快手Java一面,全是基础
现在已经到了面试招聘比较火热的时候,准备面试的过程中,一定要多看面经,多自测!
今天分享的是一位贵州大学的同学分享的快手一面面经。
快手一面主要会问一些基础问题,也就是比较简单且容易准备的常规八股,通常不会问项目。到了二面,会开始问项目,各种问题也挖掘的更深一些。

很多同学觉得这种基础问题的考查意义不大,实际上还是很有意义的,这种基础性的知识在日常开发中也会需要经常用到。例如,线程池这块的拒绝策略、核心参数配置什么的,如果你不了解,实际项目中使用线程池可能就用的不是很明白,容易出现问题。而且,其实这种基础性的问题是最容易准备的,像各种底层原理、系统设计、场景题以及深挖你的项目这类才是最难的!
1、Long 的长度和范围,为什么要减 1 ?
先来复习一下 Java 中的 8 种基本数据类型:
-
6 种数字类型:
-
4 种整数型:
byte、short、int、long -
2 种浮点型:
float、double
-
-
1 种字符类型:
char -
1 种布尔型:
boolean。
这 8 种基本数据类型的默认值以及所占空间的大小如下:
| 基本类型 | 位数 | 字节 | 默认值 | 取值范围 |
|---|---|---|---|---|
byte | 8 | 1 | 0 | -128 ~ 127 |
short | 16 | 2 | 0 | -32768(-2^15) ~ 32767(2^15 - 1) |
int | 32 | 4 | 0 | -2147483648 ~ 2147483647 |
long | 64 | 8 | 0L | -9223372036854775808(-2^63) ~ 9223372036854775807(2^63 -1) |
char | 16 | 2 | 'u0000' | 0 ~ 65535(2^16 - 1) |
float | 32 | 4 | 0f | 1.4E-45 ~ 3.4028235E38 |
double | 64 | 8 | 0d | 4.9E-324 ~ 1.7976931348623157E308 |
boolean | 1 | false | true、false |
可以看到,像 byte、short、int、long能表示的最大正数都减 1 了。这是为什么呢?这是因为在二进制补码表示法中,最高位是用来表示符号的(0 表示正数,1 表示负数),其余位表示数值部分。所以,如果我们要表示最大的正数,我们需要把除了最高位之外的所有位都设为 1。如果我们再加 1,就会导致溢出,变成一个负数。
对于 boolean,官方文档未明确定义,它依赖于 JVM 厂商的具体实现。逻辑上理解是占用 1 位,但是实际中会考虑计算机高效存储因素。
另外,Java 的每种基本类型所占存储空间的大小不会像其他大多数语言那样随机器硬件架构的变化而变化。这种所占存储空间大小的不变性是 Java 程序比用其他大多数语言编写的程序更具可移植性的原因之一(《Java 编程思想》2.2 节有提到)。
2、JAVA 异常的层次结构
Java 异常类层次结构图概览:
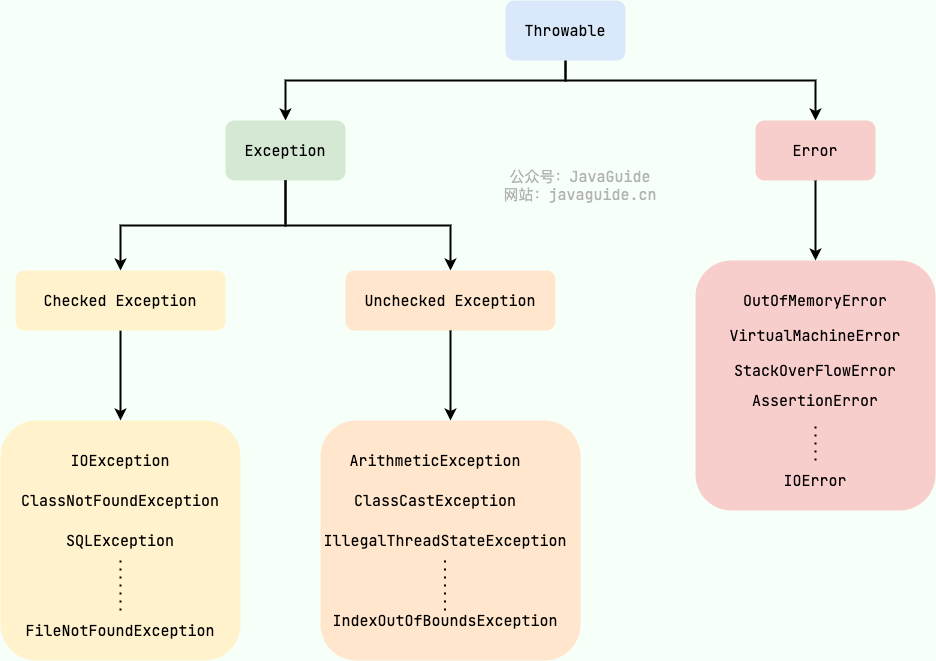
Java 异常类层次结构图
在 Java 中,所有的异常都有一个共同的祖先 java.lang 包中的 Throwable 类。Throwable 类有两个重要的子类:
-
Exception:程序本身可以处理的异常,可以通过catch来进行捕获。Exception又可以分为 Checked Exception (受检查异常,必须处理) 和 Unchecked Exception (不受检查异常,可以不处理)。 -
**
Error**:Error属于程序无法处理的错误 ,我们没办法通过catch来进行捕获不建议通过catch捕获 。例如 Java 虚拟机运行错误(Virtual MachineError)、虚拟机内存不够错误(OutOfMemoryError)、类定义错误(NoClassDefFoundError)等 。这些异常发生时,Java 虚拟机(JVM)一般会选择线程终止。
3、JAVA 的集合类有了解么?
Java 集合, 也叫作容器,主要是由两大接口派生而来:一个是 Collection接口,主要用于存放单一元素;另一个是 Map 接口,主要用于存放键值对。对于Collection 接口,下面又有三个主要的子接口:List、Set 和 Queue。
Java 集合框架如下图所示:
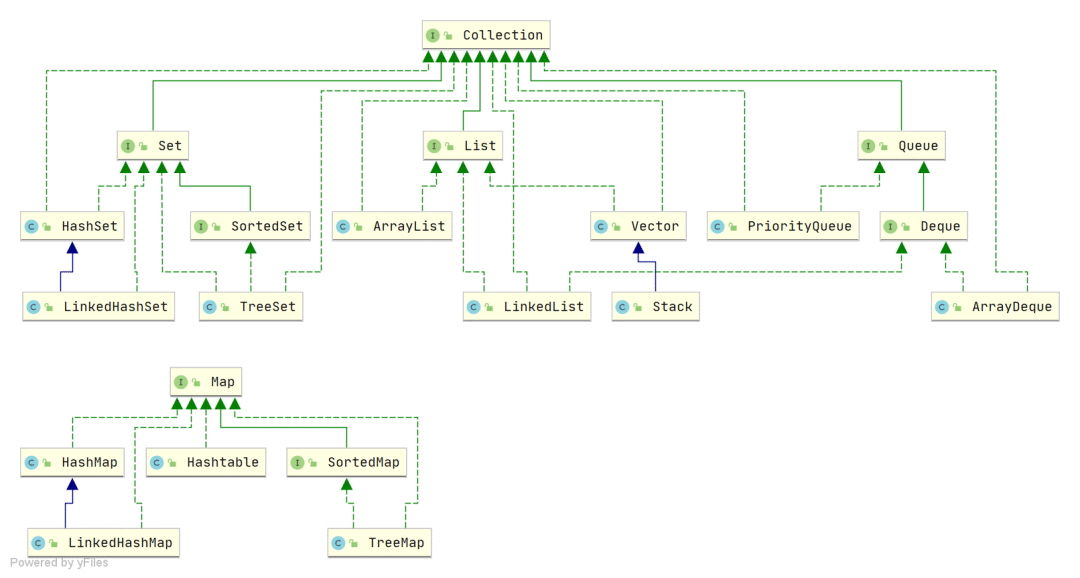
Java 集合框架概览
注:图中只列举了主要的继承派生关系,并没有列举所有关系。比方省略了AbstractList, NavigableSet等抽象类以及其他的一些辅助类,如想深入了解,可自行查看源码。
-
List(对付顺序的好帮手): 存储的元素是有序的、可重复的。 -
Set(注重独一无二的性质): 存储的元素不可重复的。 -
Queue(实现排队功能的叫号机): 按特定的排队规则来确定先后顺序,存储的元素是有序的、可重复的。 -
Map(用 key 来搜索的专家): 使用键值对(key-value)存储,类似于数学上的函数 y=f(x),"x" 代表 key,"y" 代表 value,key 是无序的、不可重复的,value 是无序的、可重复的,每个键最多映射到一个值。
4、ArrayList 和 LinkedList 区别
-
是否保证线程安全:
ArrayList和LinkedList都是不同步的,也就是不保证线程安全; -
底层数据结构:
ArrayList底层使用的是Object数组;LinkedList底层使用的是 双向链表 数据结构(JDK1.6 之前为循环链表,JDK1.7 取消了循环。注意双向链表和双向循环链表的区别,下面有介绍到!) -
插入和删除是否受元素位置的影响:
-
ArrayList采用数组存储,所以插入和删除元素的时间复杂度受元素位置的影响。比如:执行add(E e)方法的时候,ArrayList会默认在将指定的元素追加到此列表的末尾,这种情况时间复杂度就是 O(1)。但是如果要在指定位置 i 插入和删除元素的话(add(int index, E element)),时间复杂度就为 O(n)。因为在进行上述操作的时候集合中第 i 和第 i 个元素之后的(n-i)个元素都要执行向后位/向前移一位的操作。 -
LinkedList采用链表存储,所以在头尾插入或者删除元素不受元素位置的影响(add(E e)、addFirst(E e)、addLast(E e)、removeFirst()、removeLast()),时间复杂度为 O(1),如果是要在指定位置i插入和删除元素的话(add(int index, E element),remove(Object o),remove(int index)), 时间复杂度为 O(n) ,因为需要先移动到指定位置再插入和删除。
-
-
是否支持快速随机访问:
LinkedList不支持高效的随机元素访问,而ArrayList(实现了RandomAccess接口) 支持。快速随机访问就是通过元素的序号快速获取元素对象(对应于get(int index)方法)。 -
内存空间占用:
ArrayList的空间浪费主要体现在在 list 列表的结尾会预留一定的容量空间,而 LinkedList 的空间花费则体现在它的每一个元素都需要消耗比 ArrayList 更多的空间(因为要存放直接后继和直接前驱以及数据)。
我们在项目中一般是不会使用到 LinkedList 的,需要用到 LinkedList 的场景几乎都可以使用 ArrayList 来代替,并且,性能通常会更好!就连 LinkedList 的作者约书亚 · 布洛克(Josh Bloch)自己都说从来不会使用 LinkedList 。
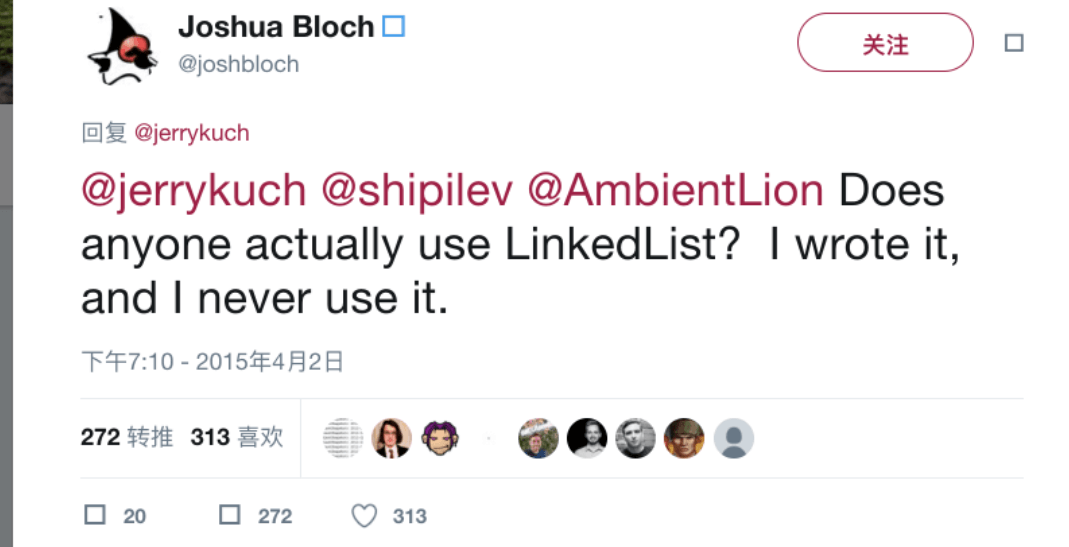
另外,不要下意识地认为 LinkedList 作为链表就最适合元素增删的场景。我在上面也说了,LinkedList 仅仅在头尾插入或者删除元素的时候时间复杂度近似 O(1),其他情况增删元素的平均时间复杂度都是 O(n) 。
补充内容: 双向链表和双向循环链表
双向链表: 包含两个指针,一个 prev 指向前一个节点,一个 next 指向后一个节点。
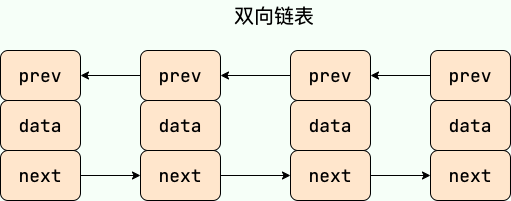
双向链表
双向循环链表: 最后一个节点的 next 指向 head,而 head 的 prev 指向最后一个节点,构成一个环。
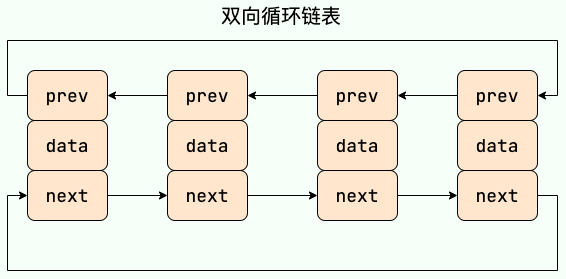
双向循环链表
补充内容:RandomAccess 接口
public interface RandomAccess {
}
查看源码我们发现实际上 RandomAccess 接口中什么都没有定义。所以,在我看来 RandomAccess 接口不过是一个标识罢了。标识什么?标识实现这个接口的类具有随机访问功能。
在 binarySearch() 方法中,它要判断传入的 list 是否 RandomAccess 的实例,如果是,调用indexedBinarySearch()方法,如果不是,那么调用iteratorBinarySearch()方法
public static <T>int binarySearch(List<? extends Comparable<? super T>> list, T key) {if (list instanceof RandomAccess || list.size()<BINARYSEARCH_THRESHOLD)return Collections.indexedBinarySearch(list, key);elsereturn Collections.iteratorBinarySearch(list, key);}
ArrayList 实现了 RandomAccess 接口, 而 LinkedList 没有实现。为什么呢?我觉得还是和底层数据结构有关!ArrayList 底层是数组,而 LinkedList 底层是链表。数组天然支持随机访问,时间复杂度为 O(1),所以称为快速随机访问。链表需要遍历到特定位置才能访问特定位置的元素,时间复杂度为 O(n),所以不支持快速随机访问。ArrayList 实现了 RandomAccess 接口,就表明了他具有快速随机访问功能。RandomAccess 接口只是标识,并不是说 ArrayList 实现 RandomAccess 接口才具有快速随机访问功能的!
5、HashMap 有了解么,它的底层实现,为什么线程不安全?
HashMap 主要用来存放键值对,它基于哈希表的 Map 接口实现,是常用的 Java 集合之一,是非线程安全的。
HashMap 可以存储 null 的 key 和 value,但 null 作为键只能有一个,null 作为值可以有多个
JDK1.8 之前 HashMap 由 数组+链表 组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的(“拉链法”解决冲突)。JDK1.8 以后的 HashMap 在解决哈希冲突时有了较大的变化,当链表长度大于等于阈值(默认为 8)(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)时,将链表转化为红黑树,以减少搜索时间。
HashMap 默认的初始化大小为 16。之后每次扩充,容量变为原来的 2 倍。并且, HashMap 总是使用 2 的幂作为哈希表的大小。
JDK1.7 及之前版本,在多线程环境下,HashMap 扩容时会造成死循环和数据丢失的问题。
数据丢失这个在 JDK1.7 和 JDK 1.8 中都存在,这里以 JDK 1.8 为例进行介绍。
JDK 1.8 后,在 HashMap 中,多个键值对可能会被分配到同一个桶(bucket),并以链表或红黑树的形式存储。多个线程对 HashMap 的 put 操作会导致线程不安全,具体来说会有数据覆盖的风险。
举个例子:
-
两个线程 1,2 同时进行 put 操作,并且发生了哈希冲突(hash 函数计算出的插入下标是相同的)。
-
不同的线程可能在不同的时间片获得 CPU 执行的机会,当前线程 1 执行完哈希冲突判断后,由于时间片耗尽挂起。线程 2 先完成了插入操作。
-
随后,线程 1 获得时间片,由于之前已经进行过 hash 碰撞的判断,所有此时会直接进行插入,这就导致线程 2 插入的数据被线程 1 覆盖了。
public V put(K key, V value) {return putVal(hash(key), key, value, false, true);
}final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {// ...// 判断是否出现 hash 碰撞// (n - 1) & hash 确定元素存放在哪个桶中,桶为空,新生成结点放入桶中(此时,这个结点是放在数组中)if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);// 桶中已经存在元素(处理hash冲突)else {// ...
}
还有一种情况是这两个线程同时 put 操作导致 size 的值不正确,进而导致数据覆盖的问题:
-
线程 1 执行
if(++size > threshold)判断时,假设获得size的值为 10,由于时间片耗尽挂起。 -
线程 2 也执行
if(++size > threshold)判断,获得size的值也为 10,并将元素插入到该桶位中,并将size的值更新为 11。 -
随后,线程 1 获得时间片,它也将元素放入桶位中,并将 size 的值更新为 11。
-
线程 1、2 都执行了一次
put操作,但是size的值只增加了 1,也就导致实际上只有一个元素被添加到了HashMap中。
public V put(K key, V value) {return putVal(hash(key), key, value, false, true);
}final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {// ...// 实际大小大于阈值则扩容if (++size > threshold)resize();// 插入后回调afterNodeInsertion(evict);return null;
}
6、CoucurHashMap 和 HashTable
ConcurrentHashMap 和 Hashtable 的区别主要体现在实现线程安全的方式上不同。
-
底层数据结构: JDK1.7 的
ConcurrentHashMap底层采用 分段的数组+链表 实现,JDK1.8 采用的数据结构跟HashMap1.8的结构一样,数组+链表/红黑二叉树。Hashtable和 JDK1.8 之前的HashMap的底层数据结构类似都是采用 数组+链表 的形式,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的; -
实现线程安全的方式(重要):
-
在 JDK1.7 的时候,
ConcurrentHashMap对整个桶数组进行了分割分段(Segment,分段锁),每一把锁只锁容器其中一部分数据(下面有示意图),多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高并发访问率。 -
到了 JDK1.8 的时候,
ConcurrentHashMap已经摒弃了Segment的概念,而是直接用Node数组+链表+红黑树的数据结构来实现,并发控制使用synchronized和 CAS 来操作。(JDK1.6 以后synchronized锁做了很多优化) 整个看起来就像是优化过且线程安全的HashMap,虽然在 JDK1.8 中还能看到Segment的数据结构,但是已经简化了属性,只是为了兼容旧版本; -
Hashtable(同一把锁) :使用synchronized来保证线程安全,效率非常低下。当一个线程访问同步方法时,其他线程也访问同步方法,可能会进入阻塞或轮询状态,如使用 put 添加元素,另一个线程不能使用 put 添加元素,也不能使用 get,竞争会越来越激烈效率越低。
-
下面,我们再来看看两者底层数据结构的对比图。
Hashtable :
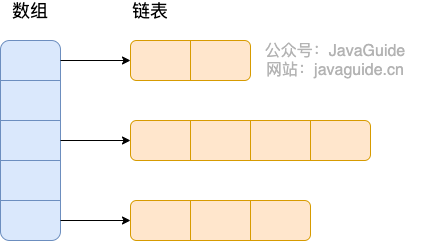
Hashtable 的内部结构
https://www.cnblogs.com/chengxiao/p/6842045.html>
JDK1.7 的 ConcurrentHashMap:
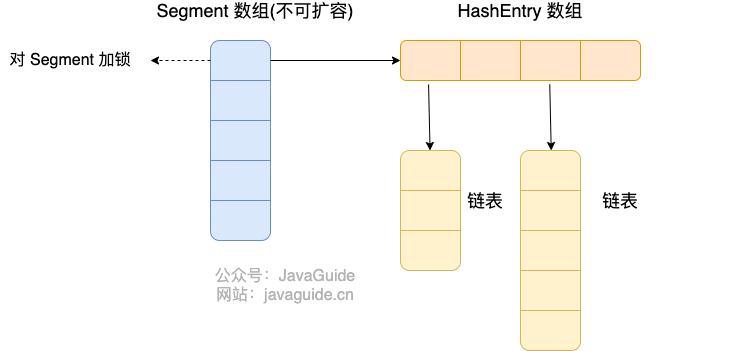
Java7 ConcurrentHashMap 存储结构
ConcurrentHashMap 是由 Segment 数组结构和 HashEntry 数组结构组成。
Segment 数组中的每个元素包含一个 HashEntry 数组,每个 HashEntry 数组属于链表结构。
JDK1.8 的 ConcurrentHashMap:
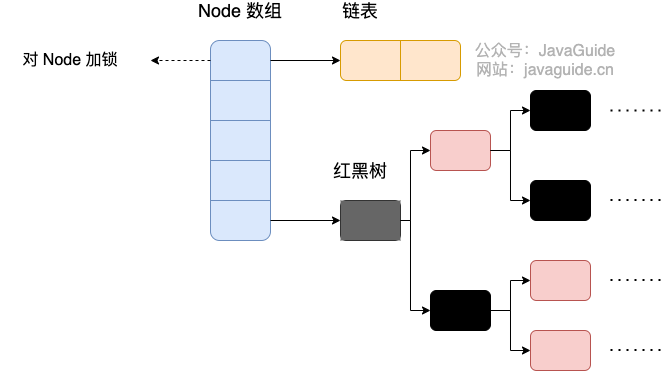
Java8 ConcurrentHashMap 存储结构
JDK1.8 的 ConcurrentHashMap 不再是 Segment 数组 + HashEntry 数组 + 链表,而是 Node 数组 + 链表 / 红黑树。不过,Node 只能用于链表的情况,红黑树的情况需要使用 TreeNode。当冲突链表达到一定长度时,链表会转换成红黑树。
TreeNode是存储红黑树节点,被TreeBin包装。TreeBin通过root属性维护红黑树的根结点,因为红黑树在旋转的时候,根结点可能会被它原来的子节点替换掉,在这个时间点,如果有其他线程要写这棵红黑树就会发生线程不安全问题,所以在 ConcurrentHashMap 中TreeBin通过waiter属性维护当前使用这棵红黑树的线程,来防止其他线程的进入。
static final class TreeBin<K,V> extends Node<K,V> {TreeNode<K,V> root;volatile TreeNode<K,V> first;volatile Thread waiter;volatile int lockState;// values for lockStatestatic final int WRITER = 1; // set while holding write lockstatic final int WAITER = 2; // set when waiting for write lockstatic final int READER = 4; // increment value for setting read lock
...
}
7、线程池有了解么,讲一下。
顾名思义,线程池就是管理一系列线程的资源池,其提供了一种限制和管理线程资源的方式。每个线程池还维护一些基本统计信息,例如已完成任务的数量。
这里借用《Java 并发编程的艺术》书中的部分内容来总结一下使用线程池的好处:
-
降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
-
提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行。
-
提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
线程池一般用于执行多个不相关联的耗时任务,没有多线程的情况下,任务顺序执行,使用了线程池的话可让多个不相关联的任务同时执行。
8、线程池配置无界队列了之后,拒绝策略怎么搞,什么时候用到无界对列?
线程池配置无界队列了之后,拒绝策略其实就失去了意义,因为无论有多少任务提交到线程池,都会被放入队列中等待执行,不会触发拒绝策略。不过,这样可能堆积大量的请求,从而导致 OOM。因此,一般不推荐使用误解队列。
假设不是无界队列的话,如果当前同时运行的线程数量达到最大线程数量并且队列也已经被放满了任务时,ThreadPoolTaskExecutor 定义一些拒绝策略:
-
ThreadPoolExecutor.AbortPolicy:抛出RejectedExecutionException来拒绝新任务的处理。 -
ThreadPoolExecutor.CallerRunsPolicy:调用执行自己的线程运行任务,也就是直接在调用execute方法的线程中运行(run)被拒绝的任务,如果执行程序已关闭,则会丢弃该任务。因此这种策略会降低对于新任务提交速度,影响程序的整体性能。如果您的应用程序可以承受此延迟并且你要求任何一个任务请求都要被执行的话,你可以选择这个策略。 -
ThreadPoolExecutor.DiscardPolicy:不处理新任务,直接丢弃掉。 -
ThreadPoolExecutor.DiscardOldestPolicy:此策略将丢弃最早的未处理的任务请求。
举个例子:
Spring 通过 ThreadPoolTaskExecutor 或者我们直接通过 ThreadPoolExecutor 的构造函数创建线程池的时候,当我们不指定 RejectedExecutionHandler 饱和策略的话来配置线程池的时候默认使用的是 ThreadPoolExecutor.AbortPolicy。在默认情况下,ThreadPoolExecutor 将抛出 RejectedExecutionException 来拒绝新来的任务 ,这代表你将丢失对这个任务的处理。对于可伸缩的应用程序,建议使用 ThreadPoolExecutor.CallerRunsPolicy。当最大池被填满时,此策略为我们提供可伸缩队列(这个直接查看 ThreadPoolExecutor 的构造函数源码就可以看出,比较简单的原因,这里就不贴代码了)。
9、MVCC 讲一下
MVCC 是多版本并发控制方法,即对一份数据会存储多个版本,通过事务的可见性来保证事务能看到自己应该看到的版本。通常会有一个全局的版本分配器来为每一行数据设置版本号,版本号是唯一的。
MVCC 在 MySQL 中实现所依赖的手段主要是: 隐藏字段、read view、undo log。
-
undo log : undo log 用于记录某行数据的多个版本的数据。
-
read view 和 隐藏字段 : 用来判断当前版本数据的可见性。
关于 InnoDB 对 MVCC 的具体实现可以看这篇文章:[InnoDB 存储引擎对 MVCC 的实现]( "InnoDB 存储引擎对 MVCC 的实现") 。
10、事务特性、隔离级别
关系型数据库(例如:MySQL、SQL Server、Oracle 等)事务都有 ACID 特性:
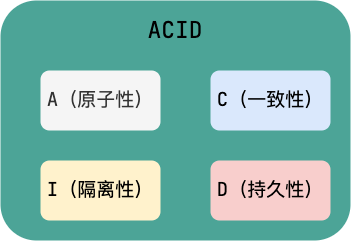
ACID
-
原子性(
Atomicity):事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用; -
一致性(
Consistency):执行事务前后,数据保持一致,例如转账业务中,无论事务是否成功,转账者和收款人的总额应该是不变的; -
隔离性(
Isolation):并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的; -
持久性(
Durability):一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
🌈 这里要额外补充一点:只有保证了事务的持久性、原子性、隔离性之后,一致性才能得到保障。也就是说 A、I、D 是手段,C 是目的! 想必大家也和我一样,被 ACID 这个概念被误导了很久! 我也是看周志明老师的公开课《周志明的软件架构课》[1]才搞清楚的(多看好书!!!)。
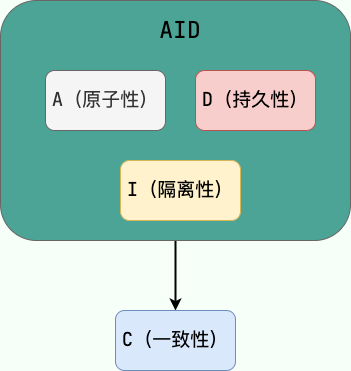
AID->C
另外,DDIA 也就是 《Designing Data-Intensive Application(数据密集型应用系统设计)》[2] 的作者在他的这本书中如是说:
Atomicity, isolation, and durability are properties of the database, whereas consis‐ tency (in the ACID sense) is a property of the application. The application may rely on the database’s atomicity and isolation properties in order to achieve consistency, but it’s not up to the database alone.
翻译过来的意思是:原子性,隔离性和持久性是数据库的属性,而一致性(在 ACID 意义上)是应用程序的属性。应用可能依赖数据库的原子性和隔离属性来实现一致性,但这并不仅取决于数据库。因此,字母 C 不属于 ACID 。
《Designing Data-Intensive Application(数据密集型应用系统设计)》这本书强推一波,值得读很多遍!豆瓣有接近 90% 的人看了这本书之后给了五星好评。另外,中文翻译版本已经在 GitHub 开源,地址:https://github.com/Vonng/ddia[3] 。

SQL 标准定义了四个隔离级别:
-
READ-UNCOMMITTED(读取未提交) :最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。
-
READ-COMMITTED(读取已提交) :允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。
-
REPEATABLE-READ(可重复读) :对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
-
SERIALIZABLE(可串行化) :最高的隔离级别,完全服从 ACID 的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| READ-UNCOMMITTED | √ | √ | √ |
| READ-COMMITTED | × | √ | √ |
| REPEATABLE-READ | × | × | √ |
| SERIALIZABLE | × | × | × |
MySQL 的隔离级别基于锁和 MVCC 机制共同实现的。
SERIALIZABLE 隔离级别是通过锁来实现的,READ-COMMITTED 和 REPEATABLE-READ 隔离级别是基于 MVCC 实现的。不过, SERIALIZABLE 之外的其他隔离级别可能也需要用到锁机制,就比如 REPEATABLE-READ 在当前读情况下需要使用加锁读来保证不会出现幻读。
MySQL InnoDB 存储引擎的默认支持的隔离级别是 REPEATABLE-READ(可重读)。我们可以通过SELECT @@tx_isolation;命令来查看,MySQL 8.0 该命令改为SELECT @@transaction_isolation;
mysql> SELECT @@tx_isolation;
+-----------------+
| @@tx_isolation |
+-----------------+
| REPEATABLE-READ |
+-----------------+
关于 MySQL 事务隔离级别的详细介绍,可以看看我写的这篇文章:MySQL 事务隔离级别详解[4]。
相关文章:
快手Java一面,全是基础
现在已经到了面试招聘比较火热的时候,准备面试的过程中,一定要多看面经,多自测! 今天分享的是一位贵州大学的同学分享的快手一面面经。 快手一面主要会问一些基础问题,也就是比较简单且容易准备的常规八股࿰…...
未来芯片设计领域的药明康德——青芯如何在N个项目间游走平衡
总部位于上海张江的青芯半导体(CyanSemi),ASIC定制设计是其核心业务之一。 青芯在单纯的设计服务维度之上,打造了从设计到生产的一套完整ASIC定制业务,不仅做芯片设计,还提供封装、测试服务,也…...

【跟小嘉学 Rust 编程】十九、高级特性
系列文章目录 【跟小嘉学 Rust 编程】一、Rust 编程基础 【跟小嘉学 Rust 编程】二、Rust 包管理工具使用 【跟小嘉学 Rust 编程】三、Rust 的基本程序概念 【跟小嘉学 Rust 编程】四、理解 Rust 的所有权概念 【跟小嘉学 Rust 编程】五、使用结构体关联结构化数据 【跟小嘉学…...
pandas由入门到精通-数据清洗-缺失值处理
pandas-02-数据清洗&预处理 A.缺失值处理1. Pandas缺失值判断2. 缺失值过滤2.1 Series.dropna()2.2 DataFrame.dropna()3. 缺失值填充3.1 值填充3.2 向前/向后填充文中用S代指Series,用Df代指DataFrame 数据清洗是处理大型复杂情况数据必不可少的步骤,这里总结一些数据清…...

Redis 教程 - 主从复制
Redis 教程 - 主从复制 Redis 支持主从复制(Master-Slave Replication),通过主从复制可以将一个 Redis 服务器(主节点)的数据复制到其他 Redis 服务器(从节点),以实现数据的冗余备份…...
[递归] 子集 全排列和组合问题
1.1 子集I 思路可以简单概括为 二叉树,每一次分叉要么选择一个元素,要么选择空,总共有n次,因此到n1进行保存结果,返回。像这样: #include <cstdio> #include <vector> #include <algorithm&…...
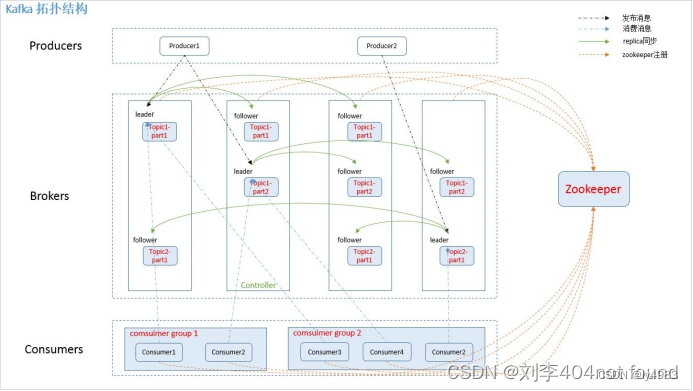
ELK安装、部署、调试(四)KAFKA消息队列的安装和部署
1.简介 Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通…...

半导体晶片机器视觉测量及MARK点视觉定位
半导体晶片机器视觉测量及MARK点视觉定位 客户的需求: 检测内容: SMT行业晶片位置角度与PCB板Mark点位置的测试测量 检测要求: 精度0.04mm,移动速度100mm/s 视觉可行性分析: 对样品进行了光学实验,并进行图像处理,…...
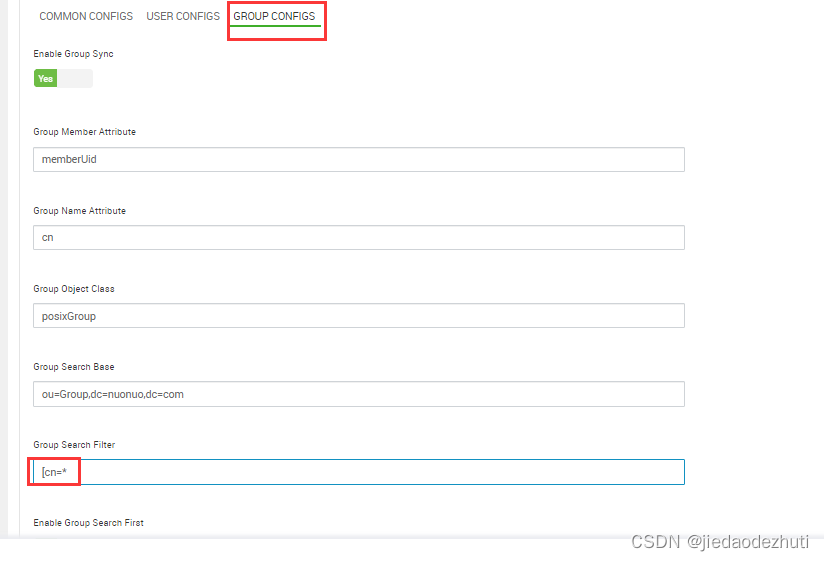
ranger无法同步用户问题解决
1.首先就是定位日志,日志目录 cd /var/log/ranger/usersync 定位到问题报错如下: LdapDeltaUserGroupBuilder.getUsers() failed with exception:java.naming.AuthticationExceptiom :[LDAP:error code 49 - Invalid Credentials]:remaing name ‘ouPeople,dc*.dccom’ 解决办法…...
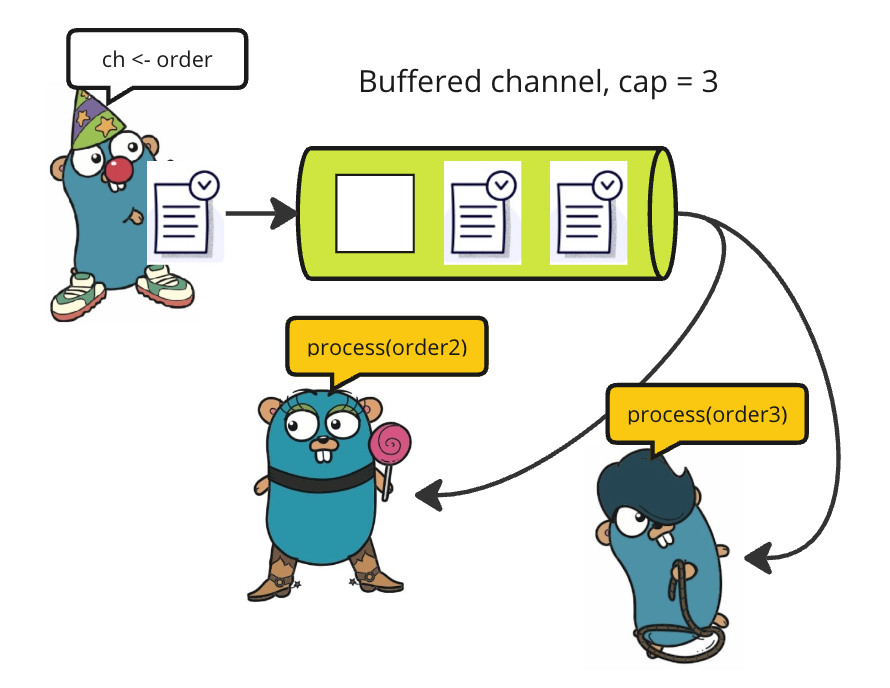
使用通信顺序进程(CSP)模型的 Go 语言通道
在并发编程中,许多编程语言采用共享内存/状态模型。然而,Go 通过实现 通信顺序进程(CSP)模型来区别于众多。在CSP中,程序由不共享状态的并行进程组成;相反,它们通过通道进行通信和同步操作。因此…...

VPN网关
阿里云VPN网关(VPN Gateway,简称VPN)是一款基于Internet,通过加密通道将企业数据中心、办公网或终端与专有网络(VPC) 安全可靠连接起来的服务。 VPN网关提供IPsec-VPN和SSL-VPN两种。 网络连接方式应用场景IPsec-VPN支持在企业本地数据中心、企业办公网…...

产品展示视频制作的要点
制作产品展示视频时通过精心策划的视频剧本和拍摄手法,可以准确地呈现活动的目的、主题和特点,让观众更好地理解和认同活动的意义。深圳产品活动视频制作公司老友记小编还为您整理了以下一些重要的制作要点: 1.明确目标受众:了解你…...

appium+python自动化测试
获取APP的包名 1、aapt即Android Asset Packaging Tool,在SDK的build-tools目录下。该工具可以查看apk包名和launcherActivity 2、在android-sdk里面双击SDK-manager,下载buidl-tools 3、勾选build-tools,随便选一个版本,我这里选的是24的版…...

【AI辅助办公】PDF转PPT,移除水印
PDF转PPT 将PDF上传链接即可转换成PPT。 https://www.camscanner.com/pdftoppthttps://www.camscanner.com/pdftoppt移除水印 第一步:打开视图-宏 第二步:输入宏名(可以是人以文字…...
ssm农业视频实时发布管理系统源码
ssm农业视频实时发布管理系统源码108 开发工具:idea 数据库mysql5.7 数据库链接工具:navcat,小海豚等 技术:ssm package com.controller;import java.io.File; import java.io.FileNotFoundException; import java.io.IOException; impo…...

【100天精通python】Day48:python Web开发_WSGI接口与使用
目录 1 WSGI接口 1.1 CGI 简介 1.2 WSGI 简介 1.3 定义 WSGI 接口 1.3.1 应用程序(Application) 1.3.2 服务器(Server) 1.4 WSGI 接口的使用示例 1.5 WSGI接口的优势 1 WSGI接口 上一节实现了静态服务器,但是当…...

Understanding Lockup Cells
工具会分析扫描链和EDT逻辑之间的控制时序元素的时钟的时序关系,当必须要同步时钟并保持数据完整性时插入边沿触发寄存器(lockup cells)。 可以使用report_edt_lockup_cells命令来展示工具已经插入的lockup cells的详细报告。 Lockup Cell Insertion 工具会分析控制时序元…...

javaCV实现java图片ocr提取文字效果
引入依赖: <dependency><groupId>org.bytedeco</groupId><artifactId>javacv-platform</artifactId><version>1.5.5</version></dependency> 引入中文语言训练数据集:chi_sim GitHub - tesseract-ocr…...
七牛云OSS存储
前言: 七牛云的存储项目的附件,需要开发一套七牛云的工具类,可以使用该工具类进行七牛云服务器进行文件的上传与下载操作; 七牛云的文档学习: 相关的依赖项的配置: <dependency><groupId>com.amazonaws</groupId><artifactId>aws-java-sdk-s3…...
11.物联网lwip,网卡原理
一。LWIP协议栈内存管理 1.LWIP内存管理方案 (1)堆heap 1.灰色为已使用内存 2.黑色为未使用内存 3.紫色为使用后内存 按照某种算法,把数据放在内存块中 (2)池pool 设置内存池,设置成大小相同的内存块。 2…...

合同系统功能详解:相对方管理
上一期,我们讲解了合同系统的业务功用。本期开始,我们将逐一对合同系统的核心功能进行拆解,结合实际业务场景展开详细讲解。今天,我们重点介绍合同系统中的相对方管理功能。 在实际业务落地过程中,不同企业的经营业态…...

2026网盘横评:国民级云盘领衔,这几款备选也值得一看
前言作为长期接触AI资源、代码项目、大文件存储的从业者,日常高频使用各类网盘。很多朋友都会纠结主流网盘该如何选择,不同产品的存储能力、传输表现、功能适配差距明显。本文摒弃夸张测评,以客观分享的视角,从传输、存储、功能、…...

淘金币自动化脚本:每天节省20分钟,解放双手的终极指南
淘金币自动化脚本:每天节省20分钟,解放双手的终极指南 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.com/gh_mirrors/ta/taojinb…...

2026 网络安全渗透测试行业报告|机遇与前景
随着数字化转型的深入和网络威胁的日益复杂化,网络安全渗透测试行业在2025年迎来了前所未有的发展机遇与挑战。本文基于最新行业数据、招聘趋势与技术演进,全面剖析当前渗透测试行业的市场规模、人才供需、薪资水平、技术变革及未来发展方向,…...

Orbit存储系统完全指南:SQLite、IndexedDB与Firestore三大方案深度解析
Orbit存储系统完全指南:SQLite、IndexedDB与Firestore三大方案深度解析 【免费下载链接】orbit Experimental spaced repetition platform for exploring ideas in memory augmentation and programmable attention 项目地址: https://gitcode.com/gh_mirrors/orb…...

读《AI时代成为行业精英的融合型学习法》
这段时间看了日本科普作家竹内熏写的《AI时代成为行业精英的融合型学习法》一书,想说说自己的体会。这是一本很薄的书,一共100来页,个人觉得,在现在这个什么都不会的小白也能用AI写出几万字文章的时代,这本书可以算得上…...

毕业设计精选【芳心科技】无人机定点投放控制
实物效果图:实现功能:本次设计的目的是实现无人机在空中投放物品的落点计算,系统的核心是单片机,它控制本系统的各种功能,所以它的选择是非常重要的,在本设计中选用的是GD32F103C8T6单片机,这款…...

AMD Ryzen SMU Debug Tool完整指南:轻松掌握硬件级调试的5个关键步骤
AMD Ryzen SMU Debug Tool完整指南:轻松掌握硬件级调试的5个关键步骤 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地…...

福州儿童康复推荐
当我们谈论儿童康复时,其实是在谈论一个家庭面对未知时的所有期许与不安。每一个孩子的成长节奏都值得被尊重,尤其是那些在语言、社交或行为上稍显“慢热”的小天使。在福州,有这样一处地方,它不追求“速成”,也不承诺…...

用Python复现黏菌算法SMA:从生物觅食到代码优化的完整实战
用Python复现黏菌算法SMA:从生物觅食到代码优化的完整实战 黏菌算法(Slime Mould Algorithm, SMA)作为一种新兴的智能优化算法,近年来在工程优化、机器学习参数调优等领域展现出独特优势。本文将带您从生物行为理解到Python实现&a…...