hive表向es集群同步数据20230830
背景:实际开发中遇到一个需求,就是需要将hive表中的数据同步到es集群中,之前没有做过,查看一些帖子,发现有一种方案挺不错的,记录一下。
我的电脑环境如下
| 软件名称 | 版本 | |
|---|---|---|
| Hadoop | 3.3.0 | |
| hive | 3.1.3 | |
| jdk | 1.8 | |
| Elasticsearch | 7.10.2 | |
| kibana | 7.10.2 | |
| logstash | 7.10.2 | |
| ES-Hadoop | 7.10.2 |
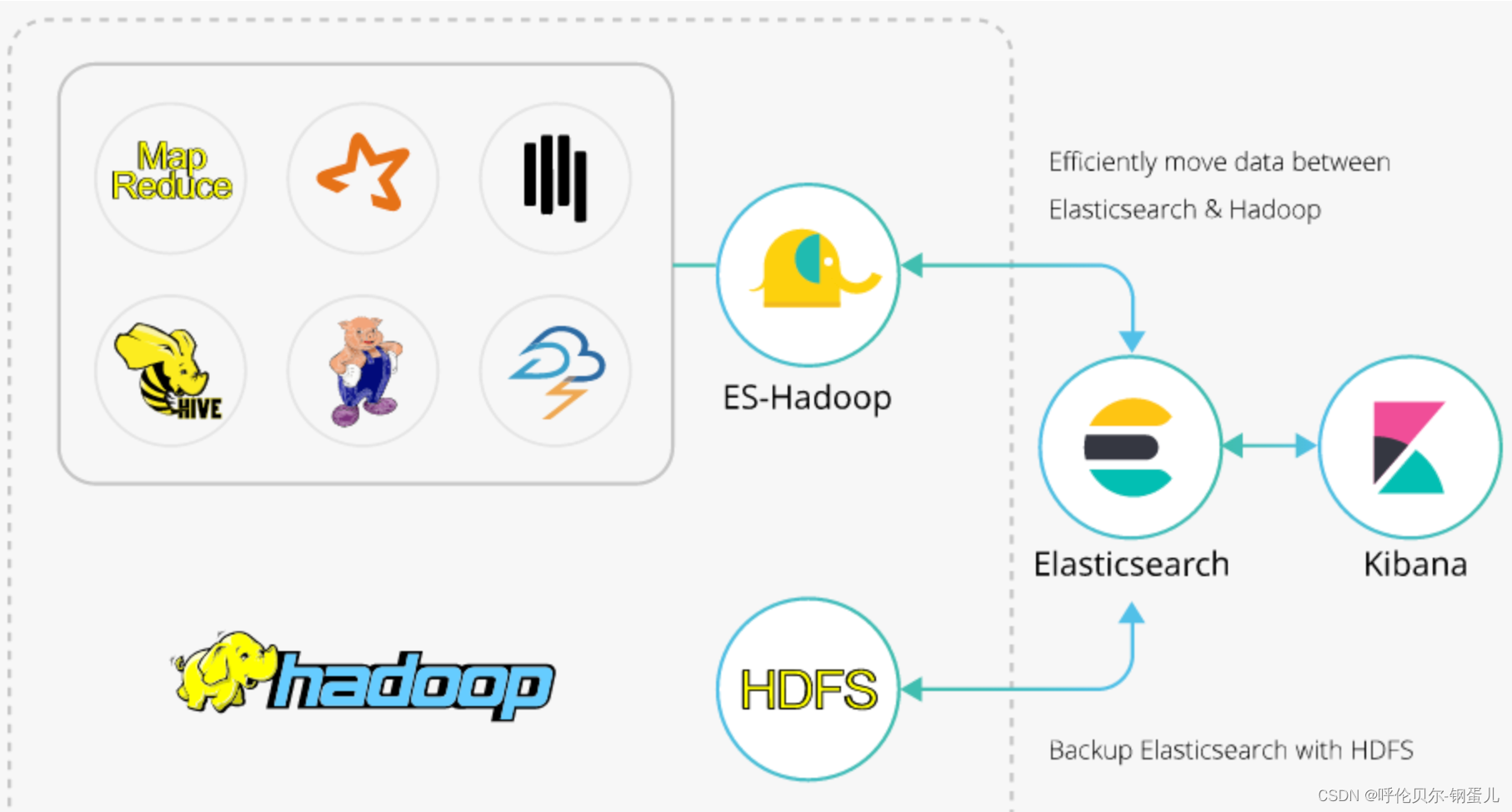
ES-Hadoop的引入
hadoop、hive和es的关系如下图,中间有一个组件叫做ES-Hadoop,是连接Hadoop和es的桥梁,es的官网上提供了这个组件,解决Hadoop和es之间的数据同步问题。
下面说一下数据同步的具体步骤
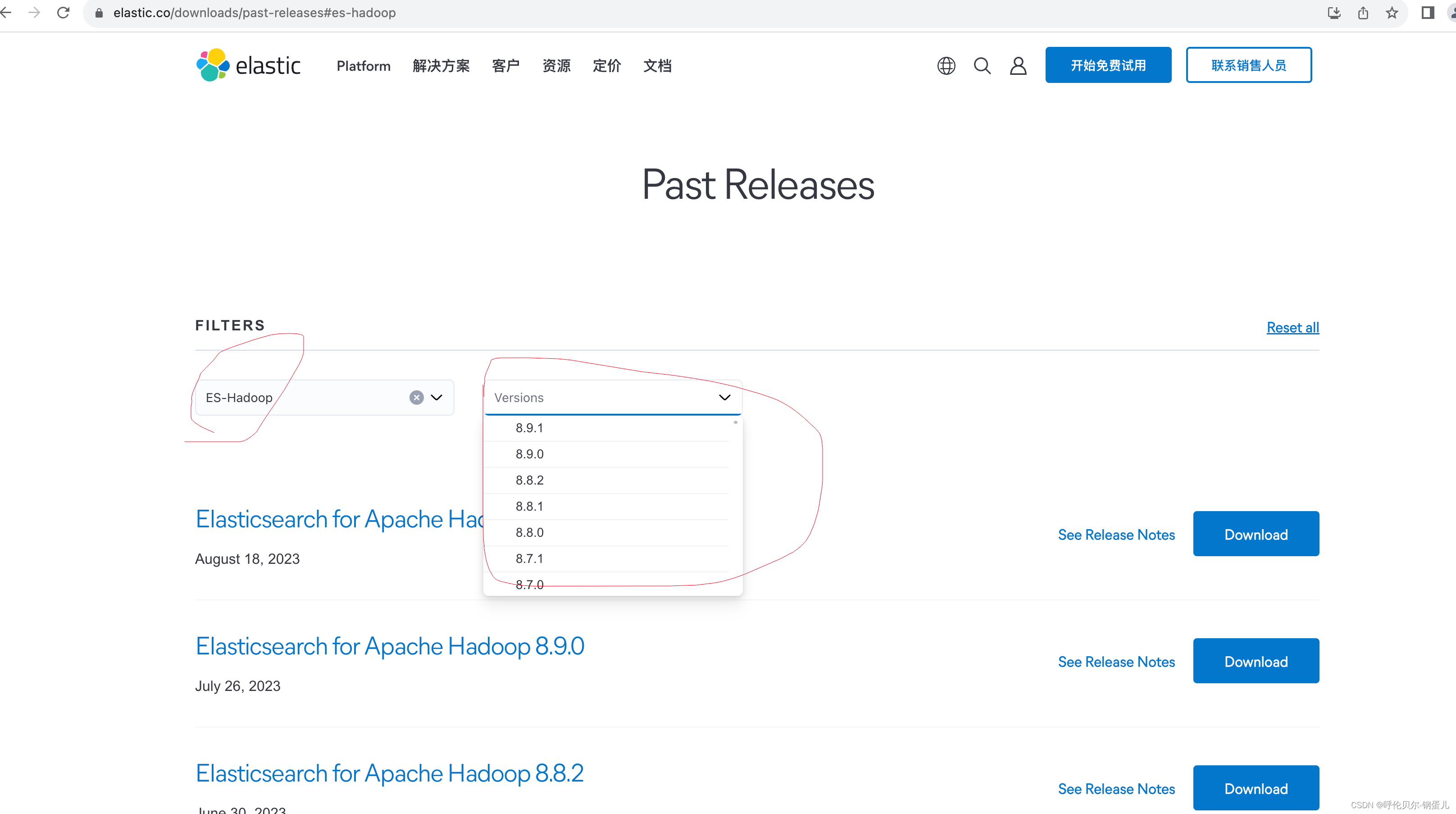
第一步:去es的官网上下载ES-Hadoop组件
注意:ES-Hadoop 的版本需要和es的版本是一致的
官网下载地址:es的官网链接-点我
在输入框中输入es-hadoop,在version版本处找到和你es相同的版本即可
第二步:上传这个安装包到集群上,解压完成后将其中的jar包上传到HDFS上你新建的目录
命令如下;
hadoop fs -put elasticsearch-hadoop-7.10.2.jar /user/hive/warehouse/es_hadoop/
第三步:将这个jar包添加到hive中
在hive的终端下输入如下命令
add jar hdfs:///user/hive/warehouse/es_hadoop/elasticsearch-hadoop-7.10.2.jar;
第四步:在hive中创建临时表,作为测试用
创建一个hive中的表,并且添加上测试数据
CREATE EXTERNAL TABLE `hive_test`(`name` string, `age` int, `hight` int)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES ( 'field.delim'=',', 'serialization.format'=',')
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION'hdfs://master:9000/user/hive/warehouse/pdata_dynamic.db/hive_test';
添加数据,展示如下
hive> select * from hive_test;
OK
吴占喜 30 175
令狐冲 50 180
任我行 60 160
第五步:创建hive到es的映射表
CREATE EXTERNAL TABLE `es_hadoop_cluster`(`name` string COMMENT 'from deserializer',`age` string COMMENT 'from deserializer',`hight` string COMMENT 'from deserializer')
ROW FORMAT SERDE'org.elasticsearch.hadoop.hive.EsSerDe'
STORED BY'org.elasticsearch.hadoop.hive.EsStorageHandler'
WITH SERDEPROPERTIES ('serialization.format'='1')
LOCATION'hdfs://master:9000/user/hive/warehouse/pdata_dynamic.db/es_hadoop_cluster'
TBLPROPERTIES ('bucketing_version'='2','es.batch.write.retry.count'='6','es.batch.write.retry.wait'='60s','es.index.auto.create'='TRUE','es.index.number_of_replicas'='0','es.index.refresh_interval'='-1','es.mapping.name'='name:name,age:age,hight:hight','es.nodes'='172.16.27.133:9200','es.nodes.wan.only'='TRUE','es.resource'='hive_to_es/_doc');
映射表的参数说明
| 参数 | 参数 | 参数说明 |
|---|---|---|
| bucketing_version | 2 | |
| es.batch.write.retry.count | 6 | |
| es.batch.write.retry.wait | 60s | |
| es.index.auto.create | TRUE | 通过Hadoop组件向Elasticsearch集群写入数据,是否自动创建不存在的index: true:自动创建 ; false:不会自动创建 |
| es.index.number_of_replicas | 0 | |
| es.index.refresh_interval | -1 | |
| es.mapping.name | 7.10.2 | hive和es集群字段映射 |
| es.nodes | 指定Elasticsearch实例的访问地址,建议使用内网地址。 | |
| es.nodes.wan.only | TRUE | 开启Elasticsearch集群在云上使用虚拟IP进行连接,是否进行节点嗅探: true:设置 ;false:不设置 |
| es.resource | 7.10.2 | es集群中索引名称 |
| es.nodes.discovery | TRUE | 是否禁用节点发现:true:禁用 ;false:不禁用 |
| es.input.use.sliced.partitions | TRUE | 是否使用slice分区: true:使用。设置为true,可能会导致索引在预读阶段的时间明显变长,有时会远远超出查询数据所耗费的时间。建议设置为false,以提高查询效率; false:不使用。 |
| es.read.metadata | FALSE | 操作Elasticsearch字段涉及到_id之类的内部字段,请开启此属性。 |
第六步:写同步SQL测试一下
同步SQL
insert into es_hadoop_cluster select * from hive_test;
结果报错了,nice,正好演示一下这个错误怎么解决
报错信息中有一行:Caused by: java.lang.ClassNotFoundException: org.elasticsearch.hadoop.hive.EsHiveInputFormat
报错原因:在hive中执行add jar xxx 这个命令,只在当前窗口下有效
解决方案:1.每次执行insert into的时候,执行下面的添加jar包的命令
add jar hdfs:///user/hive/warehouse/es_hadoop/elasticsearch-hadoop-7.10.2.jar;
2.将这个jar包作为永久的函数加载进来(后面在补充再补充一下)
Query ID = root_20230830041146_d125a01c-4174-48a5-8b9c-a15b41d27403
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1693326922484_0004, Tracking URL = http://master:8088/proxy/application_1693326922484_0004/
Kill Command = /root/soft/hadoop/hadoop-3.3.0//bin/mapred job -kill job_1693326922484_0004
Hadoop job information for Stage-2: number of mappers: 1; number of reducers: 0
2023-08-30 04:11:51,842 Stage-2 map = 0%, reduce = 0%
2023-08-30 04:12:45,532 Stage-2 map = 100%, reduce = 0%
Ended Job = job_1693326922484_0004 with errors
0 [582efbca-df6e-4f87-b4a4-5a5f03667fd9 main] ERROR org.apache.hadoop.hive.ql.exec.Task - Ended Job = job_1693326922484_0004 with errors
Error during job, obtaining debugging information...
1 [Thread-33] ERROR org.apache.hadoop.hive.ql.exec.Task - Error during job, obtaining debugging information...
Examining task ID: task_1693326922484_0004_m_000000 (and more) from job job_1693326922484_0004
3 [Thread-34] ERROR org.apache.hadoop.hive.ql.exec.Task - Examining task ID: task_1693326922484_0004_m_000000 (and more) from job job_1693326922484_0004Task with the most failures(4):
-----
Task ID:task_1693326922484_0004_m_000000URL:http://master:8088/taskdetails.jsp?jobid=job_1693326922484_0004&tipid=task_1693326922484_0004_m_000000
-----
Diagnostic Messages for this Task:
Error: java.lang.RuntimeException: Failed to load plan: hdfs://master:9000/tmp/hive/root/582efbca-df6e-4f87-b4a4-5a5f03667fd9/hive_2023-08-30_04-11-47_010_5312656494742717839-1/-mr-10002/ae1cf98b-a157-4266-92b3-7d618b411f00/map.xmlat org.apache.hadoop.hive.ql.exec.Utilities.getBaseWork(Utilities.java:502)at org.apache.hadoop.hive.ql.exec.Utilities.getMapWork(Utilities.java:335)at org.apache.hadoop.hive.ql.io.HiveInputFormat.init(HiveInputFormat.java:435)at org.apache.hadoop.hive.ql.io.HiveInputFormat.pushProjectionsAndFilters(HiveInputFormat.java:881)at org.apache.hadoop.hive.ql.io.HiveInputFormat.pushProjectionsAndFilters(HiveInputFormat.java:874)at org.apache.hadoop.hive.ql.io.CombineHiveInputFormat.getRecordReader(CombineHiveInputFormat.java:716)at org.apache.hadoop.mapred.MapTask$TrackedRecordReader.<init>(MapTask.java:175)at org.apache.hadoop.mapred.MapTask.runOldMapper(MapTask.java:444)at org.apache.hadoop.mapred.MapTask.run(MapTask.java:349)at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:178)at java.security.AccessController.doPrivileged(Native Method)at javax.security.auth.Subject.doAs(Subject.java:422)at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1845)at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:172)
Caused by: org.apache.hive.com.esotericsoftware.kryo.KryoException: Unable to find class: org.elasticsearch.hadoop.hive.EsHiveInputFormat
Serialization trace:
inputFileFormatClass (org.apache.hadoop.hive.ql.plan.TableDesc)
tableInfo (org.apache.hadoop.hive.ql.plan.FileSinkDesc)
conf (org.apache.hadoop.hive.ql.exec.vector.VectorFileSinkOperator)
childOperators (org.apache.hadoop.hive.ql.exec.vector.VectorSelectOperator)
childOperators (org.apache.hadoop.hive.ql.exec.TableScanOperator)
aliasToWork (org.apache.hadoop.hive.ql.plan.MapWork)at org.apache.hive.com.esotericsoftware.kryo.util.DefaultClassResolver.readName(DefaultClassResolver.java:156)at org.apache.hive.com.esotericsoftware.kryo.util.DefaultClassResolver.readClass(DefaultClassResolver.java:133)at org.apache.hive.com.esotericsoftware.kryo.Kryo.readClass(Kryo.java:670)at org.apache.hadoop.hive.ql.exec.SerializationUtilities$KryoWithHooks.readClass(SerializationUtilities.java:185)at org.apache.hive.com.esotericsoftware.kryo.serializers.DefaultSerializers$ClassSerializer.read(DefaultSerializers.java:326)at org.apache.hive.com.esotericsoftware.kryo.serializers.DefaultSerializers$ClassSerializer.read(DefaultSerializers.java:314)at org.apache.hive.com.esotericsoftware.kryo.Kryo.readObjectOrNull(Kryo.java:759)at org.apache.hadoop.hive.ql.exec.SerializationUtilities$KryoWithHooks.readObjectOrNull(SerializationUtilities.java:203)at org.apache.hive.com.esotericsoftware.kryo.serializers.ObjectField.read(ObjectField.java:132)at org.apache.hive.com.esotericsoftware.kryo.serializers.FieldSerializer.read(FieldSerializer.java:551)at org.apache.hive.com.esotericsoftware.kryo.Kryo.readObject(Kryo.java:708)at org.apache.hadoop.hive.ql.exec.SerializationUtilities$KryoWithHooks.readObject(SerializationUtilities.java:218)at org.apache.hive.com.esotericsoftware.kryo.serializers.ObjectField.read(ObjectField.java:125)at org.apache.hive.com.esotericsoftware.kryo.serializers.FieldSerializer.read(FieldSerializer.java:551)at org.apache.hive.com.esotericsoftware.kryo.Kryo.readObject(Kryo.java:708)at org.apache.hadoop.hive.ql.exec.SerializationUtilities$KryoWithHooks.readObject(SerializationUtilities.java:218)at org.apache.hive.com.esotericsoftware.kryo.serializers.ObjectField.read(ObjectField.java:125)at org.apache.hive.com.esotericsoftware.kryo.serializers.FieldSerializer.read(FieldSerializer.java:551)at org.apache.hive.com.esotericsoftware.kryo.Kryo.readClassAndObject(Kryo.java:790)at org.apache.hadoop.hive.ql.exec.SerializationUtilities$KryoWithHooks.readClassAndObject(SerializationUtilities.java:180)at org.apache.hive.com.esotericsoftware.kryo.serializers.CollectionSerializer.read(CollectionSerializer.java:134)at org.apache.hive.com.esotericsoftware.kryo.serializers.CollectionSerializer.read(CollectionSerializer.java:40)at org.apache.hive.com.esotericsoftware.kryo.Kryo.readObject(Kryo.java:708)at org.apache.hadoop.hive.ql.exec.SerializationUtilities$KryoWithHooks.readObject(SerializationUtilities.java:218)at org.apache.hive.com.esotericsoftware.kryo.serializers.ObjectField.read(ObjectField.java:125)at org.apache.hive.com.esotericsoftware.kryo.serializers.FieldSerializer.read(FieldSerializer.java:551)at org.apache.hive.com.esotericsoftware.kryo.Kryo.readClassAndObject(Kryo.java:790)at org.apache.hadoop.hive.ql.exec.SerializationUtilities$KryoWithHooks.readClassAndObject(SerializationUtilities.java:180)at org.apache.hive.com.esotericsoftware.kryo.serializers.CollectionSerializer.read(CollectionSerializer.java:134)at org.apache.hive.com.esotericsoftware.kryo.serializers.CollectionSerializer.read(CollectionSerializer.java:40)at org.apache.hive.com.esotericsoftware.kryo.Kryo.readObject(Kryo.java:708)at org.apache.hadoop.hive.ql.exec.SerializationUtilities$KryoWithHooks.readObject(SerializationUtilities.java:218)at org.apache.hive.com.esotericsoftware.kryo.serializers.ObjectField.read(ObjectField.java:125)at org.apache.hive.com.esotericsoftware.kryo.serializers.FieldSerializer.read(FieldSerializer.java:551)at org.apache.hive.com.esotericsoftware.kryo.Kryo.readClassAndObject(Kryo.java:790)at org.apache.hadoop.hive.ql.exec.SerializationUtilities$KryoWithHooks.readClassAndObject(SerializationUtilities.java:180)at org.apache.hive.com.esotericsoftware.kryo.serializers.MapSerializer.read(MapSerializer.java:161)at org.apache.hive.com.esotericsoftware.kryo.serializers.MapSerializer.read(MapSerializer.java:39)at org.apache.hive.com.esotericsoftware.kryo.Kryo.readObject(Kryo.java:708)at org.apache.hadoop.hive.ql.exec.SerializationUtilities$KryoWithHooks.readObject(SerializationUtilities.java:218)at org.apache.hive.com.esotericsoftware.kryo.serializers.ObjectField.read(ObjectField.java:125)at org.apache.hive.com.esotericsoftware.kryo.serializers.FieldSerializer.read(FieldSerializer.java:551)at org.apache.hive.com.esotericsoftware.kryo.Kryo.readObject(Kryo.java:686)at org.apache.hadoop.hive.ql.exec.SerializationUtilities$KryoWithHooks.readObject(SerializationUtilities.java:210)at org.apache.hadoop.hive.ql.exec.SerializationUtilities.deserializeObjectByKryo(SerializationUtilities.java:729)at org.apache.hadoop.hive.ql.exec.SerializationUtilities.deserializePlan(SerializationUtilities.java:613)at org.apache.hadoop.hive.ql.exec.SerializationUtilities.deserializePlan(SerializationUtilities.java:590)at org.apache.hadoop.hive.ql.exec.Utilities.getBaseWork(Utilities.java:463)... 13 more
Caused by: java.lang.ClassNotFoundException: org.elasticsearch.hadoop.hive.EsHiveInputFormatat java.net.URLClassLoader.findClass(URLClassLoader.java:387)at java.lang.ClassLoader.loadClass(ClassLoader.java:418)at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:355)at java.lang.ClassLoader.loadClass(ClassLoader.java:351)at java.lang.Class.forName0(Native Method)at java.lang.Class.forName(Class.java:348)at org.apache.hive.com.esotericsoftware.kryo.util.DefaultClassResolver.readName(DefaultClassResolver.java:154)... 60 more98 [Thread-33] ERROR org.apache.hadoop.hive.ql.exec.Task -
Task with the most failures(4):
-----
Task ID:task_1693326922484_0004_m_000000URL:http://master:8088/taskdetails.jsp?jobid=job_1693326922484_0004&tipid=task_1693326922484_0004_m_000000
-----
Diagnostic Messages for this Task:
Error: java.lang.RuntimeException: Failed to load plan: hdfs://master:9000/tmp/hive/root/582efbca-df6e-4f87-b4a4-5a5f03667fd9/hive_2023-08-30_04-11-47_010_5312656494742717839-1/-mr-10002/ae1cf98b-a157-4266-92b3-7d618b411f00/map.xmlat org.apache.hadoop.hive.ql.exec.Utilities.getBaseWork(Utilities.java:502)at org.apache.hadoop.hive.ql.exec.Utilities.getMapWork(Utilities.java:335)at org.apache.hadoop.hive.ql.io.HiveInputFormat.init(HiveInputFormat.java:435)at org.apache.hadoop.hive.ql.io.HiveInputFormat.pushProjectionsAndFilters(HiveInputFormat.java:881)at org.apache.hadoop.hive.ql.io.HiveInputFormat.pushProjectionsAndFilters(HiveInputFormat.java:874)at org.apache.hadoop.hive.ql.io.CombineHiveInputFormat.getRecordReader(CombineHiveInputFormat.java:716)at org.apache.hadoop.mapred.MapTask$TrackedRecordReader.<init>(MapTask.java:175)at org.apache.hadoop.mapred.MapTask.runOldMapper(MapTask.java:444)at org.apache.hadoop.mapred.MapTask.run(MapTask.java:349)at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:178)at java.security.AccessController.doPrivileged(Native Method)at javax.security.auth.Subject.doAs(Subject.java:422)at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1845)at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:172)
Caused by: org.apache.hive.com.esotericsoftware.kryo.KryoException: Unable to find class: org.elasticsearch.hadoop.hive.EsHiveInputFormat
Serialization trace:
inputFileFormatClass (org.apache.hadoop.hive.ql.plan.TableDesc)
tableInfo (org.apache.hadoop.hive.ql.plan.FileSinkDesc)
conf (org.apache.hadoop.hive.ql.exec.vector.VectorFileSinkOperator)
childOperators (org.apache.hadoop.hive.ql.exec.vector.VectorSelectOperator)
childOperators (org.apache.hadoop.hive.ql.exec.TableScanOperator)
aliasToWork (org.apache.hadoop.hive.ql.plan.MapWork)at org.apache.hive.com.esotericsoftware.kryo.util.DefaultClassResolver.readName(DefaultClassResolver.java:156)at org.apache.hive.com.esotericsoftware.kryo.util.DefaultClassResolver.readClass(DefaultClassResolver.java:133)at org.apache.hive.com.esotericsoftware.kryo.Kryo.readClass(Kryo.java:670)at org.apache.hadoop.hive.ql.exec.SerializationUtilities$KryoWithHooks.readClass(SerializationUtilities.java:185)at org.apache.hive.com.esotericsoftware.kryo.serializers.DefaultSerializers$ClassSerializer.read(DefaultSerializers.java:326)at org.apache.hive.com.esotericsoftware.kryo.serializers.DefaultSerializers$ClassSerializer.read(DefaultSerializers.java:314)at org.apache.hive.com.esotericsoftware.kryo.Kryo.readObjectOrNull(Kryo.java:759)at org.apache.hadoop.hive.ql.exec.SerializationUtilities$KryoWithHooks.readObjectOrNull(SerializationUtilities.java:203)at org.apache.hive.com.esotericsoftware.kryo.serializers.ObjectField.read(ObjectField.java:132)at org.apache.hive.com.esotericsoftware.kryo.serializers.FieldSerializer.read(FieldSerializer.java:551)at org.apache.hive.com.esotericsoftware.kryo.Kryo.readObject(Kryo.java:708)at org.apache.hadoop.hive.ql.exec.SerializationUtilities$KryoWithHooks.readObject(SerializationUtilities.java:218)at org.apache.hive.com.esotericsoftware.kryo.serializers.ObjectField.read(ObjectField.java:125)at org.apache.hive.com.esotericsoftware.kryo.serializers.FieldSerializer.read(FieldSerializer.java:551)at org.apache.hive.com.esotericsoftware.kryo.Kryo.readObject(Kryo.java:708)at org.apache.hadoop.hive.ql.exec.SerializationUtilities$KryoWithHooks.readObject(SerializationUtilities.java:218)at org.apache.hive.com.esotericsoftware.kryo.serializers.ObjectField.read(ObjectField.java:125)at org.apache.hive.com.esotericsoftware.kryo.serializers.FieldSerializer.read(FieldSerializer.java:551)at org.apache.hive.com.esotericsoftware.kryo.Kryo.readClassAndObject(Kryo.java:790)at org.apache.hadoop.hive.ql.exec.SerializationUtilities$KryoWithHooks.readClassAndObject(SerializationUtilities.java:180)at org.apache.hive.com.esotericsoftware.kryo.serializers.CollectionSerializer.read(CollectionSerializer.java:134)at org.apache.hive.com.esotericsoftware.kryo.serializers.CollectionSerializer.read(CollectionSerializer.java:40)at org.apache.hive.com.esotericsoftware.kryo.Kryo.readObject(Kryo.java:708)at org.apache.hadoop.hive.ql.exec.SerializationUtilities$KryoWithHooks.readObject(SerializationUtilities.java:218)at org.apache.hive.com.esotericsoftware.kryo.serializers.ObjectField.read(ObjectField.java:125)at org.apache.hive.com.esotericsoftware.kryo.serializers.FieldSerializer.read(FieldSerializer.java:551)at org.apache.hive.com.esotericsoftware.kryo.Kryo.readClassAndObject(Kryo.java:790)at org.apache.hadoop.hive.ql.exec.SerializationUtilities$KryoWithHooks.readClassAndObject(SerializationUtilities.java:180)at org.apache.hive.com.esotericsoftware.kryo.serializers.CollectionSerializer.read(CollectionSerializer.java:134)at org.apache.hive.com.esotericsoftware.kryo.serializers.CollectionSerializer.read(CollectionSerializer.java:40)at org.apache.hive.com.esotericsoftware.kryo.Kryo.readObject(Kryo.java:708)at org.apache.hadoop.hive.ql.exec.SerializationUtilities$KryoWithHooks.readObject(SerializationUtilities.java:218)at org.apache.hive.com.esotericsoftware.kryo.serializers.ObjectField.read(ObjectField.java:125)at org.apache.hive.com.esotericsoftware.kryo.serializers.FieldSerializer.read(FieldSerializer.java:551)at org.apache.hive.com.esotericsoftware.kryo.Kryo.readClassAndObject(Kryo.java:790)at org.apache.hadoop.hive.ql.exec.SerializationUtilities$KryoWithHooks.readClassAndObject(SerializationUtilities.java:180)at org.apache.hive.com.esotericsoftware.kryo.serializers.MapSerializer.read(MapSerializer.java:161)at org.apache.hive.com.esotericsoftware.kryo.serializers.MapSerializer.read(MapSerializer.java:39)at org.apache.hive.com.esotericsoftware.kryo.Kryo.readObject(Kryo.java:708)at org.apache.hadoop.hive.ql.exec.SerializationUtilities$KryoWithHooks.readObject(SerializationUtilities.java:218)at org.apache.hive.com.esotericsoftware.kryo.serializers.ObjectField.read(ObjectField.java:125)at org.apache.hive.com.esotericsoftware.kryo.serializers.FieldSerializer.read(FieldSerializer.java:551)at org.apache.hive.com.esotericsoftware.kryo.Kryo.readObject(Kryo.java:686)at org.apache.hadoop.hive.ql.exec.SerializationUtilities$KryoWithHooks.readObject(SerializationUtilities.java:210)at org.apache.hadoop.hive.ql.exec.SerializationUtilities.deserializeObjectByKryo(SerializationUtilities.java:729)at org.apache.hadoop.hive.ql.exec.SerializationUtilities.deserializePlan(SerializationUtilities.java:613)at org.apache.hadoop.hive.ql.exec.SerializationUtilities.deserializePlan(SerializationUtilities.java:590)at org.apache.hadoop.hive.ql.exec.Utilities.getBaseWork(Utilities.java:463)... 13 more
Caused by: java.lang.ClassNotFoundException: org.elasticsearch.hadoop.hive.EsHiveInputFormatat java.net.URLClassLoader.findClass(URLClassLoader.java:387)at java.lang.ClassLoader.loadClass(ClassLoader.java:418)at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:355)at java.lang.ClassLoader.loadClass(ClassLoader.java:351)at java.lang.Class.forName0(Native Method)at java.lang.Class.forName(Class.java:348)at org.apache.hive.com.esotericsoftware.kryo.util.DefaultClassResolver.readName(DefaultClassResolver.java:154)... 60 moreFAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask
106 [582efbca-df6e-4f87-b4a4-5a5f03667fd9 main] ERROR org.apache.hadoop.hive.ql.Driver - FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask
MapReduce Jobs Launched:
Stage-Stage-2: Map: 1 HDFS Read: 0 HDFS Write: 0 FAIL
Total MapReduce CPU Time Spent: 0 msec
将jar包添加进来又报错了,very nice,正好在演示一下这个错误,😄
报错如下所示
报错原因分析:仔细看这行Error: java.lang.ClassNotFoundException: org.apache.commons.httpclient.HttpConnectionManager,原因是缺少httpclient.的jar包导致的
解决方案:将httpclient.的jar包像上面的es-hadoop的jar包一样导入即可
hive> insert into es_hadoop_cluster select * from hive_test;
Query ID = root_20230830041906_20c85a80-072a-4023-b5ab-8b532e5db092
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1693326922484_0005, Tracking URL = http://master:8088/proxy/application_1693326922484_0005/
Kill Command = /root/soft/hadoop/hadoop-3.3.0//bin/mapred job -kill job_1693326922484_0005
Hadoop job information for Stage-2: number of mappers: 1; number of reducers: 0
2023-08-30 04:19:15,561 Stage-2 map = 0%, reduce = 0%
2023-08-30 04:19:34,095 Stage-2 map = 100%, reduce = 0%
Ended Job = job_1693326922484_0005 with errors
408543 [582efbca-df6e-4f87-b4a4-5a5f03667fd9 main] ERROR org.apache.hadoop.hive.ql.exec.Task - Ended Job = job_1693326922484_0005 with errors
Error during job, obtaining debugging information...
408543 [Thread-57] ERROR org.apache.hadoop.hive.ql.exec.Task - Error during job, obtaining debugging information...
Examining task ID: task_1693326922484_0005_m_000000 (and more) from job job_1693326922484_0005
408547 [Thread-58] ERROR org.apache.hadoop.hive.ql.exec.Task - Examining task ID: task_1693326922484_0005_m_000000 (and more) from job job_1693326922484_0005Task with the most failures(4):
-----
Task ID:task_1693326922484_0005_m_000000URL:http://master:8088/taskdetails.jsp?jobid=job_1693326922484_0005&tipid=task_1693326922484_0005_m_000000
-----
Diagnostic Messages for this Task:
Error: java.lang.ClassNotFoundException: org.apache.commons.httpclient.HttpConnectionManagerat java.net.URLClassLoader.findClass(URLClassLoader.java:387)at java.lang.ClassLoader.loadClass(ClassLoader.java:418)at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:355)at java.lang.ClassLoader.loadClass(ClassLoader.java:351)at org.elasticsearch.hadoop.rest.commonshttp.CommonsHttpTransportFactory.create(CommonsHttpTransportFactory.java:40)at org.elasticsearch.hadoop.rest.NetworkClient.selectNextNode(NetworkClient.java:99)at org.elasticsearch.hadoop.rest.NetworkClient.<init>(NetworkClient.java:82)at org.elasticsearch.hadoop.rest.NetworkClient.<init>(NetworkClient.java:58)at org.elasticsearch.hadoop.rest.RestClient.<init>(RestClient.java:101)at org.elasticsearch.hadoop.rest.RestService.createWriter(RestService.java:620)at org.elasticsearch.hadoop.mr.EsOutputFormat$EsRecordWriter.init(EsOutputFormat.java:175)at org.elasticsearch.hadoop.hive.EsHiveOutputFormat$EsHiveRecordWriter.write(EsHiveOutputFormat.java:59)at org.apache.hadoop.hive.ql.exec.FileSinkOperator.process(FileSinkOperator.java:987)at org.apache.hadoop.hive.ql.exec.vector.VectorFileSinkOperator.process(VectorFileSinkOperator.java:111)at org.apache.hadoop.hive.ql.exec.Operator.vectorForward(Operator.java:966)at org.apache.hadoop.hive.ql.exec.Operator.forward(Operator.java:939)at org.apache.hadoop.hive.ql.exec.vector.VectorSelectOperator.process(VectorSelectOperator.java:158)at org.apache.hadoop.hive.ql.exec.Operator.vectorForward(Operator.java:966)at org.apache.hadoop.hive.ql.exec.Operator.forward(Operator.java:939)at org.apache.hadoop.hive.ql.exec.TableScanOperator.process(TableScanOperator.java:125)at org.apache.hadoop.hive.ql.exec.vector.VectorMapOperator.closeOp(VectorMapOperator.java:990)at org.apache.hadoop.hive.ql.exec.Operator.close(Operator.java:733)at org.apache.hadoop.hive.ql.exec.mr.ExecMapper.close(ExecMapper.java:193)at org.apache.hadoop.mapred.MapRunner.run(MapRunner.java:61)at org.apache.hadoop.hive.ql.exec.mr.ExecMapRunner.run(ExecMapRunner.java:37)at org.apache.hadoop.mapred.MapTask.runOldMapper(MapTask.java:465)at org.apache.hadoop.mapred.MapTask.run(MapTask.java:349)at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:178)at java.security.AccessController.doPrivileged(Native Method)at javax.security.auth.Subject.doAs(Subject.java:422)at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1845)at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:172)408555 [Thread-57] ERROR org.apache.hadoop.hive.ql.exec.Task -
Task with the most failures(4):
-----
Task ID:task_1693326922484_0005_m_000000URL:http://master:8088/taskdetails.jsp?jobid=job_1693326922484_0005&tipid=task_1693326922484_0005_m_000000
-----
Diagnostic Messages for this Task:
Error: java.lang.ClassNotFoundException: org.apache.commons.httpclient.HttpConnectionManagerat java.net.URLClassLoader.findClass(URLClassLoader.java:387)at java.lang.ClassLoader.loadClass(ClassLoader.java:418)at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:355)at java.lang.ClassLoader.loadClass(ClassLoader.java:351)at org.elasticsearch.hadoop.rest.commonshttp.CommonsHttpTransportFactory.create(CommonsHttpTransportFactory.java:40)at org.elasticsearch.hadoop.rest.NetworkClient.selectNextNode(NetworkClient.java:99)at org.elasticsearch.hadoop.rest.NetworkClient.<init>(NetworkClient.java:82)at org.elasticsearch.hadoop.rest.NetworkClient.<init>(NetworkClient.java:58)at org.elasticsearch.hadoop.rest.RestClient.<init>(RestClient.java:101)at org.elasticsearch.hadoop.rest.RestService.createWriter(RestService.java:620)at org.elasticsearch.hadoop.mr.EsOutputFormat$EsRecordWriter.init(EsOutputFormat.java:175)at org.elasticsearch.hadoop.hive.EsHiveOutputFormat$EsHiveRecordWriter.write(EsHiveOutputFormat.java:59)at org.apache.hadoop.hive.ql.exec.FileSinkOperator.process(FileSinkOperator.java:987)at org.apache.hadoop.hive.ql.exec.vector.VectorFileSinkOperator.process(VectorFileSinkOperator.java:111)at org.apache.hadoop.hive.ql.exec.Operator.vectorForward(Operator.java:966)at org.apache.hadoop.hive.ql.exec.Operator.forward(Operator.java:939)at org.apache.hadoop.hive.ql.exec.vector.VectorSelectOperator.process(VectorSelectOperator.java:158)at org.apache.hadoop.hive.ql.exec.Operator.vectorForward(Operator.java:966)at org.apache.hadoop.hive.ql.exec.Operator.forward(Operator.java:939)at org.apache.hadoop.hive.ql.exec.TableScanOperator.process(TableScanOperator.java:125)at org.apache.hadoop.hive.ql.exec.vector.VectorMapOperator.closeOp(VectorMapOperator.java:990)at org.apache.hadoop.hive.ql.exec.Operator.close(Operator.java:733)at org.apache.hadoop.hive.ql.exec.mr.ExecMapper.close(ExecMapper.java:193)at org.apache.hadoop.mapred.MapRunner.run(MapRunner.java:61)at org.apache.hadoop.hive.ql.exec.mr.ExecMapRunner.run(ExecMapRunner.java:37)at org.apache.hadoop.mapred.MapTask.runOldMapper(MapTask.java:465)at org.apache.hadoop.mapred.MapTask.run(MapTask.java:349)at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:178)at java.security.AccessController.doPrivileged(Native Method)at javax.security.auth.Subject.doAs(Subject.java:422)at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1845)at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:172)FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask
408563 [582efbca-df6e-4f87-b4a4-5a5f03667fd9 main] ERROR org.apache.hadoop.hive.ql.Driver - FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask
MapReduce Jobs Launched:
Stage-Stage-2: Map: 1 HDFS Read: 0 HDFS Write: 0 FAIL
Total MapReduce CPU Time Spent: 0 msec
在hive的终端下,添加上httpclient的jar包,然后重新执行insert语句
命令如下;
add jar hdfs:///user/hive/warehouse/es_hadoop/commons-httpclient-3.1.jar;
执行成功喽,😄
hive> insert into es_hadoop_cluster select * from hive_test;
Query ID = root_20230830043006_1cf3a042-e5e4-4bec-8cee-49e670ac9b49
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1693326922484_0006, Tracking URL = http://master:8088/proxy/application_1693326922484_0006/
Kill Command = /root/soft/hadoop/hadoop-3.3.0//bin/mapred job -kill job_1693326922484_0006
Hadoop job information for Stage-2: number of mappers: 1; number of reducers: 0
2023-08-30 04:30:17,504 Stage-2 map = 0%, reduce = 0%
2023-08-30 04:30:21,633 Stage-2 map = 100%, reduce = 0%, Cumulative CPU 0.79 sec
MapReduce Total cumulative CPU time: 790 msec
Ended Job = job_1693326922484_0006
MapReduce Jobs Launched:
Stage-Stage-2: Map: 1 Cumulative CPU: 0.79 sec HDFS Read: 6234 HDFS Write: 0 SUCCESS
Total MapReduce CPU Time Spent: 790 msec
OK
Time taken: 16.482 seconds
第七步:查询一下映射表,并去es集群上查询数据是否同步成功了
1.查询映射表
nice,又报错了,报错如下;
报错原因分析:我之前做的时候,将解压的所有包都放在hive的lib目录下了,现在看来,只需要一个即可,将其余的都删除
解决方案:删除多余的jar包在hive的lib的目录下
hive> select * from es_hadoop_cluster;
OK
Exception in thread "main" java.lang.ExceptionInInitializerErrorat org.elasticsearch.hadoop.rest.RestService.findPartitions(RestService.java:216)at org.elasticsearch.hadoop.mr.EsInputFormat.getSplits(EsInputFormat.java:414)at org.elasticsearch.hadoop.hive.EsHiveInputFormat.getSplits(EsHiveInputFormat.java:115)at org.elasticsearch.hadoop.hive.EsHiveInputFormat.getSplits(EsHiveInputFormat.java:51)at org.apache.hadoop.hive.ql.exec.FetchOperator.generateWrappedSplits(FetchOperator.java:425)at org.apache.hadoop.hive.ql.exec.FetchOperator.getNextSplits(FetchOperator.java:395)at org.apache.hadoop.hive.ql.exec.FetchOperator.getRecordReader(FetchOperator.java:314)at org.apache.hadoop.hive.ql.exec.FetchOperator.getNextRow(FetchOperator.java:540)at org.apache.hadoop.hive.ql.exec.FetchOperator.pushRow(FetchOperator.java:509)at org.apache.hadoop.hive.ql.exec.FetchTask.fetch(FetchTask.java:146)at org.apache.hadoop.hive.ql.Driver.getResults(Driver.java:2691)at org.apache.hadoop.hive.ql.reexec.ReExecDriver.getResults(ReExecDriver.java:229)at org.apache.hadoop.hive.cli.CliDriver.processLocalCmd(CliDriver.java:259)at org.apache.hadoop.hive.cli.CliDriver.processCmd(CliDriver.java:188)at org.apache.hadoop.hive.cli.CliDriver.processLine(CliDriver.java:402)at org.apache.hadoop.hive.cli.CliDriver.executeDriver(CliDriver.java:821)at org.apache.hadoop.hive.cli.CliDriver.run(CliDriver.java:759)at org.apache.hadoop.hive.cli.CliDriver.main(CliDriver.java:683)at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)at java.lang.reflect.Method.invoke(Method.java:498)at org.apache.hadoop.util.RunJar.run(RunJar.java:323)at org.apache.hadoop.util.RunJar.main(RunJar.java:236)
Caused by: java.lang.RuntimeException: Multiple ES-Hadoop versions detected in the classpath; please use only one
jar:file:/root/soft/hive/apache-hive-3.1.3-bin/lib/elasticsearch-hadoop-7.17.6.jar
jar:file:/root/soft/hive/apache-hive-3.1.3-bin/lib/elasticsearch-hadoop-hive-7.17.6.jar
jar:file:/root/soft/hive/apache-hive-3.1.3-bin/lib/elasticsearch-hadoop-mr-7.17.6.jar
jar:file:/root/soft/hive/apache-hive-3.1.3-bin/lib/elasticsearch-hadoop-pig-7.17.6.jar
jar:file:/root/soft/hive/apache-hive-3.1.3-bin/lib/elasticsearch-spark-20_2.11-7.17.6.jar
jar:file:/root/soft/hive/apache-hive-3.1.3-bin/lib/elasticsearch-storm-7.17.6.jar
删除掉多余的jar包,然后在执行一次insert 语句,再进行查询,显示如下,在hive中查询是没有问题了
hive> select * from es_hadoop_cluster ;
OK
吴占喜 30 175
令狐冲 50 180
任我行 60 160
吴占喜 30 175
令狐冲 50 180
任我行 60 160
2.在es集群上去进行查询
根据映射表中创建时的索引,进行查询,数据正常展示出来了,nice
开心,😄,有问题欢迎留言交流

相关文章:
hive表向es集群同步数据20230830
背景:实际开发中遇到一个需求,就是需要将hive表中的数据同步到es集群中,之前没有做过,查看一些帖子,发现有一种方案挺不错的,记录一下。 我的电脑环境如下 软件名称版本Hadoop3.3.0hive3.1.3jdk1.8Elasti…...

五、Kafka消费者
目录 5.1 Kafka的消费方式5.2 Kafka 消费者工作流程1、总体流程2、消费者组原理3、消费者组初始化流程4、消费者组详细消费流程 5.3 消费者API1 独立消费者案例(订阅主题)2 独立消费者案例(订阅分区)3 消费者组案例 5.4 生产经验—…...

类 中下的一些碎片知识点
判断下面两个函数是否能同时存在 void Print(); void Pirnt() const 答:能同时存在,因为构成函数重载(注意函数的返回值不同是不能构成函数重载的)。 const 对象能调用 非const 成员函数吗 答:不能,因为权…...

JVM第二篇 类加载子系统
JVM主要包含两个模块,类加载子系统和执行引擎,本篇博客将类加载子系统做一下梳理总结。 目录 1. 类加载子系统功能 2. 类加载子系统执行过程 2.1 加载 2.2 链接 2.3 初始化 3. 类加载器分类 3.1 引导类加载器 3.2 自定义加载器 3.2.1 自定义加载器实…...
火爆全网!HubSpot CRM全面集成,引爆营销业绩!
HubSpot CRM是什么?它是一款强大的客户关系管理工具,专为企业优化销售、服务和市场营销流程而设计。它在B2B行业中扮演着极为重要的角色,让我来告诉你为什么吧! HubSpot CRM不仅拥有用户友好的界面和强大的功能,还能够…...
远程调试环境
一、远程调试 1.安装vscode 2.打开vscode,下载插件Remote-SSH,用于远程连接 3.安装php debug 4.远程连接,连接到远端服务器 注:连接远程成功后,在远程依然要进行安装xdebug,刚才只是在vscode中进行的安装。 5.配置la…...
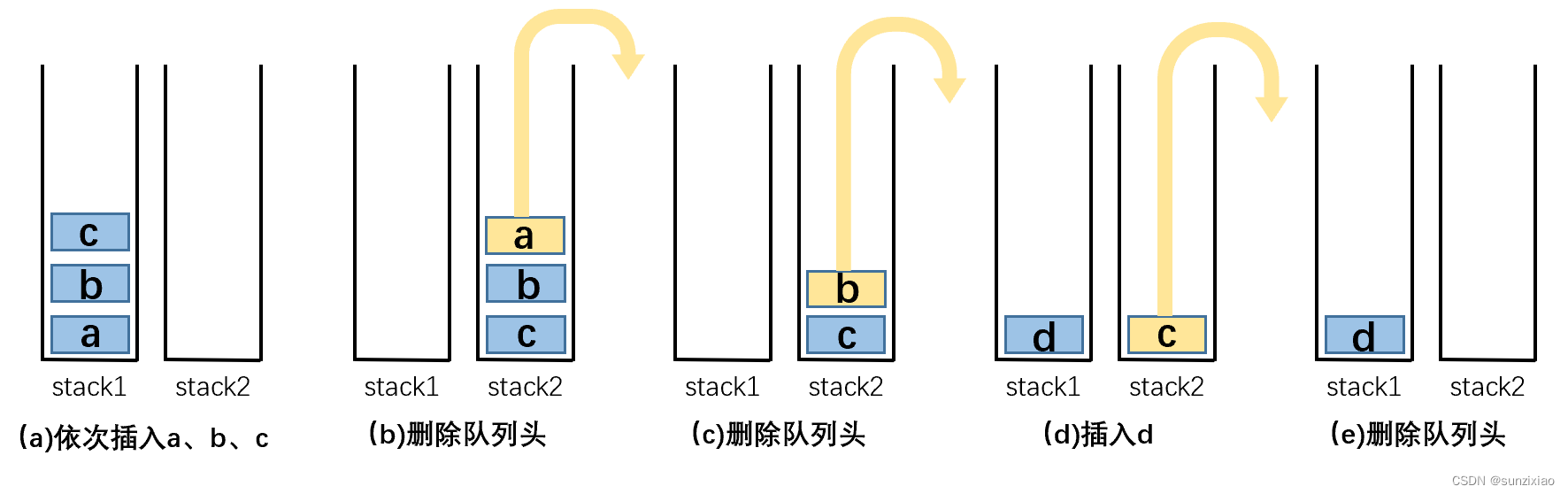
Java面试之用两个栈实现队列
文章目录 题目一、什么是队列和栈?1.1队列1.2栈 二、具体实现2.1 思路分析2.2代码实现 题目 用两个栈实现一个队列,实现在队列尾部插入节点和在队列头部删除节点的功能。 一、什么是队列和栈? 1.1队列 队列是一种特殊的线性表,…...

Python-实用的文件管理及操作
本章,来说说,个人写代码过程中,对于文件管理常用的几种操作。 三个维度 1、指定文件的路径拼接2、检查某文件是否存在3、配置文件的路径管理 1、指定文件的路径拼接 这个操作可以用来管理文件路径也就是上述中的第三点。但是,这里…...
Mysql 事物与存储引擎
MySQL事务 MySQL 事务主要用于处理操作量大,复杂度高的数据。比如说,在人员管理系统中, 要删除一个人员,即需要删除人员的基本资料,又需要删除和该人员相关的信息,如信箱, 文章等等。这样&#…...

java.lang.classnotfoundexception: com.android.tools.lint.client.api.vendor
Unity Android studio打包报错修复 解决方式 java.lang.classnotfoundexception: com.android.tools.lint.client.api.vendor 解决方式 在 launcherTemplate 目录下找到 Android/lintOptions 选项 加上 checkReleaseBuilds false lintOptions { abortOnError false checkRelea…...

pytest fixture夹具,@pytest.fixture
fixture 是pytest 用于测试前后进行预备,清理工作的代码处理机制 fixture相对于setup 和teardown: fixure ,命名更加灵活,局限性比较小 conftest.py 配置里面可以实现数据共享,不需要import 就能自动找到一些配置 setu…...

YOLOv7源码解析
YOLOv7源码解析 YAML文件 YAML文件 以yolov7 cfg/yolov7-w6-pose.yaml为例: # parametersnc: 1 # number of classes nkpt: 4 # number of key points depth_multiple: 1.0 # model depth multiple width_multiple: 1.0 # layer channel multiple dw_conv_kpt:…...

2023高教社杯数学建模思路 - 复盘:校园消费行为分析
文章目录 0 赛题思路1 赛题背景2 分析目标3 数据说明4 数据预处理5 数据分析5.1 食堂就餐行为分析5.2 学生消费行为分析 建模资料 0 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 1 赛题背景 校园一卡通是集…...
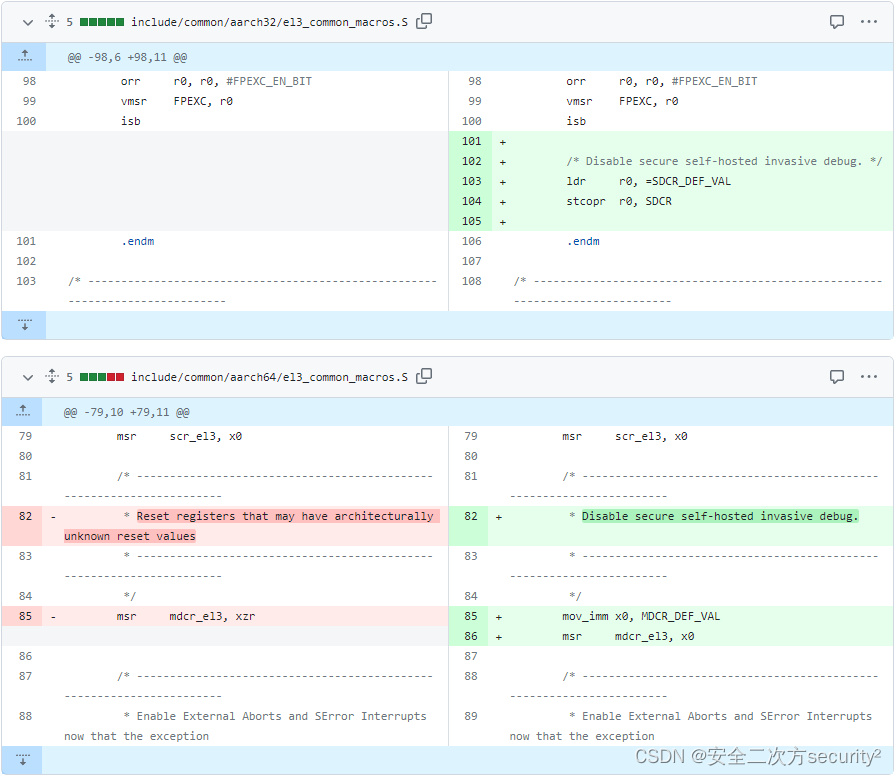
ATF(TF-A)安全通告 TFV-2 (CVE-2017-7564)
安全之安全(security)博客目录导读 ATF(TF-A)安全通告汇总 目录 一、ATF(TF-A)安全通告 TFV-2 (CVE-2017-7564) 二、 CVE-2017-7564 一、ATF(TF-A)安全通告 TFV-2 (CVE-2017-7564) Title 启用安全自托管侵入式调试接口,可允许非安全世界引发安全世界panic CV…...

无涯教程-PHP - 标量函数声明
在PHP 7中,引入了一个新函数,即标量类型声明。标量类型声明有两个选项- Coercive - 强制性是默认模式。Strict - 严格模式必须明确提示。 可以使用上述模式强制执行以下类型的函数参数- intfloatbooleanstringinterfacesarraycallable 强制模…...

动态规划(Dynamic programming)讲解(线性 DP 篇)
文章目录 动态规划(Dynamic Programing)第一关:线性DP第一战: C F 191 A . D y n a s t y P u z z l e s \color{7F25DF}{CF191A.\space Dynasty\enspace Puzzles} CF191A. DynastyPuzzles题目描述难度: ☆☆☆ \color…...

提升开发能力的低代码思路
一、低代码理念 在现代软件开发中,低代码开发平台备受关注。那么,什么是低代码开发平台呢?简单来说,它是一种能够提供丰富的图形化用户界面,让开发者通过拖拽组件和模型就能构建应用的开发环境。与传统开发方式相比&am…...
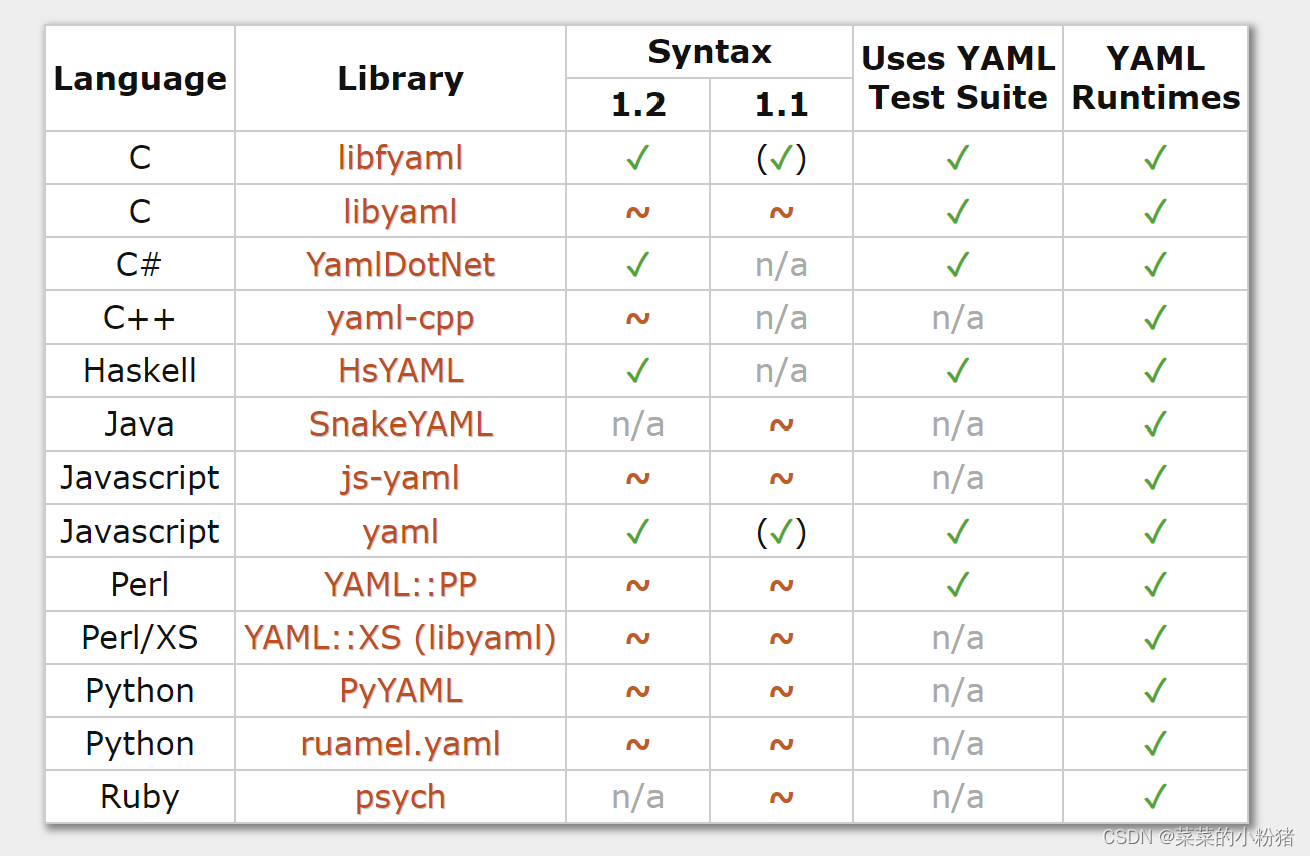
YAML详解及使用方法
YAML详解及使用方法 一、基本介绍二、数据类型2.1 纯量(scalars)/标量2.1.1 字符串2.1.2 保留换行(Newlines preserved)2.1.3 布尔值(Boolean)2.1.4 整数(Integer)2.1.5 浮点数(Floating Point)2.1.6 空(Nu…...
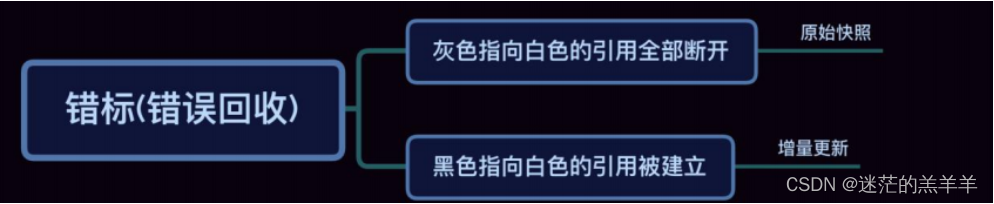
垃圾回收器
垃圾回收器就是垃圾回收的实践者,随着JDK的发展,垃圾回收器也在不断的更迭,在不同的场合下使用不同的垃圾回收器,这也是JVM调优的一部分。 1.垃圾回收器的分类 按线程可分为单线程(串行)垃圾回收器和多线程(并行)垃圾回收器。 按…...

SpringBoot 读取配置文件的值为 Infinity
1.配置信息 appid:6E212341234 2.获取方式 Value("${admin}")private String admin; 获取到结果 Infinity 3.修改方案 配置信息上加号 appid:‘6E212341234 yml中使用[单引号]不会转换单引号里面的特殊字符,使用""[双…...
)
基于java的畅阅读系统小程序设计与实现(源码+数据库+文档)
畅阅读系统小程 目录 基于java的畅阅读系统小程序设计与实现 一、前言 二、系统功能设计 三、系统实现 四、数据库设计 1、实体ER图 五、核心代码 六、论文参考 七、最新计算机毕设选题推荐 八、源码获取: 博主介绍:✌️大厂码农|毕设布道师&a…...

护照阅读器在海外的经典案例分享
...

2026 最新 Web 安全入门教程 零基础全面吃透 Web 攻防
“未知攻,焉知防”——真正的安全始于理解攻击者的思维 在日益数字化的世界中,Web安全工程师已成为企业防护体系的“数字盾牌”。本文将提供一条清晰的进阶路径,助你在2025年的网络安全领域脱颖而出。 一、认知篇:理解安全本质 …...

Zygo测试驱动开发实践:如何为解释器编写可靠的测试套件
Zygo测试驱动开发实践:如何为解释器编写可靠的测试套件 【免费下载链接】zygomys Zygo is a Lisp interpreter written in 100% Go. Central use case: dynamically compose Go struct trees in a zygo script, then invoke compiled Go functions on those trees. …...
)
pointer reference作为顶层参数(三)
一、核心代码#include "array_FIFO.h"//void array_FIFO (dout_t d_o[4], din_t d_i[4], didx_t idx[4]) { void array_FIFO (dout_t d_o[4], din_t *d_i, didx_t idx[4]) { #pragma HLS INTERFACE m_axi depth4 portd_i //#pragma HLS INTERFACE s_axilite register…...

CANN ops-sparse与Ascend C编程:深入理解NPU原生稀疏计算
CANN ops-sparse与Ascend C编程:深入理解NPU原生稀疏计算 【免费下载链接】ops-sparse 本项目是CANN提供的高性能稀疏矩阵计算的算子库,专注于优化稀疏矩阵的计算效率。 项目地址: https://gitcode.com/cann/ops-sparse 在高性能计算领域…...

MySQL中redo log 和 bin log的本质区别,别再搞混了!
很多初学者容易把 redo log 和 binlog 搞混,它们都是 MySQL 的日志,但有着本质的区别:对比维度redo logbin log所属层级InnoDB 存储引擎层MySQL Server 层日志类型物理日志,记录数据页的修改逻辑日志,记录SQL语句或行变…...

对比按需计费与 Token Plan 套餐哪种方式更适合长期项目
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比按需计费与 Token Plan 套餐哪种方式更适合长期项目 在长期且用量稳定的开发项目中,如何选择成本模型是技术决策的…...

Themes 与 Styles
Themes 与 Styles 主题目录:Source/Themes项目说明H.Theme主题核心。H.Themes.Colors.Accent强调色。H.Themes.Colors.Blue蓝色。H.Themes.Colors.Copper铜色/复古。H.Themes.Colors.Gray灰色。H.Themes.Colors.Industrial工业风。H.Themes.Colors.Mineral矿物色。H…...
)
仅限本周开放|Lovable高阶工程化实践内部培训课件(含模块化架构图、依赖注入容器源码注释版)
更多请点击: https://codechina.net 第一章:Lovable应用开发完整教程 Lovable 是一个面向现代 Web 应用的轻量级响应式框架,专为构建高交互性、可访问性强且易于维护的单页应用(SPA)而设计。它采用声明式组件模型与响…...