软件测试/测试开发丨Pytest和Allure报告 学习笔记
点此获取更多相关资料
本文为霍格沃兹测试开发学社学员学习笔记分享
原文链接:https://ceshiren.com/t/topic/26755
Pytest 命名规则
| 类型 | 规则 |
|---|---|
| 文件 | test_开头 或者 _test 结尾 |
| 类 | Test 开头 |
| 方法/函数 | test_开头 |
注意:测试类中不可以添加__init__构造函数 |
注意:pytest对于测试包的命名没有要求
方法:类中定义的函数
函数:类外面定义的函数
谷歌风格开源项目风格指南:
https://zh-google-styleguide.readthedocs.io/en/latest/google-python-styleguide/python_style_rules/ 2
Pytest用例断言
断言的概念
断言(assert),是一种在程序中的一阶逻辑(如:一个结果为真或假的逻辑判断式),目的为了表示与验证软件开发者预期的结果。当程序执行到断言的位置时,对应的断言应该为真。若断言不为真时,程序会中止执行,并给出错误信息。

断言的用法
-
断言写法
assert <表达式>assert <表达式>,<描述>
assert <bool expression>;
assert <bool expression> : <message>;
示例一
def test_a():assert Truedef test_b():a = 1b = 1c = 2assert a + b == c, f"{a}+{b}=={c}, 结果为真"示例二
def test_c():a = 1b = 1c = 2assert 'abc' in "abcd"import sys
def test_plat():assert ('linux' in sys.platform), "该代码只能在 Linux 下执行"
Pytest测试框架结构(setup/teardown)
测试装置介绍
| 类型 | 规则 |
|---|---|
| setup_module/teardown_module | 全局模块级 |
| setup_class/teardown_class | 类级,只在类中前后运行一次 |
| setup_function/teardown_function | 函数级,在类外 |
| setup_method/teardown_method | 方法级,类中的每个方法执行前后 |
| setup/teardown | 在类中,运行在调用方法的前后(重点) |
Pyrest参数化用例
参数化
- 通过参数的方式传递数据,从而实现数据和脚本分离。
- 并且可以实现用例的重复生成与执行。
参数化测试函数使用
单参数情况
- 单参数,可以将数据放在列表中
search_list = ['appium','selenium','pytest']@pytest.mark.parametrize('name',search_list)
def test_search(name):assert name in search_list
多参数情况
- 将数据放在列表嵌套元组中
- 将数据放在列表嵌套列表中
# 数据放在元组中
@pytest.mark.parametrize("test_input,expected",[("3+5",8),("2+5",7),("7+5",12)
])
def test_mark_more(test_input,expected):assert eval(test_input) == expected
# 数据放在列表中
@pytest.mark.parametrize("test_input,expected",[["3+5",8],["2+5",7],["7+5",12]
])
def test_mark_more(test_input,expected):assert eval(test_input) == expected
用例重命名-添加 ids 参数
- 通过ids参数,将别名放在列表中
@pytest.mark.parametrize("test_input,expected",[("3+5",8),("2+5",7),("7+5",12)
],ids=['add_3+5=8','add_2+5=7','add_3+5=12'])
def test_mark_more(test_input,expected):assert eval(test_input) == expected
用例重命名-添加 ids 参数(中文)
@pytest.mark.parametrize("test_input,expected",[("3+5",8),("2+5",7),("7+5",12)
],ids=["3和5相加","2和5相加","7和5相加"])
def test_mark_more(test_input,expected):assert eval(test_input) == expectedids不支持中文,默认是unicode编码格式,可以用如下方法转换
# 在项目(最末一级)下创建conftest.py 文件 ,将下面内容添加进去,运行脚本
def pytest_collection_modifyitems(items):"""测试用例收集完成时,将收集到的用例名name和用例标识nodeid的中文信息显示在控制台上"""for i in items:i.name=i.name.encode("utf-8").decode("unicode_escape")i._nodeid=i.nodeid.encode("utf-8").decode("unicode_escape")
笛卡尔积
接口测试中用的较多,因为接口的值很多
-
两组数据
- a=[1,2,3]
- b=[a,b,c]
-
对应有几种组合形势 ?
- (1,a),(1,b),(1,c)
- (2,a),(2,b),(2,c)
- (3,a),(3,b),(3,c)
@pytest.mark.parametrize("b",["a","b","c"])
@pytest.mark.parametrize("a",[1,2,3])
def test_param1(a,b):print(f"笛卡积形式的参数化中 a={a} , b={b}")
执行方向:由近致远
使用 Mark 标记测试用例
Mark:标记测试用例
-
场景:只执行符合要求的某一部分用例 可以把一个web项目划分多个模块,然后指定模块名称执行。
-
解决: 在测试用例方法上加 @pytest.mark.标签名
-
执行: -m 执行自定义标记的相关用例
pytest -s 文件名 -m=webtestpytest -s test_mark_zi_09.py -m apptestpytest -s test_mark_zi_09.py -m "not ios"(必须要是双引号)- pytest -v是能输出更详细的用例信息,成功与失败不再是.和F
如何解决warnings问题
[pytest]
# 在项目目录下创建一个pytest.ini放标签,这样这些标签就不会warning。而且要换行写,也不要顶头写,会被认为是key
# 在这里注册好标签名后,pytest可以识别
markers = strbignumfloatintminuszero
pytest 设置跳过、预期失败
Mark:跳过(Skip)及预期失败(xFail)
- 这是 pytest 的内置标签,可以处理一些特殊的测试用例,不能成功的测试用例
- skip - 始终跳过该测试用例
- skipif - 遇到特定情况跳过该测试用例
- xfail - 遇到特定情况,产生一个“期望失败”输出
Skip 使用场景
-
调试时不想运行这个用例
-
标记无法在某些平台上运行的测试功能
-
在某些版本中执行,其他版本中跳过
-
比如:当前的外部资源不可用时跳过
- 如果测试数据是从数据库中取到的,
- 连接数据库的功能如果返回结果未成功就跳过,因为执行也都报错
-
解决 1:添加装饰器
@pytest.mark.skip@pytest.mark.skipif
-
解决 2:代码中添加跳过代码
pytest.skip(reason)
# 形式一:跳过这个方法
@pytest.mark.skip(reason="存在bug")
def test_double_str():print("代码未开发完")assert 'aa' == 'aa'# 形式二:跳过这个方法
@pytest.mark.skipif(sys.platform == "win32", reason="does not run on win32")
def test_case():print(sys.platform)assert True# 形式二:在代码中跳过代码
def check_login():return Falsedef test_double_str():print("start")if not check_login():pytest.skip("未登录,不进行下去")print("end")
# ============================= 1 skipped in 0.02s ======
xfail 使用场景
用于标记此用例可能会失败,当脚本失败时,测试报告也不会打印错误追踪,只是会显示xfail状态。xfail的主要作用是比如在进行测试提前时,当产品某功能尚未开发完成而进行自动化脚本开发,当然此时也可以把这些脚本注释起来,但这不是pytest推荐的做法,pytest推荐使用xfail标记,如此则虽然产品功能尚未开发完成,但是自动化脚本已经可以跑起来了,只不过在测试报告中会显示xfail而已。
- 与 skip 类似 ,预期结果为 fail ,标记用例为 fail
- 与skip不同,xfail标记的用例依然会被执行,如果执行成功就返回XPASS,执行失败就返回XFAIL。只是起到一个提示的作用。
- 用法:添加装饰器
@pytest.mark.xfail
@pytest.mark.xfail
def test_case():print("test_xfail 方法执行")assert 2 == 2
# XPASS [100%]test_xfail @pytest.mark.xfail
def test_case():print("test_xfail 方法执行")assert 1 == 2# XFAIL [100%]test_xfail 方法执行xfail = pytest.mark.xfail
@xfail(reason="bug 110")
def test_case():print("test_xfail 方法执行")assert 1 == 2# XFAIL (bug 110) [100%]test_xfail 方法执行pytest 运行用例
运行多条用例方式
如果要进入某个文件所在的目录终端,可以右键文件->选择open in terminal
-
执行包下所有的用例:
pytest/py.test [包名] -
执行单独一个 pytest 模块:
pytest 文件名.py -
运行某个模块里面某个类:
pytest 文件名.py::类名 -
运行某个模块里面某个类里面的方法:
pytest 文件名.py::类名::方法名 -
加-v可以具体展示,如pytest -v 文件名.py::类名::方法名 (-v在前在后都行)
- test_skip.py::TestDemo::test_demo1 PASSED [100%]
运行结果分析
- 常用的:fail/error/pass(error可能是代码写错了)
- 特殊的结果:warning/deselect(后面会讲)
python 执行 pytest
前面已经介绍了几种执行用例的方法,一个是点击代码方法或类的左侧绿色箭头,一个是右键测试用例,一个是终端pytest解释器执行,我们也可以用python解释器执行
Python 代码执行 pytest
-
方法一:使用 main 函数
-
方法二:使用 python -m pytest 调用 pytest(jenkins 持续集成用到),相当于在原来pytest 用例前加了python -m。
- 方便指定python版本,比如有的用例使用python老版本写的
Python 代码执行 pytest - main 函数
if __name__ == '__main__':# 1、运行当前目录下所有符合规则的用例,包括子目录(test_*.py 和 *_test.py)pytest.main()# 2、运行test_mark1.py::test_dkej模块中的某一条用例pytest.main(['test_mark1.py::test_dkej','-vs'])# 3、运行某个 标签pytest.main(['test_mark1.py','-vs','-m','dkej'])运行方式`python test_*.py `
pytest 异常处理
异常处理方法 try …except
try:可能产生异常的代码块
except [ (Error1, Error2, ... ) [as e] ]:处理异常的代码块1
except [ (Error3, Error4, ... ) [as e] ]:处理异常的代码块2
except [Exception]:处理其它异常
异常处理方法 pytest.raise()
- 可以捕获特定的异常
- 获取捕获的异常的细节(异常类型,异常信息)
- 发生异常,后面的代码将不会被执行
def test_raise():with pytest.raises(ValueError, match='must be 0 or None'):raise ValueError("value must be 0 or None")def test_raise1():with pytest.raises(ValueError) as exc_info:raise ValueError("value must be 42")assert exc_info.type is ValueErrorassert exc_info.value.args[0] == "value must be 42"
这样可以选择一个异常
def test_raise():with pytest.raises((ZeroDivisionError,ValueError)):raise ZeroDivisionError("value must be 0 or None")
Pytest 结合数据驱动 YAML
数据驱动
-
什么是数据驱动?
- 数据驱动就是数据的改变从而驱动自动化测试的执行,最终引起测试结果的改变。简单来说,就是参数化的应用。数据量小的测试用例可以使用代码的参数化来实现数据驱动,数据量大的情况下建议大家使用一种结构化的文件(例如 yaml,json 等)来对数据进行存储,然后在测试用例中读取这些数据。
-
应用:
- App、Web、接口自动化测试
- 测试步骤的数据驱动
- 测试数据的数据驱动
- 配置的数据驱动
yaml 文件介绍
-
对象:键值对的集合,用冒号 “:” 表示
-
数组:一组按次序排列的值,前加 “-”
-
纯量:单个的、不可再分的值
- 字符串
- 布尔值
- 整数
- 浮点数
- Null
- 时间
- 日期
# 编程语言
languages:- PHP- Java- Python
book:Python入门: # 书籍名称price: 55.5author: Lilyavailable: Truerepertory: 20date: 2018-02-17Java入门:price: 60author: Lilyavailable: Falserepertory: Nulldate: 2018-05-11
相当于:
languages:['PHP', 'Java', 'Python'] # languages是key值
yaml 文件使用
-
查看 yaml 文件
- pycharm
- txt 记事本
-
读取 yaml 文件
- 安装:
pip install pyyaml - 方法:
yaml.safe_load(f)(yaml->python) - 方法:
yaml.safe_dump(f)(python->yaml)
- 安装:
import yaml
file_path = './my.yaml'
with open(file_path, 'r', encoding='utf-8') as f:data = yaml.safe_load(f)
工程目录结构(看项目文件datadriver_yaml)
- data 目录:存放 yaml 数据文件
- func 目录:存放被测函数文件
- testcase 目录:存放测试用例文件
# 工程目录结构
.
├── data
│ └── data.yaml
├── func
│ ├── __init__.py
│ └── operation.py
└── testcase├── __init__.py└── test_add.py
测试准备
- 被测对象:
operation.py - 测试用例:
test_add.py - 测试数据:
data.yaml
# operation.py 文件内容
def my_add(x, y):result = x + yreturn result
# test_add.py 文件内容
class TestWithYAML:@pytest.mark.parametrize('x,y,expected', [[1, 1, 2]])def test_add(self, x, y, expected):assert my_add(int(x), int(y)) == int(expected)
# data.yaml 文件内容
-- 1- 1- 2
-- 3- 6- 9
-- 100- 200- 300
Pytest 数据驱动结合 yaml 文件
# 读取yaml文件
def get_yaml():"""获取json数据:return: 返回数据的结构:[[1, 1, 2], [3, 6, 9], [100, 200, 300]]"""with open('../datas/data.yaml', 'r') as f:data = yaml.safe_load(f)return data
Pytest 结合数据驱动 Excel
读取 Excel 文件
-
第三方库
xlrdxlwingspandas
-
openpyxl
- 官方文档: openpyxl - A Python library to read/write Excel 2010 xlsx/xlsm files — openpyxl 3.1.2 documentation
openpyxl 库的安装
- 安装:
pip install openpyxl - 导入:
import openpyxl
openpyxl 库的操作
- 读取工作簿
- 读取工作表
- 读取单元格
import openpyxl# 获取工作簿
book = openpyxl.load_workbook('../data/params.xlsx')# 读取工作表
sheet = book.active# 读取单个单元格
cell_a1 = sheet['A1']
cell_a3 = sheet.cell(column=1, row=3) # A3# 读取多个连续单元格
cells = sheet["A1":"C3"]# 获取单元格的值
cell_a1.value
工程目录结构
- data 目录:存放 excel 数据文件
- func 目录:存放被测函数文件
- testcase 目录:存放测试用例文件
# 工程目录结构
.
├── data
│ └── params.excel
├── func
│ ├── __init__.py
│ └── operation.py
└── testcase├── __init__.py└── test_add.py
测试准备
- 被测对象:
operation.py - 测试用例:
test_add.py
# operation.py 文件内容
def my_add(x, y):result = x + yreturn result# test_add.py 文件内容
class TestWithEXCEL:@pytest.mark.parametrize('x,y,expected', get_excel())def test_add(self, x, y, expected):assert my_add(int(x), int(y)) == int(expected)
测试准备
- 测试数据:
params.xlsx

注意:.xlsx文件要在外面创建,不要在编辑器里创建
Pytest 数据驱动结合 Excel 文件
# 读取Excel文件
import openpyxl
import pytestdef get_excel():# 获取工作簿book = openpyxl.load_workbook('../data/params.xlsx')# 获取活动行(非空白的)sheet = book.active# 提取数据,格式:[[1, 2, 3], [3, 6, 9], [100, 200, 300]]values = []for row in sheet:line = []for cell in row:line.append(cell.value)values.append(line)return values
Pytest 结合数据驱动 csv
csv 文件介绍
- csv:逗号分隔值
- 是 Comma-Separated Values 的缩写
- 以纯文本形式存储数字和文本
- 文件由任意数目的记录组成
- 每行记录由多个字段组成
Linux从入门到高级,linux,¥5000
web自动化测试进阶,python,¥3000
app自动化测试进阶,python,¥6000
Docker容器化技术,linux,¥5000
测试平台开发与实战,python,¥8000
csv 文件使用
-
读取数据
- 内置函数:
open() - 内置模块:
csv
- 内置函数:
-
方法:
csv.reader(iterable)- 参数:iterable ,文件或列表对象
- 返回:迭代器,每次迭代会返回一行数据。
# 读取csv文件内容def get_csv():with open('demo.csv', 'r') as file:raw = csv.reader(file)for line in raw:print(line)
工程目录结构
- data 目录:存放 csv 数据文件
- func 目录:存放被测函数文件
- testcase 目录:存放测试用例文件
# 工程目录结构
.
├── data
│ └── params.csv
├── func
│ ├── __init__.py
│ └── operation.py
└── testcase├── __init__.py└── test_add.py
测试准备
- 被测对象:
operation.py - 测试用例:
test_add.py - 测试数据:
params.csv
# operation.py 文件内容
def my_add(x, y):result = x + yreturn result# test_add.py 文件内容
class TestWithCSV:@pytest.mark.parametrize('x,y,expected', [[1, 1, 2]])def test_add(self, x, y, expected):assert my_add(int(x), int(y)) == int(expected)# params.csv 文件内容
1,1,2
3,6,9
100,200,300
Pytest 数据驱动结合 csv 文件
# 读取 data目录下的 params.csv 文件
import csvdef get_csv():"""获取csv数据:return: 返回数据的结构:[[1, 1, 2], [3, 6, 9], [100, 200, 300]]"""with open('../data/params.csv', 'r') as file:raw = csv.reader(file)data = []for line in raw:data.append(line)return data
Pytest 结合数据驱动 json
json 文件介绍
-
json 是 JS 对象
-
全称是 JavaScript Object Notation
-
是一种轻量级的数据交换格式
-
json 结构
- 对象
{"key": value} - 数组
[value1, value2 ...]
- 对象
{"name:": "hogwarts ","detail": {"course": "python","city": "北京"},"remark": [1000, 666, 888]
}
json 文件使用
-
查看 json 文件
- pycharm
- txt 记事本
-
读取 json 文件
- 内置函数 open()
- 内置库 json
- 方法:
json.loads() - 方法:
json.dumps()
# 读取json文件内容
def get_json():with open('demo.json', 'r') as f:data = json.loads(f.read())print(data)
测试准备
- 被测对象:
operation.py - 测试用例:
test_add.py - 测试数据:
params.json
# operation.py 文件内容
def my_add(x, y):result = x + yreturn result# test_add.py 文件内容
class TestWithJSON:@pytest.mark.parametrize('x,y,expected', [[1, 1, 2]])def test_add(self, x, y, expected):assert my_add(int(x), int(y)) == int(expected)# params.json 文件内容
{"case1": [1, 1, 2],"case2": [3, 6, 9],"case3": [100, 200, 300]
}
Pytest 数据驱动结合 json 文件
# 读取json文件
def get_json():"""获取json数据:return: 返回数据的结构:[[1, 1, 2], [3, 6, 9], [100, 200, 300]]"""with open('../data/params.json', 'r') as f:data = json.loads(f.read())return list(data.values())
pytest测试用例生命周期管理
Fixture 用法
Fixture 特点及优势
- 1、命令灵活:对于 setup,teardown,可以不起这两个名字
- 2、数据共享:在 conftest.py 配置⾥写⽅法可以实现数据共享,不需要 import 导⼊。可以跨⽂件共享
- 3、scope 的层次及神奇的 yield 组合相当于各种 setup 和 teardown
- 4、实现参数化
Fixture 在自动化中的应用- 基本用法
-
场景:
测试⽤例执⾏时,有的⽤例需要登陆才能执⾏,有些⽤例不需要登陆。
setup 和 teardown ⽆法满⾜。fixture 可以。默认 scope(范围)function
-
步骤:
- 1.导⼊ pytest
- 2.在登陆的函数上⾯加@pytest.fixture()
- 3.在要使⽤的测试⽅法中传⼊(登陆函数名称),就先登陆
- 4.不传⼊的就不登陆直接执⾏测试⽅法。
# test_fixture.pyimport pytest# 定义登录的fixture
@pytest.fixture()
def login():print("完成登录操作")def test_search():print("搜索")def test_cart(login): #不需要把login放在函数里面,只要传参就可以print("购物车")def test_order(login):print("下单")
Fixture 在自动化中的应用 - 作用域
| 取值 | 范围 | 说明 |
|---|---|---|
| function | 函数级 | 每一个函数或方法都会调用 |
| class | 类级别 | 每个测试类只运行一次 |
| module | 模块级 | 每一个.py 文件调用一次 |
| package | 包级 | 每一个 python 包只调用一次(暂不支持) |
| session | 会话级 | 每次会话只需要运行一次,会话内所有方法及类,模块都共享这个方法 |
注:整个项目就是一个会话
import pytest# 定义登录的fixture
@pytest.fixture(scope="class")
def login():print("完成登录操作")def test_search(login):print("搜索")def test_cart(login):print("购物车")def test_order(login):print("下单")class TestDemo:def test_case1(self,login):print("case1")def test_case2(self,login):print("case2")
Fixture 在自动化中的应用 - yield 关键字
- 场景:
你已经可以将测试⽅法【前要执⾏的或依赖的】解决了,
测试⽅法后销毁清除数据的要如何进⾏呢?
- 解决:
通过在 fixture 函数中加⼊ yield 关键字,yield 是调⽤第⼀次返回结果,
第⼆次执⾏它下⾯的语句返回。
- 步骤:
在@pytest.fixture(scope=module)。
在登陆的⽅法中加 yield,之后加销毁清除的步骤
import pytest# 定义登录的fixture
@pytest.fixture(scope="class")
def login():# setup 操作print("完成登录操作")token = "abcd"username = "hogwarts"yield token, username # 相当于return# teardown 操作print("完成登出操作")def test_search(login):token, username = loginprint(f"token:{token},name:{username}")print("搜索")def test_cart(login):print("购物车")def test_order(login):print("下单")class TestDemo:def test_case1(self,login):print("case1")def test_case2(self,login):print("case2")
Fixture 在自动化中的应用 - 数据共享
- 场景:
你与其他测试⼯程师合作⼀起开发时,公共的模块要在不同⽂件中,要在⼤家都访问到的地⽅。
- 解决:
使⽤ conftest.py 这个⽂件进⾏数据共享,并且他可以放在不同位置起着不同的范围共享作⽤。
-
前提:
- conftest ⽂件名是不能换的
- 放在项⽬下是全局的数据共享的地⽅
-
执⾏:
- 系统执⾏到参数 login 时先从本模块中查找是否有这个名字的变量什么的,
- 之后在 conftest.py 中找是否有。
-
步骤:
- 将登陆模块带@pytest.fixture 写在 conftest.py
Fixture 在自动化中的应用 - 自动应用
场景:
不想原测试⽅法有任何改动,或全部都⾃动实现⾃动应⽤,
没特例,也都不需要返回值时可以选择⾃动应⽤
解决:
使⽤ fixture 中参数 autouse=True 实现
步骤:
在⽅法上⾯加 @pytest.fixture(autouse=True)
比如要实现fixture时session级别的,就要每个用例都添加fixture方法。可以通过自动应用来避免。
问题:那yield返回参数的怎么办?
Fixture 在自动化中的应用 -参数化
场景:
测试离不开数据,为了数据灵活,⼀般数据都是通过参数传的
解决:
fixture 通过固定参数 request 传递
步骤:
在 fixture 中增加@pytest.fixture(params=[1, 2, 3, ‘linda’])
在⽅法参数写 request,方法体里面使用 request.param 接收参数
Fixture 的用法总结
- 模拟 setup,teardown(一个用例可以引用多个 fixture)
- yield 的用法
- 作用域( session,module, 类级别,方法级别 )
- 自动执行 (autouse 参数)
- conftest.py 用法,一般会把 fixture 写在 conftest.py 文件中(这个文件名字是固定的,不能改)
- 实现参数化
# test_fixture_param.py
import pytest@pytest.fixture(params=[["selenium",123], ["appium",123]])
def login(request):print(f"用户名:{request.param}")return request.paramdef test_demo1(login):print(f"demo1 case:数据为{login}")
相关文章:
软件测试/测试开发丨Pytest和Allure报告 学习笔记
点此获取更多相关资料 本文为霍格沃兹测试开发学社学员学习笔记分享 原文链接:https://ceshiren.com/t/topic/26755 Pytest 命名规则 类型规则文件test_开头 或者 _test 结尾类Test 开头方法/函数test_开头注意:测试类中不可以添加__init__构造函数 注…...
十七、命令模式
一、什么是命令模式 命令(Command)模式的定义:将一个请求封装为一个对象,使发出请求的责任和执行请求的责任分割开。这样两者之间通过命令对象进行沟通,这样方便将命令对象进行储存、传递、调用、增加与管理。 命令…...

服务器安装 anaconda 及 conda: command not found [解决方案]
[解决方案] conda: command not found Anaconda3 安装conda: command not found Anaconda3 安装 由于连接的服务器,无法直接在anaconda官网上下载安装文件,所以使用如下方法: wget https://repo.anaconda.com/archive/Anaconda3-2023.03-Li…...
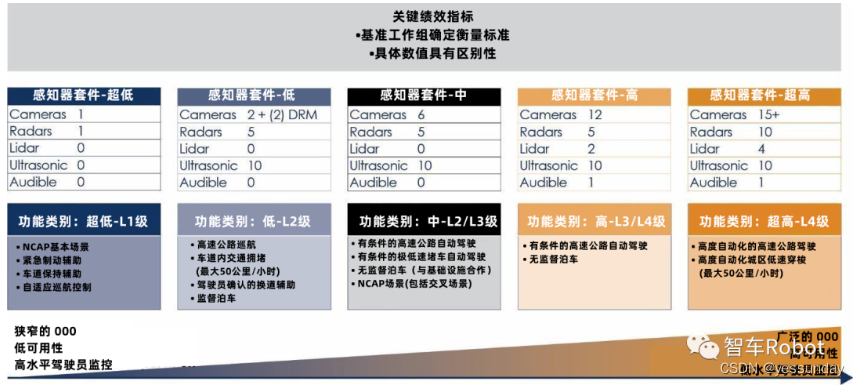
自动驾驶和辅助驾驶系统的概念性架构(二)
摘要: 本篇为第二部分主要介绍底层计算单元、示例工作负载 前言 本文档参考自动驾驶计算联盟(Autonomous Vehicle Computing Consortium)关于自动驾驶和辅助驾驶计算系统的概念系统架构。该架构旨在与SAE L1-L5级别的自动驾驶保持一致。本文主要介绍包括功能模块图…...
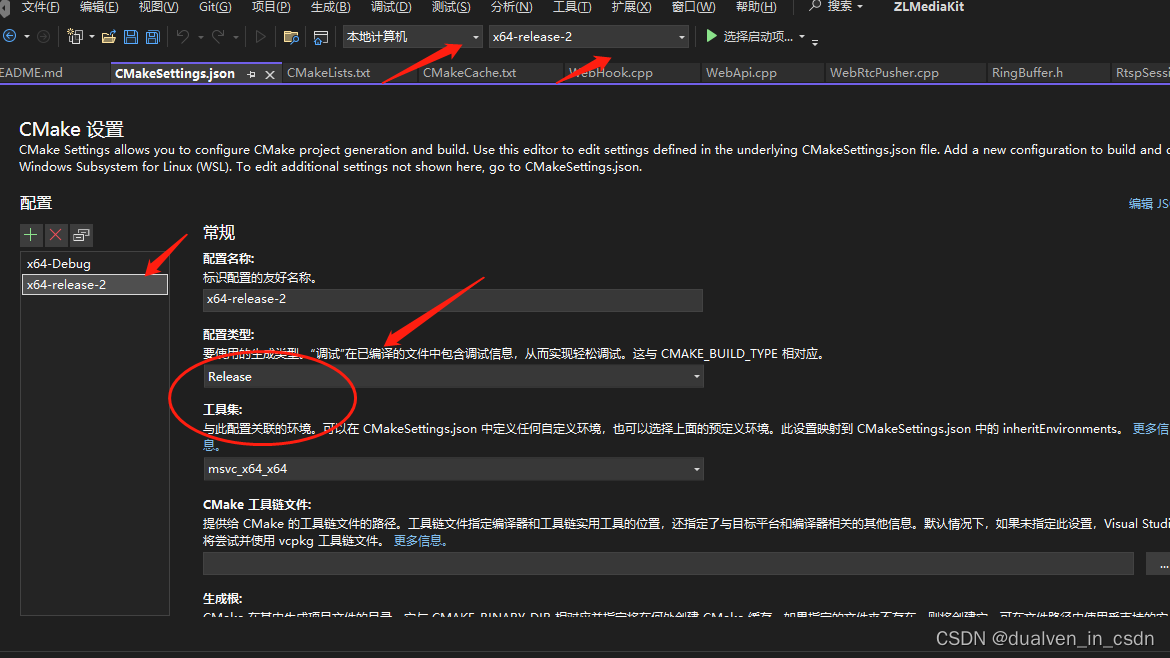
【c++】VC编译出的版本,发布版本如何使用
目录 使用release类型进行发布 应用程序无法正常启动 0xc000007b 版本对应 vcruntime140d 应用版本 参考文章 使用release类型进行发布 应用程序无法正常启动 0xc000007b "应用程序无法正常启动 0xc000007b" 错误通常是一个 Windows 应用程序错误…...

自然语言处理(五):子词嵌入(fastText模型)
子词嵌入 在英语中,“helps”“helped”和“helping”等单词都是同一个词“help”的变形形式。“dog”和“dogs”之间的关系与“cat”和“cats”之间的关系相同,“boy”和“boyfriend”之间的关系与“girl”和“girlfriend”之间的关系相同。在法语和西…...
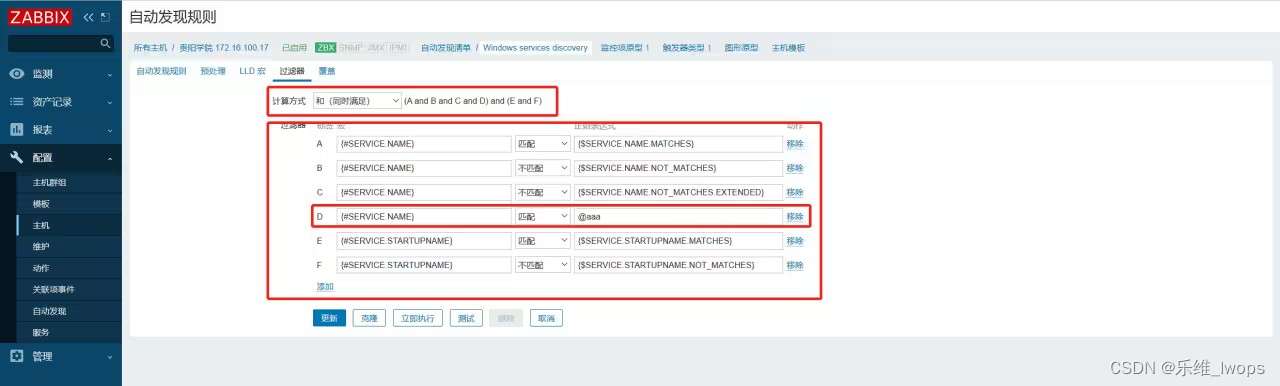
Zabbix“专家坐诊”第202期问答汇总
问题一 Q:请问一下 zabbix 里面怎么能创建出和sh文件有关联的监控项? A: 1.使用 Zabbix Agent 主动模式:如果你在目标主机上安装了 Zabbix Agent,并且想要监控与 sh 文件相关的指标,可以创建一个自定义的…...
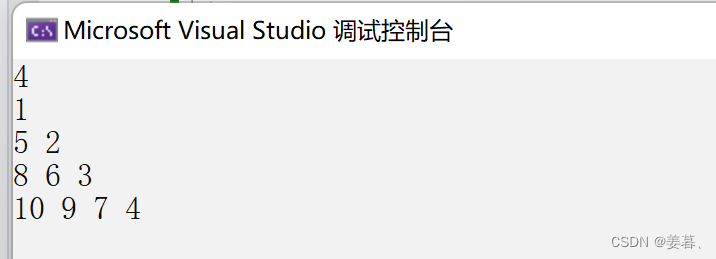
【c语言】输出n行按如下规律排列的数
题述:输出n行按如下规律排列的数 输入: 4(应该指的是n) 输出: 思路: 利用下标的规律求解,考察数组下标的灵活应用,我们可以看出数从1开始是斜着往下放的,那么我们如何利用两层for循环求解这道题ÿ…...

023 - STM32学习笔记 - 扩展外部SDRAM(二) - 扩展外部SDRAM实验
023- STM32学习笔记 - 扩展外部SDRAM(一) - 扩展外部SDRAM实验 本节内容中要配置的引脚很多,如果你用的开发板跟我的不一样,请详细参照STM32规格书中说明对相关GPIO引脚进行配置。 先提前对本届内容的变成步骤进行总结如下&…...

机器学习 | Python实现XGBoost极限梯度提升树模型答疑
机器学习 | MATLAB实现XGBoost极限梯度提升树模型答疑 目录 机器学习 | MATLAB实现XGBoost极限梯度提升树模型答疑问题系列问题回答问题系列 关于XGBoost有几个问题想请教一下。1.XGBoost的API有哪些种调用方法?2.参数如何调? 问题回答 XGBoost的API有2种调用方法,一种是我们…...
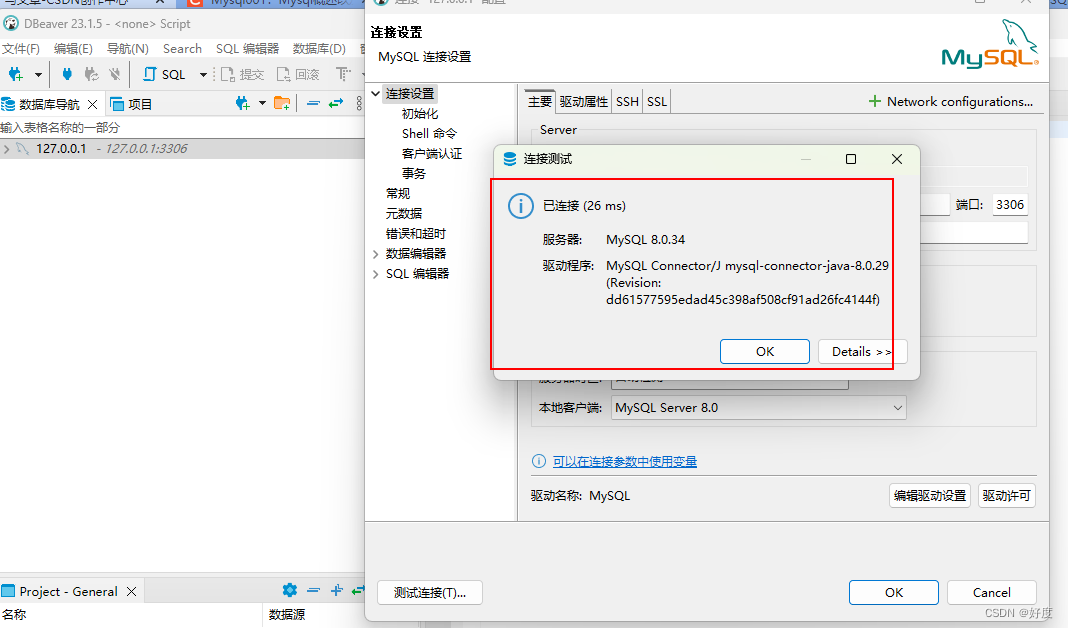
关于使用远程工具连接mysql数据库时,提示:Public Key Retrieval is not allowed
我在使用DBeaver工具连接 数据库时,提示:Public Key Retrieval is not allowed, 我在前一天还是可以连接的,但是今天突然无法连接了, 但是最后捣鼓了一下又可以了。 具体方法:首先先把mysql服务停了&#x…...

leetcode做题笔记117. 填充每个节点的下一个右侧节点指针 II
给定一个二叉树: struct Node {int val;Node *left;Node *right;Node *next; } 填充它的每个 next 指针,让这个指针指向其下一个右侧节点。如果找不到下一个右侧节点,则将 next 指针设置为 NULL 。 初始状态下,所有 next 指针都…...
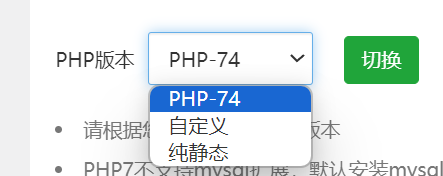
解决博客不能解析PHP直接下载源码问题
背景: 在网站设置反向代理后,网站突然不能正常访问,而是会直接下载访问文件的PHP源码 解决办法: 由于在搞完反向代理之后,PHP版本变成了纯静态,所以网站不能正常解析;只需要把PHP版本恢复正常…...

voc 转coco
import os import random import shutil import sys import json import glob import xml.etree.ElementTree as ET""" 修改下面3个参数 1.val_files_num : 验证集的数量 2.test_files_num :测试集的数量 3.voc_annotations : voc的annotations路径 …...

【C语言每日一题】03. 对齐输出
题目来源:http://noi.openjudge.cn/ch0101/03/ 03 对齐输出 总时间限制: 1000ms 内存限制: 65536kB 问题描述 读入三个整数,按每个整数占8个字符的宽度,右对齐输出它们。 输入 只有一行,包含三个整数,整数之间以一…...

七大排序完整版
目录 一、直接插入排序 (一)单趟直接插入排 1.分析核心代码 2.完整代码 (二)全部直接插入排 1.分析核心代码 2.完整代码 (三)时间复杂度和空间复杂度 二、希尔排序 (一)对…...

C语言的数据类型简介
一、基本类型 (1)六种基本类型 **字符串常量和字符常量的不同 1)‘a’为字符常量,”a”为字符串常量 2)每个字符串的结尾,编译器会自动添加一个结束标志位‘\0’ “a”包含两个字符’a’和’\0’ &#x…...

Fei-Fei Li-Lecture 16:3D Vision 【斯坦福大学李飞飞CV课程第16讲:3D Vision】
目录 P1 2D Detection and Segmentation P2 Video 2D time series P3 Focus on Two Problems P4 Many more topics in 3D Vision P5-10 Multi-View CNN P11 Experiments – Classification & Retrieval P12 3D Shape Representations P13--17 3D Shape Represen…...
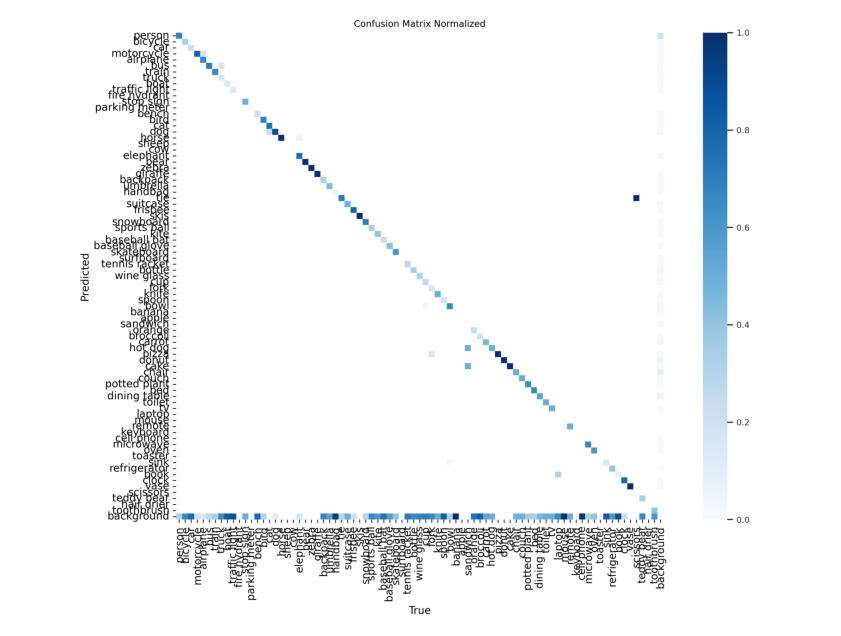
【计算机视觉】YOLO 入门:训练 COCO128 数据集
一、COCO128 数据集 我们以最近大热的YOLOv8为例,回顾一下之前的安装过程: %pip install ultralytics import ultralytics ultralytics.checks()这里选择训练的数据集为:COCO128 COCO128是一个小型教程数据集,由COCOtrain2017中…...

【数分面试答疑】XX场景如何分析问题的思考
问题: 如何分析消费贷客户的用款活跃度,简单列出分析报告的思路框架 解答 这个问题是一个典型的数据分析类的面试问题,主要考察面试者对于消费贷客户的用款活跃度分析的理解和方法,以及对于数据分析报告的撰写和呈现的能力。回…...
PDFMathTranslate:突破语言障碍的学术文档翻译终极解决方案
PDFMathTranslate:突破语言障碍的学术文档翻译终极解决方案 【免费下载链接】PDFMathTranslate PDF scientific paper translation with preserved formats - 基于 AI 完整保留排版的 PDF 文档全文双语翻译,支持 Google/DeepL/Ollama/OpenAI 等服务&…...

手把手教你用AI搞定独立游戏美术:从DeepSeek写方案到Unity导入模型的完整流程
手把手教你用AI搞定独立游戏美术:从DeepSeek写方案到Unity导入模型的完整流程 独立游戏开发最令人头疼的环节之一就是美术资源。传统方式要么需要高昂的外包成本,要么耗费大量时间自学建模。但现在,AI工具链已经能帮我们实现从概念设计到3D模…...
开源翻译终端效果展示:Pixel Language Portal处理专业术语准确率分析
开源翻译终端效果展示:Pixel Language Portal处理专业术语准确率分析 1. 产品概览 Pixel Language Portal(像素语言跨维传送门)是一款基于腾讯Hunyuan-MT-7B核心引擎构建的创新翻译工具。与传统翻译软件不同,它将翻译过程转化为…...

科大奥锐虚拟仿真实验避坑指南:从85分到95分,我的密度测量实验复盘与代码优化
科大奥锐虚拟仿真实验提分实战:从85分到95分的密度测量实验深度优化 第一次接触科大奥锐的密度测量虚拟仿真实验时,我和大多数同学一样,以为按照指导手册操作就能轻松拿高分。直到连续三次实验分数卡在85-87分之间,才意识到这个看…...

SecGPT-14B真实生成效果:漏洞成因解释、CVSS评分建议与PoC生成
SecGPT-14B真实生成效果:漏洞成因解释、CVSS评分建议与PoC生成 1. SecGPT-14B网络安全大模型简介 SecGPT是由云起无垠团队开发的开源大语言模型,专门针对网络安全领域优化。这个14B参数规模的模型采用vLLM框架部署,并通过Chainlit提供用户友…...

解锁开源工具QMK Toolbox:完全掌握机械键盘个性化定制
解锁开源工具QMK Toolbox:完全掌握机械键盘个性化定制 【免费下载链接】qmk_toolbox A Toolbox companion for QMK Firmware 项目地址: https://gitcode.com/gh_mirrors/qm/qmk_toolbox QMK Toolbox是一款开源的设备管理工具,专为QMK固件设计&…...

Dan Koe: 如果你有多重兴趣,请不要浪费接下来的2-3年
本文整理自 Dan Koe 原文。Dan Koe 是 YouTube、X 等平台拥有数百万粉丝的个人成长领域创作者,以"一人公司"理念、深度内容创作和高效 AI 工作流著称。你是否曾因为无法只专注一件事而感到自责? 你学设计,又想学编程;读…...

PyTorch 2.8镜像一键部署教程:支持Slurm集群调度的HPC环境快速接入
PyTorch 2.8镜像一键部署教程:支持Slurm集群调度的HPC环境快速接入 1. 镜像概述与核心优势 PyTorch 2.8深度学习镜像是一个经过深度优化的高性能计算环境,专为现代AI工作负载设计。这个预配置环境最大的特点是开箱即用,免去了繁琐的环境配置…...

Python中CSV文件处理的常见累积错误及修正方案
在使用 Python 的 csv 模块处理学生成绩数据时,一个极易被忽视却影响结果准确性的典型问题是变量作用域与重用逻辑错误。如原始代码所示,grades [] 被定义在 for row in reader: 循环外部,导致每次迭代都将新学生的成绩追加到同一个列表中—…...
实战部署与优化指南)
神州数码无线网络(AC+AP)实战部署与优化指南
1. 神州数码ACAP无线网络部署前的规划准备 第一次接触神州数码无线网络方案时,我被它简洁的架构设计惊艳到了。AC(无线控制器)AP(接入点)的组网模式,特别适合500-2000平米的中型企业办公环境。但在真正动手…...