SpringCloud(十)——ElasticSearch简单了解(二)DSL查询语句及RestClient查询文档
文章目录
- 1. DSL查询文档
- 1.1 DSL查询分类
- 1.2 全文检索查询
- 1.3 精确查询
- 1.4 地理查询
- 1.5 查询算分
- 1.6 布尔查询
- 1.7 结果排序
- 1.8 分页查询
- 1.9 高亮显示
- 2. RestClient查询文档
- 2.1 查询全部
- 2.2 其他查询语句
- 2.3 排序和分页
- 2.4 高亮显示
1. DSL查询文档
1.1 DSL查询分类
- 查询所有:查询出所有数据,一般测试用。例如:
match_all - 全文检索查询:利用分词器对用户输入内容分词,然后去倒排索引库中匹配。例如:
- match_query
- multi_match_query
- 精确查询:根据精确词条值查找数据,一般是查找keyword、数值、日期、boolean等类型字段。例如:
- ids
- range
- term
- 地理查询:根据经纬度查询。例如:
- geo_distance
- geo_bounding_box
- 复合查询:复合查询可以将上述各种查询条件组合起来,合并查询条件。例如:
- bool
- function_score
下面我们以一个基本的查询语句来举例,比如,我们需要查询索引库 hotel 全部内容,使用的DSL语句如下:
GET /hotel/_search
{"query": {"match_all": {}}
}
1.2 全文检索查询
全文检索常用的有两个查询函数,分别是 match 以及 multi_match 。
match函数会对用户输入内容分词,然后去倒排索引库检索,语法如下:
比如搜索GET /indexName/_search {"query": {"match": {"FIELD": "TEXT"}} }hotel索引库中的name字段,如下:GET /hotel/_search {"query": {"match": {"name": "酒店"}} }multi_match函数与match类似,不过允许查询多个字段,语法如下:
比如搜索GET /indexName/_search {"query": {"multi_match": {"query": "TEXT","fields": ["FIELD1", " FIELD2"]}} }hotel索引库中的name字段,如下:GET /hotel/_search {"query": {"multi_match": {"query": "如家","fields": ["name", " brand"]}} }
1.3 精确查询
精确查询的语句函数主要有 term 语句和 range 语句,精确查询必须要查询的内容与字段里面的所有内容完全匹配才行,一般的查询是keyword、数值、日期、boolean等类型字段。
term的语法如下:GET /indexName/_search {"query": {"term": {"FIELD": {"value": "VALUE"}}} }range查询的语法如下:
其中GET /indexName/_search {"query": {"range": {"FIELD": {"gte": 10,"lte": 20}}} }gt是大于,lt是小于,gte是大于等于,lte是小于等于。
1.4 地理查询
地理查询主要是根据经纬度来进行查询的,主要使用的函数有 geo_bounding_box 和 geo_distance 。
geo_bounding_box函数的语法如下:
该函数能够将在一个矩阵框中的经纬度全部筛选出来,该矩阵的左上角的点以及右下角的点如上述定义所示,根据这两个点已经就能够定义一个矩形了,。GET /indexName/_search {"query": {"geo_bounding_box": {"FIELD": {"top_left": {"lat": 31.1,"lon": 121.5},"bottom_right": {"lat": 30.9,"lon": 121.7}}}} }geo_distance函数的语法如下:
该函数是筛选距离定义经纬度点指定距离内的所有点,这个距离指的是距定义点方圆的距离。GET /indexName/_search {"query": {"geo_distance": {"distance": "15km","FIELD": "31.21,121.5"}} }
1.5 查询算分
在使用关键词等进行查询的时候,会有一个 _score 属性,这就是每条数据与查询关键词的相关性分数,该分数在ElasticSearch5.0之前是使用的 TF-IDF 算法进行的评分,ElasticSearch5.0之后是使用的 BM25 算法进行评分。

我们可以使用 function score query,修改文档的相关性算分(query score),根据新得到的算分排序。修改算分的示例语句如下:
GET /hotel/_search
{"query": {"function_score": {"query": { "match": {"all": "外滩"} },"functions": [{"filter": {"term": {"id": "1"}},"weight": 10}],"boost_mode": "multiply"}}
}
在上面的例句中,
query是正常的查询语句filter表示过滤条件,符合条件的文档才会被重新算分weight是指算分函数,算分函数的结果称为function score,将来会与原始的query score运算,得到新算分,常见的算分函数有:- weight:给一个常量值,作为函数结果(function score)
- field_value_factor:用文档中的某个字段值作为函数结果
- random_score:随机生成一个值,作为函数结果
- script_score:自定义计算公式,公式结果作为函数结果
boost_mode定义function score与query score的运算方式,常见的加权方式如下:- multiply:两者相乘。默认就是这个
- replace:用function score 替换 query score
- 其它:sum、avg、max、min
1.6 布尔查询
布尔查询时一个或多个查询的字句,子查询的组合方式有:
- must:必须匹配每个子查询,类似“与”
- should:选择性匹配子查询,类似“或”
- must_not:必须不匹配,不参与算分,类似“非”
- filter:必须匹配,不参与算分
示例如下:
GET /hotel/_search
{"query": {"bool": {"must": [{"term": {"city": "上海" }}],"should": [{"term": {"brand": "皇冠假日" }},{"term": {"brand": "华美达" }}],"must_not": [{ "range": { "price": { "lte": 500 } }}],"filter": [{ "range": {"score": { "gte": 45 } }}]}}
}
1.7 结果排序
elasticsearch支持对搜索结果排序,默认是根据相关度算分(_score)来排序。可以排序字段类型有:keyword类型、数值类型、地理坐标类型、日期类型等。
GET /indexName/_search
{"query": {"match_all": {}},"sort": [{"FIELD": "desc" // 排序字段和排序方式ASC、DESC}]
}
以上就是指定字段的排序, ASC 代表升序,DASC 代表降序,如果有多个排序字段,那么按照从上到下的优先级进行排序。
举个例子,如果我们想要按照某一个经纬度的距离进行排序,那么模板如下:
GET /indexName/_search
{"query": {"match_all": {}},"sort": [{"_geo_distance" : {"FIELD" : "纬度,经度","order" : "asc","unit" : "km"}}]
}
1.8 分页查询
ElasticSearch查询时默认只显示10条数据,那如果我们想要看到其他的数据怎么办呢?这就涉及到了分页。ElasticSearch分页的方式有很多种,这里讲一下使用 from, size 参数以及 search after 来进行分页。
-
使用
from, size两个参数进行分页。可以在搜索时规定这两个参数的值,from表示从何处开始进行查看,默认是 0 0 0 ,size表示每次查询的信息有多少条。比如每也10条数据,我们想要查看第二页的数据,那么就需要设置from: 10,size:10,格式如下:GET /hotel/_search {"query": {"match_all": {}},"from": 990, // 分页开始的位置,默认为0"size": 10, // 期望获取的文档总数"sort": [{"price": "asc"}] }但是,这种方式要求
from+size不大于 10000 10000 10000 ,且该方式是先查询所有的数据,然后再对数据进行截取,不可避免的,该方式会面临深度分页问题,即我们的ElasticSearch肯定是要有集群的,当我们需要取出前 1000 1000 1000 个结果时,需要整理每个集群中的结果,再重新排序,再选出前 1000 1000 1000 个,但是,如果结果集很大,这对内存以及CPU的消耗就很大。 -
使用
search after进行分页。针对深度分页,ElasticSearch提供了search after方法,该方法没有查询上限,只限制了单次的size不超过 10000 10000 10000 。search after方法分页时需要排序,原理是从上一次的排序值开始,查询下一页数据。例如,我们查询到了第一页的数据,最后一条数据如下:

我们将最后一条数据的sort字段复制到search_after中,再规定一个size属性,就能够在该条数据之后再显示size条数据,语法模板如下:GET /hotel/_search {"query": {"match_all": {}},"search_after": [161],"size": 10,"sort": [{"price": "asc"}] }
1.9 高亮显示
在使用搜索引擎进行搜索时,我们发现我们输入的关键词显示都是用了高亮进行显示,这就是搜索结果的高亮。其实,这种高亮的显示是在搜索结果中将关键字用标签进行标注出来,再到页面中进行CSS的渲染。默认在进行高亮查询时会在高亮字段前后添加 em 标签,如果想添加其他标签可以进行更改,语法模板如下:
GET /hotel/_search
{"query": {"match": {"FIELD": "TEXT"}},"highlight": {"fields": { // 指定要高亮的字段,可以添加多个字段"FIELD": {"pre_tags": "<em>", // 用来标记高亮字段的前置标签,默认就是em标签,所以可以不写"post_tags": "</em>" // 用来标记高亮字段的后置标签}}}
}
这里我们对酒店数据进行查询的例子如下:
GET /hotel/_search
{"query": {"match": {"all": "如家"}},"highlight": {"fields": { "name": {"require_field_match": "false"}}}
}
在上面的搜索中, all 字段是 name, brand 等字段 copy_to 后的属性,而下面高亮显示的属性是 name 属性,这就导致了查询的属性与高亮显示的属性不一致的情况,这种情况默认是不会进行高亮显示的,需要查询的属性与高亮显示的属性一致才进行高亮显示。但是我们就可以设置 require_field_match 属性为 false 控制高亮显示与查询字段和高亮显示的字段无关。
高亮结果显示如下:

2. RestClient查询文档
2.1 查询全部
查询全部的代码如下所示,
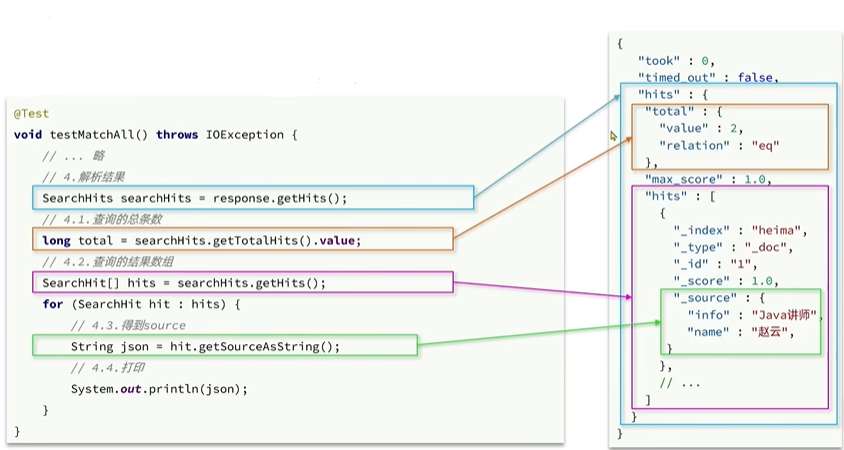
@Testvoid testMatchAll() throws IOException {//1.准备Request对象SearchRequest request = new SearchRequest("hotel");//2.准备DSLrequest.source().query(QueryBuilders.matchAllQuery());//3.发送请求SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT);//4.解析响应SearchHits searchHits = response.getHits();//5.1 获取总条数long total = searchHits.getTotalHits().value;System.out.println("共有" + total + "条数据");//5.2 文档数组存储文档SearchHit[] hits = searchHits.getHits();for(SearchHit hit: hits){//6.获取文档sourceString json = hit.getSourceAsString();//7.反序列化HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);System.out.println(hotelDoc);}System.out.println(response);}
其中每一段代码与DSL语句的对应关系如下:
2.2 其他查询语句
其实其他查询语句与上述查询全部的语句中大部分代码是类似的,唯一变化的是 request.source().query() 中 query 的参数。
- match
// 分别是字段名和查询的语句 request.source().query(QueryBuilders.matchQuery("all", "如家")); - multi_match
// 分别是查询词以及查询字段 request.source().query(QueryBuilders.matchQuery("如家", "name", "brand")); - term
// 分别是查询字段以及查询词 request.source().query(QueryBuilders.termQuery("city", "成都")); - range
// 分别是查询词以及查询条件 request.source().query(QueryBuilders.rangeQuery("price").gte(100).lte(300)); - 布尔查询
// 构建布尔查询 BoolQueryBuilder boolQuery = QueryBuilders.boolQuery(); // must语句 boolQuery.must(QueryBuilders.termQuery("city", "成都")); //filter语句 boolQuery.filter(QueryBuilders.rangeQuery("price").gte(100).lte(300)) request.source().query(boolQuery);
2.3 排序和分页
排序与分页的代码也仅需要在 request.source().query() 上进行修改即可,修改示例如下:
request.source().query(QueryBuilders.termQuery("city", "成都"));
// 排序
request.source().sort("price", SortOrder.ASC);
//分页
request.source().from(0).size(10);
2.4 高亮显示
高亮显示仅需要在查询的内容后面添加一行代码即可,如下:
// 设置高亮显示并关闭查询字段与高亮字段一致
request.source().highlighter(new HighlightBuilder().field("name").requireFieldMatch(false));
但是,设置了高亮后输出发现并不是高亮的内容,需要高亮的内容前后没有标签,这是怎么回事呢?
回顾上面可以发现,高亮的内容与 _source 内容是分开的,是重新的一个字段,于是,我们需要用高亮的字段覆盖原来的字段,那么循环里面的代码如下:
for(SearchHit hit: hits){//6.获取文档sourceString json = hit.getSourceAsString();//7.反序列化HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);//获取高亮结果Map<String, HighlightField> highlightFieldMap = hit.getHighlightFields();//简洁判断,判断highlightFieldMap是否为空或者size==0if(!CollectionUtils.isEmpty(highlightFieldMap)){//获取highlight属性中的name属性HighlightField highlightField = highlightFieldMap.get("name");if(highlightField != null){//得到name属性的第一个值的字符串String name = highlightField.getFragments()[0].string();//覆盖原本的值hotelDoc.setName(name);}}System.out.println(hotelDoc);
}
相关文章:
SpringCloud(十)——ElasticSearch简单了解(二)DSL查询语句及RestClient查询文档
文章目录 1. DSL查询文档1.1 DSL查询分类1.2 全文检索查询1.3 精确查询1.4 地理查询1.5 查询算分1.6 布尔查询1.7 结果排序1.8 分页查询1.9 高亮显示 2. RestClient查询文档2.1 查询全部2.2 其他查询语句2.3 排序和分页2.4 高亮显示 1. DSL查询文档 1.1 DSL查询分类 查询所有…...

Python Flask Web开发一:环境搭建
一、创建环境 创建一个项目文件夹和一个.venv文件夹 $ mkdir myproject $ cd myproject $ python3 -m venv .venv 二、激活环境 在开始项目之前,请激活相应的环境 激活成功的话会在开发工具自带的终端那里看到以(.venv)开头的 $ . .venv…...

DataTable扩展 列转行方法(2*2矩阵转换)
源数据 如图所示 // <summary>/// DataTable扩展 列转行方法(2*2矩阵转换)/// </summary>/// <param name"dtSource">数据源</param>/// <param name"columnFilter">逗号分隔 如SDateTime,PM25,PM10…...

Decomposed Prompting: A MODULAR APPROACH FOR SOLVING COMPLEX TASKS
本文是LLM系列文章,针对《Decomposed Prompting: A MODULAR APPROACH FOR SOLVING COMPLEX TASKS》的翻译。 分解提示:一种求解复杂任务的模块化方法 摘要1 引言2 相关工作3 分解提示4 案例5 结论 摘要 小样本提示是一种使用大型语言模型(L…...
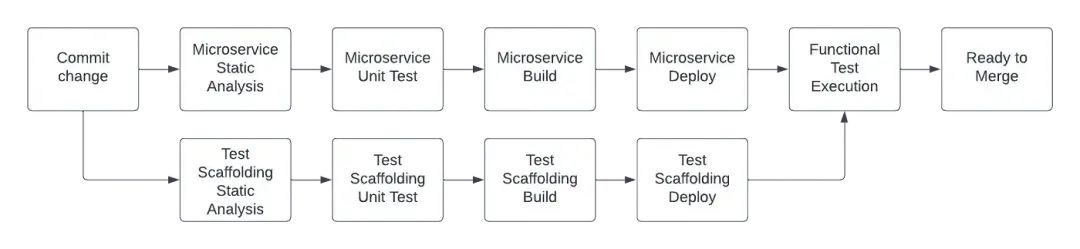
无需测试环境!如何利用测试脚手架隔离微服务,实现功能自动化
想在不建立完整测试环境的情况下测试微服务? 想在将变更推送到主线分支之前完成测试? 这是我们在进行项目交付时经常遇到的难题。最近,当我们开始一个新的项目,为客户构建一个新的聚合平台时,我们希望将尽可能多的测…...

HOperatorSet.Connection 有内存泄漏或缓存
开发环境 Win7 VS2002 halcon12, 直接运行Debug的exe 宽高5000,单格1*1的棋盘占用内存 手动释放region regionConnect private void butTemp_Click(object sender, EventArgs e) { butTemp.Enabled false; HOperatorS…...
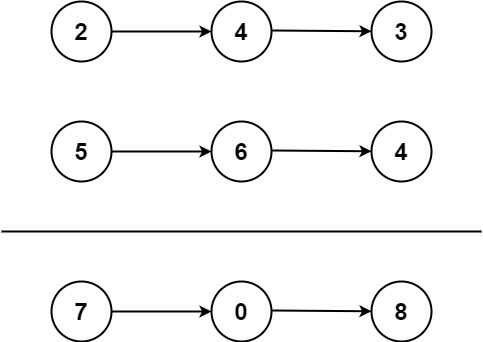
力扣2. 两数相加
2. 两数相加 给你两个 非空 的链表,表示两个非负的整数。它们每位数字都是按照 逆序 的方式存储的,并且每个节点只能存储 一位 数字。 请你将两个数相加,并以相同形式返回一个表示和的链表。 你可以假设除了数字 0 之外,这两个…...

无涯教程-Android Intent Standard Extra Data函数
下表列出了各种重要的Android Intent Standard Extra Data。您可以查看Android官方文档以获取额外数据的完整列表- Sr.NoExtra Data & Description1 EXTRA_ALARM_COUNT 用作AlarmManager intents(意图)中的int Extra字段,以告诉正在调用的应用程序intents(意图)释放了多少…...
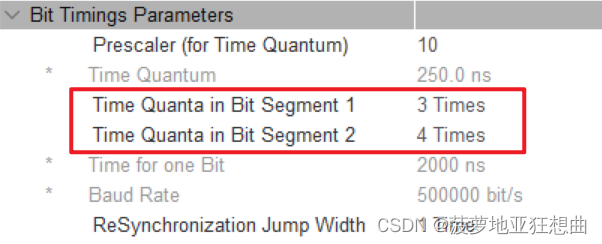
STM32 CAN 波特率计算分析
这里写目录标题 前言时钟分析时钟元到BIT 前言 CubeMX中配置CAN波特率的这个界面刚用的时候觉得非常难用,怎么都配置不到想要的波特率。接下来为大家做一下简单的分析。 时钟分析 STM32F4的CAN时钟来自APB1 在如下界面配置,最好配置为1个整一点的数。…...

每日后端面试5题 第十天
一、说出Spring的9种设计模式 1.简单工厂 2.工厂方法(Factory Method) 3.单例(Singleton) 4.适配器(Adapter) 5.包装器(Decorator) 6.代理(Proxy) 7.观…...

荷兰国旗问题之快速分组
朋友们,现在我出一个非常简单的问题,给你一个数组,把它进行处理,变成左边小,中间相等,右边大的一个数组,如何解决呢,这里涉及到一个基本方法叫分组,今天咱们不解决这个问…...

只允许程序单实例运行
有时候,我们只能允许程序单实例运行,以免程序运行出错。可以通过使用App.PrevInstance和系统级的Mutex等多种办法来实现。 代码如下: 用户昵称: 留下些什么 个人简介: 一个会做软件的货代 CSDN网址:https://blog.csdn.net/zezes…...

巨人互动|Facebook海外户Facebook游戏全球发布实用策略
Facebook是全球最大的社交媒体平台之一,拥有庞大的用户基数和广阔的市场。对于游戏开发商而言,利用Facebook进行全球发布是一项重要的策略。下面小编将介绍一些实用的策略帮助开发商在Facebook上进行游戏全球发布。 巨人互动|Facebook海外户&Faceboo…...
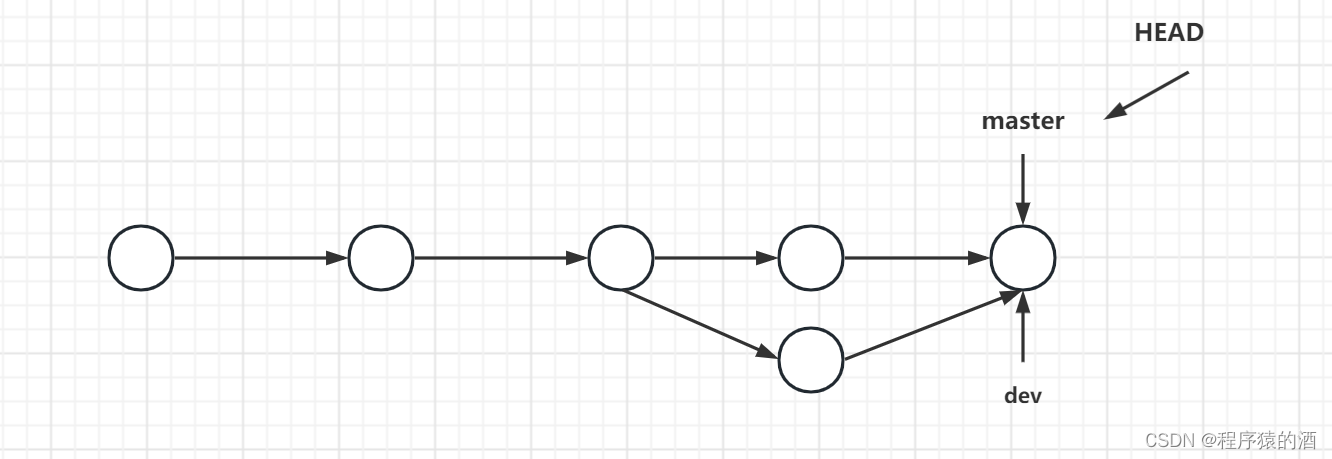
【Java架构-版本控制】-Git进阶
本文摘要 Git作为版本控制工具,使用非常广泛,在此咱们由浅入深,分三篇文章(Git基础、Git进阶、Gitlab搭那家)来深入学习Git 文章目录 本文摘要1. Git分支管理2. Git分支本质2.1 分支流转流程(只新增文件)2.2 分支流转流…...
业务需要咨询?开发遇到 bug 想反馈?开发者在线提单功能上线!
大家是否遇到过下列问题—— 在开发的时候,遇到 bug 需要反馈… 有合作意向的时候,想更多了解业务和相关产品… 在接入的时候,需要得到专业技术支持… 别急,荣耀开发者服务平台在线提单功能上线了~ 处理问题分类说明࿱…...

MybatisPlus插件篇—逻辑删除+p6spy
文章目录 一、前言二、插件1、逻辑删除1.1、官方说明:1.2、配置依赖1.3、配置全局配置1.4、实体类字段上添加TableLogic注解1.5、验证是否成功 2、执行SQL分析打印2.1、配置依赖2.2、数据库驱动配置2.3、spy配置文件配置2.4、注意事项 三、总结提升 一、前言 本文将…...

Android studio中EditText设置默认值
如果想对EditText设置默认值,在java代码中使用setText函数是不行的,需要在layout文件中设置“text变量”,如下所示设置默认值为“192.168.1.1”: <EditTextandroid:id"id/car1_ip_edit"android:layout_width"1…...

《Java面向对象程序设计》学习笔记——第 13 章 泛型与集合框架
笔记汇总:《Java面向对象程序设计》学习笔记 # 第 13 章 泛型与集合框架 Java 提供了实现常见数据结构的类,这些实现数据结构的类通称为 Java 集合框架。 在 JDK1.5 后, Java 集合框架开始支持泛型,本章首先介绍泛型&#…...

python进阶--魔法方法之类的表示
下面的魔法方法都可以用了描述类 1、__str__ 该方法一般返回字符串,也许不会返回一个有效的 Python 表达式,但可以使用更方便或更准确的描述信息。在类中重写该方法,用来输出类的属性值等信息 调用:str(object)或者内置函数format()或者print()都会调用__str__()方法 c…...

JVM 创建对象时分配内存的几种方法、分配方法的选择
创建对象分配内存的方法 指针碰撞 假设Java堆中内存是绝对规整的,所有被使用过的内存都被放在一边,空闲的内存被放在另一边,中间放着一个指针作为分界点的指示器,那所分配内存就仅仅是把那 个指针向空闲空间方向挪动一段与对象大…...

STM32CubeMX外设配置实战——以F103C8T6的CAN与DMA为例
1. STM32CubeMX与F103C8T6开发基础 STM32CubeMX是ST官方推出的图形化配置工具,它能极大简化STM32系列MCU的外设初始化流程。对于刚接触STM32开发的工程师来说,这个工具就像"乐高积木说明书"——通过可视化操作就能完成80%的底层配置工作。我最…...

Steam Achievement Manager完整指南:快速解决游戏成就难题的终极工具
Steam Achievement Manager完整指南:快速解决游戏成就难题的终极工具 【免费下载链接】SteamAchievementManager A manager for game achievements in Steam. 项目地址: https://gitcode.com/gh_mirrors/st/SteamAchievementManager 核心关键词:S…...

Gitclaw:封装复杂Git操作,提升开发效率的命令行工具
1. 项目概述:一个为Git操作注入“爪牙”的命令行工具如果你和我一样,日常开发工作重度依赖Git,那你肯定也经历过这样的时刻:面对一个需要多步操作才能完成的复杂Git任务,比如清理多个已合并的分支、批量重写提交历史中…...

品牌声音技能化:从模糊概念到可执行AI内容策略
1. 项目概述:品牌声音的“技能化”构建最近在和一些做品牌营销、内容运营的朋友聊天,发现一个挺普遍的现象:大家手里都有一堆品牌手册、VI规范,但一到具体执行,比如写一篇公众号推文、拍一条短视频,或者回复…...

本地可控 AI 助手搭建|Windows 一键安装 OpenClaw 操作指南
OpenClaw(小龙虾)Windows 一键部署保姆级教程|10 分钟搭建专属数字员工 前言 2026 年备受关注的开源 AI 智能体 OpenClaw(昵称小龙虾),在 GitHub 收获大量关注,凭借本地运行、零代码操作、自动…...

Node.js代理池实战:proxy-agents库核心原理与高级应用
1. 项目概述与核心价值最近在折腾一些需要处理大量网络请求的自动化脚本,比如数据采集、API测试或者模拟用户操作,一个绕不开的痛点就是IP被封。单个IP频繁请求,对方服务器很容易就把你拉黑了。这时候,代理池就成了刚需。市面上成…...

嵌入式开发内存优化实战:裁剪IRLib2红外库,释放微控制器Flash空间
1. 项目概述:当红外遥控遇上内存焦虑红外遥控,这个听起来有点“复古”的技术,至今仍是智能家居、玩具和各类嵌入式设备里最经济可靠的无线通信方案之一。它的原理不复杂:用一个特定频率(通常是38kHz)的载波…...

免费开源字体编辑器终极指南:5个核心模块带你从零到专业设计
免费开源字体编辑器终极指南:5个核心模块带你从零到专业设计 【免费下载链接】fontforge Free (libre) font editor for Windows, Mac OS X and GNULinux 项目地址: https://gitcode.com/gh_mirrors/fo/fontforge 想要免费编辑字体却找不到合适的工具&#x…...

如何用FanControl快速解决电脑风扇噪音问题:完整免费指南
如何用FanControl快速解决电脑风扇噪音问题:完整免费指南 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending…...

Linux网络运维实战:从ifconfig、ethtool到网络状态深度诊断
1. 从ifconfig开始:你的网络诊断第一课 刚接手一台Linux服务器时,我习惯性敲下的第一个命令永远是ifconfig。这个看似简单的命令就像汽车仪表盘,能快速告诉你当前网络接口的基本状态。记得有次凌晨处理线上故障,就是通过ifconfig…...