自然语言处理(五):子词嵌入(fastText模型)
子词嵌入
在英语中,“helps”“helped”和“helping”等单词都是同一个词“help”的变形形式。“dog”和“dogs”之间的关系与“cat”和“cats”之间的关系相同,“boy”和“boyfriend”之间的关系与“girl”和“girlfriend”之间的关系相同。在法语和西班牙语等其他语言中,许多动词有40多种变形形式,而在芬兰语中,名词最多可能有15种变形。在语言学中,形态学研究单词形成和词汇关系。但是,word2vec和GloVe都没有对词的内部结构进行探讨。
文章内容来自李沐大神的《动手学深度学习》并加以我的理解,感兴趣可以去https://zh-v2.d2l.ai/查看完整书籍
文章目录
- 子词嵌入
- fastText模型
- 字节对编码
fastText模型
回想一下词在word2vec中是如何表示的。在跳元模型和连续词袋模型中,同一词的不同变形形式直接由不同的向量表示,不需要共享参数。为了使用形态信息,fastText模型提出了一种子词嵌入方法,其中子词是一个字符 n n n-gram (Bojanowski et al., 2017)。fastText可以被认为是子词级跳元模型,而非学习词级向量表示,其中每个中心词由其子词级向量之和表示。
fastText是一种用于自然语言处理的词向量表示和文本分类的模型。与传统的词向量模型(如word2vec)不同,fastText不仅考虑了单词级别的表示,还考虑了子词(n-grams)级别的表示。这使得fastText能够更好地处理词汇中的复杂性和稀有词。
以下是fastText模型的主要特点和工作原理:
-
子词表示:fastText将每个单词表示为其字符级别n-grams的平均值。例如,对于单词"apple",它可以表示为"ap"、“app”、“ppl”、"ple"等子词的平均向量。这样做的好处是能够捕捉到词汇的内部结构和形态信息,对于处理未登录词(out-of-vocabulary)和稀有词具有优势。
-
分层Softmax:fastText使用了分层Softmax来加速训练过程。传统的词向量模型在训练时需要计算输出层中所有词的概率,而分层Softmax将词汇表划分为多个层级,每个层级包含一部分词汇。这样可以减少计算量,并加快训练速度。
-
文本分类:除了词向量表示,fastText还可以用于文本分类任务。它使用了基于词袋(bag-of-words)模型的方法,将文本表示为词向量的加权和,并通过softmax函数进行分类预测。
fastText是一个开源项目,由Facebook AI Research团队开发。它以其快速训练速度、对稀有词的处理能力和在文本分类任务上的良好表现而受到广泛关注和应用。
让我们来说明如何以单词“where”为例获得fastText中每个中心词的子词。首先,在词的开头和末尾添加特殊字符“<”和“>”,以将前缀和后缀与其他子词区分开来。 然后,从词中提取字符 n n n-gram。 例如,值 n = 3 n=3 n=3时,我们将获得长度为3的所有子词: “<wh”“whe”“her”“ere”“re>”和特殊子词“”。
在fastText中,对于任意词 w w w,用 C w C_w Cw表示其长度在3和6之间的所有子词与其特殊子词的并集。词表是所有词的子词的集合。假设 z g z_g zg是词典中的子词 g g g的向量,则跳元模型中作为中心词的词 w w w的向量 v w v_w vw是其子词向量的和:
v w = ∑ g ∈ C w z g v_w=\sum_{g\in C_w}z_g vw=g∈Cw∑zg
fastText的其余部分与跳元模型相同。与跳元模型相比,fastText的词量更大,模型参数也更多。此外,为了计算一个词的表示,它的所有子词向量都必须求和,这导致了更高的计算复杂度。然而,由于具有相似结构的词之间共享来自子词的参数,罕见词甚至词表外的词在fastText中可能获得更好的向量表示。
字节对编码
在fastText中,所有提取的子词都必须是指定的长度,例如 3 3 3到 6 6 6,因此词表大小不能预定义。为了在固定大小的词表中允许可变长度的子词,我们可以应用一种称为字节对编码(Byte Pair Encoding,BPE)的压缩算法来提取子词 (Sennrich et al., 2015)。
字节对编码执行训练数据集的统计分析,以发现单词内的公共符号,诸如任意长度的连续字符。从长度为1的符号开始,字节对编码迭代地合并最频繁的连续符号对以产生新的更长的符号。请注意,为提高效率,不考虑跨越单词边界的对。最后,我们可以使用像子词这样的符号来切分单词。字节对编码及其变体已经用于诸如GPT-2 (Radford et al., 2019)和RoBERTa (Liu et al., 2019)等自然语言处理预训练模型中的输入表示。在下面,我们将说明字节对编码是如何工作的。
首先,我们将符号词表初始化为所有英文小写字符、特殊的词尾符号’_‘和特殊的未知符号’[UNK]'。
import collectionssymbols = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm','n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z','_', '[UNK]']
因为我们不考虑跨越词边界的符号对,所以我们只需要一个字典raw_token_freqs将词映射到数据集中的频率(出现次数)。注意,特殊符号’_'被附加到每个词的尾部,以便我们可以容易地从输出符号序列(例如,“a_all er_man”)恢复单词序列(例如,“a_all er_man”)。由于我们仅从单个字符和特殊符号的词开始合并处理,所以在每个词(词典token_freqs的键)内的每对连续字符之间插入空格。换句话说,空格是词中符号之间的分隔符。
raw_token_freqs = {'fast_': 4, 'faster_': 3, 'tall_': 5, 'taller_': 4}
token_freqs = {}
for token, freq in raw_token_freqs.items():token_freqs[' '.join(list(token))] = raw_token_freqs[token]
token_freqs

我们定义以下get_max_freq_pair函数,其返回词内最频繁的连续符号对,其中词来自输入词典token_freqs的键。
def get_max_freq_pair(token_freqs):pairs = collections.defaultdict(int)for token, freq in token_freqs.items():symbols = token.split()for i in range(len(symbols) - 1):# “pairs”的键是两个连续符号的元组pairs[symbols[i], symbols[i + 1]] += freqreturn max(pairs, key=pairs.get) # 具有最大值的“pairs”键
作为基于连续符号频率的贪心方法,字节对编码将使用以下merge_symbols函数来合并最频繁的连续符号对以产生新符号。
def merge_symbols(max_freq_pair, token_freqs, symbols):symbols.append(''.join(max_freq_pair))new_token_freqs = dict()for token, freq in token_freqs.items():new_token = token.replace(' '.join(max_freq_pair),''.join(max_freq_pair))new_token_freqs[new_token] = token_freqs[token]return new_token_freqs
解释一下new_token = token.replace(’ ‘.join(max_freq_pair),’'.join(max_freq_pair))
max_freq_pair是一个元组,表示最高频率的一对符号。例如,假设max_freq_pair = ('a', 'b')。
' '.join(max_freq_pair)将最高频率符号对中的两个符号用空格连接起来,生成一个字符串。对于上述示例,结果将是'a b'。
''.join(max_freq_pair)将最高频率符号对中的两个符号直接连接起来,生成一个新的合并后的符号。对于上述示例,结果将是'ab'。
token.replace(' '.join(max_freq_pair), ''.join(max_freq_pair))则使用生成的字符串和新的合并后的符号对标记进行替换操作。它将标记中所有出现的最高频率符号对'a b'替换为合并后的符号'ab',得到新的合并标记。
现在,我们对词典token_freqs的键迭代地执行字节对编码算法。在第一次迭代中,最频繁的连续符号对是’t’和’a’,因此字节对编码将它们合并以产生新符号’ta’。在第二次迭代中,字节对编码继续合并’ta’和’l’以产生另一个新符号’tal’。
num_merges = 10
for i in range(num_merges):max_freq_pair = get_max_freq_pair(token_freqs)token_freqs = merge_symbols(max_freq_pair, token_freqs, symbols)print(f'合并# {i+1}:',max_freq_pair)

在字节对编码的10次迭代之后,我们可以看到列表symbols现在又包含10个从其他符号迭代合并而来的符号。
print(symbols)
['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z', '_', '[UNK]', 'ta', 'tal', 'tall', 'fa', 'fas', 'fast', 'er', 'er_', 'tall_', 'fast_']对于在词典raw_token_freqs的键中指定的同一数据集,作为字节对编码算法的结果,数据集中的每个词现在被子词“fast_”“fast”“er_”“tall_”和“tall”分割。例如,单词“faster_”和“taller_”分别被分割为“fast er_”和“tall er_”。
print(list(token_freqs.keys()))

请注意,字节对编码的结果取决于正在使用的数据集。我们还可以使用从一个数据集学习的子词来切分另一个数据集的单词。作为一种贪心方法,下面的segment_BPE函数尝试将单词从输入参数symbols分成可能最长的子词。
def segment_BPE(tokens, symbols):outputs = []for token in tokens:start, end = 0, len(token)cur_output = []# 具有符号中可能最长子字的词元段while start < len(token) and start < end:if token[start: end] in symbols:cur_output.append(token[start: end])start = endend = len(token)else:end -= 1if start < len(token):cur_output.append('[UNK]')outputs.append(' '.join(cur_output))return outputs
-
函数接受两个参数:
tokens和symbols。tokens是待分割的标记列表。symbols是用于分割标记的符号列表。
-
函数创建一个空列表
outputs用于存储分割后的结果。 -
对于每个标记
token,进行以下操作: -
初始化两个变量
start和end为 0 和标记的长度。 -
创建一个空列表
cur_output用于存储当前标记的分割结果。 -
在一个循环中,尝试从标记的起始位置开始找到最长的子字,使其在符号列表
symbols中存在。 -
如果从
start到end的子字在symbols中存在,则将该子字添加到cur_output中,并更新start为end,将end重置为标记的长度。 -
如果子字不在
symbols中,则将end减小 1,继续尝试找到更短的子字。 -
如果
start小于标记的长度,说明有未被分割的部分,将其视为未知符号[UNK],并将其添加到cur_output中。 -
将
cur_output使用空格连接为一个字符串,并将其添加到outputs列表中。 -
循环结束后,返回
outputs列表,其中包含了对每个标记进行分割后的结果。
我们使用列表symbols中的子词(从前面提到的数据集学习)来表示另一个数据集的tokens。
tokens = ['tallest_', 'fatter_']
print(segment_BPE(tokens, symbols))

相关文章:
自然语言处理(五):子词嵌入(fastText模型)
子词嵌入 在英语中,“helps”“helped”和“helping”等单词都是同一个词“help”的变形形式。“dog”和“dogs”之间的关系与“cat”和“cats”之间的关系相同,“boy”和“boyfriend”之间的关系与“girl”和“girlfriend”之间的关系相同。在法语和西…...
Zabbix“专家坐诊”第202期问答汇总
问题一 Q:请问一下 zabbix 里面怎么能创建出和sh文件有关联的监控项? A: 1.使用 Zabbix Agent 主动模式:如果你在目标主机上安装了 Zabbix Agent,并且想要监控与 sh 文件相关的指标,可以创建一个自定义的…...
【c语言】输出n行按如下规律排列的数
题述:输出n行按如下规律排列的数 输入: 4(应该指的是n) 输出: 思路: 利用下标的规律求解,考察数组下标的灵活应用,我们可以看出数从1开始是斜着往下放的,那么我们如何利用两层for循环求解这道题ÿ…...

023 - STM32学习笔记 - 扩展外部SDRAM(二) - 扩展外部SDRAM实验
023- STM32学习笔记 - 扩展外部SDRAM(一) - 扩展外部SDRAM实验 本节内容中要配置的引脚很多,如果你用的开发板跟我的不一样,请详细参照STM32规格书中说明对相关GPIO引脚进行配置。 先提前对本届内容的变成步骤进行总结如下&…...

机器学习 | Python实现XGBoost极限梯度提升树模型答疑
机器学习 | MATLAB实现XGBoost极限梯度提升树模型答疑 目录 机器学习 | MATLAB实现XGBoost极限梯度提升树模型答疑问题系列问题回答问题系列 关于XGBoost有几个问题想请教一下。1.XGBoost的API有哪些种调用方法?2.参数如何调? 问题回答 XGBoost的API有2种调用方法,一种是我们…...
关于使用远程工具连接mysql数据库时,提示:Public Key Retrieval is not allowed
我在使用DBeaver工具连接 数据库时,提示:Public Key Retrieval is not allowed, 我在前一天还是可以连接的,但是今天突然无法连接了, 但是最后捣鼓了一下又可以了。 具体方法:首先先把mysql服务停了&#x…...

leetcode做题笔记117. 填充每个节点的下一个右侧节点指针 II
给定一个二叉树: struct Node {int val;Node *left;Node *right;Node *next; } 填充它的每个 next 指针,让这个指针指向其下一个右侧节点。如果找不到下一个右侧节点,则将 next 指针设置为 NULL 。 初始状态下,所有 next 指针都…...
解决博客不能解析PHP直接下载源码问题
背景: 在网站设置反向代理后,网站突然不能正常访问,而是会直接下载访问文件的PHP源码 解决办法: 由于在搞完反向代理之后,PHP版本变成了纯静态,所以网站不能正常解析;只需要把PHP版本恢复正常…...

voc 转coco
import os import random import shutil import sys import json import glob import xml.etree.ElementTree as ET""" 修改下面3个参数 1.val_files_num : 验证集的数量 2.test_files_num :测试集的数量 3.voc_annotations : voc的annotations路径 …...

【C语言每日一题】03. 对齐输出
题目来源:http://noi.openjudge.cn/ch0101/03/ 03 对齐输出 总时间限制: 1000ms 内存限制: 65536kB 问题描述 读入三个整数,按每个整数占8个字符的宽度,右对齐输出它们。 输入 只有一行,包含三个整数,整数之间以一…...

七大排序完整版
目录 一、直接插入排序 (一)单趟直接插入排 1.分析核心代码 2.完整代码 (二)全部直接插入排 1.分析核心代码 2.完整代码 (三)时间复杂度和空间复杂度 二、希尔排序 (一)对…...

C语言的数据类型简介
一、基本类型 (1)六种基本类型 **字符串常量和字符常量的不同 1)‘a’为字符常量,”a”为字符串常量 2)每个字符串的结尾,编译器会自动添加一个结束标志位‘\0’ “a”包含两个字符’a’和’\0’ &#x…...

Fei-Fei Li-Lecture 16:3D Vision 【斯坦福大学李飞飞CV课程第16讲:3D Vision】
目录 P1 2D Detection and Segmentation P2 Video 2D time series P3 Focus on Two Problems P4 Many more topics in 3D Vision P5-10 Multi-View CNN P11 Experiments – Classification & Retrieval P12 3D Shape Representations P13--17 3D Shape Represen…...
【计算机视觉】YOLO 入门:训练 COCO128 数据集
一、COCO128 数据集 我们以最近大热的YOLOv8为例,回顾一下之前的安装过程: %pip install ultralytics import ultralytics ultralytics.checks()这里选择训练的数据集为:COCO128 COCO128是一个小型教程数据集,由COCOtrain2017中…...

【数分面试答疑】XX场景如何分析问题的思考
问题: 如何分析消费贷客户的用款活跃度,简单列出分析报告的思路框架 解答 这个问题是一个典型的数据分析类的面试问题,主要考察面试者对于消费贷客户的用款活跃度分析的理解和方法,以及对于数据分析报告的撰写和呈现的能力。回…...
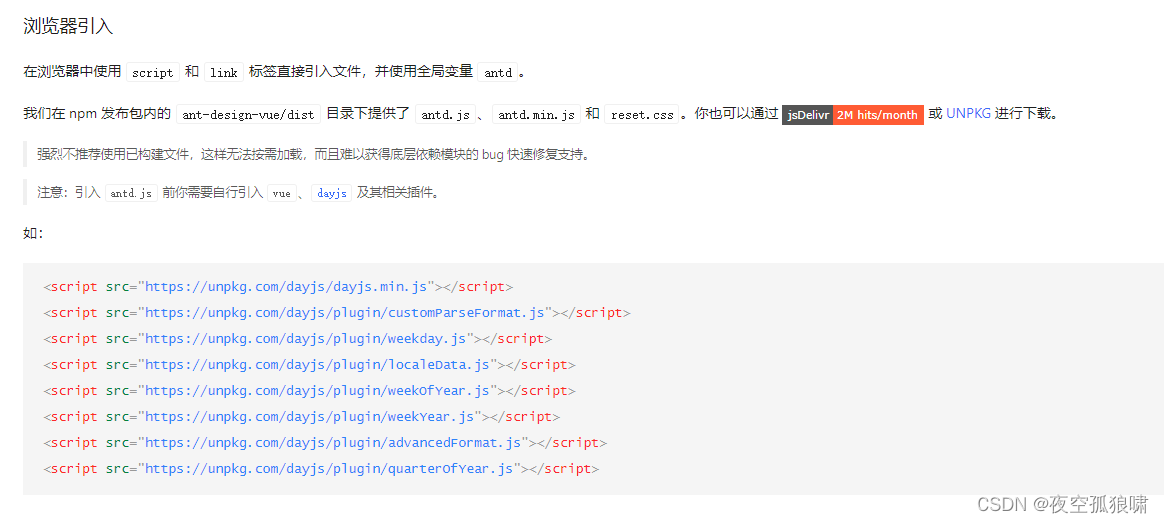
html中如何用vue语法,并使用UI组件库 ,html中引入vue+ant-design-vue或者vue+element-plus
html中如何用vue语法,并使用UI组件库 前言 先说一下本次应用的场景,本次项目中,需要引入github中别人写好的插件,插件比较大,没有方法直接在自己项目中,把别人的项目打包合并生成html(类似于前…...
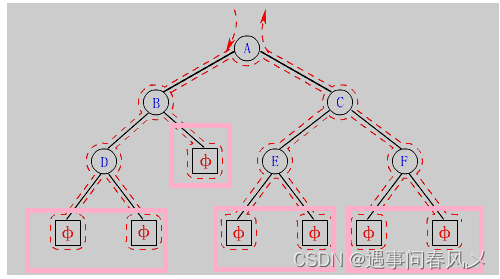
【数据结构】二叉数的存储与基本操作的实现
文章目录 🍀二叉树的存储🌳二叉树的基本操作🐱👤二叉树的创建🐱👓二叉树的遍历🎡前中后序遍历📌前序遍历📌中序遍历📌后续遍历 🛫层序遍历&am…...

使用 Netty 实现群聊功能的步骤和注意事项
文章目录 前言声明功能说明实现步骤WebSocket 服务启动Channel 初始化HTTP 请求处理HTTP 页面内容WebSocket 请求处理 效果展示总结 前言 通过之前的文章介绍,我们可以深刻认识到Netty在网络编程领域的卓越表现和强大实力。这篇文章将介绍如何利用 Netty 框架开发一…...

一篇文章搞定《WebView的优化及封装》
一篇文章搞定《WebView的优化及封装》 前言WebView的过程分析确定优化方案一、预加载,复用缓冲池(初始化优化)优化的解析说明具体的实现 二、预置模版(请求、渲染优化)优化的解析说明具体的实现1、离线包2、预获取数据…...
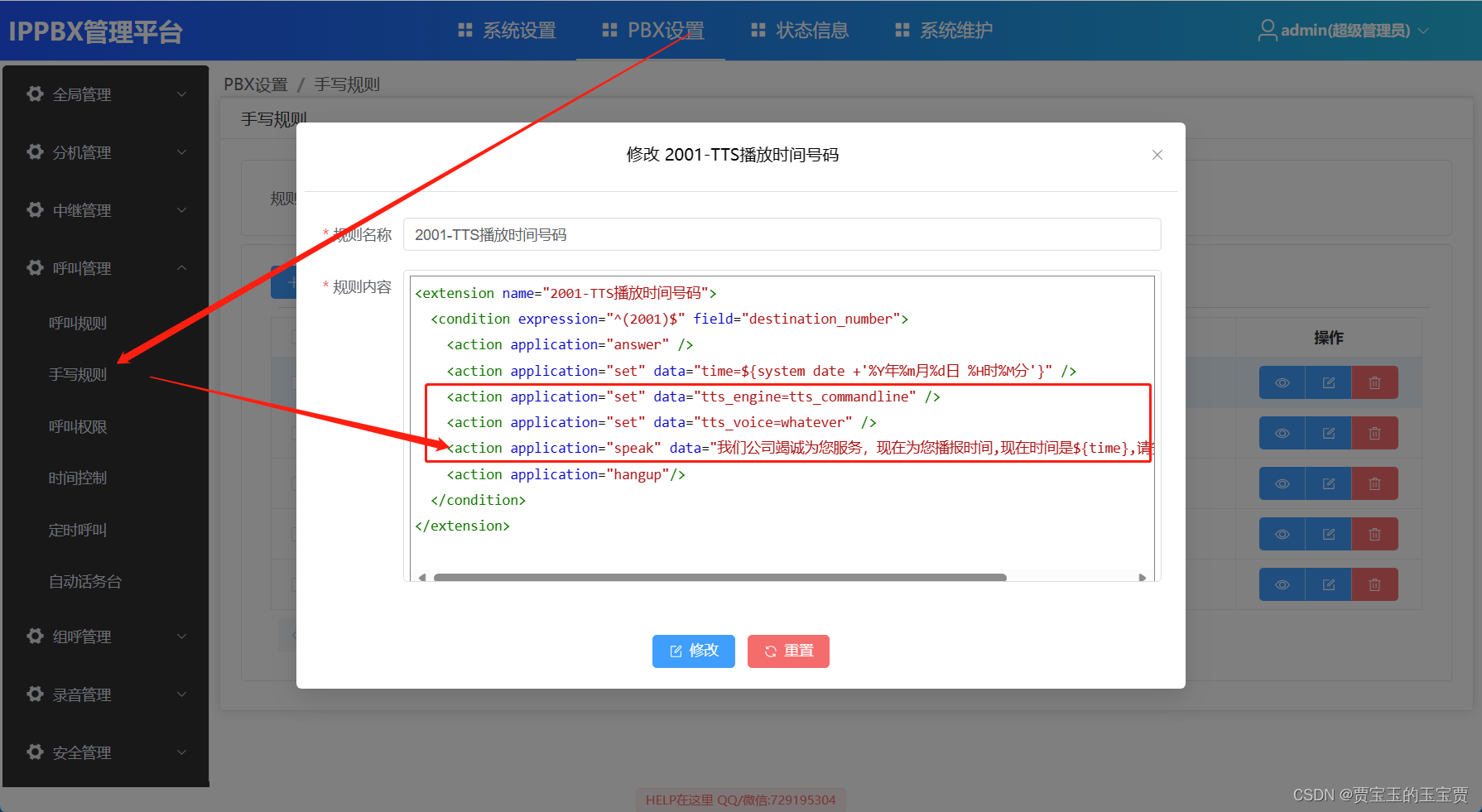
FreeSWITCH 1.10.10 简单图形化界面5 - 使用百度TTS
FreeSWITCH 1.10.10 简单图形化界面5 - 使用百度TTS 0、 界面预览1、注册百度AI开放平台,开通语音识别服务2、获取AppID/API Key/Secret Key3、 安装百度语音合成sdk4、合成代码5、在PBX中使用百度TTS6、音乐文件-TTS7、拨号规则-tts_command 0、 界面预览 http://…...

高效掌握多步提示工程:进阶AI任务处理的系统方法论
高效掌握多步提示工程:进阶AI任务处理的系统方法论 【免费下载链接】LangGPT LangGPT: Empowering everyone to become a prompt expert! 🚀 📌 结构化提示词(Structured Prompt)提出者 📌 元提示词&#x…...

m4s-converter:打破B站缓存限制,永久保存珍贵视频内容
m4s-converter:打破B站缓存限制,永久保存珍贵视频内容 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 在数字内容时代&am…...

避开生产计划大坑:不懂MPS和MRP的区别,你的SAP PP模块白学了
避开生产计划大坑:不懂MPS和MRP的区别,你的SAP PP模块白学了 在制造业数字化转型的浪潮中,SAP PP模块作为生产计划的核心枢纽,常常成为企业运营的"隐形战场"。许多实施顾问和计划专员在MD41和MD02这两个相似的事务码前陷…...

如何用StreamCap实现多平台直播内容的自动捕获与管理
如何用StreamCap实现多平台直播内容的自动捕获与管理 【免费下载链接】StreamCap Multi-Platform Live Stream Automatic Recording Tool | 多平台直播流自动录制客户端 基于FFmpeg 支持监控/定时/转码 项目地址: https://gitcode.com/gh_mirrors/st/StreamCap 在数字…...

PyTorch模型转ONNX避坑指南:从repeat_interleave到Concat类型匹配的实战解决方案
PyTorch模型转ONNX避坑指南:从动态张量到类型匹配的深度解决方案 在模型部署的最后一公里,PyTorch到ONNX的转换常常成为绊倒开发者的隐蔽陷阱。当你在本地训练环境获得完美指标后,准备将模型推向生产时,各种意想不到的导出错误可能…...

解锁开源工具QMK Toolbox:完全掌握机械键盘个性化定制
解锁开源工具QMK Toolbox:完全掌握机械键盘个性化定制 【免费下载链接】qmk_toolbox A Toolbox companion for QMK Firmware 项目地址: https://gitcode.com/gh_mirrors/qm/qmk_toolbox QMK Toolbox是一款开源的设备管理工具,专为QMK固件设计&…...

Polars 2.0大规模清洗崩溃全解析:内存溢出、Schema冲突、LazyFrame中断——3类高频致命报错的5分钟修复方案
第一章:Polars 2.0大规模清洗崩溃全解析:内存溢出、Schema冲突、LazyFrame中断——3类高频致命报错的5分钟修复方案 当处理TB级结构化数据时,Polars 2.0的LazyFrame虽带来性能飞跃,却也因底层执行引擎变更放大了三类典型崩溃风险。…...

Qwen2.5-7B微调保姆级教程:单卡十分钟快速上手,小白也能搞定
Qwen2.5-7B微调保姆级教程:单卡十分钟快速上手,小白也能搞定 1. 前言:为什么选择Qwen2.5-7B进行微调 大模型微调听起来很高深?其实没那么复杂。今天我要带大家用最简单的方式,在单张显卡上10分钟内完成Qwen2.5-7B模型…...

Phi-3-mini-4k-instruct-gguf步骤详解:supervisor服务管理与错误日志定位方法
Phi-3-mini-4k-instruct-gguf步骤详解:supervisor服务管理与错误日志定位方法 1. 模型概述 Phi-3-mini-4k-instruct-gguf是微软Phi-3系列中的轻量级文本生成模型GGUF版本,特别适合问答、文本改写、摘要整理和简短创作等场景。这个开箱即用的解决方案已…...

PyTorch核心模块实战指南:从nn.Sequential到nn.MaxPool2d的深度解析
1. 快速上手nn.Sequential:像搭积木一样构建神经网络 第一次接触PyTorch时,我被各种复杂的网络结构吓到了——直到发现nn.Sequential这个"乐高积木盒"。这个容器让我能用拼积木的方式组合网络层,比如下面这个图像分类器的经典结构&…...