Iceberg实战踩坑指南
第 1 章 介绍
Apache Iceberg 是一种用于大型分析数据集的开放表格,Iceberge 向 Trino 和 Spark 添加了使用高性能格式的表,就像 Sql 表一样。
Iceberg 为了避免出现不变要的一些意外,表结构和组织并不会实际删除,用户也不需要特意了解分区便可进行快速查询。
- Iceberg 的表支持快速添加、删除、更新或重命名操作
- 将分区列进行隐藏,避免用户错误的使用分区和进行极慢的查询。
- 分区列也会随着表数据量或查询模式的变化而自动更新。
- 表可以根据时间进行表快照,方便用户根据时间进行检查更改。
- 提供版本回滚,方便用户纠错数据。
Iceberg 是为大表而建的,Iceberg 用于生产中,其中单表数据量可包含 10pb 左右数据, 甚至可以在没有分布式 SQL 引擎的情况下读取这些巨量数据。
- 查询计划非常迅速,不需要分布式 SQL 引擎来读取数据
- 高级过滤:可以使用分区和列来过滤查询这些数据
- 可适用于任何云存储
- 表的任何操作都是原子性的,用户不会看到部分或未提交的内容。
- 使用多个并发器进行写入,并使用乐观锁重试的机制来解决兼容性问题
第 2 章 构建 Iceberg
构建 Iceberge 需要 Grade 5.41 和 java8 或 java11 的环境
2.1 构建 Iceberg
1.上传 iceberg-apache-iceberg-0.11.1.zip,并进行解压
[root@hadoop103 software]# unzip iceberg-apache-iceberg-0.11.1.zip -d /opt/module/
[root@hadoop103 software]# cd /opt/module/iceberg-apache-iceberg-0.11.1/2.修改对应版本
[root@hadoop103 iceberg-apache-iceberg-0.11.1]# vim versions.props org.apache.flink:* = 1.11.0
org.apache.hadoop:* = 3.1.3
org.apache.hive:hive-metastore = 2.3.7org.apache.hive:hive-serde = 2.3.7
org.apache.spark:spark-hive_2.12 = 3.0.1
org.apache.hive:hive-exec = 2.3.7
org.apache.hive:hive-service = 2.3.73.修改国内镜像
[root@hadoop103 iceberg-apache-iceberg-0.11.1]# vim build.gradle buildscript {
repositories { jcenter() gradlePluginPortal()
maven{ url 'http://maven.aliyun.com/nexus/content/groups/public/' } maven{ url 'http://maven.aliyun.com/nexus/content/repositories/jcenter'} maven { url "http://palantir.bintray.com/releases" }
maven { url "https://plugins.gradle.org/m2/" }
}allprojects {
group = "org.apache.iceberg" version = getProjectVersion() repositories {
maven{ url 'http://maven.aliyun.com/nexus/content/groups/public/'} maven{ url 'http://maven.aliyun.com/nexus/content/repositories/jcenter'} maven { url "http://palantir.bintray.com/releases" }
mavenCentral() mavenLocal()
}
}4.构建项目
[root@hadoop103 iceberg-apache-iceberg-0.11.1]# ./gradlew build -x test第 3 章 Spark 操作
3.1.配置参数和 jar 包
1.将构建好的 Iceberg 的 spark 模块 jar 包,复制到 spark jars 下
[root@hadoop103]/opt/module/iceberg-apache-iceberg-0.11.1/spark3-extensions/build/libs/ [root@hadoop103 libs]# cp *.jar /opt/module/spark-3.0.1-bin-hadoop2.7/jars/ [root@hadoop103 libs]# cd
/opt/module/iceberg-apache-iceberg-0.11.1/spark3-runtime/build/libs/
[root@hadoop103 libs]# cp *.jar /opt/module/spark-3.0.1-bin-hadoop2.7/jars/2.配置 spark 参数,配置 Spark Sql Catlog,可以用两种方式,基于 hive 和基于 hadoop,这里先选择基于 hadoop。
[root@hadoop103 libs]# cd /opt/module/spark-3.0.1-bin-hadoop2.7/conf/
[root@hadoop103 conf]# vim spark-defaults.conf spark.sql.catalog.hive_prod = org.apache.iceberg.spark.SparkCatalog spark.sql.catalog.hive_prod.type = hive spark.sql.catalog.hive_prod.uri = thrift://hadoop101:9083spark.sql.catalog.hadoop_prod = org.apache.iceberg.spark.SparkCatalog
spark.sql.catalog.hadoop_prod.type = hadoopspark.sql.catalog.hadoop_prod.warehouse = hdfs://mycluster/spark/warehousespark.sql.catalog.catalog-name.type = hadoop spark.sql.catalog.catalog-name.default-namespace = db spark.sql.catalog.catalog-name.uri = thrift://hadoop101:9083
spark.sql.catalog.catalog-name.warehouse= hdfs://mycluster/spark/warehouse3.2 Spark sql 操作
- 正在上传…重新上传取消使用 spark sql 创建 iceberg 表,配置完毕后,会多出一个 hadoop_prod.db 数据库,但是注意这个数据库通过 show tables 是看不到的
[root@hadoop103 ~]# spark-sql
spark-sql (default)> use hadoop_prod.db; create table testA(
id bigint, name string, age int,
dt string) USING iceberg
PARTITIONED by(dt);2.插入数据
spark-sql (default)> insert into testA values(1,'张三',18,'2021-06-21');3.查询
spark-sql (default)> select *from testA;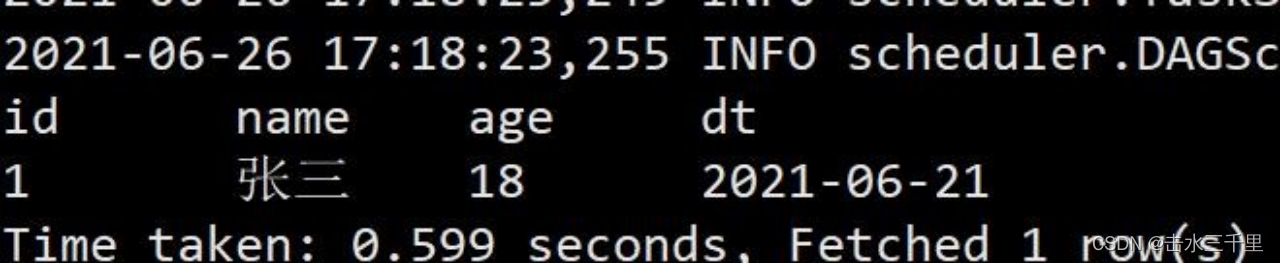
3.2.1over write 操作
(1)覆盖操作与 hive 一样,会将原始数据重新刷新
spark-sql (default)> insert overwrite testA values(2,'李四',20,'2021-06-21');
spark-sql (default)> select *from testA;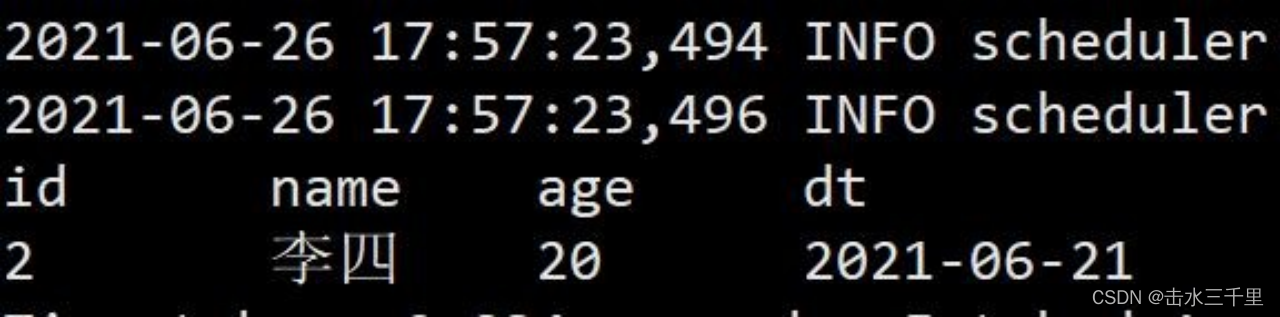
3.2.2动态覆盖
1.Spark 的默认覆盖模式是静态的,但在写入 iceberg 时建议使用动态覆盖模式。静态覆盖模式需要制定分区列,动态覆盖模式不需要。
spark-sql (default)> insert overwrite testA values(2,'李四',20,'2021-06-21');
spark-sql (default)> select *from testA;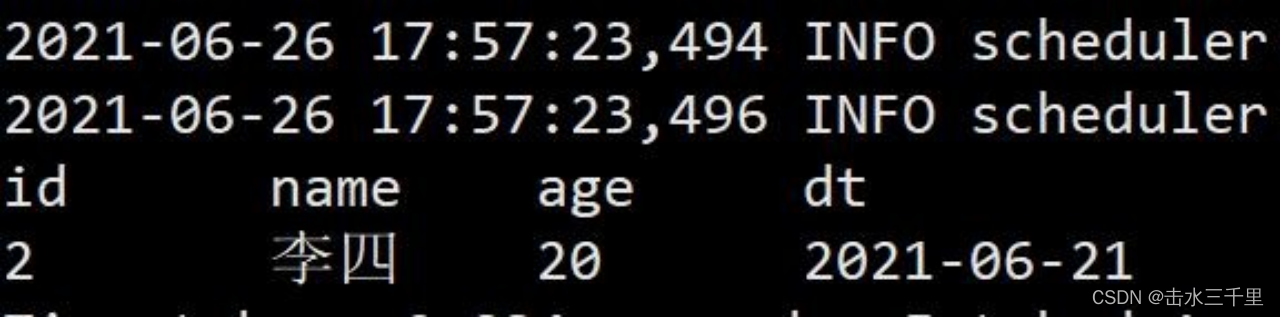
2.设置动态覆盖模式,修改 spark-default.conf,添加对应参数
[root@hadoop103 conf]# vim spark-defaults.conf
spark.sql.sources.partitionOverwriteMode=dynamic3.创建一张表结构与 testA 完全一致的表 testB
create table hadoop_prod.db.testB( id bigint,
name string, age int,
dt string) USING iceberg
PARTITIONED by(dt);4.向 testA 表中再插入一条数据
spark-sql (default)> use hadoop_prod.db;spark-sql (default)> insert into testA values(1,'张三',18,'2021-06-22');5.查询 testA 表,此时 testA 表中有两条记录
spark-sql (default)> select *from testA;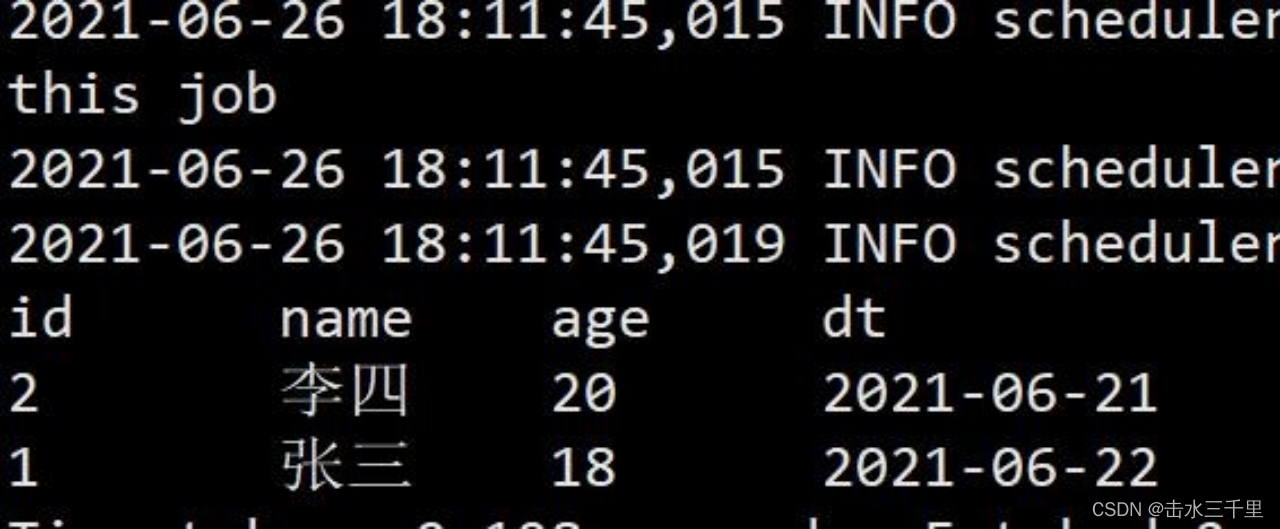
6.通过动态覆盖模式将 A 表插入到 B 表中
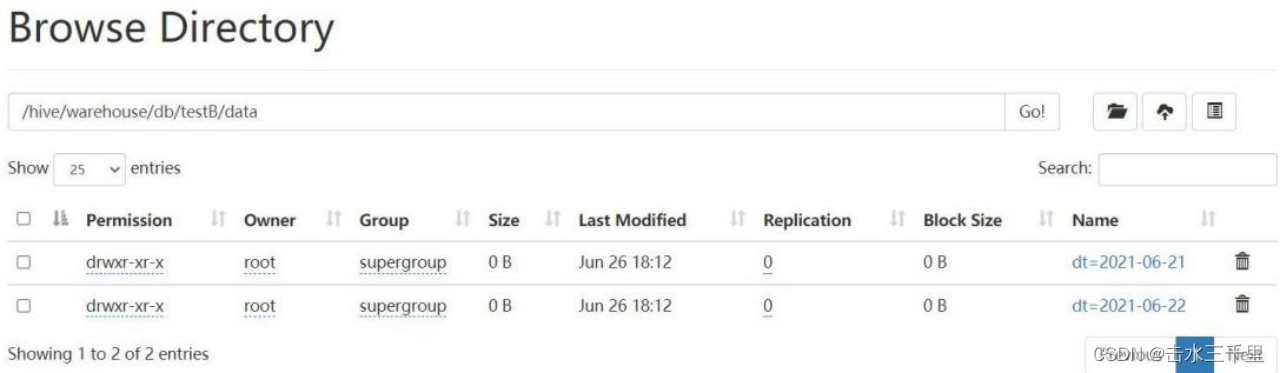
spark-sql (default)> insert overwrite testB select *from testA;7.查询 testB 表,可以看到效果与 hive 中的动态分区一样,自动根据列的顺序进行匹配插入,无须手动指定分区。
spark-sql (default)> select *from testB;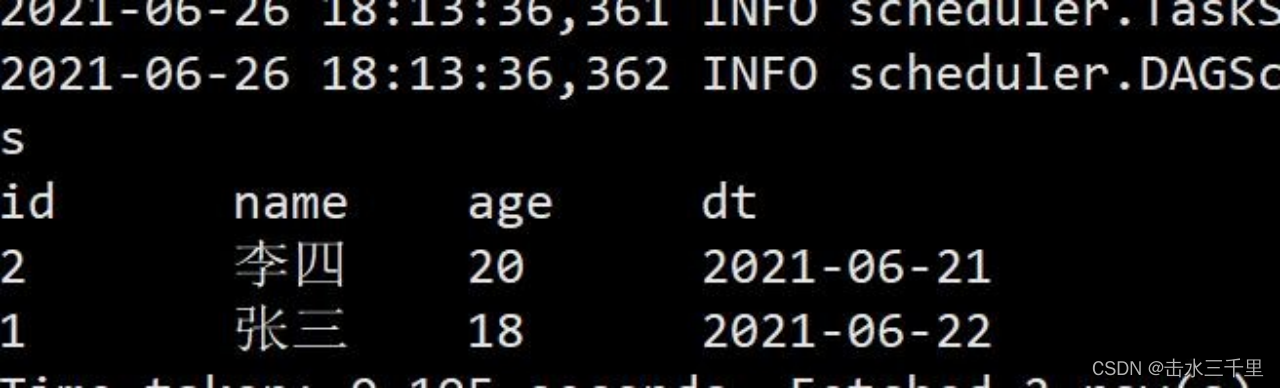
3.2.3静态覆盖
1.静态覆盖,则跟 hive 插入时手动指定分区一致,需要手动指定分区列的值
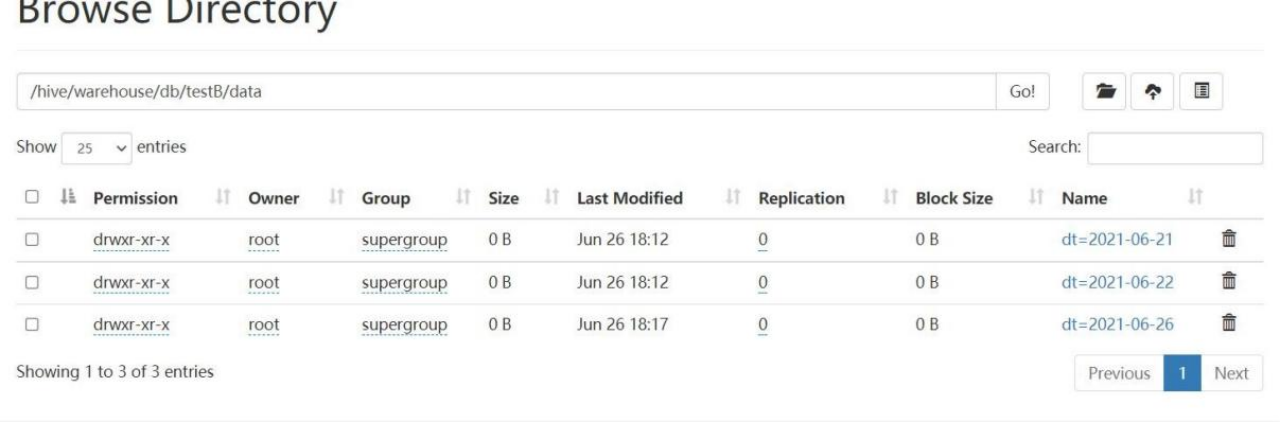
spark-sql (default)> insert overwrite testB Partition(dt='2021-06-26')
select id,name,age from testA;2.查询表数据
spark-sql (default)> select *from testB;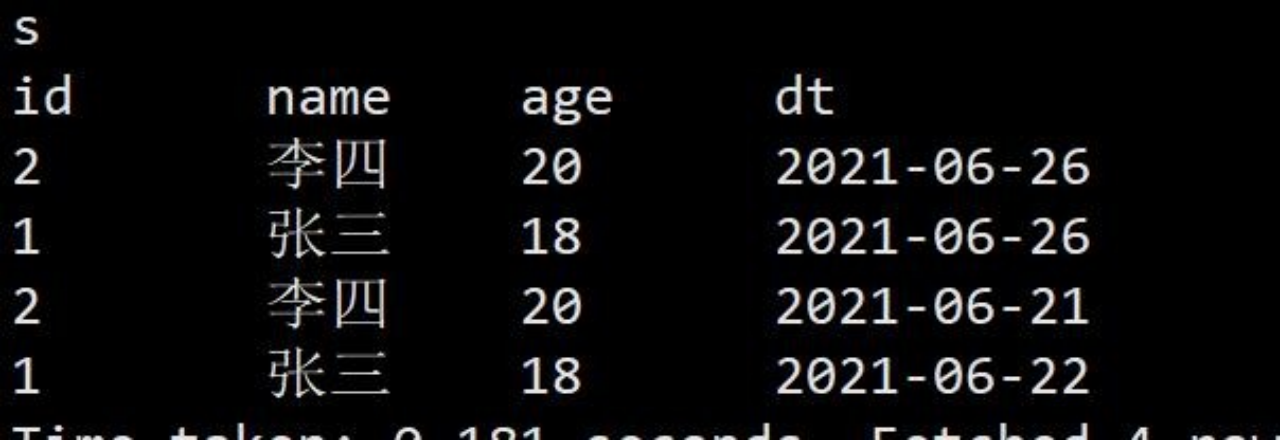
3.2.4删除数据
1.iceberg 并不会物理删除数据,下面演示 delete 操作,根据分区列进行删除 testB 表数据
spark-sql (default)> delete from testB where dt >='2021-06-21' and dt <='2021-06-26';2.提示删除成功,再次查询数据。发现表中已无数据,但是存在 hdfs 上的物理并没有实际删除

3.查看 hdfs 数据,仍然存在。
3.2.5历史快照
1.每张表都拥有一张历史表,历史表的表名为当前表加上后缀.history,注意:查询历史表的时候必须是表的全称,不可用先切到 hadoop.db 库中再查 testB
spark-sql (default)> select *from hadoop_prod.db.testB.history;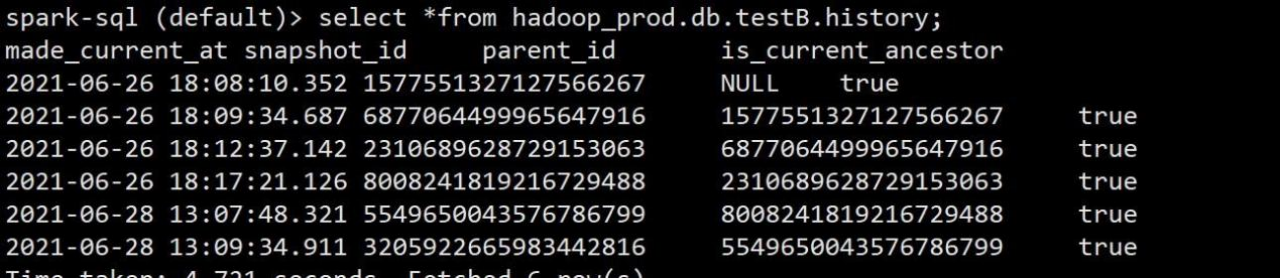
2.可以查看到每次操作后的对应的快照记录,也可以查询对应快照表,快照表的表名在 原表基础上加上.snapshots,也是一样必须是表的全称不能简写
spark-sql (default)> select *from hadoop_prod.db.testB.snapshots;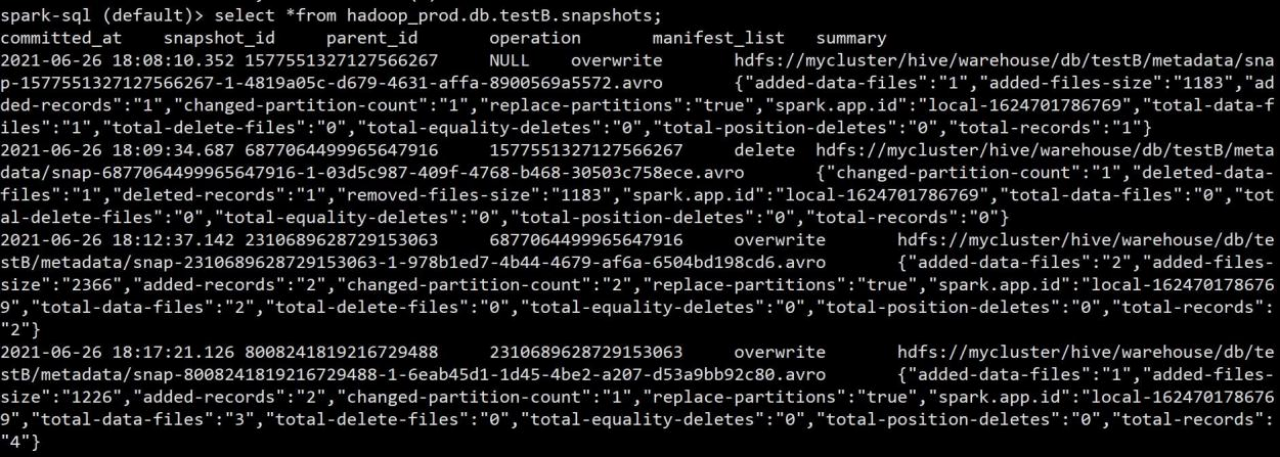
3.可以在看到 commit 的时间,snapshot 快照的 id,parent_id 父节点,operation 操作类型, 已经 summary 概要,summary 概要字段中可以看到数据量大小,总条数,路径等信息。
两张表也可以根据 snapshot_id 快照 id 进行 join 关联查询。
spark-sql (default)> select *from hadoop_prod.db.testB.history a join hadoop_prod.db.testB.snapshots b on a.snapshot_id=b.snapshot_id ;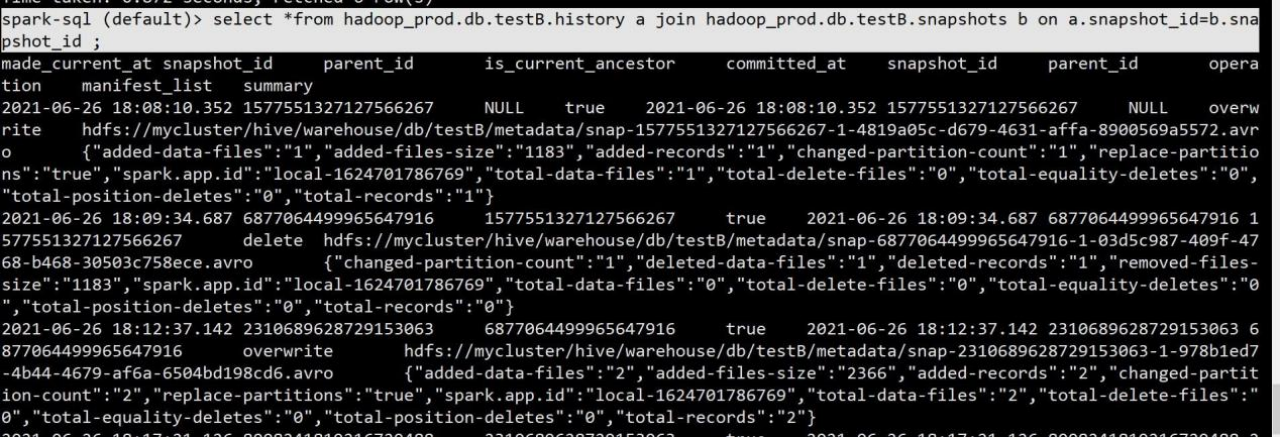
4.知道了快照表和快照信息后,可以根据快照 id 来查询具体的历史信息,发进行检测是否误操作,如果是误操作则可通过 spark 重新刷新数据。查询方式如下
scala>
spark.read.option("snapshot-id","5549650043576786799").format("iceberg").load("/hive/w arehouse/db/testB").show
3.2.6隐藏分区(有 bug 时区不对)
1.days 函数
1)上面演示了创建分区表, 接下来演示创建隐藏分区表。隐藏分区支持的函数有 years,months,days,hours,bucket,truncate。比如接下来创建一张 testC 表,表中有id,name 和 ts时间戳。
create table hadoop_prod.db.testC(
id bigint, name string, ts timestamp) using iceberg
partitioned by (days(ts));2)创建成功分别往里面插入不同天时间戳的数据
spark-sql (default)> insert into hadoop_prod.db.testC values(1,'张三',cast(1624773600 as timestamp)),(2,'李四',cast(1624860000 as timestamp));3)插入成功之后再来查询表数据。
spark-sql (default)> select *from hadoop_prod.db.testC;4)可以看到有两条数据,并且日期也不是同一天,查看 hdfs 上对应的分区。已经自动按天进行了分区。

2.years 函数
1)删除 testC 表,重新建表,字段还是不变,分区字段使用 years 函数
spark-sql (default)> drop table hadoop_prod.db.testC; create table hadoop_prod.db.testC(
id bigint, name string, ts timestamp) using iceberg
partitioned by (years(ts));2)同样,插入两条不同年时间戳的数据,进行查询对比
spark-sql (default)> insert into hadoop_prod.db.testC values(1,'张三',cast(1624860000 as timestamp)),(2,'李四',cast(1593324000 as timestamp));3)查询数据
spark-sql (default)> select *from hadoop_prod.db.testC;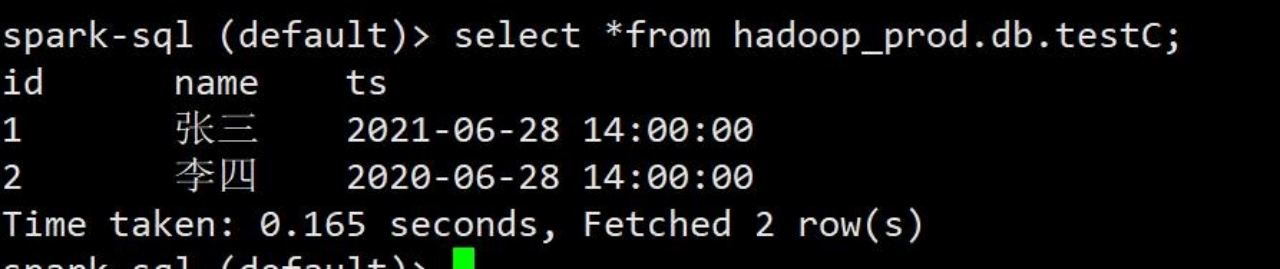
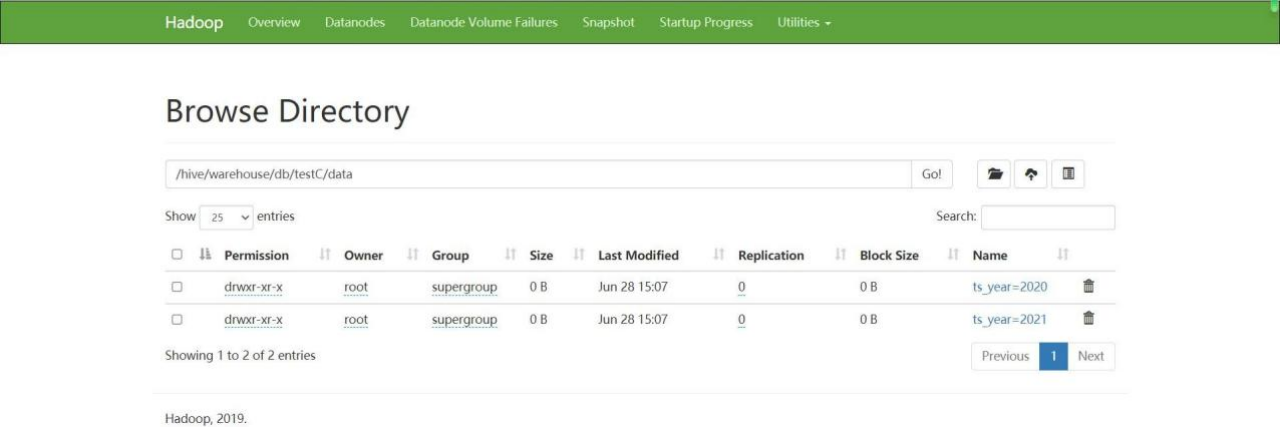
4)再查看 hdfs 对应的地址,已经按年建好分区
3.month 函数
1)删除 testC 表,重新建表,字段不变, 使用 month 函数进行分区
spark-sql (default)> drop table hadoop_prod.db.testC; create table hadoop_prod.db.testC(
id bigint, name string, ts timestamp) using iceberg
partitioned by (months(ts));2)同样,插入不同月份时间戳的两条记录
spark-sql (default)> insert into hadoop_prod.db.testC values(1,'张三',cast(1624860000 as timestamp)),(2,'李四',cast(1622181600 as timestamp));3)查询数据和 hdfs 对应地址
spark-sql (default)> select *from hadoop_prod.db.testC;4.hours 函数
1)删除 testC 表,重新建表,字段不变使用 hours 函数
spark-sql (default)> drop table hadoop_prod.db.testC; create table hadoop_prod.db.testC(
id bigint, name string, ts timestamp) using iceberg
partitioned by (hours(ts));2)插入两条不同小时的时间戳数据
spark-sql (default)> insert into hadoop_prod.db.testC values(1,'张三',cast(1622181600 as timestamp)),(2,'李四',cast(1622178000 as timestamp));3)查询数据和 hdfs 地址
发现时区不对,修改对应参数
- 再次启动 spark sql 插入数据
- 查看 hdfs 路径,还是错误分区目录(bug)
-
-
-
- bucket 函数(有 bug)
-
-
- 正在上传…重新上传取消正在上传…重新上传取消正在上传…重新上传取消删除 testC 表,重新创建,表字段不变,使用 bucket 函数。分桶 hash 算法采用 Murmur3 hash,官网介绍 https://iceberg.apache.org/spec/#partition-transforms
- 插入一批测试数据,为什么分多批插入,有 bug:如果一批数据中有数据被分到同一个桶里会报错
(1002,'张 10',cast(1622152800 as timestamp)),(1004,'李 10',cast(1622178000 as timestamp));
- 查看表数据和 hdfs 路径
spark-sql (default)> select *from hadoop_prod.db.testC;
-
-
-
- truncate 函数
-
-
- 删除表,重新建表,字段不变,使用 truncate 函数,截取长度来进行分区
- 插入一批测试数据
正在上传…重新上传取消正在上传…重新上传取消正在上传…重新上传取消
正在上传…重新上传取消正在上传…重新上传取消正在上传…重新上传取消
- 查询表数据和 hdfs 地址,分区目录为 id 数/4 得到的值(计算方式是 /不是%)。
spark-sql (default)> select *from hadoop_prod.db.testC;
第 4 章 DataFrame 操作
-
- 配置 Resources
(1)将自己 hadoop 集群的客户端配置文件复制到 resource 下,方便 local 模式调试
-
- 配置 pom.xml
(1)配置相关依赖
-
- 读取表
-
- 读取快照
-
- 写入表
-
-
- 写入数据并创建表
-
- 编写代码执行
- 验证,进入 spark sql 窗口,查看表结构和表数据
spark-sql (default)> desc test1;
spark-sql (default)> select *from test1;
查看 hdfs,是否按 dt 进行分区
-
-
- 写数据
-
-
-
-
- Append
-
-
编写代码,执行
- 执行完毕后进行测试,注意:小 bug,执行完代码后,如果 spark sql 黑窗口不重新打开是不会刷新数据的,只有把 spark sql 窗口界面重新打开才会刷新数据。如果使用代码查询能看到最新数据
- 关闭,再次进入查询,可以查询到数据
-
-
-
- OverWrite
-
-
编写代码,测试
查询
- 显示,手动指定覆盖分区
- 查询,2021-06-30 分区的数据已经被覆盖走
-
- 模拟数仓
-
-
- 表模型
-
(1)表模型,底下 6 张基础表,合成一张宽表,再基于宽表统计指标
-
-
- 建表语句
-
(1)建表语句
建表语句.txt
-
-
- 测试数据
-
(1)测试数据上传到 hadoop,作为第一层 ods
-
-
- 编写代码
-
-
-
-
- dwd 层
-
-
- 创建目录,划分层级
- 编写所需实体类
- 编写 DwdIcebergService
package com.atguigu.iceberg.warehouse.service
import java.sql.Timestamp import java.time.LocalDate
import java.time.format.DateTimeFormatter
import com.atguigu.iceberg.warehouse.bean.{BaseWebsite, MemberRegType, VipLevel} import org.apache.spark.sql.SparkSession
object DwdIcebergService {
def readOdsData(sparkSession: SparkSession) = { import org.apache.spark.sql.functions._ import sparkSession.implicits._ sparkSession.read.json("/ods/baseadlog.log")
.withColumn("adid", col("adid").cast("Int"))
.writeTo("hadoop_prod.db.dwd_base_ad").overwritePartitions()
sparkSession.read.json("/ods/baswewebsite.log").map(item => { val createtime = item.getAs[String]("createtime")
val str = LocalDate.parse(createtime, DateTimeFormatter.ofPattern("yyyy-MM-dd")).atStartOfDay().
format(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss")) BaseWebsite(item.getAs[String]("siteid").toInt, item.getAs[String]("sitename"),
item.getAs[String]("siteurl"), item.getAs[String]("delete").toInt, Timestamp.valueOf(str), item.getAs[String]("creator"), item.getAs[String]("dn"))
}).writeTo("hadoop_prod.db.dwd_base_website").overwritePartitions()
sparkSession.read.json("/ods/member.log").drop("dn")
.withColumn("uid", col("uid").cast("int"))
.withColumn("ad_id", col("ad_id").cast("int"))
.writeTo("hadoop_prod.db.dwd_member").overwritePartitions()
sparkSession.read.json("/ods/memberRegtype.log").drop("domain").drop("dn")
.withColumn("regsourcename", col("regsource"))
.map(item => {
val createtime = item.getAs[String]("createtime")
val str = LocalDate.parse(createtime, DateTimeFormatter.ofPattern("yyyy-MM-dd")).atStartOfDay().
format(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss")) MemberRegType(item.getAs[String]("uid").toInt, item.getAs[String]("appkey"),
item.getAs[String]("appregurl"), item.getAs[String]("bdp_uuid"), Timestamp.valueOf(str), item.getAs[String]("isranreg"), item.getAs[String]("regsource"), item.getAs[String]("regsourcename"), item.getAs[String]("websiteid").toInt, item.getAs[String]("dt"))
}).writeTo("hadoop_prod.db.dwd_member_regtype").overwritePartitions()
sparkSession.read.json("/ods/pcenterMemViplevel.log").drop("discountval")
.map(item => {
val startTime = item.getAs[String]("start_time") val endTime = item.getAs[String]("end_time")
val last_modify_time = item.getAs[String]("last_modify_time")
val startTimeStr = LocalDate.parse(startTime, DateTimeFormatter.ofPattern("yyyy-MM-dd")).atStartOfDay().
format(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"))
val endTimeStr = LocalDate.parse(endTime, DateTimeFormatter.ofPattern("yyyy-MM-dd")).atStartOfDay().
format(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"))
val last_modify_timeStr = LocalDate.parse(last_modify_time, DateTimeFormatter.ofPattern("yyyy-MM-dd")).atStartOfDay().
format(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss")) VipLevel(item.getAs[String]("vip_id").toInt, item.getAs[String]("vip_level"),
Timestamp.valueOf(startTimeStr), Timestamp.valueOf(endTimeStr), Timestamp.valueOf(last_modify_timeStr),
item.getAs[String]("max_free"), item.getAs[String]("min_free"), item.getAs[String]("next_level"), item.getAs[String]("operator"), item.getAs[String]("dn"))
}).writeTo("hadoop_prod.db.dwd_vip_level").overwritePartitions()
sparkSession.read.json("/ods/pcentermempaymoney.log")
.withColumn("uid", col("uid").cast("int"))
.withColumn("siteid", col("siteid").cast("int"))
.withColumn("vip_id", col("vip_id").cast("int"))
.writeTo("hadoop_prod.db.dwd_pcentermempaymoney").overwritePartitions()
}
}
| 转存失败重新上传取消正在上传…重新上传取消正在上传…重新上传取消 |
编写 DwdIcebergController
-
-
-
- dws 层(表指定多个分区列会有 bug)
-
-
创建 case class
- 创建 DwdIcebergDao 操作六张基础表
编写 DwsIcebergService,处理业务
package com.atguigu.iceberg.warehouse.service
import java.sql.Timestamp import java.time.LocalDateTime
import java.time.format.DateTimeFormatter
import com.atguigu.iceberg.warehouse.bean.{DwsMember, DwsMember_Result} import com.atguigu.iceberg.warehouse.dao.DwDIcebergDao
import org.apache.spark.sql.SparkSession
object DwsIcebergService {
def getDwsMemberData(sparkSession: SparkSession, dt: String) = { import sparkSession.implicits._
val dwdPcentermempaymoney = DwDIcebergDao.getDwdPcentermempaymoney(sparkSession).where($"dt" === dt)
val dwdVipLevel = DwDIcebergDao.getDwdVipLevel(sparkSession)
val dwdMember = DwDIcebergDao.getDwdMember(sparkSession).where($"dt" === dt) val dwdBaseWebsite = DwDIcebergDao.getDwdBaseWebsite(sparkSession)
val dwdMemberRegtype = DwDIcebergDao.getDwdMemberRegtyp(sparkSession).where($"dt" ===
dt)
val dwdBaseAd = DwDIcebergDao.getDwdBaseAd(sparkSession)
val result = dwdMember.join(dwdMemberRegtype.drop("dt"), Seq("uid"), "left")
.join(dwdPcentermempaymoney.drop("dt"), Seq("uid"), "left")
.join(dwdBaseAd, Seq("ad_id", "dn"), "left")
.join(dwdBaseWebsite, Seq("siteid", "dn"), "left")
.join(dwdVipLevel, Seq("vip_id", "dn"), "left_outer")
.select("uid", "ad_id", "fullname", "iconurl", "lastlogin", "mailaddr", "memberlevel",
"password"
, "paymoney", "phone", "qq", "register", "regupdatetime", "unitname", "userip", "zipcode", "appkey"
, "appregurl", "bdp_uuid", "reg_createtime", "isranreg", "regsource", "regsourcename", "adname"
, "siteid", "sitename", "siteurl", "site_delete", "site_createtime", "site_creator", "vip_id", "vip_level",
"vip_start_time", "vip_end_time", "vip_last_modify_time", "vip_max_free", "vip_min_free", "vip_next_level"
, "vip_operator", "dt", "dn").as[DwsMember]
val resultData = result.groupByKey(item => item.uid + "_" + item.dn)
.mapGroups { case (key, iters) => val keys = key.split("_")
val uid = Integer.parseInt(keys(0)) val dn = keys(1)
| val dwsMembers = iters.toList val paymoney = dwsMembers.filter(_.paymoney != | ||
| null).map(item=>BigDecimal.apply(item.paymoney)).reduceOption(_ | + | |
| _).getOrElse(BigDecimal.apply(0.00)).toString | ||
| val ad_id = dwsMembers.map(_.ad_id).head | ||
| val fullname = dwsMembers.map(_.fullname).head | ||
| val icounurl = dwsMembers.map(_.iconurl).head | ||
| val lastlogin = dwsMembers.map(_.lastlogin).head | ||
| val mailaddr = dwsMembers.map(_.mailaddr).head | ||
| val memberlevel = dwsMembers.map(_.memberlevel).head | ||
| val password = dwsMembers.map(_.password).head | ||
| val phone = dwsMembers.map(_.phone).head | ||
| val qq = dwsMembers.map(_.qq).head | ||
| val register = dwsMembers.map(_.register).head | ||
| val regupdatetime = dwsMembers.map(_.regupdatetime).head | ||
| val unitname = dwsMembers.map(_.unitname).head | ||
| val userip = dwsMembers.map(_.userip).head | ||
| val zipcode = dwsMembers.map(_.zipcode).head | ||
| val appkey = dwsMembers.map(_.appkey).head | ||
| val appregurl = dwsMembers.map(_.appregurl).head | ||
| val bdp_uuid = dwsMembers.map(_.bdp_uuid).head | ||
| val reg_createtime = if (dwsMembers.map(_.reg_createtime).head | != | null) |
| dwsMembers.map(_.reg_createtime).head else "1970-01-01 00:00:00" val isranreg = dwsMembers.map(_.isranreg).head val regsource = dwsMembers.map(_.regsource).head val regsourcename = dwsMembers.map(_.regsourcename).head val adname = dwsMembers.map(_.adname).head val siteid = if (dwsMembers.map(_.siteid).head != null) dwsMembers.map(_.siteid).head else "0" val sitename = dwsMembers.map(_.sitename).head val siteurl = dwsMembers.map(_.siteurl).head val site_delete = dwsMembers.map(_.site_delete).head val site_createtime = dwsMembers.map(_.site_createtime).head val site_creator = dwsMembers.map(_.site_creator).head val vip_id = if (dwsMembers.map(_.vip_id).head != null) dwsMembers.map(_.vip_id).head else "0" val vip_level = dwsMembers.map(_.vip_level).max val vip_start_time = if (dwsMembers.map(_.vip_start_time).min != null) dwsMembers.map(_.vip_start_time).min else "1970-01-01 00:00:00" val vip_end_time = if (dwsMembers.map(_.vip_end_time).max != null) dwsMembers.map(_.vip_end_time).max else "1970-01-01 00:00:00" val vip_last_modify_time = if (dwsMembers.map(_.vip_last_modify_time).max != null) dwsMembers.map(_.vip_last_modify_time).max else "1970-01-01 00:00:00" val vip_max_free = dwsMembers.map(_.vip_max_free).head val vip_min_free = dwsMembers.map(_.vip_min_free).head val vip_next_level = dwsMembers.map(_.vip_next_level).head val vip_operator = dwsMembers.map(_.vip_operator).head val formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss") val reg_createtimeStr = LocalDateTime.parse(reg_createtime, formatter); val vip_start_timeStr = LocalDateTime.parse(vip_start_time, formatter) val vip_end_timeStr = LocalDateTime.parse(vip_end_time, formatter) val vip_last_modify_timeStr = LocalDateTime.parse(vip_last_modify_time, formatter) DwsMember_Result(uid, ad_id, fullname, icounurl, lastlogin, mailaddr, memberlevel, password, paymoney, phone, qq, register, regupdatetime, unitname, userip, zipcode, appkey, appregurl, bdp_uuid, Timestamp.valueOf(reg_createtimeStr), isranreg, regsource, regsourcename, adname, siteid.toInt, sitename, siteurl, site_delete, site_createtime, site_creator, vip_id.toInt, vip_level, Timestamp.valueOf(vip_start_timeStr), Timestamp.valueOf(vip_end_timeStr), Timestamp.valueOf(vip_last_modify_timeStr), vip_max_free, vip_min_free, vip_next_level, vip_operator, dt, dn) | ||
编写 DwsIcebergController,进行运行测试
- 发生报错,和上面在 spark sql 黑窗口测试的错误一致,当有批量数据插入分区时提示分区已关闭无法插入
重新建表,分区列去掉 dn,只用 dt,bug:不能指定多个分区,只能指定一个分区列
- 建完表后,重新测试,插入数据成功
-
-
-
- ads 层
-
-
- 编写所需 case class
- 编写 DwsIcebergDao,查询宽表
编写 AdsIcebergService,统计指标
package com.atguigu.iceberg.warehouse.service
import com.atguigu.iceberg.warehouse.bean.QueryResult import com.atguigu.iceberg.warehouse.dao.DwsIcebergDao import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.{SaveMode, SparkSession}
object AdsIcebergService {
def queryDetails(sparkSession: SparkSession, dt: String) = { import sparkSession.implicits._
val result = DwsIcebergDao.queryDwsMemberData(sparkSession).as[QueryResult].where(s"dt='${dt}'")
result.cache()
//统计根据 url 统计人数 wordcount result.mapPartitions(partition => {
partition.map(item => (item.appregurl + "_" + item.dn + "_" + item.dt, 1))
}).groupByKey(_._1)
.mapValues(item => item._2).reduceGroups(_ + _)
.map(item => {
val keys = item._1.split("_") val appregurl = keys(0)
val dn = keys(1) val dt = keys(2)
(appregurl, item._2, dt, dn)
}).toDF("appregurl", "num", "dt", "dn").writeTo("hadoop_prod.db.ads_register_appregurlnum").overwritePartitions()
//统计各 memberlevel 等级 支付金额前三的用户import org.apache.spark.sql.functions._ result.withColumn("rownum",
row_number().over(Window.partitionBy("memberlevel").orderBy(desc("paymoney"))))
.where("rownum<4").orderBy("memberlevel", "rownum")
编写 AdsIcebergController,进行本地测试
- 查询,验证结果
-
-
- yarn 测试
-
- local 模式测试完毕后,将代码打成 jar 包,提交到集群上进行测试,那么插入模式当前都是为 overwrite 模式,所以在 yarn 上测试的时候也无需删除历史数据
- 打 jar 包之前,注意将代码中 setMast(local[*]) 注释了,把集群上有的依赖也可用
<scope>provided</scope>剔除了打一个瘦包
- 打成 jar 包提交到集群,运行 spark-submit 命令运行 yarn 模式。
第 5 章 Structured Streaming 操作
5.1 基于 Structured Streaming 落明细数据
-
- 创建测试 topic
- 启动 kafka,创建测试用的 topic
- 导入依赖
编写 producer 往 topic 里发送测试数据
-
- 创建测试表
partitioned by(days(ts));
-
- 编写代码
基于 test1 的测试数据,编写结构化流代码,进行测试
package com.atguigu.iceberg.spark.structuredstreaming
import java.sql.Timestamp
import org.apache.spark.SparkConf
import org.apache.spark.sql.{Dataset, SparkSession}
object TestTopicOperators {
def main(args: Array[String]): Unit = { val sparkConf = new SparkConf()
.set("spark.sql.catalog.hadoop_prod", "org.apache.iceberg.spark.SparkCatalog")
.set("spark.sql.catalog.hadoop_prod.type", "hadoop")
.set("spark.sql.catalog.hadoop_prod.warehouse", "hdfs://mycluster/hive/warehouse")
.set("spark.sql.catalog.catalog-name.type", "hadoop")
.set("spark.sql.catalog.catalog-name.default-namespace", "default")
.set("spark.sql.sources.partitionOverwriteMode", "dynamic")
.set("spark.sql.session.timeZone", "GMT+8")
.set("spark.sql.shuffle.partitions", "12")
//.setMaster("local[*]")
.setAppName("test_topic")
val sparkSession = SparkSession.builder().config(sparkConf).getOrCreate() val df = sparkSession.readStream.format("kafka")
.option("kafka.bootstrap.servers", "hadoop101:9092,hadoop102:9092,hadoop103:9092")
.option("subscribe", "test1")
.option("startingOffsets", "earliest")
.option("maxOffsetsPerTrigger", "10000")
.load()
import sparkSession.implicits._
val query = df.selectExpr("cast (value as string)").as[String]
.map(item => {
val array = item.split("\t") val uid = array(0)
val courseid = array(1) val deviceid = array(2) val ts = array(3)
Test1(uid.toLong, courseid.toInt, deviceid.toInt, new Timestamp(ts.toLong))
}).writeStream.foreachBatch { (batchDF: Dataset[Test1], batchid: Long) => batchDF.writeTo("hadoop_prod.db.test_topic").overwritePartitions()
}.option("checkpointLocation", "/ss/checkpoint")
.start() query.awaitTermination()
}
case class Test1(uid: BigInt,
courseid: Int, deviceid: Int, ts: Timestamp)
}
-
- 提交 yarn 测试速度
- 打成 jar 包,上传到集群,运行代码跑 yarn 模式 让 vcore 个数和 shuffle 分区数保持
1:1 最高效运行
- 运行起来后,查看 Spark Web UI 界面监控速度。趋于稳定后,可以看到速度能到每秒10200,条左右,已经达到了我参数所设置的上限。当然分区数(kafka 分区和 shuffle 分区) 和 vcore 越多实时性也会越高目前测试是 12 分区。
- 实时性没问题,但是有一个缺点,没有像 hudi 一样解决小文件问题。解决过多文件数可以更改 trigger 触发时间,但也会影响实时效率,两者中和考虑使用。
- 最后是花了 18 分钟跑完 1000 万条数据,查询表数据观察是否有数据丢失。数据没有丢失。
第 6 章存在的问题和缺点
-
- 问题
- 时区无法设置
- Spark Sql 黑窗口,缓存无法更新,修改表数据后,得需要关了黑窗口再重新打开,查询才是更新后的数据
- 表分区如果指定多个分区或分桶,那么插入批量数据时,如果这一批数据有多条数据在同一个分区会报错
-
- 缺点
- 与 hudi 相比,没有解决小文件问题
- 与 hudi 相比,缺少行级更新,只能对表的数据按分区进行 overwrite 全量覆盖
第 7 章 Flink 操作
-
- 配置参数和 jar 包
- Flink1.11 开始就不在提供 flink-shaded-hadoop-2-uber 的支持,所以如果需要 flink 支持
hadoop 得配置环境变量 HADOOP_CLASSPATH
- 目前 Iceberg 只支持 flink1.11.x 的版本,所以我这使用 flink1.11.0,将构建好的 Iceberg
的 jar 包复制到 flink 下
-
- Flink SQL Client
在 hadoop 环境下,启动一个单独的 flink 集群
- 启动 flin sql client
-
- 使用 Catalogs 创建目录
- ) flink 可以通过 sql client 来创建 catalogs 目录, 支持的方式有 hive catalog,hadoop catalog,custom catlog。我这里采用 hadoop catlog。
使用当前 catalog
- 创建 sql-client-defaults.yaml,方便以后启动 flink-sql 客户端,走 iceberg 目录
-
- Flink Sql 操作
-
-
- 建库
-
- 再次启动 Flink Sql 客户端
- 可以使用默认数据库,也可以创建数据库
使用 iceberg 数据库
-
-
- 建表(flink 不支持隐藏分区)
-
(1)建表,我这里直接创建分区表了,使用 flink 对接 iceberg 不能使用 iceberg 的隐藏分区这一特性,目前还不支持。
-
-
- like 建表
-
-
-
- insert into
-
使用 insert into 插入数据
-
-
- 查询
-
-
-
- 任务监控
-
( 1 ) 可 查 看 hadoop103 默 认 端 口 8081 查 看 standlone 模 式 任 务 是 否 成 功
插入数据后,同样 hdfs 路径上也是有对应目录和数据块
-
-
- insert overwrite
-
使用 overwrite 插入
- flink 默认使用流的方式插入数据,这个时候流的插入是不支持 overwrite 操作的
- 需要将插入模式进行修改,改成批的插入方式,再次使用 overwrite 插入数据。如需要改回流式操作参数设置为 SET execution.type = streaming ;
- 查询结果,已经将结果根据分区进行覆盖操作
第 8 章 Flink API 操作
-
- 配置 pom.xml
(1)配置相关依赖
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-table-common -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-table-api-java -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!--
https://mvnrepository.com/artifact/org.apache.flink/flink-table-api-java-bridge -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-table-planner -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!--
https://mvnrepository.com/artifact/org.apache.flink/flink-table-planner-blink -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.iceberg</groupId>
<artifactId>iceberg-flink-runtime</artifactId>
<version>0.11.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
</dependencies>
</project>
-
- 读取表数据
-
-
- batch read
-
(1)通过 batch 的方式去读取数据
-
-
- streaming read
-
通过 streaming 的方式去读取数据
- 启动之后程序不会立马停止
- 因为是流处理,这个时候手动往表中追加一条数据
Flink SQL> insert into iceberg.testA values(3,'哈哈哈',18,'2021-07-01');
- 可以看到控制台,实时打印出了数据
-
- 写数据
-
-
- Appending Data
-
使用上面 create table testB like testA 的 testB 表,读取 A 表数据插入到 B 表数据
采用的是 batch 批处理,代码执行两次并查询查看 append 效果
-
-
- Overwrite Data
-
- 编写代码,将 overwrite 设置为 true
- 查询 testB 表查看 overwrite 效果,根据分区将数据进行了覆盖操作
-
- 模拟数仓
-
-
- 建表语句
-
(1)还是根据上述 spark 表模型,进行建表。建表语句:
flink数仓建表语句.txt
-
-
- 编写代码
-
-
-
-
- dwd 层
-
-
- 同样,创建目录划分层级
- 添加 fastjson 依赖
编写 service 层,读取 ods 层数据插入到 iceberg 表中
public class DwdIcebergSerivce {
public void readOdsData(StreamExecutionEnvironment env) {
DataStream<String> baseadDS = env.readTextFile("hdfs://mycluster/ods/baseadlog.log");
DataStream<RowData> baseadInput = baseadDS.map(item -> { JSONObject jsonObject = JSONObject.parseObject(item); GenericRowData rowData = new GenericRowData(3); rowData.setField(0, jsonObject.getIntValue("adid"));
rowData.setField(1, StringData.fromString(jsonObject.getString("adname"))); rowData.setField(2, StringData.fromString(jsonObject.getString("dn"))); return rowData;
});
TableLoader dwdbaseadTable = TableLoader.fromHadoopTable("hdfs://mycluster/flink/warehouse/iceberg/dwd_base_ad");
FlinkSink.forRowData(baseadInput).tableLoader(dwdbaseadTable).overwrite(true).build();
DataStream<String> basewebsiteDS = env.readTextFile("hdfs://mycluster/ods/baswewebsite.log");
DataStream<RowData> basewebsiteInput = basewebsiteDS.map(item -> { JSONObject jsonObject = JSONObject.parseObject(item); GenericRowData rowData = new GenericRowData(7); rowData.setField(0, jsonObject.getIntValue("siteid"));
rowData.setField(1, StringData.fromString(jsonObject.getString("sitename"))); rowData.setField(2, StringData.fromString(jsonObject.getString("siteurl"))); rowData.setField(3, jsonObject.getIntValue("delete"));
LocalDateTime localDateTime = LocalDate.parse(jsonObject.getString("createtime"),
DateTimeFormatter.ofPattern("yyyy-MM-dd"))
.atStartOfDay();
rowData.setField(4, TimestampData.fromLocalDateTime(localDateTime)); rowData.setField(5, StringData.fromString(jsonObject.getString("creator"))); rowData.setField(6, StringData.fromString(jsonObject.getString("dn"))); return rowData;
});
TableLoader dwdbasewebsiteTable = TableLoader.fromHadoopTable("hdfs://mycluster/flink/warehouse/iceberg/dwd_base_website ");
FlinkSink.forRowData(basewebsiteInput).tableLoader(dwdbasewebsiteTable).overwrite(true)
.build();
DataStream<String> memberDS = env.readTextFile("hdfs://mycluster/ods/member.log"); DataStream<RowData> memberInput = memberDS.map(item -> {
JSONObject jsonObject = JSONObject.parseObject(item); GenericRowData rowData = new GenericRowData(19); rowData.setField(0, jsonObject.getIntValue("uid")); rowData.setField(1, jsonObject.getIntValue("ad_id"));
rowData.setField(2, StringData.fromString(jsonObject.getString("birthday"))); rowData.setField(3, StringData.fromString(jsonObject.getString("email"))); rowData.setField(4, StringData.fromString(jsonObject.getString("fullname"))); rowData.setField(5, StringData.fromString(jsonObject.getString("iconurl"))); rowData.setField(6, StringData.fromString(jsonObject.getString("lastlogin"))); rowData.setField(7, StringData.fromString(jsonObject.getString("mailaddr"))); rowData.setField(8,
StringData.fromString(jsonObject.getString("memberlevel")));
rowData.setField(9, StringData.fromString(jsonObject.getString("password"))); rowData.setField(10, StringData.fromString(jsonObject.getString("paymoney")));
rowData.setField(11, StringData.fromString(jsonObject.getString("phone"))); rowData.setField(12, StringData.fromString(jsonObject.getString("qq"))); rowData.setField(13, StringData.fromString(jsonObject.getString("register"))); rowData.setField(14,
StringData.fromString(jsonObject.getString("regupdatetime")));
rowData.setField(15, StringData.fromString(jsonObject.getString("unitname"))); rowData.setField(16, StringData.fromString(jsonObject.getString("userip"))); rowData.setField(17, StringData.fromString(jsonObject.getString("zipcode"))); rowData.setField(18, StringData.fromString(jsonObject.getString("dt"))); return rowData;
});
TableLoader dwdmemberTable = TableLoader.fromHadoopTable("hdfs://mycluster/flink/warehouse/iceberg/dwd_member");
FlinkSink.forRowData(memberInput).tableLoader(dwdmemberTable).overwrite(true).build();
DataStream<String> memberregtypDS = env.readTextFile("hdfs://mycluster/ods/memberRegtype.log");
DataStream<RowData> memberregtypInput = memberregtypDS.map(item -> { JSONObject jsonObject = JSONObject.parseObject(item); GenericRowData rowData = new GenericRowData(10); rowData.setField(0, jsonObject.getIntValue("uid"));
rowData.setField(1, StringData.fromString(jsonObject.getString("appkey"))); rowData.setField(2, StringData.fromString(jsonObject.getString("appregurl"))); rowData.setField(3, StringData.fromString(jsonObject.getString("bdp_uuid"))); LocalDateTime localDateTime =
LocalDate.parse(jsonObject.getString("createtime"), DateTimeFormatter.ofPattern("yyyy-MM-dd"))
.atStartOfDay();
rowData.setField(4, TimestampData.fromLocalDateTime(localDateTime)); rowData.setField(5, StringData.fromString(jsonObject.getString("isranreg"))); rowData.setField(6, StringData.fromString(jsonObject.getString("regsource"))); rowData.setField(7, StringData.fromString(jsonObject.getString("regsource"))); rowData.setField(8, jsonObject.getIntValue("websiteid"));
rowData.setField(9, StringData.fromString(jsonObject.getString("dt"))); return rowData;
});
TableLoader dwdmemberregtypeTable = TableLoader.fromHadoopTable("hdfs://mycluster/flink/warehouse/iceberg/dwd_member_regty pe");
FlinkSink.forRowData(memberregtypInput).tableLoader(dwdmemberregtypeTable).overwrite(t rue).build();
DataStream<String> memviplevelDS = env.readTextFile("hdfs://mycluster/ods/pcenterMemViplevel.log");
DataStream<RowData> memviplevelInput = memviplevelDS.map(item -> { JSONObject jsonObject = JSONObject.parseObject(item); GenericRowData rowData = new GenericRowData(10); rowData.setField(0, jsonObject.getIntValue("vip_id"));
rowData.setField(1, StringData.fromString(jsonObject.getString("vip_level"))); LocalDateTime start_timeDate =
LocalDate.parse(jsonObject.getString("start_time"), DateTimeFormatter.ofPattern("yyyy-MM-dd"))
.atStartOfDay();
LocalDateTime end_timeDate = LocalDate.parse(jsonObject.getString("end_time"), DateTimeFormatter.ofPattern("yyyy-MM-dd"))
.atStartOfDay();
LocalDateTime last_modify_timeDate = LocalDate.parse(jsonObject.getString("last_modify_time"), DateTimeFormatter.ofPattern("yyyy-MM-dd"))
.atStartOfDay();
rowData.setField(2, TimestampData.fromLocalDateTime(start_timeDate)); rowData.setField(3, TimestampData.fromLocalDateTime(end_timeDate)); rowData.setField(4, TimestampData.fromLocalDateTime(last_modify_timeDate)); rowData.setField(5, StringData.fromString(jsonObject.getString("max_free"))); rowData.setField(6, StringData.fromString(jsonObject.getString("min_free"))); rowData.setField(7,
StringData.fromString(jsonObject.getString("next_level")));
rowData.setField(8, StringData.fromString(jsonObject.getString("operator"))); rowData.setField(9, StringData.fromString(jsonObject.getString("dn"))); return rowData;
});
TableLoader dwdviplevelTable = TableLoader.fromHadoopTable("hdfs://mycluster/flink/warehouse/iceberg/dwd_vip_level");
FlinkSink.forRowData(memviplevelInput).tableLoader(dwdviplevelTable).overwrite(true).b uild();
DataStream<String> mempaymoneyDS = env.readTextFile("hdfs://mycluster/ods/pcentermempaymoney.log");
DataStream<RowData> mempaymoneyInput = mempaymoneyDS.map(item -> { JSONObject jsonObject = JSONObject.parseObject(item); GenericRowData rowData = new GenericRowData(6); rowData.setField(0, jsonObject.getIntValue("uid"));
rowData.setField(1, StringData.fromString(jsonObject.getString("paymoney"))); rowData.setField(2, jsonObject.getIntValue("siteid"));
rowData.setField(3, jsonObject.getIntValue("vip_id")); rowData.setField(4, StringData.fromString(jsonObject.getString("dt"))); rowData.setField(5, StringData.fromString(jsonObject.getString("dn"))); return rowData;
});
TableLoader dwdmempaymoneyTable = TableLoader.fromHadoopTable("hdfs://mycluster/flink/warehouse/iceberg/dwd_pcentermempa ymoney");
FlinkSink.forRowData(mempaymoneyInput).tableLoader(dwdmempaymoneyTable).overwrite(true)
.build();
}
}
- 编写 dwd 层 controller
- local 模式执行,注意当一次性插入数据比较多是,flink sink 最后可能会提示 writer 关
闭失败,推测是 iceberg 并发写入的问题。
排查是否丢数据,查询插入中逻辑最后的表 count 个数,与原始日志数据的 count 个数做对比。
- 虽然发生 writer 关闭失败的错,但是数据并没有问题。
-
-
-
- dws 层
-
-
(1)编写 DwdIcebergDao,查询 dwd 层基础表数据
public Table getDwdPcentermempaymoney(StreamExecutionEnvironment env, StreamTableEnvironment tableEnv) {
TableLoader tableLoader = TableLoader.fromHadoopTable("hdfs://mycluster/flink/warehouse/iceberg/dwd_pcentermempa ymoney");
DataStream<RowData> result = FlinkSource.forRowData().env(env).tableLoader(tableLoader).streaming(false).build();
Table table = tableEnv.fromDataStream(result); return table;
}
public Table getDwdVipLevel(StreamExecutionEnvironment env, StreamTableEnvironment tableEnv) {
TableLoader tableLoader = TableLoader.fromHadoopTable("hdfs://mycluster/flink/warehouse/iceberg/dwd_vip_level");
DataStream<RowData> result = FlinkSource.forRowData().env(env).tableLoader(tableLoader).streaming(false).build();
Table table = tableEnv.fromDataStream(result).renameColumns($("start_time").as("vip_start_time"))
.renameColumns($("end_time").as("vip_end_time")).renameColumns($("last_mo dify_time").as("vip_last_modify_time"))
.renameColumns($("max_free").as("vip_max_free")).renameColumns($("min_fre e").as("vip_min_free"))
.renameColumns($("next_level").as("vip_next_level")).renameColumns($("ope rator").as("vip_operator"));
return table;
}
public Table getDwdBaseWebsite(StreamExecutionEnvironment env, StreamTableEnvironment tableEnv) {
TableLoader tableLoader = TableLoader.fromHadoopTable("hdfs://mycluster/flink/warehouse/iceberg/dwd_base_website ");
DataStream<RowData> result = FlinkSource.forRowData().env(env).tableLoader(tableLoader).streaming(false).build();
Table table = tableEnv.fromDataStream(result).renameColumns($("delete").as("site_delete"))
.renameColumns($("createtime").as("site_createtime")).renameColumns($("cr eator").as("site_creator"));
return table;
}
public Table getDwdMemberRegtyp(StreamExecutionEnvironment env, StreamTableEnvironment tableEnv) {
TableLoader tableLoader = TableLoader.fromHadoopTable("hdfs://mycluster/flink/warehouse/iceberg/dwd_member_regty pe");
DataStream<RowData> result = FlinkSource.forRowData().env(env).tableLoader(tableLoader).streaming(false).build();
Table table = tableEnv.fromDataStream(result).renameColumns($("createtime").as("reg_createtime"));
return table;
}
public Table getDwdBaseAd(StreamExecutionEnvironment env, StreamTableEnvironment tableEnv) {
TableLoader tableLoader = TableLoader.fromHadoopTable("hdfs://mycluster/flink/warehouse/iceberg/dwd_base_ad");
DataStream<RowData> result = FlinkSource.forRowData().env(env).tableLoader(tableLoader).streaming(false).build();
Table table = tableEnv.fromDataStream(result); return table;
- 编写 DwsIcebergService,进行 join 形成宽表
package com.atguigu.iceberg.warhouse.service;
import com.atguigu.iceberg.warhouse.dao.DwdIcebergDao; import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.table.api.DataTypes;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment; import org.apache.flink.table.data.RowData;
import org.apache.iceberg.flink.TableLoader; import org.apache.iceberg.flink.sink.FlinkSink;
import static org.apache.flink.table.api.Expressions.$;
public class DwsIcebergService { DwdIcebergDao dwdIcebergDao;
public void getDwsMemberData(StreamExecutionEnvironment env, StreamTableEnvironment tableEnv, String dt) {
dwdIcebergDao = new DwdIcebergDao();
Table dwdPcentermempaymoney = dwdIcebergDao.getDwdPcentermempaymoney(env, tableEnv).where($("dt").isEqual(dt));
Table dwdVipLevel = dwdIcebergDao.getDwdVipLevel(env, tableEnv);
Table dwdMember = dwdIcebergDao.getDwdMember(env, tableEnv).where($("dt").isEqual(dt));
Table dwdBaseWebsite = dwdIcebergDao.getDwdBaseWebsite(env, tableEnv);
Table dwdMemberRegtype = dwdIcebergDao.getDwdMemberRegtyp(env, tableEnv).where($("dt").isEqual(dt));
Table dwdBaseAd = dwdIcebergDao.getDwdBaseAd(env, tableEnv);
Table result = dwdMember.dropColumns($("paymoney")).leftOuterJoin(dwdMemberRegtype.renameColumns($("u id").as("reg_uid")).dropColumns($("dt")),
$("uid").isEqual($("reg_uid")))
.leftOuterJoin(dwdPcentermempaymoney.renameColumns($("uid").as("pcen_uid")
).dropColumns($("dt")),
$("uid").isEqual($("pcen_uid")))
.leftOuterJoin(dwdBaseAd.renameColumns($("dn").as("basead_dn")),
$("ad_id").isEqual($("adid")).and($("dn").isEqual($("basead_dn"))))
.leftOuterJoin(dwdBaseWebsite.renameColumns($("siteid").as("web_siteid")). renameColumns($("dn").as("web_dn")),
$("siteid").isEqual($("web_siteid")).and($("dn").isEqual("web_dn")))
.leftOuterJoin(dwdVipLevel.renameColumns($("vip_id").as("v_vip_id")).rena meColumns($("dn").as("vip_dn")),
$("vip_id").isEqual($("v_vip_id")).and($("dn").isEqual($("vip_dn"))))
.groupBy($("uid"))
.select($("uid"), $("ad_id").min(), $("fullname").min(),
$("iconurl").min(), $("lastlogin").min(), $("mailaddr").min(), $("memberlevel").min(),
$("password").min()
, $("paymoney").cast(DataTypes.DECIMAL(10, 4)).sum().cast(DataTypes.STRING()), $("phone").min(), $("qq").min(), $("register").min(),
$("regupdatetime").min(), $("unitname").min(), $("userip").min(), $("zipcode").min(),
$("appkey").min()
, $("appregurl").min(), $("bdp_uuid").min(),
$("reg_createtime").min().cast(DataTypes.STRING()), $("isranreg").min(),
- 编写 DwsIcebergController,调用 service
-
-
-
- ads 层
-
-
- 创建所需 bean
private BigDecimal paymoney; private String dt;
private String dn;
public Integer getUid() { return uid;
}
public void setUid(Integer uid) { this.uid = uid;
}
public Integer getAd_id() { return ad_id;
}
public void setAd_id(Integer ad_id) { this.ad_id = ad_id;
}
public String getMemberlevel() { return memberlevel;
}
public void setMemberlevel(String memberlevel) { this.memberlevel = memberlevel;
}
public String getRegister() { return register;
}
public void setRegister(String register) { this.register = register;
}
public String getAppregurl() { return appregurl;
}
public void setAppregurl(String appregurl) { this.appregurl = appregurl;
}
public String getRegsource() { return regsource;
}
public void setRegsource(String regsource) { this.regsource = regsource;
}
public String getRegsourcename() { return regsourcename;
}
public void setRegsourcename(String regsourcename) { this.regsourcename = regsourcename;
}
public String getAdname() { return adname;
创建 DwsIcbergDao 查询宽表统计字段
创建 AdsIcebergService 编写统计逻辑
package com.atguigu.iceberg.warhouse.service;
import com.atguigu.iceberg.warhouse.bean.QueryResult; import com.atguigu.iceberg.warhouse.dao.DwsIcbergDao; import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment; import org.apache.flink.table.data.RowData;
import org.apache.iceberg.flink.TableLoader; import org.apache.iceberg.flink.sink.FlinkSink;
import static org.apache.flink.table.api.Expressions.$;
public class AdsIcebergService {
DwsIcbergDao dwsIcbergDao = new DwsIcbergDao();
public void queryDetails(StreamExecutionEnvironment env, StreamTableEnvironment tableEnv, String dt) {
Table table = dwsIcbergDao.queryDwsMemberData(env, tableEnv).where($("dt").isEqual(dt));
DataStream<QueryResult> queryResultDataStream = tableEnv.toAppendStream(table, QueryResult.class);
tableEnv.createTemporaryView("tmpA", queryResultDataStream);
String sql = "select *from(select uid,memberlevel,register,appregurl" + ",regsourcename,adname,sitename,vip_level,cast(paymoney as
decimal(10,4)),row_number() over" +
- (partition by memberlevel order by cast(paymoney as decimal(10,4)) desc) as rownum,dn,dt from tmpA where dt='" + dt + "') " +
- where rownum<4 ";
Table table1 = tableEnv.sqlQuery(sql);
DataStream<RowData> top3DS = tableEnv.toRetractStream(table1, RowData.class).filter(item -> item.f0).map(item -> item.f1);
String sql2 = "select appregurl,count(uid),dn,dt from tmpA where dt='" + dt + "' group by appregurl,dn,dt";
Table table2 = tableEnv.sqlQuery(sql2);
DataStream<RowData> appregurlnumDS = tableEnv.toRetractStream(table2, RowData.class).filter(item -> item.f0).map(item -> item.f1);
TableLoader top3Table = TableLoader.fromHadoopTable("hdfs://mycluster/flink/warehouse/iceberg/ads_register_top 3memberpay");
TableLoader appregurlnumTable = TableLoader.fromHadoopTable("hdfs://mycluster/flink/warehouse/iceberg/ads_register_app
- 创建创建 AdsController 控制流程
-
- Flink Streaming 落明细数据
-
-
- 创建测试表
-
-
-
- 编写代码
-
添加依赖
- 编写 Flink Streaming 代码消费前面 test1 的数据,将数据写入 iceberg.test_topic 表中
import org.apache.flink.api.common.serialization.SimpleStringSchema; import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer010; import org.apache.flink.table.data.GenericRowData;
import org.apache.flink.table.data.RowData; import org.apache.flink.table.data.StringData; import org.apache.iceberg.flink.TableLoader; import org.apache.iceberg.flink.sink.FlinkSink;
import java.sql.Timestamp; import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter; import java.util.Properties;
public class TestTopic {
public static void main(String[] args) throws Exception { StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(1000l);
Properties properties = new Properties(); properties.setProperty("bootstrap.servers",
"hadoop101:9092,hadoop102:9092,hadoop103:9092"); properties.setProperty("group.id", "flink-test-group");
FlinkKafkaConsumer010<String> kafakSource = new FlinkKafkaConsumer010<>("test1", new SimpleStringSchema(), properties);
kafakSource.setStartFromEarliest();
DataStream<RowData> result = env.addSource(kafakSource).map(item -> { String[] array = item.split("\t");
Long uid = Long.parseLong(array[0]);
Integer courseid = Integer.parseInt(array[1]); Integer deviceid = Integer.parseInt(array[2]);
DateTimeFormatter df = DateTimeFormatter.ofPattern("yyyy-MM-dd"); LocalDateTime localDateTime = new
Timestamp(Long.parseLong(array[3])).toLocalDateTime(); String dt = df.format(localDateTime); GenericRowData rowData = new GenericRowData(4); rowData.setField(0, uid);
rowData.setField(1, courseid); rowData.setField(2, deviceid); rowData.setField(3, StringData.fromString(dt)); return rowData;
});
TableLoader testtopicTable = TableLoader.fromHadoopTable("hdfs://mycluster/flink/warehouse/iceberg/test_topic");
FlinkSink.forRowData(result).tableLoader(testtopicTable).overwrite(true).build(); result.print();
env.execute();
}
}
第 9 章 Flink 存在的问题
- Flink 不支持 Iceberg 隐藏分区
- 不支持通过计算列创建表
- 不支持创建带水位线的表
- 不支持添加列、删除列、重命名列
相关文章:
Iceberg实战踩坑指南
第 1 章 介绍 Apache Iceberg 是一种用于大型分析数据集的开放表格,Iceberge 向 Trino 和 Spark 添加了使用高性能格式的表,就像 Sql 表一样。 Iceberg 为了避免出现不变要的一些意外,表结构和组织并不会实际删除,用户也不需要特…...

预告|2月25日 第四届OpenI/O 启智开发者大会昇腾人工智能应用专场邀您共启数字未来!
如今,人工智能早已脱离科幻小说中的虚构想象,成为可触及的现实,并渗透到我们的生活。随着人工智能的发展,我们正在迎来一个全新的时代——数智化时代。数据、信息和知识是这个时代的核心资源,而人工智能则是这些资源的…...
UnRaid虚拟机安装OpenWrt软路由
文章目录0、前言1、Openwrt虚拟机安装1.1、前提,需要先在UnRaid中开启虚拟机:1.2、下载OpenWrt虚拟机镜像并上传至UnRaid共享文件夹1.3、创建OpenWrt虚拟机2、开启并设置OpenWrt虚拟机2.1、修改OpenWrt管理ip2.2、OpenWrt的上网设置0、前言 最近折腾了很…...
开发日记-lombok
开发日记-lombok环境问题解决方案:1 Data注解失效 无法正常生成 get和set方法2 RequiredArgsConstructor(onConstructor _(Lazy)) 符号_无法识别环境 idea2020.1lombok1.18.24jdk1.8 问题 Data注解失效 无法正常生成 get和set方法RequiredArgsConstructor(onCons…...

Web3中文|2023年zk赛道爆发,即将推出的Polygon zkEVM有多重要?
2月15日,以太坊第2层解决方案提供商Polygon终于公布了备受期待的扩展更新,其零知识以太坊虚拟机(zkEVM)主网的测试版定于3月27日发布。 据官方消息报道,自去年10月上线测试网以来,已取得许多重要的里程碑&…...
【自然语言处理】主题建模:Top2Vec(理论篇)
主题建模:Top2Vec(理论篇)Top2Vec 是一种用于 主题建模 和 语义搜索 的算法。它自动检测文本中出现的主题,并生成联合嵌入的主题、文档和词向量。 算法基于的假设:许多语义相似的文档都可以由一个潜在的主题表示。首先…...

【ICLR 2022】重新思考点云中的网络设计和局部几何:一个简单的残差MLP框架
文章目录RETHINKING NETWORK DESIGN AND LOCAL GEOMETRY IN POINT CLOUD: A SIMPLE RESIDUAL MLP FRAMEWORKPointMLP残差点模块几何仿射模块精简版模型:PointMLP-elite实验结果消融实验RETHINKING NETWORK DESIGN AND LOCAL GEOMETRY IN POINT CLOUD: A SIMPLE RESI…...
 原理)
《MySQL学习》 count(*) 原理
一 . count(*)的实现方式 MyISAM 引擎把一个表的总行数存在了磁盘上,因此执行 count() 的时候会直接返回这个数,效率很高; 而 InnoDB 引擎就麻烦了,它执行 count(*) 的时候,需要把数据一行一行…...
时间序列数据预测的类型
本文主要内容是使用LSTM网络进行不同类型的时间序列预测任务,不涉及代码,仅仅就不同类型的预测任务和数据划分进行说明。 参考文章:https://machinelearningmastery.com/how-to-develop-lstm-models-for-time-series-forecasting/ 注…...

sk_buff结构体成员变量说明
一. 前言 Socket Buffer的数据包在穿越内核空间的TCP/IP协议栈过程中,数据内容不会被修改,只是数据包缓冲区中的协议头信息发生变化。大量操作都是围绕sk_buff结构体来进行的。 sk_buff结构的成员大致分为3类:结构管理域,常规数据…...

springbatch设置throttle-limit参数不生效
背景描述 当springbatch任务处理缓慢时,就需要使用多线程并行处理任务。 参数throttle-limit用于控制当前任务能够使用的线程数的最大值。 调整throttle-limit为10时,处理线程只有8,再次增大throttle-limit值为20,处理线程依旧为…...
用 tensorflow.js 做了一个动漫分类的功能(一)
前言:浏览某乎网站时发现了一个分享各种图片的博主,于是我顺手就保存了一些。但是一张一张的保存实在太麻烦了,于是我就想要某虫的手段来处理。这样保存的确是很快,但是他不识图片内容,最近又看了 mobileNet 的预训练模…...

看完这篇Vue-element-admin,跟面试官聊骚没问题
Vue-element-admin vue-element-admin 是一个后台前端解决方案,它基于 vue 和 element-ui实现。它使用了最新的前端技术栈,内置了 i18 国际化解决方案,动态路由,权限验证,提炼了典型的业务模型,提供了丰富…...

2022年全国职业院校技能大赛(中职组)网络安全竞赛试题A(5)
目录 模块A 基础设施设置与安全加固 一、项目和任务描述: 二、服务器环境说明 三、具体任务(每个任务得分以电子答题卡为准) A-1任务一 登录安全加固(Windows) 1.密码策略 a.密码策略必须同时满足大小写字母、数…...
基于Java+SpringBoot+Vue+Uniapp前后端分离商城系统设计与实现
博主介绍:✌全网粉丝3W,全栈开发工程师,从事多年软件开发,在大厂呆过。持有软件中级、六级等证书。可提供微服务项目搭建与毕业项目实战✌ 博主作品:《微服务实战》专栏是本人的实战经验总结,《Spring家族及…...

新建ES别名 添加别名 切换别名
# 查询别名指向到哪个索引 GET bebd_factory_search/_alias # 查询这个索引使用了什么别名 GET bebd_factory_search_1588250935622/_alias # 删除索引 DELETE bebd_factory_search_1588250935622 # 新建别名 POST /_aliases { "actions": [ { "ad…...
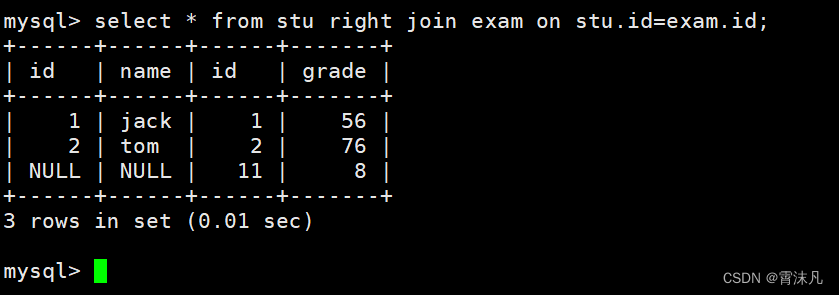
MySQL —— 内外连接
目录 表的内外连接 一、内连接 二、外连接 1. 左外连接 2. 右外连接 表的内外连接 表的连接分为内连和外连 一、内连接 内连接实际上就是利用where子句对两种表形成的笛卡儿积进行筛选,我们前面博客中的查询都是内连接,也是在开发过程中使用的最多…...

EXCEL中文本和数字的相互转换方法
将EXCEL中存为文本的数字转换成数字 如果在 Excel 中,将数字存储为文本格式,可以通过以下步骤将其转换为数字: 选中需要转换格式的单元格或者整列;右键单击,选择“格式单元格”;在弹出的对话框中选择“常…...

React源码分析6-hooks源码
本文将讲解 hooks 的执行过程以及常用的 hooks 的源码。 hooks 相关数据结构 要理解 hooks 的执行过程,首先想要大家对 hooks 相关的数据结构有所了解,便于后面大家顺畅地阅读代码。 Hook 每一个 hooks 方法都会生成一个类型为 Hook 的对象ÿ…...
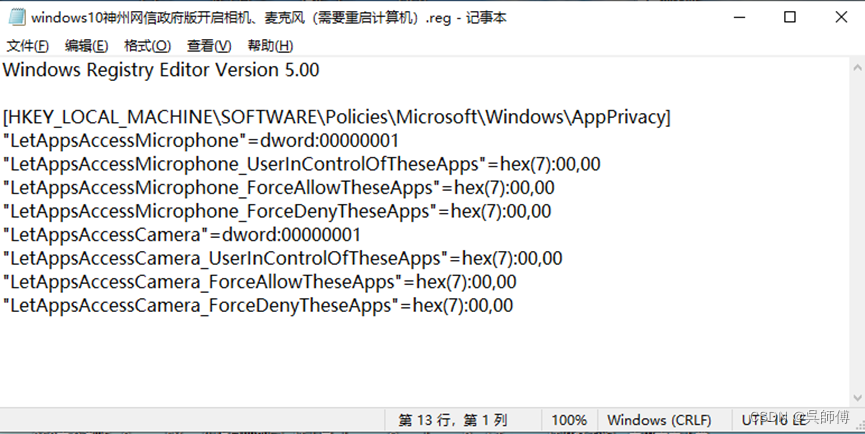
Windows10神州网信政府版麦克风、摄像头的使用
Windows10神州网信政府版默认麦克风摄像头是禁用状态,此禁用状态符合版本规定。 在录课和直播过程中,如果需要使用麦克风和摄像头的功能,可以这样更改: 1、鼠标右键点击屏幕左下角的开始菜单图标,选择windows中的“运…...

2026届毕业生推荐的十大降重复率助手实际效果
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 人工智能技术于学术写作领域的运用愈发广泛,其助力论文撰写的本领已获实证&#…...

深圳地铁大数据客流分析系统:如何用开源技术栈破解千万级乘客的交通治理难题
深圳地铁大数据客流分析系统:如何用开源技术栈破解千万级乘客的交通治理难题 【免费下载链接】SZT-bigdata 深圳地铁大数据客流分析系统🚇🚄🌟 项目地址: https://gitcode.com/gh_mirrors/sz/SZT-bigdata 深圳地铁作为中国…...

如何在5分钟内快速上手Wade搜索库:终极快速入门指南
如何在5分钟内快速上手Wade搜索库:终极快速入门指南 【免费下载链接】wade :ocean: Blazing fast 1kb search library 项目地址: https://gitcode.com/gh_mirrors/wa/wade Wade是一个轻量级、高性能的JavaScript搜索库,仅1kb大小却提供了强大的全…...

# 大数据开发面试题库
大数据开发岗面试必备:SQL 高频题、Spark 性能调优、数仓建模实战、项目经验梳理,覆盖初中级到高级岗位 📌 前言 为什么面试总被问倒? 为什么项目经验说不清楚? 为什么调优问题总是泛泛而谈? 根本原因&am…...

2 轻量设备鸿蒙应用开发极简流程 | 鸿蒙开发筑基实战
轻量设备鸿蒙应用开发极简流程 | 鸿蒙开发筑基实战 作者:杨建宾(华夏之光永存) 摘要 本文面向鸿蒙轻量设备(HiSpark系列、穿戴设备、IoT终端)开发者,拆解从工程创建到上线的全流程。聚焦轻量设备硬件资源有…...

2025届学术党必备的十大AI科研方案推荐榜单
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 在当下的学术与内容创作范畴之内,对于AI生成文本的检测变得越发严格起来。降AI率…...

容器环境下各种兼容模式+多实例
注意: #多实例端口不同数据目录不同容器名不同 1. -p 主机端口:容器端口 容器端口永远是 54321(不用改) 主机端口必须不一样:4321、4322、4323... 一个端口只能给一个数据库用,就像一个门不能同时进两个人。2. -v 主机…...

2025届毕业生推荐的十大降重复率神器横评
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 眼下,人工智能生成内容愈发普遍,各类AI检测工具便跟着出现了…...

全球AI薪资热力图:旧金山VS深圳的残酷对比
一场不平等的技术竞赛当我们谈论人工智能(AI)的未来时,旧金山湾区与深圳无疑是最为闪耀的两个坐标。前者是硅谷的心脏,全球科技创新的策源地;后者是中国乃至世界硬件制造与新兴科技应用的前沿阵地。然而,对…...

MouseClick:让重复点击成为过去的智能鼠标自动化工具
MouseClick:让重复点击成为过去的智能鼠标自动化工具 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软件界面美观 ,操…...