clickhouse-配置解释
详细内容看官网文档
一、全局服务配置
1.配置详解
| 名称 | 含义 | 默认值 |
|---|---|---|
| allow_use_jemalloc_memory | 允许使用 jemalloc 内存 | 1(布尔) |
| asynchronous_heavy_metrics_update_period_s | 更新异步指标的时间段(以秒为单位) | 120 |
| asynchronous_metrics_update_period_s | 更新异步指标的时间段(以秒为单位) | 1 |
| background_buffer_flush_schedule_pool_size | 将用于在后台对缓冲区引擎表执行刷新操作的最大线程数 | 16 |
| background_common_pool_size | 将用于在后台对 *MergeTree 引擎表执行各种操作(主要是垃圾回收)的最大线程数 | 8 |
| background_distributed_schedule_pool_size | 将用于执行分布式发送的最大线程数 | 16 |
| background_fetches_pool_size | 将用于从后台 *MergeTree 引擎表的另一个副本获取数据部分的最大线程数 | 8 |
| background_merges_mutations_concurrency_ratio | 设置线程数与可以同时执行的后台合并和突变数之间的比率。 例如,如果比率等于2并且background_pool_size设置为16,那么ClickHouse可以同时执行32个后台合并。 这是可能的,因为后台操作可以暂停和推迟。 这是为小型合并提供更多执行优先级所必需的。 您只能在运行时增加此比率。 要降低它,您必须重新启动服务器。 与background_pool_size设置相同的background_merges_mutations_concurrency_ratio可以从默认配置文件中应用以实现向后兼容性。 | 2(float) |
| background_merges_mutations_scheduling_policy | 关于如何执行后台合并和突变调度的策略。 可能的值为:round_robin 和shortest_task_first round_robin — 每个并发合并和变异都按循环顺序执行,以确保无饥饿操作。 较小的合并比较大的合并完成得更快,因为它们需要合并的块较少。 shortest_task_first — 始终执行较小的合并或突变。 合并和突变根据其结果大小分配优先级。 较小尺寸的合并优先于较大尺寸的合并。 此策略可确保以最快的速度合并小部分,但可能会导致 INSERT 严重过载的分区中的大合并无限期匮乏。 | round_robin |
| background_message_broker_schedule_pool_size | 将用于执行消息流的后台操作的最大线程数 | 16 |
| background_move_pool_size | 将用于将数据部分移动到后台 *MergeTree 引擎表的另一个磁盘或卷的最大线程数 | 8 |
| background_pool_size | 设置使用 MergeTree 引擎对表执行后台合并和突变的线程数。 您只能在运行时增加线程数。 要减少线程数,您必须重新启动服务器。 通过调整此设置,您可以管理 CPU 和磁盘负载。 较小的池大小使用较少的 CPU 和磁盘资源,但后台进程进展较慢,最终可能会影响查询性能。 在更改之前,还请查看相关的 MergeTree 设置,例如 number_of_free_entries_in_pool_to_lower_max_size_of_merge 和 number_of_free_entries_in_pool_to_execute_mutation。 | 16 |
| background_schedule_pool_size | 将用于不断对复制表、Kafka 流式处理和 DNS 缓存更新执行某些轻量级定期操作的最大线程数。 | 128 |
| backup_threads | 执行备份请求的最大线程数 | 16 |
| backups_io_thread_pool_queue_size | 备份 IO 线程池上可以调度的最大作业数。 由于当前的 S3 备份逻辑,建议保持此队列不受限制 (0)。 | 0 |
| cache_size_to_ram_max_ratio | 将缓存大小设置为 RAM 最大比率。允许降低低内存系统上的缓存大小 | 0.5 |
| concurrent_threads_soft_limit_num | 允许运行所有查询的最大查询处理线程数(不包括用于从远程服务器检索数据的线程)。 这不是硬性限制。 万一达到限制,查询仍将至少有一个线程运行。 如果有更多线程可用,查询可以在执行期间扩展到所需的线程数。 | 0 |
| concurrent_threads_soft_limit_ratio_to_cores | 与 concurrent_threads_soft_limit_num 相同,但具有与核心的比率。 | 0 |
| default_database | 默认数据库名称 | default |
| disable_internal_dns_cache | 禁用内部 DNS 缓存。 建议在基础设施经常变化的系统(例如 Kubernetes)中运行 ClickHouse。 | 0(布尔) |
| dns_cache_update_period | 内部 DNS 缓存更新周期(以秒为单位) | 15 |
| dns_max_consecutive_failures | 从 ClickHouse DNS 缓存中删除主机之前的最大连续解析失败次数 | 1024 |
| index_mark_cache_size | 索引标记的缓存大小。零表示禁用 此设置可以在运行时修改,并将立即生效。 | 0 |
| index_uncompressed_cache_size | 合并树索引的未压缩块的缓存大小。零表示禁用 此设置可以在运行时修改,并将立即生效 | 0 |
| io_thread_pool_queue_size | IO 线程池的队列大小。零表示无限制。 | 10000 |
| mark_cache_policy | 标记缓存策略名称 | SLRU |
| mark_cache_size | 标记的缓存大小(合并树系列表的索引) 此设置可以在运行时修改,并将立即生效 | 5368709120 |
| max_backup_bandwidth_for_server | 服务器上所有备份的最大读取速度(以字节/秒为单位)。零表示无限制 | 0 |
| max_backups_io_thread_pool_free_size | 如果Backups IO Thread池中的空闲线程数量超过max_backup_io_thread_pool_free_size,ClickHouse将释放空闲线程占用的资源并减小池大小。 如果需要,可以再次创建线程。 | 0 |
| max_backups_io_thread_pool_size | 用于备份查询的 IO 操作的最大线程数 | 1000 |
| max_concurrent_queries | 并发执行查询总数的限制。 零意味着无限。 请注意,还必须考虑对插入和选择查询以及用户最大查询数的限制。 另请参见 max_concurrent_insert_queries、max_concurrent_select_queries、max_concurrent_queries_for_all_users。 零意味着无限。 此设置可以在运行时修改,并将立即生效。已在运行的查询将保持不变。 | 0 |
| max_concurrent_insert_queries | 并发插入查询总数的限制。零表示无限制 此设置可以在运行时修改,并将立即生效。已在运行的查询将保持不变 | 0 |
| max_concurrent_select_queries | 限制并发选择查询的总数。零表示无限制。 此设置可以在运行时修改,并将立即生效。已在运行的查询将保持不变 | 0 |
| max_connections | 最大服务器连接数 | 1024 |
| max_io_thread_pool_free_size | IO 线程池的最大可用大小 | 0 |
| max_io_thread_pool_size | 将用于 IO 操作的最大线程数 | 100 |
| max_local_read_bandwidth_for_server | 本地读取的最大速度(以字节/秒为单位)。零表示无限制 | 0 |
| max_local_write_bandwidth_for_server | 本地写入的最大速度(以字节/秒为单位)。零表示无限制 | 0 |
| max_partition_size_to_drop | 限制删除分区。如果 MergeTree 表的大小超过 max_partition_size_to_drop (以字节为单位),则无法使用 DROP PARTITION 查询删除分区。 此设置不需要重新启动 Clickhouse 服务器即可应用。 禁用限制的另一种方法是创建 /flags/force_drop_table 文件。 值 0 表示您可以不受任何限制地删除分区。 | 50GB |
| max_remote_read_network_bandwidth_for_server | 通过网络进行数据交换的最大速度,以字节/秒为单位进行读取。零表示无限制 | 0 |
| max_remote_write_network_bandwidth_for_server | 通过网络进行写入的数据交换的最大速度(以字节/秒为单位)。零表示无限制 | 0 |
| max_server_memory_usage | 总内存使用量限制。 零意味着无限。默认 max_server_memory_usage 值的计算方式为:memory_amount * max_server_memory_usage_to_ram_ratio。 | 0 |
| max_table_size_to_drop | 删除表的大小限制 | 50GB |
| max_temporary_data_on_disk_size | 可用于外部聚合、联接或排序的最大存储量。 超过此限制的查询将失败并出现异常。 零意味着无限。 另请参阅 max_temporary_data_on_disk_size_for_user 和 max_temporary_data_on_disk_size_for_query。 | 0 |
| max_thread_pool_free_size | 如果全局线程池中的空闲线程数大于 max_thread_pool_free_size,则 ClickHouse 会释放部分线程占用的资源,并减小池大小。 如果需要的话可以再次创建线程 | 1000 |
| max_thread_pool_size | 可以从操作系统分配并用于查询执行和后台操作的最大线程数 | 10000 |
| mmap_cache_size | 设置映射文件的缓存大小(以字节为单位)。 此设置可以避免频繁的打开/关闭调用(由于随之而来的页面错误,这非常昂贵),并可以重用来自多个线程和查询的映射。 设置值为映射区域的数量(通常等于映射文件的数量)。 可以使用 MMappedFiles 和 MMappedFileBytes 指标在表 system.metrics 和 system.metric_log 中监视映射文件中的数据量。 此外,在 system.asynchronous_metrics 和 system.asynchronous_metrics_log 中通过 MMapCacheCells 指标,在 system.events、system.processes、system.query_log、system.query_thread_log、system.query_views_log 中通过 CreatedReadBufferMMap、CreatedReadBufferMMapFailed、MMappedFileCacheHits、MMappedFileCacheMisses 事件。 请注意,映射文件中的数据量不会直接消耗内存,并且不会计入查询或服务器内存使用量中,因为该内存可以像操作系统页面缓存一样被丢弃。 在删除 MergeTree 系列表中的旧部分时,缓存会自动删除(文件被关闭),也可以通过 SYSTEM DROP MMAP CACHE 查询手动删除。 此设置可以在运行时修改 | 1000 |
| restore_threads | 执行还原请求的最大线程数 | 16 |
| show_addresses_in_stack_traces | 如果设置为 true,将在堆栈跟踪中显示地址 | 1(布尔) |
| shutdown_wait_unfinished_queries | 如果设置为 true,ClickHouse 将等待运行查询完成,然后再关闭。 | 0(布尔) |
| temporary_data_in_cache | 使用此选项,临时数据将存储在特定磁盘的缓存中。 在本节中,您应该指定具有类型缓存的磁盘名称。 在这种情况下,缓存和临时数据将共享相同的空间,并且可以逐出磁盘缓存以创建临时数据。 只能使用一个选项来配置临时数据存储:tmp_path、tmp_policy、temporary_data_in_cache。 | |
| thread_pool_queue_size | 全局线程池上可以调度的最大作业数。 增加队列大小会导致更大的内存使用量。 建议将此值保持等于 max_thread_pool_size。 零意味着无限。 | 10000 |
| tmp_policy | 包含临时数据的存储策略 只能使用一个选项来配置临时数据存储:tmp_path、tmp_policy、temporary_data_in_cache。 move_factor、keep_free_space_bytes、max_data_part_size_bytes 和 被忽略。 策略应该只有一个带有本地磁盘的卷。 | |
| uncompressed_cache_policy | 未压缩的缓存策略名称 | SLRU |
| uncompressed_cache_size | 合并树系列中的表引擎使用的未压缩数据的高速缓存大小(以字节为单位)。零表示禁用。服务器有一个共享缓存。内存按需分配。如果启用了选项 use_uncompressed_cache,则使用缓存。在个别情况下,未压缩的缓存对于非常短的查询是有利的。 此设置可以在运行时修改,并将立即生效 | 0 |
| builtin_dictionaries_reload_interval | 重新加载内置词典之前的间隔(以秒为单位)。ClickHouse每x秒重新加载一次内置词典。这样就可以“动态”编辑词典,而无需重新启动服务器 | 3600 |
| compression | 合并树引擎表的数据压缩设置,如果您刚刚开始使用ClickHouse,请不要使用它。 case内容如下: min_part_size – 数据部分的最小大小。 min_part_size_ratio – 数据部分大小与表大小的比率。 method——压缩方法。 可接受的值:lz4、lz4hc、zstd、deflate_qpl。 level – 压缩级别。 | |
| encryption | 配置命令以获取加密编解码器使用的密钥。 密钥(或多个密钥)应写入环境变量或在配置文件中设置。密钥可以是十六进制或长度等于 16 字节的字符串。 | |
| custom_settings_prefixes | 自定义设置的前缀列表。前缀必须用逗号分隔。 | |
| core_dump | 配置核心转储文件大小的软限制 | 1073741824 (1 GB) |
| database_atomic_delay_before_drop_table_sec | 设置删除表数据之前的延迟(以秒为单位)。 如果查询具有 SYNC 修饰符,则忽略此设置。 | 480 (8 minute) |
| database_catalog_unused_dir_hide_timeout_sec | 从 store/ 目录清理垃圾的任务的参数。 如果某些子目录未被 clickhouse-server 使用,并且该目录在最后的 database_catalog_unused_dir_hide_timeout_sec 秒内没有被修改,则该任务将通过删除所有访问权限来“隐藏”该目录。 它也适用于 clickhouse-server 不希望在 store/ 中看到的目录。 零意味着“立即”。 | 3600 (1 hour) |
| database_catalog_unused_dir_rm_timeout_sec | 从 store/ 目录清理垃圾的任务的参数。 如果某些子目录未被 clickhouse-server 使用并且之前已“隐藏”(请参阅database_catalog_unused_dir_hide_timeout_sec),并且在最后的database_catalog_unused_dir_rm_timeout_sec 秒内未修改此目录,则任务将删除此目录。 它也适用于 clickhouse-server 不希望在 store/ 中看到的目录。 零意味着“从不”。 | 2592000 (30 days) |
| database_catalog_unused_dir_cleanup_period_sec | 从 store/ 目录清理垃圾的任务的参数。 设置任务的调度周期。 零意味着“从不”。 | 86400 (1 day) |
| default_profile | 设置配置文件位于参数 user_config 中指定的文件中。 | |
| default_replica_name | ZooKeeper 中的副本名称 | |
| dictionaries_config | 字典配置文件的路径,路径可以包含通配符 * 和 ? | |
| user_defined_executable_functions_config | 可执行的用户定义函数的配置文件的路径,路径可以包含通配符 * 和 ? | |
| dictionaries_lazy_load | 字典的延迟加载。如果为 true,则每个字典都会在第一次使用时创建。 如果字典创建失败,则使用该字典的函数将引发异常。如果为 false,则在服务器启动时创建所有字典,如果创建的字典太长或创建时出现错误,则服务器启动时不会创建这些字典,并继续尝试创建这些字典。 | true |
| format_schema_path | 包含输入数据方案的目录路径,例如 CapnProto 格式的方案。 | |
| graphite | 发送监控数据给graphite的配置 | |
| graphite_rollup | graphite细化数据的设置 | |
| http_port/https_port | 用于通过 HTTP 连接到服务器的端口 | |
| http_server_default_response | 访问 ClickHouse HTTP(s) 服务器时默认显示的页面。 默认值为“OK”。 (末尾有换行符) | |
| hsts_max_age | HSTS 的过期时间(以秒为单位)。 默认值为 0 表示 clickhouse 禁用 HSTS。 如果您设置一个正数,则 HSTS 将启用,并且 max-age 是您设置的数字。 | 0 |
| include_from | 包含替换的文件的路径。 | |
| interserver_listen_host | 对可以在 ClickHouse 服务器之间交换数据的主机的限制。 如果使用Keeper,不同Keeper实例之间的通信也会受到同样的限制。 默认值等于listen_host设置。 | |
| interserver_http_port | 用于在 ClickHouse 服务器之间交换数据的端口 | |
| interserver_http_host | 其他服务器可以用来访问该服务器的主机名。如果省略,则其定义方式与 hostname -f 命令相同。对于脱离特定的网络接口很有用。 | |
| interserver_https_port | 通过 HTTPS 在 ClickHouse 服务器之间交换数据的端口 | |
| interserver_https_host | 与 interserver_http_host 类似,不同之处在于该主机名可以被其他服务器用来通过 HTTPS 访问该服务器。 | |
| interserver_http_credentials | 用于在复制期间连接到其他服务器的用户名和密码。 服务器还使用这些凭据对其他副本进行身份验证。 因此,集群中所有副本的 interserver_http_credentials 必须相同。 默认情况下,如果省略 interserver_http_credentials 部分,则在复制期间不使用身份验证。 user——用户名。 password——密码。 allow_empty — 如果为 true,则即使设置了凭据,也允许其他副本无需身份验证即可连接。 如果为 false,则拒绝未经身份验证的连接。默认值:false。 old — 包含凭证轮换期间使用的旧用户和密码。 可以指定几个旧部分。 | |
| keep_alive_timeout | ClickHouse 在关闭连接之前等待传入请求的秒数 | 10秒 |
| listen_host | 对请求可以来自的主机的限制。 如果您希望服务器回答所有请求,请指定::。 | |
| listen_backlog | 侦听套接字的积压(待处理连接的队列大小)。侦听套接字的积压(待处理连接的队列大小)。通常不需要更改该值,因为:默认值足够大,并且为了接受客户端的连接,服务器有单独的线程。因此,即使您的 TcpExtListenOverflows(来自 nstat)非零并且该计数器随着 ClickHouse 服务器的增加而增加,也不意味着该值需要增加 | 4096 |
| logger | 日志设置 level – 日志记录级别。 可接受的值:跟踪、调试、信息、警告、错误。 log——日志文件。 包含按级别排列的所有条目。 errorlog – 错误日志文件。 size – 文件的大小。 适用于日志和错误日志。 一旦文件达到大小,ClickHouse 就会对其进行归档并重命名,并在其位置创建一个新的日志文件。 count – ClickHouse 存储的归档日志文件的数量。 console – 将日志和错误日志发送到控制台而不是文件。 要启用,请设置为 1 或 true。 Stream_compress – 使用 lz4 流压缩来压缩日志和错误日志。 要启用,请设置为 1 或 true。 | |
| send_crash_reports | 向clickhouse开发团队发送崩溃报考 | |
| macros | 复制表的参数替换 | |
| max_open_files | 打开文件的最大数量 | |
| merges_mutations_memory_usage_soft_limit | 设置允许使用多少 RAM 来执行merge(合并)和mutation(更新)操作。 零意味着无限。 如果 ClickHouse 达到此限制,它不会安排任何新的后台合并或突变操作,但会继续执行已安排的任务。 | |
| merges_mutations_memory_usage_to_ram_ratio | 默认的 merges_mutations_memory_usage_soft_limit 值的计算方式为:memory_amount * merges_mutations_memory_usage_to_ram_ratio。 | 0.5 |
| merge_tree | 对MergeTree中的表进行微调 | |
| metric_log | 默认情况下,它处于启用状态。如果不是,您可以手动执行此操作,如果要禁用则需要创建这个文件 /etc/clickhouse-server/config.d/disable_metric_log.xml,内容如下 <clickhouse><metric_log remove=“1” /></clickhouse> | |
| replicated_merge_tree | 对ReplicatedMergeTree中的表进行微调 | |
| openSSL | 加密链接配置,不做详细介绍 | |
| part_log | 记录与 MergeTree 关联的事件。 例如,添加或合并数据。 您可以使用日志来模拟合并算法并比较它们的特性。 您可以可视化合并过程。使用以下参数来配置日志记录: database – 数据库的名称。 table – 系统表的名称。 partition_by — 系统表的自定义分区键。 如果引擎已定义则无法用。 order_by - 系统表的自定义排序键。 如果引擎已定义则无法使用。 engine - 系统表的 MergeTree 引擎定义。 如果定义了partition_by或order_by则不能使用。 lush_interval_milliseconds – 将数据从内存缓冲区刷新到表的时间间隔。 max_size_rows – 日志的最大大小(以行为单位)。 当未刷新的日志量达到max_size时,日志转储到磁盘。 默认值:1048576。 served_size_rows – 为日志预先分配的内存大小(以行为单位)。 默认值:8192。 buffer_size_rows_flush_threshold – 行数阈值,达到该阈值会在后台将日志刷新到磁盘。 默认值:max_size_rows / 2。 lush_on_crash - 指示在发生崩溃时是否应将日志转储到磁盘。 默认值:false。 storage_policy – 用于表的存储策略的名称(可选) settings - 控制 MergeTree 行为的附加参数(可选)。 | |
| path | 包含数据的目录的路径 | |
| Prometheus | 指定接受指标数据的prometheus | |
| query_log | 用于记录通过 log_queries=1 设置接收到的查询的设置。查询记录在 system.query_log 表中,而不是单独的文件中。 您可以在表参数中更改表的名称(见下文)。使用以下参数来配置日志记录:(参数与part_log表一致)如果该表不存在,ClickHouse 将创建它。 如果ClickHouse服务器更新时查询日志的结构发生变化,旧结构的表将被重命名,并自动创建新表。 | |
| query_cache | 查询缓存允许仅计算查询一次,并直接从缓存中为同一查询的进一步执行提供服务。 根据查询的类型,这可以显着减少 ClickHouse 服务器select的延迟和资源消耗。 max_size_in_bytes:最大缓存大小(以字节为单位)。 0 表示查询缓存已禁用。 默认值:1073741824 (1 GiB)。 max_entries:缓存中存储的SELECT查询结果的最大数量。 默认值:1024。 max_entry_size_in_bytes:SELECT 查询结果可能必须保存在缓存中的最大大小(以字节为单位)。 默认值:1048576 (1 MiB)。 max_entry_size_in_rows:SELECT 查询结果可能要保存在缓存中的最大行数。 默认值:30000000(3000 万)。 更改立即生效 查询缓存的数据分配在 DRAM 中。 如果内存不足,请确保为 max_size_in_bytes 设置一个较小的值或完全禁用查询缓存。 | |
| query_thread_log | 用于记录通过 log_query_threads=1 设置接收的查询线程的设置。查询记录在 system.query_thread_log 表中。 | |
| query_views_log | 记录视图(实时、具体化等)的设置取决于使用 log_query_views=1 设置接收到的查询。查询记录在 system.query_views_log 表中,而不是单独的文件中。 | |
| text_log | 用于记录文本消息的text_log 系统表的设置。 多出的字段:level — 将存储在表中的最大消息级别(默认为Trace)。 | |
| trace_log | Trace_log系统表操作的设置。 | |
| asynchronous_insert_log | 用于记录异步插入的 asynchronous_insert_log 系统表的设置。 | |
| crash_log | crash_log系统表的设置 | |
| query_masking_rules | 基于正则表达式的规则,将应用于查询所有日志消息,然后将它们存储在服务器日志、system.query_log、system.text_log、system.processes 表以及发送到客户端的日志中。 这样可以防止敏感数据从 SQL 查询(如姓名、电子邮件、个人标识符或信用卡号)泄漏到日志中。配置字段: name - 规则的名称(可选) regexp - RE2 兼容的正则表达式(强制) replace - 敏感数据的替换字符串(可选,默认情况下 - 六个星号) 屏蔽规则应用于整个查询(以防止由于格式错误/不可解析的查询而泄漏敏感数据)。system.events 表有计数器 QueryMaskingRulesMatch,它具有查询屏蔽规则匹配的总数。对于分布式查询,每个服务器必须单独配置,否则,传递到其他节点的子查询将不加掩码地存储。 | |
| remote_servers | 分布式表引擎和簇表功能使用的簇的配置。 | |
| timezone | 时区 | |
| tcp_port | 通过 TCP 协议与客户端通信的端口。 | |
| tcp_port_secure | 用于与客户端安全通信的 TCP 端口。 将其与 OpenSSL 设置一起使用。 | 9440 |
| mysql_port | 通过mysql协议与客户端通信的端口 | |
| postgresql_port | 通过postgresql协议与客户端通信的端口 | |
| tmp_path | 本地文件系统上用于存储处理大型查询的临时数据的路径。只能使用一个选项来配置临时数据存储:tmp_path、tmp_policy、temporary_data_in_cache。尾部斜杠是强制性的。例如<tmp_path>/var/lib/clickhouse/tmp/</tmp_path> | |
| user_files_path | 包含用户文件的目录,规定了使用file()函数的路径 | |
| user_scripts_path | 包含用户脚本文件的目录。 用于可执行的用户定义函数 | |
| user_defined_path | 包含用户定义文件的目录。 用于 SQL 用户定义函数 | |
| users_config | 包含以下内容的文件的路径:用户配置。访问权。设置配置文件。配额设置。 | |
| zookeeper | 包含允许 ClickHouse 与 ZooKeeper 集群交互的设置。当使用复制表时,ClickHouse 使用 ZooKeeper 来存储副本的元数据。 如果不使用复制表,这部分参数可以省略。该部分包含以下参数: 节点 — ZooKeeper 端点。 您可以设置多个端点。 session_timeout_ms — 客户端会话的最大超时时间(以毫秒为单位)。 operation_timeout_ms — 一项操作的最大超时时间(以毫秒为单位)。 root — 用作 ClickHouse 服务器使用的 znode 的根的 znode。 选修的。 fallback_session_lifetime.min - 如果通过zookeeper_load_balancing策略解析的第一个zookeeper主机不可用,则将zookeeper会话的生命周期限制到后备节点。 这样做是为了负载平衡的目的,以避免其中一台 Zookeeper 主机负载过重。 此设置设置回退会话的最短持续时间。 以秒为单位设置。 选修的。 默认为 3 小时。 fallback_session_lifetime.max - 如果通过zookeeper_load_balancing策略解析的第一个zookeeper主机不可用,则将zookeeper会话的生命周期限制到后备节点。 这样做是为了负载平衡的目的,以避免其中一台 Zookeeper 主机负载过重。 此设置设置回退会话的最大持续时间。 以秒为单位设置。 选修的。 默认值为 6 小时。 identity — ZooKeeper 可能需要用户和密码来授予对所请求的 znode 的访问权限。 选修的。 Zookeeper_load_balancing - 指定 ZooKeeper 节点选择的算法,有以下几种算法。 random - 随机选择 ZooKeeper 节点之一。 in_order - 选择第一个 ZooKeeper 节点,如果不可用则选择第二个,依此类推。 nearest_hostname - 选择主机名与服务器主机名最相似的 ZooKeeper 节点。 first_or_random - 选择第一个 ZooKeeper 节点,如果它不可用,则随机选择剩余的 ZooKeeper 节点之一。 round_robin - 选择第一个 ZooKeeper 节点,如果发生重新连接,则选择下一个。 | |
| use_minimalistic_part_header_in_zookeeper | 此设置仅适用于 MergeTree 系列。 可以指定:全局位于 config.xml 文件的 merge_tree 部分。ClickHouse 使用服务器上所有表的设置。 您可以随时更改设置。 当设置更改时,现有表会更改其行为。对于每张表。创建表时,指定相应的引擎设置。 即使全局设置发生更改,具有此设置的现有表的行为也不会更改。可能的值0 — 功能已关闭。1 — 功能已打开。如果 use_minimalistic_part_header_in_zookeeper = 1,则复制表使用单个 znode 紧凑地存储数据部分的标头。 如果表包含很多列,这种存储方式会显着减少Zookeeper中存储的数据量。注意:应用use_minimalistic_part_header_in_zookeeper = 1 后,您无法将 ClickHouse 服务器降级到不支持此设置的版本。 在集群中的服务器上升级 ClickHouse 时要小心。 不要一次升级所有服务器。 在测试环境中或仅在集群的几台服务器上测试 ClickHouse 的新版本会更安全。已使用此设置存储的数据部分标头无法恢复为其之前的(非紧凑)表示形式。 | 0 |
| distributed_ddl | 管理在集群上执行分布式 ddl 查询(CREATE、DROP、ALTER、RENAME)。 仅当启用 ZooKeeper 时才有效。<distributed_ddl> 中的可配置设置包括: path:DDL查询的task_queue在Keeper中的路径 profile:用于执行DDL查询的配置文件 pool_size:可以同时运行多少个 ON CLUSTER 查询 max_tasks_in_queue:队列中可以容纳的最大任务数。 默认值为 1,000 task_max_lifetime:如果节点的年龄大于此值,则删除节点。 默认为 7 * 24 * 60 * 60(一周以秒为单位) cleanup_delay_period:如果上次清理没有早于 cleanup_delay_period 秒前进行,则在收到新节点事件后开始清理。 默认值为 60 秒 | |
| access_control_path | ClickHouse 服务器存储 SQL 命令创建的用户和角色配置的文件夹路径 | /var/lib/clickhouse/access/ |
| user_directories | 包含设置的配置文件部分:具有预定义用户的配置文件的路径。存储由 SQL 命令创建的用户的文件夹路径。ZooKeeper 节点路径,其中存储和复制由 SQL 命令创建的用户(实验)。如果指定此部分,则不会使用 users_config 和 access_control_path 中的路径。user_directories 部分可以包含任意数量的项目,项目的顺序意味着它们的优先级(项目越高优先级越高)。 | |
| total_memory_profiler_step | 设置每个峰值分配步骤的堆栈跟踪的内存大小(以字节为单位)。 query_id等于空字符串的话数据存储在system.trace_log系统表中, | 4194304 |
| total_memory_tracker_sample_probability | 允许收集随机分配和释放,并将它们写入 system.trace_log 系统表中,trace_type 等于具有指定概率的 MemorySample。 概率针对每次分配或取消分配,无论分配的大小如何。 请注意,仅当未跟踪内存量超过未跟踪内存限制(默认值为 4 MiB)时才会进行采样。 如果降低total_memory_profiler_step,则可以降低它。 您可以将total_memory_profiler_step设置为等于1以进行更细粒度的采样。0 — 禁止在 system.trace_log 系统表中写入随机分配和释放。 | 0 |
| compiled_expression_cache_size | 设置编译表达式的缓存大小(以字节为单位)。 | 134217728 |
| compiled_expression_cache_elements_size | 设置编译表达式的缓存大小(以元素为单位)。 | 10000 |
| display_secrets_in_show_and_select | 启用或禁用在表、数据库、表函数和字典的 SHOW 和 SELECT 查询中显示机密。希望查看机密的用户还必须打开 format_display_secrets_in_show_and_select 格式设置并具有 displaySecretsInShowAndSelect 权限。0禁用,1启用 | 0 |
2.配置示例
2.1 interserver_http_credentials的示例与详解:
ClickHouse 支持动态服务器间凭证轮换,无需同时停止所有副本来更新其配置。 可以通过几个步骤更改凭据。
要启用身份验证,请将 interserver_http_credentials.allow_empty 设置为 true 并添加凭据。 这允许有身份验证和无身份验证的连接。
<interserver_http_credentials><user>admin</user><password>111</password><allow_empty>true</allow_empty>
</interserver_http_credentials>
配置所有副本后,将allow_empty 设置为 false 或删除此设置。 它强制使用新凭据进行身份验证。
要更改现有凭据,请将用户名和密码移至 interserver_http_credentials.old 部分,并使用新值更新用户和密码。 此时,服务器使用新凭据连接到其他副本,并接受使用新或旧凭据的连接。
<interserver_http_credentials><user>admin</user><password>222</password><old><user>admin</user><password>111</password></old><old><user>temp</user><password>000</password></old>
</interserver_http_credentials>
将新凭据应用于所有副本时,可能会删除旧凭据
2.2 zookeeper配置模版
<zookeeper><node><host>example1</host><port>2181</port></node><node><host>example2</host><port>2181</port></node><session_timeout_ms>30000</session_timeout_ms><operation_timeout_ms>10000</operation_timeout_ms><!-- Optional. Chroot suffix. Should exist. --><root>/path/to/zookeeper/node</root><!-- Optional. Zookeeper digest ACL string. --><identity>user:password</identity><!--<zookeeper_load_balancing>random / in_order / nearest_hostname / first_or_random / round_robin</zookeeper_load_balancing>--><zookeeper_load_balancing>random</zookeeper_load_balancing>
</zookeeper>
2.3 distributed_ddl的设置
<distributed_ddl><!-- Path in ZooKeeper to queue with DDL queries --><path>/clickhouse/task_queue/ddl</path><!-- Settings from this profile will be used to execute DDL queries --><profile>default</profile><!-- Controls how much ON CLUSTER queries can be run simultaneously. --><pool_size>1</pool_size><!--Cleanup settings (active tasks will not be removed)--><!-- Controls task TTL (default 1 week) --><task_max_lifetime>604800</task_max_lifetime><!-- Controls how often cleanup should be performed (in seconds) --><cleanup_delay_period>60</cleanup_delay_period><!-- Controls how many tasks could be in the queue --><max_tasks_in_queue>1000</max_tasks_in_queue>
</distributed_ddl>
2.4 user_directories配置的示例和解释
<user_directories><users_xml><path>/etc/clickhouse-server/users.xml</path></users_xml><local_directory><path>/var/lib/clickhouse/access/</path></local_directory>
</user_directories>
Users, roles, row policies, quotas, and profiles 也可以存储在 ZooKeeper 中:
<user_directories><users_xml><path>/etc/clickhouse-server/users.xml</path></users_xml><replicated><zookeeper_path>/clickhouse/access/</zookeeper_path></replicated>
</user_directories>
您还可以定义部分内存 - 表示仅将信息存储在内存中,而不写入磁盘,而 ldap - 表示将信息存储在 LDAP 服务器上。
要将 LDAP 服务器添加为本地未定义的用户的远程用户目录,请使用以下参数定义单个 ldap 部分:
- server — ldap_servers 配置部分中定义的 LDAP 服务器名称之一。 该参数为必填项,不能为空。
- roles — 包含本地定义的角色列表的部分,这些角色将分配给从 LDAP 服务器检索到的每个用户。 如果未指定角色,用户在身份验证后将无法执行任何操作。 如果在身份验证时未在本地定义任何列出的角色,则身份验证尝试将失败,就像提供的密码不正确一样。
<ldap><server>my_ldap_server</server><roles><my_local_role1 /><my_local_role2 /></roles>
</ldap>
二、query-level的变量配置
1.配置和查询方法
有多种方法可以设置 ClickHouse 查询级别设置。 设置按层进行配置,每个后续层都会重新定义设置的先前值。
定义设置的优先级顺序是:
- 直接或在设置配置文件中将设置应用于用户
- SQL(推荐)
- 将一个或多个 XML 或 YAML 文件添加到 /etc/clickhouse-server/users.d
- 会话设置
- 从 ClickHouse Cloud SQL 控制台或 clickhouse 客户端以交互模式发送 SET setting=value。 同样,您可以在 HTTP 协议中使用 ClickHouse 会话。 为此,您需要指定 session_id HTTP 参数。
- 查询设置
- 非交互方式启动clickhouse客户端时,设置启动参数–setting=value。
- 使用 HTTP API 时,传递 CGI 参数(URL?setting_1=value&setting_2=value…)。
- 在 SELECT 查询的 SETTINGS 子句中定义设置。 设置值仅应用于该查询,并在执行查询后重置为默认值或之前的值。
1.1 创建用户时候直接设置
# 设置方法
CREATE USER ingester
IDENTIFIED WITH sha256_hash BY '7e099f39b84ea79559b3e85ea046804e63725fd1f46b37f281276aae20f86dc3'
SETTINGS async_insert = 1# 查看方法
SHOW ACCESS# 也可以通过设置profile来配置
CREATE
SETTINGS PROFILE log_ingest SETTINGS async_insert = 0CREATE USER ingester
IDENTIFIED WITH sha256_hash BY '7e099f39b84ea79559b3e85ea046804e63725fd1f46b37f281276aae20f86dc3'
SETTINGS PROFILE log_ingest
1.2 通过配置文件制定
<!-- /etc/clickhouse-server/users.d/users.xml-->
<clickhouse><profiles><log_ingest><async_insert>1</async_insert></log_ingest></profiles><users><ingester><password_sha256_hex>7e099f39b84ea79559b3e85ea046804e63725fd1f46b37f281276aae20f86dc3</password_sha256_hex><profile>log_ingest</profile></ingester><default replace="true"><password_sha256_hex>7e099f39b84ea79559b3e85ea046804e63725fd1f46b37f281276aae20f86dc3</password_sha256_hex><access_management>1</access_management><named_collection_control>1</named_collection_control></default></users>
</clickhouse>
1.3 设置session变量
# 这只是session级别变量
SET async_insert =1;
SELECT value FROM system.settings where name='async_insert';# 也可以设置变量为默认值,这样就会取这个变量的默认值来设置变量async_insert的默认值为0
SET async_insert = DEFAULT;
1.4 在查询中直接制定变量
INSERT INTO YourTable
SETTINGS async_insert=1
VALUES (...)
1.5 自定义变量的设置和查询
SET custom_a = 123;
# 这个查询可以查看query-level的value为true或者false的变量,具体值的变量无法查看
SELECT getSetting('custom_a');
2.具体配置
具体配置可看官方文档,后续会逐渐补充一些用到的配置
相关文章:

clickhouse-配置解释
详细内容看官网文档 一、全局服务配置 1.配置详解 名称含义默认值allow_use_jemalloc_memory允许使用 jemalloc 内存1(布尔)asynchronous_heavy_metrics_update_period_s更新异步指标的时间段(以秒为单位)120asynchronous_metr…...

基于亚马逊云科技无服务器服务快速搭建电商平台——性能篇
使用 Serverless 构建独立站的优势 在传统架构模式下,如果需要进行电商大促需要提前预置计算资源以支撑高并发访问,会造成计算资源浪费并且增加运维工作量。本文介绍一种新的部署方式,将 WordPress 和 WooCommerce 部署在 Amazon Lambda 中。…...

LINQ详解(查询表达式)
什么是LINQ? LINQ(语言集成查询)是将查询功能直接集成到C#中。数据查询表示简单的字符串,在编译时不会进行类型检查和IntelliSense(代码补全辅助工具)支持。 在开发中,通常需要对不同类型的数据源了解不同的查询语句,如SQL数据库…...

【DEVOPS】现状篇
0. 目录 1. 前言2. 现状2.1 需求管理2.2 开发流程2.3 测试流程2.4 部署流程2.5 维护阶段 3. 后记4. 相关 1. 前言 一直以来,深感内部工程化能力欠缺,急于将事情向前推进,总是希望能够向前走几步,再走几步。 可惜的是,…...

Linux文件管理知识:查找文件(第二篇)
Linux文件管理知识:查找文件(第二篇) 上篇文章详细介绍了linux系统中查找文件的工具或者命令程序locate和find命令的基本操作。那么,今天这篇文章紧接着查找文件相关操作内容介绍。 Find命令所属操作列表中的条目,有助于我们想要…...
医疗小程序:让服务更高效,用户体验更优化
随着移动互联网的快速发展,小程序已经成为了一个热门的开发方向。医疗健康类小程序也不例外,拥有广泛的市场需求和前景。本文将为你提供一份完整的医疗健康类小程序开发攻略,帮助你快速开发上线一个专业成熟的小程序商城。 一、选择合适的小程…...
C++11 std::transform函数使用说明
std::transform是C标准库中的一个算法,它用于对输入范围内的元素进行操作,并将结果存储在输出范围内。这个算法特别适合于将一种数据类型转换为另一种数据类型。 函数定义在头文件algorithm中 std::transform的基本语法如下: std::transfor…...

JavaScript-DOM查询
获取元素节点 获取元素节点的子节点 元素节点的属性 节点的修改 JavaScript中的DOM(文档对象模型)是一种编程接口,它允许JavaScript与HTML文档交互。创建DOM查询,可以使用多种方法. 获取元素节点 1. getElementById() – 通…...

大数据-玩转数据-Flink 水印
一、Flink 中的水印 在Flink的流式操作中, 会涉及不同的时间概念: 1.1 处理时间 是指的执行操作的各个设备的时间,对于运行在处理时间上的流程序, 所有的基于时间的操作(比如时间窗口)都是使用的设备时钟。比如, 一个长度为1个小时的窗口将会包含设备…...

【Apollo】阿波罗自动驾驶系统:驶向未来的智能出行(含源码安装)
前言 Apollo (阿波罗)是一个开放的、完整的、安全的平台,将帮助汽车行业及自动驾驶领域的合作伙伴结合车辆和硬件系统,快速搭建一套属于自己的自动驾驶系统。 开放能力、共享资源、加速创新、持续共赢是 Apollo 开放平台的口号。百度把自己所拥有的强大、…...

网络-Netty
how pipeline.addLast(ChannelHandler)...

如何使用vue-smooth-dnd
Vue Smooth DnD是一个基于Vue的平滑易用的拖放库。它提供了简单易用的API和可自定义的样式。 要使用Vue Smooth DnD,可以按照以下步骤进行操作: 安装Vue Smooth DnD npm install vue-smooth-dnd --save 在组件中引入Vue Smooth DnD import VueSmoot…...

为AWS认证做好准备:一份全面的备考指南
随着云计算的快速发展,越来越多的专业人士选择获取AWS(亚马逊网络服务)认证。这个认证不仅可以证明你对AWS的理解和专业技能,还有助于你在云计算领域获得更好的工作机会。 以下是一份全面的备考指南,帮助你为AWS认证做…...

尚硅谷SpringMVC
九、HttpMessageConverter...

django的简易的图书管理系统jsp书店进销存源代码MySQL
本项目为前几天收费帮学妹做的一个项目,Java EE JSP项目,在工作环境中基本使用不到,但是很多学校把这个当作编程入门的项目来做,故分享出本项目供初学者参考。 一、项目描述 django的简易的图书管理系统 系统有1权限:…...

力扣125. 验证回文串
125. 验证回文串 如果在将所有大写字符转换为小写字符、并移除所有非字母数字字符之后,短语正着读和反着读都一样。则可以认为该短语是一个 回文串 。 字母和数字都属于字母数字字符。 给你一个字符串 s,如果它是 回文串 ,返回 true &…...

用WebStorm创建Mock数据
WebStorm是一款强大的集成式开发环境,它集成了许多实用的功能,包括Mock数据的创建。 下面是用WebStorm创建Mock数据的步骤: 打开WebStorm,选择一个项目或新建一个项目;在项目中创建一个名为“mock”的文件夹…...

Python钢筋混凝土结构计算.pdf-已知弯矩确定混凝土梁截面尺寸
计算原理 确定混凝土梁截面的合理尺寸通常需要考虑弯矩、受力要求和约束条件等多个因素。以下是一种常见的计算公式,用于基于已知弯矩确定混凝土梁截面的合理尺寸: 请注意,以上公式仅提供了一种常见的计算方法,并且具体的规范和设…...

【正点原子STM32连载】第二十四章 高级定时器PWM输入模式实验 摘自【正点原子】APM32F407最小系统板使用指南
1)实验平台:正点原子stm32f103战舰开发板V4 2)平台购买地址:https://detail.tmall.com/item.htm?id609294757420 3)全套实验源码手册视频下载地址: http://www.openedv.com/thread-340252-1-1.html# 第二…...
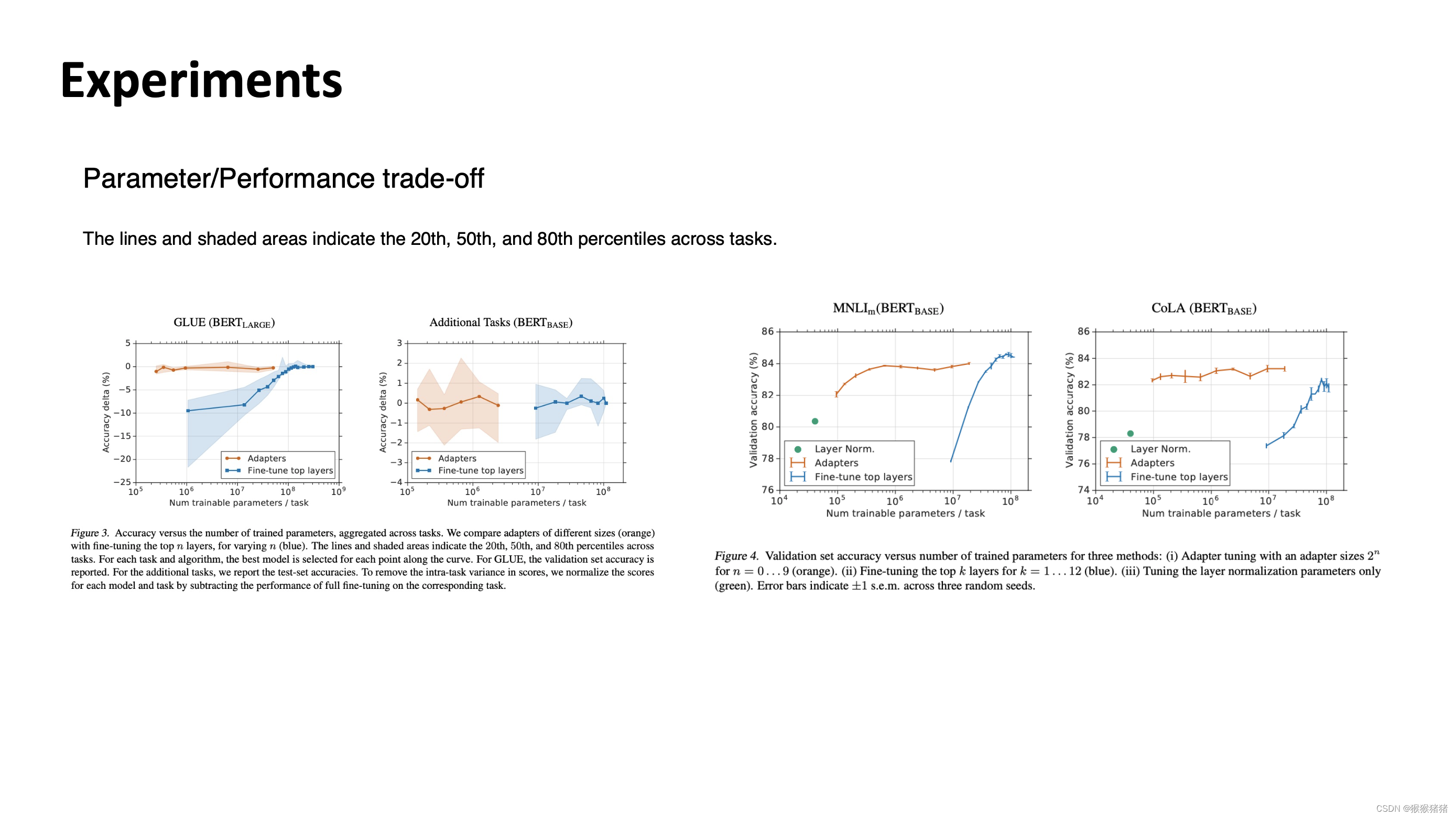
Adapter Tuning Overview:在CV,NLP,多模态领域的代表性工作
文章目录 Delta TuningAdapter Tuning in CVAdapter Tuning in NLP Delta Tuning Adapter Tuning in CV 题目: Learning multiple visual domains with residual adapters 机构:牛津VGG组 论文: https://arxiv.org/pdf/1705.08045.pdf Adapter Tuning in NLP …...
手机版通用)
杀戮尖塔2绅士mod官方正版2026最新版pc免费下载(看到请立即转存 资源随时失效)手机版通用
下载链接 解压密码:www.kdacg.com 基于响应式状态机的高清动态 UI 组件设计与跨平台渲染优化实践 在当前的企业级前端与交互设计开发中,如何在高复杂度的业务逻辑下,实现高清、高性能且具备强即时反馈的多模态动态 UI 组件,一直…...
)
苹果手机快速开启开发者模式教程(iOS 16+)
在Mac Xcode 给 iPhone 安装自签 IPA、做苹果 App 打包测试时,iOS 16 及以上的系统第一次启动这类"非 App Store 来源"的 App,都会弹一个 “需要启用开发者模式” 的提示,点"好"就退出了,App 根本进不去。 这是苹果从 iOS 16 开始加的安全限制:任何用开发…...

瑞芯微RV1126在无人机视觉AI应用:从芯片选型到部署实战
1. 项目概述:当国产芯遇上天空之眼最近几年,无人机早已不是航拍发烧友的专属玩具,它在农业植保、电力巡检、安防监控、测绘建模等专业领域大放异彩。在这些场景里,无人机不再仅仅是“会飞的相机”,它需要成为一台“会飞…...
如何用TranslucentTB实现Windows任务栏透明化:3分钟完成桌面美化终极指南
如何用TranslucentTB实现Windows任务栏透明化:3分钟完成桌面美化终极指南 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB 你是…...

如何免费打造终极跨平台音乐播放器:一站式解决你的所有音乐需求
如何免费打造终极跨平台音乐播放器:一站式解决你的所有音乐需求 【免费下载链接】VutronMusic 高颜值的第三方网易云播放器;支持流媒体音乐,如navidrome、jellyfin、emby;支持本地音乐播放、离线歌单、逐字歌词、桌面歌词、Touch …...

ElevenLabs蒙古文语音接入全攻略:从API密钥配置到蒙古文音素对齐的7步落地法
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs蒙古文语音接入的背景与技术价值 随着全球多语言AI语音技术加速演进,蒙古语作为联合国教科文组织列为“脆弱型”语言之一,其数字语音合成能力长期受限于高质量语音数据…...

如何5分钟部署小鹿快传:零基础P2P文件传输终极指南
如何5分钟部署小鹿快传:零基础P2P文件传输终极指南 【免费下载链接】deershare 小鹿快传,一款在线P2P文件传输工具,使用WebSocket WebRTC技术 项目地址: https://gitcode.com/gh_mirrors/de/deershare 小鹿快传(DeerShare…...

BilibiliDown音频提取终极指南:3种方法从B站视频提取高质量音乐
BilibiliDown音频提取终极指南:3种方法从B站视频提取高质量音乐 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_…...

用USRP B200mini和GNU Radio抓取大疆无人机位置:一个极客的无线安全实验手记
极客实验室:用USRP B200mini破解无人机通信协议实战指南 从零开始的SDR探险 去年夏天的一个傍晚,我在阳台上调试天线时,突然注意到头顶频繁掠过的无人机。这些飞行器究竟在传输什么数据?这个偶然的观察引发了我长达三个月的技术…...
)
新手避坑指南:用DFS软件读取安卓手机MEID和串码,手把手教你识别端口与驱动(附高低版本对比)
安卓设备底层参数读取实战:从端口识别到安全操作的完整指南 当第一次打开DFS这类专业工具时,许多安卓设备爱好者都会被满屏的专业术语和复杂界面吓退。901D、COM3、QC Diag…这些看似简单的端口名称背后,隐藏着芯片组、系统版本和驱动兼容性的…...