CS144(2023 Spring)Lab 1: stitching substrings into a byte stream
文章目录
- 前言
- 其他笔记
- 相关链接
- 1. Getting started
- 2. Putting substrings in sequence
- 2.1 需求分析
- 2.2 注意事项
- 2.3 代码实现
- 3. 测试与优化
前言
这一个Lab主要是实现一个TCP receiver的字符串接收重组部分。
其他笔记
Lab 0: networking warmup
Lab 1: stitching substrings into a byte stream
相关链接
课程主页
lab 1
1. Getting started
CS144这个Lab本来是自上而下从头到尾代码复用的,这导致我开局顺手就把远程库给干掉了,结果没想到到Lab居然叫我merge,那就重新弄一下吧:
git remote add base git@github.com:CS144/minnow.git
git fetch base
打开VS的分支管理器,可以看到这个远程库里面应该是check1 - 6挨个发布的,看提交记录这个应该是当时上课的时候才一步步弄的仓库,理论上来讲直接合并check6的分支就可以了
右键合并到main,接受冲突,然后提交上传,就可以继续撸码了
2. Putting substrings in sequence
2.1 需求分析

Lab1和2做的事情是写一个TCP接收器,大概工作就如同Lab0的末尾写的那样,写一个类去处理字节流,不过这个数据将不用内存传输上,而是通过网络传输。
由于网络传输的不确定性以及成本问题,在传输数据时我们都是将串切成一段一段的,比如这里提到的每个 s h o r t s e g m e n t s short\ segments short segments不超过1460个 b y t e byte byte,又是考虑到网络传输的不确定性以及TCP的性质,这些字段通常会出现乱序、丢失的情况,而我们需要保证能够重排回最初的字符串。
具体到本Lab,我们要实现一个叫 R e a s s e m b l e r Reassembler Reassembler的东西,这是用来在接收端接受上面说的那一堆字段的,而每一个 B y t e Byte Byte(而非 s e g m e n t segment segment)都有一个对应的 i n d e x index index。文档约束了这个类的两个必要接口,insert将一个data写入output,写入的位置自first_index起,它还用了一个bool变量去标识当前段是否为最后一个段;而bytes_pending则仅仅返回一下存在 R e a s s e m b l e r Reassembler Reassembler中的字节,但是哪些字节存在这里面呢?我们知道单纯网络传输不保证顺序,有可能提前接收到了后面的字段,就只好暂存在 R e a s s e m b l e r Reassembler Reassembler,等它前面的字段写完了再存进去。
然后进一步展示了这个类应当做的工作的一些细节。
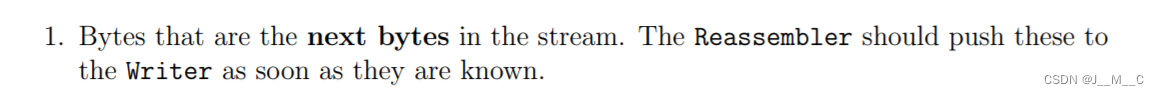
首先,我们应当知道流的下一个待接收的字节(的 i n d e x index index),正如上面说的那样,类内部还有一大堆字段嗷嗷待哺等着进流;

然后,我们需要处理提前到达的暂时没被推进流的串;

而对于哪些超出流接收能力的字节,应当直接扔掉;

然后这个图演示了总共存在三类byte:未进流暂存的、已进流缓存的、已被read弹出的,第三个我们这个Lab应该不用考虑。绿色内存以及类内暂存的一整块空间共同组成了capacity,可知我们的红色内存的最大值只能为capacity - buffered,超过这个的字节就得丢掉了。在实现上,这个值就是上一个Lab实现的available_capacity。
2.2 注意事项

然后是一些FAQ,我们可以提炼出这些信息:
- 流的 i n d e x index index自0始;
- 我们会同Lab0一样有个跑分环境;
- 每个字段都是来自字符串的准确切片,不用做异常处理;
- 鼓励用标准库、数据结构;
- 尽可能早地将字节推进流,免得一直存着;
insert接收到的data字符串是有可能与其他字符串重叠的;- 可以往类里面加私有成员(这不是废话吗);
- 对于每一个字节,类内部应当只存储它的一份副本,不要存重叠的字符串;
- 运行
./scripts/lines-of-code以计算实现代码行数,这个值一般在50-60。
2.3 代码实现
下面给出我的代码实现,里面有很多注释,就不挨着说了,不过注意我这里用到了std::ranges和std::views,因此你的编译器要在gcc13.1及以上。稍微需要探讨一下的是用什么数据结构来当做 b u f f e r buffer buffer,这个数据结构需要满足什么样的需求呢?首先它会有频繁的任意处插入,然后它需要去频繁遍历比较大小查找,给出几个常见的数据结构的复杂度:
| 插入 | 头删 | 删除k个 | 查找 | |
|---|---|---|---|---|
| list | O ( 1 ) O(1) O(1) | O ( 1 ) O(1) O(1) | O ( k ) O(k) O(k) | O ( n ) O(n) O(n) |
| vector | O ( n ) O(n) O(n) | O ( n ) O(n) O(n) | O ( n ) O(n) O(n) | O ( log n ) O(\log n) O(logn) |
| deque | O ( n ) O(n) O(n) | O ( 1 ) O(1) O(1) | O ( n ) O(n) O(n) | O ( log n ) O(\log n) O(logn) |
| map | O ( log n ) O(\log n) O(logn) | O ( log n ) O(\log n) O(logn) | O ( log n + k ) O(\log n + k) O(logn+k) | O ( n ) O(n) O(n) |
可以看到,综合考虑下list基本是最优秀的容器了。其中虽然map红黑树自带的查找是 O ( log n ) O(\log n) O(logn),但是我们的查找是要查找两个端点,如果将左右区间的pair作为key的话就不能用它内置的二分查找算法——它无法传递自定义比较谓词,而使用<algorithm>中的二分算法的话又因为它的迭代器不满足随即迭代器的条件,意味着只能 O ( n ) O(n) O(n)查找。综合来看,我们维护一个有序链表是最优的。
此外在向 b u f f e r buffer buffer暂存的过程中,可能涉及到区间合并的问题,可以参考LeetCode 57. 插入区间
,给出这道题我的实现,本Lab直接套用即可:
// https://leetcode.cn/u/zi-bu-yu-mf/
class Solution {
public:vector<vector<int>> insert(vector<vector<int>>& intervals, vector<int>& newInterval) {auto beg = intervals.begin(), end = intervals.end();int& a = newInterval[0], & b = newInterval[1];auto l = lower_bound(beg, end, vector{ a, a });auto r = upper_bound( l, end, vector{ b, b});if (l != end) a = min(a, l[ 0][0]);if (r != beg) b = max(b, r[-1][1]);intervals.insert(intervals.erase(l, r), newInterval);return intervals;}
};
/*****************************************************************//*** \file reassembler.hh* \brief 实现一个 Reassembler 类, 用于将乱序的字符串重新组装成有序的* 字符串,并推入字节流.* * \author JMC* \date August 2023*********************************************************************/
#pragma once#include "byte_stream.hh"#include <string>
#include <list>
#include <tuple>class Reassembler
{bool had_last_ {}; // 是否已经插入了最后一个字符串uint64_t next_index_ {}; // 下一个要写入的字节的索引uint64_t buffer_size_ {}; // buffer_中的字节数std::list<std::tuple<uint64_t, uint64_t, std::string>> buffer_ {};/*** \breif 将data推入output流.*/void push_to_output(std::string data, Writer& output);/*** \brief 将data推入buffer暂存区.* \param first_index data的第一个字节的索引* \param last_index data的最后一个字节的索引* \param data 待推入的字符串, 下标为[first_index, last_index]闭区间*/void buffer_push( uint64_t first_index, uint64_t last_index, std::string data );/*** 尝试将buffer中的串推入output流.*/void buffer_pop(Writer& output);public:/** Insert a new substring to be reassembled into a ByteStream.* `first_index`: the index of the first byte of the substring* `data`: the substring itself* `is_last_substring`: this substring represents the end of the stream* `output`: a mutable reference to the Writer** The Reassembler's job is to reassemble the indexed substrings (possibly out-of-order* and possibly overlapping) back into the original ByteStream. As soon as the Reassembler* learns the next byte in the stream, it should write it to the output.** If the Reassembler learns about bytes that fit within the stream's available capacity* but can't yet be written (because earlier bytes remain unknown), it should store them* internally until the gaps are filled in.** The Reassembler should discard any bytes that lie beyond the stream's available capacity* (i.e., bytes that couldn't be written even if earlier gaps get filled in).** The Reassembler should close the stream after writing the last byte.*/void insert( uint64_t first_index, std::string data, bool is_last_substring, Writer& output );// How many bytes are stored in the Reassembler itself?uint64_t bytes_pending() const;
};
/*****************************************************************//*** \file reassembler.cc* \brief 实现一个 Reassembler 类, 用于将乱序的字符串重新组装成有序的* 字符串,并推入字节流.* \author JMC* \date August 2023*********************************************************************/
#include "reassembler.hh"#include <ranges>
#include <algorithm>using namespace std;
void Reassembler::push_to_output( std::string data, Writer& output ) {next_index_ += data.size();output.push( move( data ) );
}void Reassembler::buffer_push( uint64_t first_index, uint64_t last_index, std::string data )
{// 合并区间auto l = first_index, r = last_index;auto beg = buffer_.begin(), end = buffer_.end();auto lef = lower_bound( beg, end, l, []( auto& a, auto& b ) { return get<1>( a ) < b; } );auto rig = upper_bound( lef, end, r, []( auto& b, auto& a ) { return get<0>( a ) > b; } );if (lef != end) l = min( l, get<0>( *lef ) );if (rig != beg) r = max( r, get<1>( *prev( rig ) ) );// 当data已在buffer_中时,直接返回if ( lef != end && get<0>( *lef ) == l && get<1>( *lef ) == r ) {return;}buffer_size_ += 1 + r - l;if ( data.size() == r - l + 1 && lef == rig ) { // 当buffer_中没有data重叠的部分buffer_.emplace( rig, l, r, move( data ) );return;}string s( 1 + r - l, 0 );for ( auto&& it : views::iota( lef, rig ) ) {auto& [a, b, c] = *it;buffer_size_ -= c.size();ranges::copy(c, s.begin() + a - l);}ranges::copy(data, s.begin() + first_index - l);buffer_.emplace( buffer_.erase( lef, rig ), l, r, move( s ) );
}void Reassembler::buffer_pop( Writer& output ) {while ( !buffer_.empty() && get<0>( buffer_.front() ) == next_index_ ) {auto& [a, b, c] = buffer_.front();buffer_size_ -= c.size();push_to_output( move( c ), output ); buffer_.pop_front();}if ( had_last_ && buffer_.empty() ) {output.close();}
}void Reassembler::insert( uint64_t first_index, string data, bool is_last_substring, Writer& output )
{if ( data.empty() ) {if ( is_last_substring ) {output.close();}return;}auto end_index = first_index + data.size(); // data: [first_index, end_index)auto last_index = next_index_ + output.available_capacity(); // 可用范围: [next_index_, last_index)if ( end_index < next_index_ || first_index >= last_index ) {return; // 不在可用范围内, 直接返回}// 调整data的范围if ( last_index < end_index ) {end_index = last_index;data.resize( end_index - first_index );is_last_substring = false;}if ( first_index < next_index_ ) {data = data.substr( next_index_ - first_index );first_index = next_index_;}// 若data可以直接写入output, 则直接写入if ( first_index == next_index_ && ( buffer_.empty() || end_index < get<1>( buffer_.front() ) + 2 ) ) {if ( buffer_.size() ) { // 若重叠, 则调整data的范围data.resize( min( end_index, get<0>( buffer_.front() ) ) - first_index );}push_to_output( move( data ), output );} else { // 否则, 将data插入buffer_buffer_push( first_index, end_index - 1, data );}had_last_ |= is_last_substring;// 尝试将buffer_中的数据写入outputbuffer_pop(output);
}uint64_t Reassembler::bytes_pending() const
{return buffer_size_;
}
3. 测试与优化
写这个Lab我跑测试遇到了挺多Bug的,心态比较麻,看一下我的git记录,大体代码从五点到六点半就写完了,然后又调了三四个小时的Bug。。。:
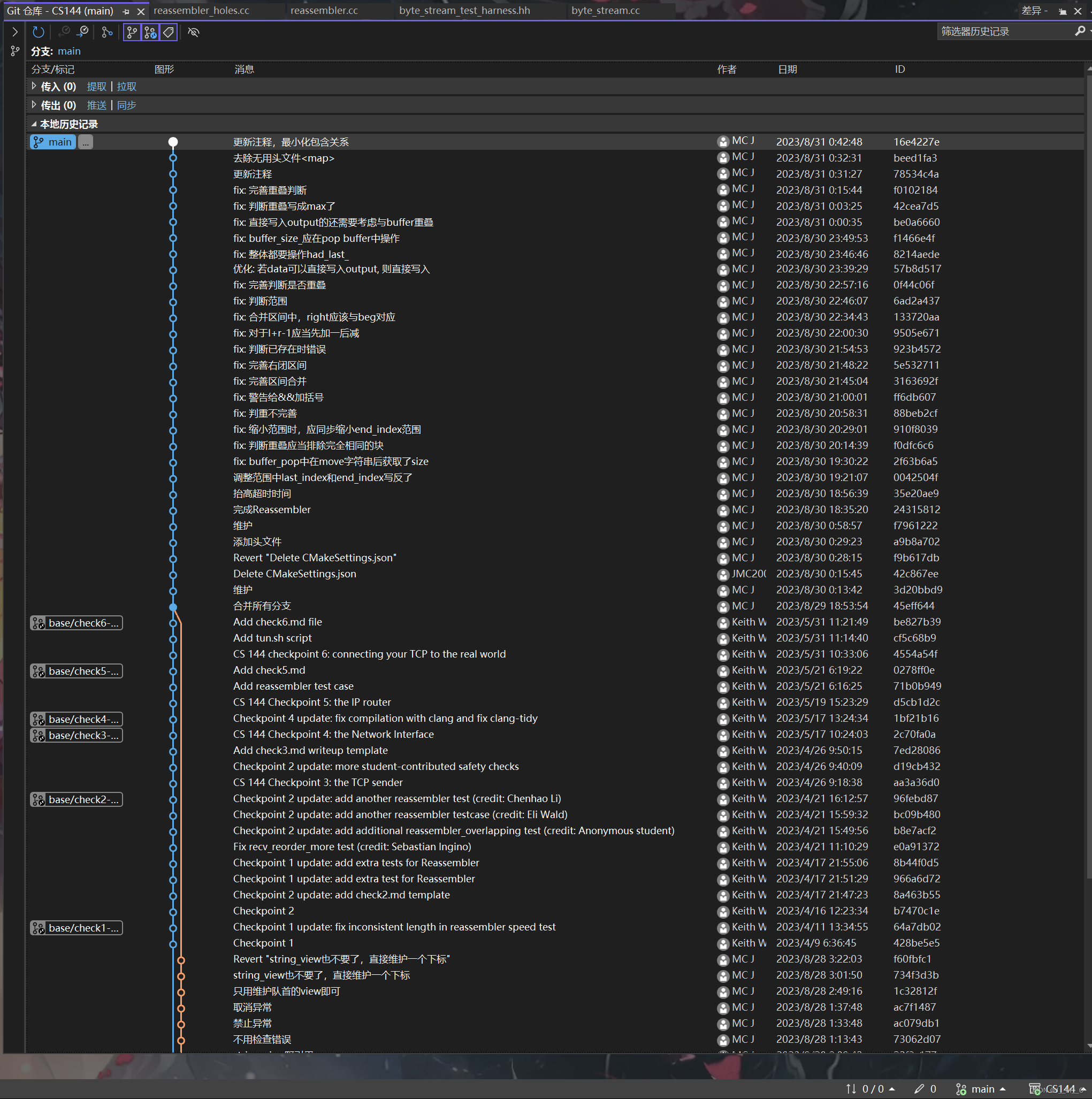
这个Lab最主要的优化点还是要记得使用std::move转发字符串,然后这是我不管字符串能不能直接进流,都先进buffer后进流的速度

这是我对这种情况的特殊处理后的速度,可以看到来到了9.5Gbit/s+8Gbit/s这个速度,按理说我的入buffer操作对于这种情况仅仅是多跑了一遍链表而已,没想到速度也差不少:
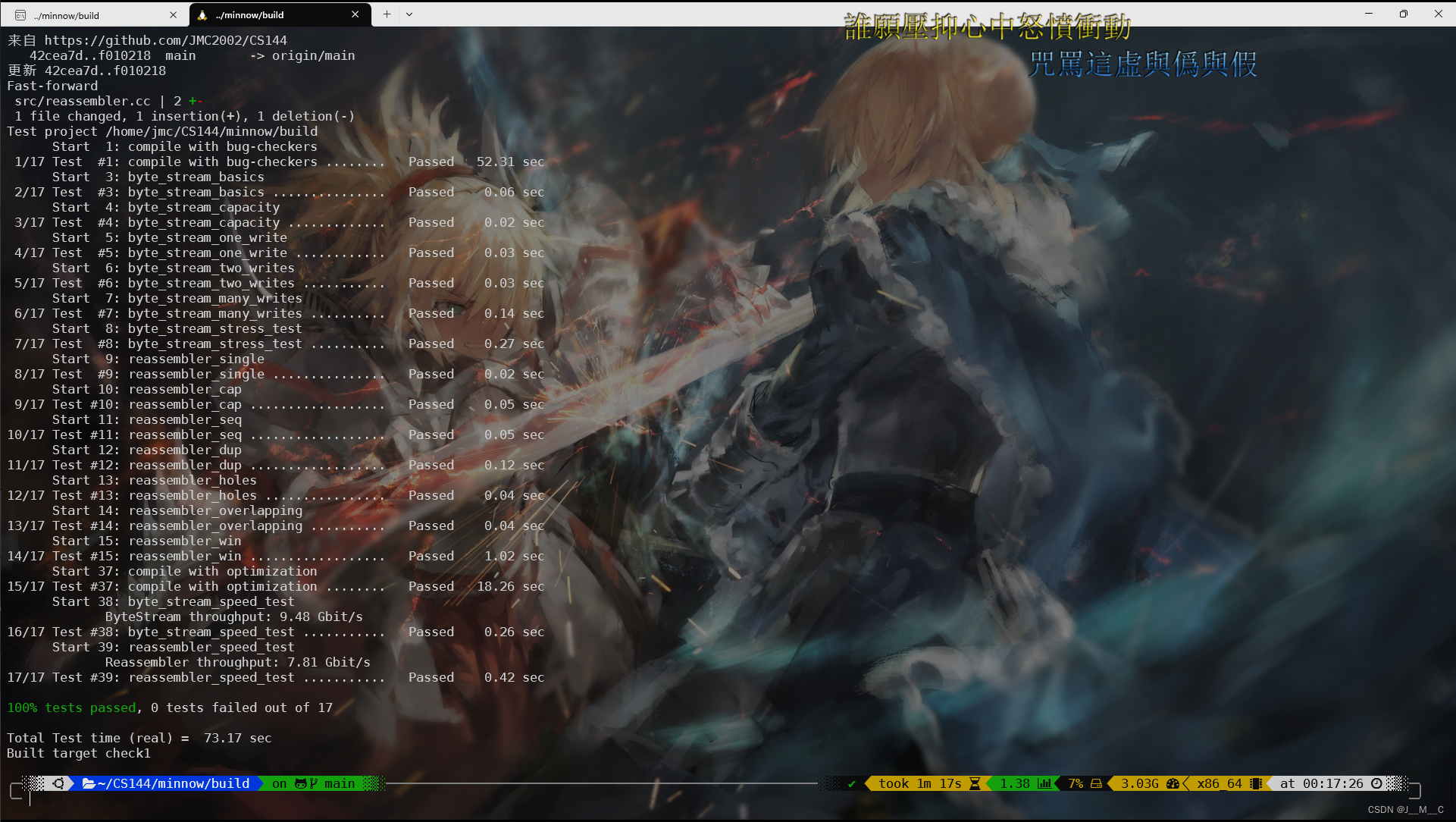
最后看看代码行数,运行./scripts/lines-of-code,如果报错则需要安装一个工具sudo apt-get install sloccount:

它说基础代码是22行,我们就写了77行。我看了一下这个统计行数其实就是去除了注释和空行,他说50-60行是正常的,我这里写得比较详细,想压行也不是压不了,也差不多。

相关文章:
CS144(2023 Spring)Lab 1: stitching substrings into a byte stream
文章目录 前言其他笔记相关链接 1. Getting started2. Putting substrings in sequence2.1 需求分析2.2 注意事项2.3 代码实现 3. 测试与优化 前言 这一个Lab主要是实现一个TCP receiver的字符串接收重组部分。 其他笔记 Lab 0: networking warmup Lab 1: stitching substri…...

【PHP】常用的PHP内置函数
1、PHP内置函数非常丰富,用于执行各种任务。以下是一些常用的PHP内置函数: 字符串操作函数: strlen(): 返回字符串的长度。 strpos(): 查找字符串中的某个子串第一次出现的位置。 substr(): 返回字符串的子串。 str_replace(): 替换字符串中的…...
css自学框架之消息弹框
首先我们还是看看消息弹框效果: 主要实现代码分为三部分 一、CSS部分,这部分主要是定义样式,也就是我们看到的外表,主要代码: /* - 弹窗 */notice{top: 0;left: 0;right: 0;z-index: 10;padding: 1em;position: fix…...
42、Flink 的table api与sql之Hive Catalog
Flink 系列文章 1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接 13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…...

PAT 1145 Hashing - Average Search Time
个人学习记录,代码难免不尽人意。 The task of this problem is simple: insert a sequence of distinct positive integers into a hash table first. Then try to find another sequence of integer keys from the table and output the average search time (the…...
C++调用Python Win10 Miniconda虚拟环境配置
目录 前言1. Win10 安装 Miniconda2. 创建虚拟环境3. 配置C调用python环境4. C调用Python带参函数5.遇到的问题6. 总结 前言 本文记录了Win10 系统下Qt 应用程序调用Python时配置Miniconda虚拟环境的过程及遇到的问题,通过配置Python虚拟环境,简化了Qt应…...

从0到1学会Git(第一部分):Git的下载和初始化配置
1.Git是什么: 首先我们看一下百度百科的介绍:Git(读音为/gɪt/)是一个开源的分布式版本控制系统,可以有效、高速地处理从很小到非常大的项目版本管理。 也是Linus Torvalds为了帮助管理Linux内核开发而开发的一个开放源码的版本控制软件。 …...

【记录】手机QQ和电脑QQ里的emoji种类有什么差异?
版本 手机 QQ:V 8.9.76.12115 电脑 QQ:QQ9.7.15(29157) 偶然发现,有一种emoji手机上怎么找都找不到,一开始以为自己失忆了,后来发现这种emoji只在电脑上有。 接下来简单说一下找emoji差异的方式…...
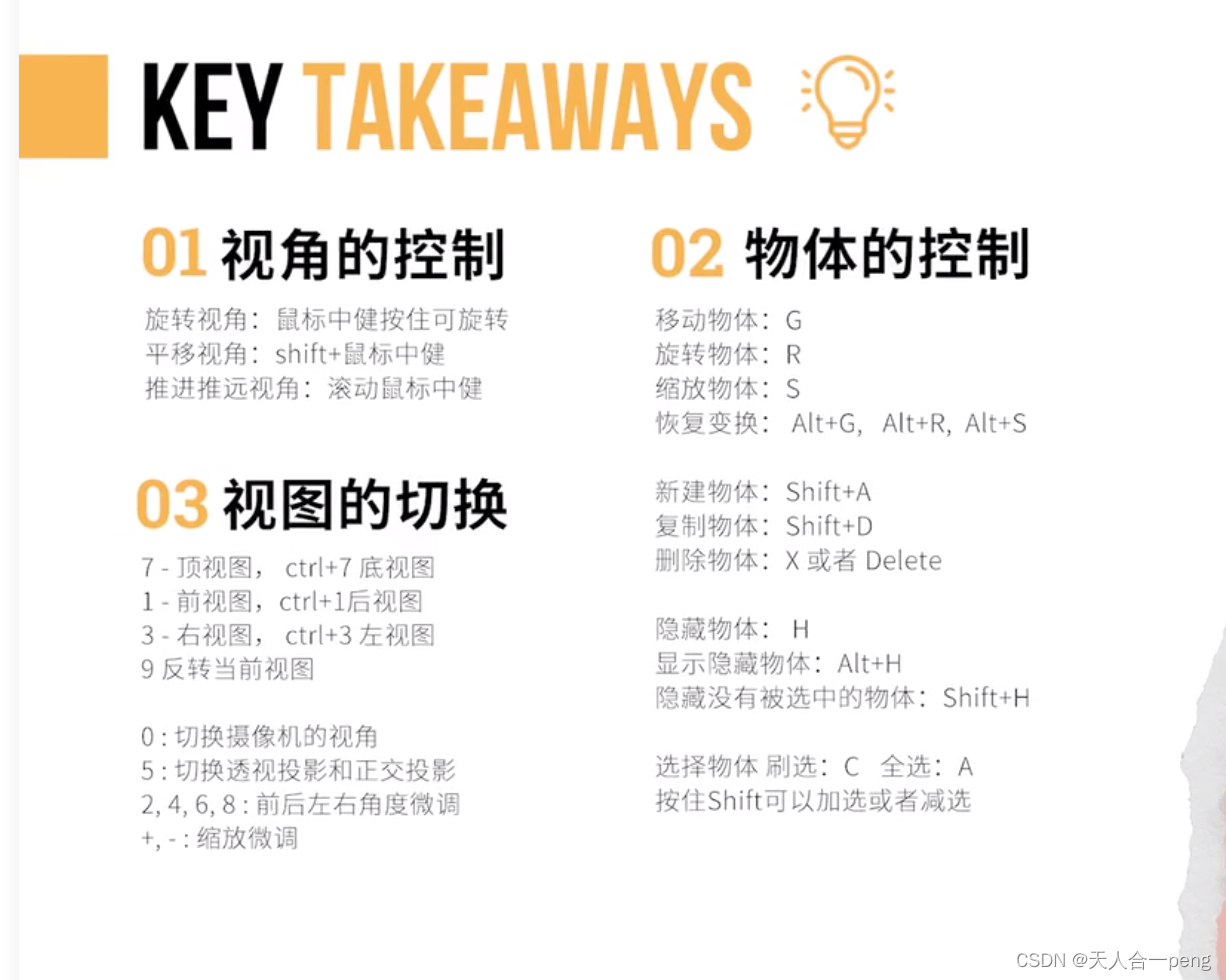
blender界面认识01
学习视频 【基础篇】1.2 让手听话_哔哩哔哩_bilibili 目录 控制视角 控制物体 选择对象1 小结 控制视角 长按鼠标中键-----视角旋转 shift鼠标中键-----视角平移 滚动鼠标中键-----视角缩放 也可以通过界面的快捷工具实现 这个视角旋转有一点像catia中罗盘,…...

TCP数据报结构分析(面试重点)
在传输层中有UDP和TCP两个重要的协议,下面将针对TCP数据报的结构进行分析 关于UDP数据报的结构分析推荐看UDP数据报结构分析(面试重点) TCP结构图示 TCP报头结构的分析 一.16位源端口号 源端口表示发送数据时,发送方的端口号&am…...

合并两个有序的单链表,合并之后的链表依然有序
定义节点 class ListNode {var next: ListNode _var x: Int _def this(x: Int) {thisthis.x x}override def toString: String s"x>$x" } 定义方法 class LinkedList {var head new ListNode(0)def getHead(): ListNode this.headdef add(listNode: Li…...
eureka迁移到nacos--双服务中心注册
服务注册中心的迁移有多种方式,官网使用nacos sync,还有民间开发的双注册中心组件eureka-nacos-proxy,但是我用了不太顺利,所以用的是阿里巴巴的双注册中心组件edas-sc-migration-starter spring boot:2.5.3 引入依赖 …...

线程池使用不规范导致线程数大以及@Async的规范使用
文章详细内容来自:线程数突增!领导:谁再这么写就滚蛋! 下面是看完后文章的,一个总结 线程池的使用不规范,导致程序中线程数不下降,线程数量大。 临时变量的接口,通过下面简单的线…...

启莱OA treelist.aspx SQL注入
子曰:“为政以德,譬如北辰,居其所,而众星共之。” 漏洞复现 访问漏洞url: 使用SQLmap对参数 user 进行注入 漏洞证明: 文笔生疏,措辞浅薄,望各位大佬不吝赐教,万分感…...
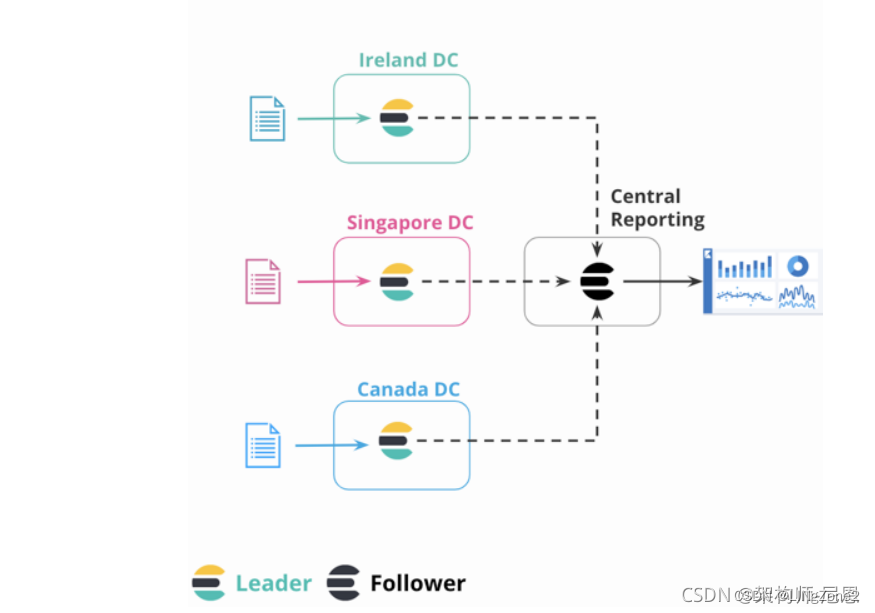
ES是一个分布式全文检索框架,隐藏了复杂的处理机制,核心数据分片机制、集群发现、分片负载均衡请求路由
ES是一个分布式框架,隐藏了复杂的处理机制,核心数据分片机制、集群发现、分片负载均衡请求路由。 ES的高可用架构,总体如下图: 说明:本文会以pdf格式持续更新,更多最新尼恩3高pdf笔记,请从下面…...

xml和json互转工具类
分享一个json与xml互转的工具类,非常好用 一、maven依赖 <!-->json 和 xm 互转</!--><dependency><groupId>org.dom4j</groupId><artifactId>dom4j</artifactId><version>2.1.3</version></dependency&g…...

Windows系统下MMDeploy预编译包的使用
Windows系统下MMDeploy预编译包的使用 MMDeploy步入v1版本后安装/使用难度大幅下降,这里以部署MMDetection项目的Faster R-CNN模型为例,将PyTorch模型转换为ONNX进而转换为Engine模型,部署到TensorRT后端,实现高效推理,…...
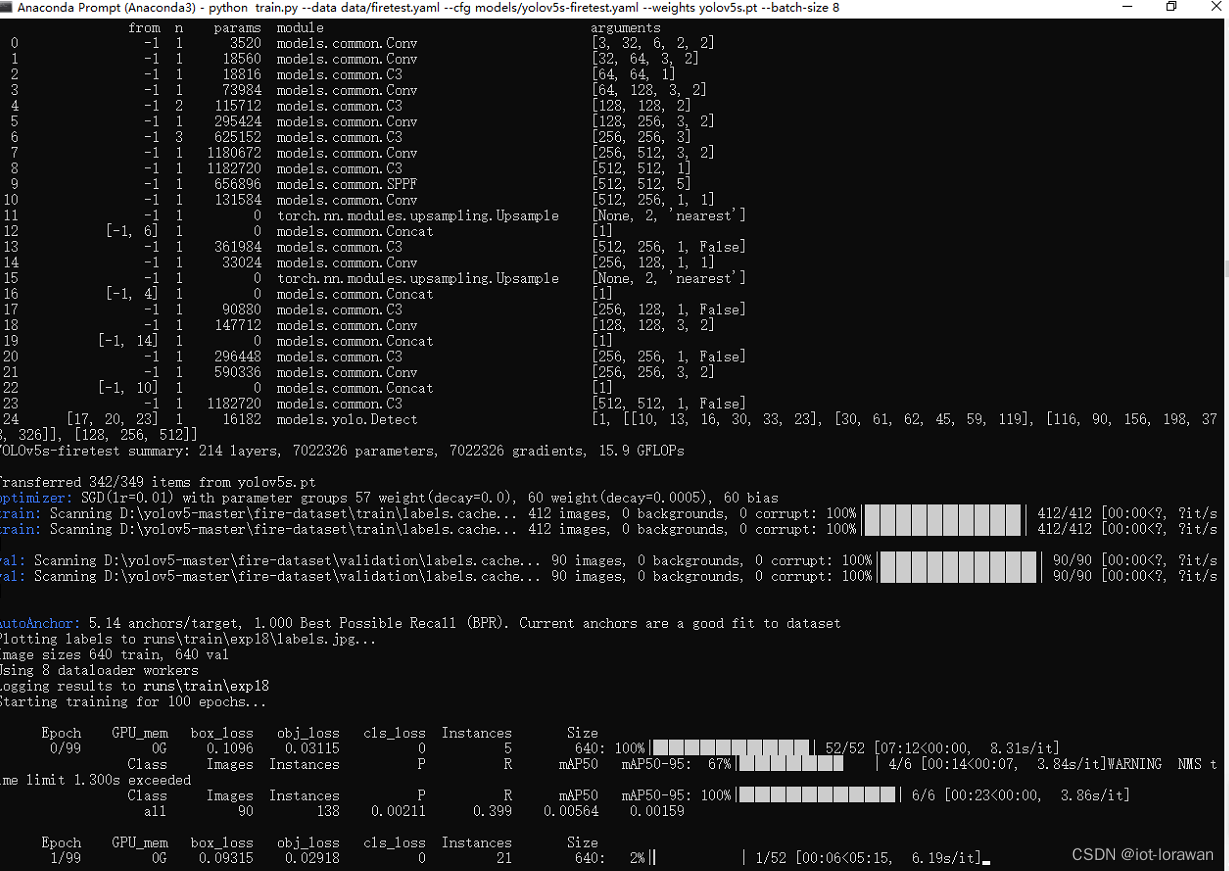
yolov5自定义模型训练二
前期准备好了用于训练识别是否有火灾的数据集后就可以开始修改yolo相关文件来进行训练 数据集放到yolov5目录里 在data目录下新建yaml文件设置数据集信息如下 在model文件夹下新增新的model文件 开始训练 训练出错 确认后是对训练数据集文件夹里的文件名字有要求,原…...
)
Spring框架获取用户真实IP(注解式)
文章目录 一、最终使用效果(ClientIp 注解获取)二、实现代码1.注解2.方法参数解析器(Resolver)3.全局增加Resolver配置 Spring 框架没有现成工具可以方便提取客户端的IP地址,普遍做法就是通过 HttpServletRequest 的 g…...

利用 IDEA IDE 的轻量编辑模式快速查看和编辑工程外的文本文件
作为程序员, 我们都知道 IDE 的很好用的, 它的文本编辑器功能也非常的强大, 用起来非常便捷. 在长年累月的使用中, 我们也变得对其非常熟悉, 以致于使用起其它简单地轻量级的文本编辑器来, 比如什么记事本, Notepad, UltraEdit 等等呀, 觉得既不方便又不熟悉. 关键是很多的操作…...
实战XSS:从标签事件到高级Payload的攻防演练)
Pikachu(皮卡丘靶场)实战XSS:从标签事件到高级Payload的攻防演练
1. 初识XSS与Pikachu靶场环境搭建 跨站脚本攻击(XSS)就像在别人的网页里偷偷塞小纸条,当其他用户打开这个网页时,小纸条上的内容就会被浏览器执行。想象一下,你在图书馆的公共留言板上贴了一张看似普通的便利贴&#x…...

初创公司如何借助Taotoken统一管理多个AI模型的API密钥
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初创公司如何借助Taotoken统一管理多个AI模型的API密钥 对于技术资源有限的初创公司而言,在业务开发中引入多种大模型能…...

闪电网络水龙头与MCP钱包:构建微支付应用的开发实践
1. 项目概述:闪电网络水龙头与MCP钱包的融合最近在捣鼓闪电网络相关的开源项目时,发现了一个挺有意思的仓库:lightningfaucet/lightning-wallet-mcp。光看这个名字,就包含了几个关键元素:“闪电网络”、“水龙头”、“…...

Atmosphere 1.7.1:基于安全监控器的任天堂Switch微内核架构深度解析
Atmosphere 1.7.1:基于安全监控器的任天堂Switch微内核架构深度解析 【免费下载链接】Atmosphere-stable 大气层整合包系统稳定版 项目地址: https://gitcode.com/gh_mirrors/at/Atmosphere-stable Atmosphere 1.7.1是一个针对任天堂Switch游戏主机的完整自定…...

GEO优化实操框架:GEO优化的正确姿势是“带着答案去找客户”
如果你是B2B企业的老板或市场负责人,你一定听过这句话: “我们网上曝光是不少,但来的询盘都不对——问价格的比问方案的还多,还有不少是学生做调研的。” 这不是你一个人遇到的问题。这是传统SEO和竞价广告的天然缺陷——你只能“…...

FanControl终极指南:免费开源的风扇控制神器,轻松解决Windows散热与噪音问题
FanControl终极指南:免费开源的风扇控制神器,轻松解决Windows散热与噪音问题 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https:…...

Swagger2Word终极指南:3种方法实现API文档自动化转换
Swagger2Word终极指南:3种方法实现API文档自动化转换 【免费下载链接】swagger2word 项目地址: https://gitcode.com/gh_mirrors/swa/swagger2word 还在为手动编写API文档而烦恼吗?Swagger2Word为你提供了一站式自动化解决方案,将Swa…...

恶劣环境下LED发光服饰的可靠系统构建:从设计到工艺的工程实践
1. 项目概述与核心挑战如果你曾经尝试过制作一件会发光的服装,无论是为了音乐节、万圣节还是水下表演,你大概都体会过那种“亮一次,修三次”的挫败感。LED灯带在工作室的桌面上测试时完美无瑕,一旦穿到身上,开始活动、…...

从零构建个人知识库:Go+React全栈项目RocketNotes实战解析
1. 项目概述:从零到一构建个人知识管理工具最近在整理个人笔记和代码片段时,发现了一个挺有意思的开源项目fynnfluegge/rocketnotes。乍一看这个名字,可能会联想到火箭(Rocket)和笔记(Notes)的结…...
)
低多边形≠简陋!掌握这7个结构化Prompt技巧,3分钟产出可商用IP形象(附Figma网格对齐校验表)
更多请点击: https://intelliparadigm.com 第一章:低多边形设计的认知革命:从“简陋感”到“结构化美学” 低多边形(Low-Poly)设计曾长期被误读为建模能力不足的妥协产物,但其本质是一场对数字视觉语法的系…...