vector
目录
vector的成员函数:
at:
编辑
size:
assign:赋值
insert
find?
erase
swap
shrink_to_fit
编辑
vector的模拟实现:
vector的框架:
构造函数:
size和capacity
reserve函数:
begin和end
[]
尾插函数:
const修饰的begin和end
const修饰的[]
empty函数:
resize:
尾删
insert:
标准库里面的find函数:
vector的成员函数:
at:

at表示访问vector的第n个位置的数据。
我们进行实验:
#include<stdio.h>
#include<vector>
#include<iostream>
using namespace std;void vector_test1()
{vector<int> v;v.resize(10, 5);for (int i = 0; i < v.size(); i++){cout << v.at(i) << " ";}cout << endl;
}
int main()
{vector_test1();return 0;
}我们使用resize对v进行初始化,初始化的结果是vector有是个整型元素,十个元素都是5,我们遍历v,使用at函数,打印vector的每一个元素。
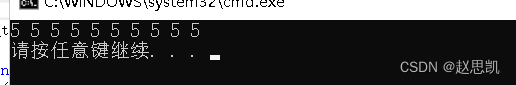
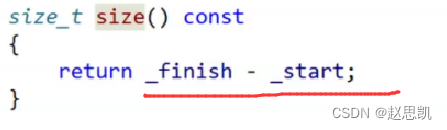
size:

size函数的返回值是vector中有效元素的个数。
void func(const vector<int>&v)
{v.size();
}
void test_vector2()
{vector<int> v;v.push_back(1);v.push_back(2);v.push_back(3);v.push_back(4);v.push_back(5);v.size();func(v);
}
int main()
{/*vector_test1();*/test_vector2();return 0;
}如图所示的函数,为什么func这里需要传引用呢?
![]()
答:因为我们的vector中存储的数据类型不仅可能是内置类型,也有可能是自定义类型,传值传参的过程本身就是拷贝,对于内置类型,拷贝的消耗不大,但是对于自定义类型,拷贝的消耗就很大,所以我们用传引用传参提高效率。
如图所示,为什么传参时需要加上const呢?
![]()
答:因为我们是传引用传参,我们得到v是为了读取到v上的size(),假如我们不加const,我们对v或v上的数据进行修改时,v本身也会做出相应的变化,所以我们加上const,表示我们的v是只读的,防止函数内部对v进行修改。
如图所示:这两个size函数的调用是同一个size吗?
答:如图所示:

是同一个size,因为我们的size只有一个接口函数,加上const的原因是我们的size是vector的基础属性,我们可以读取size,但是不能对size进行修改。我们在传参时,发生了权限的缩小,我们的v在test_vector2函数中是可读可写的,但是到了func函数中,我们的v变成了只读函数。
同样是vector函数,为什么size函数只有一个接口函数,而[]函数却有两个接口函数?

void func(const vector<int>&v)
{v[0];v[0]++;
}
void test_vector2()
{vector<int> v;v.push_back(1);v.push_back(2);v.push_back(3);v.push_back(4);v.push_back(5);v[0];v[0]++;func(v);
}
int main()
{/*vector_test1();*/test_vector2();return 0;
}我们进行编译:

func的v[0]++出现错误:原因如下:
答:在test_vector2中,因为我们的v是可读可写的,所以我们的[]匹配的就是这个函数:
![]()
在func2中,因为我们的v被const修饰,所以我们的v是只读的,我们调用[]函数匹配的就是这个函数:
![]()
因为我们的[]被const修饰,所以我们只能读而不能修改。
总结:1:只读函数,const例如:size()
我们的size()函数本身就是只读的,所以我们用可读的对象或者可读可写的对象都可以调用size()函数。
2:只写函数,非const 例如:push_back()
我们的push_back函数必须要求调用函数的对象必须是可写的,也就是说const修饰的对象不能调用push_back函数。
3:可读可写的函数 例如:[]和at()函数
我们这些函数有两个接口函数,当我们调用函数的对象是可读可写的,我们就调用第一个函数,假如我们调用函数的对象是只读的,我们就调用第二个函数。

问题:at()和[]函数的区别在哪里?
我们先写一串代码:
void test_vector3()
{vector<int> v;v.reserve(10);for (size_t i = 0; i < 10; ++i){v[i] = i;}
}
int main()
{/*vector_test1();*/test_vector3();return 0;
}我们进行运行会报错:
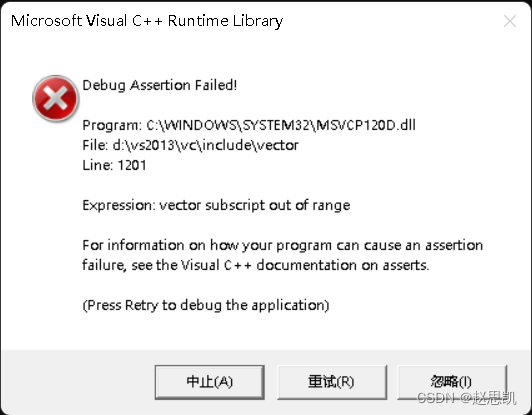
这里报的错误是断言错误,原因如下:我们虽然reserve开了10个空间,但是我们并没有resize,所以我们的size依旧是0,我们的[]内部的实现里有一个断言函数:要求[i]中的i要小于size,我们的size为0,所以不满足断言,所以会报错。
假如我们把这里的[]换成at呢?还会报错吗?
依旧会报错,但是这里报错的形式是抛异常。
总结:at和[]的不同点在于报错的形式:
at是通过抛异常的形式进行报错。
[]是通过断言的形式进行报错。
断言报错是有缺点的,因为assert只有在Debug版本下才能生效,在release版本下会失效。
assign:赋值

assign有两种写法,第一种写法是以迭代器区间的形式进行赋值,第二种就是普通的赋值。
问题1:为什么这里需要用类摸板,为什么不直接用迭代器。
答:原因是我们的vector中不仅会有内置类型,也可能会有自定义类型,对于自定义类型的迭代器,我们可以用类模板实现。
我们对两种函数进行实验:
void test_vector3()
{vector<int> v;v.push_back(1);v.push_back(2);v.push_back(3);v.assign(10, 1);for (auto e : v){cout << e << " ";}cout << endl;
}
int main()
{/*vector_test1();*/test_vector3();return 0;
}assign表示把vector的前十个元素都赋值为1.

assign的第二种应用。
void test_vector3()
{vector<int> v,v1;v.push_back(1);v.push_back(2);v.push_back(3);v1.assign(v.begin(), v.end());for (auto e : v1){cout << e << " ";}cout << endl;
}
int main()
{/*vector_test1();*/test_vector3();return 0;
}assign这里表示把从迭代器v.begin()到v.end()的全部元素都赋值给v1.
我们进行调用。

接下来,我们尝试用string进行赋值。
void test_vector3()
{/*vector<int> v,v1;v.push_back(1);v.push_back(2);v.push_back(3);*/vector<int> v;string str("hello world");v.assign(str.begin(), str.end());//v1.assign(v.begin(), v.end());for (auto e : v){cout << e << " ";}cout << endl;
}
int main()
{/*vector_test1();*/test_vector3();return 0;
}我们把迭代器str.begin()到str.end()的元素赋值给v,我们进行打印。

之所以是数字:我们的vector内的数据类型是int,所以把string中的char类型强制转换成为了int,变成了数字。
insert

我们的string的insert函数的参数使用的是下标,而我们的vecor的insert使用的都是迭代器。
我们在vector中不提供头插和头删,原因是头插和头删需要挪动数据,造成效率降低。
如果我们真的想要使用头插或者头删时,我们可以使用insert和erase来代替。
例如:
void test_vector3()
{vector<int> v;v.reserve(10);v.insert(v.begin(), 1);for (int i = 0; i < v.size(); i++){cout << v[i] << "";}cout << endl;
}
int main()
{/*vector_test1();*/test_vector3();return 0;
}find?

我们发现,vector的成员函数并没有find,为什么呢?
我们在std标准库找到了find函数

因为除了string容器之外,其他容器的find函数都是通过迭代器实现的,所以我们把这些容器的find函数直接写成一个,直接写在标准库中。

我们从迭代器first找到last,因为last是容器最后一个元素的下一个位置,所以last一定不是需要找的元素,所以当找到时,我们返回对应的迭代器,没有找到,我们返回last这个迭代器即可。
我们进行实验:
void test_vector3()
{vector<int> v;v.resize(10);for (size_t i = 0; i < v.size(); i++){v[i] = i;}vector<int>::iterator it = find(v.begin(), v.end(), 3);if (it != v.end()){v.insert(it, 30);}for (auto e : v){cout << e << " ";}cout << endl;
}
int main()
{/*vector_test1();*/test_vector3();return 0;
}我们的目的是从v中找到3的位置,在3的位置插入10。
问题:string为什么不使用标准库里面的find函数?
答:1:因为string出现的比较早,string出现的时候,标准库还没有完善。
2:因为string可能存在查找子串,我们用迭代器无法实现查找子串。
erase

表示删除vector的元素,分为两个接口函数,第一个接口函数是删除迭代器位置的一个元素,第二个接口函数是删除两个迭代器之间的元素。
具体的使用案例我们在网站就能查到,这里不再赘述。
swap

我们知道,算法库里面也有一个swap函数:

这两个函数哪一个函数更建议使用?
答:我们更建议使用vector的成员函数swap,如图所示:
标准库里面的swap函数是通过类模板实现的,并且中间使用了三次拷贝构造函数,因为vector中的数据类型也可能是自定义类型,对于自定义类型的拷贝构造效率太低,所以我们尽量使用vector自己提供的swap函数。

既然vector已经提供了swap函数,但是为什么标准库std又特殊的为vector提供了swap函数,如图所示:

我们写一串代码进行分析:
void test_vector3()
{vector<int> v,v1;v1.push_back(10);v1.push_back(20);v1.push_back(30);v1.swap(v);swap(v1, v);
}
int main()
{/*vector_test1();*/test_vector3();return 0;
}
这里出现了两个swap函数,第一个swap函数是vector的成员函数,第二个swap函数是标准库std里面的swap函数。
我们知道,算法库里面的swap函数走的是三次深拷贝,但是我们这里的第二个函数调用的就是算法库里面的swap,是否真的会调用三次深拷贝呢?
答:并不会,如图所示:

我们知道,编译器在匹配摸板的时候,一定找最合适的进行匹配,因为我们已经写好了我们是vector的摸板,所以调用算法库里面的swap函数直接匹配这里的摸板,有了摸板就不需要多次深拷贝了。
简单的说,如图所示:

我们这里调用的swap(v1,v)会进行检查,编译器发现swap的两个参数都是vector,所以我们直接调用转换为调用vector的成员函数swap,也就是这样:v1.swap(v)

所以我们调用的这两个函数,最终的结果是一样的,第一个函数直接调用vector的成员函数swap,第二个调用标准库的swap函数,swap函数再进行识别,我们转而调用vector的成员函数swap。
shrink_to_fit

表示把vector的容量调整到和vector的size相同。
提出一个问题:缩容适合使用吗?
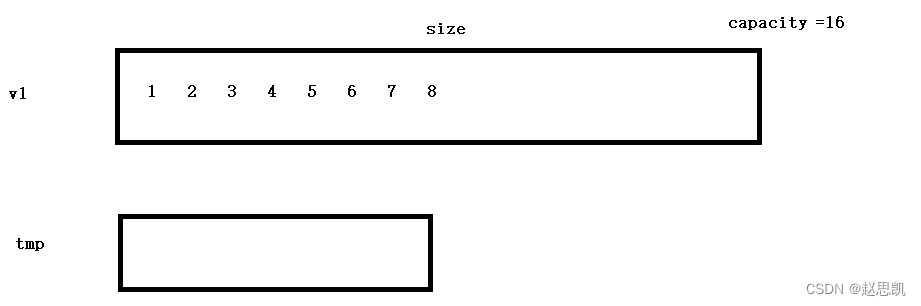
不适合,原因如下:首先,缩容是异地缩容,如图所示:

我们的size是8,我们的capacity是16,假如我们要进行缩容,我们首先开辟一个空间大小为8的一份空间:
然后我们把v1的有效元素放到tmp上,然后让v1指向tmp,然后释放掉v1即可。
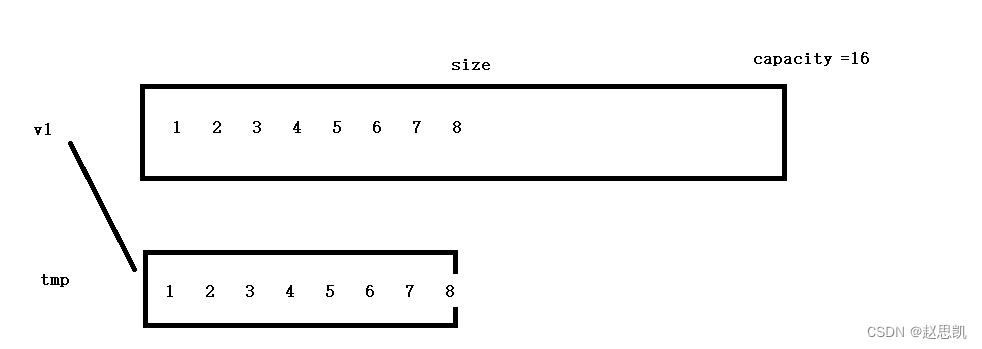
这就是异地缩容的原理,所以异地缩容比较繁琐,效率低下,有没有原地缩容?
答:并没有原地缩容,例如:
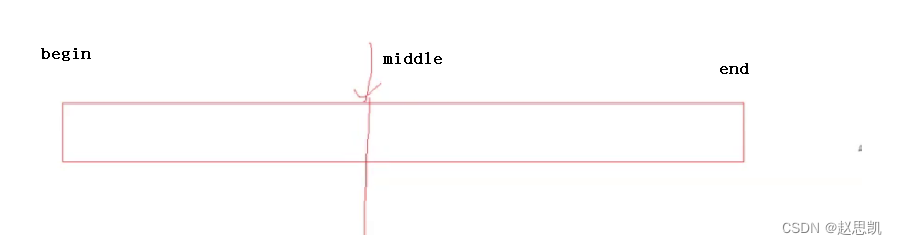
这是我们向内存申请的空间,假如我们想要释放空间的话,我们是不允许从middle位置释放空间的,因为这一部分空间是连贯的,我们只能从begin位置释放整个空间,所以也就不支持本地缩容。
vector函数支持缩容吗?
答:不支持,我们进行实验:
void test_vector3()
{vector<int> v,v1;v1.reserve(10);v1.push_back(10);v1.push_back(20);v1.push_back(30);cout << v1.capacity() << endl;v1.reserve(3);cout << v1.capacity() << endl;
}
int main()
{/*vector_test1();*/test_vector3();return 0;
}假如vector支持缩容时,我们打印的结果应该为3.

所以vector并不支持缩容。
resize可以缩容吗?
答:不可以,我们进行实验:
void test_vector3()
{vector<int> v,v1;v1.reserve(10);v1.push_back(10);v1.push_back(20);v1.push_back(30);cout << v1.capacity() << endl;v1.resize(3);cout << v1.capacity() << endl;
}
int main()
{/*vector_test1();*/test_vector3();return 0;
}我们进行运行:
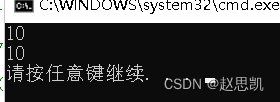
resize也不能缩容。
总结:vector一般不支持缩容。
在如今的计算机领域,硬件存储空间越来越大的情况下,时间就要比空间重要的多,所以我们一般不频繁使用缩容函数,因为缩容一定是异地缩容,异地缩容的本质是以时间换空间。
我们对shrink_to_fit进行实验:
void test_vector3()
{vector<int> v,v1;v1.reserve(10);v1.push_back(10);v1.push_back(20);v1.push_back(30);cout << v1.capacity() << endl;v1.shrink_to_fit();cout << v1.capacity() << endl;
}
int main()
{/*vector_test1();*/test_vector3();return 0;
}我们进行运行:

成功缩容。
vector的模拟实现:
我们首先看一下vector的源代码,我们通过调试就可以看pj版本的源代码:

vector在pj版本下的源代码大概是3000行,这里的内容是开源声明。
sgi的版本更适合我们初学者学习,我们查看sgi版本。
我们把我们在源码中找最重要的代码,进行精简:
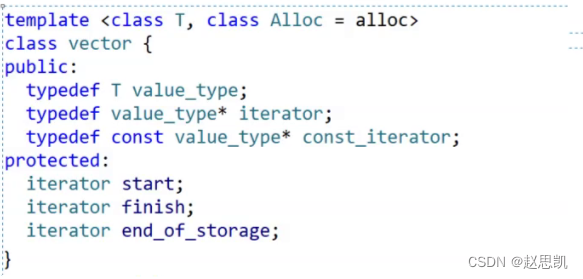
我们可以发现,vector的成员变量的雷西那个都是迭代器。
vector的结构图如图所示:
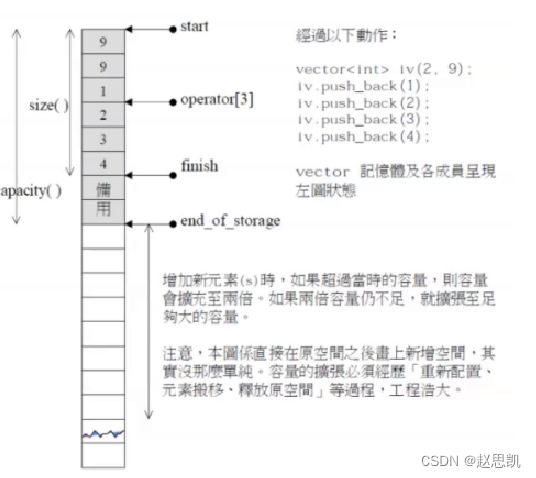
我们按照这个框架模拟实现vector
vector的框架:
#pragma once
namespace bit
{template<class T>clasee vector{public:typedef T* iterator;private:iterator _start;iterator _finish;iterator _endofstorge;
};
}T是我们定义的摸板,我们把T*类型重命名为iterator,我们有三个成员变量。
构造函数:
![]()
这是源代码中vector的构造函数,其中使用了初始化列表,把三个迭代器都置为0,我们按照他的写法实现构造函数。
vector():_start(nullptr), _finish(nullptr), _endofstorge(nullptr){}我们的三个成员变量都是迭代器,我们可以先把迭代器理解为指针,对于指针的初始化,我们可以赋值nullptr,初始化列表是在调用函数内容之前就已经实现的。
size和capacity
size_t size(){return _finish - _start;}size_t capacity(){return _endofstorage - _start;}我们把迭代器先理解为指针,指针与指针相减的结果为数字,size是有效元素的个数,capacity是容量,我们根据图像就能够写出对应的函数。

reserve函数:
void reserve(size_t n){if (n > capacity()){T*tmp = new T*[n];memcpy(tmp, _start, sizeof(T)*size());delete[] _start;_start = tmp;_finish = _start + size();_endofstorge = _start + n;}}我们进行画图解释:

只有当n大于我们的capacity时,我们才进行扩容,我们的reserve不缩容。
我们的思路是异地扩容,我们新申请一个大小为n的空间tmp,然后把vector上的数据拷贝到tmp上,然后释放掉原来vector的数据,让新的空间指向tmp,再对_finish和endofstorge进行修改。
![]()
这里可以用malloc初始化吗?
答:不能,因为malloc只会对内置类型初始化,对于自定义类型不初始化。
new相较于malloc的优点:
malloc需要判断是否申请空间失败,而new不需要,new失败的话会抛异常。
begin和end
iterator begin(){return _start;}iterator end(){return _finish;}[]
T&operator[](size_t pos){assert(pos < size());return _start[pos];}我们的[]函数内部必须要断言:要求pos一定要小于size()
尾插函数:
void push_back(const T&x){if (_finish == _endofstorge){size_t newcapacity = capacity() == 0 ? 4 : capacity() * 2;reserve(newcapacity);}*_finish = x;++_finish;}![]()
我们进行尾插的数据类型 T既有可能是内置类型,也有可能是自定义类型,对于内置类型,我们可以不传引用,但是对于自定义类型必须传引用。
![]()
我们传了引用,在函数中可能会导致x的值发生变化,我们加上const表示x是只读的。

假如我们的元素数和容量相等,表示我们需要扩容了,又因为capacity的初始化值可能为0,所以我们使用三目操作符,假如capacity为0时,我们把4赋给newCapacity,然后调用reserve函数进行扩容。

判断并执行扩容之后,接下来,进行尾插元素,我们的迭代器可以理解为指针 ,我们在_finish插入元素x,再++_finish即可。
特殊情况:

当我们的vector没有一个元素,我们进行尾插时,我们的newcapacity就被设置为4,然后我们调用reserve函数进行扩容:
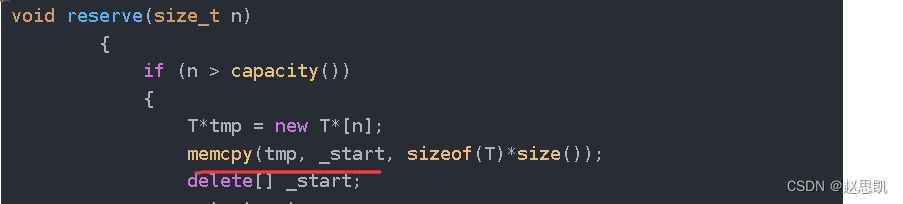
这时候,因为我们vector中的元素实际为空,所以我们并不需要进行内存拷贝,所以我们可以优化一下reserve函数
void reserve(size_t n){if (n > capacity()){T*tmp = new T*[n];if (_start){memcpy(tmp, _start, sizeof(T)*size());delete[] _start;}_start = tmp;_finish = _start + size();_endofstorge = _start + n;}}接下来,我们测试之前写的代码是否有误。
测试代码
using namespace std;
#include<iostream>
#include"vector.h"
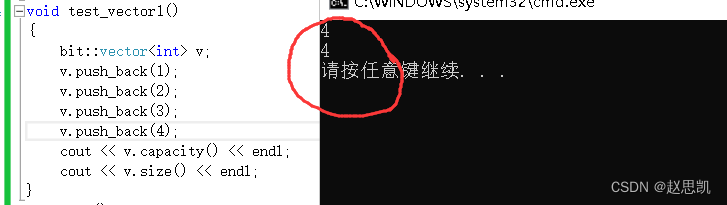
void test_vector1()
{bit::vector<int> v;v.push_back(1);v.push_back(2);v.push_back(3);v.push_back(4);cout << v.capacity() << endl;cout << v.size() << endl;
}
int main()
{test_vector1();return 0;
}
报错的原因在我们的reserve函数上:

我们画图进行解释:

我们让_start指向tmp对应的空间:
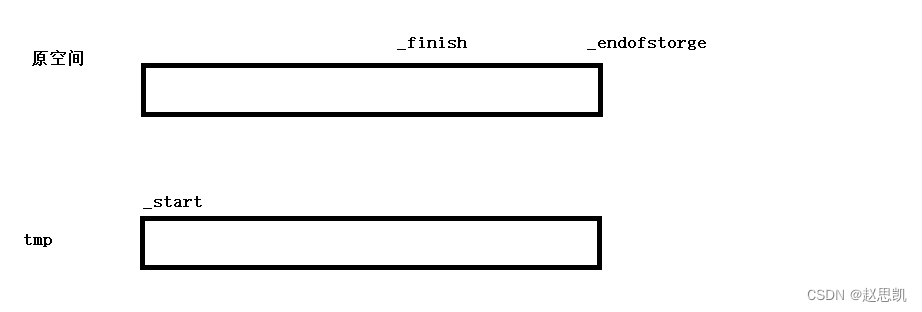
这时候,我们的_start和_finish不在同一块空间内,我们调用size函数:
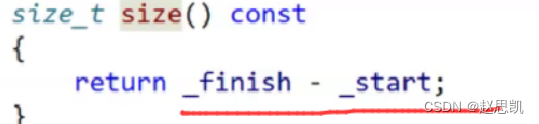
两块不同的空间进行相加减的值是未知的,我们接下来会对_finsh进行解引用,就会报错。
我们可以这样处理:

我们可以先处理finish,画图进行解释:

我们先处理finish
![]()
size函数表示_finish和_start相减,两个指针相减的结果是两个指针区域指向的相同数据的数目,是整型,我们让tmp+_finish.

这时候,我们再把tmp赋值给_start。

这时候就没有什么问题了,我们继续测试:
const修饰的begin和end
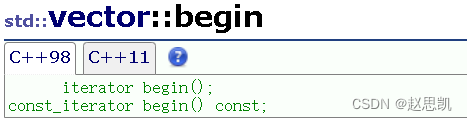
我们发现,begin和end都有两个接口函数,分别是const和非const。
![]()
这两个const有什么区别吗?
答:第二个const:假如调用begin()函数的对象用const修饰了,我们就调用这个begin()函数。
第一个const:我们用const对象调用begin函数,返回的迭代器也用const修饰。
const iterator begin() const{return _start;}const iterator end() const{return _finish;}const修饰的[]
const T&operator[](size_t pos) const{assert(pos < size());return _start[pos];}empty函数:
bool empty() const{return _start == _finish;}当_start和_finsh相等时,也就是当_start=_finsh=nullptr时,vector对象为空。
resize:
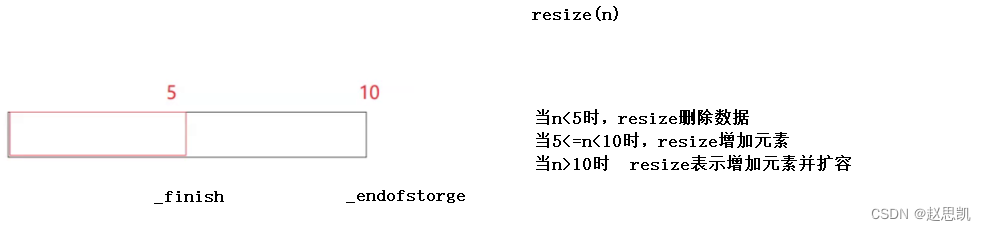
void resize(size_t n, T val = T()){if (n>capacity()){reserve(n);}if (n > size()){while (_finish < _start + n){*_finish = val;++_finish;}}else{_finish = _start + n;}} ![]()
这里的缺省值可以写0吗?
答:不行,对于内置类型,我们可以用0初始化,但是vector存储的数据既有可能是内置类型,也有可能是自定义类型,而对于自定义类型,我们不能用0去初始化。

我们首先判断n是否大于capacity,如果大于我们需要进行扩容。

判断n是否大于size,大于时需要填元素,我们调用循环把val填入到vector中。
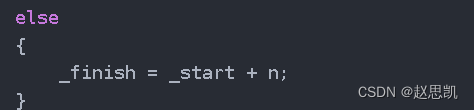
这里表示n小于size,所以我们需要元素,我们可以直接修改_finish的值,就能达到删除数据的目的。
尾删
void pop_back(){_finish--;}我们直接让_finish--来删除数据。
不断的尾删会导致什么样的结果:
using namespace std;
#include<windows.h>
#include<iostream>
#include"vector.h"
void test_vector1()
{bit::vector<int> v;v.push_back(1);v.push_back(2);v.push_back(3);v.push_back(4);while (1){v.pop_back();cout << v.size() << endl;Sleep(100);}
}
int main()
{test_vector1();return 0;
}我们进行运行:
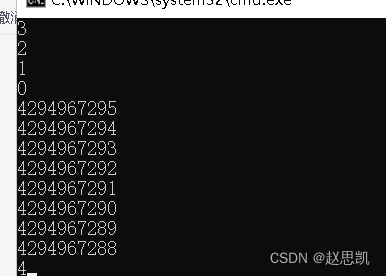
因为我们的size是无符号类型,所以不断的进行尾删之后,size反而变成一个非常大的数据了。
我们调用库里面的尾删函数进行尝试:
using namespace std;
#include<vector>
#include<windows.h>
#include<iostream>
//#include"vector.h"
void test_vector1()
{vector<int> v;v.push_back(1);v.push_back(2);v.push_back(3);v.push_back(4);while (1){v.pop_back();cout << v.size() << endl;Sleep(100);}
}
int main()
{test_vector1();return 0;
}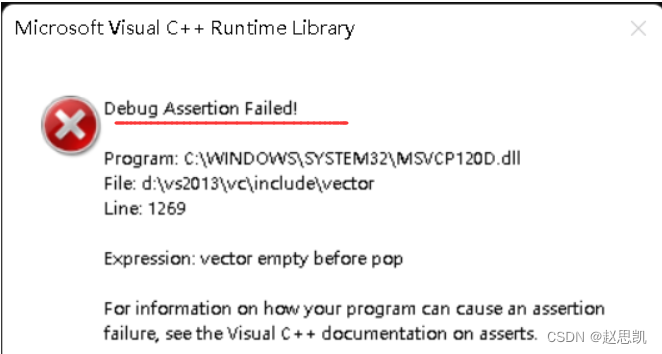
我们发现,库里面报的错误是断言错误,所以我们可以仿照库的写法对尾删函数进行完善:
void pop_back(){assert(_finish >= _start);_finish--;}insert:
void insert(iterator pos, const T& val){if (_finish == _endofstorge){size_t newcapacity = capacity() == 0 ? 4 : capacity() * 2;reserve(newcapacity);}iterator end = _finish - 1;while (end >= pos){*(end + 1) = *end;--end;}*pos = val;++_finish;}insert表示我们从pos位置处插入元素val。
![]() 为什么这里要加上const和&?
为什么这里要加上const和&?
答:首先,必须加上引用,因为我们insert插入的极有可能是内置类型,也有可能是自定义类型,传参的过程本质是一个拷贝,对于自定义类型的深拷贝效率太低,消耗很大,所以我们通过传引用来传参,传引用的话我们就要限制函数内部,禁止对val进行修改,所以要加上const。

首先,我们要判断是否需要扩容。

我们的思路是这样的,先把pos位置后的数据全部往后面挪动一个位置,然后才填数据。
我们对insert函数进行实验:
using namespace std;
//#include<vector>
#include<windows.h>
#include<iostream>
#include<assert.h>
#include"vector.h"
void test_vector1()
{bit::vector<int> v;v.push_back(1);v.push_back(2);v.push_back(3);v.push_back(4);bit::vector<int>::iterator it = v.end();v.insert(it, 15);for (auto s : v){cout << s << " ";}cout << endl;
}
int main()
{test_vector1();return 0;
}我们在调试时发现两处异常:
异常1:
我们发现,编译器会一直执行while循环,不会终止。
异常2:

我们进行的是尾插,pos与_finish的值却不相等。
这些问题是扩容的问题:
扩容导致了迭代器失效:
因为我们只有我们的capacity和size都为4,我们要插入元素就需要扩容,我们的pos的值和_finish是相等的。
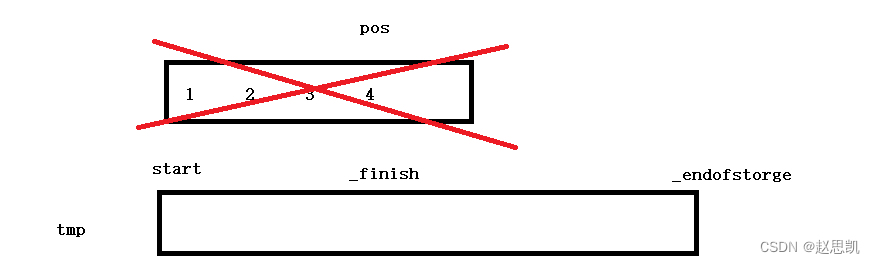
我们的原空间被销毁,所以pos迭代器就失效了,pos和_finish无法比较大小,所以while死循环,pos位置已经被释放了所以无法被继续访问。
我们要做的就是更新pos:
void insert(iterator pos, const T& val){assert(pos <= _finish);assert(pos >= _start);if (_finish == _endofstorge){size_t len = pos - _start;size_t newcapacity = capacity() == 0 ? 4 : capacity() * 2;reserve(newcapacity);pos = _start + len;}iterator end = _finish - 1;while (end >= pos){*(end + 1) = *end;--end;}*pos = val;++_finish;}我们思考一个问题:insert之后的迭代器还能继续使用吗?
如代码所示:

答:最好不要,首先,只要我们因为调用insert而导致扩容,就会导致迭代器失效,it位置已经被释放。
许多人会有疑问:我们不是已经解决了迭代器失效了吗?

我们只是保证函数能正常使用,但是并没有保证迭代器没有失效:如图:
![]()
我们调用insert传参传递的it是传值传参,pos只是it的拷贝,pos值的修改并不影响it的变化,所以迭代器it还是失效了 。
那为什么insert函数不传引用传递第一个参数呢?
如图:

为什么不这样写呢?
答:因为限制条件太多 ,例如:
![]()
假如我们这样调用函数时,因为我们是传引用,我们的v.begin()是调用begin函数的返回值,是一个临时变量,临时变量具有常数属性,我们无法把临时变量当作参数调用insert函数。
所以,调用insert(pos,val)之后,pos对应的迭代器最好不要再使用。
标准库里面的find函数:
void test_vector1()
{bit::vector<int> v;v.push_back(1);v.push_back(2);v.push_back(3);v.push_back(4);bit::vector<int>::iterator it = find(v.begin(), v.end(), 3);if (it != v.end()){v.insert(it, 30);}for (auto s : v){cout << s << " ";}cout << endl;
}我们进行运行:

相关文章:
vector
目录 vector的成员函数: at: 编辑 size: assign:赋值 insert find? erase swap shrink_to_fit 编辑 vector的模拟实现: vector的框架: 构造函数: size和capacity r…...

LeetCode——104. 二叉树的最大深度
一、题目 给定一个二叉树,找出其最大深度。 二叉树的深度为根节点到最远叶子节点的最长路径上的节点数。 说明: 叶子节点是指没有子节点的节点。 来源:力扣(LeetCode) 链接:https://leetcode.cn/problems/maximum…...

漫画 | Python是一门烂语言?
这个电脑的主人是个程序员,他相继学习了C、Java、Python、Go, 但是似乎总是停留在Hello World的水平。 每天晚上,夜深人静的时候,这些Hello World程序都会热火朝天地聊天但是,这一天发生了可怕的事情随着各个Hello wor…...

2023.2 新方案 java代码混淆 java加密 字符串加密
Java字节码可以反编译,特别是创业公司,很好的项目很容易被别人破解反编译,造成很严重的损失,所以本混淆方案能很好的保护源码,而且在不断迭代,增强混淆效果,异常问题处理,达到保护项目的目的: 本次升级包括: 2023年02年19日 : ht-confusion-project-1.8…...

Swift 周报 第二十三期
前言 本期是 Swift 编辑组自主整理周报的第十四期,每个模块已初步成型。各位读者如果有好的提议,欢迎在文末留言。 欢迎投稿或推荐内容。目前计划每两周周一发布,欢迎志同道合的朋友一起加入周报整理。 勇敢是即便知道好结局不会每每降临在…...

android系统屏幕旋转角度,应用界面横竖屏,设备旋转角度,三者的区别以及使用。
注意区分以下三种概念的区别!!!。以及使用这三种方式判断横竖屏的方式。系统屏幕旋转角度fun getSystemRotation(): Int {val angle (getSystemService(WINDOW_SERVICE) as WindowManager).defaultDisplay.rotation//系统屏幕旋转的角度值re…...
【华为云-开发者专属集市】DevCloud+ECS、MySQL搭建WordPress
文章目录AppBazaar官网选择与购买项目项目概况操作过程购买DevCloud服务创建项目添加制品库应用部署购买ECS添加部署模板并执行任务故障排除安装及访问WordPress登录网站管理后台访问网站完善部署模板资源释放使用总结AppBazaar官网 首先,我们来到AppBazaar的官网&…...

Milvus 群星闪耀时|又一个小目标达成 :社区正式突破 15,000 星!
如果把 Milvus 看作开源世界中的一束微光,那用户便是无垠宇宙中点点闪烁的星光。用户每一次点亮 star 之时,Milvus 就会迸发出更加耀眼的光芒。不知不觉,已有数以万计的 star 为 Milvus 而亮。2022 年 4 月,Milvus 在 GitHub 的 …...
Qt信号与槽使用方法总结
前言 在图形界面编程中QT是为首选,组件之间如何实现通信是核心的技术内容。Qt 使用了信号与槽的机制,非常的高效、简单、易学,方便开发者的使用。本文详细的介绍了Qt 当中信号与槽的概念,并演示了各种信号与槽的连接方式。 什么…...

SpringCloud alibaba-Sentinel服务降级策略
文章目录RT:异常比例:异常数:RT: 平均响应时间 (DEGRADE_GRADE_RT):当 1s 内持续进入 N 个请求,对应时刻的平均响应时间(秒级)均超过阈值(count,以 ms 为单位…...
函数)
python常用函数——random()函数
random() 返回随机生成的一个实数,范围在[0,1)之间 语法如下: import random random.random() # 注意:random()是不能直接访问的,需要导入random包,然后通过random静态对象调用 # 参数: 无 # 返回值 返回随…...

PX4之启动脚本
PX4通过rcS脚本来设定需要启动的程序,比如设备驱动、控制模块、数据通信等。rcS脚本在项目中的文件位置 ROMFS/px4fmu_common/rcS 对应硬件平台固件上的位置 /etc/init.d/rcS 启动脚本流程如下 #!/bin/sh # PX4FMU startup script. # # 一些注释 ## 设置默认参…...
Java零基础入门到精通(持续更新中)
打开CMD命令窗口 WINR输入cmd 常用cmd命令代码 切换磁盘 E: 回车即可切换到e盘查看当前路径下的所有内容 dir进入目录 cd test回退到上一级目录 cd..进入多级目录 cd test\index\aaa回退到磁盘目录 cd \清屏 cls关闭命令行窗口 exit小例子:使用命令行窗口…...
:Bilibili视频缓存 m4s音视频合并 shell脚本)
杂七杂八(12):Bilibili视频缓存 m4s音视频合并 shell脚本
视频目录结构如下: 267132000/ 267132000/c_1015740000/ 267132000/c_1015740000/entry.json 267132000/c_1015740000/80/ 267132000/c_1015740000/80/audio.m4s 267132000/c_1015740000/80/video.m4s267132000/c_1015740011/ 267132000/c_1015740011/entry.json 2…...

Qt 某光谱仪程序开发
某光谱仪程序开发 文章目录某光谱仪程序开发摘要安装驱动注册COM组件导出.h和.cpp在Qt 中添加源文件开发打包程序关键字: Demo、 Qt、 COM、 dumpcpp、 C摘要 今天接到一个临时小任务,写一个的项目子模块的Demo,以供和专家们交流一下项目技…...

蛋白质组学技术与常见分析培训班火热招生中!
什么是蛋白质组学? 蛋白质组学(proteomics),是以蛋白质组为研究对象,研究细胞、组织或生物体蛋白质组成及其变化规律的科学。包括蛋白质的表达水平,翻译后修饰,蛋白与蛋白相互作用等研究内容,集中于动态描述…...
唤醒手腕 Java 后端 Springboot 框架结合 socketio 学习笔记
socketio 安装配置 Socket.IO是一个完全由JavaScript实现、基于Node.js、支持WebSocket的协议用于实时通信、跨平台的开源框架,它包括了客户端的JavaScript和服务器端的Node.js。 Socket.IO除了支持WebSocket通讯协议外,还支持许多种轮询(P…...

C++入门:内联函数、auto关键字、基于范围for循环及指针空值nullptr
目录 一. 内联函数 1.1 内联函数的概念 1.2 内联函数的特性 1.3 内联函数和宏的优缺点对比 二. auto关键字(C11) 2.1 auto的功能 2.2 auto在使用时的注意事项 三. 基于范围的for循环(C11) 四. 指针空值nullptr(…...

Python遗传算法
1 人工智能概述 2020中国人工智能产业年会在苏州召开,会上发布的《中国人工智能发展报告2020》显示,过去十年(2011-2020) ,中国人工智能专利申请量达389571件,占全球总量的74.7%,位居世界第一。 报告指出,…...
GEE学习笔记 六十四:绿色中国报告(个人版)
2019年上半年在遥感圈里最火的一篇文章莫过于这篇《China and India lead in greening of the world through land-use management》(China and India lead in greening of the world through land-use management | Nature Sustainability),…...

PyTorch 2.8开源大模型镜像实操:HuggingFace模型本地化API服务封装
PyTorch 2.8开源大模型镜像实操:HuggingFace模型本地化API服务封装 1. 镜像环境概览 1.1 硬件与软件配置 这个基于PyTorch 2.8的深度学习镜像经过RTX 4090D显卡和CUDA 12.4的深度优化,为大型模型推理和训练提供了开箱即用的环境。主要配置包括&#x…...

Windows 11 家庭版安装 WSL + Docker 踩坑记:从 Store 地狱到 --web-download 救赎
一句话总结当你发现 wsl --update 和 wsl --install 永远卡住、报权限错误或连接重置时,不要挣扎,直接用 --web-download 绕过 Microsoft Store。 这 99% 能解决 Windows 11 家庭版上的 WSL 安装/更新问题。一、问题现象:一切看起来都很正常&…...
Laravel Stats Tracker设备检测技术解析:精准识别移动端与桌面端
Laravel Stats Tracker设备检测技术解析:精准识别移动端与桌面端 【免费下载链接】tracker Laravel Stats Tracker 项目地址: https://gitcode.com/gh_mirrors/tr/tracker Laravel Stats Tracker是一款强大的Laravel统计跟踪工具,它提供了精准的设…...
)
2026 年真正必备的 10 个 Claude 插件(以及它们的作用)
如何把 Claude 从聊天机器人,变成能写代码、联网、访问数据、自动化全流程的超级 AIClaude 刚刚获得了超能力。 而大多数人还以为它只是个聊天机器人。 2026 年 2 月 24 日,Anthropic 为企业用户推出了私有插件市场。而在此两周前,社区已经发…...

Ostrakon-VL-8B对比评测:主流开源多模态模型在餐饮场景的较量
Ostrakon-VL-8B对比评测:主流开源多模态模型在餐饮场景的较量 最近在餐饮和零售行业,用AI来“看懂”图片的需求越来越多了。比如,自动识别菜品、分析菜单、甚至根据顾客拍的模糊照片推荐相似菜品。这背后,多模态模型是关键。 市…...

10分钟零成本搭建KIMI AI免费API:个人智能助手完整指南
10分钟零成本搭建KIMI AI免费API:个人智能助手完整指南 【免费下载链接】kimi-free-api 🚀 KIMI AI 长文本大模型逆向API【特长:长文本解读整理】,支持高速流式输出、智能体对话、联网搜索、探索版、K1思考模型、长文档解读、图像…...

嵌入式调试实战:常见错误与高效排查方法
1. 程序员调试中的那些"荒唐"错误 作为一名从业多年的嵌入式工程师,我深知调试过程中的酸甜苦辣。那些看似简单的问题往往耗费我们最多时间,而最终解决方案却常常让人哭笑不得。今天就来分享几个真实的调试故事,希望能给同行们带来…...

多图拼长条与宫格拼接批处理备忘
手头有一批产品白底图,需要批量产出两类物料:一类是横向四连图做详情对比,一类是 22 宫格做缩略封面。统一用【批量图片拼接工具】走完,下面只记参数组合和踩坑点,不写实现细节。输入侧是「主文件夹」路径,…...

QMCFLAC2MP3:解锁音乐格式封印,让QQ音乐真正属于你
QMCFLAC2MP3:解锁音乐格式封印,让QQ音乐真正属于你 【免费下载链接】qmcflac2mp3 直接将qmcflac文件转换成mp3文件,突破QQ音乐的格式限制 项目地址: https://gitcode.com/gh_mirrors/qm/qmcflac2mp3 你是否曾经遇到过这样的尴尬场景&a…...

【Python实战】AI自动整理文件:告别桌面混乱
用PythonAI打造一个桌面文件整理助手,让混乱的桌面瞬间清爽 一、痛点:桌面文件的"灾难现场" 我的桌面曾经是这样的: 截图、下载文件、临时文档混在一起 找文件要翻半天 重要文件被淹没在垃圾文件里 手动整理太麻烦,坚持…...