pytorch学习(8)——现有网络模型的使用以及修改
1 vgg16模型
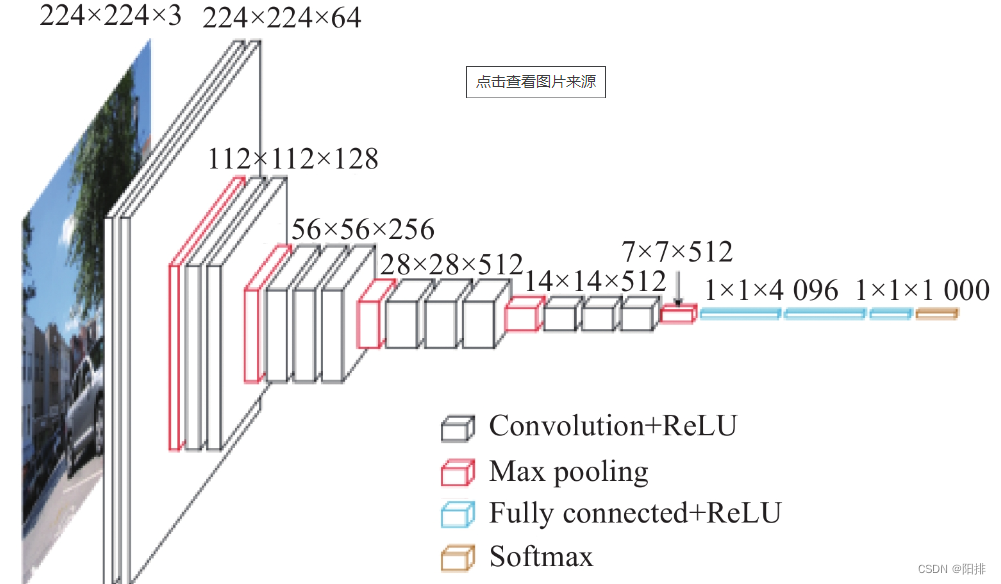
1.1 vgg16模型的下载
采用torchvision中的vgg16模型,能够实现1000个类型的图像分类,VGG模型在AlexNet的基础上使用3*3小卷积核,增加网络深度,具有很好的泛化能力。
首先下载vgg16模型,python代码如下:
import torchvision# 下载路径:C:\Users\win10\.cache\torch\hub\checkpoints
vgg16_false = torchvision.models.vgg16(pretrained=False)
vgg16_true = torchvision.models.vgg16(pretrained=True)
print("ok")
下载结果:
G:\Anaconda3\envs\pytorch\lib\site-packages\torchvision\models\_utils.py:208: UserWarning: The parameter 'pretrained' is deprecated since 0.13 and may be removed in the future, please use 'weights' instead.warnings.warn(
G:\Anaconda3\envs\pytorch\lib\site-packages\torchvision\models\_utils.py:223: UserWarning: Arguments other than a weight enum or `None` for 'weights' are deprecated since 0.13 and may be removed in the future. The current behavior is equivalent to passing `weights=None`.warnings.warn(msg)
G:\Anaconda3\envs\pytorch\lib\site-packages\torchvision\models\_utils.py:223: UserWarning: Arguments other than a weight enum or `None` for 'weights' are deprecated since 0.13 and may be removed in the future. The current behavior is equivalent to passing `weights=VGG16_Weights.IMAGENET1K_V1`. You can also use `weights=VGG16_Weights.DEFAULT` to get the most up-to-date weights.warnings.warn(msg)
ok
1.2 vgg16模型内部结构
查看预训练的模型和未预训练的模型的内部结构:
import torchvisionvgg16_false = torchvision.models.vgg16(pretrained=False)
vgg16_true = torchvision.models.vgg16(pretrained=True)print(vgg16_true)
print(vgg16_false)
预训练的模型和未预训练的模型在整体结构上相同,但内部节点的参数(weight和bias)有所不同。
输出结果如下:
VGG((features): Sequential((0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(1): ReLU(inplace=True)(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(3): ReLU(inplace=True)(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(6): ReLU(inplace=True)(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(8): ReLU(inplace=True)(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(11): ReLU(inplace=True)(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(13): ReLU(inplace=True)(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(15): ReLU(inplace=True)(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(18): ReLU(inplace=True)(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(20): ReLU(inplace=True)(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(22): ReLU(inplace=True)(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(25): ReLU(inplace=True)(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(27): ReLU(inplace=True)(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(29): ReLU(inplace=True)(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False))(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))(classifier): Sequential((0): Linear(in_features=25088, out_features=4096, bias=True)(1): ReLU(inplace=True)(2): Dropout(p=0.5, inplace=False)(3): Linear(in_features=4096, out_features=4096, bias=True)(4): ReLU(inplace=True)(5): Dropout(p=0.5, inplace=False)(6): Linear(in_features=4096, out_features=1000, bias=True))
)
可以发现(classifier)中最后一层可以发现out_features=1000,表示该模型能够支持1000种类型的图像分类。
2 迁移学习
迁移学习是机器学习的一个子领域,它允许一个已经在一个任务上训练好的模型用于另一个但相关的任务。通过这种方式,模型可以借用在原任务上学到的知识,从而更快地、更准确地完成新任务。
本文采用CIFAR10数据集,内部包含10个种类的图像,修改vgg16模型对数据集进行图像分类。为了将此数据集代入vgg16模型,需要对模型进行修改。
(classifier): Sequential(... ...(6): Linear(in_features=4096, out_features=1000, bias=True)
)
2.1 添加层
使用add_module()函数添加模块。由于最后的归一化层为4096通道输出转1000通道输出,因此添加一个归一化层将1000通道输出转换为10通道输出。
import torchvision
from torch import nnvgg16_true = torchvision.models.vgg16(pretrained=True)
print(vgg16_true)vgg16_true.classifier.add_module('add_linear', nn.Linear(1000, 10))
print(vgg16_true)
输出结果(部分):
(classifier): Sequential((0): Linear(in_features=25088, out_features=4096, bias=True)(1): ReLU(inplace=True)(2): Dropout(p=0.5, inplace=False)(3): Linear(in_features=4096, out_features=4096, bias=True)(4): ReLU(inplace=True)(5): Dropout(p=0.5, inplace=False)(6): Linear(in_features=4096, out_features=1000, bias=True)(add_linear): Linear(in_features=1000, out_features=10, bias=True))
2.2 修改层
对classifier内的第6层进行修改。由于最后的归一化层为4096通道输出转1000通道输出,因此需要修改为4096通道输出转换为10通道输出。
import torchvision
from torch import nnvgg16_false = torchvision.models.vgg16(pretrained=False)
print(vgg16_false)vgg16_false.classifier[6] = nn.Linear(4096, 10)
print(vgg16_false)
输出结果(部分):
(classifier): Sequential((0): Linear(in_features=25088, out_features=4096, bias=True)(1): ReLU(inplace=True)(2): Dropout(p=0.5, inplace=False)(3): Linear(in_features=4096, out_features=4096, bias=True)(4): ReLU(inplace=True)(5): Dropout(p=0.5, inplace=False)(6): Linear(in_features=4096, out_features=10, bias=True))
2.3 模型保存
有两种方式保存模型数据。第一种保存方式是将模型结构和模型参数保存,第二种保存方式只是保存模型参数,以字典类型保存。
python代码如下:
import torch
import torchvision
from torch import nn
from torch.nn import Linear, Conv2d, MaxPool2d, Flatten, Sequential, CrossEntropyLossvgg16_false = torchvision.models.vgg16(pretrained=False) # 未经过训练的模型# 保存方式1,模型结构+模型参数
torch.save(vgg16_false, "G:\\Anaconda\\pycharm_pytorch\\learning_project\\model\\vgg16_method1.pth")# 保存方式2,模型参数(官方推荐)
torch.save(vgg16_false.state_dict(), "G:\\Anaconda\\pycharm_pytorch\\learning_project\\model\\vgg16_method2.pth")
保存修改过的模型或自己的编写的模型:
# 保存模型和导入模型时都需要导入MYNN这个类
class MYNN(nn.Module):def __init__(self):super(MYNN, self).__init__()self.model1 = Sequential(Conv2d(3, 32, 5, padding=2, stride=1),MaxPool2d(2),Conv2d(32, 32, 5, padding=2, stride=1),MaxPool2d(2),Conv2d(32, 64, 5, padding=2, stride=1),MaxPool2d(2),Flatten(),Linear(1024, 64),Linear(64, 10))def forward(self, x):x = self.model1(x)return xmynn = MYNN()
torch.save(mynn, "G:\\Anaconda\\pycharm_pytorch\\learning_project\\model\\mynn_method1.pth")
以上两部分Python代码运行结果如下:
2.4 模型导入
有两种方式导入模型数据。第一种导入方式能够直接使用,第二种导入方法需要将字典数据导入原来的网络模型。
import torch
import torchvision
from torch import nn
from torch.nn import Linear, Conv2d, MaxPool2d, Flatten, Sequential, CrossEntropyLoss# 方式1:加载模型
vgg16_import = torch.load("G:\\Anaconda\\pycharm_pytorch\\learning_project\\model\\vgg16_method1.pth")
print(vgg16_import)# 方式2:加载模型(字典数据)
vgg16_import2 = torch.load("G:\\Anaconda\\pycharm_pytorch\\learning_project\\model\\vgg16_method2.pth")
vgg16_new = torchvision.models.vgg16(pretrained=False) # 重新加载模型
vgg16_new.load_state_dict(vgg16_import2) # 将数据填入模型
print(vgg16_import2)
print(vgg16_new)
导入保存的自己的模型,python代码如下:
# 需要导入自己网络模型
class MYNN(nn.Module):def __init__(self):super(MYNN, self).__init__()self.model1 = Sequential(Conv2d(3, 32, 5, padding=2, stride=1),MaxPool2d(2),Conv2d(32, 32, 5, padding=2, stride=1),MaxPool2d(2),Conv2d(32, 64, 5, padding=2, stride=1),MaxPool2d(2),Flatten(),Linear(1024, 64),Linear(64, 10))def forward(self, x):x = self.model1(x)return xmodel = torch.load("G:\\Anaconda\\pycharm_pytorch\\learning_project\\model\\mynn_method1.pth")
print(model)
自己的网络模型导入运行结果:
MYNN((model1): Sequential((0): Conv2d(3, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))(1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(2): Conv2d(32, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(4): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(6): Flatten(start_dim=1, end_dim=-1)(7): Linear(in_features=1024, out_features=64, bias=True)(8): Linear(in_features=64, out_features=10, bias=True))
)
完整的模型训练套路-GPU训练
模型验证套路
Github上的代码
相关文章:
pytorch学习(8)——现有网络模型的使用以及修改
1 vgg16模型 1.1 vgg16模型的下载 采用torchvision中的vgg16模型,能够实现1000个类型的图像分类,VGG模型在AlexNet的基础上使用3*3小卷积核,增加网络深度,具有很好的泛化能力。 首先下载vgg16模型,python代码如下&…...

get和post请求的区别
GET和POST是HTTP请求的两种方法,其区别如下 ① GET请求表示从指定的服务器中获取数据(请求数据),比如查询用户信息;POST请求表示将数据提交到指定的服务器进行处理(发送数据), ② GET请求是一个幂等的请求,一般用于对服务器资源不会产生影响的场景,比如说请求一个网友的…...

extern “C”关键字的作用
目录 概述C和C在函数调用和变量命名等方面的差异示例总结 概述 extern "C"是用于在C中声明使用C语言编写的函数和变量的关键字。C和C在函数调用和变量命名等方面存在一些差异,为了在C代码中正确地使用C语言的函数和变量,需要使用extern "…...

使用ffmpeg截取视频片段
本文将介绍2中使用ffmpeg截取视频的方法 指定截取视频的 开始时间 和 结束时间,进行视频截取指定截取视频的 开始时间 和 截取的秒数,进行视频截取 两种截取方式的命令行如下 截取某一时间段视频 优先使用 ffmpeg -i ./input.mp4 -c:v libx264 -crf…...

Python教程(11)——Python中的字典dict的用法介绍
dict的用法介绍 创建字典访问字典修改字典删除字典字典的相关函数 列表虽然好,但是如果需要快速的数据查找,就必须进行需要遍历,也就是最坏情况需要遍历完一遍才能找到需要的那个数据,时间复杂度是O(n),显然这个速度是…...

三道dfs题
一:1114. 棋盘问题 - AcWing题库 分别枚举行和列,能填的地方就填,dfs就行 #include <iostream> using namespace std;const int N 10; char g[N][N]; int n, k; int res; bool st[N];void dfs(int u, int cnt) // u枚举行 {if(cnt …...
Seaborn数据可视化(四)
目录 1.绘制箱线图 2.绘制小提琴图 3.绘制多面板图 4.绘制等高线图 5.绘制热力图 1.绘制箱线图 import seaborn as sns import matplotlib.pyplot as plt # 加载示例数据(例如,使用seaborn自带的数据集) tips sns.load_dataset("t…...

kubernetes deploy standalone mysql demo
kubernetes 集群内部署 单节点 mysql ansible all -m shell -a "mkdir -p /mnt/mysql/data"cat mysql-pv-pvc.yaml apiVersion: v1 kind: PersistentVolume metadata:name: mysql-pv-volumelabels:type: local spec:storageClassName: manualcapacity:storage: 5Gi…...
)
【Map】Map集合有序与无序测试案例:HashMap,TreeMap,LinkedHashMap(121)
简单介绍常用的三种Map:不足之处,欢迎指正! HashMap:put数据是无序的; TreeMap:key值按一定的顺序排序;数字做key,put数据是有序,非数字字符串做key,put数据…...
TiDB Serverless Branching:通过数据库分支简化应用开发流程
2023 年 7 月 10 日,TiDB Serverless 正式商用。这是一个完全托管的数据库服务平台(DBaaS),提供灵活的集群配置和基于用量的付费模式。紧随其后,TiDB Serverless Branching 的测试版也发布了。 TiDB Serverless Branc…...
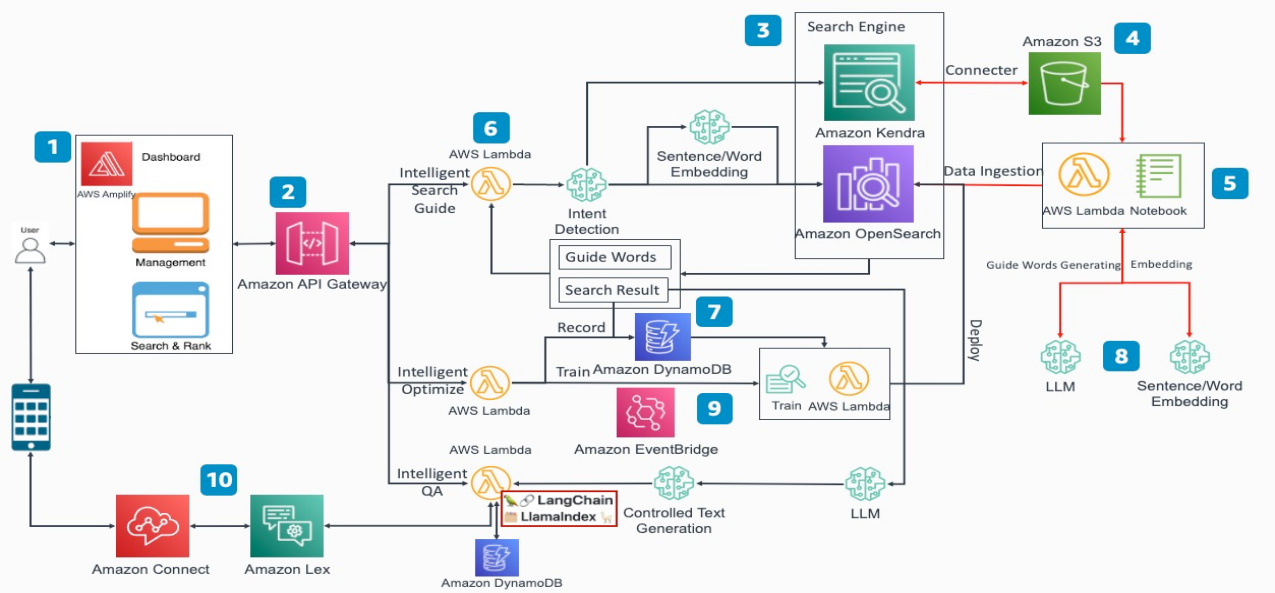
运用亚马逊云科技Amazon Kendra,快速部署企业智能搜索应用
亚马逊云科技Amazon Kendra是一项由机器学习(ML)提供支持的企业搜索服务。Kendra内置数据源连接器,支持快速访问Amazon S3、AmazonRDS、AmazonFSX以及其他外部数据源,帮助用户自动提取文档并建立索引。Kendra支持超过30多种多国语…...

C# 使用 OleDbConnection 连接读取Excel的方法
Connection类有四种:SqlConnection,OleDbConnection,OdbcConnection和OracleConnection。 (1)Sqlconnetcion类的对象连接是SQL Server数据库; (2)OracleConnection类的对象连接Oracle数据库&…...

【LeetCode-中等题】98. 验证二叉搜索树
文章目录 题目方法一:BFS 层序遍历方法二: 递归方法三: 中序遍历(栈)方法四: 中序遍历(递归) 题目 思路就是首先得知道什么是二叉搜索树 左孩子在(父节点的最小值&#x…...

Leetcode-每日一题【剑指 Offer 37. 序列化二叉树】
题目 请实现两个函数,分别用来序列化和反序列化二叉树。 你需要设计一个算法来实现二叉树的序列化与反序列化。这里不限定你的序列 / 反序列化算法执行逻辑,你只需要保证一个二叉树可以被序列化为一个字符串并且将这个字符串反序列化为原始的树结构。 …...

删除无点击数据offer数据分析使用
梳理思路: 1、 获取 7month 和 8month fullreport 报表中 所有offer;输出结果:offerid, totalClickCount; 2、 分析数据7month totalClickCount0 and 8month totalClickCount0 的offer去除; result.…...

【Apollo学习笔记】——规划模块TASK之SPEED_BOUNDS_PRIORI_DECIDER
文章目录 前言SPEED_BOUNDS_PRIORI_DECIDER功能简介SPEED_BOUNDS_PRIORI_DECIDER相关配置SPEED_BOUNDS_PRIORI_DECIDER流程将障碍物映射到ST图中ComputeSTBoundary(PathDecision* path_decision)ComputeSTBoundary(Obstacle* obstacle)GetOverlapBoundaryPointsComputeSTBounda…...
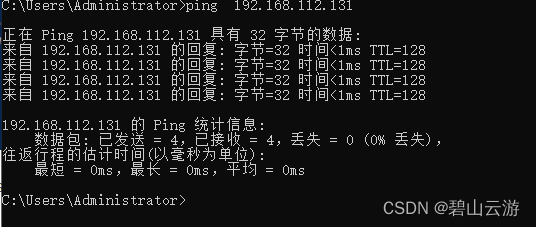
物理机ping不通windows server 2012
刚才尝试各种方法,在物理机上就是ping不能wmware中的windows server 2012 . 折腾了几个小时,原来是icmp 被windows server 2012 禁用了 现在使用使用以下协议就能启用Icmp协议。 netsh firewall set icmpsetting 8然后,就能正常ping 通虚…...

誉天HCIE-Datacom丨为什么选择誉天数通HCIE课程学习
大家好,我是誉天HCIE-Datacom的一名学员,在2022年觉得自己技术水平不够,想要提升自己,经朋友介绍在誉天报的名。 听朋友说誉天的阮Sir的课讲的非常好,我在B站上看了几节阮老师的课确实比之前在听得其他机构的课程讲的要…...
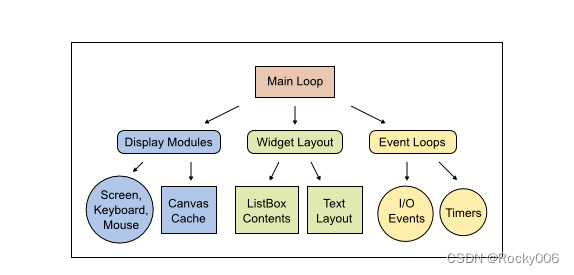
Python文本终端GUI框架详解
今天笔者带大家,梳理几个常见的基于文本终端的 UI 框架,一睹为快! Curses 首先出场的是 Curses。 Curses 是一个能提供基于文本终端窗口功能的动态库,它可以: 使用整个屏幕 创建和管理一个窗口 使用 8 种不同的彩色 为程序提供…...
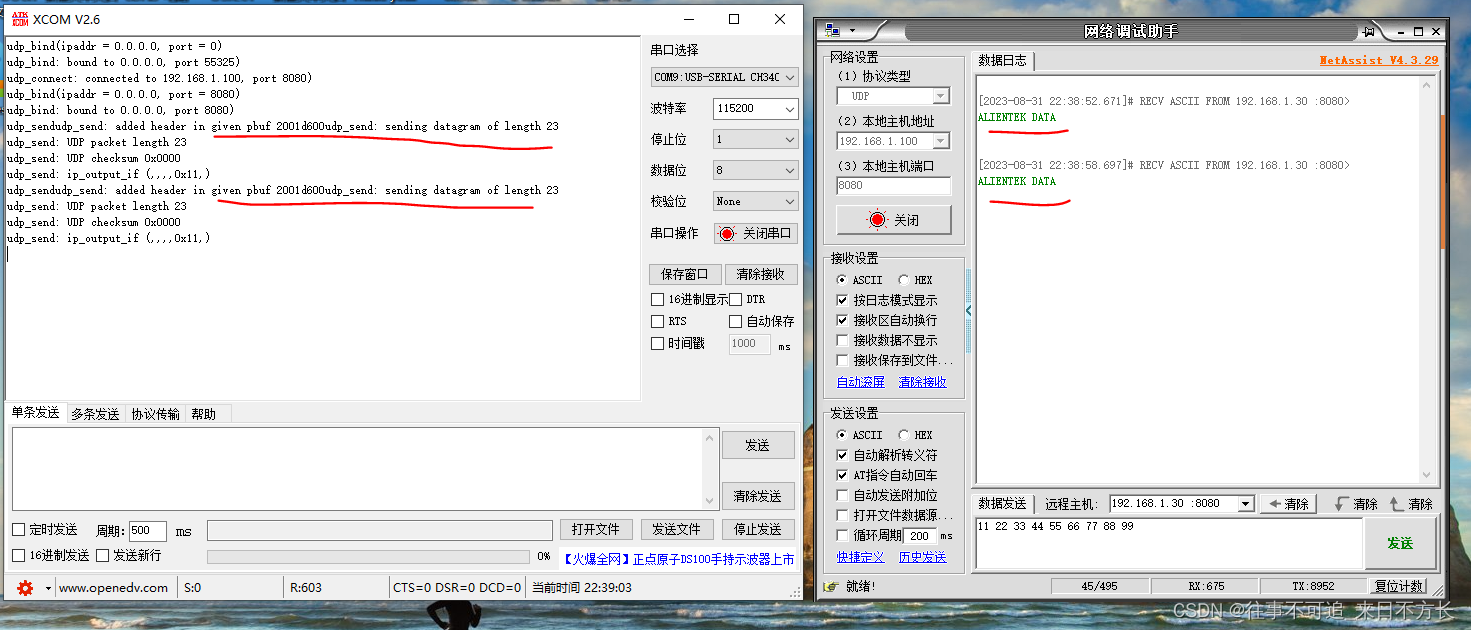
01_lwip_raw_udp_test
1.打开UDP的调试功能 (1)设置宏定义 (2)打开UDP的调试功能 (3)修改内容,串口助手打印的日志信息自动换行 2.电脑端连接 UDP发送一帧数据 3.电路板上发送一帧数据...

告别快捷键混乱!PowerToys保姆级教程:让Win键位秒变Mac,开发效率翻倍
告别快捷键混乱!PowerToys保姆级教程:让Win键位秒变Mac,开发效率翻倍 作为一名长期在Windows和Mac双平台切换的开发者,最令人抓狂的莫过于快捷键的差异。每次从Mac切换到Windows,肌肉记忆总会在关键时刻背叛你——当你…...

避坑指南:在Codesys V3.5中用ST处理XML,我踩过的那些‘坑’
Codesys实战:ST语言处理XML文件的7个关键陷阱与解决方案 在工业自动化领域,XML作为数据交换的标准格式,其重要性不言而喻。然而,当我们在Codesys V3.5环境下使用ST语言处理XML文件时,往往会遇到一系列令人头疼的问题。…...

毕业设计精选【芳心科技】12V锂电池充放电管理系统
实物效果图:实现功能:1.通过电流传感器,电压传感器检测电池电压电流。 2.通过ds18b20温度传感器检测电池温度 3.超温,超压时控制电池停止放电或充电4.利用安时积分法估算剩余电量电量显示要求能实时监控5.控制充放电用一个继电器控…...

RT-Thread下lwIP协议栈内存优化实战:从300KB降至120KB
1. 项目概述与核心价值最近在做一个基于RT-Thread的物联网网关项目,硬件资源是STM32F407,带1MB的RAM。项目需要同时处理4路TCP长连接和若干UDP广播包,原本以为内存绰绰有余,结果一上电跑起来,系统内存占用直接飙到了90…...

你的RAR5密码有多安全?我用hashcat掩码攻击实测了一下
RAR5密码安全实测:从暴力破解到防御策略 当你在深夜赶工,把重要文件打包成加密压缩包发送给同事时,是否想过这个密码能撑多久?上周我给自己设置了一个看似安全的8位数字密码,结果在咖啡还没凉透前就被破解了。这不是危…...

【论文阅读】从过程技能到策略基因:走向经验驱动的测试时进化 From Procedural Skills to Strategy Genes: Towards Experience-Driven
从过程技能到策略基因:走向经验驱动的测试时进化 From Procedural Skills to Strategy Genes: Towards Experience-Driven Test-Time Evolution 作者:Junjie Wang˒* Yiming Ren˒* Haoyang Zhang* InfiniteEvolutionLab, EvoMap 清华大学 wangjunjie@sz.tsinghua.edu.cn…...

注册培训师、咨询师——杨刚老师简介
注册培训师、咨询师——杨刚老师简介注册培训师、咨询师 MTP认证讲师——日本产业训练协会认证 世界500强管理目视化解决方案 版权持有人 杨老师具备10年生产管理经验、15年培训及咨询辅导经验。曾任某日资企业制作课课长、某上市企业精益经理、某民营企业绩效经理、某咨…...

pixi-editor
npm: zouchengxin/pixi-editor 在线地址:pixi-editor.pages.dev 还在为PixiJS缺少可视化编辑器而烦恼?试试 zouchengxin/pixi-editor! 基于 PixiJS 构建的无限画布组件,支持画布平移、缩放,以及元素的拖动、旋转、缩…...

Perplexity计算原理与业务落地脱节?——资深算法架构师亲授7步校准法,避免模型上线翻车
更多请点击: https://codechina.net 第一章:Perplexity的本质定义与数学直觉 Perplexity(困惑度)是衡量概率模型对未知序列预测能力的核心指标,其本质是交叉熵的指数形式,直观反映了模型在面对真实数据时的…...

Kubernetes Operator开发实战
Kubernetes Operator开发实战 一、Operator概述 Kubernetes Operator是一种软件扩展模式,用于管理复杂的有状态应用。 1.1 Operator模式 ┌──────────────────────────────────────────────────────────…...