使用Linux部署Kafka教程
目录
一、部署Zookeeper
1 拉取Zookeeper镜像
2 运行Zookeeper
二、部署Kafka
1 拉取Kafka镜像
2 运行Kafka
三、验证是否部署成功
1 进入到kafka容器中
2 创建topic 生产者
3 生产者发送消息
4 消费者消费消息
四、搭建kafka管理平台
五、SpringBoot整合Kafka
1、导入依赖
2、修改配置
3、生产者
4、消费者
5、测试发送消息
6、测试收到消息
一、部署Zookeeper
1 拉取Zookeeper镜像
docker pull wurstmeister/zookeeper
- 1
2 运行Zookeeper
docker run --restart=always --name zookeeper \
--log-driver json-file \
--log-opt max-size=100m \
--log-opt max-file=2 \
-p 2181:2181 \
-v /etc/localtime:/etc/localtime \
-d wurstmeister/zookeeper二、部署Kafka
1 拉取Kafka镜像
docker pull wurstmeister/kafka
2 运行Kafka
docker run --restart=always --name kafka \
--log-driver json-file \
--log-opt max-size=100m \
--log-opt max-file=2 \-p 9092:9092 \-e KAFKA_BROKER_ID=0 \-e KAFKA_ZOOKEEPER_CONNECT=192.168.8.102:2181 \-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.8.102:9092 \-e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 \-v /etc/localtime:/etc/localtime \-d wurstmeister/kafka
参数说明:
-e KAFKA_BROKER_ID=0 在kafka集群中,每个kafka都有一个BROKER_ID来区分自己
-e KAFKA_ZOOKEEPER_CONNECT=172.16.0.13:2181/kafka 配置zookeeper管理kafka的路径172.16.0.13:2181/kafka
-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://172.16.0.13:9092 把kafka的地址端口注册给zookeeper,如果是远程访问要改成外网IP,类如Java程序访问出现无法连接。
-e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 配置kafka的监听端口
-v /etc/localtime:/etc/localtime 容器时间同步虚拟机的时间
三、验证是否部署成功
1 进入到kafka容器中
docker exec -it kafka /bin/sh
2 创建topic 生产者
cd opt/kafka_2.13-2.8.1bin/kafka-topics.sh --create --zookeeper 192.168.8.102:2181 --replication-factor 1 --partitions 1 --topic partopic

3 生产者发送消息
bin/kafka-console-producer.sh --broker-list 192.168.8.102:9092 --topic partopic

4 消费者消费消息
- 新打开个ssh窗口
- 跟前面步骤一样进入到容器
bin/kafka-console-consumer.sh --bootstrap-server 192.168.8.102:9092 --topic partopic --from-beginning
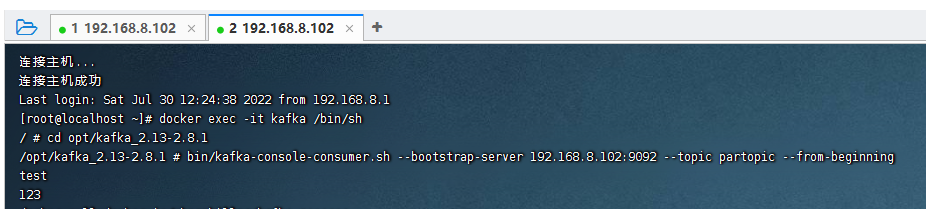
四、搭建kafka管理平台
docker search kafdrop

docker run -d --rm -p 9000:9000 \-e JVM_OPTS="-Xms32M -Xmx64M" \-e KAFKA_BROKERCONNECT=<host:port,host:port> \-e SERVER_SERVLET_CONTEXTPATH="/" \obsidiandynamics/kafdrop<host:port,host:port> 为 外网集群地址 多个用逗号分隔 例如xxx.xxx.xxx.xxx:9092,yyy.yyy.yyy.yyy:9092 尖角号不留上面的命令是百度的以下是我自己尝试的
docker run -d --name kafdrop -p 9001:9001 \-e JVM_OPTS="-Xms32M -Xmx64M -Dserver.port=9001" \-e KAFKA_BROKERCONNECT=192.168.58.130:9092 \-e SERVER_SERVLET_CONTEXTPATH="/" \obsidiandynamics/kafdrop因为我docker启动了其他东西占用了9001端口,而这个kafdrop其实就是一个springboot项目,以jar命令的形式启动访问地址:Kafdrop: Broker List

五、SpringBoot整合Kafka
1、导入依赖
<dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId></dependency>2、修改配置
spring:kafka:bootstrap-servers: 192.168.58.130:9092 #部署linux的kafka的ip地址和端口号producer:# 发生错误后,消息重发的次数。retries: 1#当有多个消息需要被发送到同一个分区时,生产者会把它们放在同一个批次里。该参数指定了一个批次可以使用的内存大小,按照字节数计算。batch-size: 16384# 设置生产者内存缓冲区的大小。buffer-memory: 33554432# 键的序列化方式key-serializer: org.apache.kafka.common.serialization.StringSerializer# 值的序列化方式value-serializer: org.apache.kafka.common.serialization.StringSerializer# acks=0 : 生产者在成功写入消息之前不会等待任何来自服务器的响应。# acks=1 : 只要集群的首领节点收到消息,生产者就会收到一个来自服务器成功响应。# acks=all :只有当所有参与复制的节点全部收到消息时,生产者才会收到一个来自服务器的成功响应。acks: 1consumer:# 自动提交的时间间隔 在spring boot 2.X 版本中这里采用的是值的类型为Duration 需要符合特定的格式,如1S,1M,2H,5Dauto-commit-interval: 1S# 该属性指定了消费者在读取一个没有偏移量的分区或者偏移量无效的情况下该作何处理:# latest(默认值)在偏移量无效的情况下,消费者将从最新的记录开始读取数据(在消费者启动之后生成的记录)# earliest :在偏移量无效的情况下,消费者将从起始位置读取分区的记录auto-offset-reset: earliest# 是否自动提交偏移量,默认值是true,为了避免出现重复数据和数据丢失,可以把它设置为false,然后手动提交偏移量enable-auto-commit: false# 键的反序列化方式key-deserializer: org.apache.kafka.common.serialization.StringDeserializer# 值的反序列化方式value-deserializer: org.apache.kafka.common.serialization.StringDeserializerlistener:# 在侦听器容器中运行的线程数。concurrency: 5#listner负责ack,每调用一次,就立即commitack-mode: manual_immediatemissing-topics-fatal: false本次测试:linux地址:192.168.58.130
spring.kafka.bootstrap-servers=192.168.58.130:9092
advertised.listeners=192.168.58.130:9092
3、生产者
import com.alibaba.fastjson.JSON;import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.SendResult;
import org.springframework.stereotype.Component;
import org.springframework.util.concurrent.ListenableFuture;
import org.springframework.util.concurrent.ListenableFutureCallback;/*** 事件的生产者*/
@Slf4j
@Component
public class KafkaProducer {@Autowiredpublic KafkaTemplate kafkaTemplate;/** 主题 */public static final String TOPIC_TEST = "Test";/** 消费者组 */public static final String TOPIC_GROUP = "test-consumer-group";public void send(Object obj){String obj2String = JSON.toJSONString(obj);log.info("准备发送消息为:{}",obj2String);//发送消息ListenableFuture<SendResult<String, Object>> future = kafkaTemplate.send(TOPIC_TEST, obj);//回调future.addCallback(new ListenableFutureCallback<SendResult<String, Object>>() {@Overridepublic void onFailure(Throwable ex) {//发送失败的处理log.info(TOPIC_TEST + " - 生产者 发送消息失败:" + ex.getMessage());}@Overridepublic void onSuccess(SendResult<String, Object> result) {//成功的处理log.info(TOPIC_TEST + " - 生产者 发送消息成功:" + result.toString());}});}}4、消费者
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.support.Acknowledgment;
import org.springframework.kafka.support.KafkaHeaders;
import org.springframework.messaging.handler.annotation.Header;
import org.springframework.stereotype.Component;import java.util.Optional;/*** 事件消费者*/
@Component
public class KafkaConsumer {private Logger logger = LoggerFactory.getLogger(org.apache.kafka.clients.consumer.KafkaConsumer.class);@KafkaListener(topics = KafkaProducer.TOPIC_TEST,groupId = KafkaProducer.TOPIC_GROUP)public void topicTest(ConsumerRecord<?,?> record, Acknowledgment ack, @Header(KafkaHeaders.RECEIVED_TOPIC) String topic){Optional<?> message = Optional.ofNullable(record.value());if (message.isPresent()) {Object msg = message.get();logger.info("topic_test 消费了: Topic:" + topic + ",Message:" + msg);ack.acknowledge();}}
}5、测试发送消息
@Testvoid kafkaTest(){kafkaProducer.send("Hello Kafka");}6、测试收到消息
![]()
相关文章:

使用Linux部署Kafka教程
目录 一、部署Zookeeper 1 拉取Zookeeper镜像 2 运行Zookeeper 二、部署Kafka 1 拉取Kafka镜像 2 运行Kafka 三、验证是否部署成功 1 进入到kafka容器中 2 创建topic 生产者 3 生产者发送消息 4 消费者消费消息 四、搭建kafka管理平台 五、SpringBoot整合Kafka 1…...

pyechart笔记:opts.AxisOpts
定制化图表的轴线(x轴和y轴)的样式和设置 0 不设置坐标轴 c1(Bar().add_xaxis([力量,智力,敏捷]).add_yaxis(全能骑士,# 系列名称,用于 tooltip 的显示,legend 的图例筛选。[429,321,296],#系列数据).add_yaxis(猴子,[352,236,4…...

深度思考rpc框架面经之五:rpc熔断限流、rpc复用连接机制
11 RPC框架如何实现限流和熔断 推荐文章:RPC实现原理之核心技术-限流熔断 11.1 为什么Dubbo要做服务的限流?(根本原因是服务端进行自我保护) 限流是一种常见的系统保护手段。在分布式系统和微服务架构中,一个接口的过度使用可能会导致资源…...

Go 数组
数组用于在单个变量中存储相同类型的多个值,而不是为每个值声明单独的变量。 声明数组 在Go中,有两种声明数组的方式: 使用var关键字: 语法 var array_name [length]datatype{values} // 这里定义了长度 或者 var array_n…...
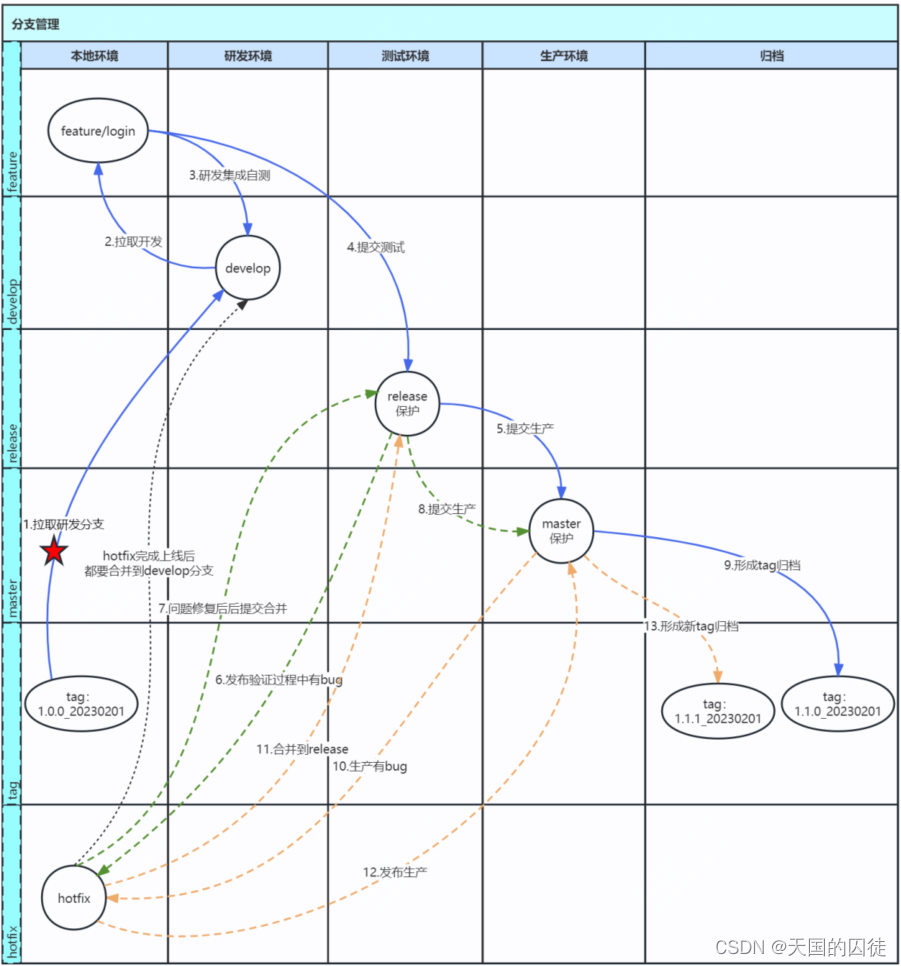
04架构管理之分支管理实践-一种git分支管理最佳实践
专栏说明:针对于企业的架构管理岗位,分享架构管理岗位的职责,工作内容,指导架构师如何完成架构管理工作,完成架构师到架构管理者的转变。计划以10篇博客阐述清楚架构管理工作,专栏名称:架构管理…...

D.OASIS City 和 Warrix 在The Sandbox 庆祝 Rise of the 10th Legend十周年
D.OASIS 首次展示了变革性娱乐 D.OASIS City,正如它与 WARRIX 一起承诺的那样。WARRIX 是获得泰国国家队球衣生产授权的标志性运动服装品牌。 这款激动人心的游戏冒险游戏于今天推出,让用户能够投入 D.OASIS City x WARRIX:Rise of the 10th…...
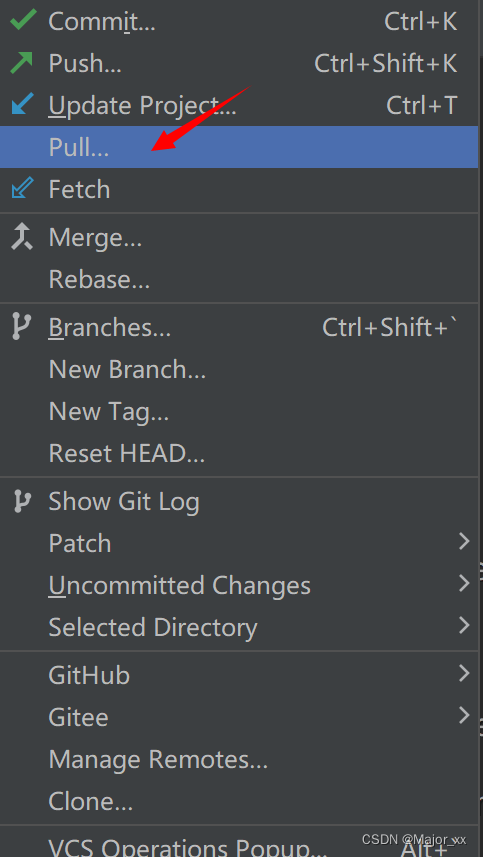
Git基本操作(Idea版)
第一次发布项目(本地->远程) 方式一 通过push的方式推送本地库到远程库(远程已创建好仓库) 这种方式需要提前创建好仓库。 右键点击项目,可以将当前分支的内容 push 到 GitHub 的远程仓库中。 注意:…...
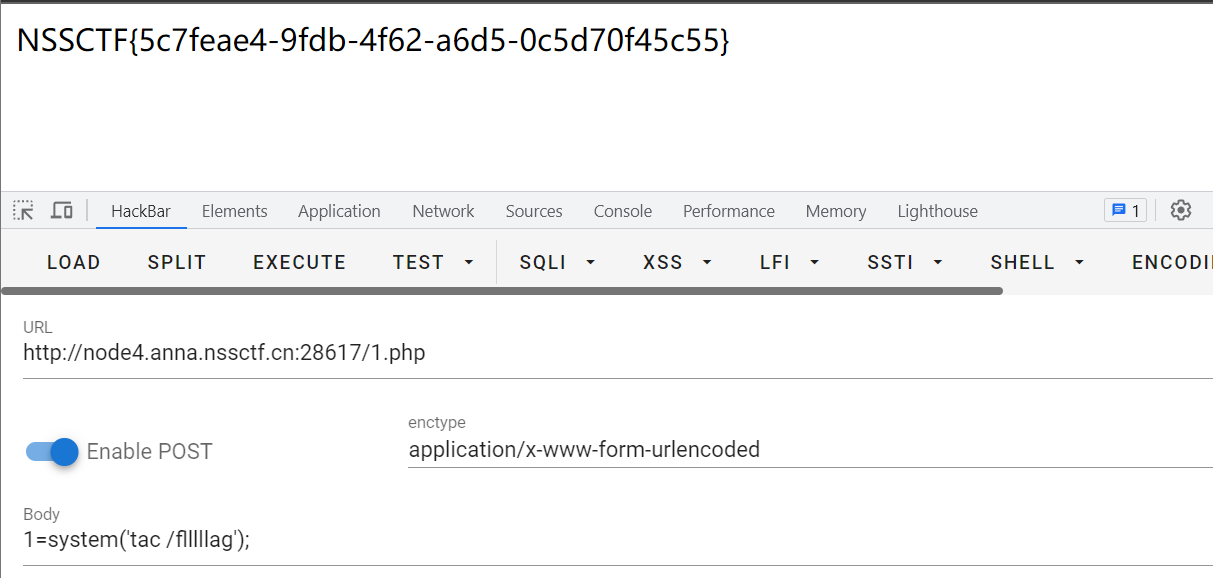
NSS [羊城杯 2020]easyser
NSS [羊城杯 2020]easyser 开题。很容易让人觉得环境坏了。 不要慌,无从下手时。看源码、扫目录、抓包。一套操作下来,发现几个可以下手的路由。 /index.php /robots.txt 访问 /star1.php,一说到百度,就猜测是否存在SSRF。 源码中…...
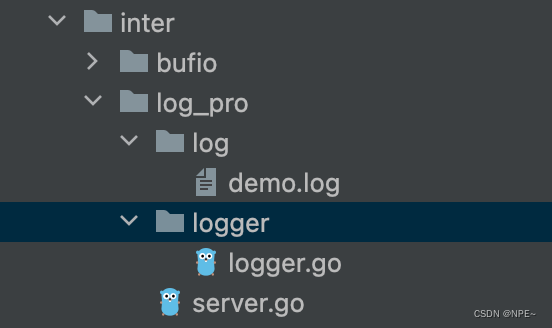
理解底层— —Golang的log库,二开实现自定义Logger
理解底层— —Golang的log库,实现自定义Logger 1 分析实现思路 基于golang中自带的log库实现:对日志实现设置日志级别,每天生成一个文件,同时添加上前缀以及展示文件名等 日志级别,通过添加prefix:[INFO]、…...
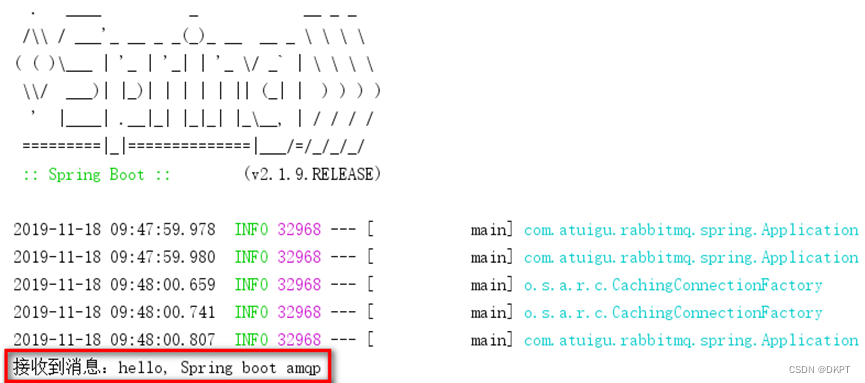
RabbitMQ---Spring AMQP
Spring AMQP 1. 简介 Spring有很多不同的项目,其中就有对AMQP的支持: Spring AMQP的页面:http://spring.io/projects/spring-amqp 注意这里一段描述: Spring-amqp是对AMQP协议的抽象实现,而spring-rabbit 是对协…...

C语言练习题解析:挑战与突破,开启编程新篇章!(2)
💓博客主页:江池俊的博客⏩收录专栏:C语言刷题专栏👉专栏推荐:✅C语言初阶之路 ✅C语言进阶之路💻代码仓库:江池俊的代码仓库🎉欢迎大家点赞👍评论📝收藏⭐ 文…...

sqlite3 加密访问
关于sqlite3 加密 一、相关加密用到的sqlcipher 1.1 sqlcipher 是一个数据库加密的开源库 sqlcipher开源地址 我这边是使用的docker镜像,镜像地址: https://hub.docker.com/r/pallocchi/sqlcipher 加密格式 docker run -v <workdir>:/sqlcip…...

clickhouse 系列1:clickhouse v21.7.5.29 源码编译
1.gcc10安装 安装依赖 yum update yum install -y gcc gcc-c++ yum install -y bzip2 下载gcc 源码包并解压 wget -P /data/base https://mirrors.aliyun.com/gnu/gcc/gcc-10.2.0/gcc-10.2.0.tar.gz cd /data/base && tar -xzvf /data/base/gcc-...

servlet初体验之环境搭建!!!
我们需要用到tomcat服务器,咩有下载的小伙伴看过来:如何正确下载tomcat???_明天更新的博客-CSDN博客 1. 创建普通的Java项目,并在项目中创建libs目录存放第三方的jar包。 建立普通项目 创建libs目录存放第三…...

宁芝 NIZ 键盘开机需要重新插拔 USB 线才能使用
宁芝 NIZ 键盘开机需要重新插拔 USB 线才能使用 问题描述 宁芝 NIZ 键盘开机后无法识别到键盘,需要重新插拔 USB 线才能使用。 解决方法 按住 Fn BackSpaceE 键 5 秒,键盘会切换模式, 状态灯闪 1 次为 USB 接口;状态灯闪 2 次为 PS / 2 …...

R编程教程_编程入门自学教程_菜鸟教程-免费教程分享
教程简介 R是用于统计分析、绘图的语言和操作环境。R是属于GNU系统的一个自由、免费、源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具。R语言的核心是解释计算机语言,其允许分支和循环以及使用函数的模块化编程。 R语言允许与以Cÿ…...

[CMake教程] CMake列表 - list
目录 零、简介一、Reading二、Search三、Modification四、Ordering 零、简介 列表在CMake中大量使用。初始化列表语法如下: set(myList a b c) # Creates the list "a;b;c"归根结底,列表只是一个由分号分隔列表项的单个字符串,这…...
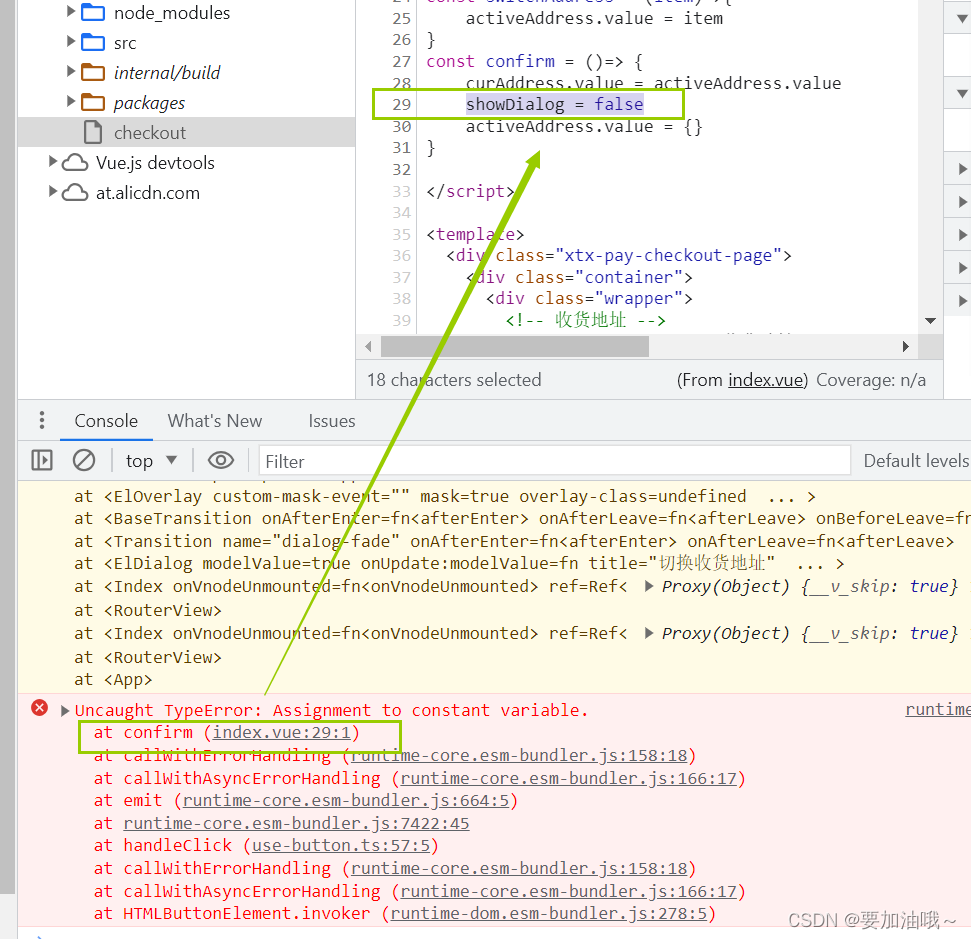
报错 - net::ERR_ABORTED 500 (Internal Server Error)
报错:net::ERR_ABORTED 500 (Internal Server Error) 根据提示找到对应文件 解决:检查代码,根据高亮颜色判断,发现箭头函数漏了一个>。 报错:Uncaught TypeError: Assignment to constant variable. 原因&#x…...

【Java Easypoi Apache poi】 Word导入与导出
引入依赖 <dependency><groupId>cn.afterturn</groupId><artifactId>easypoi-spring-boot-starter</artifactId> </dependency> <!-- 下面的版本需要对应上面依赖中的版本 否则可能会起冲突 --> <!-- 下面的依赖主要是为了使用A…...
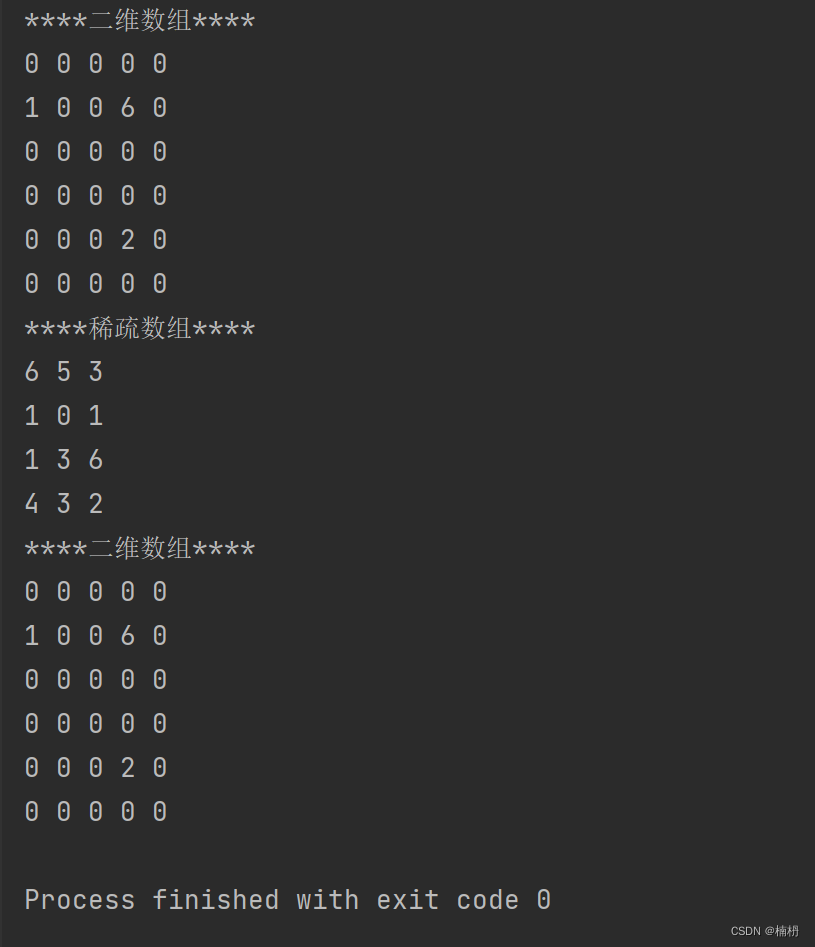
Java稀疏数组
目录 1.稀疏数组 2.稀疏数组的使用 2.1 二维数组转换为稀疏数组 2.2 稀疏数组转换为二维数组 1.稀疏数组 稀疏数组(Sparse Array):当一个数组中的大部分元素为相同的值,可使用稀疏数组来保存该数组,可以将稀疏数组…...

机器学习赋能6G近场通信:从信道估计到波束赋形的智能革命
1. 项目概述:当6G遇见近场,为何机器学习成为破局关键?如果你关注过5G到6G的技术演进路线,会发现一个核心趋势:天线阵列的规模正在从“大规模”走向“极大规模”。这不仅仅是数量的堆砌,更是通信物理原理的一…...

从Gamma函数到泊松分布:一个概率论中的含参量积分实用案例解析
Gamma函数与泊松分布:概率论中的数学之美 在数据科学和机器学习的实践中,概率分布构成了建模的基石。当我们深入探究这些分布背后的数学原理时,Gamma函数以其优雅的性质和广泛的应用脱颖而出。它不仅连接了离散与连续概率世界,更在…...
)
Python基础语法:生成器 generator(yield)
一、简介根据指定的规则循环生成数据,当条件不成立时则生成数据结束。数据不是一次性全部生成出来,而是使用一个,再生成一个,好处是可以节约大量的内存。就像设计模式中的懒汉式。适合处理大数据或流数。生成器是一种特殊的迭代器…...

当 AI Coding 进入复杂企业系统,为什么提效远没有宣传里那么美好 ?
以 Claude Code、Codex 为代表的自主编码智能体(Coding Agents),正在以惊人的速度席卷软件开发者生态。与此同时,类似“10 倍开发效率”“普通人也能随手构建软件”“程序员即将失业”的说法,也随处可见。这种不分场景…...

AI IDE 革命:程序员正在被重新定义
很多开发者第一次使用 Cursor 的 CtrlK 或 Composer(高级多文件编辑模式)时,都会有一种强烈的、甚至让人有些脊背发凉的冲击感。 因为: 它已经不再是那个我们熟悉的、只能在原地等待光标落下的: “代码自动补全插件&am…...

基于USB ACA模式实现安卓手机边玩边充的游戏手柄设计
1. 项目缘起:当手机性能过剩,却败给了触摸屏几年前,我清理手机游戏时,发现一个挺无奈的现象:性能足以媲美掌机的智能手机里,只剩下一些慢节奏的平台解谜或者数独。那些曾经让我在掌机上废寝忘食的赛车、动作…...

NanaZip:现代Windows文件压缩问题的终极解决方案
NanaZip:现代Windows文件压缩问题的终极解决方案 【免费下载链接】NanaZip The 7-Zip derivative intended for the modern Windows experience 项目地址: https://gitcode.com/gh_mirrors/na/NanaZip 还在为Windows文件压缩工具界面老旧、功能单一而烦恼吗&…...

Style-Bert-VITS2未来发展方向:从语音克隆到实时语音转换的技术演进路线
Style-Bert-VITS2未来发展方向:从语音克隆到实时语音转换的技术演进路线 【免费下载链接】Style-Bert-VITS2 Style-Bert-VITS2: Bert-VITS2 with more controllable voice styles. 项目地址: https://gitcode.com/gh_mirrors/st/Style-Bert-VITS2 Style-Bert…...

Burp抓包失败的五大隐形墙与HTTPS解密断裂点排查指南
1. 这不是Burp用得不对,是环境链路断在了你没看见的地方“Burp抓不到包”——这句话我过去三年里听开发、测试、刚转安全的新人说了不下两百遍。但真正打开Burp一看,Proxy标签页里空空如也,连个localhost:8080的请求都没有,十有八…...

抖音批量下载助手:一键构建你的专属视频素材库
抖音批量下载助手:一键构建你的专属视频素材库 【免费下载链接】douyinhelper 抖音批量下载助手 项目地址: https://gitcode.com/gh_mirrors/do/douyinhelper 还在为手动保存抖音视频而烦恼吗?想要批量获取心仪创作者的精彩内容却无从下手&#x…...