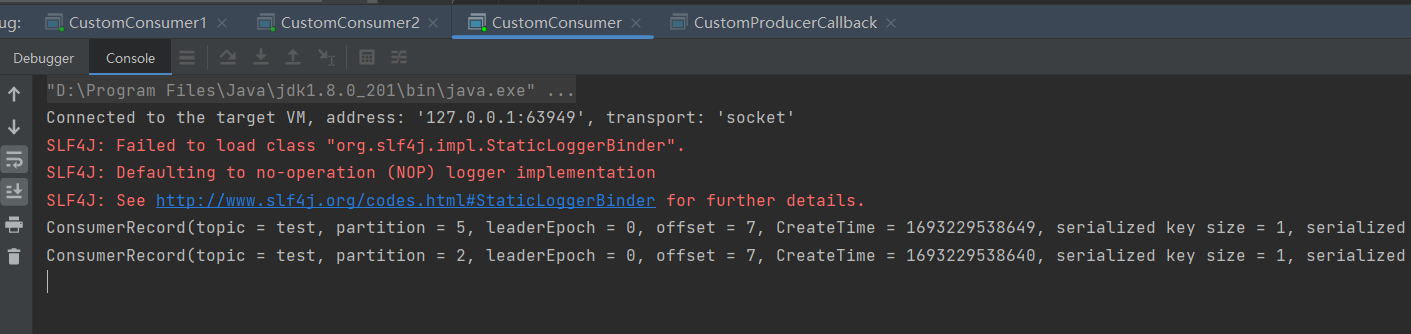
3)RoundRobin 分区分配再平衡案例
停止掉 0 号消费者,快速重新发送消息观看结果(45s 以内,越快越好)。
1 号消费者:消费到 2、5 号分区数据
2 号消费者:消费到 4、1 号分区数据
0 号消费者的任务会按照 RoundRobin 的方式,把数据轮询分成 0 和6 、 3 号分区数据,分别由 1 号消费者或者 2 号消费者消费。


说明:0 号消费者挂掉后,消费者组需要按照超时时间 45s 来判断它是否退出,所以需要等待,时间到了 45s 后,判断它真的退出就会把任务分配给其他 broker 执行
(2)再次重新发送消息观看结果(45s 以后)。
1 号消费者:消费到 0、2、4、6 号分区数据
2 号消费者:消费到 1、3、5 号分区数据
说明:消费者 0 已经被踢出消费者组,所以重新按照 RoundRobin 方式分配。
3 Sticky 以及再平衡
1) 定义
粘性分区定义:可以理解为分配的结果带有“粘性的”。即在执行一次新的分配之前,考虑上一次分配的结果,尽量少的调整分配的变动,可以节省大量的开销
2) Sticky 分区策略demo演示
3)Sticky 分区分配再平衡
5.5 offset位移
1、offset 的默认维护位置

__consumer_offsets 主题里面采用 key 和 value 的方式存储数据。key 是 group.id+topic+分区号,value 就是当前 offset 的值。每隔一段时间,kafka 内部会对这个 topic 进行compact,也就是每个 group.id+topic+分区号就保留最新数据
1)__consumer_offsets 查看
2、自动提交 offset
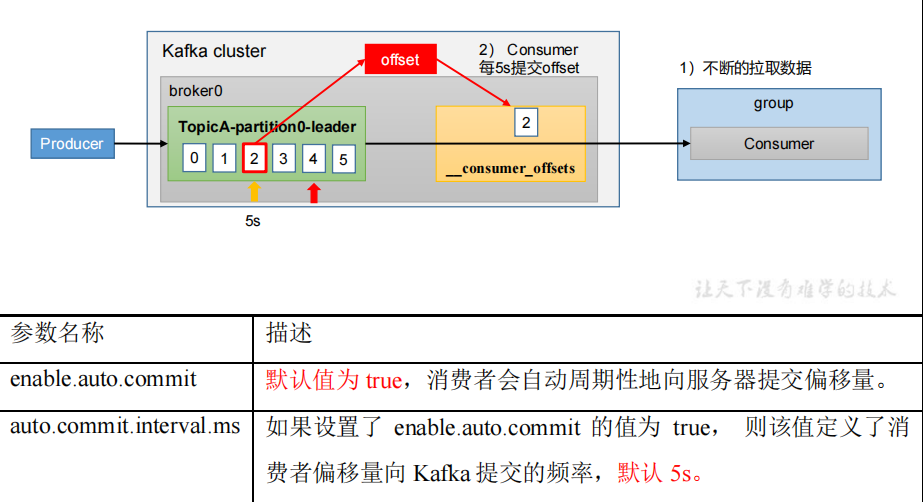
为了使我们能够专注于自己的业务逻辑,Kafka提供了自动提交offset的功能。
自动提交offset的相关参数:
- enable.auto.commit:是否开启自动提交offset功能,默认是true
- auto.commit.interval.ms:自动提交offset的时间间隔,默认是5s
1)消费者自动提交 offset
// 自动提交
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,true);
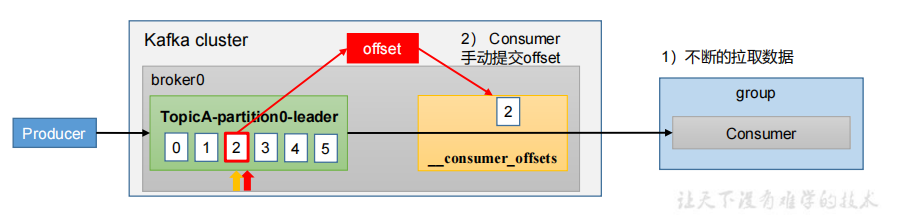
3、手动提交 offset
虽然自动提交offset十分简单便利,但由于其是基于时间提交的,开发人员难以把握offset提交的时机。因此Kafka还提供了手动提交offset的API
手动提交offset的方法有两种:分别是commitSync(同步提交)和commitAsync(异步提交)。
两者的相同点是,都会将本次提交的一批数据最高的偏移量提交;
不同点是,同步提交阻塞当前线程,一直到提交成功,并且会自动失败重试(由不可控因素导致,也会出现提交失败);而异步提交则没有失败重试机制,故有可能提交失败。
- commitSync(同步提交):必须等待offset提交完毕,再去消费下一批数据。
- commitAsync(异步提交) :发送完提交offset请求后,就开始消费下一批数据了。
1)同步提交 offset
由于同步提交 offset 有失败重试机制,故更加可靠,但是由于一直等待提交结果,提交的效率比较低。以下为同步提交 offset 的示例。
public class CustomConsumerByHandSync {public static void main(String[] args) {// 0 配置Properties properties = new Properties();// 连接 bootstrap.serversproperties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.239.11:9092");// 反序列化properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());// 配置消费者组idproperties.put(ConsumerConfig.GROUP_ID_CONFIG,"test");// 手动提交properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,false);// 1 创建一个消费者 "", "hello"KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties);// 2 订阅主题 firstArrayList<String> topics = new ArrayList<>();topics.add("first");kafkaConsumer.subscribe(topics);// 3 消费数据while (true){ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(1));for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {System.out.println(consumerRecord);}// 手动提交offsetkafkaConsumer.commitSync();}}
}2)异步提交 offset
虽然同步提交 offset 更可靠一些,但是由于其会阻塞当前线程,直到提交成功。因此吞吐量会受到很大的影响。因此更多的情况下,会选用异步提交 offset 的方式。
public class CustomConsumerByHandSync {public static void main(String[] args) {// 0 配置Properties properties = new Properties();// 连接 bootstrap.serversproperties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.239.11:9092");// 反序列化properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());// 配置消费者组idproperties.put(ConsumerConfig.GROUP_ID_CONFIG,"test");// 手动提交properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,false);// 1 创建一个消费者 "", "hello"KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties);// 2 订阅主题 firstArrayList<String> topics = new ArrayList<>();topics.add("first");kafkaConsumer.subscribe(topics);// 3 消费数据while (true){ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(1));for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {System.out.println(consumerRecord);}// 手动提交offsetkafkaConsumer.commitAsync();}}
}4、指定Offset进行消费
public class CustomConsumerSeek {public static void main(String[] args) {// 0 配置信息Properties properties = new Properties();properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.239.11:9092");properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());properties.put(ConsumerConfig.GROUP_ID_CONFIG,"test3");// 1 创建消费者KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties);// 2 订阅主题ArrayList<String> topics = new ArrayList<>();topics.add("second");kafkaConsumer.subscribe(topics);// 指定位置进行消费Set<TopicPartition> assignment = kafkaConsumer.assignment();// 保证分区分配方案已经制定完毕while (assignment.size() == 0){kafkaConsumer.poll(Duration.ofSeconds(1));assignment = kafkaConsumer.assignment();}// 指定消费的offsetfor (TopicPartition topicPartition : assignment) {kafkaConsumer.seek(topicPartition,100);}// 3 消费数据while (true){ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(1));for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {System.out.println(consumerRecord);}}}
}
5、指定时间进行消费
需求:在生产环境中,会遇到最近消费的几个小时数据异常,想重新按照时间消费。
例如要求按照时间消费前一天的数据,怎么处理?
6 、漏消费和重复消费
7 生产经验——数据积压
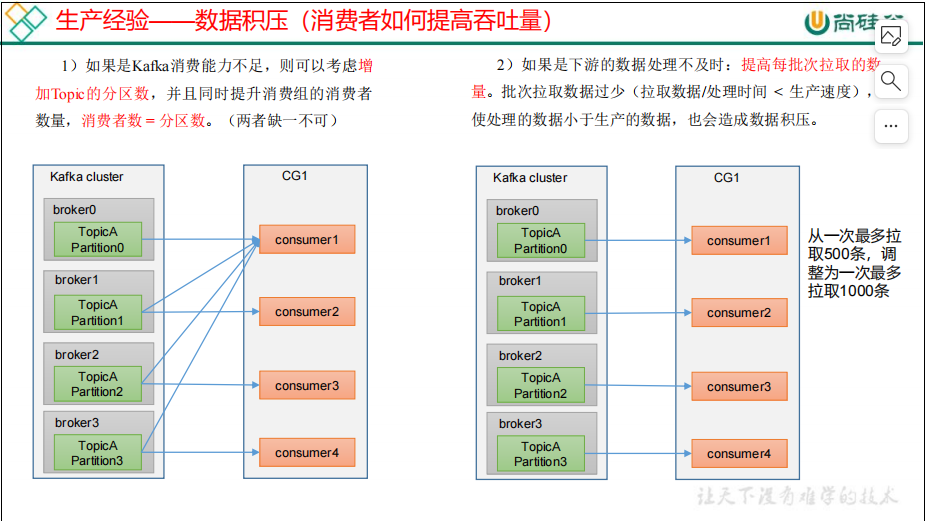

相关文章:
五、Kafka消费者
目录 5.1 Kafka的消费方式5.2 Kafka 消费者工作流程1、总体流程2、消费者组原理3、消费者组初始化流程4、消费者组详细消费流程 5.3 消费者API1 独立消费者案例(订阅主题)2 独立消费者案例(订阅分区)3 消费者组案例 5.4 生产经验—…...

类 中下的一些碎片知识点
判断下面两个函数是否能同时存在 void Print(); void Pirnt() const 答:能同时存在,因为构成函数重载(注意函数的返回值不同是不能构成函数重载的)。 const 对象能调用 非const 成员函数吗 答:不能,因为权…...

JVM第二篇 类加载子系统
JVM主要包含两个模块,类加载子系统和执行引擎,本篇博客将类加载子系统做一下梳理总结。 目录 1. 类加载子系统功能 2. 类加载子系统执行过程 2.1 加载 2.2 链接 2.3 初始化 3. 类加载器分类 3.1 引导类加载器 3.2 自定义加载器 3.2.1 自定义加载器实…...
火爆全网!HubSpot CRM全面集成,引爆营销业绩!
HubSpot CRM是什么?它是一款强大的客户关系管理工具,专为企业优化销售、服务和市场营销流程而设计。它在B2B行业中扮演着极为重要的角色,让我来告诉你为什么吧! HubSpot CRM不仅拥有用户友好的界面和强大的功能,还能够…...
远程调试环境
一、远程调试 1.安装vscode 2.打开vscode,下载插件Remote-SSH,用于远程连接 3.安装php debug 4.远程连接,连接到远端服务器 注:连接远程成功后,在远程依然要进行安装xdebug,刚才只是在vscode中进行的安装。 5.配置la…...
Java面试之用两个栈实现队列
文章目录 题目一、什么是队列和栈?1.1队列1.2栈 二、具体实现2.1 思路分析2.2代码实现 题目 用两个栈实现一个队列,实现在队列尾部插入节点和在队列头部删除节点的功能。 一、什么是队列和栈? 1.1队列 队列是一种特殊的线性表,…...

Python-实用的文件管理及操作
本章,来说说,个人写代码过程中,对于文件管理常用的几种操作。 三个维度 1、指定文件的路径拼接2、检查某文件是否存在3、配置文件的路径管理 1、指定文件的路径拼接 这个操作可以用来管理文件路径也就是上述中的第三点。但是,这里…...
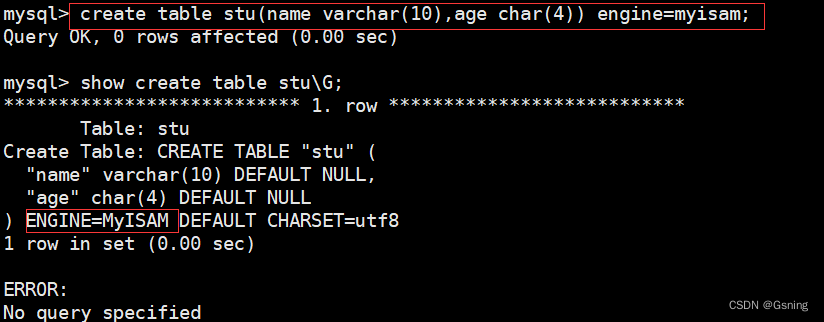
Mysql 事物与存储引擎
MySQL事务 MySQL 事务主要用于处理操作量大,复杂度高的数据。比如说,在人员管理系统中, 要删除一个人员,即需要删除人员的基本资料,又需要删除和该人员相关的信息,如信箱, 文章等等。这样&#…...

java.lang.classnotfoundexception: com.android.tools.lint.client.api.vendor
Unity Android studio打包报错修复 解决方式 java.lang.classnotfoundexception: com.android.tools.lint.client.api.vendor 解决方式 在 launcherTemplate 目录下找到 Android/lintOptions 选项 加上 checkReleaseBuilds false lintOptions { abortOnError false checkRelea…...

pytest fixture夹具,@pytest.fixture
fixture 是pytest 用于测试前后进行预备,清理工作的代码处理机制 fixture相对于setup 和teardown: fixure ,命名更加灵活,局限性比较小 conftest.py 配置里面可以实现数据共享,不需要import 就能自动找到一些配置 setu…...

YOLOv7源码解析
YOLOv7源码解析 YAML文件 YAML文件 以yolov7 cfg/yolov7-w6-pose.yaml为例: # parametersnc: 1 # number of classes nkpt: 4 # number of key points depth_multiple: 1.0 # model depth multiple width_multiple: 1.0 # layer channel multiple dw_conv_kpt:…...

2023高教社杯数学建模思路 - 复盘:校园消费行为分析
文章目录 0 赛题思路1 赛题背景2 分析目标3 数据说明4 数据预处理5 数据分析5.1 食堂就餐行为分析5.2 学生消费行为分析 建模资料 0 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 1 赛题背景 校园一卡通是集…...
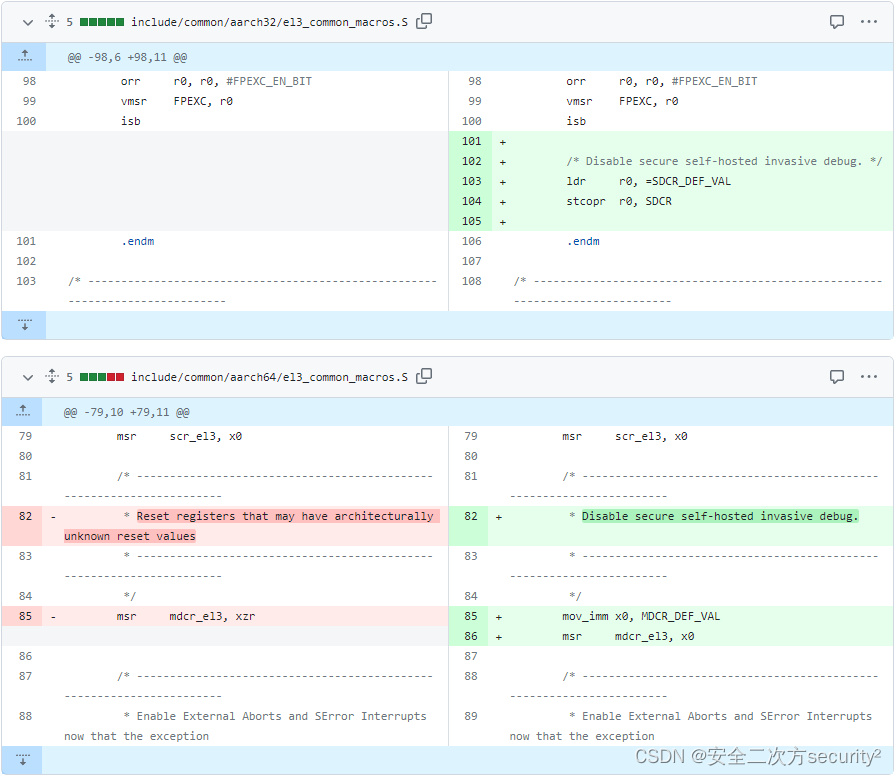
ATF(TF-A)安全通告 TFV-2 (CVE-2017-7564)
安全之安全(security)博客目录导读 ATF(TF-A)安全通告汇总 目录 一、ATF(TF-A)安全通告 TFV-2 (CVE-2017-7564) 二、 CVE-2017-7564 一、ATF(TF-A)安全通告 TFV-2 (CVE-2017-7564) Title 启用安全自托管侵入式调试接口,可允许非安全世界引发安全世界panic CV…...

无涯教程-PHP - 标量函数声明
在PHP 7中,引入了一个新函数,即标量类型声明。标量类型声明有两个选项- Coercive - 强制性是默认模式。Strict - 严格模式必须明确提示。 可以使用上述模式强制执行以下类型的函数参数- intfloatbooleanstringinterfacesarraycallable 强制模…...

动态规划(Dynamic programming)讲解(线性 DP 篇)
文章目录 动态规划(Dynamic Programing)第一关:线性DP第一战: C F 191 A . D y n a s t y P u z z l e s \color{7F25DF}{CF191A.\space Dynasty\enspace Puzzles} CF191A. DynastyPuzzles题目描述难度: ☆☆☆ \color…...

提升开发能力的低代码思路
一、低代码理念 在现代软件开发中,低代码开发平台备受关注。那么,什么是低代码开发平台呢?简单来说,它是一种能够提供丰富的图形化用户界面,让开发者通过拖拽组件和模型就能构建应用的开发环境。与传统开发方式相比&am…...
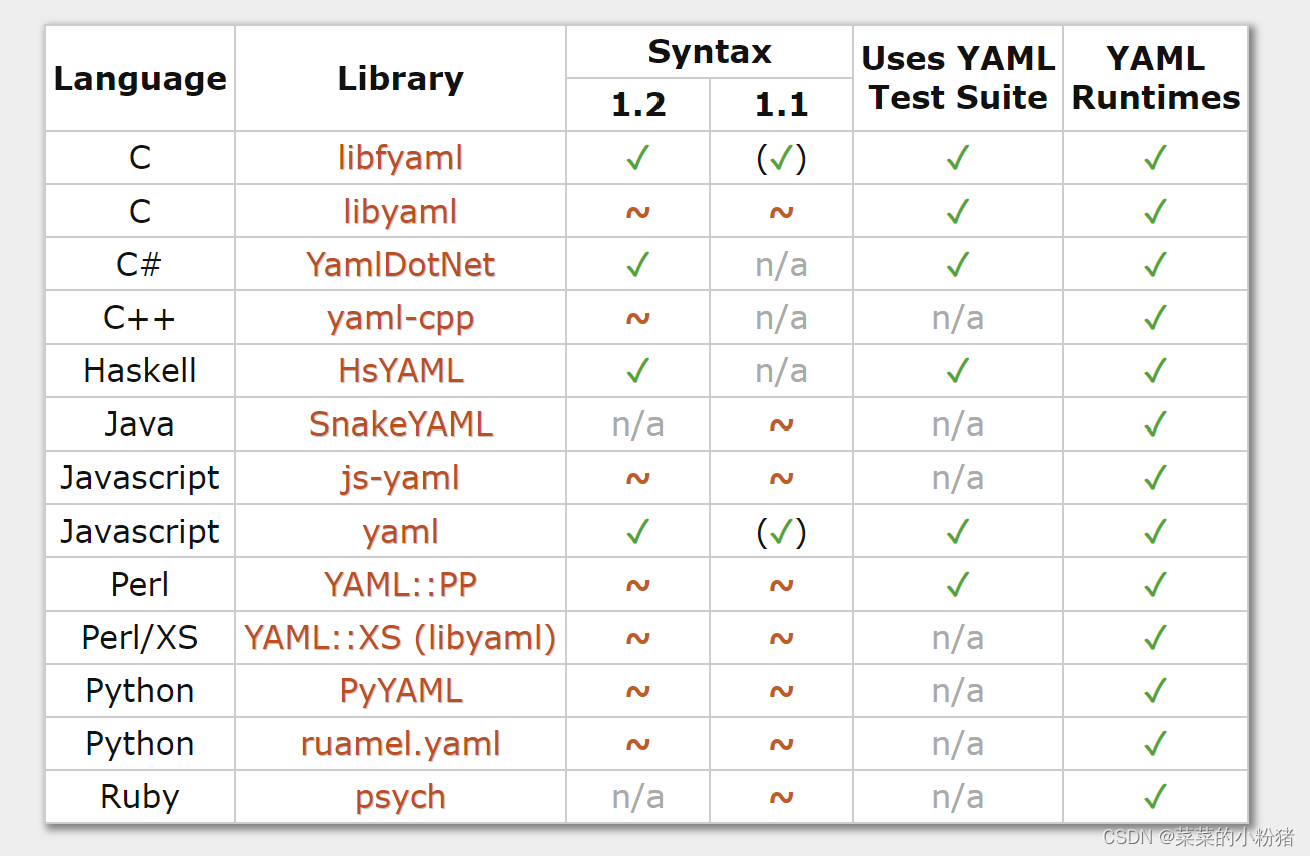
YAML详解及使用方法
YAML详解及使用方法 一、基本介绍二、数据类型2.1 纯量(scalars)/标量2.1.1 字符串2.1.2 保留换行(Newlines preserved)2.1.3 布尔值(Boolean)2.1.4 整数(Integer)2.1.5 浮点数(Floating Point)2.1.6 空(Nu…...
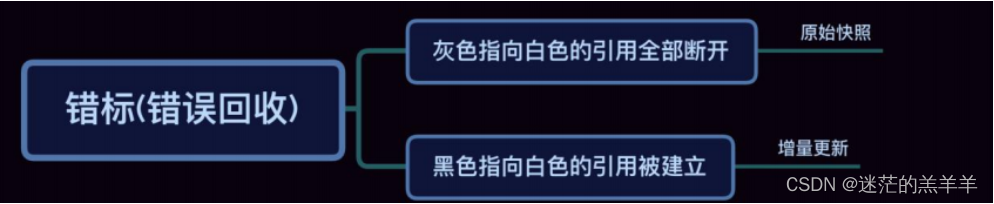
垃圾回收器
垃圾回收器就是垃圾回收的实践者,随着JDK的发展,垃圾回收器也在不断的更迭,在不同的场合下使用不同的垃圾回收器,这也是JVM调优的一部分。 1.垃圾回收器的分类 按线程可分为单线程(串行)垃圾回收器和多线程(并行)垃圾回收器。 按…...

SpringBoot 读取配置文件的值为 Infinity
1.配置信息 appid:6E212341234 2.获取方式 Value("${admin}")private String admin; 获取到结果 Infinity 3.修改方案 配置信息上加号 appid:‘6E212341234 yml中使用[单引号]不会转换单引号里面的特殊字符,使用""[双…...
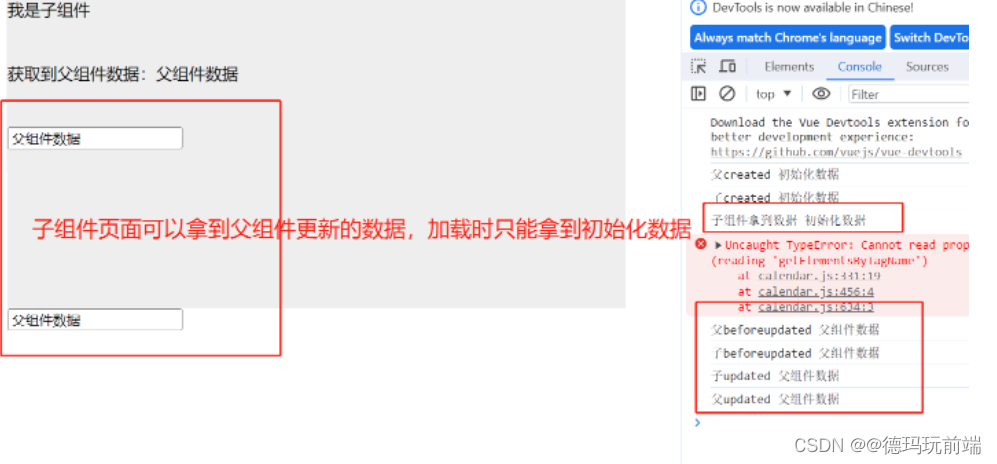
学习笔记230827--vue项目中,子组件拿不到父组件异步获取数据的问题
🧋 问题描述 父组件的数据是请求后台所得,因为是异步数据,就会出现,父组件的值传递过去了,子组件加载不到,拿不到值的问题。 下面从同步数据传递和异步数据传递开始论述问题 🧋🧋1…...

中科院空天院团队Geography and Sustainability:1985年至2022年各国人均耕地面积差距的扩大:对实现可持续发展目标的威胁
耕地作为粮食的载体,是保障粮食安全的关键要素。全球人口增长不可避免地导致耕地扩张以满足对食物、纤维和能源日益增长的需求,这给耕地的承载能力带来沉重负担,并加速了土壤退化与流失,对实现联合国可持续发展目标2(S…...

ElevenLabs支持闽南语吗?福建话语音合成实测:从API调用到音色克隆的7步通关手册
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs福建话语音支持现状与能力边界 ElevenLabs 目前尚未在官方语音模型库中提供对福建话(含闽南语、闽东语等分支)的原生支持。其公开文档与 API 文档均未列出任何以“Fuj…...

终极指南:免费开源的AMD Ryzen调试神器SMUDebugTool完整使用教程
终极指南:免费开源的AMD Ryzen调试神器SMUDebugTool完整使用教程 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: …...
)
Superpowers 总览与原理(通俗版)
一句话结论 Superpowers 不是一个“新模型”,而是一套“技能(skills) 启动引导(bootstrap)”的工作流层,用明确的流程和纪律约束智能体如何思考、如何拆解任务、如何实现与复核。 它是怎么用的(…...

CANN/asc-devkit:__hltu函数文档
__hltu 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com/can…...

读《AI时代成为行业精英的融合型学习法》
这段时间看了日本科普作家竹内熏写的《AI时代成为行业精英的融合型学习法》一书,想说说自己的体会。这是一本很薄的书,一共100来页,个人觉得,在现在这个什么都不会的小白也能用AI写出几万字文章的时代,这本书可以算得上…...

如何用 polyfill-iconv 处理中文编码?GBK、BIG5、UTF-8 转换终极指南
如何用 polyfill-iconv 处理中文编码?GBK、BIG5、UTF-8 转换终极指南 【免费下载链接】polyfill-iconv This component provides a native PHP implementation of the php.net/iconv functions. 项目地址: https://gitcode.com/gh_mirrors/po/polyfill-iconv …...

《CVPR2025-DEIM创新改进项目实战:从原理到部署的深度学习优化全攻略》020、从原理到部署的深度学习优化全攻略
CVPR2025-DEIM创新改进项目实战:从原理到部署的深度学习优化全攻略 020、DEIM在嵌入式设备上的部署:ONNX导出与TensorRT优化 一、凌晨三点的调试现场 上周五晚上,我盯着Jetson Orin的终端,看着DEIM模型推理速度卡在12.3ms纹丝不动。旁边同事的YOLOv8已经跑到3.2ms了,差…...

双榜第一!文心5.1登顶中文创意写作综合实力评测
【大力财经】5月18日,全球权威ICT领域市场研究机构Omdia发布《2026 年基础模型中文创意写作能力评估》报告,围绕中文创意写作七大核心维度,对 DeepSeek V4、文心5.1(ERNIE 5.1)、GPT 5.5 等 8大国内外主流顶级文本模型…...

如何在脑电信号处理的星辰大海中,找到你的开源坐标?[特殊字符]
如何在脑电信号处理的星辰大海中,找到你的开源坐标?🚀 【免费下载链接】eeglab EEGLAB is an open source signal processing environment for electrophysiological signals running on Matlab and developed at the SCCN/UCSD 项目地址: …...