【Python】PySpark
前言
Apache Spark是用于大规模数据(large-scala data)处理的统一(unified)分析引擎。
简单来说,Spark是一款分布式的计算框架,用于调度成百上千的服务器集群,计算TB、PB乃至EB级别的海量数据。
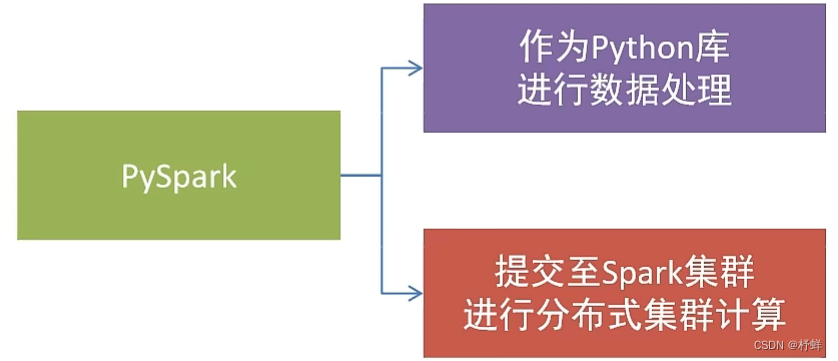
Spark对Python语言的支持,重点体现在Python第三方库:PySpark
PySpark是由Spark官方开发的Python语言第三方库。
Python开发者可以使用pip程序快速的安装PySpark并像其它第三方库那样直接使用。
基础准备
安装
同其它的Python第三方库一样,PySpark同样可以使用pip程序进行安装。
pip install pyspark或使用国内代理镜像网站(清华大学源)
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyspark
构建PySpark执行环境入口对象
想要使用PySpark库完成数据处理,首先需要构建一个执行环境入口对象。
PySpark的执行环境入口对象是:类SparkContext的类对象
# 导包
from pyspark import SparkConf, SparkContext# 创建SparkConf类对象
conf = SparkConf().setMaster('local[*]').setAppName('test_spark_app')# 基于SparkConf类对象创建SparkContext类对象
sc = SparkContext(conf=conf)# 打印PySpark的运行版本
print(sc.version)# 停止SparkContext对象的运行(停止PySpark程序)
sc.stop()
运行需要Java环境,推荐jdk8
PySpark的编程模型
SparkContext类对象,是PySpark编程中一切功能的入口。
PySpark的编程,主要分为如下三大步骤:

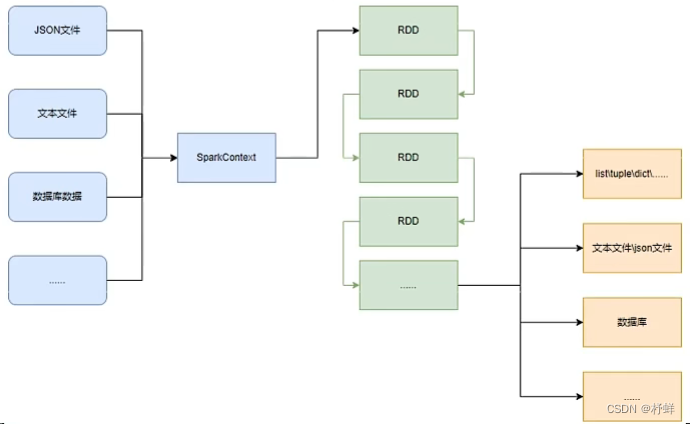
数据输入
PySpark支持多种数据的输入,在输入完成后,都会得到一个:RDD类的对象
RDD全称为:弹性分布式数据集(Resilient Distributed Datasets)
PySpark针对数据的处理,都是以RDD对象作为载体,即:
- 数据存储在RDD内
- 各类数据的计算方法,也都是RDD的成员方法
- RDD的数据计算方法,返回值依旧是RDD对象
Python数据容器转RDD对象
PySpark支持通过SparkContext对象的parallelize成员方法,将list/tuple/set/dict/str转换为PySpark的RDD对象
# 导包
from pyspark import SparkConf, SparkContext# 创建SparkConf类对象
conf = SparkConf().setMaster('local[*]').setAppName('test_spark_app')# 基于SparkConf类对象创建SparkContext类对象
sc = SparkContext(conf=conf)rdd1 = sc.parallelize([1, 2, 3])
rdd2 = sc.parallelize((1, 2, 3))
rdd3 = sc.parallelize({1, 2, 3})
rdd4 = sc.parallelize({'key1': 'value1', 'key2': 'value2'})
rdd5 = sc.parallelize('hello') # 输出RDD的内容,需要使用collect()
print(rdd1.collect()) # [1, 2, 3]
print(rdd2.collect()) # [1, 2, 3]
print(rdd3.collect()) # [1, 2, 3]
print(rdd4.collect()) # ['key1', 'key2']
print(rdd5.collect()) # ['h', 'e', 'l', 'l', 'o']# 停止SparkContext对象的运行(停止PySpark程序)
sc.stop()
注意:
- 字符串会被拆分出一个个的字符,存入RDD对象
- 字典仅有key会被存入RDD对象
读取文件转RDD对象
PySpark也支持通过SparkContext入口对象来读取文件,构建出RDD对象。
先提前预备一个txt文件
hello
python
day
# 导包
from pyspark import SparkConf, SparkContext# 创建SparkConf类对象
conf = SparkConf().setMaster('local[*]').setAppName('test_spark_app')# 基于SparkConf类对象创建SparkContext类对象
sc = SparkContext(conf=conf)rdd = sc.textFile('E:\\code\\py-space\\8.27\\hello.txt')# 输出RDD的内容,需要使用collect()
print(rdd.collect()) # ['hello', 'python', 'day']# 停止SparkContext对象的运行(停止PySpark程序)
sc.stop()
数据计算
RDD对象内置丰富的:成员方法(算子)
map算子
将RDD的数据一条条处理(处理的逻辑基于map算子中接收的处理函数),返回新的RDD
rdd.map(func)
# func: f:(T) -> U
# f: 表示这是一个函数
# (T) -> U 表示的是方法的定义:()表示无需传入参数,(T)表示传入1个参数
# T是泛型的代称,在这里表示 任意类型
# U是泛型的代称,在这里表示 任意类型# (T) -> U : 这是一个函数,该函数接收1个参数,传入参数类型不限,返回一个返回值,返回值类型不限
# (A) -> A : 这是一个函数,该函数接收1个参数,传入参数类型不限,返回一个返回值,返回值类型和传入参数类型一致
示例:
# 导包
from pyspark import SparkConf, SparkContext, sql
import os# 设置环境变量
os.environ['PYSPARK_PYTHON'] = 'D:/Python/python.exe'# 创建SparkConf类对象
conf = SparkConf().setMaster('local[*]').setAppName('test_spark_app')# 基于SparkConf类对象创建SparkContext类对象
sc = SparkContext(conf=conf)rdd = sc.parallelize([1, 2, 3, 4, 5, 6])# 通过map方法将全部数据乘以10,传入参数为函数
rdd2 = rdd.map(lambda x: x * 10)# 输出RDD的内容,需要使用collect()
print(rdd2.collect()) # [10, 20, 30, 40, 50, 60]# 停止SparkContext对象的运行(停止PySpark程序)
sc.stop()
由于map()的返回值还是RDD对象,可以继续在尾部进行链式调用
rdd3 = rdd.map(lambda x: x * 10).map(lambda x: x + 9)
flatMap算子
对RDD执行map操作,然后进行解除嵌套操作。

# 导包
from pyspark import SparkConf, SparkContext, sql
import os# 设置环境变量
os.environ['PYSPARK_PYTHON'] = 'D:/Python/python.exe'# 创建SparkConf类对象
conf = SparkConf().setMaster('local[*]').setAppName('test_spark_app')# 基于SparkConf类对象创建SparkContext类对象
sc = SparkContext(conf=conf)rdd = sc.parallelize(['a b c', 'd e f'])# 输出RDD的内容,需要使用collect()
print(rdd.map(lambda x: x.split(' ')).collect()) # [['a', 'b', 'c'], ['d', 'e', 'f']]
print(rdd.flatMap(lambda x:x.split(' ')).collect()) # ['a', 'b', 'c', 'd', 'e', 'f']# 停止SparkContext对象的运行(停止PySpark程序)
sc.stop()
reduceByKey算子
针对KV型(二元元组)RDD,自动按照key分组,然后根据你提供的聚合逻辑,完成组内数据(value)的聚合操作
rdd.reduceByKey(func)
# func: (V, V) -> V
# 接收2个传入参数(类型要一致),返回一个返回值,返回值类型和传入参数类型要求一致
示例:
# 导包
from pyspark import SparkConf, SparkContext, sql
import os# 设置环境变量
os.environ['PYSPARK_PYTHON'] = 'D:/Python/python.exe'# 创建SparkConf类对象
conf = SparkConf().setMaster('local[*]').setAppName('test_spark_app')# 基于SparkConf类对象创建SparkContext类对象
sc = SparkContext(conf=conf)rdd = sc.parallelize([('a', 1), ('a', 1), ('b', 1), ('b', 1), ('b', 1)])# 输出RDD的内容,需要使用collect()
print(rdd.reduceByKey(lambda a, b: a+b).collect()) # [('b', 3), ('a', 2)]# 停止SparkContext对象的运行(停止PySpark程序)
sc.stop()
reduceByKey中的聚合逻辑是:比如有[1,2,3,4,5],然后聚合函数是:lambda a,b: a+b
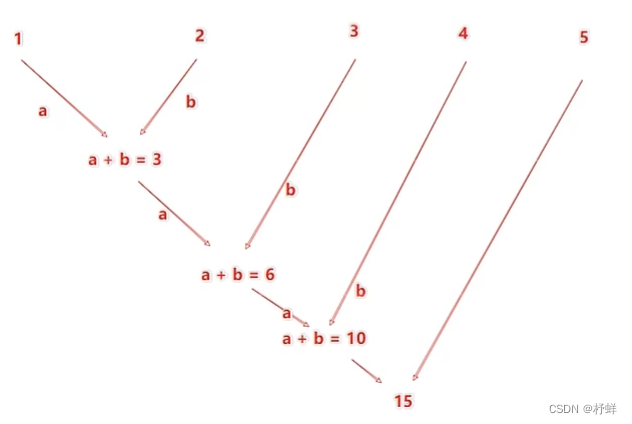
注意:reduceByKey中接收的函数,只负责聚合,不理会分组;分组是自动
by key来分组的
filter算子
过滤想要的数据进行保留。
rdd.filter(func)
# func: (T) -> bool
# 传入一个参数任意类型,返回值必须是True/False,返回是True的数据被保留,False的数据被丢弃
示例:
# 导包
from pyspark import SparkConf, SparkContext, sql
import os# 设置环境变量
os.environ['PYSPARK_PYTHON'] = 'D:/Python/python.exe'# 创建SparkConf类对象
conf = SparkConf().setMaster('local[*]').setAppName('test_spark_app')# 基于SparkConf类对象创建SparkContext类对象
sc = SparkContext(conf=conf)rdd = sc.parallelize([1, 2, 3, 4, 5, 6])# 输出RDD的内容,需要使用collect()
print(rdd.filter(lambda x: x % 2 == 0).collect()) # [2, 4, 6]# 停止SparkContext对象的运行(停止PySpark程序)
sc.stop()
distinct算子
对RDD数据进行去重,返回新的RDD
rdd.distinct() # 无需传参
示例:
# 导包
from pyspark import SparkConf, SparkContext, sql
import os# 设置环境变量
os.environ['PYSPARK_PYTHON'] = 'D:/Python/python.exe'# 创建SparkConf类对象
conf = SparkConf().setMaster('local[*]').setAppName('test_spark_app')# 基于SparkConf类对象创建SparkContext类对象
sc = SparkContext(conf=conf)rdd = sc.parallelize([1, 2, 3, 3, 2, 6])# 输出RDD的内容,需要使用collect()
print(rdd.distinct().collect()) # [6, 1, 2, 3]# 停止SparkContext对象的运行(停止PySpark程序)
sc.stop()
sortBy算子
对RDD数据进行排序,基于你指定的排序依据。
rdd.sortKey(func, ascending=False, numPartitions=1)
# func: (T) -> U:告知按照RDD中的哪个数据进行排序,比如lambda x: x[1]表示按照RDD中的第二列元素进行排序
# ascending:True升序,False降序
# numPartitions:用多少分区排序,全局排序需要设置为1
示例:
# 导包
from pyspark import SparkConf, SparkContext, sql
import os# 设置环境变量
os.environ['PYSPARK_PYTHON'] = 'D:/Python/python.exe'# 创建SparkConf类对象
conf = SparkConf().setMaster('local[*]').setAppName('test_spark_app')# 基于SparkConf类对象创建SparkContext类对象
sc = SparkContext(conf=conf)rdd = sc.parallelize([('Aiw', 9), ('Tom', 6), ('Jack', 8), ('Bolb', 5)])# 输出RDD的内容,需要使用collect()
print(rdd.sortBy(lambda x: x[1], ascending=False,numPartitions=1).collect()) # [('Aiw', 9), ('Jack', 8), ('Tom', 6), ('Bolb', 5)]# 停止SparkContext对象的运行(停止PySpark程序)
sc.stop()
数据输出
collect算子
将RDD各个分区内的数据,统一收集到Driver中,形成一个List对象。
rdd.collect()
# 返回值是一个List
示例:
# 导包
from pyspark import SparkConf, SparkContext, sql
import os# 设置环境变量
os.environ['PYSPARK_PYTHON'] = 'D:/Python/python.exe'# 创建SparkConf类对象
conf = SparkConf().setMaster('local[*]').setAppName('test_spark_app')# 基于SparkConf类对象创建SparkContext类对象
sc = SparkContext(conf=conf)rdd = sc.parallelize([1, 2, 3])rdd_list: list = rdd.collect()print(rdd_list) # [1, 2, 3]
print(type(rdd_list)) # <class 'list'># 停止SparkContext对象的运行(停止PySpark程序)
sc.stop()
reduce算子
对RDD数据集按照你传入的逻辑进行聚合
rdd.reduce(func)
# func:(T, T) -> T
# 传入2个参数,1个返回值,要求返回值和参数类型一致
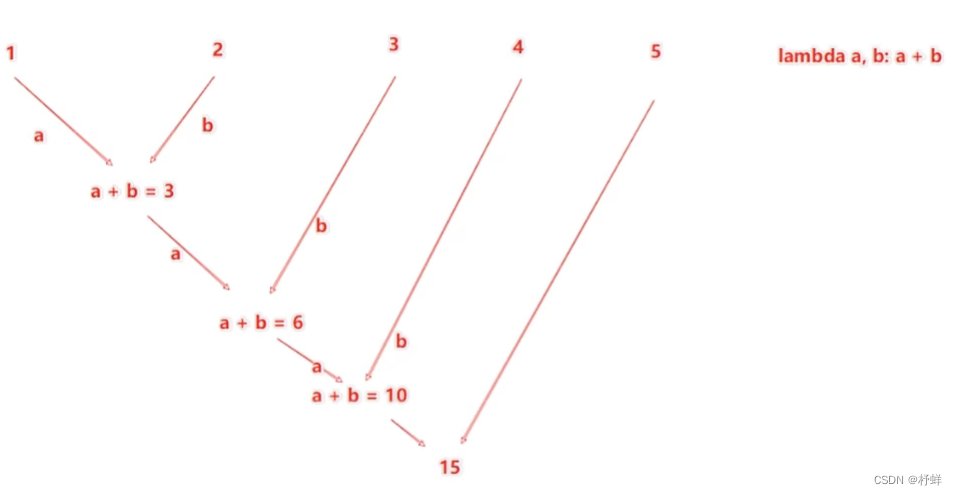
示例:
# 导包
from pyspark import SparkConf, SparkContext, sql
import os# 设置环境变量
os.environ['PYSPARK_PYTHON'] = 'D:/Python/python.exe'# 创建SparkConf类对象
conf = SparkConf().setMaster('local[*]').setAppName('test_spark_app')# 基于SparkConf类对象创建SparkContext类对象
sc = SparkContext(conf=conf)rdd = sc.parallelize(range(1, 10))print(rdd.reduce(lambda a, b: a+b)) # 45# 停止SparkContext对象的运行(停止PySpark程序)
sc.stop()
take算子
取RDD的前N个元素,组合成List进行返回。
# 导包
from pyspark import SparkConf, SparkContext, sql
import os# 设置环境变量
os.environ['PYSPARK_PYTHON'] = 'D:/Python/python.exe'# 创建SparkConf类对象
conf = SparkConf().setMaster('local[*]').setAppName('test_spark_app')# 基于SparkConf类对象创建SparkContext类对象
sc = SparkContext(conf=conf)rdd = sc.parallelize(range(1, 10))rdd_take: list = rdd.take(3)print(rdd_take) # [1, 2, 3]
print(type(rdd_take)) # <class 'list'># 停止SparkContext对象的运行(停止PySpark程序)
sc.stop()
count算子
计算RDD有多少条数据,返回值是一个数字。
# 导包
from pyspark import SparkConf, SparkContext, sql
import os# 设置环境变量
os.environ['PYSPARK_PYTHON'] = 'D:/Python/python.exe'# 创建SparkConf类对象
conf = SparkConf().setMaster('local[*]').setAppName('test_spark_app')# 基于SparkConf类对象创建SparkContext类对象
sc = SparkContext(conf=conf)rdd = sc.parallelize(range(1, 10))rdd_count: int = rdd.count()print(rdd_count) # 9
print(type(rdd_count)) # <class 'int'># 停止SparkContext对象的运行(停止PySpark程序)
sc.stop()
saveAsTextFile算子
将RDD的数据写入文本文件中。支持本地写出、HDFS等文件系统。
注意事项:

# 导包
from pyspark import SparkConf, SparkContext, sql
import os# 设置环境变量
os.environ['PYSPARK_PYTHON'] = 'D:/Python/python.exe'
os.environ['HADOOP_HOME'] = 'D:/Hadoop-3.0.0'# 创建SparkConf类对象
conf = SparkConf().setMaster('local[*]').setAppName('test_spark_app')# 基于SparkConf类对象创建SparkContext类对象
sc = SparkContext(conf=conf)rdd = sc.parallelize(range(1, 10))rdd.saveAsTextFile('./8.27/output') # 运行之前确保输出文件夹不存在,否则报错# 停止SparkContext对象的运行(停止PySpark程序)
sc.stop()
上述代码输出结果,输出文件夹内有多个分区文件
修改RDD分区为1个
方式一:SparkConf对象设置属性全局并行度为1:
# 创建SparkConf类对象
conf = SparkConf().setMaster('local[*]').setAppName('test_spark_app')
# 设置属性全局并行度为1
conf.set('spark.default.parallelism','1')
# 基于SparkConf类对象创建SparkContext类对象
sc = SparkContext(conf=conf)
方式二:创建RDD的时候设置(parallelize方法传入numSlices参数为1)
rdd = sc.parallelize(range(1, 10), numSlices=1)
rdd = sc.parallelize(range(1, 10), 1)
相关文章:
【Python】PySpark
前言 Apache Spark是用于大规模数据(large-scala data)处理的统一(unified)分析引擎。 简单来说,Spark是一款分布式的计算框架,用于调度成百上千的服务器集群,计算TB、PB乃至EB级别的海量数据…...

pycharm 打开Terminal时报错activate.ps1,因为在此系统上禁止运行脚本,并因此无法进入虚拟环境
pycharm 打开Terminal时报错activate.ps1,因为在此系统上禁止运行脚本,并因此无法进入虚拟环境 如下图所示: 网上说可以set_restrictFalse什么的,虽然也可但可能会降低电脑安全性,可以将下面的终端改为cmd.exe即可...

[C++][C#]yolox TensorRT C++ C#部署
YOLOX是一种新型的高性能探测器,由开发者Zheng Ge、Songtao Liu、Feng Wang、Zeming Li和Jian Sun在《YOLOX: Exceeding YOLO Series in 2021》首次提出。与YOLOV5和YOLOV8相比,YOLOX具有更高的性能和更好的平衡,在速度和精度方面都表现出优越…...

根据源码,模拟实现 RabbitMQ - 网络通讯设计,自定义应用层协议,实现 BrokerServer (8)
目录 一、网络通讯协议设计 1.1、交互模型 1.2、自定义应用层协议 1.2.1、请求和响应格式约定 编辑 1.2.2、参数说明 1.2.3、具体例子 1.2.4、特殊栗子 1.3、实现 BrokerServer 1.3.1、属性和构造 1.3.2、启动 BrokerServer 1.3.3、停止 BrokerServer 1.3.4、处…...
MongoDB入门
简介 MongoDB是一个开源、高性能、支持海量数据存储的文档型数据库 是NoSQL数据库产品中的一种,是最像关系型数据库(MySQL)的非关系型数据库 内部采用BSON(二进制JSON)格式来存储数据,并支持水平扩展。 MongoDB本身并不是完全免费的,它对于…...

vr智慧党建主题展厅赋予企业数字化内涵
现如今,VR全景技术的发展让我们动动手指就能在线上参观博物馆、纪念馆,不仅不用受时间和空间的限制,还能拥有身临其境般的体验,使得我们足不出户就能随时随地学习、传承红色文化。 很多党建展厅都是比较传统的,没有运用…...

go中mutex的sema信号量是什么?
先看下go的sync.mutex是什么 type Mutex struct {state int32sema uint32 } 这里面有个sema,这个就是信号量。 什么是信号量? 什么是信号量?_kina100的博客-CSDN博客 其实通俗的来说,信号量就是信号灯,但是他不是…...

LeetCode笔记:Weekly Contest 360
LeetCode笔记:Weekly Contest 360 0. 吐槽1. 题目一 1. 解题思路2. 代码实现 2. 题目二 1. 解题思路2. 代码实现 3. 题目三 1. 解题思路2. 代码实现 4. 题目四 1. 解题思路2. 代码实现 比赛链接:https://leetcode.com/contest/weekly-contest-360/ 0.…...
【树DP】2021ICPC南京 H
Problem - H - Codeforces 题意: 思路: 这题应该算是铜牌题 铜牌题 简单算法 基础思维 简单复盘一下思路 首先,我们发现有个很特殊的条件: ti < 3 然后看一下样例: 注意到,对于一个结点 u &#…...
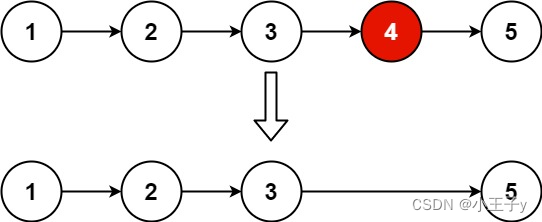
Leedcode19. 删除链表的倒数第 N 个结点
给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。 输入:head [1,2,3,4,5], n 2 输出:[1,2,3,5] 示例 2: 输入:head [1], n 1 输出:[] 示例 3: 输入࿱…...
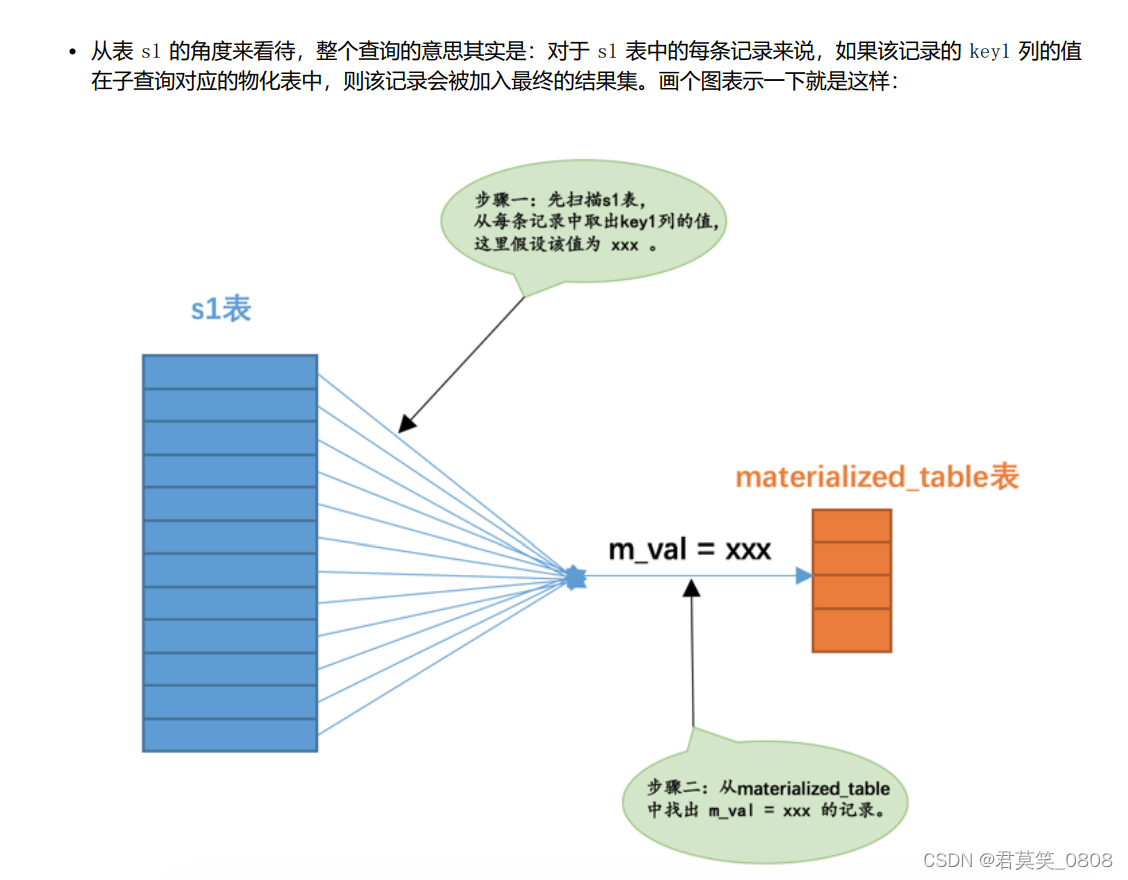
Mysql-索引查询相关
一、单表查询 1.1 二级索引为null 不论是普通的二级索引,还是唯一二级索引,它们的索引列对包含 NULL 值的数量并不限制,所以我们采用key IS NULL 这种形式的搜索条件最多只能使用 ref 的访问方法,而不是 const 的访问方法 1.2 c…...

C++ Pimpl
Pimpl(Pointer to implementation,指向实现的指针) 是一种减少代码依赖和编译时间的C编程技巧,其基本思想是将一个外部可见类(visible class)的实现细节(一般是所有私有的非虚成员)放在一个单独的实现类(implementation class)中&…...

rust学习-类型转换
基本类型转换 // 不显示类型转换产生的溢出警告。 #![allow(overflowing_literals)]fn main() {let decimal 65.4321_f32;// 错误!不提供隐式转换// let integer: u8 decimal;// 可以显式转换let integer decimal as u8;let character integer as char;println…...
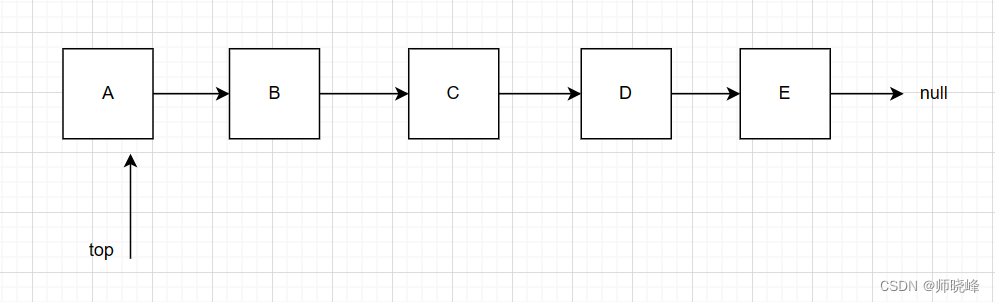
算法通过村第四关-栈青铜笔记|手写栈操作
文章目录 前言1. 栈的基础概要1.1 栈的特征1.2 栈的操作1.3 Java中的栈 2. 栈的实现(手写栈)2.1 基于数组实现2.2 基于链表实现2.3 基于LinkedList实现 总结 前言 提示:我自己一个人的感觉很好 我并不想要拥有你 除非你比我的独处更加宜人 --…...

Python计算加速利器
迷途小书童的 Note 读完需要 6分钟 速读仅需 2 分钟 1 简介 Python 是一门应用非常广泛的高级语言,但是,长久以来,Python的运行速度一直被人诟病,相比 c/c、java、c#、javascript 等一众高级编程语言,完全没有优势。 那…...
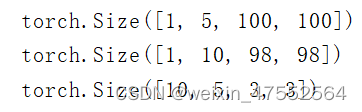
PyTorch 深度学习实践 第10讲刘二大人
总结: 1.输入通道个数 等于 卷积核通道个数 2.卷积核个数 等于 输出通道个数 1.单通道卷积 以单通道卷积为例,输入为(1,5,5),分别表示1个通道,宽为5,高为5。假设卷积核大小为3x3,…...

Linux特殊指令
目录 1.dd命令 2.mkfs格式化 3.df命令 4.mount实现硬盘的挂载 5.unshare 1.dd命令 dd命令可以用来读取转换并输出数据。 示例一: if表示infile,of表示outfile。这里的/dev/zero是一个特殊文件,会不断产生空白数据。 bs表示复制一块的大…...

MPI之主从模式的一般编程示例
比如,我们可以选举0号进程为master进程,其余进程为slaver进程 #include "mpi.h" #include <unistd.h> #include <iostream>int main(int argc, char *argv[]) {int err MPI_Init(&argc,&argv);int rank,size;MPI_Comm_r…...

基于野狗算法优化的BP神经网络(预测应用) - 附代码
基于野狗算法优化的BP神经网络(预测应用) - 附代码 文章目录 基于野狗算法优化的BP神经网络(预测应用) - 附代码1.数据介绍2.野狗优化BP神经网络2.1 BP神经网络参数设置2.2 野狗算法应用 4.测试结果:5.Matlab代码 摘要…...

C语言面向对象的编程思想
面向对象编程 面向对象编程Object-Oriented Programming,OOP) 作为一种新方法,其本质是以建立模型体现出来的抽象思维过程和面向对象的方法。模型是用来反映现实世界中事物特征的。任何一个模型都不可能反映客观事物的一切具体特征࿰…...
)
保姆级教程:在CentOS 7上用达梦8搭建DCA练习环境(附ulimit、VNC、ODBC全配置)
达梦8 DCA认证实战:CentOS 7环境搭建与调优全指南 在国产数据库技术快速发展的今天,达梦数据库作为核心产品之一,其DCA认证已成为众多从业者提升竞争力的重要选择。与理论为主的认证不同,DCA更注重实际操作能力,而一个…...

混合求解器:用神经网络增强传统微分方程数值方法
1. 项目概述:当数值方法遇到机器学习在科学计算和工程仿真领域,求解常微分方程(ODE)和偏微分方程(PDE)是绕不开的核心任务。无论是模拟电路中的电流变化、预测天气系统的演变,还是分析机械结构的…...

Unity安卓打包实战指南:从环境配置到APK生成全链路排错
1. 这不是“入门教程”,而是一份写给真实开发现场的生存指南你打开Unity,新建一个3D项目,拖进一个Cube,点击Play——它动了。你松了口气,觉得“Unity好像也没那么难”。但当你把APK打包发给测试同事,对方回…...

Godot中型项目工程化实践:目录规范、资源引用与状态管理
1. 这不是续集,而是项目落地的分水岭“Godot 游戏引擎项目(二)”——看到这个标题,很多人第一反应是:“哦,上一篇讲了环境搭建和Hello World,这篇该讲节点树和信号了?”但我在带三个…...

【python】ImportError: DLL load failed while importing QtWidgets: 找不到指定的程序。重新安装后搞定
文章目录前言一、PyQt6引用后报错二、使用步骤总结前言 想做个好看的界面,引用了PyQt6,却产生了新问题。 pip install pyqt6-tools,优先做这个动作进行修复。 一、PyQt6引用后报错 python里引用: from PyQt6.QtWidgets import…...

uWSGI目录穿越漏洞CVE-2018-7490深度利用与防御实战
1. 这不是“读文件”那么简单:uWSGI目录穿越在真实攻防链中的定位与误判代价你刚在Vulfocus靶场里跑通了CVE-2018-7490的PoC,用curl "http://target:8080/?p../../../../etc/passwd"成功读出了root:x:0:0:root:/root:/bin/bash,截…...

HiveWE终极指南:快速掌握魔兽争霸III现代化地图编辑器
HiveWE终极指南:快速掌握魔兽争霸III现代化地图编辑器 【免费下载链接】HiveWE A Warcraft III world editor. 项目地址: https://gitcode.com/gh_mirrors/hi/HiveWE 还在为传统魔兽争霸III地图编辑器缓慢的加载速度和复杂的操作界面而烦恼吗?Hiv…...

ModernWMS核心功能详解:从ASN入库到Dispatch出库的完整工作流
ModernWMS核心功能详解:从ASN入库到Dispatch出库的完整工作流 【免费下载链接】ModernWMS The open source simple and complete warehouse management system is derived from our many years of experience in implementing erp projects. We stripped the origin…...

Xia Sql插件:可调试的SQL注入决策引擎
1. 这不是又一个“自动扫SQL”的插件,而是把渗透工程师的判断逻辑塞进了Burp里你有没有过这种经历:在Burp Proxy里看着一堆GET参数、POST JSON、Cookie字段,心里清楚“这里大概率能注入”,但手动拼payload试了七八轮,还…...

CMSIS-DAP调试器原理与应用:以Elektor mbed interface为例
1. 项目概述:Elektor mbed interface [150554] 是什么?如果你玩过ARM Cortex-M系列的单片机,尤其是NXP LPC800系列,那你可能对“CMSIS-DAP”这个调试器标准不陌生。它是由ARM官方推出的一个开源调试接口标准,最大的好处…...