(二十)大数据实战——Flume数据采集的基本案例实战
前言
本节内容我们主要介绍几个Flume数据采集的基本案例,包括监控端口数据、实时监控单个追加文件、实时监控目录下多个新文件、实时监控目录下的多个追加文件等案例。完成flume数据监控的基本使用。
正文
- 监控端口数据
①需求说明
- 使用 Flume 监听一个端口,收集该端口数据,并打印到控制台
②需求分析:
③安装netcat 工具:sudo yum install -y nc
④查看监听端口1111是否被占用:注意测试端口的范围是0-65535
⑤在flume安装目录下创建一个job目录:用与存放监听数据的配置文件
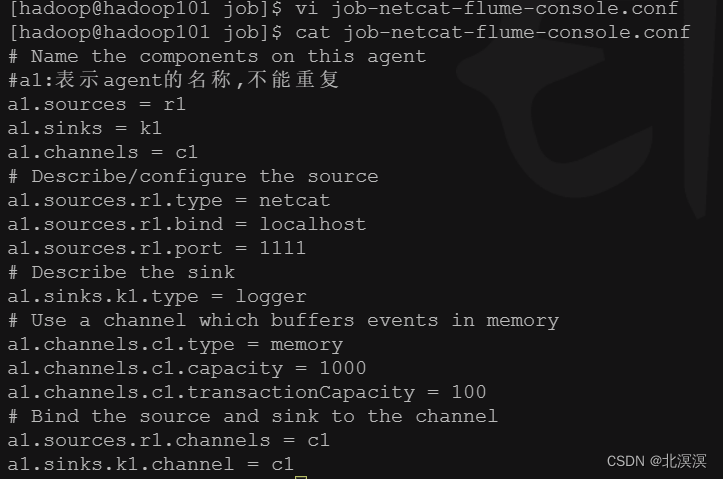
⑥在job目录下创建监听数据的配置文件:job-netcat-flume-console.conf
# Name the components on this agent #a1:表示agent的名称,不能重复 a1.sources = r1 #r1:表示a1的Source的名称 a1.sinks = k1 #k1:表示a1的Sink的名称 a1.channels = c1 #c1:表示a1的Channel的名称 # Describe/configure the source a1.sources.r1.type = netcat #表示a1的输入源类型为netcat端口类型 a1.sources.r1.bind = localhost #表示a1的监听的主机 a1.sources.r1.port = 1111 #表示a1的监听的端口号 # Describe the sink a1.sinks.k1.type = logger #表示a1的输出目的地是控制台logger类型 # Use a channel which buffers events in memory a1.channels.c1.type = memory #表示a1的channel类型是memory内存型 a1.channels.c1.capacity = 1000 #表示a1的channel总容量1000个event a1.channels.c1.transactionCapacity = 100 #表示a1的channel传输时收集到了100条event以后再去提交事务 # Bind the source and sink to the channel a1.sources.r1.channels = c1 #表示将r1和c1连接起来 a1.sinks.k1.channel = c1 #表示将k1和c1连接起来
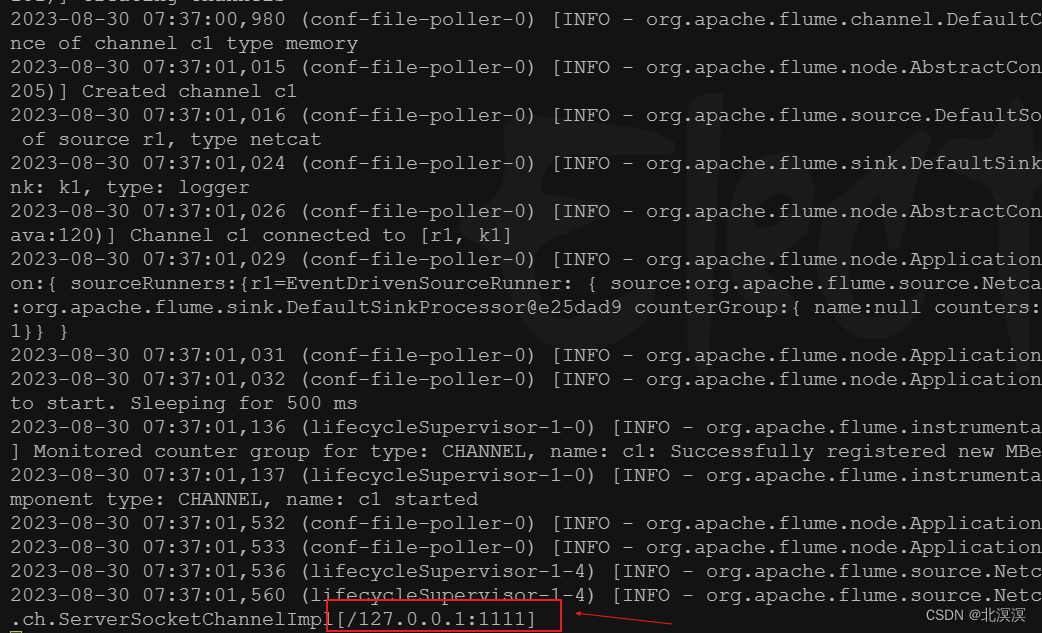
⑦开启 flume服务监听端口:
bin/flume-ng agent -c conf/ -n a1 -f job/job-netcat-flume-console.conf -Dflume.root.logger=INFO,console
⑧启动参数说明:
--conf/-c:表示配置文件存储在 conf/目录
--name/-n:表示给 agent 起名为 a1
--conf-file/-f:flume本次启动读取的配置文件是在job文件夹下的job-netcat-flume-console.conf文件
-Dflume.root.logger=INFO,console :-D 表示 flume 运行时动态修改 flume.root.logger 参数属性值,并将控制台日志打印级别设置为 INFO 级别。日志级别包括:log、info、warn、 error
⑨使用netcat 工具向本机的1111端口发送内容



- 实时监控单个追加文件
①监控需求
- 实时监控Hive日志,并上传到HDFS
②需求分析:
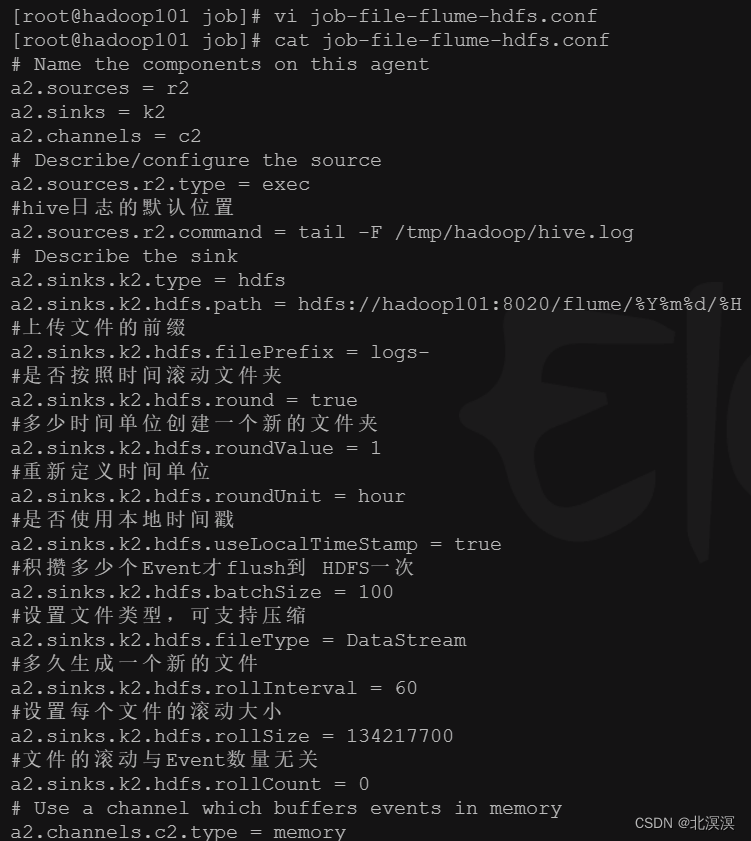
③在job目录下创建监听数据的配置文件:job-file-flume-hdfs.conf
# Name the components on this agent a2.sources = r2 a2.sinks = k2 a2.channels = c2 # Describe/configure the source a2.sources.r2.type = exec #hive日志的默认位置 a2.sources.r2.command = tail -F /tmp/hadoop/hive.log # Describe the sink a2.sinks.k2.type = hdfs a2.sinks.k2.hdfs.path = hdfs://hadoop101:8020/flume/%Y%m%d/%H #上传文件的前缀 a2.sinks.k2.hdfs.filePrefix = logs- #是否按照时间滚动文件夹 a2.sinks.k2.hdfs.round = true #多少时间单位创建一个新的文件夹 a2.sinks.k2.hdfs.roundValue = 1 #重新定义时间单位 a2.sinks.k2.hdfs.roundUnit = hour #是否使用本地时间戳 a2.sinks.k2.hdfs.useLocalTimeStamp = true #积攒多少个Event才flush到 HDFS一次 a2.sinks.k2.hdfs.batchSize = 100 #设置文件类型,可支持压缩 a2.sinks.k2.hdfs.fileType = DataStream #多久生成一个新的文件 a2.sinks.k2.hdfs.rollInterval = 60 #设置每个文件的滚动大小 a2.sinks.k2.hdfs.rollSize = 134217700 #文件的滚动与Event数量无关 a2.sinks.k2.hdfs.rollCount = 0 # Use a channel which buffers events in memory a2.channels.c2.type = memory a2.channels.c2.capacity = 1000 a2.channels.c2.transactionCapacity = 100 # Bind the source and sink to the channel a2.sources.r2.channels = c2 a2.sinks.k2.channel = c2
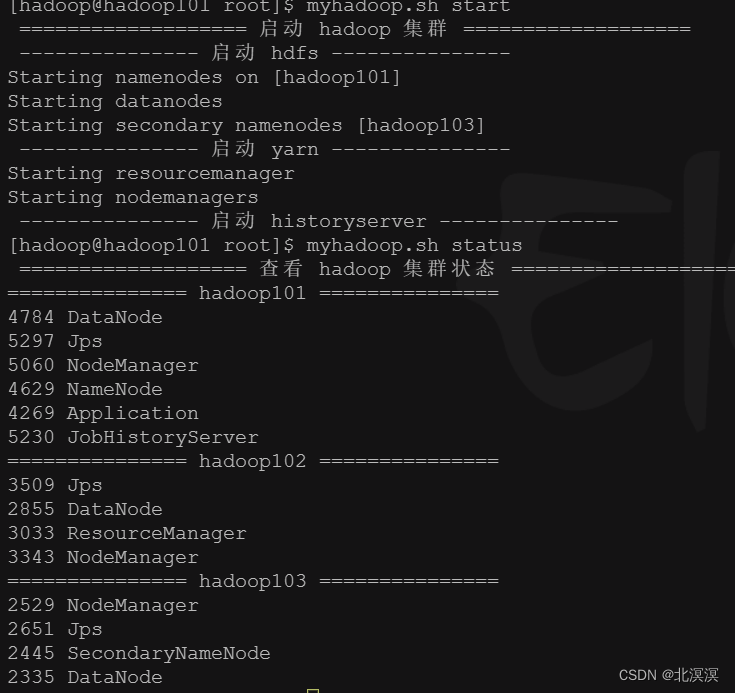
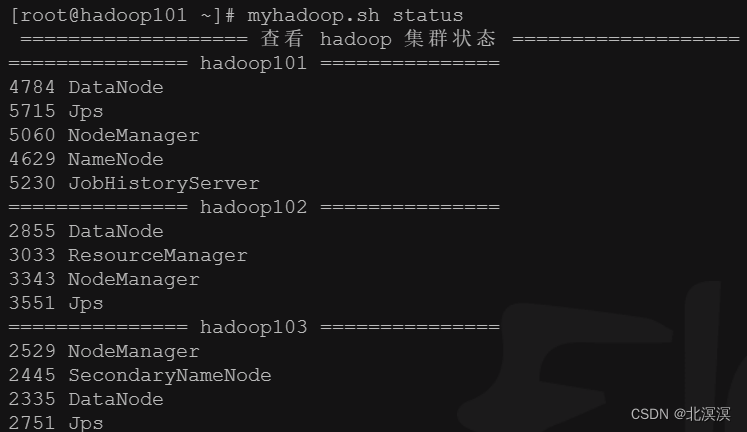
④启动hadoop集群
⑤启动flume监控任务
bin/flume-ng agent --conf conf/ --name a2 --conf-file job/job-file-flume-hdfs.conf -Dflume.root.logger=INFO,console
⑥启动hive
⑦查看hdfs是否有监控日志
⑧存在的问题
- tail命令不能实现断点续传监控的功能,可能会有数据丢失的情况或者数据重复的问题
- Exec source 适用于监控一个实时追加的文件,不能实现断点续传




- 实时监控目录下多个新文件
①监控需求
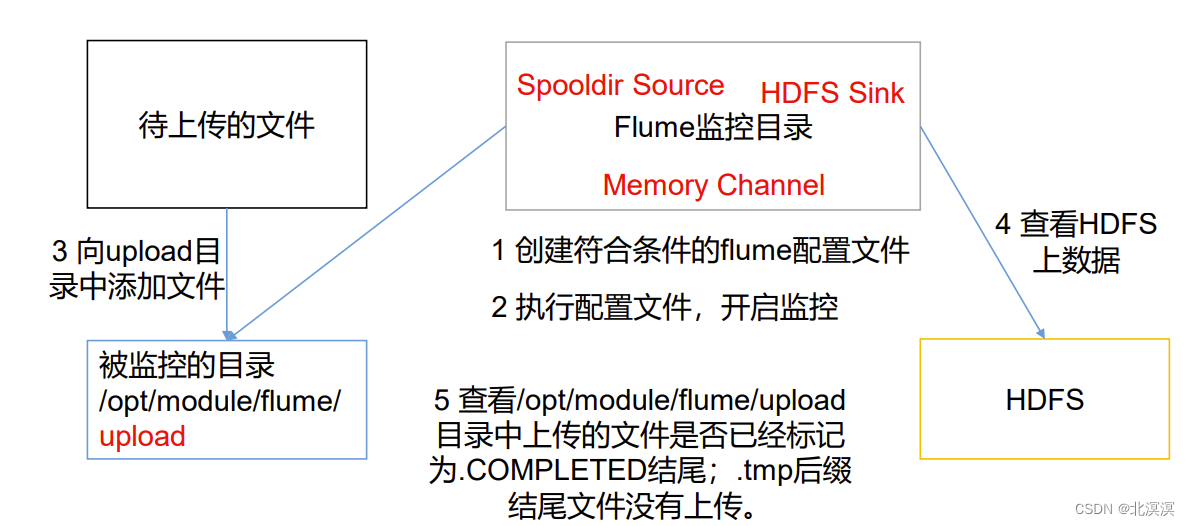
- 使用 Flume 监听整个目录的文件,并上传至 HDFS
②需求分析
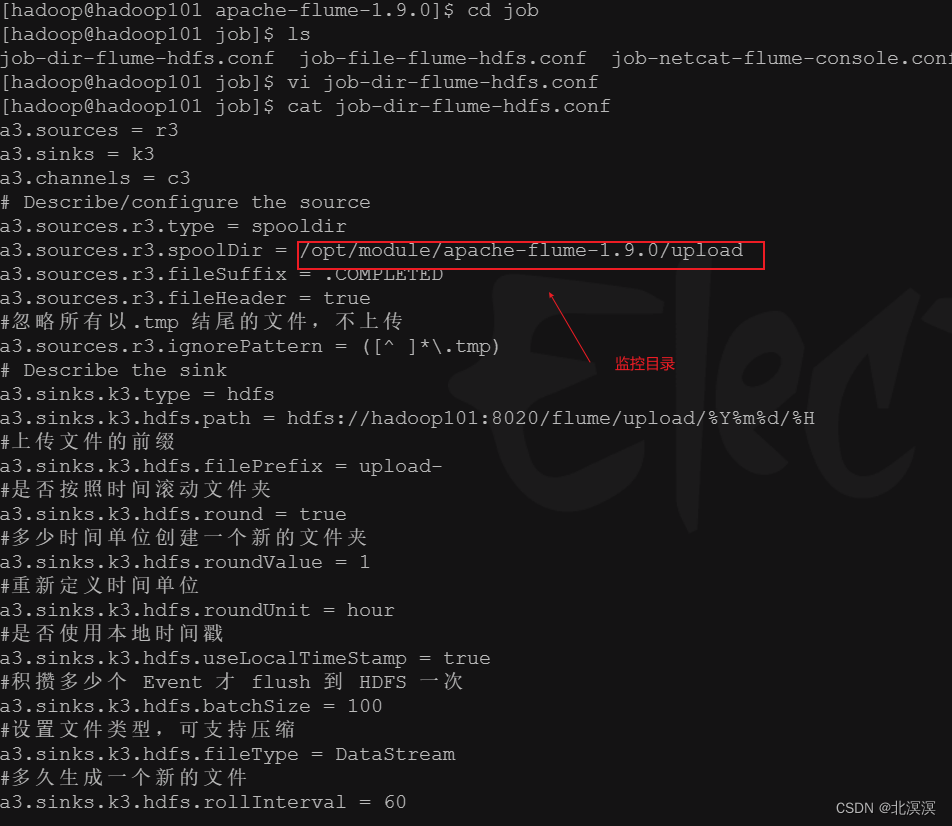
③在job目录下创建监听目录数据的配置文件:job-dir-flume-hdfs.conf
a3.sources = r3 a3.sinks = k3 a3.channels = c3 # Describe/configure the source a3.sources.r3.type = spooldir a3.sources.r3.spoolDir = /opt/module/apache-flume-1.9.0/upload a3.sources.r3.fileSuffix = .COMPLETED a3.sources.r3.fileHeader = true #忽略所有以.tmp 结尾的文件,不上传 a3.sources.r3.ignorePattern = ([^ ]*\.tmp) # Describe the sink a3.sinks.k3.type = hdfs a3.sinks.k3.hdfs.path = hdfs://hadoop101:8020/flume/upload/%Y%m%d/%H #上传文件的前缀 a3.sinks.k3.hdfs.filePrefix = upload- #是否按照时间滚动文件夹 a3.sinks.k3.hdfs.round = true #多少时间单位创建一个新的文件夹 a3.sinks.k3.hdfs.roundValue = 1 #重新定义时间单位 a3.sinks.k3.hdfs.roundUnit = hour #是否使用本地时间戳 a3.sinks.k3.hdfs.useLocalTimeStamp = true #积攒多少个 Event 才 flush 到 HDFS 一次 a3.sinks.k3.hdfs.batchSize = 100 #设置文件类型,可支持压缩 a3.sinks.k3.hdfs.fileType = DataStream #多久生成一个新的文件 a3.sinks.k3.hdfs.rollInterval = 60 #设置每个文件的滚动大小大概是 128M a3.sinks.k3.hdfs.rollSize = 134217700 #文件的滚动与 Event 数量无关 a3.sinks.k3.hdfs.rollCount = 0 # Use a channel which buffers events in memory a3.channels.c3.type = memory a3.channels.c3.capacity = 1000 a3.channels.c3.transactionCapacity = 100 # Bind the source and sink to the channel a3.sources.r3.channels = c3 a3.sinks.k3.channel = c3
④启动hadoop集群
⑤创建upload监控目录
⑥启动目录监控任务
bin/flume-ng agent -c conf/ -n a3 -f job/job-dir-flume-hdfs.conf -Dflume.root.logger=INFO,console
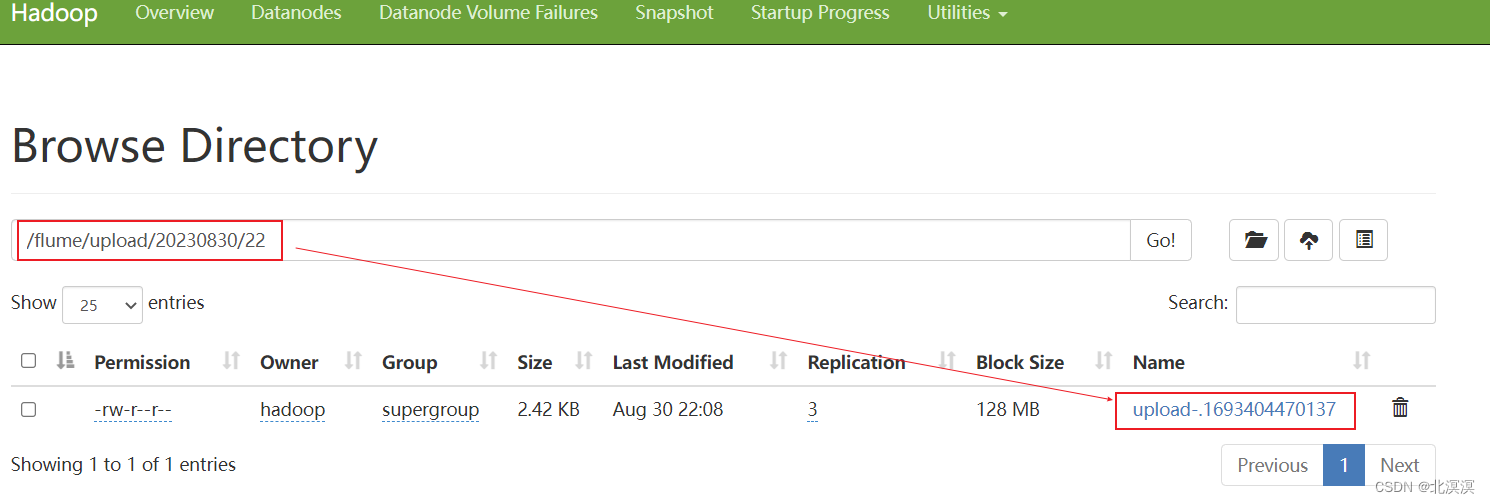
⑦在upload中上传文件
⑧查看hdfs中是否上传成功
⑨存在的问题
- 相同文件名的文件不能重复上传,只能上传一次,修改了也不会再次上传
- 忽略的文件和配置后缀.COMPLETED的文件不能重复上传
- Spooldir Source 适合用于同步新文件,但不适合对实时追加日志的文件进行监听并同步



- 实时监控目录下的多个追加文件
①案例需求
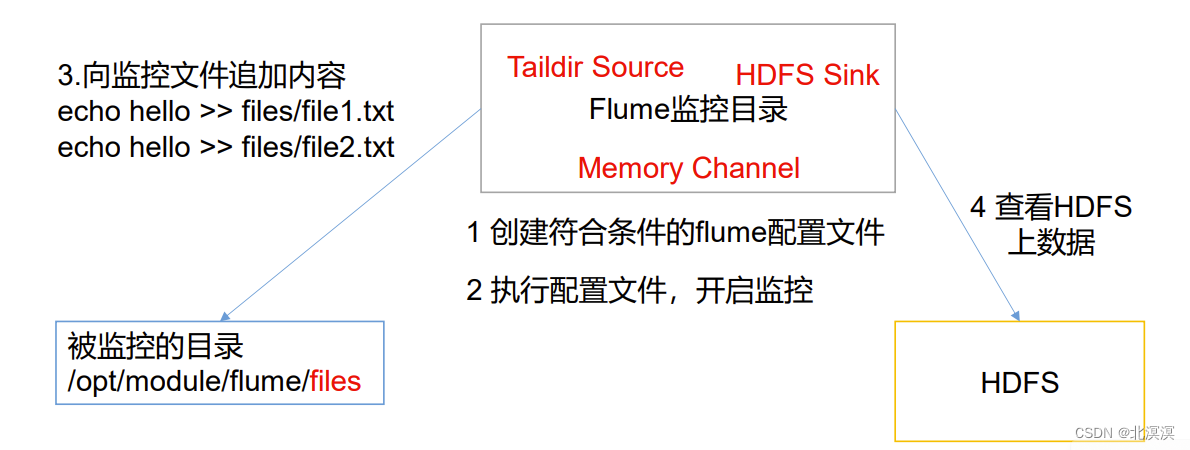
- 使用Flume监听整个目录的实时追加文件,并上传至HDFS
- 使用Taildir Source适合用于监听多个实时追加的文件,并且能够实现断点续传
②需求分析
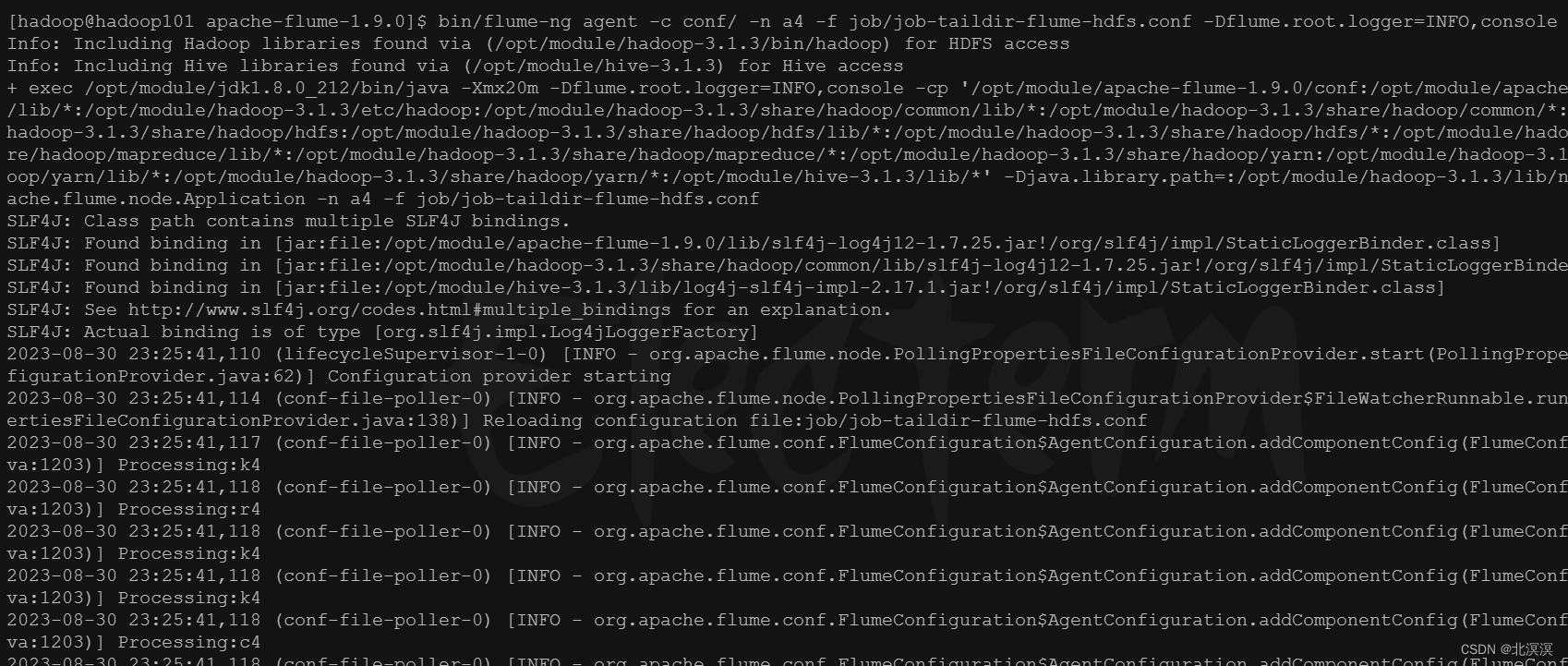
③在job目录下创建监听目录数据的配置文件:job-taildir-flume-hdfs.conf
a4.sources = r4 a4.sinks = k4 a4.channels = c4 # Describe/configure the source a4.sources.r4.type = TAILDIR a4.sources.r4.positionFile = /opt/module/apache-flume-1.9.0/tail_dir.json a4.sources.r4.filegroups = f1 f2 a4.sources.r4.filegroups.f1 = /opt/module/apache-flume-1.9.0/files/.*file.* a4.sources.r4.filegroups.f2 = /opt/module/apache-flume-1.9.0/files2/.*log.* # Describe the sink a4.sinks.k4.type = hdfs a4.sinks.k4.hdfs.path = hdfs://hadoop101:8020/flume/upload2/%Y%m%d/%H #上传文件的前缀 a4.sinks.k4.hdfs.filePrefix = upload- #是否按照时间滚动文件夹 a4.sinks.k4.hdfs.round = true #多少时间单位创建一个新的文件夹 a4.sinks.k4.hdfs.roundValue = 1 #重新定义时间单位 a4.sinks.k4.hdfs.roundUnit = hour #是否使用本地时间戳 a4.sinks.k4.hdfs.useLocalTimeStamp = true #积攒多少个 Event 才 flush 到 HDFS 一次 a4.sinks.k4.hdfs.batchSize = 100 #设置文件类型,可支持压缩 a4.sinks.k4.hdfs.fileType = DataStream #多久生成一个新的文件 a4.sinks.k4.hdfs.rollInterval = 60 #设置每个文件的滚动大小大概是 128M a4.sinks.k4.hdfs.rollSize = 134217700 #文件的滚动与 Event 数量无关 a4.sinks.k4.hdfs.rollCount = 0 # Use a channel which buffers events in memory a4.channels.c4.type = memory a4.channels.c4.capacity = 1000 a4.channels.c4.transactionCapacity = 100 # Bind the source and sink to the channel a4.sources.r4.channels = c4 a4.sinks.k4.channel = c4
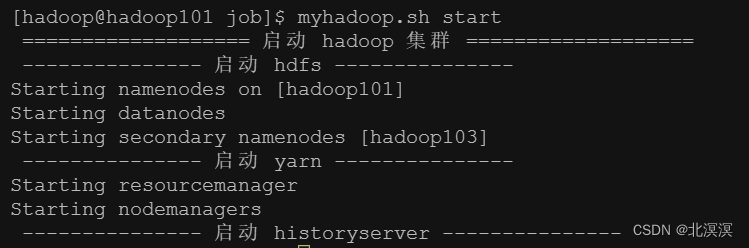
④启动hadoop集群
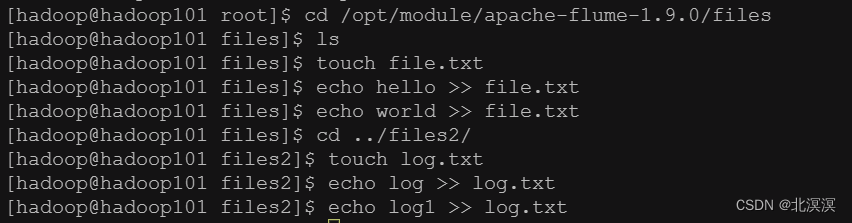
⑤创建监控目录文件files和files2
⑥启动flume监控
bin/flume-ng agent -c conf/ -n a4 -f job/job-taildir-flume-hdfs.conf -Dflume.root.logger=INFO,console
⑦往files和files2目录中的文件写数据
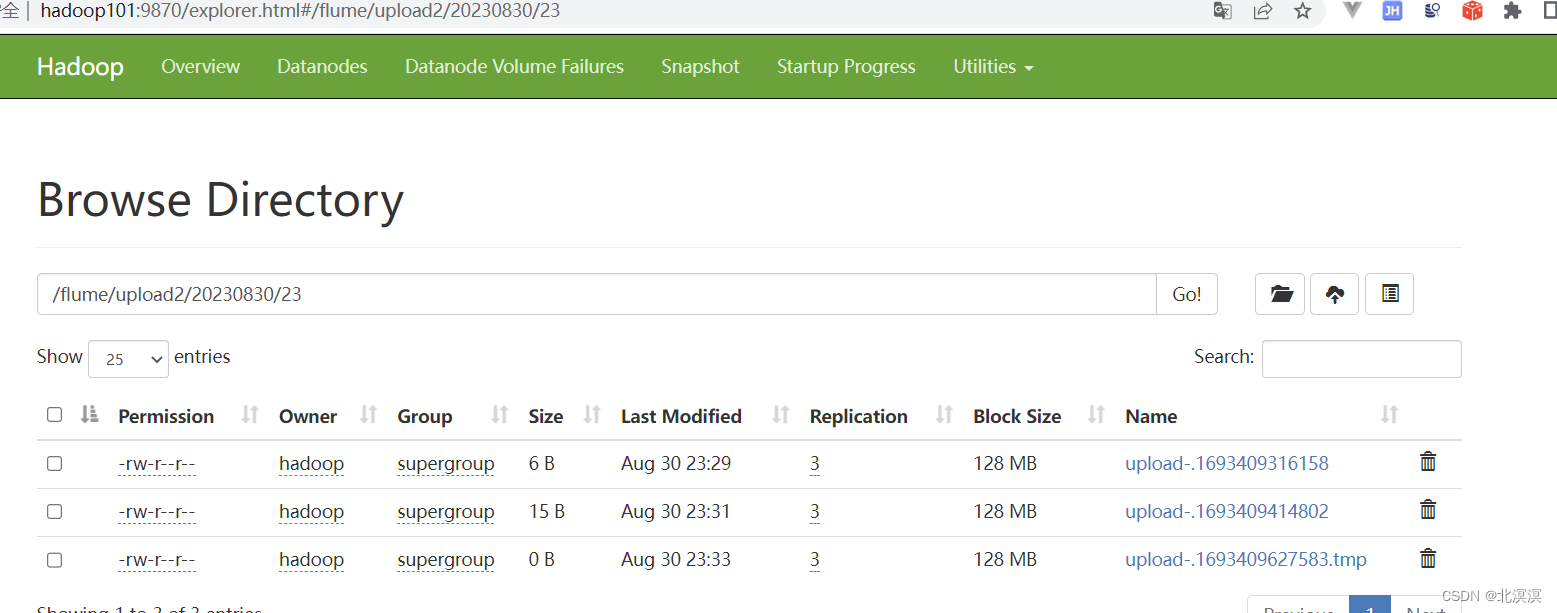
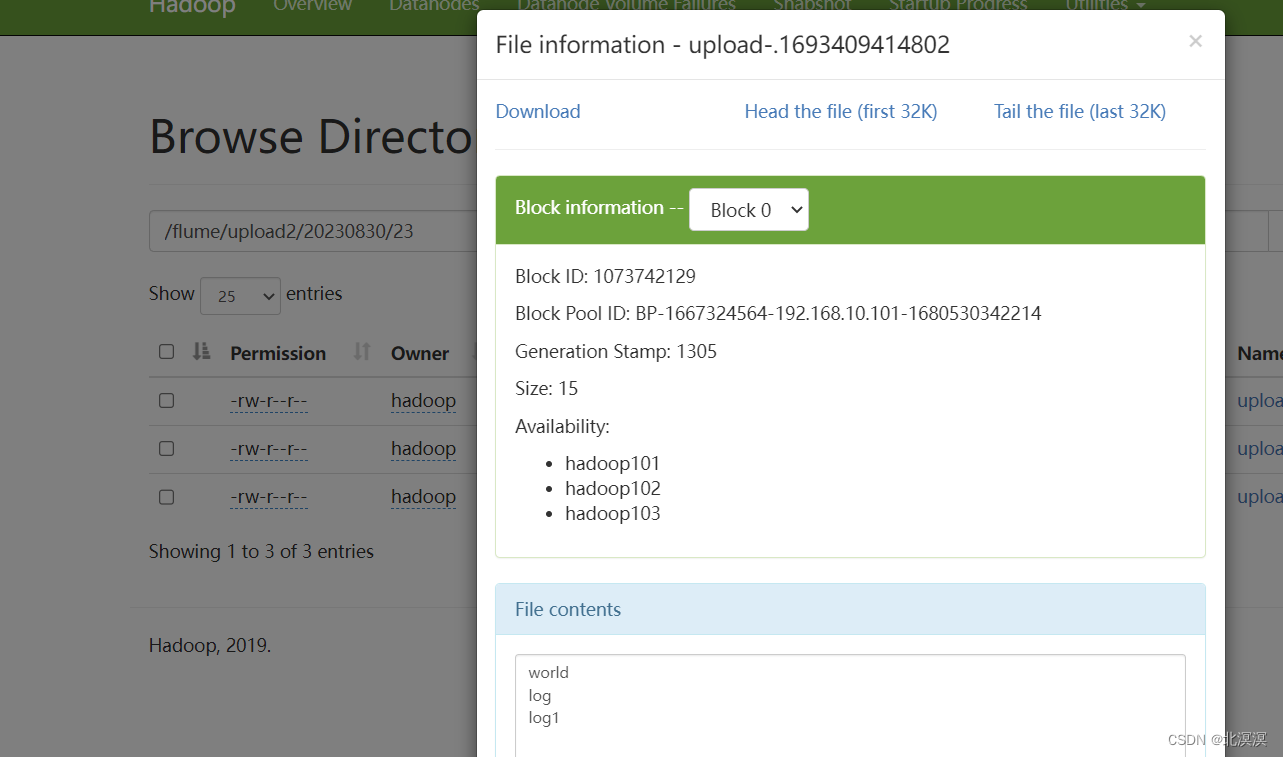
⑧在hdfs中查看数据


结语
关于Flume数据采集的基本案例实战到这里就结束了,我们下期见。。。。。。
相关文章:
(二十)大数据实战——Flume数据采集的基本案例实战
前言 本节内容我们主要介绍几个Flume数据采集的基本案例,包括监控端口数据、实时监控单个追加文件、实时监控目录下多个新文件、实时监控目录下的多个追加文件等案例。完成flume数据监控的基本使用。 正文 监控端口数据 ①需求说明 - 使用 Flume 监听一个端口&am…...

AutoCAD图如何保存为Word
AutoCAD图如何保存为Word 引言AutoCAD图保存为Word文件步骤: 引言 不知道大家有没有是否遇到需要将AutoCAD图保存到Word中。有些小伙伴可能直接截图插入Word中,这种方法简单,但对于有高清图片需求的小伙伴就不适用了。接下来我就为大家介绍一…...
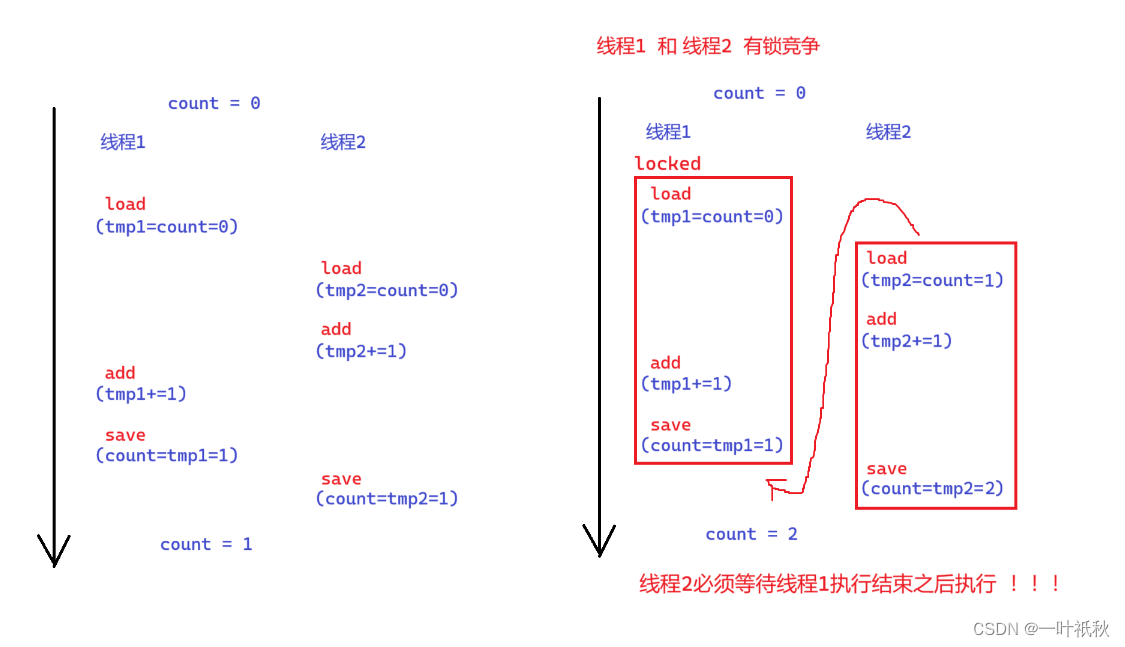
Java线程 - 详解(2)
一,线程安全问题 有些代码在单个线程的环境下运行,完全正确,但是同样的代码,让多个线程去执行,此时就可能出现BUG,这就是所谓的 "线程安全问题"。举一个例子: public class Demo {s…...

事务特性 - 达梦数据库
达梦数据库事务特性 1 事务特性1.1 原子性1.2 一致性1.3 隔离性1.4 持久性 1 事务特性 事务必须具备什么属性才是一个有效的事务呢?一个逻辑工作单元必须表现出四种属性,即原子性、一致性、隔离性和持久性,这样才能成为一个有效的事务。DM 数…...

axios 使用FormData格式发送GET请求
如果你需要使用,FormData格式,发送GET请求 将参数拼接到 FormData对象 中,使用 URLSearchParams 将FormData对象转换为查询参数字符串,并将其拼接到URL中,这样就能以FormData格式发送GET请求给服务器 注意࿱…...

CS144(2023 Spring)Lab 1: stitching substrings into a byte stream
文章目录 前言其他笔记相关链接 1. Getting started2. Putting substrings in sequence2.1 需求分析2.2 注意事项2.3 代码实现 3. 测试与优化 前言 这一个Lab主要是实现一个TCP receiver的字符串接收重组部分。 其他笔记 Lab 0: networking warmup Lab 1: stitching substri…...

【PHP】常用的PHP内置函数
1、PHP内置函数非常丰富,用于执行各种任务。以下是一些常用的PHP内置函数: 字符串操作函数: strlen(): 返回字符串的长度。 strpos(): 查找字符串中的某个子串第一次出现的位置。 substr(): 返回字符串的子串。 str_replace(): 替换字符串中的…...
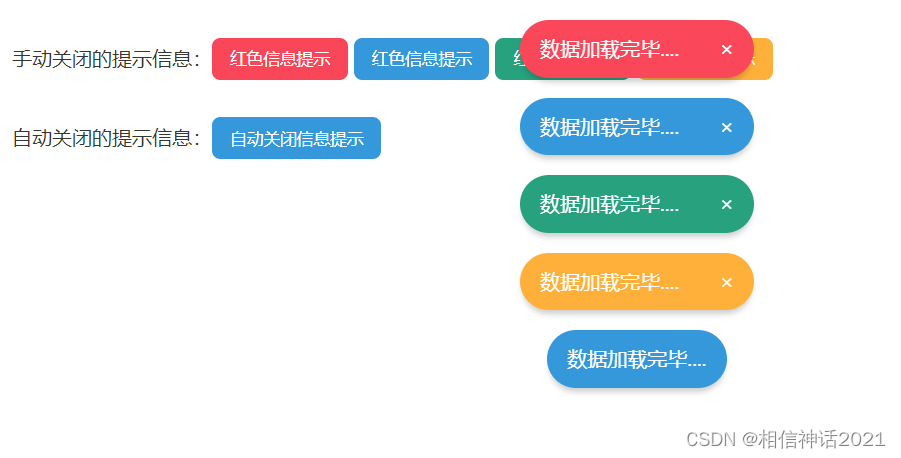
css自学框架之消息弹框
首先我们还是看看消息弹框效果: 主要实现代码分为三部分 一、CSS部分,这部分主要是定义样式,也就是我们看到的外表,主要代码: /* - 弹窗 */notice{top: 0;left: 0;right: 0;z-index: 10;padding: 1em;position: fix…...
42、Flink 的table api与sql之Hive Catalog
Flink 系列文章 1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接 13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…...

PAT 1145 Hashing - Average Search Time
个人学习记录,代码难免不尽人意。 The task of this problem is simple: insert a sequence of distinct positive integers into a hash table first. Then try to find another sequence of integer keys from the table and output the average search time (the…...
C++调用Python Win10 Miniconda虚拟环境配置
目录 前言1. Win10 安装 Miniconda2. 创建虚拟环境3. 配置C调用python环境4. C调用Python带参函数5.遇到的问题6. 总结 前言 本文记录了Win10 系统下Qt 应用程序调用Python时配置Miniconda虚拟环境的过程及遇到的问题,通过配置Python虚拟环境,简化了Qt应…...

从0到1学会Git(第一部分):Git的下载和初始化配置
1.Git是什么: 首先我们看一下百度百科的介绍:Git(读音为/gɪt/)是一个开源的分布式版本控制系统,可以有效、高速地处理从很小到非常大的项目版本管理。 也是Linus Torvalds为了帮助管理Linux内核开发而开发的一个开放源码的版本控制软件。 …...

【记录】手机QQ和电脑QQ里的emoji种类有什么差异?
版本 手机 QQ:V 8.9.76.12115 电脑 QQ:QQ9.7.15(29157) 偶然发现,有一种emoji手机上怎么找都找不到,一开始以为自己失忆了,后来发现这种emoji只在电脑上有。 接下来简单说一下找emoji差异的方式…...
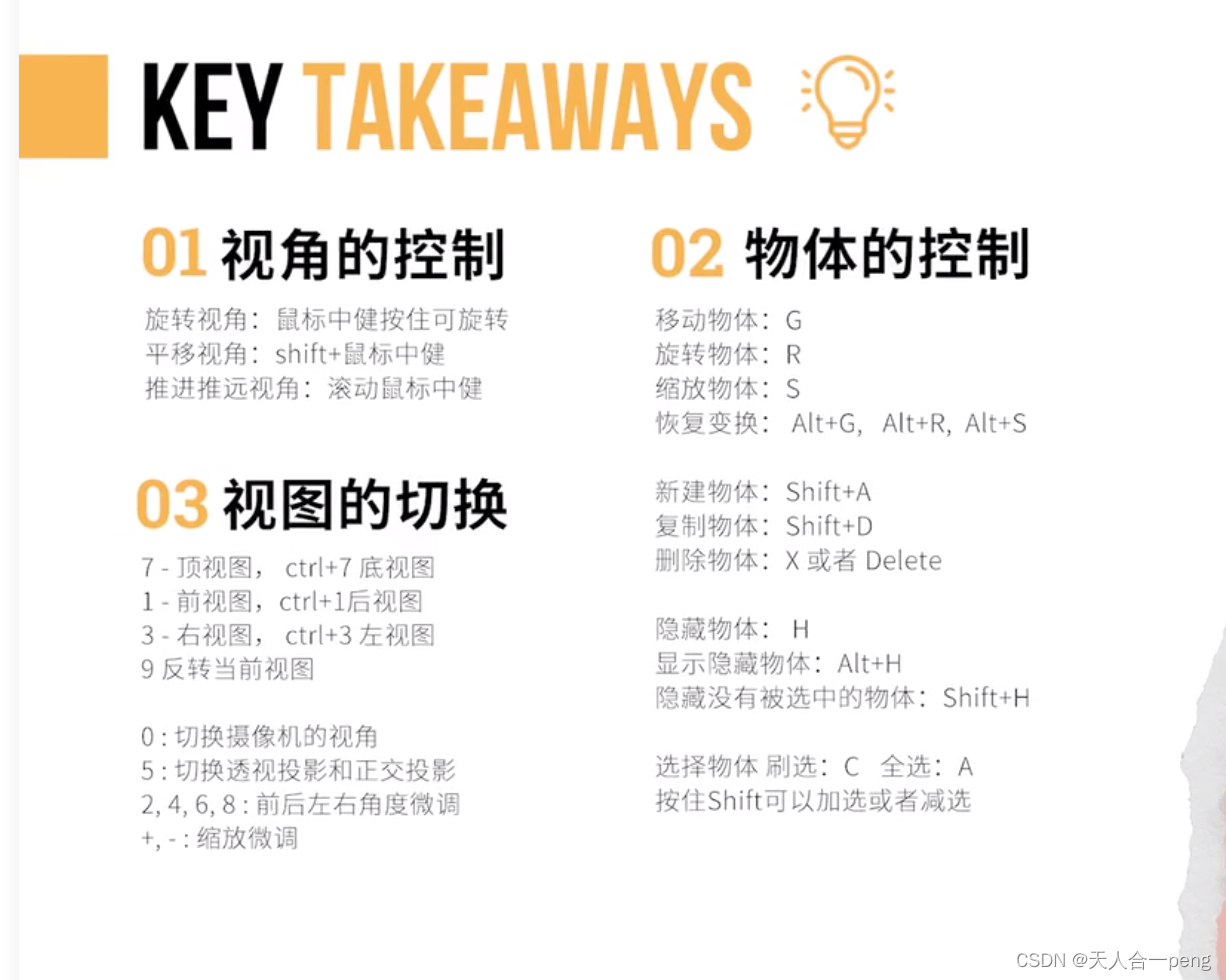
blender界面认识01
学习视频 【基础篇】1.2 让手听话_哔哩哔哩_bilibili 目录 控制视角 控制物体 选择对象1 小结 控制视角 长按鼠标中键-----视角旋转 shift鼠标中键-----视角平移 滚动鼠标中键-----视角缩放 也可以通过界面的快捷工具实现 这个视角旋转有一点像catia中罗盘,…...

TCP数据报结构分析(面试重点)
在传输层中有UDP和TCP两个重要的协议,下面将针对TCP数据报的结构进行分析 关于UDP数据报的结构分析推荐看UDP数据报结构分析(面试重点) TCP结构图示 TCP报头结构的分析 一.16位源端口号 源端口表示发送数据时,发送方的端口号&am…...

合并两个有序的单链表,合并之后的链表依然有序
定义节点 class ListNode {var next: ListNode _var x: Int _def this(x: Int) {thisthis.x x}override def toString: String s"x>$x" } 定义方法 class LinkedList {var head new ListNode(0)def getHead(): ListNode this.headdef add(listNode: Li…...
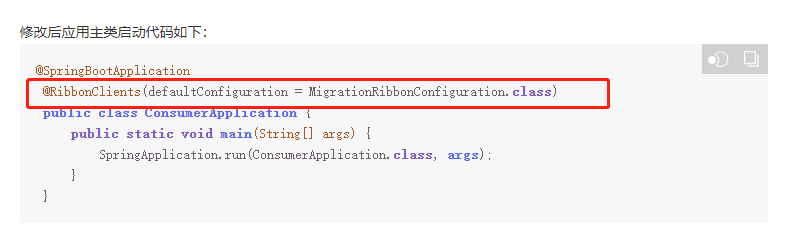
eureka迁移到nacos--双服务中心注册
服务注册中心的迁移有多种方式,官网使用nacos sync,还有民间开发的双注册中心组件eureka-nacos-proxy,但是我用了不太顺利,所以用的是阿里巴巴的双注册中心组件edas-sc-migration-starter spring boot:2.5.3 引入依赖 …...

线程池使用不规范导致线程数大以及@Async的规范使用
文章详细内容来自:线程数突增!领导:谁再这么写就滚蛋! 下面是看完后文章的,一个总结 线程池的使用不规范,导致程序中线程数不下降,线程数量大。 临时变量的接口,通过下面简单的线…...

启莱OA treelist.aspx SQL注入
子曰:“为政以德,譬如北辰,居其所,而众星共之。” 漏洞复现 访问漏洞url: 使用SQLmap对参数 user 进行注入 漏洞证明: 文笔生疏,措辞浅薄,望各位大佬不吝赐教,万分感…...
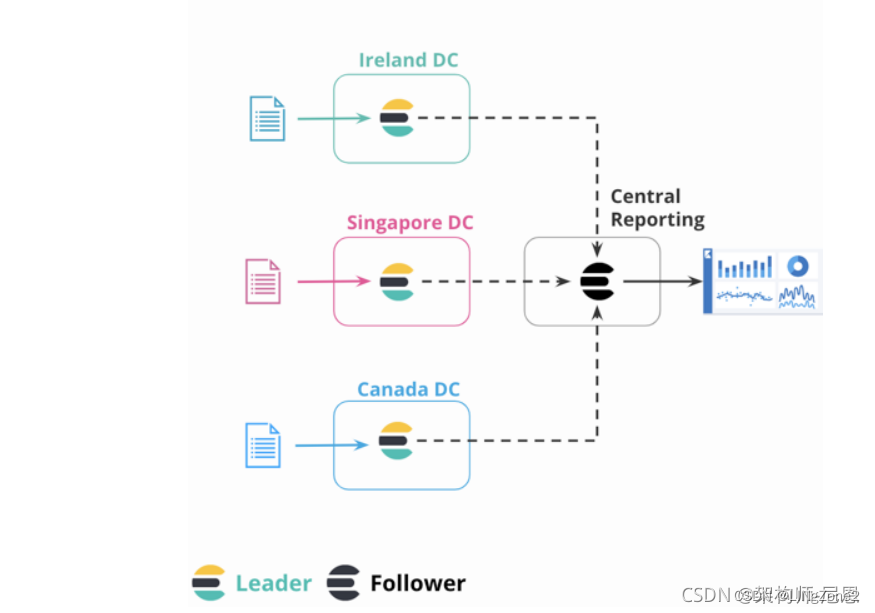
ES是一个分布式全文检索框架,隐藏了复杂的处理机制,核心数据分片机制、集群发现、分片负载均衡请求路由
ES是一个分布式框架,隐藏了复杂的处理机制,核心数据分片机制、集群发现、分片负载均衡请求路由。 ES的高可用架构,总体如下图: 说明:本文会以pdf格式持续更新,更多最新尼恩3高pdf笔记,请从下面…...

Manage Buddy:轻量自托管团队协作工具的设计、部署与实战
1. 项目概述与核心价值最近在梳理团队内部工具链时,我重新审视了一个我们重度依赖的开源项目——maziminds/manage-buddy。这并非一个广为人知的明星项目,但在中小型技术团队,尤其是追求敏捷与效率的研发团队中,它扮演着“隐形冠军…...

基于本地大模型的字幕翻译:LM Studio集成方案与实战优化
1. 项目概述:当本地大模型遇上字幕翻译最近在折腾本地大模型应用时,发现了一个挺有意思的场景:字幕翻译。很多朋友喜欢看海外影视剧或学习资料,但苦于没有高质量的中文字幕。在线翻译工具要么有字数限制,要么担心隐私泄…...

2026实测:能耗管控场景下的AI工具数据分析能力横向对比,实在Agent如何通过ISSUT打破数据孤岛?
【摘要】 步入2026年,全球能源结构转型进入深水区。随着数据中心耗电量突破1000太瓦时(TWh)以及工业领域对“双碳”目标的刚性对标,能耗管控场景已成为企业运营的战略核心。然而,企业在推进自动化能效管理时࿰…...

Adobe-GenP终极指南:5分钟破解Adobe创意套件限制的完整教程
Adobe-GenP终极指南:5分钟破解Adobe创意套件限制的完整教程 【免费下载链接】Adobe-GenP Adobe CC 2019/2020/2021/2022/2023 GenP Universal Patch 3.0 项目地址: https://gitcode.com/gh_mirrors/ad/Adobe-GenP 你是否曾因为Adobe Creative Cloud高昂的订阅…...

如何安全备份微信聊天记录:PyWxDump工具使用全指南
如何安全备份微信聊天记录:PyWxDump工具使用全指南 【免费下载链接】PyWxDump 删库 项目地址: https://gitcode.com/GitHub_Trending/py/PyWxDump 你是否曾因误删重要微信对话而懊悔不已?是否想永久保存珍贵聊天记录却不知从何下手?Py…...

如何快速掌握openpilot:从零到精通的自动驾驶系统终极指南
如何快速掌握openpilot:从零到精通的自动驾驶系统终极指南 【免费下载链接】openpilot openpilot is an operating system for robotics. Currently, it upgrades the driver assistance system on 300 supported cars. 项目地址: https://gitcode.com/GitHub_Tre…...

Taotoken用量看板如何帮助个人开发者管理月度预算
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板如何帮助个人开发者管理月度预算 对于独立工作的个人开发者而言,项目预算往往是决定技术选型与使用策…...

低温预警!固化慢、易开裂……密封胶冬季施工手册
低温预警!固化慢、易开裂……密封胶冬季施工手册 硅酮耐候密封胶主要作用是保障幕墙的气密性、水密性。其出现问题,可能会导致耐候密封失效,从而造成幕墙漏水漏气,影响幕墙的正常使用。耐候密封胶由于考虑到现场施工,几乎都是单组分硅酮密封胶产品。进入冬季,气候变化明…...

3分钟掌握跨平台模组下载神器:WorkshopDL全攻略
3分钟掌握跨平台模组下载神器:WorkshopDL全攻略 【免费下载链接】WorkshopDL WorkshopDL - The Best Steam Workshop Downloader 项目地址: https://gitcode.com/gh_mirrors/wo/WorkshopDL 还在为Epic Games或GOG平台的游戏无法使用Steam创意工坊模组而烦恼吗…...

5步实现AutoHotkey脚本独立运行:Ahk2Exe编译实战指南
5步实现AutoHotkey脚本独立运行:Ahk2Exe编译实战指南 【免费下载链接】Ahk2Exe Official AutoHotkey script compiler - written itself in AutoHotkey 项目地址: https://gitcode.com/gh_mirrors/ah/Ahk2Exe 你是否遇到过这样的困扰?精心编写的A…...